【線分交差】GISを作るデータ構造とアルゴリズム【計算幾何学】
概要
前回の記事では, GISの基本機能のひとつ,「凸包計算」を実装した. 計算幾何学のなかで培われてきた幾何情報へのアルゴリズムの美しさの一端が見えたかと思う.
今回から, より実用的なGIS機能に合わせた処理を考えていく.まずは, 「地図の重ね合わせ」 である.
GISを使っているといくつかの地図データ(レイヤー) を重ねて,新たなデータを作ったり分析したりすることがある.例えば, 異なる災害のハザードマップの重ねて, 自分が住んでいるエリア・街の被災リスクを検討することが挙げられる.
以下は国土交通省が公開している「重ねるハザードマップ」の例である.
洪水・内水のハザードマップ

津波のハザードマップ

こうした「地図の重ね合わせ」処理について実装していこうと思う.
重要なテクニックとして, 地物のポリゴンを「二重辺リスト」と呼ばれるデータ構造で表現し, 「平面走査法」と呼ばれるアルゴリズムを用い, 「地図の重ね合わせ」に関わるさまざまな処理を効率的に解いていることだ.
今回はそのうちの「平面走査法」を説明する.
今回も「コンピュータ・ジオメトリ 第3版 計算幾何学:アルゴリズムと応用」を参考にしていく.
地図の重ねあわせ
「地図も重ねあわせ」の簡単な例をみながら, アルゴリズムの入力と出力についてまずは考えていこう.
いま下図のような図形
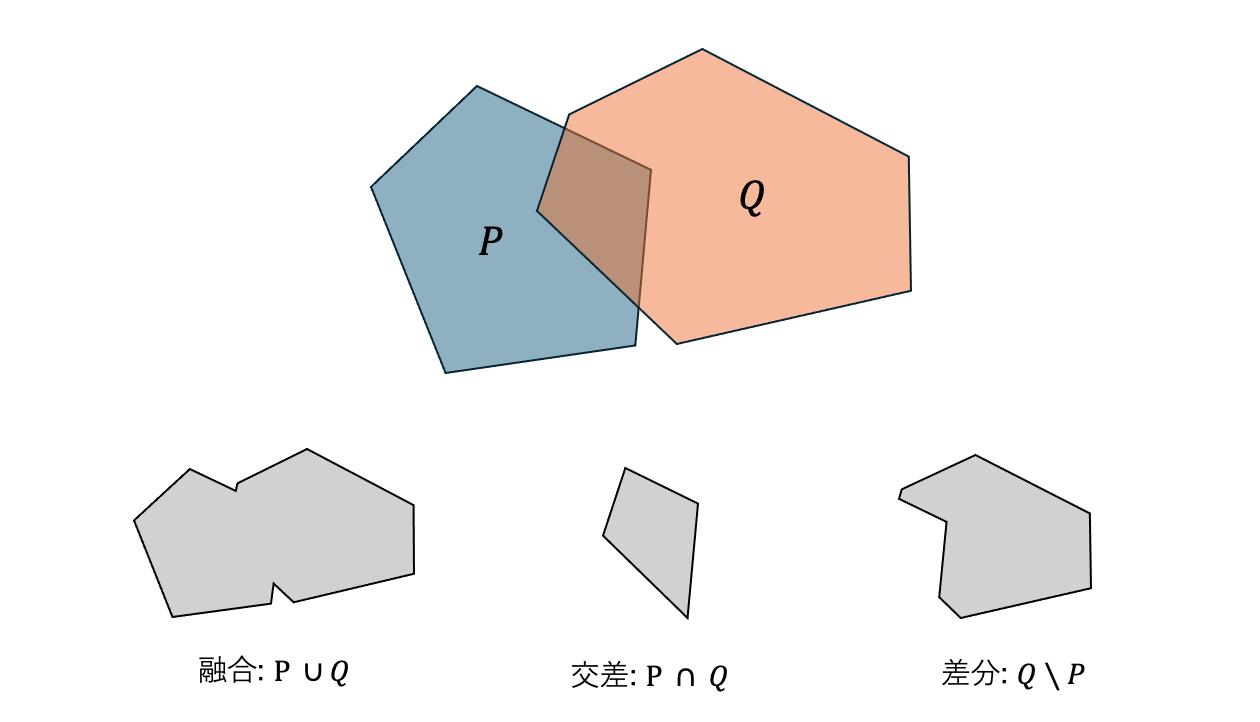
重ね合わせには, 「融合」「交差」「差分」といった種類の処理方法がある. 目的に応じて処理後の図形の形も変わっていることがわかる.[1]
ここで考えたいことは,どのようにしたら「融合」「交差」「差分」といった「重ねあわせ」の処理が実装できるか, ということだ.
どのように「処理」するかの前に, どのような「出力」であれば目的合うかを考えてみよう.
ポイントは, 前回の記事で扱った「凸包」がそうであったように, 「重ね合わせ」後の図形(=領域)は, 点集合により表現できることにある.

改めて図形
すると, 「重ねあわせ」の処理の入出力は次のようにすべて点集合で表現できる.
- 入力: 図形
P=[p_1,p_2, ..., p_5] Q=[q_1,q_2,...,q_6] - 出力:
- 融合: 図形
[p_1,p_2,A, q_2, ..., B, p_4,p_5] - 交差: 図形
[q_1,A, p_3, B] - 差分: 図形
[A, q_2, ..., q_6, B, p_3]
- 融合: 図形
注目してほしいのは, どの「重ねあわせ」方法であっても, 2つの図形の交差点を
そして, 処理への入力時にはまだ交差点の情報が入っていないことから, 「重ねあわせ」の処理のどこかで交差点を求める必要がある.
本記事は, その「交差点」を求める方法に焦点を当てよう.
わかりやすくするため, 図形を複数の線分の集合とみなし, 交差点は異なる図形に含まれる線分同士の交差により発生する, ものとしてアルゴリズムを考えよう.
線分交差
素直なやり方
前段で, 「地図の重ねあわせ」処理において, 異なる図形間での交差点を求める(あるいは, 交差するかどうかも含め)必要があると述べた.
シンプルな方法は, すべての線分の組み合わせで交差点の判定および交差点の座標を求める方法だ.いわゆる総当たり法(=ブルートフォース) と呼ばれるものだ.
言わずもがな, この方法はシンプルすぎるが故に, 大規模なデータにはとてもじゃないほどの計算コストがかかる.なぜなら, 総当たり法の計算量は
地図のデータは, 何千,何万という線分をもつデータに平気でなりうる. そのため,
よく考えると, 線分が交差するケースはそこまでないはずだ. ある線分が,他のすべての線分のうち, 交差する可能性があるものはそもそもとても少ないはずで, 計算の対象をかなり削減できるはずである.
ここでは, 実行時間が入力の線分数だけではなく, 交点の個数にも依存するようなアルゴリズムがほしいのである. こうしたものを, 出力サイズに敏感なアルゴリズムという. できるだけ無駄を排した計算方法を探したいのだが, そのヒントが「幾何学的な特徴」に隠れている.
平面走査法
「幾何学的な特徴」といえば, 何よりも座標から求まる「距離」がイメージできるだろう.
線分が交差するには,そもそも線分同士が近くなければ発生し得ない...と考えることはできないだろうか.
簡易的な方法で, 線分の長さ,つまり, 2頂点をy座標に投影してみると, なんとなく線分が交差する線分のペアが絞られてくる.(下図)
下図では,線分
y軸上に各線分を投影することで, そもそも交差する線分のペアを限定できそうだ!
つまり, y軸上での区間が重なりをもつような線分対だけを, つまり両方の線分と交わる水平線が存在するような線分対だけを調べたらよい, ことになる.

そこで, どの線分のy軸よりも高い位置から低い位置へ移動する走査線
具体的には, 走査線
もちろん走査線
上図でイメージをしてもらう. 走査線状態の更新タイミングとして,
- 線分上端に走査線が通ったとき
- 線分下端に走査線が通ったとき
のふたつのイベント点が重要である.
1)の場合, この線分を走査線状態に加え, 既存の走査線状態内の線分との交差判定に利用する.2)の場合い, この線分を走査線状態から排除し, 以後, 交差判定には使わないようにする.
上記の方法でうまくいけるかなー🧐と思うも, 実は意地悪な例もあり, その場合には総当たり法との優位性が出てこなくなる. 例えば, 下図の左のように, y軸方向に並行な線分がほどよく範囲を共有している場合だ. 実際には交点が一つもないのに, かなりの数の交差判定を要求される.
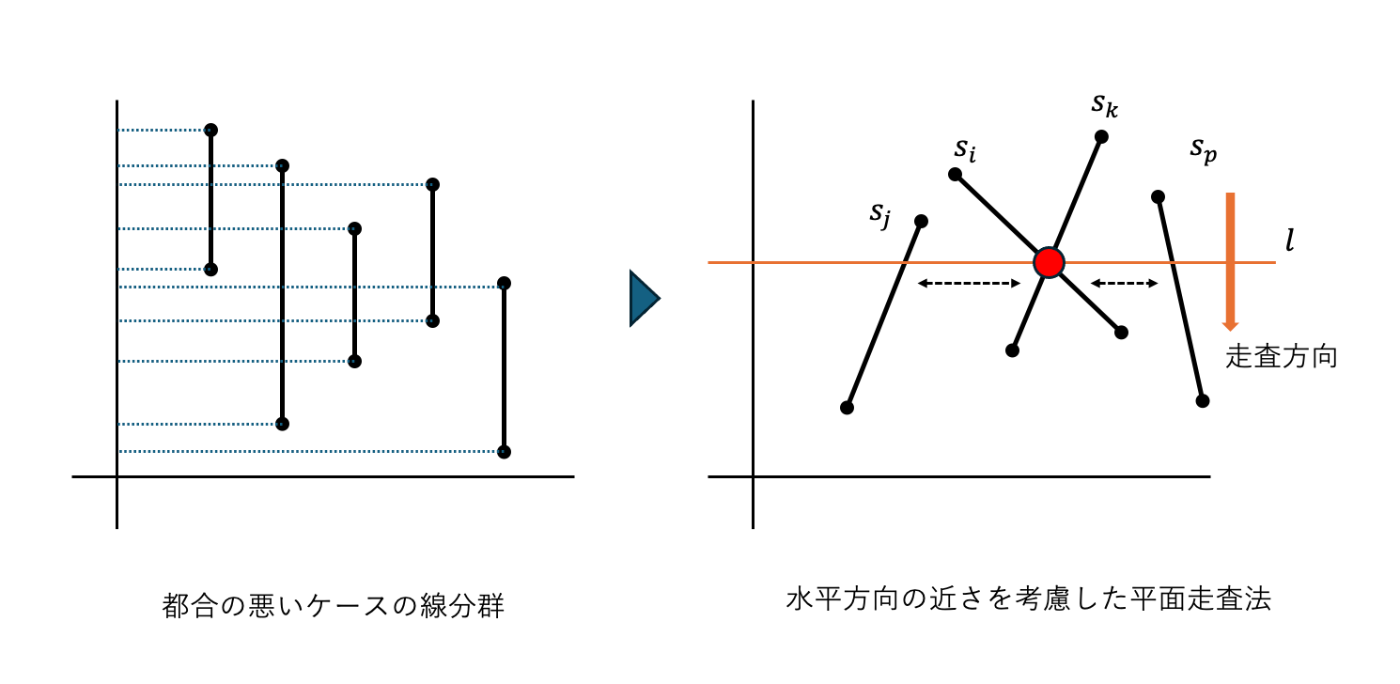
そこでさらに改良が加えられ, 水平方向の近似性を交差判定に考慮されるようにする.
つまり, x軸方向で隣接している線分同士のみで交差の判定をすることで, さらに無駄な処理を減らす.
すると,走査線状態としては単なる線分集合ではなく, 各線分の隣接関係を保持できるものに変える.
そして, 走査線状態の更新タイミングとして,
- 線分上端に走査線が通ったとき
- 線分下端に走査線が通ったとき
- (New)交差点に走査線が通ったとき
の3つのイベント点が重要である.さらに, 3番目の"交差点"をイベント点を考慮しはじめているのに注目だ.
それぞれ, 1)において, この線分を走査線状態に加え, 既存の走査線状態内の線分との隣接関係を更新し, その後, 交差判定に利用する. 2)において, この線分を走査線状態から排除し, 走査線状態内の線分との隣接関係を再更新する. 3)において, 交差点前後で, この交差点をつくる2つの線分の左右関係が変化することから, 走査線状態内の線分との隣接関係を更新する.
これならうまくいきそうだ. これらを整理して,必要なデータ構造とアルゴリズムを用意しよう.
データ構造とアルゴリズム
イベントキューと走査線状態構造
それでは必要なデータ構造から定義していく.
平面走査法では,走査線状態の更新タイミングはイベント点にあると述べた. つまり, イベントキューではこれらのイベント点を格納し, 走査線状態の更新のトリガーを管理させる.
キュー
例えば, 走査線がy軸の大きい方向から小さい方向へ移動する場合, キュー
そして, イベント点は平面走査法の処理過程で増えることもある. つまり, 交点が発見された場合だ. 交点がイベント点として重要な意味を持つことは先に述べたとおりである.
よって, キュー
キューには,単なる点座標だけでなく, その点がどの線分のものか, そして,その点が始点・終点・交点のどれかを管理しておこう. これらの情報は, あとで定義する状態構造ツリーの操作にて重要な情報となる.
pythonであれば, headqライブラリを使用すると簡単に優先度付きキューを実装できるのでおすすめだ. headqライブラリそのものの説明は以下の記事たちに任せる.
イベントキュー実装例
from heapq import heappush, heappop, heapify
class EmptyQueueException(Exception):
def __str__(self):
return "Cannot pop an empty queue"
class PriorityQueue:
'''
各イベント点を管理し 逐次処理をサポートするキュー
'''
def __init__(self):
self.queue = []
self.dup = set()
def __str__(self):
return '[' + ' '.join([str(i) for i in self.queue]) + ']'
def isEmpty(self):
return len(self.queue) == 0
def pushAll(self, l):
for a in l:
self.push(a)
# for inserting an element in the queue
def push(self, e):
if e.status != "int": # 交点以外なら素直にキューに入れる
heappush(self.queue, e)
elif e not in self.dup: # 交点であり, まだ未登録であれば追加(異なる線分での同じイベント点を重複登録するのを避ける)
heappush(self.queue, e)
self.dup.add(e)
def __len__(self):
return len(self.queue)
def pop(self):
if self.isEmpty():
raise EmptyQueueException()
else:
return heappop(self.queue)
def __iter__(self):
"""
Do ascending iteration for TreeSet
"""
for element in self.queue:
yield element
def clear(self):
self.queue = []
次に,線分の隣接関係を記録する状態構造
隣接関係という言葉からわかるように, ある線分の左隣の線分, 右隣の線分という二つの情報を記録する必要がある. とすれば, 平衡2分木が便利であろう.
このツリーが更新されるタイミングは, イベントキュー
- イベント点が線分の始点の時: 状態構造
T s - イベント点が線分の終点の時: 状態構造
T s - イベント点が線分間の交点の時: 状態構造
T
どの処理であっても, ツリー上で隣接関係が変動し, イベント点に関連する線分を中心とした隣接する線分との交差判定を実施する. もし, 交差判定により交点が見つかった場合には, イベントキュー
平衡2分木については, pythonでのbisectライブラリを使用するのが良いだろう.
こちらも以下の記事たちにライブラリの説明は任せる.
状態構造の実装例
import bisect
class TreeSet(object):
"""
bisectを用いた2分木データ構造
各セグメントの大小関係を管理させる
"""
def __init__(self): # 初期化
self._treeset = []
self.pop_number = 0
self.push_number = 0
def isEmpty(self): # 空判定
return len(self) == 0
def addAll(self, elements): # treesetにない要素であれば追加
for element in elements:
if element in self: continue
self.add(element)
def add(self, element):
if self.isEmpty() or element not in self:
bisect.insort_right(self._treeset, element)
self.push_number += 1
def add_high_low(self, element): # ツリーに新しい線分を追加
if element not in self: # 未登録であれば
index = bisect.bisect_right(self._treeset, element)
self._treeset.insert(index, element) # 新規挿入
low = self._treeset[index - 1] if index > 0 else None
high = self._treeset[index + 1] if index < len(self._treeset) - 1 else None
self.push_number += 1 # ツリーサイズの更新
return low, high # 両隣の線分を返す
return None
def push(self, element):
self.add(element)
def pushAll(self, l):
for a in l:
self.push(a)
def pop(self):
if not self.isEmpty():
res = self._treeset[0]
self._treeset = self._treeset[1:]
return res
return None
def higher(self, e): # 与えられた値よりも大きいtreesetのうち最小のものを返す(つまりセグメントeのお隣)
index = bisect.bisect_right(self._treeset, e)
if index < self.__len__():
return self[index]
else:
return None
def lower(self, e): # 与えられた値よりも小さいtreesetのうち最大のものを返す(つまりセグメントeのお隣)
index = bisect.bisect_left(self._treeset, e)
if index > 0:
return self[index - 1]
else:
return None
def swap(self, e1, e2): # treeset内の要素を交換
i1 = self._treeset.index(e1)
i2 = self._treeset.index(e2)
self._treeset[i1] = e2
self._treeset[i2] = e1
def __getitem__(self, num): # treeset[i]
return self._treeset[num]
def __len__(self):
return len(self._treeset)
def clear(self):
"""
ツリーを空にする
"""
self._treeset = []
def remove(self, element):
"""
指定した要素をツリーから排除する
"""
try:
self._treeset.remove(element)
except ValueError:
return False
return True
def __iter__(self):
"""
繰り返し処理
"""
for element in self._treeset:
yield element
def __str__(self):
return '[' + ' '.join([str(i) for i in self._treeset]) + ']'
def __eq__(self, target):
if isinstance(target, TreeSet):
return self._treeset == target._treeset
elif isinstance(target, list):
return self._treeset == target
def __contains__(self, e): # e in self の処理
"""
Fast attribution judgment by bisect
"""
try:
return e == (self._treeset[bisect.bisect_left(self._treeset, e)])
except:
return False
擬似プログラミング
アルゴリズム:
入力: 平面上の線分集合
出力:
- イベントキュー
Q Q - 状態構造
T - while
Q - ---- do
Q p - ----
HandleEventPoint(p)
アルゴリズム:
-
U(p) p p -
T p T p L(p) p C(p) - if
L(p) \cup U(p) \cup C(p) - ---- then
p L(p), U(p), C(p) -
L(p) \cup C(p) T -
U(p) \cup C(p) T T p - (
C(p) - if
U(p) \cup C(p) = 0 - ---- then
T p s_l, s_r - --------
FindNewEvent(s_l, s_r,p) - ---- else
T U(p) \cup C(p) s' - --------
s_l T s' - --------
FindNewEvent(s_l, s',p) - --------
T U(p) \cup C(p) s'' - --------
s_r T s'' - --------
FindNewEvent(s'',s_r,p)
アルゴリズム:
- if
s_l s_r p Q - ---- then この交点をイベント点として
Q
具体例
最後に, 一体全体平面走査法のなかで, イベントキュー
下図の左のような線分集合に対し交点を求めていく. それぞれ走査線の位置が,
走査線位置
走査線位置
ここで重要なのは, まだこの状態では線分
その後, 走査線位置

まとめ
今回は「地図の重ねあわせ」処理に必要な交点を見つけるアルゴリズム「平面走査法」について説明した. 次回は, アルゴリズム「平面走査法」を駆使し, いよいよ「地図の重ねあわせ」処理へと拡張していく.
P.S.
プログラムコードについては必要であれば公開する予定である. かなり長くなるので記事に載せることは避けた. 兎にも角にも, 第二章の段階で高度な話になってきていて辛い🥹
Discussion