こんにちは。アルダグラムでエンジニアをしている okenak です。
弊社サービスのKANNAでは、システム監視にDatadogを使用しております。
今回は、Datadogのダッシュボード周りを整備して監視・運用フローを改善しましたので、その点を紹介したいと思います。
Datadogの監視・運用周りの課題
弊社では昨年にDatadogを導入しましたが監視・運用において、いくつかの課題が残ってました。
- 必要十分な監視項目やアラートが設定されていない
- トラブル時にどこで問題が起こっているか分かりづらい
- アラートのオオカミ少年化
次に課題について詳細と改善内容について紹介します。
課題1. 必要十分な監視項目やアラートが設定されていない
1つ目の課題としては、KANNAのサービスが急拡大していくなかで管理するリソースが増えていくことで、Datadogのモニターやアラートが足りてないという問題がありました。
これまでは問題が発生していませんでしたが、今後システム運用を続けていくなかで
障害の検知に遅れてしまったり、問題の予兆を見逃してしまうなどのリスクはある状態でした。
改善1. 外型監視の追加
DatadogのSynthetic Monitoringを利用してAPIテストの項目を追加しました。
外部から定期的にテストを実行することでサービスに異常がないかを確認することができます。
一定時間サービスから応答がない場合はSlackにアラートが通知されるように設定しました。

改善2. ECSのタスク別で負荷を表示
これまではECSクラスター単位でのCPUやメモリ使用率を表示していましたが、複数タスクがある場合に平均での表示となってしまい各コンテナ毎の負荷状況がよくわらからない状況でした。

AWSのContainer Insightsの利用も検討しましたが、DatadogでもContainer Agentを導入することでタスク別に集計することができるようでしたので表示項目として設定しました。
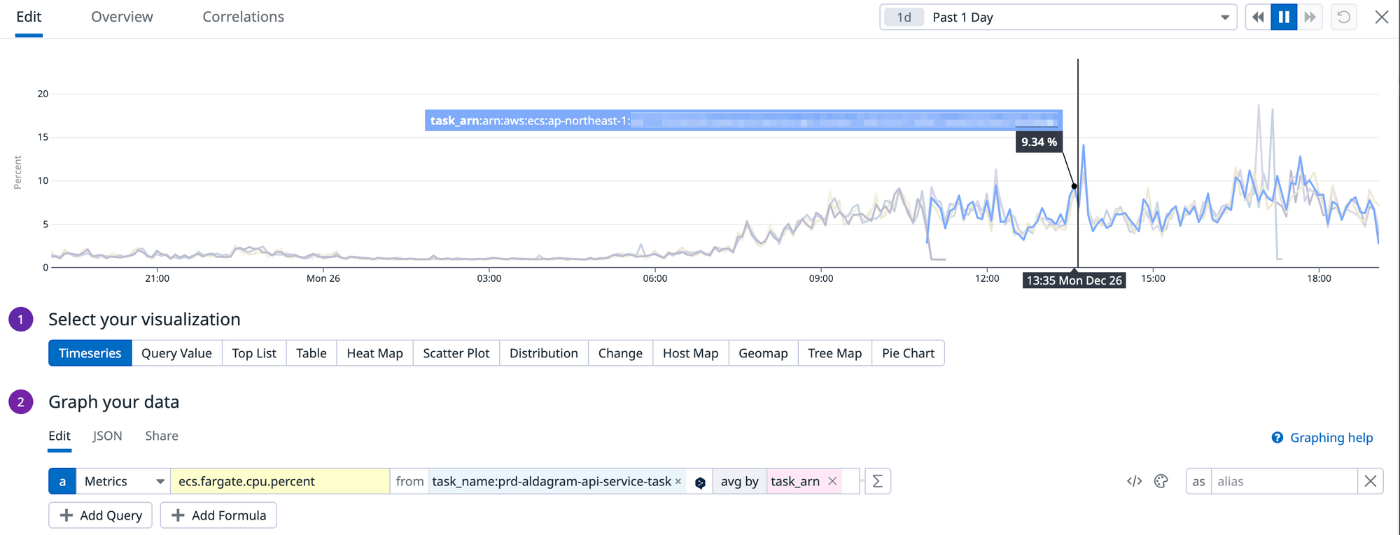
※上記グラフはECSのタスク毎に異なる色で表示されています
改善3. 各種リソースの監視項目の追加
ダッシュボード上に不足していた監視項目の追加を行いました。
- ALBはリクエスト数以外にもRPS・レスポンスタイム・正常ホスト数・エラー数を追加
- RDSはCPU、空きメモリ以外にスループット・レイテンシー・コネクション数を追加
- ElastiCache(Redis)の監視を追加


※上記については次に紹介する2番目の課題と合わせて対応を行なっています。
課題2. トラブル時にどこで問題が起こっているか分かりづらい
2つ目の課題については、トラブル時の切り分けのための情報が集約されていないことでした。
初期に作成したDatadogのダッシュボードには最低限の情報しかまとめておらず、細部を調べるためには各機能のページを参照しなければならず、サービス監視の俯瞰性が低い状態でした。

また、既存のアラートに関してもSlackに通知が流れるため、トラブル時には様々な通知でログが流れてしまい俯瞰して見づらいという問題もありました。
改善1. ダッシュボードの整理
改善後のダッシュボードでは「今何が起こっているか」「どこで問題が起きているか」を
簡単に理解できるよう意識して表示内容の整理を行いました。

改善2. サマリーの表示
最初にサマリーという項目を用意することで、KANNAのサービス全体が正常に稼働しているかを俯瞰して確認しやすいようにしています。

左半分はDatadogのサービスレベル目標(SLO)の機能を使い、各種APIの外形監視の結果を集計することでサービスの提供状況を可視化しています。
右半分のモニターサマリーとなっており、各種項目の閾値が超えてないかどうかが
分かるようになっており、障害時にどこで問題が起きてるかを見つけやすくしています。
改善3. エラーログの表示
DatadogのLogs Streamのウィジェットを利用して標準エラーを監視できるようにしました。
弊社ではRailsのエラーはBugsnagというサービスを利用してインシデントを管理していますが、
ダッシュボード側にも用意することで、トラブルシューティングが捗るようになったと思います。

改善4. パフォーマンスの表示
Datadog APMを使ってスロークエリやスローAPIを表示できるようにしました。
以前からもAPMを使ったパフォーマンス監視は行なっていましたが、各機能のページから
都度モニタリングしていたのを集約管理することで問題箇所の特定しやすくなっています。

課題3. アラートのオオカミ少年化
3つ目の課題については、緊急性や重要度が低いアラートもSlackに通知されていることで
エンジニアのアラートに対する意識が低くなってしまうことでした。
人間の注意力には限りがあるので、不必要なアラートは重要な障害を見逃すリスクになります。

改善1. アラートのトリアージ
医療現場では災害時に多くの患者が発生した場合に、患者の緊急度や重症度に応じて治療の優先度順位を決めるトリアージという行為を行うそうです。
システム運用の現場においてもトラブル発生時に対応できる人的リソースが限られてくるため、アラートの重要に応じて対応を変えていく必要がありそうです。
こちらはDatadogのモニタリング項目のPriorityを使って優先度を定義することにしました。

また、特に重要でもないインフォメーション的なアラートは通知から外しました。
改善2. 通知先の振り分け
アラートの優先度に応じてSlackの通知先チャンネルを2種類に分けることにしました。
- 緊急度高
- KANNAのサービスが停止している系。エンジニアの即時介入が必要なもの
- #bot_incidentチャンネルに通知
- KANNAのサービスが停止している系。エンジニアの即時介入が必要なもの
- 緊急度低
- 問題を検出したが対応までに猶予期間があるもの
- #bot_datadogチャンネルに通知
- 問題を検出したが対応までに猶予期間があるもの

以上の改善で #bot_incident に通知されるアラートだけに最も注意を払えばよくなったため、不必要なアラートにより注意力が削がれることを減らすことができたと思います。
まとめ
今回はDatadogを活用した監視・運用周りについて紹介させていただきました。
紹介したものについては、日々の運用の中で改善され続けていく項目になりますので、来期にはまた違った内容になってるかも知れません。
私自身もDatadogやインフラ周りについて更に詳しくなり、KANNAが中長期的な成長を遂げるための、盤石な基盤を作っていければと思っています。

株式会社アルダグラムのTech Blogです。 世界中のノンデスクワーク業界における現場の生産性アップを実現する現場DXサービス「KANNA」を開発しています。 採用情報はこちら: herp.careers/v1/aldagram0508/
Discussion