とってもやさしいGo言語入門
Webの用語を100秒で解説するチャンネルを作りました!
よかったらチェックしてみてください!
はじめに
この記事は、Go言語を学び始めたばかりの人や、チュートリアルを読んで途中で挫折してしまったという人に向けて、Go言語の基礎的な文法を解説した記事です。といっても全てをカバーするのは大変だと思ったので、私自身が A Tour of Go を読んで難しいと感じた点をいくつかピックアップして書きました。今回の記事では、ポインタ・構造体・メソッド・インターフェースについて解説していこうと思います。
ポインタ
A Tour of Go では、ポインタについて次のような説明をしています。
Go has pointers. A pointer holds the memory address of a value.
(訳) Goはポインタを扱います。 ポインタは値のメモリアドレスを指します。
この「メモリアドレス」とは何でしょうか?
メモリアドレスについて知るには、メモリとは何か知っておく必要があります。そしてメモリを知るためには、メモリ周辺の装置についても少しだけ知っておく必要があります。
この章では、まずプログラムがストレージに保存されてからCPUで実行されるまでの流れについて、ざっくりと説明します。そして次に、メモリアドレスとは何かという説明を行います。最後に、具体的なポインタの役割や使い方について解説していきたいと思います。
ストレージ→メモリ→CPUの流れ

ストレージ
まず、プログラムはストレージに保存されます。 ストレージとは、データを永続的に保存するための大容量の記憶装置のことです。別名「補助記憶装置」とも呼ばれます。メインメモリは揮発性があるので、コンピュータの電源がオフのときは記憶内容を忘れてしまいます。なので、CPUに実行してほしいプログラムなどは、最初に不揮発性であるストレージに保存されるようになっています。
メインメモリ
次に、プログラムは起動されたタイミングで、ストレージからメインメモリにコピーされます。メインメモリは、プログラムやデータを一時的に蓄えておくための装置です。別名「主記憶装置」とも呼ばれます。プログラムはストレージ上で直接実行されるわけではなく、必要なときに必要な分だけメインメモリにコピーして動作させます。メインメモリ上にはプログラムのコードだけではなく、プログラムが使うデータ(変数)なども保存されます。
CPU
最後に、プログラムの命令をCPUが1つずつ読み出して実行していきます。CPUは Central Processing Unit の略で、コンピューターの中枢部分にあたります。CPUがメインメモリにアクセスするときは、自分の足(端子)の一部を使って、『おーい、×△の場所にあるデータを僕の足に送ってくれよ!』というような電気信号をメインメモリに送信します。プログラムの命令をメインメモリが読み出したら、CPUがそれを解読して順番に実行していきます。命令を実行した結果、メインメモリ上のデータを書き変えることもできます。
以上が、メモリ周辺の装置についてのざっくりとした説明です。次は、メモリアドレスについて解説していきたいと思います。
メモリアドレス
先ほど、CPUがメインメモリにアクセスするときの場所の指定方法として、『×△の場所』というような表現をしました。実は、これが「メモリアドレス」と呼ばれるものです。
メインメモリには、1バイトごとに小部屋がぎっしりと並んでいます。各小部屋には、0番地、1番地、2番地というように、住所の番地のように連続した番号が振られており、これをメモリアドレスと呼びます。

プログラム内で変数などが宣言されると、値はこのメインメモリ上の小部屋のどこかに格納されます。このときに必要な小部屋の数は、変数の型のサイズに応じて変わります。
例えば、次のような2つの変数が宣言されているプログラムを実行した場合、
var a string = "a"
var num int = 10
変数 a は string 型で、string 型のデータは半角1文字につき1バイトのサイズを持つので、小部屋は1つだけ割り当てられます。変数 num は int 型で、int 型のデータは4バイト[1]のサイズを持つので、4つの小部屋が割り当てられます。

図では、変数 a には 100 番、変数 num には 101〜104 番のメモリアドレスが割り当てられていますが、連続した領域(小部屋)が割り当てられている場合は、先頭のアドレスが代表として用いられることになっています。なので、この場合の変数 num のメモリアドレスは 101 番となります。
また、実際のメモリアドレスはコンパイル時に自動で割り振られるので、どの変数がどのメモリアドレスになるかは分かりません。しかし、次に述べる方法を使えばメモリアドレスは簡単に調べることができます。
変数のメモリアドレスを取得する
その方法とは、変数名の前に & ( アドレス演算子 ) という記号を付けるだけです。
&変数名
上記のような書き方で、メモリアドレスの取得ができます。では、実際に変数 a と num のメモリアドレスを調べてみましょう。
fmt.Println(&a) // => 0xc00010a210
fmt.Println(&num) // => 0xc000126000
ここでは「0xc00010a210」と「0xc000126000」が表示されました。(この値は実行環境によって異なります)
頭の「0x(ゼロエックス)」という記号は、この値が 16進数であること示します。Go言語やC言語などでは、16進数を扱うときはこの接頭辞を付けることで、2進数・8進数・10進数などから16進数をすぐに判別できるようにしています。先ほどの図では、分かりやすさ重視のためメモリアドレスは10進数で表していましたが、通常メモリアドレスはこのように16進数で表示されます。
また、メモリアドレスは 16進数で書かれていようが 10進数で書かれていようが、値はただの数値です。単なる数値なら、変数に入れることもできるはずです。なので、次は取得したメモリアドレスを変数に格納してみましょう。
ポインタ変数の宣言
では、さっそく変数 a のメモリアドレスを格納するための変数を作ってみましょう。コードは次のように書きます。
var ptrA *string = &a
※ 上記のコードにある *string については、別途「ポインタ変数に型を付けよう」で解説します。ここでは一旦気にせずに読み飛ばしてください。
ptrA には、変数 a のメモリアドレスが格納されています。実はこの ptrA のように、「メモリアドレスを入れることのできる変数」のことを私たちは「ポインタ変数[2]」と呼びます。
なぜこれがポインタ変数と呼ばれるのでしょうか。ポインタという単語は「指し示すもの」という意味があります。ではこの変数 ptrA は、一体何を指し示しているのでしょうか?
ポインタとは
Cambridge Dictionary という辞書で、改めてポインタの意味を探ってみると「物を指し示すために使われるもの」ということが書かれています。例えば、レーザーポインタやマウスポインタなどです。
something that is used for pointing at things, such as a long, thin stick that you hold to direct attention to a place on a map or words on a board, or a cursor
(訳) 地図上の場所やボード上の文字に注意を向けるために持っている細長い棒や、カーソルなど、物を指し示すために使われるもの

では Go言語におけるポインタは何を指し示すのでしょうか?
それは、ある特定のメモリアドレスです。
先ほど、変数 a のメモリアドレス格納する変数 ptrA を作成しました。
var ptrA *string = &a
これを図で表すと、次のようなイメージになります。[3]
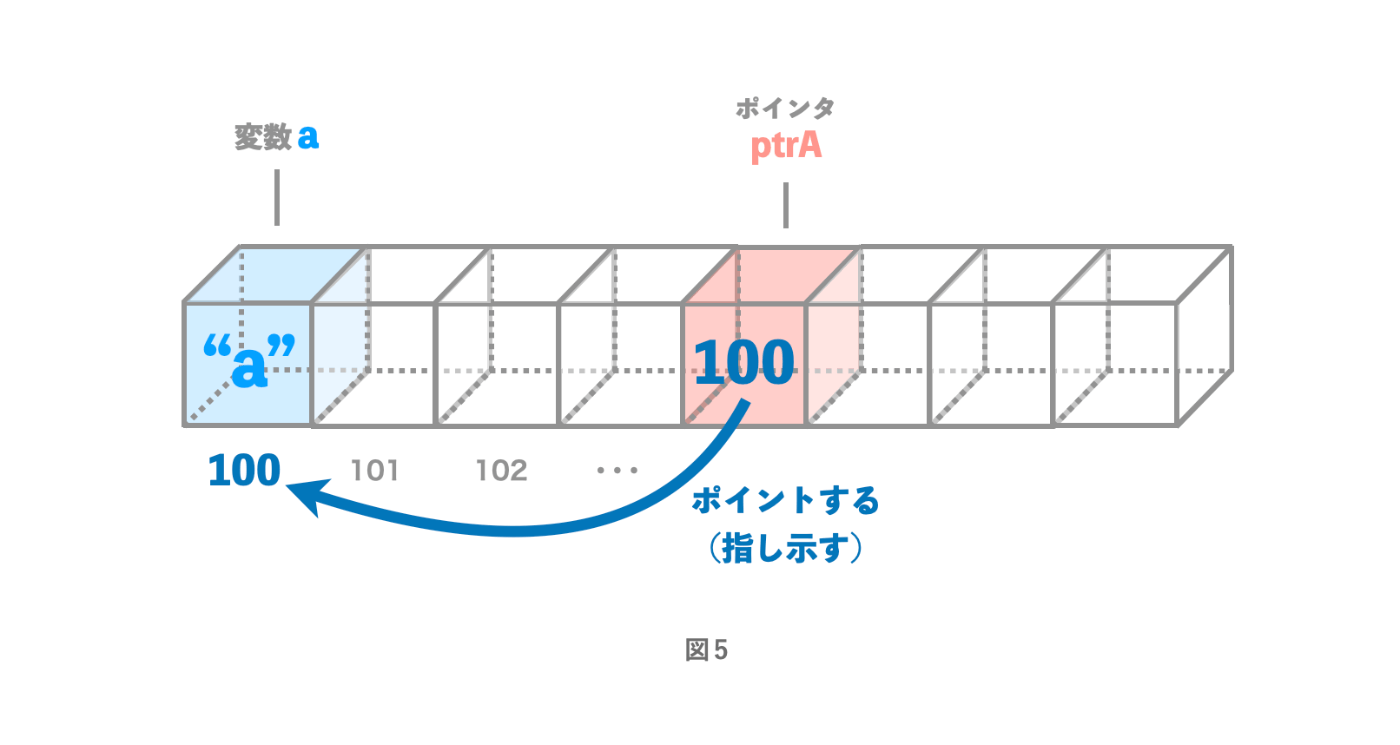
ptrA の小部屋の中には a のメモリアドレス(100番地)が格納されているので、ptrA は a のメモリアドレスをポイントする(指し示す)役割を持っていると言えます。
図4では、レーザーポインターは円グラフを指し示していました。Go言語のポインタ変数も何かを指し示すという点では同じです。異なるのは、ポイントする対象が円グラフではなく、ある特定のメモリアドレスだということです。

まとめると、ポインタ変数は次の特徴を持った変数であると言うことができます。
- 変数のメモリアドレスを格納する
- 格納したメモリアドレスを指し示す役割を持つ
ただ、これだけしかできないのであればポインタ変数の役割は皆無に近いですよね。次は、ポインタ変数を使って実際に私たちができることについてお話したいと思います。
間接参照
現実の世界では、住所が分かれば、その家を訪問することができます。
メモリの世界でも同様に、変数の住所(メモリアドレス)さえ特定できれば、そこにある変数の中を覗いたりすることができるようになります。

変数の中を覗きに行くためには、変数の住所を格納しているポインタ変数の存在が必要不可欠です。
しかしポインタ変数というのは、基本的にメモリアドレスを指し示すことだけを仕事としているので、「覗きにいく」という行為をやってもらうためには、私たちプログラマがそのような指示をポインタ変数に与える必要があります。
現実世界で例えるならば、ポインタ変数は住所が書かれたメモ用紙をただ失くさないようにずっと持っているだけのような人なので、何かをして欲しければ、ポインタ変数に何かを命じなければならないのです。

では具体的にどうやって指示を与えればいいのでしょうか。
その方法とは、ポインタ変数名の前に *(間接参照演算子)を付けるだけです。
*ポインタ変数名
上記のように、ポインタ変数名の前に * という記号を付けることで「そのポインタ変数が指しているメモリの内容を参照しろ」というような意味になります。
また実際の変数名そのものではなく、ポインタ変数を介して値を参照するということなので、私たちはこのことを「間接参照」と呼びます。[4]
では、実際に間接参照を使って、変数 a の値を覗き見してみましょう。
a := "a"
ptrA := &a
fmt.Println(ptrA) // => "0xc00010a210"
fmt.Println(*ptrA) // => "a"
上記のプログラムでは、まず変数 a に文字列 "a" を入れて変数宣言した後、それを変数 ptrA の中に格納してポインタ変数を作成しています。ここまでは前節で解説した通りです。
その後、*(間接参照演算子)を用いて ptrA が指し示すメモリアドレスに入っている変数の値、つまり変数 a の値を取得しています。fmt.Println により表示される値は "a" となるはずです。
このように、ポインタ変数に対して間接参照を使うと、変数の中身を覗きに行くことが可能になります。

それだけではありません。間接参照を使えば、変数の中の値を書き換えることもできます。
例えば次のコードでは、 ポインタ変数の作成後に、そのポインタ変数が指し示すメモリアドレスの変数の値を "b" という値に上書きしています。
a := "a"
ptrA := &a
*ptrA = "b" // 間接参照を使って変数ptrAの値を"b"に変更する
fmt.Println(*ptrA) // => "b"
このように間接参照を使えば、値を参照するだけではなく、ポインタ変数が指すメモリアドレスに別の値を代入することも可能となるのです。
以上で、間接参照についての説明は終わりです。これまで一通りポインタについて解説してきましたが、実はまだ型の付け方については触れていませんでした。最後に、ポインタ型についてお話したいと思います。
ポインタ変数に型を付けよう
Go言語でポインタ変数を宣言するときは、型名の前に * を付ける必要があります。こうすることで「ポインタ型」の変数として宣言することができます。
var 変数名 *型
この * の後ろには、ポインタが指し示す変数と同じデータ型を記します。例えば、ポインタが int 型の変数を指し示す場合、ポインタ型は *int になります。
var i int = 10
var ptrI *int = &i
ポインタ変数は *int 型であっても *string 型であっても、サイズは大体4バイトか8バイトのどちらかになります。(32ビットOSなら前者で64ビットOSなら後者)
つまり、ポインタ変数が指し示す先の変数の型が異なっていても、ポインタ変数自体のサイズはどれも同じということです。試しに unsafe.Sizeof を使って、異なるポインタ型のサイズをそれぞれ調べてみましょう。すると、どちらも同じサイズという結果になります。
var i int = 10
var ptrI *int = &i
fmt.Println(unsafe.Sizeof(ptrI)) // => 8
var s string = "Hello"
var ptrS *string = &s
fmt.Println(unsafe.Sizeof(ptrS)) // => 8
では、ポインタ変数自体のサイズがすべて同じならば、ポインタ変数が指し示す先の変数のデータ型をわざわざ指定しなければならない理由とは何でしょうか。
その理由としては、「何型」のアドレスなのか指定してあげないと、間接参照を使って変数の値を読み書きするとき、何バイトまで辿ればいいのかわからなくなってしまうからだと言えます。
というのも、ポインタ変数が指し示すメモリアドレスは先頭のメモリアドレスだけです。そのメモリアドレスから何バイトのデータがあるかは型によって異なるため、何型かの情報がなければ、そのデータにアクセスすることができなくなってしまいます。
したがって、このようなことを避けるため、ポインタ変数には明示的にその指し示す型を指定する必要があるのです。
構造体
構造体とは
構造体とは、いくつかの変数を1つにまとめて取り扱えるようにしたデータ型のことです。
例えば、私たち「人間」をプログラミングで表現しようとすると、氏名・年齢・性別・体重などの多数のデータを定義する必要があります。

これらを素直に変数で用意した場合、コードは次のようになります。
var name string // 氏名の変数
var age int // 年齢の変数
var gender string // 性別の変数
var weight int // 体重の変数
上記の変数はすべて「同一人物のデータ」という共通点を持っているわけですが、それぞれが個別の変数としてバラバラに宣言されているため、この4つの変数がまとまったデータであることは少し分かりづらくなってしまっています。
そこで、関連するデータを1つにまとめて宣言できるようにするために、「構造体」というものを利用します。
構造体は、私たちプログラマが必要に応じて自由に定義することができるデータ型です。配列を使った場合、同じ型のデータしか1つにまとめることはできませんが、構造体を使用すれば、異なるデータ型の変数でも一緒にまとめて1つのデータ型として扱うことができるようになります。

より分かりやすく例えるならば、構造体を作成することは「これからこういうものを作りますよ」という設計図を書くようなイメージです。設計図は1つあれば、それを使い回して同じものを何個も作成することができます。構造体も同じで、一度宣言してしまえば、それを使って何個でも複製することが可能になります。
ここまで、ざっくりと構造体の概念について解説をしました。次の節からは、実際に構造体の作成方法について書いていきたいと思います。
構造体の宣言
構造体は、次のように struct キーワードを使って宣言します。
struct {
フィールド名 フィールドの型
}
上記のように struct キーワードを使うことで、コンパイラに「この部分は構造体の宣言ですよ」と教えることができます。
そのすぐ後ろの {} の中には、「フィールド」と呼ばれる任意の変数名と型の組み合わせを必要なだけ並べます。例えば、先ほど定義した4つの変数を構造体を使って定義すると、次のようなコードになります。
struct {
name string
age int
gender string
weight int
}
前節でもお伝えしたとおり、構造体はプログラマが定義することのできるデータ型であり、いわば「設計図」のような役目なので、それ単体では利用することはできません。実際に構造体を使用するには、構造体をもとに変数を宣言する必要があります。
具体的には、struct キーワードの前に var 変数名 と記述します。(ここでは変数名は person としています)
var person struct {
name string
age int
gender string
weight int
}
上記のコードを細かく言語化するならば、「 name が string 型で age が int 型で gender が string 型で weight が int 型のフィールドを持った構造体の型を person という変数名で宣言する」という意味になります。
この person の中身は一体どうなっているのか、 fmt.Printf を使って見てみましょう。%#v を使えば、その値のGo言語の構文上の表現を知ることができます。
fmt.Printf("%#v", person)
// => struct { name string; age int; gender string; weight int }{name:"", age:0, gender:"", weight:0}
出力された結果から、各フィールドにはそれぞれゼロ値が設定されていることが分かります。
では、この変数 person のフィールドに何かしらの値を設定したいときは、どうすればいいのでしょうか?次の節では、その方法について説明していきたいと思います。
フィールドに値を格納する
構造体の各フィールドに値を設定する方法は、次のように2つあります。
ドット演算子を使う
1つは、ドット演算子を使う方法です。
構造体の変数は、組み込み型(int 型や string 型など)の変数と比べて、複数の値を格納しています。例えば変数 person の場合は、次の図のように4つの値を格納しています。

変数 person に値を格納するためには、person のさらに「どの場所」に値を格納するのかを具体的に指定する必要があります。そして、この「どの場所」かを示すためには .(ドット演算子)を利用します。
具体的には、次のような形で記述します。
[構造体を格納した変数].[フィールド名]
例えば、変数 person の name の値を取り出したければ、次のように記述します。
person.name
今の時点では、値はまだ設定していないため name はゼロ値のままです。もし、ここに「Tanaka Hanako」というように何かしらのデータを設定したければ、次のように記述します。
person.name = "Tanaka Hanako"
fmt.Printf("%#v", person.name) // => "Tanaka Hanako"
同様に、他のフィールドにも値を設定してみましょう。
ぜんぶ入れると、次のようなコードになります。
person.name = "Tanaka Hanako"
person.age = 25
person.gender = "female"
person.weight = 50
fmt.Printf("%#v", person) // => struct { name string; age int; gender string; weight int }{name:"Tanaka Hanako", age:25, gender:"female", weight:50}
これで、すべてのフィールドに値を設定することができました。
しかし、上記のように一つ一つ個別に値を設定していく方法は、設定する値があらかじめ決まっている場合は少し手間になります。今のところ4つしかないので個別に設定していっても問題は無いのかもしれませんが、将来的にフィールドの数が増えた場合、コードが長くなったり、値の設定をうっかり忘れてしまったりする危険性もあります。
そこで、構造体のフィールドの値を一度に設定できるようにするために、構造体は作成時に初期化することが可能です。次は、その方法について解説します。
構造体の初期化
2つ目の方法は、構造体の作成時に初期化を行う方法です。
構造体は変数宣言と同時に、全てのフィールドに対して初期値を設定することができます。[5]
person := struct {
name string
age int
gender string
weight int
}{
name: "Tanaka Hanako",
age: 25,
gender: "female",
weight: 50,
}
fmt.Printf("%#v", person) // => struct { name string; age int; gender string; weight int }{name:"Tanaka Hanako", age:25, gender:"female", weight:50}
上記のように、構造体型の直後に {} を付けて、その中でフィールド名と値の組み合わせを列挙することで、構造体に初期値を与えることができます。
これで、先ほどのコードよりはずいぶんとシンプルに見やすく書くことができるようになりました。
構造体にtypeを付ける
最後に、type というキーワードを使って新たに型を定義する方法について解説したいと思います。
「構造体とは」で構造体の概念について解説したとき、次のようにお伝えしたことを覚えているでしょうか。
設計図は1つあれば、それを使い回して同じものを何個も作成することができます。構造体も同じで、一度宣言してしまえば、それを使って何個でも複製することが可能になります。
しかし現状のコードを見返すと「使い回す」ことができるとはとても言い難いものになっています。実際に複数の構造体を作成してみると、次のコードのように何度も同じ定義を行ってしまっていることが分かると思います。
hanako := struct {
name string // まずここで定義
age int
gender string
weight int
}{
name: "Tanaka Hanako",
age: 25,
gender: "female",
weight: 50,
}
taro := struct {
name string // また同じ構造体の定義...
age int
gender string
weight int
}{
name: "Yamada Taro",
age: 20,
gender: "male",
weight: 60,
}
これを避けるため、構造体は通常 type というキーワードを一緒に組み合わせて定義します。type とは、既にある型(型リテラル)に対して新しい名前を与えるための機能です。
type [新しい名前] [既にある型]
具体的には、次のように記述します。
type Person struct {
name string
age int
gender string
weight int
}
type を使用することで、これまで構造体を利用するときに struct {name string age int gender string weight int} と長ったらしく書いていた部分を、次のように Person という1つの単語に置き換えて書くことが可能になります。
hanako := Person{
name: "Tanaka Hanako",
age: 25,
gender: "female",
weight: 50,
}
また type を使用した場合、定義した順番どおりに値を設定するのであれば、フィールド名を省略して書くこともできます。[6]
taro := Person{"Yamada Taro", 20, "male", 60}
これまでのコードを全て整理すると、以下のようになります。
type Person struct {
name string
age int
gender string
weight int
}
hanako := Person{"Tanaka Hanako", 25, "female", 50}
taro := Person{"Yamada Taro", 20, "male", 60}
type と構造体を組み合わせて定義することで、ここまでシンプルに構造体を書くことができるようになりました。
少し長くなってしまいましたが、以上で構造体の説明は終わりです。
ここまで、構造体の基本的な使い方などを中心に解説してきました。次の章では、構造体に処理を追加する方法、つまりメソッドについて解説していきたいと思います。
メソッド
メソッドとは
メソッドとは、特定の型に関連付けられた関数のことです。
第2章では、現実世界の「人間」をプログラミングで表現するために、Person という構造体を作成しました。この Person 構造体は、前章でも解説したとおり、人間を表す「設計図」のような役割を果たします。
これまで設計図には、氏名・年齢・性別・体重などの人間の「属性」を表すデータを記述してきました。しかし、実際の人間は、食べる・寝る・話すなどの「動作」を行います。こういった人間の動作も設計図に追加するためには、一体どうすればいいのでしょうか?
例えば「挨拶する」という動作の場合、動作そのものは通常の関数を使って次のように表現することができそうです。
func Greet() {
fmt.Println("Hello!")
}
しかし関数というのは、単に「一連の処理をひとまとめにしてその処理を使いやすくする」ことが仕事なので、関数を使っても設計図に動作を追加することはできません。
そこで「メソッド」というものを利用します。メソッドとは、特定の型に関連付けることができる特別な関数です。
メソッドを使えば型(Person)に対して関数を紐付けることができます。例えば Person 型に対して Greet というメソッドを紐付けると、その型をもとに作成した変数はすべて Greet メソッドを実行することができるようになります。

言い換えると、 Greet メソッドを定義することは設計図に「挨拶する」という動作を追加するイメージなので、この設計図をもとに作成された個々の人間(花子さんと太郎くん)は、生まれながら「挨拶する」という動作を実行することができます。
JavaやC++などのオブジェクト指向言語では、メソッドは「クラス」に関連付けられていて、クラスの内側でメソッドが定義されます。しかしGo言語の場合は、メソッドは構造体などの「型」に関連付けられ、型の外側でメソッドの定義が行われます。(このメソッドと型を関連付けるためにレシーバーというものを利用するのですが、くわしくは次の節で触れます)
では、具体的にどのようにメソッドを定義すればいいのでしょうか。次の節では、先ほどの Greet メソッドを例に、実際のメソッドの定義方法について解説していきたいと思います。
メソッドを定義する
メソッドは、次のような構文で定義します。
func (レシーバ値 レシーバ型) メソッド名(引数値 引数型) 戻り値の型 {
// 処理の内容
}
メソッドの定義方法は関数の定義方法とよく似ていますが、メソッドの場合は func の後ろに 「レシーバ」と呼ばれる引数が必要になります。
例えば Greet メソッドの場合は、次のように定義することができます。 (p Person) と書かれている部分がレシーバです。
func (p Person) Greet() {
fmt.Println("Hello!")
}
では、レシーバとは一体何なのでしょうか?『プログラミング言語Go』では、次のような説明が書かれていました。
メソッドは普通の関数宣言の変形で宣言され、そこでは関数名の前に追加のパラメータが書かれます。そのパラメータが、当のパラメータの型へ関数を結びつけます。
この説明から、レシーバとは 型にメソッドを紐付ける役割を持った引数 だと言うことができます。
例えば、先ほど Greet メソッドのレシーバに Person という型を指定しました。これにより Greet メソッドは Person 型に紐付いている状態となります。
型にメソッドを紐付けると、その型をもとに作成した変数も同じメソッドを利用できるようになります。例えば、Person 型をもとに hanako や taro などの変数を作成した場合、これらの変数も Greet メソッドを自動的に利用することができるようになります。
そして、定義したメソッドは次のように利用できます。
hanako := Person{"Tanaka Hanako", 25, "female", 50}
hanako.Greet() // => Hello!
上記のように、メソッドを呼び出す際は .(ドット演算子)を使用します。ドット演算子は、第2章の「フィールドに値を格納する」で構造体のフィールドにアクセスする方法として紹介しました。メソッドも、これと同様の方法で呼び出すことができます。
メソッド内から構造体のフィールドにアクセスする
さて、これまでに定義した Greet メソッドは、単に「Hello!」という固定の文字列を出力するだけでした。今度は、自分の名前も入れて「Hello! I'm 〇〇.」と出力されるようにしてみましょう。
そのためには、レシーバを通常の引数と同じように利用します。
func (p Person) Greet() {
fmt.Printf("Hello, I'm %v.", p.name)
}
func main() {
hanako := Person{"Tanaka Hanako", 25, "female", 50}
hanako.Greet() // メソッドの呼び出し
}
例えば、上記の Greet メソッドのレシーバ p は、このメソッドを呼び出している変数のデータをそのまま受け取ることができます。この場合、Greet メソッドは hanako という変数によって呼び出されているので、レシーバ p には hanako のデータがそのまま渡されます。
つまり、Greet メソッド内で p.name と記述することで、呼び出し元の変数 hanako に格納された name フィールドの値を取得することができるというわけです。
実際に値が取得できているかどうか確認してみましょう。
hanako.Greet() // => Hello, I'm Tanaka Hanako.
上記の通り「Hello, I'm Tanaka Hanako.」という結果が表示されているはずです。
このようにレシーバを使えば、特定の型にメソッドを紐付けるだけではなく、通常の引数と同じように扱うことができます。
では、このメソッド内からフィールドにアクセスする方法を使って、今度はフィールドの値を直接操作するメソッドを作成してみたいと思います。
ポインターレシーバ
今度は、フィールドの値を 直接操作 するようなメソッドを作成してみましょう。
例えば、人間は「食べる」という動作をしたら体重が増加します。食べる動作をする度に体重が 1kg 増える想定であれば、メソッドは次のように表現することができそうです。
func (p Person) Eat() {
p.weight += 1
}
では実際に上記のメソッドを実行してみて、実行前後で weight フィールドの値が増加しているかどうか確認してみましょう。
hanako := Person{"Tanaka Hanako", 25, "female", 50}
fmt.Println("食前の体重は", hanako.weight) // => 食前の体重は 50
hanako.Eat() // Eatメソッドの実行
fmt.Println("食後の体重は", hanako.weight) // => 食後の体重は 50 👈 増えてない!
結果は、「食後の体重は 50」と表示されました。どうやら Eat メソッドの実行前後で変数 hanako の体重はまったく変化していないようです。これは何故でしょうか?
実は、レシーバの型は「値型」か「ポインタ型」かどうかで挙動が少し変わってきます。値型とポインタ型のレシーバには、次のような違いがあります。
- 値型 ・・・メソッド呼び出し時に「レシーバそのもののコピー」が発生する
- ポインタ型 ・・・ ポインタ型のレシーバを受け取るため、メソッド内部で「実体」に対して変更処理を書くことが可能になる
値型のレシーバの場合は、メソッドが呼び出されたときに レシーバそのもののコピー が発生します。なので、いくらメソッド内でフィールドの値を更新したとしても、これらの変更はコピーに対して行われるため、元の hanako 構造体には何の影響も与えることはできません。
一方で、ポインタ型のレシーバを使った場合は、レシーバそのものではなくポインタを受け取ります。受け取ったポインタを利用して、メソッドの内部で間接参照を行えば、実際の値 に対して変更を行うことができます。今回のように hanako 構造体そのものを直接操作したい場合は、この方法を利用する必要があります。
ではさっそく、Eat メソッドをポインタレシーバの形に書き換えてみましょう。
func (p *Person) Eat() {
(*p).weight += 1
}
Person 型の前に * を置くことで、これがポインタ型のレシーバであることを示します。そして、メソッドのブロック内でポインタを利用して値を更新するようにコードを書き直します。
これで、Eat メソッドを実行したら hanako.weight の値が更新されるようになります🎉
func (p *Person) Eat() {
(*p).weight += 1
}
func main() {
hanako := Person{"Tanaka Hanako", 25, "female", 50}
hanako.Eat()
fmt.Println("食後の体重は", hanako.weight) // => 食後の体重は 51
}
ここで1つ注意しなければならないのは、メソッドの呼び出し元のコードは何も変更する必要がないということです。
例えば、上記のコードは本来であれば、次のように書くはずです。
func (p *Person) Eat() {
(*p).weight += 1
}
func main() {
hanako := Person{"Tanaka Hanako", 25, "female", 50}
ptrHanako := &hanako // 変数hanakoのポインタを作成
ptrHanako.Eat() // ポインタからメソッドの呼び出しを行う
fmt.Println("食後の体重は", hanako.weight) // => 51
}
なぜなら、先ほどはメソッドのレシーバを ポインタ型 に書き換えたので、メソッドを呼び出している変数 hanako も、必然的に ポインタ型 に書き換えるはず、だからです。
しかし、Go言語の場合はその必要はありません。たとえ呼び出し元の変数がポインタ型じゃなくても、レシーバがポインタ型である場合は Go言語が勝手に判断して、それをポインタ型として解釈してくれます。(もちろん上記のように、呼び出し元の変数を律儀にポインタ型に書き換えたとしても問題はありません。)
逆に、呼び出し元の変数がポインタ型だったとしても、レシーバの型が値型である場合は、値型のレシーバとして自動で解釈してくれます。
func (p Person) Eat() {
p.weight += 1 // コピーに対して変更が行われる
}
func main() {
hanako := Person{"Tanaka Hanako", 25, "female", 50}
fmt.Println("食後の体重は", hanako.weight) // => 50
ptrHanako := &hanako
ptrHanako.Eat()
fmt.Println("食後の体重は", hanako.weight) // => 50
}
上記のコードでは、Eat メソッドの呼び出し元は ptrHanako というポインタ型の変数で定義されています。 しかし、実際に Eat メソッドが必要としているのは 値型のレシーバであるため、Go言語は ptrHanako を値型として判断し、結果としてコピーに対して変更を行います。
インターフェース
インターフェースとは
インターフェースとは、型が持つべきメソッドを規約として定めたものです。Go言語の場合、ある特定の型がどのようなメソッドを持つべきかを定めるためにインターフェースを利用します。[7]
例えば、「車を運転する」という動作について考えてみましょう。
type Car struct {
color string
}
func (c Car) Accelerate() {
fmt.Println("車が加速する")
}
func (c Car) Brake() {
fmt.Println("車がブレーキをかける")
}
func drive(car Car) {
car.Accelerate()
car.Brake()
}
func main() {
var car Car = Car{}
drive(car)
}
車が加速する
車がブレーキをかける
上記のコードでは、車を運転するという動作を drive 関数を使って表現しています。この drive 関数の中には、車が加速することを表す Accelerate メソッドと、ブレーキをかけることを表す Brake メソッドが含まれています。このコードを実際に実行すると、「車が加速する」「車がブレーキをかける」という2つの文字列が出力されます。
では、この drive 関数を使って 車以外の乗り物の運転 を表現したい場合はどうすればいいでしょうか?
例えば、車と類似した乗り物にバイクが挙げられます。バイクは車と同様に、加速する・ブレーキをかけるという動作を持った乗り物です。
type Bike struct {
color string
}
func (b Bike) Accelerate() {
fmt.Println("バイクが加速する")
}
func (b Bike) Brake() {
fmt.Println("バイクがブレーキをかける")
}
func drive(car Car) {
car.Accelerate()
car.Brake()
}
func main() {
var car Car = Car{}
drive(car)
var bike Bike = Bike{}
drive(bike)
}
先ほど定義した drive 関数を再利用して、今度は Bike 構造体のインスタンスを引数に渡してみましょう。すると、次のようなコンパイルエラーが出力されてしまいます。
cannot use bike (type Bike) as type Car in argument to drive
このエラーでは「drive 関数の引数に Car 型として bike を使うことはできない」と言っています。つまり、drive 関数の引数には Car 型が設定されているので、それ以外の型の値を渡すことはできないのです。
もし引数に Bike 型の値を渡せるようにしたいのであれば、次の driveBike 関数のように、Bike 型を引数に取る関数を新しく定義する必要があります。
func driveBike(bike Bike) {
bike.Accelerate()
bike.Brake()
}
しかし、この方法はあまり得策だとは言えません。同じ処理内容が書かれた関数が引数の型ごとに定義されて、コードの重複が生まれてしまうからです。
そこで、この問題を解決するために「インターフェース」を使います。インターフェースとは、ある特定の型がどのようなメソッドを実装するべきかを規定するための型です。

これまでの車とバイクの例を使って考えてみましょう。
それぞれの構造体は Accelerate と Brake という共通のメソッドを持っています。インターフェースを使えば、これらの共通するメソッドを異なる型(構造体)から見つけ出し、それらを抽出して新しい型を作り出すことができます。
例えば、上記の図では Vehicle という型を作り出しています。この型を drive 関数の引数の型に設定してやれば、drive 関数は「 Accelerate と Brake メソッドさえ持っていれば、どのような型・値でも構わない」と示すことができます。

そうすることで、drive 関数の引数には Car 型の値と Bike 型の値の両方を渡すことができるようになるのです。
ここまでの解説で、インターフェースとはどういうものかをイメージすることはできたでしょうか。今度は、実際にコードを使ってインターフェースの使い方について解説したいと思います。
インターフェースを定義する
インターフェースを定義するときは、次のように interface キーワードを使用します。
type 型名 interface {
メソッド名①(引数名 引数の型) 戻り値の型
メソッド名②(引数名 引数の型) 戻り値の型
︙
}
{}の中には、型が実装するべきメソッドの情報(メソッド名・引数・戻り値の型)を書いて、それをリストのように並べます。
例えば、Vehicle 型の場合は次のように定義します。
type Vehicle interface {
Accelerate()
Brake()
}
このインターフェースでは、Accelerate(引数なし・戻り値なし)と Brake(引数なし・戻り値なし)の2つのメソッドが必要であることを示しています。
では、この Vehicle 型を drive 関数の引数の型に設定してみましょう。
func drive(vehicle Vehicle) {
vehicle.Accelerate()
vehicle.Brake()
}
上記のように Vehicle 型を設定することで、 drive 関数は「 Accelerate と Brake メソッドを実装した型のみ引数として受け入れる」と示すことができます。
実際に、これまで定義した Car 型と Bike 型を振り返って見てみましょう。
type Car struct {
color string
}
func (c Car) Accelerate() {
fmt.Println("車が加速する")
}
func (c Car) Brake() {
fmt.Println("車がブレーキをかける")
}
type Bike struct {
color string
}
func (b Bike) Accelerate() {
fmt.Println("バイクが加速する")
}
func (b Bike) Brake() {
fmt.Println("バイクがブレーキをかける")
}
それぞれの構造体には、Accelerate と Brake メソッドが定義されています。この2つのメソッドは、Vehicle 型で宣言されたメソッドと名前・引数・戻り値の型すべて一致しているため、これらの構造体は Vehicle インターフェースを実装している(満たしている)と見なされます。
インターフェースを実装していると見なされたら、そのインターフェース型で宣言された変数や関数の引数には、どんな値でも入れることができるようになります。
type Vehicle interface {
Accelerate()
Brake()
}
type Car struct {
color string
}
func (c Car) Accelerate() {
fmt.Println("車が加速する")
}
func (c Car) Brake() {
fmt.Println("車がブレーキをかける")
}
type Bike struct {
color string
}
func (c Bike) Accelerate() {
fmt.Println("バイクが加速する")
}
func (c Bike) Brake() {
fmt.Println("バイクがブレーキをかける")
}
func drive(vehicle Vehicle) {
vehicle.Accelerate()
vehicle.Brake()
}
func main() {
var car Car = Car{}
drive(car)
var bike Bike = Bike{}
drive(bike)
}
車が加速する
車がブレーキをかける
バイクが加速する
バイクがブレーキをかける
上記は、これまで書いた全体のコードです。drive 関数の引数には Vehicle 型を設定したため、引数には Car 型の値だけでなく Bike 型の値も渡すことができるようになりました。
最後に
今回の記事では、私がGo言語を勉強していて特に難しいと感じた点(ポインタ・構造体・メソッド・インターフェース)に絞って解説しました。その他の基本的な文法については、別の記事で書いていこうかなと思っています。
過去にこんな記事も書いています。興味ある方は是非見ていってください。
シェアフル株式会社では一緒に働く仲間を募集しています。
参考文献
- スターティングGo言語
- 6さいからのプログラミング
- 10日でおぼえるC言語入門教室
- わかりやすいC入門編
- 30日でできる! OS自作入
- 第3回 マイコンのプログラムはどこにあるの? PCのプログラムは?
- G学院 プログラミング用語解説
- 第8回 構造体でデータをスッキリと扱う
- 納得C言語 [第14回]構造体 - ほぷしぃ
- Objective-C超入門
- Head First Go
- まくまく Hugo/Go ノート
- Go言語 ハンズオン
- お気楽 Go 言語プログラミング入門
-
CPUや処理系によって、int型は2バイトや4バイトの場合があります。 ↩︎
-
変数のアドレスを「ポインタ」と呼び、ポインタを格納する変数のことを「ポインタ変数」と呼んだりします。 ↩︎
-
図では分かりやすさ重視でポインタの小部屋は1つのみで表現していますが、ポインタのサイズは大体32ビットOSなら4バイトで64ビットOSなら8バイトになります。 ↩︎
-
A Tour of Goでは、「dereferencing」や「indirecting」という名前で紹介されています。 ↩︎
-
ブランク識別子(
_)を使った場合を除きます。 ↩︎ -
フィールド名を省略して書くのはアンチパターンです。 ↩︎
-
今後リリースされるジェネリクスによって、インターフェースの解釈が変わってくる可能性があります。 ↩︎
Discussion
はじめまして、とても記事の内容がわかりやすかったです。ありがとうございます!
記事に出てくるイラストですが、何のツールを用いて作成されていますか?
グーグルスライドや、Canvaだと微妙に違うのかなと思いました。
もしよろしければ、参考にさせていただきたいので、教えていただけると幸いです。
ありがとうございます。記事内の図はKeynoteを使って作成しています。
ありがとうございます!
とてもわかりやすい図だったので、参考になります。