ひとりMongoDB University / M201 MongoDB Performance(3)
この記録は、アドベントカレンダー形式ではじめた、MongoDB Universityの学習コースの記録の続きになります!
ただいまのコース
- M201 MongoDB Performance
このコースでは、開発者 / オペレーション担当者双方向けの中級レベルの内容とのことです。
前回の記事は、ひとりMongoDB University / M201 MongoDB Performance(2) でした。
Chapter 2: MongoDB Indexes
When you can sort with Indexes(動画)
- 作成したインデックスはソートの際にも使われる
- ただし、ソートのキーの指定方法によっても、使われない場合がある
# まず対象のコレクションに設定されているインデックスを確認
db.people.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{ v: 2, key: { ssn: 1 }, name: 'ssn_1' },
{
v: 2,
key: { job: 1, employer: 1, last_name: 1, first_name: 1 },
name: 'job_employer_last_name_first_name',
background: false
}
]
# 全件抽出だけれど、インデックスのフィールドをプレフィックスに従ってカバーしている場合
# stage: 'IXSCAN' となります
exp.find({}).sort({ job: 1, employer: 1, last_name : 1, first_name : 1 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.people',
indexFilterSet: false,
parsedQuery: {},
winningPlan:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { job: 1, employer: 1, last_name: 1, first_name: 1 },
indexName: 'job_employer_last_name_first_name',
isMultiKey: false,
multiKeyPaths: { job: [], employer: [], last_name: [], first_name: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ job: [ '[MinKey, MaxKey]' ],
employer: [ '[MinKey, MaxKey]' ],
last_name: [ '[MinKey, MaxKey]' ],
first_name: [ '[MinKey, MaxKey]' ] } } },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 50474,
executionTimeMillis: 89,
totalKeysExamined: 50474,
totalDocsExamined: 50474,
executionStages:
{ stage: 'FETCH',
nReturned: 50474,
executionTimeMillisEstimate: 31,
works: 50475,
advanced: 50474,
needTime: 0,
needYield: 0,
saveState: 50,
restoreState: 50,
isEOF: 1,
docsExamined: 50474,
alreadyHasObj: 0,
inputStage:
{ stage: 'IXSCAN',
nReturned: 50474,
executionTimeMillisEstimate: 14,
works: 50475,
advanced: 50474,
needTime: 0,
needYield: 0,
saveState: 50,
restoreState: 50,
isEOF: 1,
keyPattern: { job: 1, employer: 1, last_name: 1, first_name: 1 },
indexName: 'job_employer_last_name_first_name',
isMultiKey: false,
multiKeyPaths: { job: [], employer: [], last_name: [], first_name: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ job: [ '[MinKey, MaxKey]' ],
employer: [ '[MinKey, MaxKey]' ],
last_name: [ '[MinKey, MaxKey]' ],
first_name: [ '[MinKey, MaxKey]' ] },
keysExamined: 50474,
seeks: 1,
dupsTested: 0,
dupsDropped: 0 } } },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634823326, i: 11 }),
signature:
{ hash: Binary(Buffer.from("c594527e790ef94308c80efddb54cc8b6e76bb22", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634823326, i: 11 }) }
# ソートの場合は、インデックスのフィールドの順番に沿わないと、インデックスは使わずソートが発生する
exp.find({}).sort({ employer: 1, job: 1 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.people',
indexFilterSet: false,
parsedQuery: {},
winningPlan:
{ stage: 'SORT',
sortPattern: { employer: 1, job: 1 },
memLimit: 33554432,
type: 'simple',
inputStage: { stage: 'COLLSCAN', direction: 'forward' } },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 50474,
executionTimeMillis: 270,
totalKeysExamined: 0,
totalDocsExamined: 50474,
executionStages:
{ stage: 'SORT',
nReturned: 50474,
executionTimeMillisEstimate: 211,
works: 100951,
advanced: 50474,
needTime: 50476,
needYield: 0,
saveState: 101,
restoreState: 101,
isEOF: 1,
sortPattern: { employer: 1, job: 1 },
memLimit: 33554432,
type: 'simple',
totalDataSizeSorted: 20381663,
usedDisk: false,
inputStage:
{ stage: 'COLLSCAN',
nReturned: 50474,
executionTimeMillisEstimate: 4,
works: 50476,
advanced: 50474,
needTime: 1,
needYield: 0,
saveState: 101,
restoreState: 101,
isEOF: 1,
direction: 'forward',
docsExamined: 50474 } } },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634823527, i: 3 }),
signature:
{ hash: Binary(Buffer.from("eb5e520d9b7b714960e568e75b68ebc723706c3b", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634823527, i: 3 }) }
ソートの条件指定に設定する際には、順番に気を付けること。
また、インデックス作成時には、オーダーを昇順にするか降順にするかの指定がある。
find() もしくは sort() の条件指定で、フィールドの順番とともに、オーダーの指定でもインデックスが効果的に使われない場合があるので注意。
db.coll.createIndex({ a: 1, b: -1, c: 1 })
# インデックスの通りにソートのオーダーを指定した場合は、インデックス利用
db.coll.find().sort({ a: 1, b: -1, c: 1 })
# インデックスの通りにソートのオーダーを反転させて指定した場合は、インデックス利用
db.coll.find().sort({ a: -1, b: 1, c: -1 })
# この条件ではインデックスを使いません
exp.find().sort({job: -1, employer: 1})
Check: When you can sort with Indexes
- インデックスのプリフィクスに従って、検索の際にフィールドの順番に気をつけてフィルタを指定するとインデックスが利用される
- ソートの場合も、インデックスのプリフィクスに従って、フィールドの順番に気をつけてソートの受容権を指定するとインデックスが利用される
- インデックス作成時に、それぞれのフィールドにオーダーの降順昇順を指定するので、検索やソート指定のときに、このオーダー順にしたがうか、すべて反転させるとインデックスが使われる
Multikey Indexes (動画)
マルチキーインデックスについて。
複合インデックスと何が違うの?というと、MongoDBのデータは、テーブルではなくてドキュメントという形で、キー(フィールド)に対する値がネストしたオブジェクトだったり、配列だったりする。
キーに対する値が配列である場合も、インデックスを作成することができる。
- マルチキーインデックスに対応する配列のデータが多い場合は、インデックス作成や更新にコストがかかるので注意
- マルチキーインデックスは、カバードクエリには対応していない点も注意
# データベースの切り替え
use m201
# コレクション(テーブルに相当)の一覧表示
show collections
people
restaurants
# コレクションが存在しなくても、db.コレクション名.insert() でデータ投入の際にコレクションも作成される
db.products.insert({
productName: "MongoDB Short Sleeve T-Shirt",
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: { size: "L", color: "green", quantity: 100 }
});
# ワーニングが出た。新しいメソッドを使ってね、ということですね。
'DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.'
{ acknowledged: true,
insertedIds: { '0': ObjectId("6172c7c648565e4352a45469") } }
# コレクションが追加されました
show collections
people
products
restaurants
# データの確認
db.products.find().pretty()
{ _id: ObjectId("6172c7c648565e4352a45469"),
productName: 'MongoDB Short Sleeve T-Shirt',
categories: [ 'T-Shirts', 'Clothing', 'Apparel' ],
stock: { size: 'L', color: 'green', quantity: 100 } }
# まだこの段階では、stock.quantity に対応するデータは integer で単一データ
# この状態でインデックスを作成
db.products.createIndex({ "stock.quantity": 1})
# この状態でexplain()をしてみます
var exp = db.products.explain()
exp.find({ "stock.quantity": 100 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.products',
indexFilterSet: false,
parsedQuery: { 'stock.quantity': { '$eq': 100 } },
queryHash: '0AA20206',
planCacheKey: '9ED365D5',
winningPlan:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { 'stock.quantity': 1 },
indexName: 'stock.quantity_1',
isMultiKey: false,
multiKeyPaths: { 'stock.quantity': [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { 'stock.quantity': [ '[100, 100]' ] } } },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634912602, i: 16 }),
signature:
{ hash: Binary(Buffer.from("2d4af698154314701fe7e91268986ac6446c36e9", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634912602, i: 16 }) }
# インデックススキャンですが、isMultiKey: false (マルチキー: false) と出ました
まだ対象のキーに対する値が配列でない状態。
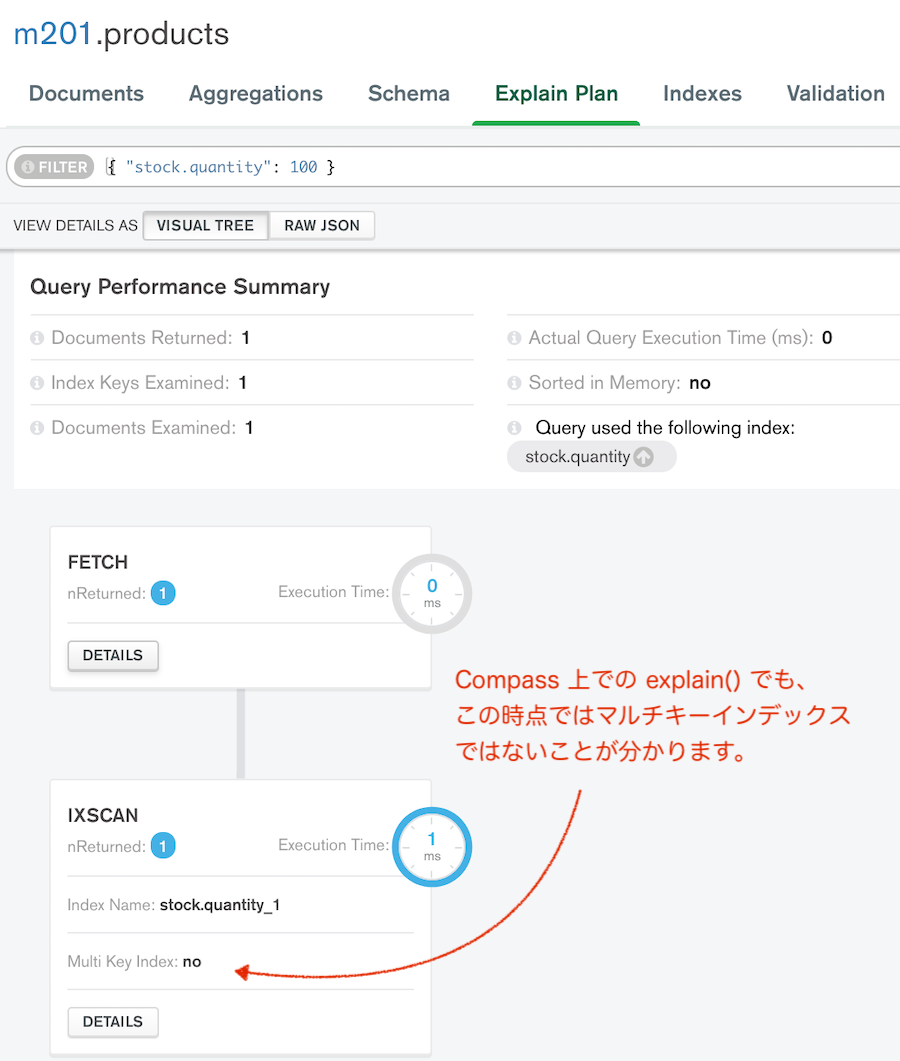
# 今度はインデックスの対象としているキーに対して、配列での値を設定します!
# 単純な数値型と配列型が混在するってなんかすごい.....
db.products.insert({
productName: "MongoDB Long Sleeve T-Shirt",
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
});
{ acknowledged: true,
insertedIds: { '0': ObjectId("6172cafa48565e4352a4546a") } }
# stock フィールドに対応する値が、単一のオブジェクトのものと、配列のものとが混在!
db.products.find().pretty()
{ _id: ObjectId("6172c7c648565e4352a45469"),
productName: 'MongoDB Short Sleeve T-Shirt',
categories: [ 'T-Shirts', 'Clothing', 'Apparel' ],
stock: { size: 'L', color: 'green', quantity: 100 } }
{ _id: ObjectId("6172cafa48565e4352a4546a"),
productName: 'MongoDB Long Sleeve T-Shirt',
categories: [ 'T-Shirts', 'Clothing', 'Apparel' ],
stock:
[ { size: 'S', color: 'red', quantity: 25 },
{ size: 'S', color: 'blue', quantity: 10 },
{ size: 'M', color: 'blue', quantity: 50 } ] }
# この状態でスキャンします
exp.find({ "stock.quantity": 100 })
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.products',
indexFilterSet: false,
parsedQuery: { 'stock.quantity': { '$eq': 100 } },
queryHash: '0AA20206',
planCacheKey: '9ED365D5',
winningPlan:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { 'stock.quantity': 1 },
indexName: 'stock.quantity_1',
isMultiKey: true,
multiKeyPaths: { 'stock.quantity': [ 'stock' ] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { 'stock.quantity': [ '[100, 100]' ] } } },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634913128, i: 10 }),
signature:
{ hash: Binary(Buffer.from("6edc2c9d02ea54a8ea3465df3bdf5a73099280eb", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634913128, i: 10 }) }
# さっきと同じ条件での find ですが、インデックスが変わっています!
# isMultiKey: true になりました
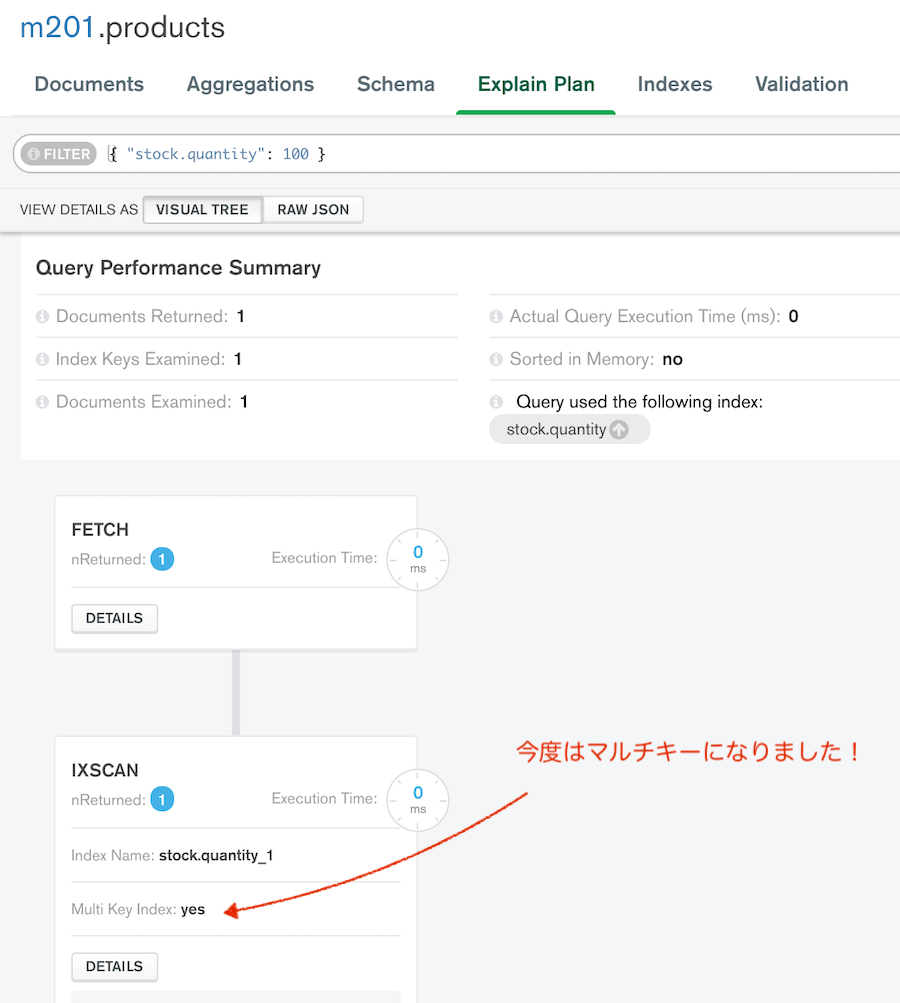
- マルチキーインデックスになりうるフィールドを2つ以上指定しての複合インデックスは作成できない
# categories は配列で、stock.quantity も配列の状態
# この組み合わせでインデックスを作成しようとすると、エラー!
db.products.createIndex({ categories: 1, "stock.quantity": 1 })
MongoServerError: Index build failed: 40b29528-eade-416f-b58d-3169dc317d93: Collection m201.products ( 4283aade-7d0b-42ec-b8a0-07a8cb8be5f0 ) :: caused by :: cannot index parallel arrays [stock] [categories]
# 配列型式のフィールドは1つだけの場合は、複合インデックスの作成 OK
db.products.createIndex({ productName: 1, "stock.quantity": 1 })
'productName_1_stock.quantity_1'
# でも、productName はあとから配列のデータを入れる様に変更できる!
db.products.insert({
productName: [
"MongoDB Short Sleeve T-Shirt",
"MongoDB Short Sleeve Shirt"
],
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: { size: "L", color: "green", quantity: 100 }
});
{ acknowledged: true,
insertedIds: { '0': ObjectId("6172cdf148565e4352a4546b") } }
# 複合インデックスを指定したフィールドに対して、どちらも配列としてデータを入れようとするとエラー
db.products.insert({
productName: [
"MongoDB Short Sleeve T-Shirt",
"MongoDB Short Sleeve Shirt"
],
categories: ["T-Shirts", "Clothing", "Apparel"],
stock: [
{ size: "S", color: "red", quantity: 25 },
{ size: "S", color: "blue", quantity: 10 },
{ size: "M", color: "blue", quantity: 50 }
]
});
Check: Multikey Indexes
この条件で複合インデックスを作成した場合。
{ name: 1, emails: 1 }
以下の形でのデータを登録したら、いくつインデックスができますか?
{
"name": "Beatrice McBride",
"age": 26,
"emails": [
"puovvid@wamaw.kp",
"todujufo@zoehed.mh",
"fakmir@cebfirvot.pm"
]
}
- nameは1つだけど、email には 3 つあるので....
- Beatrice McBride - puovvid@wamaw.kp
- Beatrice McBride - todujufo@zoehed.mh
- Beatrice McBride - fakmir@cebfirvot.pm
- 結果的に3つできます!
Partial Indexes (動画)
部分インデックスについて。
複合インデックスやマルチキーインデックスでは、コレクション中の前ドキュメントに対して設定すると、インデックス自体のデータ量や更新のコストもかかる。
複合インデックスではあるが、特定の条件のものだけにインデックスが必要な場合は、パーシャルインデックスを使うと良い。
# restaurants コレクションの例で進めます
var exp = db.restaurants.explain()
# 複数のフォールドに対しての検索について、explain() 実施
# この段階では、インデックスが設定されていないので、COLLSCAN
exp.find({'address.city': 'New York', cuisine: 'Sichuan'})
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.restaurants',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { 'address.city': { '$eq': 'New York' } },
{ cuisine: { '$eq': 'Sichuan' } } ] },
queryHash: '082139C9',
planCacheKey: '082139C9',
winningPlan:
{ stage: 'COLLSCAN',
filter:
{ '$and':
[ { 'address.city': { '$eq': 'New York' } },
{ cuisine: { '$eq': 'Sichuan' } } ] },
direction: 'forward' },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634996085, i: 16 }),
signature:
{ hash: Binary(Buffer.from("1ce7581bea4951256988ffaacd07cca505a5a75c", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634996085, i: 16 }) }
上記の例では、まだ複合インデックスが設定されていない。
住所、料理のカテゴリ(フレンチとか、日本食とか)についての複合インデックスを設定したいけれど、星3つ以上のものだけインデックスがあれえば良い、といったパターンでは、パーシャルインデックスが良い。
- partialFilterExpression を使う
- Ref. https://docs.mongodb.com/manual/core/index-partial/
Partial indexes only index the documents in a collection that meet a specified filter expression. By indexing a subset of the documents in a collection, partial indexes have lower storage requirements and reduced performance costs for index creation and maintenance.
パーシャルインデックスは、コレクションの中で特定のフィルタに一致するものだけを対象としたインデックスです。インデックスのサイズを抑える、メンテナンスコストを抑えることができます。
- 利用できるオペレータにはいくつかある
$exists: true$gt, $gte, $lt, $lte$type$and
以下、設定例。
# partialFilterExpression で設定。ここでは、stars のキーに対して値が3.5 以上のものだけを対象にインデックスを設定
db.restaurants.createIndex(
{ "address.city": 1, cuisine: 1 },
{ partialFilterExpression: { 'stars': { $gte: 3.5 } } }
)
# 部分インデックスで指定した対象になるデータをチェック(starsが3.5以上)
db.restaurants.find({'address.city': 'New York', 'cuisine': 'Sichuan'})
{ _id: ObjectId("61740f5048565e4352a4546d"),
name: 'Han Dynasty',
cuisine: 'Sichuan',
stars: 4.4,
address:
{ street: '90 3rd Ave',
city: 'New York',
state: 'NY',
zipcode: '10003' } }
# 部分インデックスの対象になっているデータについて explain() してみる
# でも、複合インデックスのフィールドの条件、順番としては合っているが、COLLSCAN になってしまっている。
db.restaurants.find({'address.city': 'New York', 'cuisine': 'Sichuan'}).explain()
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.restaurants',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { 'address.city': { '$eq': 'New York' } },
{ cuisine: { '$eq': 'Sichuan' } } ] },
winningPlan:
{ stage: 'COLLSCAN',
filter:
{ '$and':
[ { 'address.city': { '$eq': 'New York' } },
{ cuisine: { '$eq': 'Sichuan' } } ] },
direction: 'forward' },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634996712, i: 10 }),
signature:
{ hash: Binary(Buffer.from("3b67c99a9f10a190d9a412c35567b155095f7fae", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634996712, i: 10 }) }
To use the partial index, a query must contain the filter expression (or a modified filter expression that specifies a subset of the filter expression) as part of its query condition.
部分インデックスが使われるようにするには、フィルター設定した条件も含まないとだめ!とのこと。
# フィルターの条件がクエリとしてカバーされるように設定してみる
# スキャンは、IXSCAN となりました!
exp.find({'address.city': 'New York', cuisine: 'Sichuan', stars: { $gt: 4.0 }})
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.restaurants',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { 'address.city': { '$eq': 'New York' } },
{ cuisine: { '$eq': 'Sichuan' } },
{ stars: { '$gt': 4 } } ] },
queryHash: '1862D731',
planCacheKey: 'CC222B8B',
winningPlan:
{ stage: 'FETCH',
filter: { stars: { '$gt': 4 } },
inputStage:
{ stage: 'IXSCAN',
keyPattern: { 'address.city': 1, cuisine: 1 },
indexName: 'address.city_1_cuisine_1',
isMultiKey: false,
multiKeyPaths: { 'address.city': [], cuisine: [] },
isUnique: false,
isSparse: false,
isPartial: true,
indexVersion: 2,
direction: 'forward',
indexBounds:
{ 'address.city': [ '["New York", "New York"]' ],
cuisine: [ '["Sichuan", "Sichuan"]' ] } } },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-01.t9q9n.mongodb.net',
port: 27017,
version: '4.4.10',
gitVersion: '58971da1ef93435a9f62bf4708a81713def6e88c' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634997231, i: 16 }),
signature:
{ hash: Binary(Buffer.from("52ca0347241849f315c6daa775193d40b8b26f56", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634997231, i: 16 }) }
# データも確認してみます
db.restaurants.find({'address.city': 'New York', cuisine: 'Sichuan', stars: { $gt: 4.0 }})
{ _id: ObjectId("61740f5048565e4352a4546d"),
name: 'Han Dynasty',
cuisine: 'Sichuan',
stars: 4.4,
address:
{ street: '90 3rd Ave',
city: 'New York',
state: 'NY',
zipcode: '10003' } }
MongoDB Compassでも確認。

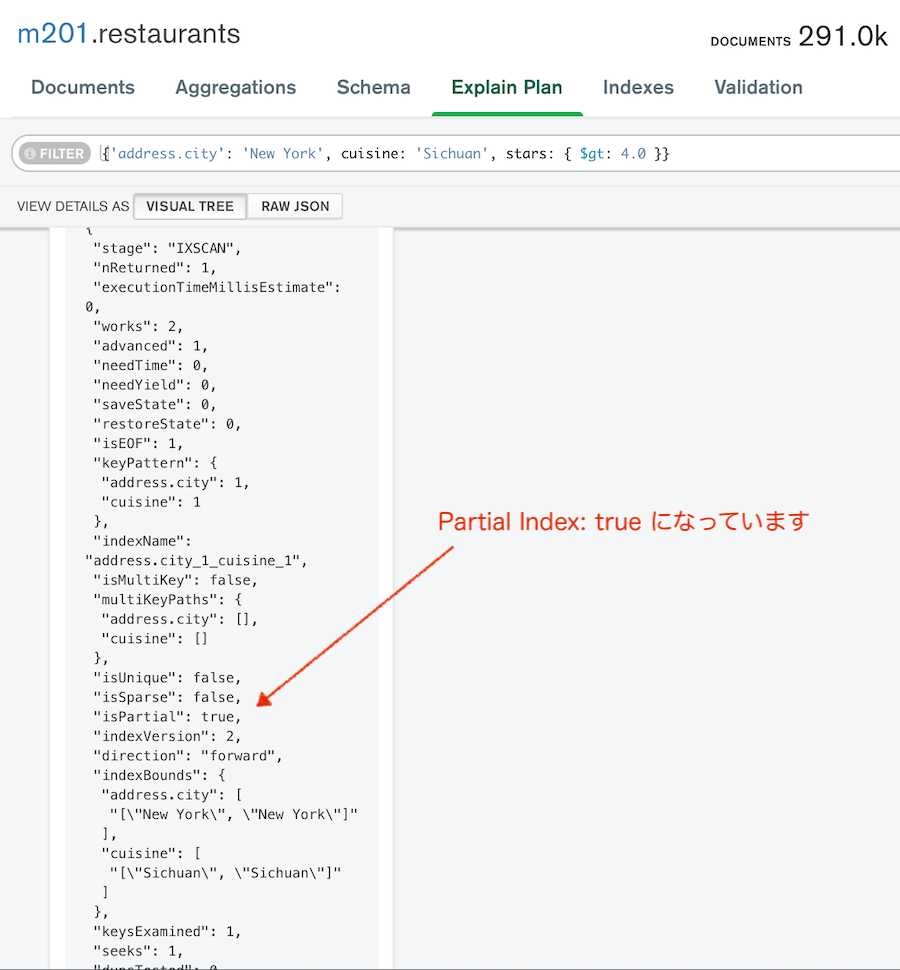
Check: Partial Indexes
- Partial indexes represent a superset of the functionality of sparse indexes.
- 部分インデックスは、間引いた (sparse) インデックスの上位集合です
- Partial indexes can be used to reduce the number of keys in an index.
- 部分インデックスは、インデックスのキーを減らすのにも利用されます
- Partial indexes support compound indexes.
- 部分インデックスは複合インデックスをサポートします
Discussion