ひとりMongoDB University / M201 MongoDB Performance(1)
この記録は、アドベントカレンダー形式ではじめた、MongoDB Universityの学習コースの記録の続きになります!
ただいまのコース
- M201 MongoDB Performance
このコースでは、開発者 / オペレーション担当者双方向けの中級レベルの内容とのことです。
前回の記事は、ひとりMongoDB University / M121 Aggregation Framework(4) でした。
前回からだいぶ間が開いてしまっています。また、時間の関係でメモは飛ばしながらでした...。
そのほかにも、以下のコースを完了しています。メモは書き出していないのですが、別途おさらいで記載しようと思います。
- M220J: MongoDB for Java Developers
- A300: Atlas Security
Chapter 1: Introduction
ハードウェアについての考慮
- コースの概要
- MongoDBのパフォーマンスにはメモリが重要
- また、アグリゲーションといったパイプライン処理のため、CPUも重要
- 特に WiredTiger ストレージエンジン採用の場合に重要
- データの永続化にあたり、RAIDのアーキテクチャが重要
- RAID 1 + 0 (RAID10) が良い
- レプリケーションとシャーディングのため
- 分散させる場合にノード間の通信、mongos 間の通信速度、地理的な距離も重要
Lab 1.1: Install Course Tools and Datasets
このコース用のデータセットを登録します。
自分用のクラスタ、もしくは Atlas 上のクラスタを利用してインポート(わたしは Atlasを使っています)
% mongoimport --drop -c people --uri "$BASE_URL/m201" people.json
2021-10-16T15:53:51.489+0900 connected to: mongodb+srv://[**REDACTED**]@cluster0.xxxxxx/m201
2021-10-16T15:53:51.655+0900 dropping: m201.people
2021-10-16T15:53:54.490+0900 [#.......................] m201.people 1.30MB/21.8MB (6.0%)
....
2021-10-16T15:54:43.155+0900 [########################] m201.people 21.8MB/21.8MB (100.0%)
2021-10-16T15:54:43.156+0900 50474 document(s) imported successfully. 0 document(s) failed to import.
# データのサイズが結構あります
% mongoimport --drop -c people --uri "$BASE_URL/m201" restaurants.json
チェック項目
※ 答えは隠しておきます。解き方のみ。
# メールアドレス保持者の件数
db.people.count({ "email" : {"$exists": 1} })
xxxxx
# aggregation も使ってみます
db.people.aggregate([
{$match: {
"email": {$exists: true}
}},
{$group: {
_id: {},
count: {"$sum": 1}
}}
]);
{ _id: {}, count: xxxxx }
チェック完了、次のセクションに進みます。
このコースでは、インデックスの状況を確認したり、アグリゲーションも利用するので、MongoDB Compass の利用がおすすめです!
Chapter 2: MongoDB Indexes
Introduction to Indexes (動画)
インデックスの概要
- MongoDB はテーブルではなく、コレクションとしてひとまとまり
- データは列ではなく、ドキュメントとします
- key / value の組み合わせでインデックスを作成します
- _id フィールドは自動でインデックスとなります
- インデックスはドキュメントに対して複数設定できます
- b-tree を採用しています
インデックスのオーバーヘッド
- インデックスによるクエリの速度向上は、タダで実現されるというわけではない
- 代わりにオーバーヘッドがある
- インデックスが加われば、書き込みに時間がかかる
- ドキュメントが追加されたり、更新されたり、削除されると、b-tree のバランスの調整が必要になる
- 不要なインデックスは設定しないこと
- インデックス設定により、書き込み自体はパフォーマンスにそれなりのインパクトがあるので
(RDBでも同じですね....)
Check
- Which of the following statements regarding indexes are true?
- 検索時のパフォーマンスを向上させてくれます
- スキャンが必要なドキュメントを絞り込んでくれます
- _id は自動的にインデックスになります
- インデックスが多いと、書き込み、更新、削除のパフォーマンスには影響があります(その分遅くなります)
How Data is Stored on Disk (動画)
インデックスを設定すると、書き込みに少なからずオーバーヘッドがかかる。
そこをうまくやりくりするためのデータの保持の工夫について。
-
インデックスのデータがどのように保持されるかについて
- WiredTiger ストレージエンジンの場合、
--dbpathで指定した場所にコレクションとインデックスのデータが保持される - デフォルトでは、
--dbpathで指定した場所に、コレクションやインデックス、ジャーナルファイルがフラットに保持される - 同じ場所に対しての読み込みや書き込みが発生する
- WiredTiger ストレージエンジンの場合、
-
mongod 起動時のオプションで、
--dbpath以下のデータ構造に階層構造を持たせることができる- コレクションごとにフォルダを作成し、その下にコレクションとインデックスのデータファイルを配置
- コレクションごとにフォルダを作成し、さらにその下にコレクション用とインデックス用のフォルダを作成
- データファイルをその下に配置
-
階層は深くなるが、シンボリックリンクなどでディスクを分けることで、I/Oを分散させることができる
-
MongoDBはデータの圧縮も対応している
- IOのサイズを抑えて、早く読み書きできる
-
データの永続化の保証のために、ジャーナルファイルがある
- 基本はメモリで操作し、定期的にチェックポイントのタイミングで書き込まれる
- 書き込みの際に、
{writeConcern: {w:1, j:true}}を指定すると、データの書き込みを保証してからアプリケーションに結果を返すので、その分オーバーヘッドがある
# start a mongod (デフォルトでは、フラット)
mongod --dbpath /data/db --fork --logpath /data/db/mongodb.log
# this time, start the server with the --directoryperdb option
# --directoryperdb オプションをつけることで、コレクションごとのフォルダ以下に配置
mongod --dbpath /data/db --fork --logpath /data/db/mongodb.log --directoryperdb
# さらにオプション設定、wiredTigerDirectoryForIndexes でコレクションとインデックス用の階層も分ける
# --wiredTigerDirectoryForIndexes options
mongod --dbpath /data/db --fork --logpath /data/db/mongodb.log \
--directoryperdb --wiredTigerDirectoryForIndexes
# 例
ls /data/db/hello
# ディレクトリが2つ出来る
./collections ./index
# write a single document into the 'hello' database
mongo hello --eval 'db.a.insert({a:1}, {writeConcern: {w:1, j:true}})'
Single Field Indexes Part 1 (動画)
最もシンプルなインデックスについて。
まずインデックスなしの状態で、実行計画を確認。
- Ref. https://docs.mongodb.com/manual/reference/explain-results/
-
db.collection.explain()で確認
-
- メソッドの引数:
- winningPlan: A document that details the plan selected by the query optimizer.
- クエリオプティマイザにより選択された抽出方法
- 以下の例だと、COLLSCAN
- executionStats: 実際にwinningPlanを使っての結果を表示
# explain() で統計情報を出力
db.people.find({ "ssn" : "720-38-5636" }).explain("executionStats")
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.people',
indexFilterSet: false,
parsedQuery: { ssn: { '$eq': '720-38-5636' } },
winningPlan:
{ stage: 'COLLSCAN',
filter: { ssn: { '$eq': '720-38-5636' } },
direction: 'forward' },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 1,
executionTimeMillis: 56,
totalKeysExamined: 0,
totalDocsExamined: 50474,
executionStages:
{ stage: 'COLLSCAN',
filter: { ssn: { '$eq': '720-38-5636' } },
nReturned: 1,
executionTimeMillisEstimate: 13,
works: 50476,
advanced: 1,
needTime: 50474,
needYield: 0,
saveState: 50,
restoreState: 50,
isEOF: 1,
direction: 'forward',
docsExamined: 50474 } },
serverInfo:
{ host: 'cluster0-shard-00-02.t9q9n.mongodb.net',
port: 27017,
version: '4.4.9',
gitVersion: 'b4048e19814bfebac717cf5a880076aa69aba481' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634441575, i: 2 }),
signature:
{ hash: Binary(Buffer.from("811092061bec64f4d63a462ae19cbc0f18d8748d", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634441575, i: 2 }) }
# 結果は1つだけど、totalDocsExamined: 50474 で、効率が悪い!
インデックスを作成してみる。
exp = db.people.explain("executionStats")
Explainable(m201.people)
exp.find( { "ssn" : "720-38-5636" } )
{ queryPlanner:
{ plannerVersion: 1,
namespace: 'm201.people',
indexFilterSet: false,
parsedQuery: { ssn: { '$eq': '720-38-5636' } },
winningPlan:
{ stage: 'FETCH',
inputStage:
{ stage: 'IXSCAN',
keyPattern: { ssn: 1 },
indexName: 'ssn_1',
isMultiKey: false,
multiKeyPaths: { ssn: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { ssn: [ '["720-38-5636", "720-38-5636"]' ] } } },
rejectedPlans: [] },
executionStats:
{ executionSuccess: true,
nReturned: 1,
executionTimeMillis: 0,
totalKeysExamined: 1,
totalDocsExamined: 1,
executionStages:
{ stage: 'FETCH',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
docsExamined: 1,
alreadyHasObj: 0,
inputStage:
{ stage: 'IXSCAN',
nReturned: 1,
executionTimeMillisEstimate: 0,
works: 2,
advanced: 1,
needTime: 0,
needYield: 0,
saveState: 0,
restoreState: 0,
isEOF: 1,
keyPattern: { ssn: 1 },
indexName: 'ssn_1',
isMultiKey: false,
multiKeyPaths: { ssn: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { ssn: [ '["720-38-5636", "720-38-5636"]' ] },
keysExamined: 1,
seeks: 1,
dupsTested: 0,
dupsDropped: 0 } } },
serverInfo:
{ host: 'cluster0-shard-00-02.t9q9n.mongodb.net',
port: 27017,
version: '4.4.9',
gitVersion: 'b4048e19814bfebac717cf5a880076aa69aba481' },
ok: 1,
'$clusterTime':
{ clusterTime: Timestamp({ t: 1634442350, i: 2 }),
signature:
{ hash: Binary(Buffer.from("7ced7bb8fa80401769d8c2b4d749b65ce5f1cf45", "hex"), 0),
keyId: 6959643930757431000 } },
operationTime: Timestamp({ t: 1634442350, i: 2 }) }
# IXSCAN になりました!
Compass の画面では、この通り。
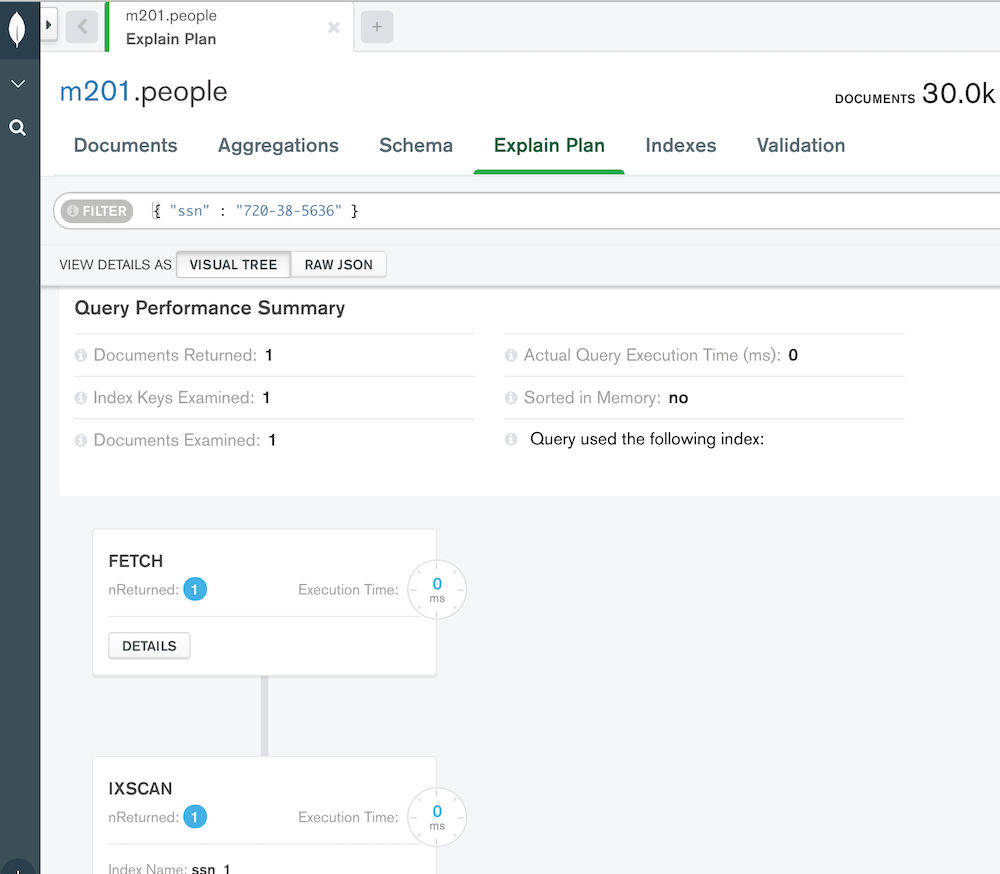
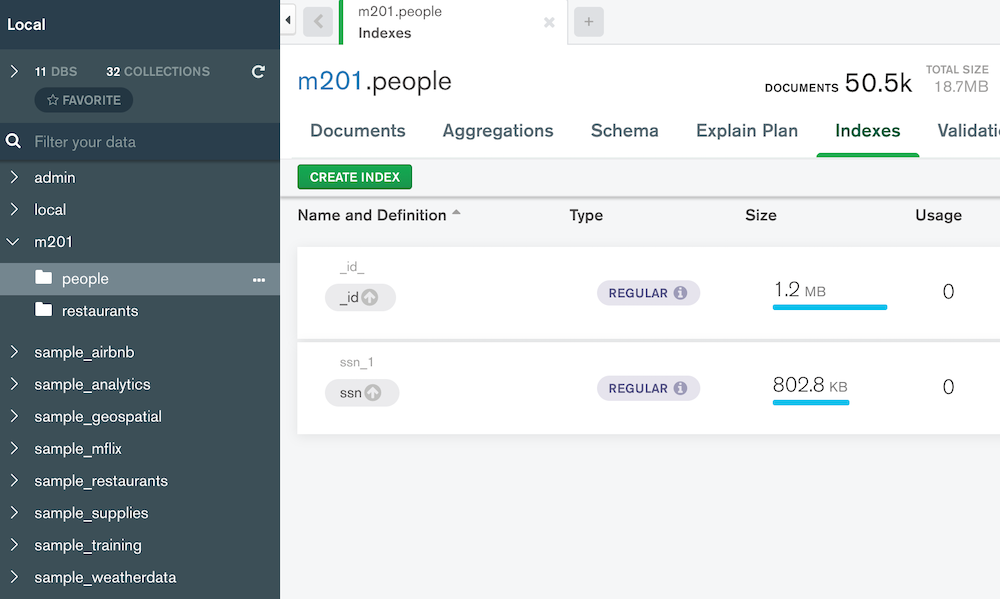
ドキュメントはフラットでなく、ネスト(サブドキュメント)の構造が持てる。
サブドキュメントのフィールドに対しても、ドット指定でのインデックスが設定できる。
// insert a documents with an embedded document
db.examples.insertOne( { _id : 0, subdoc : { indexedField: "value", otherField : "value" } } )
db.examples.insertOne( { _id : 1, subdoc : { indexedField : "wrongValue", otherField : "value" } } )
// ドットのnotation (表記)でインデックスが設定できる
db.examples.createIndex( { "subdoc.indexedField" : 1 } )
Single Field Indexes Part 2 (動画)
- インデックスを使って値がマッチするドキュメントの抽出以外にも、レンジやinが利用できる
# 範囲指定でスキャン
exp = exp = db.people.explain("executionStats")
exp.find( { ssn : { $gte : "555-00-0000", $lt : "556-00-0000" } } )
// explain a query on a set of values
exp.find( { "ssn" : { $in : [ "001-29-9184", "177-45-0950", "265-67-9973" ] } } )
インデックスをカバーするフィールドと、さらにもう1つのフィールドを指定した場合は、まずインデックスを利用して抽出し、さらに絞り込み。
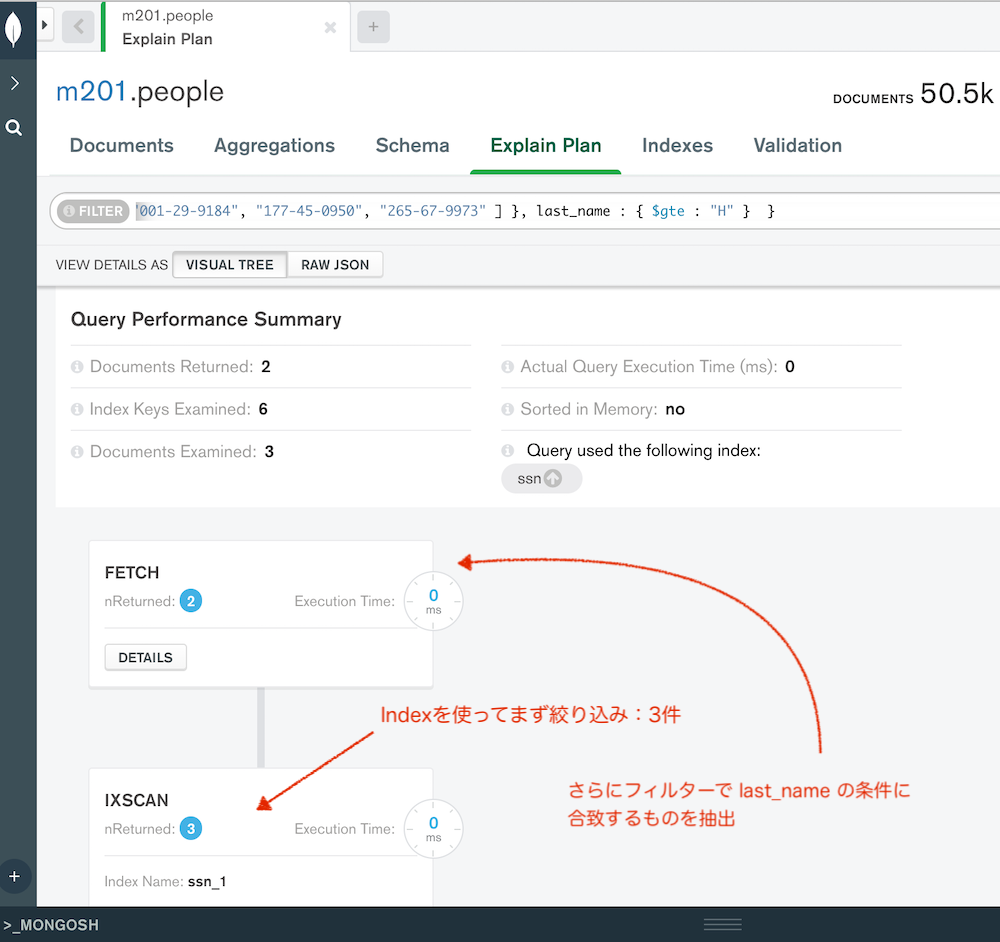
Check - Single Field Indexes
- zip フィールドに対しインデックスが設定されている場合、どのクエリがインデックスを使う?
db.addresses.find( { zip : 55555 } )
今回のメモ
久しぶりに Zenn に MongoDB のメモをアップとなりました。
途中まで進めて時間切れでの再履修なのですが、ディスク上にどのような構成でデータが保持されるかについては、すっかり忘れていた...。
インデックスの利用は、確かに検索には効きますが、その分のデータ登録、更新時のオーバーヘッドをどうするか。
今回の動画では、単一の mongod の元でのデータファイルでしたが、シャーディングする場合は、さらに別のmondodの元でデータが分割される感じになるのかな。
一台のDocker の中でシャーディング試してみると、それぞれの dbpath 以下に、同じコレクションについて分割したデータファイルが見えるかな、と思います。
(余力があったら試してみよう...)
Discussion