🔥
ひとりMongoDB University / M201 MongoDB Performance(2)
この記録は、アドベントカレンダー形式ではじめた、MongoDB Universityの学習コースの記録の続きになります!
ただいまのコース
- M201 MongoDB Performance
このコースでは、開発者 / オペレーション担当者双方向けの中級レベルの内容とのことです。
前回の記事は、ひとりMongoDB University / M201 MongoDB Performance(1) でした。
Chapter 2: MongoDB Indexes
Understanding Explain (動画)
explain() の利用について。
通常は、クエリの最後に explain() を設定する。
db.people.find().explain()- ただし、クエリが複雑になったり、アグリゲーションがあったりする場合は、末尾に設定するのが煩雑なので、クエリの前に設定してもOK
# こんなふうに指定できます
exp = db.people.explain()
exp.find({ key: value })
- explain() にはレベルが指定できる
# デフォルトはqueryPlannerで、実行まではせずに評価のみ
exp = db.people.explain("queryPlanner")
# executionStats: 実際にwinningPlanを使っての結果を表示
exp = db.people.explain(" executionStats")
インデックスなしで explain() してみる。
exp = db.people.explain()
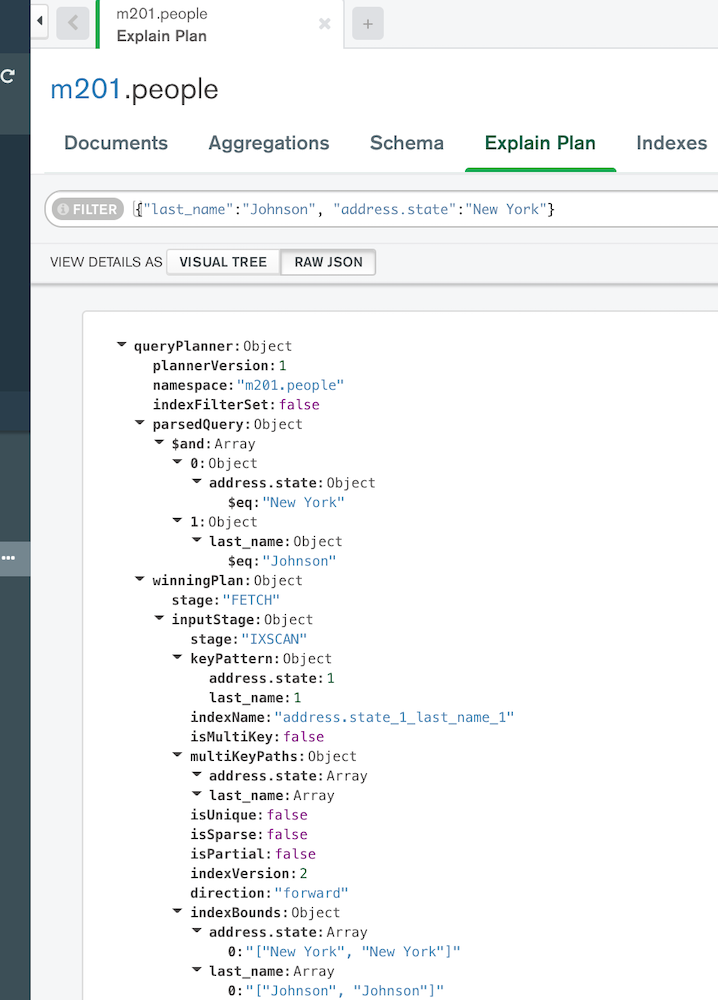
exp.find({"last_name":"Johnson", "address.state":"New York"})
# queryPlanner モードで結果が返る
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.people',
indexFilterSet: false,
parsedQuery:
{ '$and':
[ { 'address.state': { '$eq': 'New York' } },
{ last_name: { '$eq': 'Johnson' } } ] },
queryHash: '2F63C404',
planCacheKey: '2F63C404',
winningPlan:
{ stage: 'COLLSCAN',
filter:
{ '$and':
[ { 'address.state': { '$eq': 'New York' } },
{ last_name: { '$eq': 'Johnson' } } ] },
direction: 'forward' },
rejectedPlans: [] },
serverInfo:
{ host: 'cluster0-shard-00-02.t9q9n.mongodb.net',
port: 27017,
version: '4.4.9',
gitVersion: 'b4048e19814bfebac717cf5a880076aa69aba481' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634565661, i: 9 }),
signature:
{ hash: Binary(Buffer.from("5539f053e7adfcb9b4c4dbdfbb8f0548a59b2859", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634565661, i: 9 }) }
# winningPlan は、'COLLSCAN'
# ちょっとだけオブジェクトを操作してみる
# result という変数に結果を入れる
result = exp.find({"last_name":"Johnson", "address.state":"New York"})
# result.queryPlanner ではアクセスできない....
# result オブジェクトのkeyを確認してみると、どうやら '_explained' で取り出せそう
Object.keys(result)
[
'_currentIterationResult',
'_mapError',
'_mongo',
'_cursor',
'_tailable',
'_baseCursor',
'_verbosity',
'_explained'
]
# 取り出せました
result['_explained'].queryPlanner.winningPlan
{
stage: 'COLLSCAN',
filter: { '$and': [ [Object], [Object] ] },
direction: 'forward'
}
インデックスを設定してみる。
# インデックス作成
db.people.createIndex({last_name:1})
# もう一回 result という変数に結果を入れる
result = exp.find({"last_name":"Johnson", "address.state":"New York"})
# 結果が変わりました
result['_explained'].queryPlanner.winningPlan
{
stage: 'FETCH',
filter: { 'address.state': { '$eq': 'New York' } },
inputStage: {
stage: 'IXSCAN',
keyPattern: { last_name: 1 },
indexName: 'last_name_1',
isMultiKey: false,
multiKeyPaths: { last_name: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { last_name: [Array] }
}
}
クエリで指定したフィールドをカバーするインデックスを設定してみる。(複合インデックス的に)
db.people.createIndex({"address.state": 1, last_name: 1})
'address.state_1_last_name_1'
# もう一回 result という変数に結果を入れる
result = exp.find({"last_name":"Johnson", "address.state":"New York"})
# クエリの実行にあたり複数のプランがある場合、winningPlan と rejectedPlans が返される
# rejectedPlans は、配列になります
# 今回は、最初に作った単一のインデックスが rejecte
result['_explained'].queryPlanner.rejectedPlans
[
{
stage: 'FETCH',
filter: { 'address.state': [Object] },
inputStage: {
stage: 'IXSCAN',
keyPattern: [Object],
indexName: 'last_name_1',
isMultiKey: false,
multiKeyPaths: [Object],
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: [Object]
}
}
]
# winningPlan は、複合インデックスの方でした!
result['_explained'].queryPlanner.winningPlan
{
stage: 'FETCH',
inputStage: {
stage: 'IXSCAN',
keyPattern: { 'address.state': 1, last_name: 1 },
indexName: 'address.state_1_last_name_1',
isMultiKey: false,
multiKeyPaths: { 'address.state': [], last_name: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { 'address.state': [Array], last_name: [Array] }
}
}
Check: Understanding Explain
以下の結果が explain() から返ってきました。なにが言えますか?
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 23217,
"executionTimeMillis" : 91,
"totalKeysExamined" : 23217,
"totalDocsExamined" : 23217,
"executionStages" : {
"stage" : "SORT",
"nReturned" : 23217,
"executionTimeMillisEstimate" : 26,
"works" : 46437,
"advanced" : 23217,
"needTime" : 23219,
"needYield" : 0,
"saveState" : 363,
"restoreState" : 363,
"isEOF" : 1,
"sortPattern" : {
"stars" : 1
},
"memUsage" : 32522511,
"memLimit" : 33554432,
- 検索の結果の絞り込みがあまり聞いてない(インデックスの効果がイマイチ)
- ソートは全てメモリ上で実施されている
- ソートに利用したメモリのサイズと、メモリのリミットを鑑みると、ギリギリでもう少しで例外が発生したかもしれない
Understanding Explain for Sharded Clusters (動画)
シャーディングした時は、explain() の結果が変わってくる。
クラスタで起動:
- mongod ではなく mongos を使っての接続になる
- mongos から各シャードを管理するmongod に対してクエリを発行し、その結果をmongos がまとめる形になる
※ MongoDB Atlasの MongoDB Compass からはこの操作ができないので割愛。
sh.enableSharding("m201")
sh.shardCollection("m201.people", {_id: 1})
db.people.getShardDistribution()
db.people.find({"last_name":"Johnson", "address.state":"New York"}).explain("executionStats")
MongoDB Compass を使って explain() の結果がビジュアライズされる。
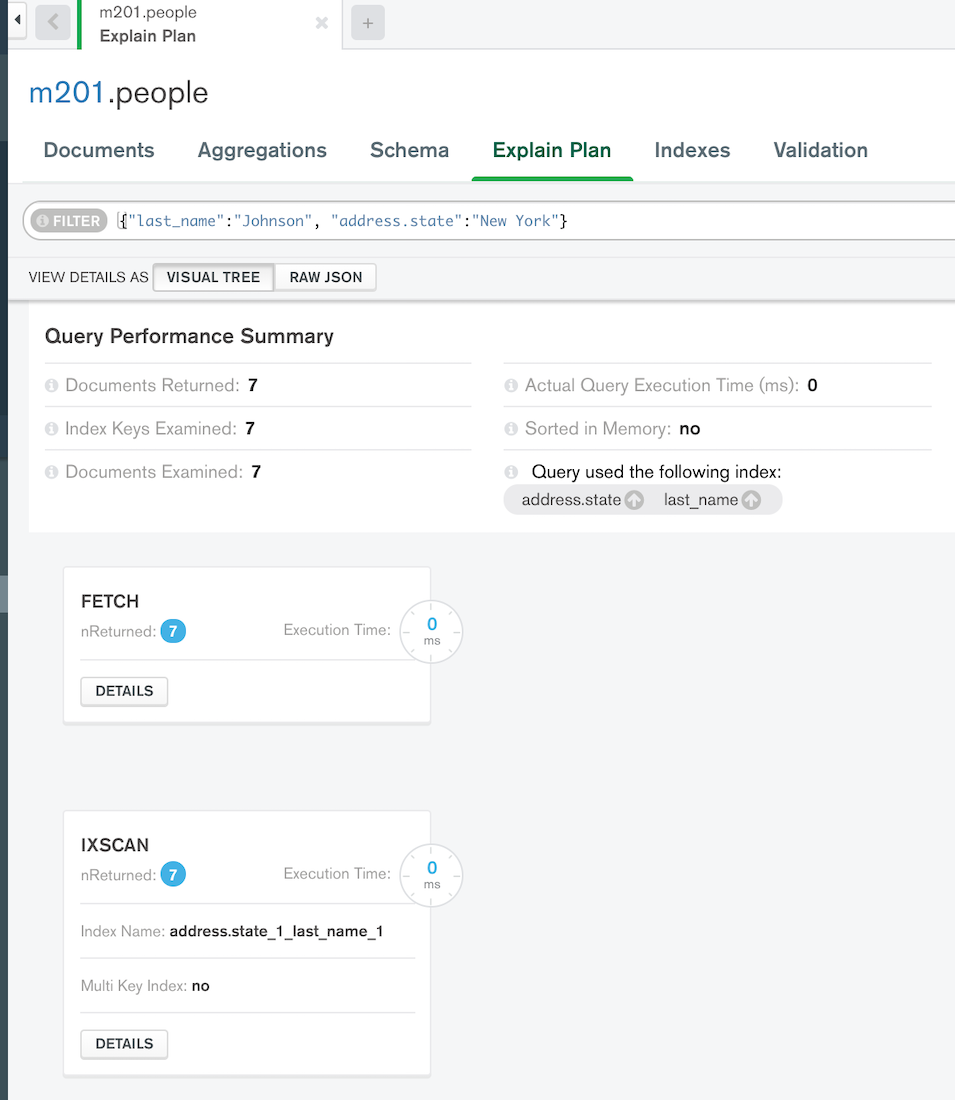
ここでのまとめ
- explain() では時間も出力される
- シャーディングした場合は、各クラスタでのexplain()の結果が合わせて出力される
- 複数のインデックス、複数の検索方法がある場合は、どれが採用されて、どれが不採用になったかも出力される
Check: Understanding Explain for Sharded Clusters
explain() で出力されるもの:
- プランにおいて選択されたインデックス
- ソートが発生した場合に、インデックスでのソートかメモリでのソートかの情報
- それぞれのステージにおける所要時間、抽出件数、フィルタされた件数などの詳細
Sorting with Indexes (動画)
- 抽出結果のソートは、インデックスでのソートと、メモリ上でのソートの2つがある
- メモリでのソートの場合、サイズが決まっていて、それを越すと例外が発生する(32メガ)
- インデックスを作成すると、基本はクエリに指定したインデックスのキーの順番を保って結果が返る
Check: Sorting with Indexes
- find() や aggregate() の時にインデックスのフィールドが指定されていなくても、sort() の条件にインデックスのフィールドが指定されていれば、インデックスソートを利用する
# 次のキーに対してインデックスがある場合
{ product_id: 1 }
# このパターンではインデックスをソートに利用
db.products.find({}).sort({ product_id: 1 })
db.products.find({}).sort({ product_id: -1 })
db.products.find({ product_id: '57d7a1' }).sort({ product_id: -1 })
db.products.find({ product_name: 'Soap' }).sort({ product_id: 1 })
Querying on Compound Indexes Part 1 (動画)
複合インデックスについて。
- インデックス自体は1次元
- フィールドが複数なので、1つめのフィールドの昇順降順、2つめのフィールドの昇順降順...といったオーダーになる
今回はインデックスの作成やexplain()の結果の確認は、MongoDB Compass を使って解説。
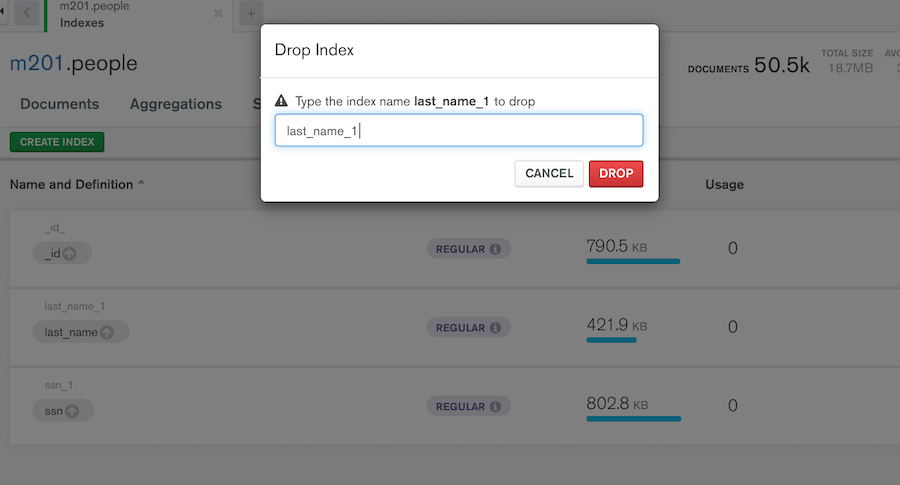
インデックスの削除
インデックスなしでの explain()
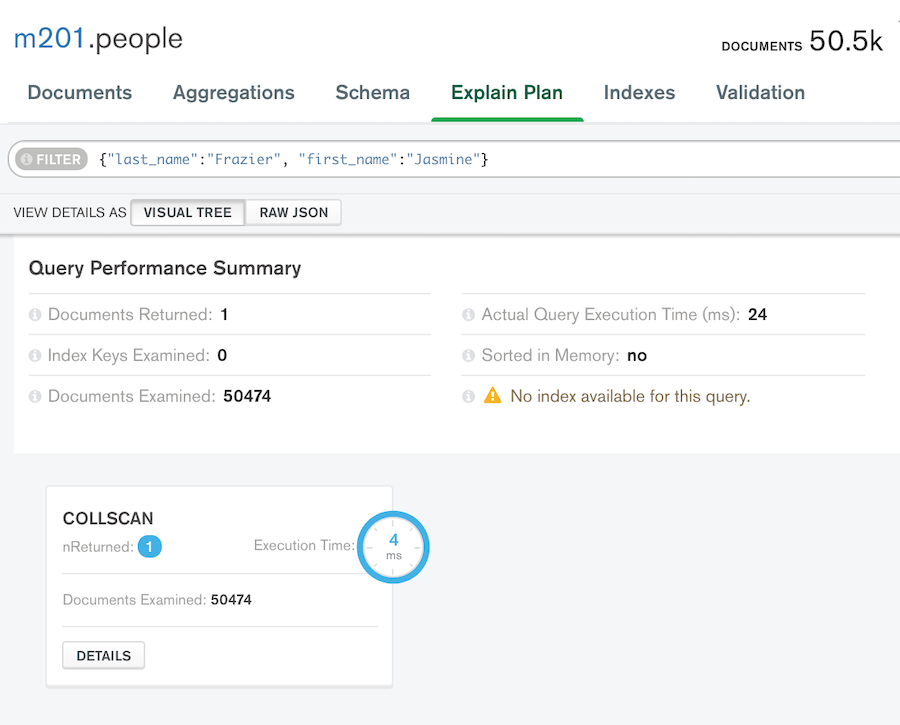
複合インデックスを作成
再度インデックス設定後にexplain()
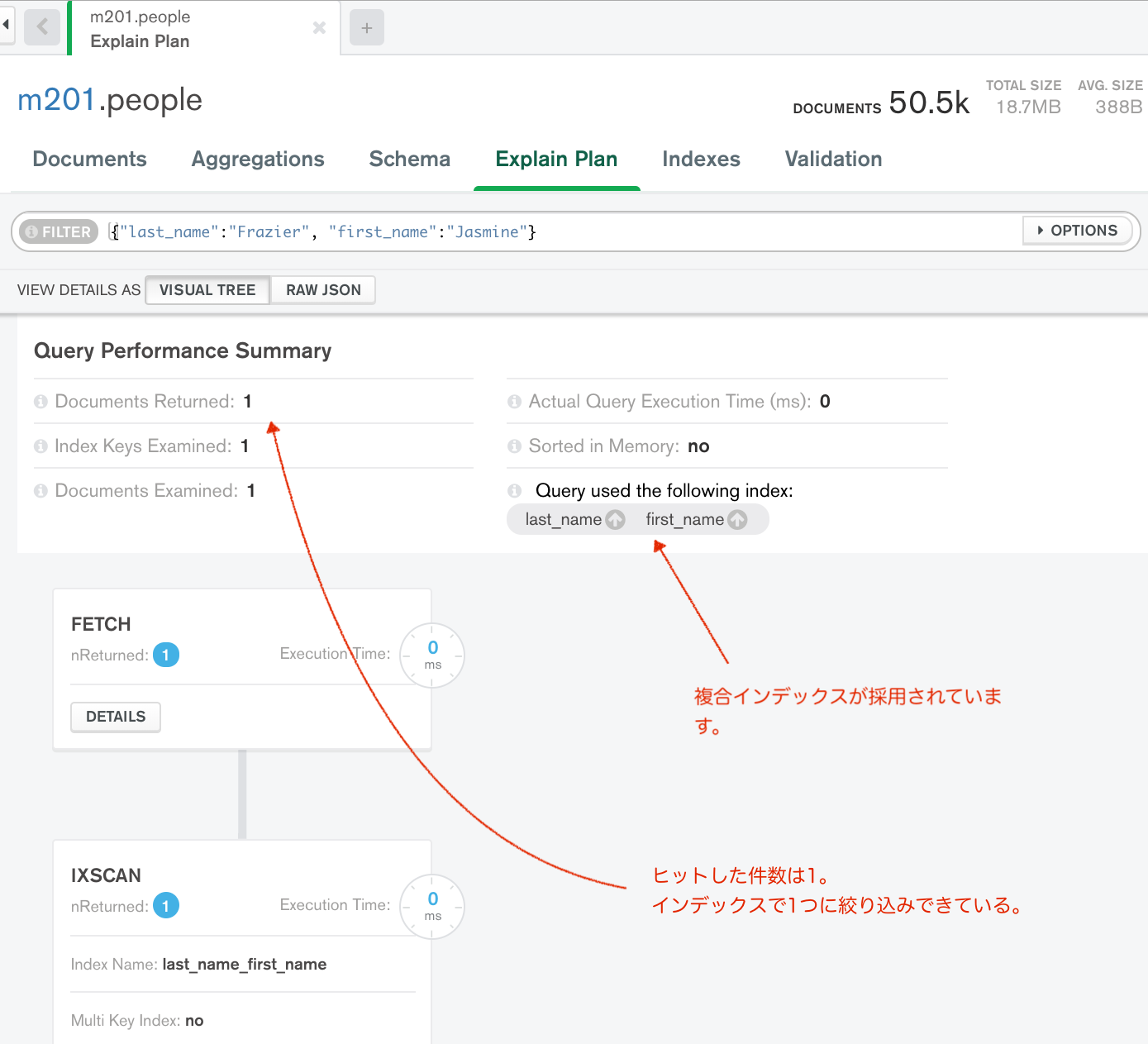
上記のように、Compass から実行計画の表示やインデックスの操作ができる。
Querying on Compound Indexes Part 2 (動画)
複合インデックスは、インデックスのフォールドに指定されたものについて、どのように利用されるか
?
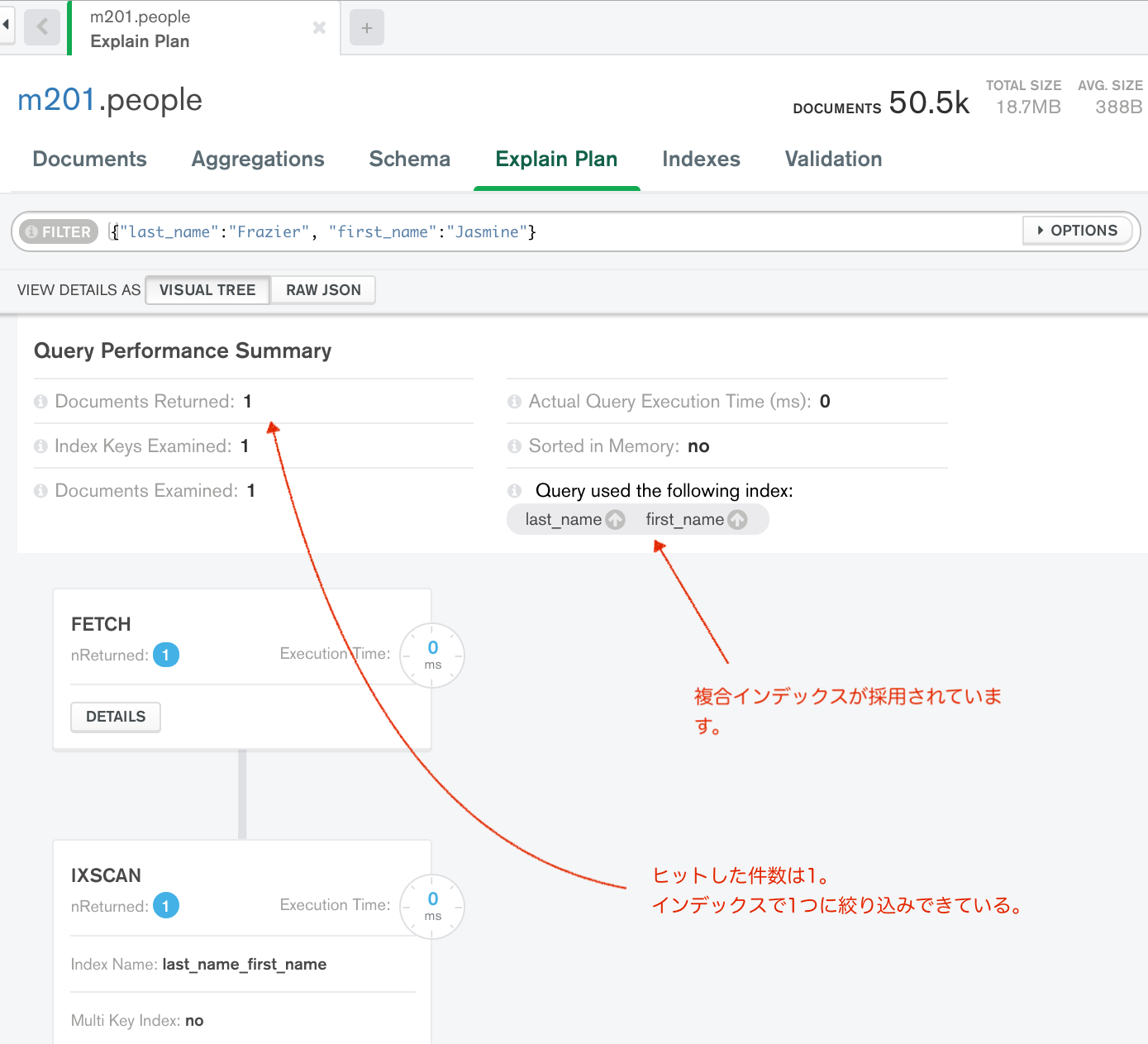
複合インデックスのフィールドをプレフィックスの順番通りにカバーした場合
複合インデックスに含まれるフィールドだけど順番が合ってない場合
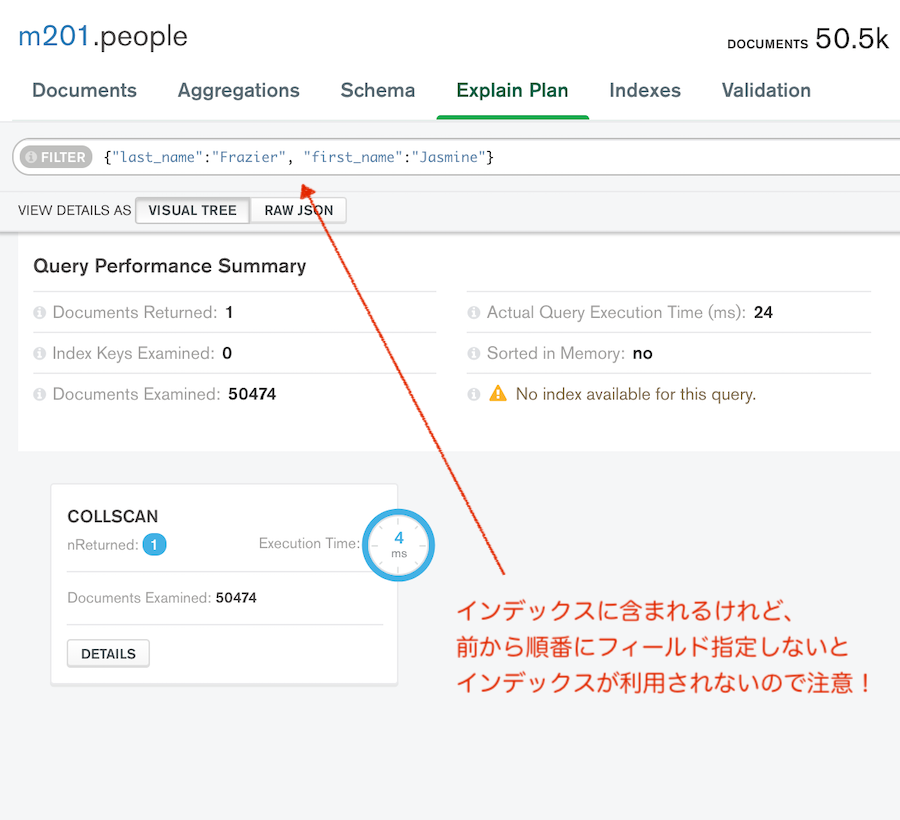
インデックスが使われるかどうかは、クエリの指定の仕方に依存するので注意!
Discussion