ひとりMongoDB University / M201 MongoDB Performance(4)
この記録は、アドベントカレンダー形式ではじめた、MongoDB Universityの学習コースの記録の続きになります!
ただいまのコース
- M201 MongoDB Performance
このコースでは、開発者 / オペレーション担当者双方向けの中級レベルの内容とのことです。
前回の記事は、ひとりMongoDB University / M201 MongoDB Performance(3) でした。
Chapter 2: MongoDB Indexes
Text Indexes (動画)
文字列のフィールドに対しては、完全一致が基本。あるいは部分一致(like的なもの)での検索になる。
テキストインデックスを使うと、テキストをスペース(その他、トークナイザー)で区切って分かち書きし、それらをキーとして検索が可能になる。
- Ref. https://docs.mongodb.com/manual/core/index-text/
- いろいろ条件があったりしますね....
- "MongoDB Long Sleeve T-shirt" という文字列だと、分かち書きされて以下のキーができる
- mongodb
- long
- sleeve
- t
- shirt
- "-" (ハイフン) もトークナイザーとみなされるので注意!
- デフォルトでは、ケースインセンシティブ(大文字小文字を区別しない)
- トークナイザーで区切って複数のキーを保持するので、マルチキーインデックスと近いものになる
テキストインデックスの注意点
- 条件にマッチさせるためのキーが多くなる
- インデックスのサイズが大きくなる
- インデックス生成 / 更新にもコスト(時間)がかかる
- ドキュメントの書き込みも遅くなる
# テストデータを登録
db.textExample.insertOne({ "statement": "MongoDB is the best" })
db.textExample.insertOne({ "statement": "MongoDB is the worst." })
# textExample というコレクションが作成されるので、データ確認
db.textExample.insertOne({ "statement": "MongoDB is the worst." })
{ acknowledged: true,
insertedId: ObjectId("617567ae48565e4352a4546f") }
db.textExample.find().pretty()
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best' }
{ _id: ObjectId("617567ae48565e4352a4546f"),
statement: 'MongoDB is the worst.' }
# 完全一致での検索
db.textExample.find({ statement: 'MongoDB is the best'})
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best' }
# 部分一致での検索
db.textExample.find({ statement: 'MongoDB is'})
# ヒットしません....
# パターンマッチでの検索 (2件ヒットします)
db.textExample.find({ statement: /MongoDB is/})
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best' }
{ _id: ObjectId("617567ae48565e4352a4546f"),
statement: 'MongoDB is the worst.' }
# MongoDB, best で検索したい場合は、このままだと難しい
# テキストインデックスを生成
db.textExample.createIndex({ statement: "text" })
# テキストインデックスの場合は、$search 演算子を使います
db.textExample.find({ $text: { $search: "MongoDB best" } })
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best' }
{ _id: ObjectId("617567ae48565e4352a4546f"),
statement: 'MongoDB is the worst.' }
# MongoDB, best というキーワードが対象ですが、2つヒットしてしまった....
# なぜ??
$searchオペレーターの注意点
-
{ $search: "MongoDB best" }と指定すると、スペースで区切ったMongoDBあるいはbestを含む OR での検索になる - 例だと、何かを含めばいいことになるので、'MongoDB is the worst.' もヒットしてしまう
- AND での検索ができないの??
# 検索の際に、どれだけ条件に一致しているかを示すため、「重み」という考え方が出てくる
# { $meta: "textScore" } でメタデータを表示してみる
db.textExample.find({ $text: { $search : "MongoDB best" } }, { score: { $meta: "textScore" } })
{ _id: ObjectId("617567ae48565e4352a4546f"),
statement: 'MongoDB is the worst.',
score: 0.75 }
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best',
score: 1.5 }
# MongoDB, best の両方を含む方は重みが 1.5になっている
# sort することで、より条件に近い(AND になっている)ものを先に持ってくることが可能
db.textExample.find({ $text: { $search : "MongoDB best" } }, { score: { $meta: "textScore" } }).sort()
{ _id: ObjectId("617567ad48565e4352a4546e"),
statement: 'MongoDB is the best',
score: 1.5 }
{ _id: ObjectId("617567ae48565e4352a4546f"),
statement: 'MongoDB is the worst.',
score: 0.75 }
テキストに対してのインデックスの重み付けは、Elasticsearch もそんな感じだったかな...。
この動画では出てきていないが、以下のドキュメントも参考に。
-
Control Search Results with Weights
- テキストインデックス作成時の、重み付けを調整できる
Compass での表示だと、以下の通り。
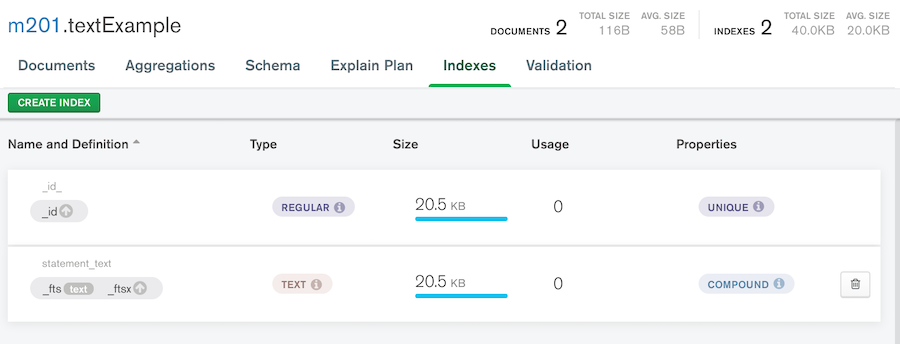
対応している言語について
- 日本語は、全角スペースや句点、句読点が認識されないので、トークナイザーの動作が異なります
# ちょっと実験
db.textExample.insertOne({ "statement": "これは、日本語の文章です。" })
# ``、``(読点) はトークナイザーになるっぽいな
db.textExample.find({ $text: { $search: "これは 文章" } }, { score: { $meta: "textScore" } })
{ _id: ObjectId("617570b448565e4352a45470"),
statement: 'これは、日本語の文章です。',
score: 0.75 }
# ``これ`` ではヒットしません
db.textExample.find({ $text: { $search: "これ" } }, { score: { $meta: "textScore" } })
# ``文章`` ではヒットしません
db.textExample.find({ $text: { $search: "文章" } }, { score: { $meta: "textScore" } })
# ``日本語の`` でもヒットしません
db.textExample.find({ $text: { $search: "日本語の" } }, { score: { $meta: "textScore" } })
# ``日本語の文章です`` ではヒット
db.textExample.find({ $text: { $search: "日本語の文章です" } }, { score: { $meta: "textScore" } })
{ _id: ObjectId("617570b448565e4352a45470"),
statement: 'これは、日本語の文章です。',
score: 0.75 }
db.textExample.find({ $text: { $search: "日本語の文章です。" } }, { score: { $meta: "textScore" } })
{ _id: ObjectId("617570b448565e4352a45470"),
statement: 'これは、日本語の文章です。',
score: 0.75 }
- サポートしている言語には指定がある
- インデックス生成時に、言語の指定ができる
# 指定例
db.quotes.createIndex(
{ content : "text" },
{ default_language: "spanish" }
)
Check: Text Indexes
- テキストインデックスは、フィールドに対して文字列をトークナイザーで分かち書きして、複数のキーを持つインデックスとして構成するので、マルチキーインデックスに近くなります
Collations (動画)
- 照合順序
- 特定の言語における発音やルールを加味した順序について
- 検索やオーダーの際には、このCollationの設定、指定によって変わってくる - Collations
- Ref. https://docs.mongodb.com/manual/reference/collation/
- コレクションやView、インデックスにも指定ができる
- Ref. https://docs.mongodb.com/manual/reference/collation/
# デフォルトではこの順番で評価
{
locale: <string>,
caseLevel: <boolean>,
caseFirst: <string>,
strength: <int>,
numericOrdering: <boolean>,
alternate: <string>,
maxVariable: <string>,
backwards: <boolean>
}
- コレクション、インデックスの作成の際に、それぞれ異なる照合順序(Collations)を設定できる
- 検索の際にも、インデックスやコレクションとは別のCollationsを指定できる
# コレクション作成(参照順序に pt: ポルトガル 指定)
db.createCollection( "foreign_text", {collation: {locale: "pt"}})
{ ok: 1 }
# ドキュメントを登録 (deprecated みたい.....)
db.foreign_text.insert({ "name": "Máximo", "text": "Bom dia minha gente!"})
'DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.'
{ acknowledged: true,
insertedIds: { '0': ObjectId("61768a15fea1cd7a41350a47") } }
# 単純に検索の場合、collation: という要素ができています
# locale の値は pt
db.foreign_text.find({ _id: {$exists:1 } } ).explain()
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.foreign_text',
indexFilterSet: false,
parsedQuery: { _id: { '$exists': true } },
collation:
{ locale: 'pt',
caseLevel: false,
caseFirst: 'off',
strength: 3,
numericOrdering: false,
alternate: 'non-ignorable',
maxVariable: 'punct',
normalization: false,
backwards: false,
version: '57.1' },
winningPlan:
{ stage: 'FETCH',
filter: { _id: { '$exists': true } },
inputStage:
{ stage: 'IXSCAN',
keyPattern: { _id: 1 },
indexName: '_id_',
collation:
{ locale: 'pt',
caseLevel: false,
caseFirst: 'off',
strength: 3,
numericOrdering: false,
alternate: 'non-ignorable',
maxVariable: 'punct',
normalization: false,
backwards: false,
version: '57.1' },
isMultiKey: false,
multiKeyPaths: { _id: [] },
isUnique: true,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { _id: [ '[MinKey, MaxKey]' ] } } },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1635158566, i: 15 }),
signature:
{ hash: Binary(Buffer.from("216e4c7cef29b3dc6b8a4328383b81d20df0aac0", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1635158566, i: 15 }) }
# it: イタリア語 の参照順序を指定して検索
db.foreign_text.find({ _id: {$exists:1 } }).collation({locale: 'it'})
{ _id: ObjectId("61768a15fea1cd7a41350a47"),
name: 'Máximo',
text: 'Bom dia minha gente!' }
# 1件しかないので、検索結果は特に変わらないけれど、aggreagtion の場合にも利用可能
db.foreign_text.aggregate([ {$match: { _id: {$exists:1 } }}], {collation: {locale: 'es'}})
{ _id: ObjectId("61768a15fea1cd7a41350a47"),
name: 'Máximo',
text: 'Bom dia minha gente!' }
# デフォルトでは pt の参照順序。
# name フィールドに関しては、イタリア語の参照順序でのインデックスを作成してみる
db.foreign_text.createIndex( {name: 1}, {collation: {locale: 'it'}} )
'name_1'
# name(インデックスに指定したフィールド)で、参照順序なしで検索の場合、コレクションのデフォルトを利用
# 今回は pt を使っている
db.foreign_text.find( {name: 'Máximo'}).explain()
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.foreign_text',
indexFilterSet: false,
parsedQuery: { name: { '$eq': 'Máximo' } },
collation:
{ locale: 'pt',
caseLevel: false,
caseFirst: 'off',
strength: 3,
numericOrdering: false,
alternate: 'non-ignorable',
maxVariable: 'punct',
normalization: false,
backwards: false,
version: '57.1' },
winningPlan:
{ stage: 'COLLSCAN',
filter: { name: { '$eq': 'Máximo' } },
direction: 'forward' },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1635166592, i: 4 }),
signature:
{ hash: Binary(Buffer.from("228dfb0f05321548ca6754b2215a5cf3a736a357", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1635166592, i: 4 }) }
# it: イタリア語 の参照順序を指定して検索、explain()してみる
# 検索時のcollation指定が有効になっている
db.foreign_text.find( {name: 'Máximo'}).collation({locale: 'it'}).explain()
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.foreign_text',
indexFilterSet: false,
parsedQuery: { name: { '$eq': 'Máximo' } },
collation:
{ locale: 'it',
caseLevel: false,
caseFirst: 'off',
strength: 3,
numericOrdering: false,
alternate: 'non-ignorable',
maxVariable: 'punct',
normalization: false,
backwards: false,
version: '57.1' },
winningPlan:
{ stage: 'COLLSCAN',
filter: { name: { '$eq': 'Máximo' } },
direction: 'forward' },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1635166060, i: 15 }),
signature:
{ hash: Binary(Buffer.from("c268f6eed3861a66edb206c1372daa8096b5a400", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1635166060, i: 15 }) }
Compass で見ると、こんな感じ。
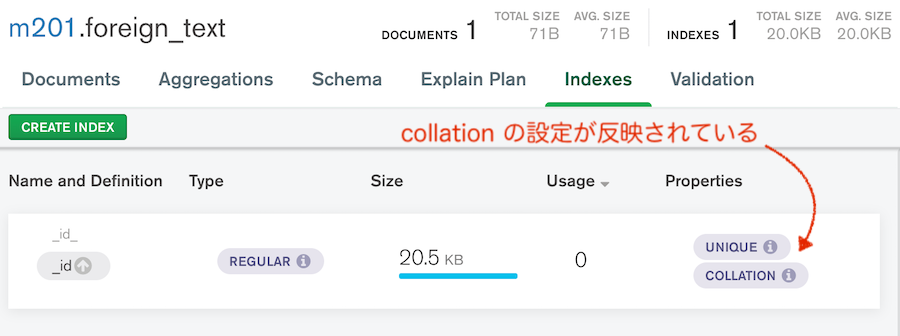
Check: Collations
- Collations allow the creation of case insensitive indexes
- Collations は、インケースセンシティブ(大文字小文字を区別しない)インデックスが利用できる
- We can define specific collations in an index
- コレクションでの指定とは別に、インデックスにCollationを設定できる
Wildcard Index Type: Part 1 (動画)
- MongoDBのドキュメントはネストしたり、キーに対して単一の値であったり配列やオブジェクトの値も取りうる
- ドキュメントの構造が変わるたびにインデックスを作成すると、たいへんなメンテナンスコストがかかる
- こういう場合、ワイルドカードインデックスが利用できる
- Ref. https://docs.mongodb.com/manual/core/index-wildcard/
- MongoDB 4.2 から利用できる
MongoDB supports creating indexes on a field or set of fields to support queries. Since MongoDB supports dynamic schemas, applications can query against fields whose names cannot be known in advance or are arbitrary.
MongoDB はダイナミックスキーマ を許容するデーターベースなので、アプリケーション側からは、今はまだ存在しないけれど将来にフィールドが追加されたような場合、その追加されたフィールドを明示して検索を行うといったことが難しい。このため、MongoDBではワイルドカードインデックスというものが利用できる。
# こんなデータ構造をもつコレクションが登録された場合
# ネストされたそれぞれのキーに対応するインデックスを都度作るのは大変
{ "userMetadata" : { "likes" : [ "dogs", "cats" ] } }
{ "userMetadata" : { "dislikes" : "pickles" } }
{ "userMetadata" : { "age" : 45 } }
{ "userMetadata" : "inactive" }
# ワイルドカードインデックスという形で、こんな風に指定できる
db.userData.createIndex( { "userMetadata.$**" : 1 } )
# こうすることで、以下のそれぞれのクエリにインデックスを利用できる
db.userData.find({ "userMetadata.likes" : "dogs" })
db.userData.find({ "userMetadata.dislikes" : "pickles" })
db.userData.find({ "userMetadata.age" : { $gt : 30 } })
db.userData.find({ "userMetadata" : "inactive" })
MongoDB Atlas のサンプルデータベースを使って確認。
use sample_weatherdata
show collections
data
# 一件データを確認してみる
# たくさんフィールドがあり、ネストもしている
db.data.findOne()
{ _id: ObjectId("5553a998e4b02cf7151190c4"),
st: 'x+47600-000700',
ts: 1984-03-05T15:00:00.000Z,
position: { type: 'Point', coordinates: [ -0.7, 47.6 ] },
elevation: 9999,
callLetters: 'FNUI',
qualityControlProcess: 'V020',
dataSource: '4',
type: 'FM-13',
airTemperature: { value: 999.9, quality: '9' },
dewPoint: { value: 999.9, quality: '9' },
pressure: { value: 1032.6, quality: '1' },
wind:
{ direction: { angle: 60, quality: '1' },
type: 'N',
speed: { rate: 7.2, quality: '1' } },
visibility:
{ distance: { value: 50000, quality: '1' },
variability: { value: 'N', quality: '9' } },
skyCondition:
{ ceilingHeight: { value: 22000, quality: '1', determination: 'C' },
cavok: 'N' },
sections: [ 'AG1', 'AY1', 'GF1', 'MD1', 'MW1', 'SA1', 'UA1' ],
precipitationEstimatedObservation: { discrepancy: '2', estimatedWaterDepth: 0 },
pastWeatherObservationManual:
[ { atmosphericCondition: { value: '0', quality: '1' },
period: { value: 3, quality: '1' } } ],
skyConditionObservation:
{ totalCoverage: { value: '01', opaque: '99', quality: '1' },
lowestCloudCoverage: { value: '99', quality: '9' },
lowCloudGenus: { value: '00', quality: '1' },
lowestCloudBaseHeight: { value: 450, quality: '1' },
midCloudGenus: { value: '04', quality: '1' },
highCloudGenus: { value: '00', quality: '1' } },
atmosphericPressureChange:
{ tendency: { code: '4', quality: '1' },
quantity3Hours: { value: 0, quality: '1' },
quantity24Hours: { value: 99.9, quality: '9' } },
presentWeatherObservationManual: [ { condition: '01', quality: '1' } ],
seaSurfaceTemperature: { value: 12.7, quality: '9' },
waveMeasurement:
{ method: 'M',
waves: { period: 2, height: 1.5, quality: '9' },
seaState: { code: '99', quality: '9' } } }
# ワイルドカードインデックスを作成してみる
db.data.createIndex( { "$**" : 1 } )
'$**_1'
# 検索してみる
db.data.find({ "waveMeasurement.waves.height": 0.5 }).count()
1916
# explain() してみる
# stage: 'IXSCAN' になっている!
db.data.find({ "waveMeasurement.waves.height": 0.5 }).explain()
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'sample_weatherdata.data',
indexFilterSet: false,
parsedQuery: { 'waveMeasurement.waves.height': { '$eq': 0.5 } },
winningPlan:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { '$_path': 1, 'waveMeasurement.waves.height': 1 },
indexName: '$**_1',
isMultiKey: false,
multiKeyPaths: { '$_path': [], 'waveMeasurement.waves.height': [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ '$_path': [ '["waveMeasurement.waves.height", "waveMeasurement.waves.height"]' ],
'waveMeasurement.waves.height': [ '[0.5, 0.5]' ] } } },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1635169344, i: 65 }),
signature:
{ hash: Binary(Buffer.from("e6d0c91a9aaa1d28914bb7e71d284608f1d0026a", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1635169344, i: 65 }) }
MongoDB Atlas で確認してみると....
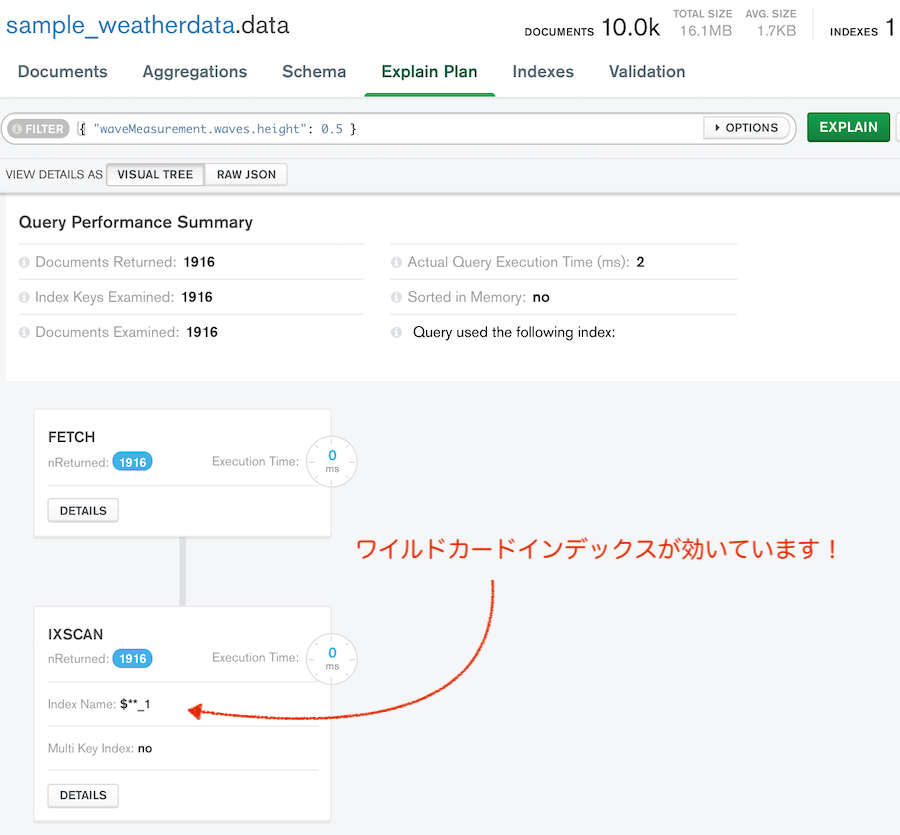
ただし、ワイルドカードインデックスには制約もあるようなので注意。
- Ref. https://docs.mongodb.com/manual/reference/index-wildcard-restrictions/#std-label-wildcard-index-restrictions
- つぎの動画で解説があるかもしれないですが、以下があつかえません
- Compound
- TTL
- 一定の期間が過ぎたら自動的に削除されるようなインデックスらしい!
- Text
- 2d (Geospatial)
- 2dsphere (Geospatial)
- Hashed
- Unique
- あとは、シャーディングに対応していない
Wildcard Index Type: Part 2 (動画)
ワイルドカードインデックスは、指定した起点からフィールドと値のペアに対してインデックスをどんどん作成する。
このため、ツリー構造、ネストした構造のドキュメントが深い場合は、インデックスが多量に作成される分、更新やメンテナンスのコストがかかる。
必要なフィールドのみ、必要なフィールドのツリーのみにワイルドカードインデックスを指定することもできる。
# フィールドを指定した例 (fieldAから先のツリーに対してインデックスを設定)
db.collection.createIndex( { "fieldA.$**" : 1 } )
また、全てのフィールドを対象にしたワイルドカードインデックスを設定する際に、一部のフィールドだけ除外するといった設定も可能。
# $** なので、全フィールドが対象
# ただし、除外するフィールドは 0 で明示できる
db.collection.createIndex(
{ "$**" : 1 },
{ "wildcardProjection" :
{ "fieldA" : 0, "fieldB.fieldC" : 0 }
}
)
ワイルドカードインデックスまとめ
- フィールドの追加更新が予測可能でない場合に有効
- 従来からのインデックスの代わりになるわけではない
-
$**で全てのフィールドを対象にできる - 全てのフィールドではなく、ドット記法を用いて、特定のフィールドのサブセットに対してのワイルドカードインデックスも指定できる
Check: Wildcard Index Type: Part 2
- include a set of fields in the Wildcard Index.
- exclude a set of fields from the Wildcard Index.
Wildcard Index Use Cases (動画)
どんなユースケースの時にワイルドカードインデックスが有効?
- 今後のフィールドの追加や変更の予測がむずかしい場合
- Atttibute pattern の構成の時
Attribute Pattern:
Attribute pattern is well suited for below use-cases.
If we have lots of similar fields and want the ability to search across many fields
Some fields are present only in small set of documents and would like the ability to query those documents.
たくさんの似通ったフィールドがあり、任意に複数のフィールドに対して検索を行いたい場合
こんなデータの場合に有効。
{
name: "product1",
price: "90.00",
releases: [
{
location: "USA",
date: ISODate("2019-05-20T01:00:00+01:00")
},
{
location: "Canada",
date: ISODate("2019-05-28T01:00:00+01:00")
},
{
location: "China",
date: ISODate("2019-08-20T01:00:00+01:00")
},
{
location: "UK",
date: ISODate("2019-05-20T01:00:00+01:00")
},
location: "India",
date: ISODate("2019-08-20T01:00:00+01:00")
},
…
],
…
}
Check: Wildcard Index Use Cases
- An application consistently queries against document fields that use the Attribute Pattern.
- The query pattern on documents of a collection is unpredictable.
Discussion