こんにちは、アルダグラムのSREエンジニアの okenak です
本記事は株式会社アルダグラム Advent Calendar 2023 17日目の記事です。
今年ももう年の瀬ということであっという間でしたが、アルダグラムのSREチームに配属されてから1年が経ったので、これまでに自分がやってきたことを振り返ってみたいと思います。
(量が多いため細かい改善などを除いた大きめのタスクだけ抜粋しています)
やってきたこと
2022/12月
Datadogでモニタリング環境の整備
社内のモニタリング環境としてDatadogが導入されていましたが、専門チームがいなかったため監視や運用周りが十分に整ってない状態だったため整備を行いました。
詳細は以下の記事をご参照ください
AWSでセキュリティ関係の機能の有効化
自社プロダクト(KANNA)の成長に伴い大手企業に求められるクラウドセキュリティ要件が高まってきたため、以下の機能を導入しました
- 外部からの侵入検知対策
- Amazon GuardDutyの有効化
- 定期的なスキャンの実施
- AWS Inspectorの有効化
- セキュリティ基準の評価
- AWS SecurityHubの有効化
今後の課題として、検出された問題に対しての運用体制の整備やセキュリティオートメーションの仕組みの構築等がありますが、来期以降の課題として引き続き取り組んでいく予定です。
OpenAPIのサーバー負荷を分散する対応
KANNAは他社システムとの連携用にOpenAPIを提供していますが、内部で提供するGraphQL部分に関しては通常のKANNAサービスと共通のRailsのバックエンドサーバーを利用していました。
この構成ではOpenAPI一部利用者の特定ケースの処理においてRailsの負荷が高まった際にKANNA全体のレスポンスタイムが悪くなるという問題が発生したため、インフラ基盤を完全に分離することで負荷影響を与えない構成を取る対応を行いました。
2023/1月~3月
シン・デプロイフローの構築
リリース前の確認環境としてdev1(メイン)とdev2(サブ)の2つの環境しかなく、開発組織の拡大に伴い同時並行で進む機能開発が多くなったことで、ビックバンリリースが増えてしまい検証にかかる時間の増加や不具合時の切り戻しなどでデプロイ頻度が悪化している状況でした。
そこで従来の開発基盤やデプロイフローを見直し、各機能施策で占有できるqa環境を10台以上用意し、本番環境の構成に近いpre-prod環境を用意したことで、qaの効率化やリリースタイミングの分散が実現したことでリリース頻度の向上を行えました。
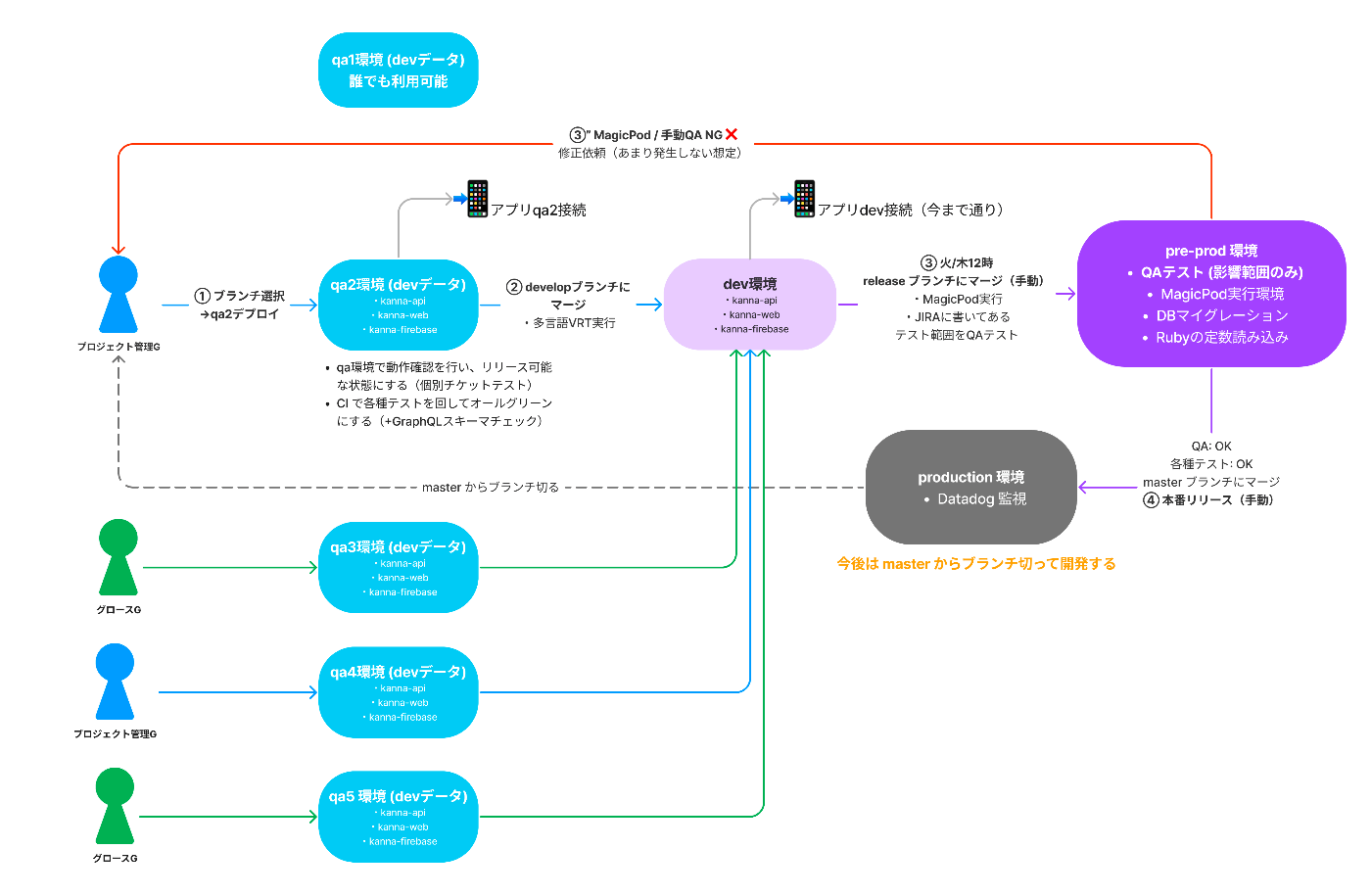
また、新規構築したqa環境ではCloudFormationによるIaC化やデータマイグレーションの手順の整備などで新しい開発環境を追加するための工数の削減を行い、2weeks→1dayに短縮しています。
DBのデータ暗号化要件に対応するためAuroraDBの設定を有効化
大手企業からのセキュリティ要件としてDBの暗号化が求められるようになってきたため、本番環境のAuroraDBの暗号化を有効化しました。
詳細は以下の記事をご参照ください
AWSアカウント管理をIAM Identity Centerへ移行
開発や本番などのAWSのマルチアカウント運用でIAMユーザーの多重管理・セキュアでないクレデンシャル発行運用・2段階認証が強制化できてない等の課題があったため、IAM Identity Centerを導入しました。
詳細は以下の記事をご参照ください
2023/4月~6月
社内のIP更新作業が大変になってきたのでAWS ClientVPNを導入
社員数増加に伴って社内システムのIP解放作業が負担になってきたため、AWS ClientVPNを導入することで管理・運用コストの削減とセキュリティ向上を実現しました。
(ただし現時点では通信料などでランニングコストが高いため別の仕組みに移行を検討してます)
詳細は以下の記事をご参照ください
社内のデータ分析要望への対応のため分析基盤としてRedashを導入
以前はKANNAのデータ分析したい要望に対応するため非エンジニア職以外の方々にもMySQLクライアントをセットアップしてSQLを叩いてもらう運用を行ってました。
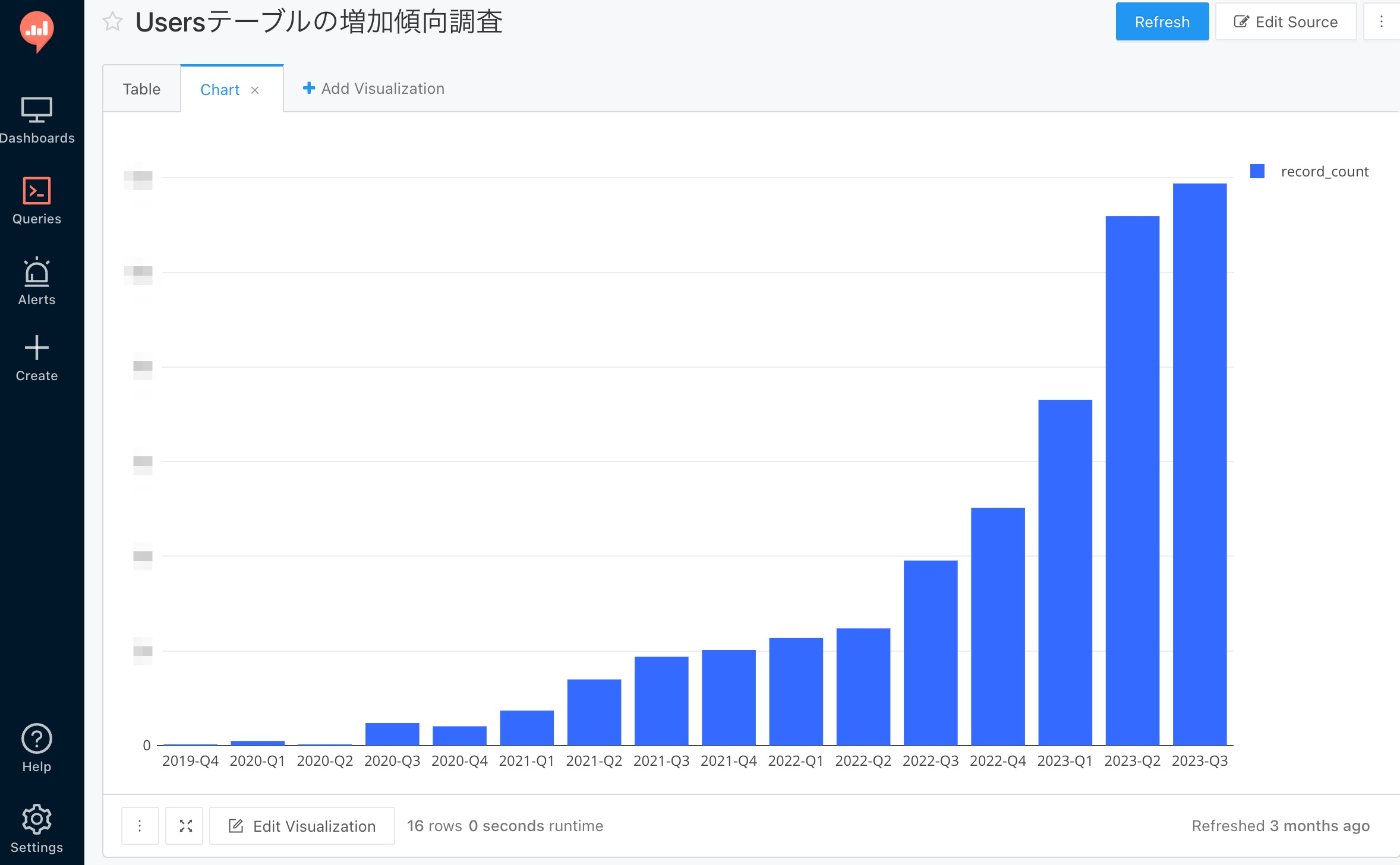
しかしデータ抽出需要の増加や社員数の増加でセットアップや個別サポート周りの対応の負荷が高くなってしまったため、Web上のGUIからクエリを実行できるツール(Redash)を導入することで運用業務の負担の削減を行いました。
Redashに移行したことで分析データのビジュアライズ化や社内共有がしやすくなり、PdM・マーケター・CSなど様々な職種で活用されるようになったため導入効果は非常に高かったです。
2023/7月~9月
KANNAレポートのインフラ基盤の構築
新規サービスを提供するということで、Kotlin + Spring BootのAPI基盤を構築しました。
既存のKANNAと同じECS Fargateを利用したアーキテクチャ構成のため大きな対応箇所はありませんでしたが、コンテナで動かすためのDocker化対応やGithubActionsでデプロイフローの構築、IaCではCloudFormationではなくTerraformを採用といった一部新しい取り組みを行なっています。
Forkeysで開発チームのパフォーマンスを計測する運用を導入
アルダグラムの開発チームではFindyTeam+というサービスを利用して、開発チームの生産性の可視化を行なってきました。その中でForkeysの指標であるデプロイ頻度や変更のリードタイムに関してはデフォルトで取得できるようになっていたのですが、変更障害率や平均修復時間に関してはSaas側が計測する仕組みと弊社のブランチ運用フローが合わなかったため、社内で計測するための運用ルールの整備を行いました。
最終的には障害時にGithubのプルリクにincidentラベルを張る運用で、変更障害数をFindyTeam+側で計測できるようにしましたが、変更障害率や平均修復時間は手計算で出すなど一部手動の運用が残ってしまったため今後の改善課題となっています。

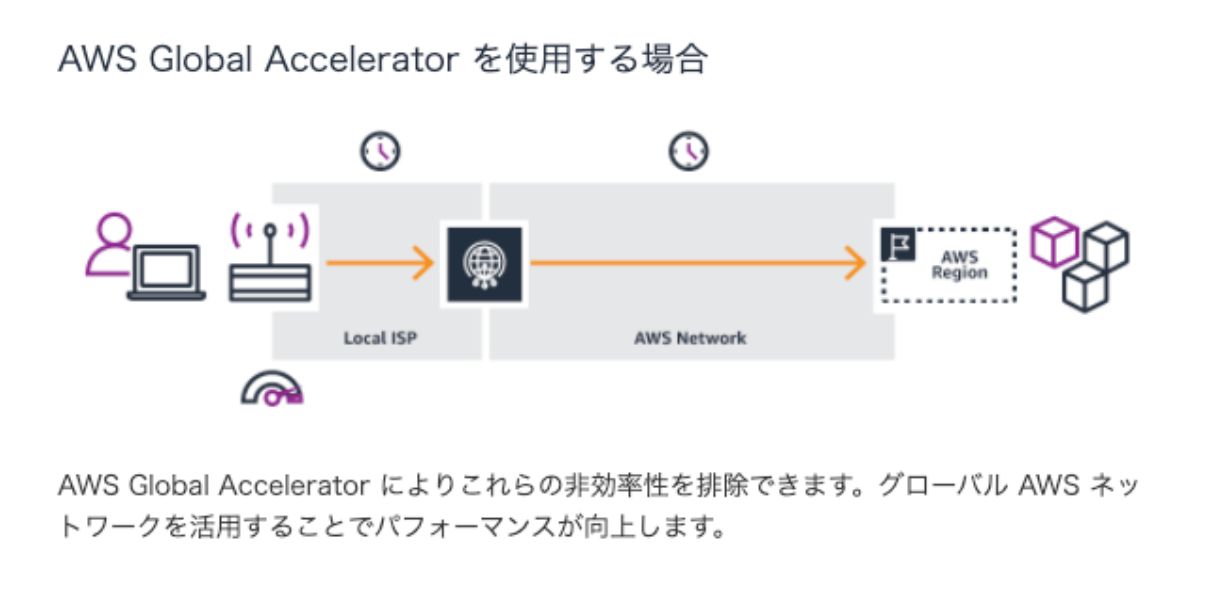
海外アクセスの通信効率化のためAWS Global Acceleratorを導入
KANNAはグローバル展開を行なっており海外からのアクセスもあるサービスなのですが、現在は日本国内リージョンのみで対応しており地理的に離れたユーザーの通信環境に関しては最適とは言えない状況でした。
海外リージョン展開に関しては、費用対効果や法律対応など様々な課題でまだ進めることが難しかったため、一旦 AWS Global Acceleratorを導入することで通信経路の最適化を実施しました。

NotionAPIを使って複数ある開発環境の利用状況の可視化する仕組みを導入
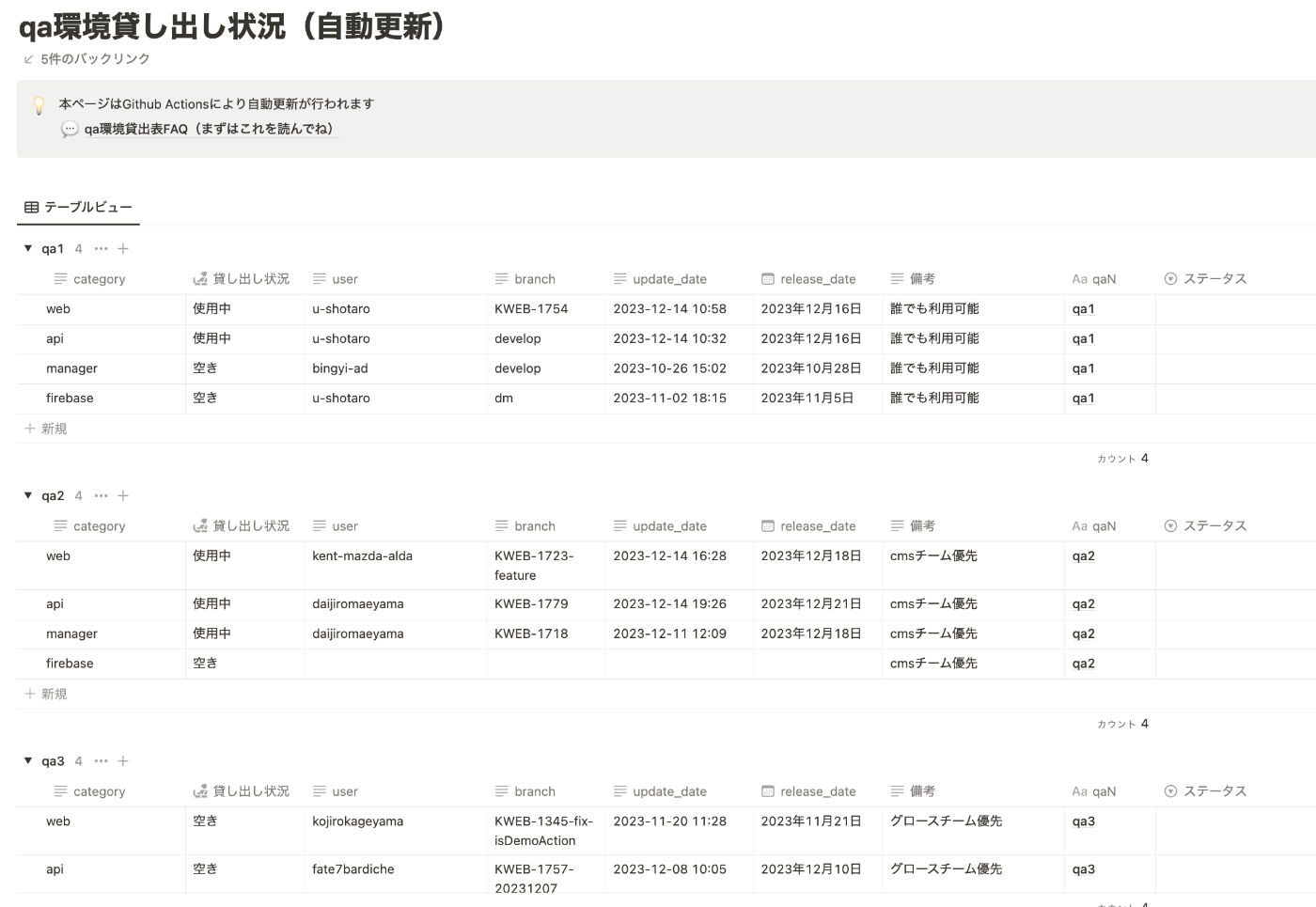
複数の開発環境(qa1~qa10)を用意したことで開発の生産性が向上したのですが、開発メンバーが何の機能開発でいつまで環境を利用するのかについてはコミュニケーションコストが高い状態でした。
社内の情報共有ツールのNotionでページを作って各環境を利用するときは利用者名・反映内容・利用期間を記載してもらう運用を当初は行いましたが、手動での記載作業は更新漏れもあり結局は直接確認しないと該当環境を利用していいのかわからない状況となってました。
この問題に関してはNotionAPIを利用してGithubActionsのデプロイ実行時に、Notionの利用状況ページを自動更新させる仕組みを構築したことで解消しました。
2023/10月~12月
インフラ費用のコスト最適化の対応
これまでは新機能の提供や開発生産性の向上のためなどの増築対応が中心だったため、AWSの費用が1年間で倍増している状態になっていました。
そのため今期ではコスト最適化のための既存構成の見直しに取り組み、FargateSpotの適用・aws samを利用した開発環境の利用時間外の自動停止の導入・NATGatewayの通信費用の削減・SavingPlanの導入に取り組みました。
詳細については別途Techblogの記事で共有したいと思います。
アプリケーションの負荷及び脆弱性への対応のための運用整備
サービスの利用者やデータ量の増加に伴い、レイテンシーの増加やDB負荷が問題になってきたため、Datadogを利用してボトルネック箇所の特定とリストアップ作業を行いました。
また、DBに関してさらに詳細なデータを取得するため各種クエリログをCloudWatchLogsに保存する設定や、Performance Insightsを有効化することで改善活動に役立ちました。
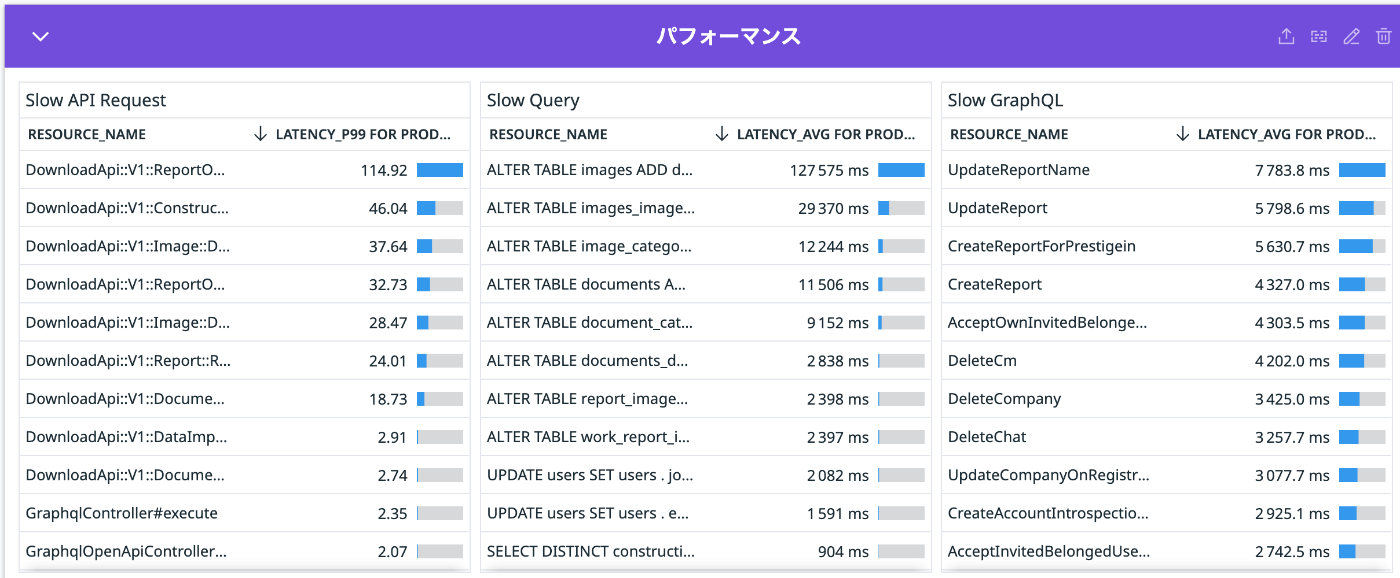
脆弱性対応に関しては、毎年実施している第三者機関(IERAE様)にお願いしている脆弱性診断の内容から、事業へのインパクトから優先順位を決めて開発チームと連携して適宜対応を行なっていくフローを整備しました。
分析負荷を分離するためレプリカ追加とカスタムエンドポイントを設定
社内で利用している分析ツールのRedashが発行するSQLはAuroraのリーダーインスタンスを向いていましたが、実行負荷が高いSQLが発行されるとサービス側に影響が出てしまう問題が発生してしまいました。
一時は社内で発行されるクエリの最適化を行ったり、重そうなクエリに関してはレビューを通すよう注意喚起を行ってましたが、確実に防げる状況ではありませんでした。
根本対応として、Auroraのレプリカとして分析専用のインスタンスを追加してカスタムエンドポイントを利用することでサービス側との向き先を分離する対応で解決しました。
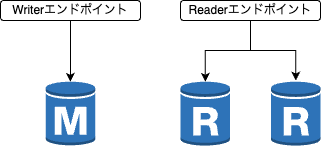
-
デフォルトのエンドポイントだとレプリカを追加してもサービス側と分離ができない
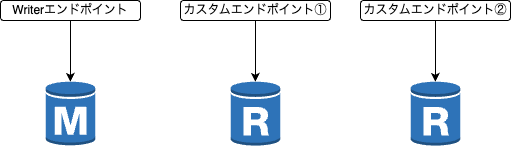
-
カスタムエンドポイントを設定することでサービス側と分析基盤の通信先の分離を行う
Aurora3系とMySQL8のバージョンアップ対応
既存DBのAuroraは2系+MySQL5.7を利用していますが、来年あたりでサポート期限がきてしまうためアップデート対応を絶賛進行中です。まだ、詳細をかける段階ではないため後日改めて報告したいと思います。
総括
あらためて眺めてみると一年を通していろいろやってきましたが、テックブログの記事として書けそうなネタがたくさんできました。まだ記事化できてない内容については今後書いていきたいと思いますので、今後にご期待ください!

株式会社アルダグラムのTech Blogです。 世界中のノンデスクワーク業界における現場の生産性アップを実現する現場DXサービス「KANNA」を開発しています。 採用情報はこちら: herp.careers/v1/aldagram0508/
Discussion