こんにちは。AI ShiftでWebフロントエンドエンジニア(?)をしている安井です。今回は私がAIエージェント開発において模索した、組織の強みを最大限に活かすためのアーキテクチャ設計を紹介します。
AI ShiftではAI Workerという企業専用のAIエージェント構築プラットフォームを開発しており、我々開発メンバーは自然言語処理を強みとするチーム(以下AIチーム)と協働してプロダクト開発をしています。
感じていた課題
*これは私個人が感じていた課題感であり、組織全体の考えでないことを強調します。
AI Shiftでは5年以上前からAIをドメイン領域として、チャットボット、ボイスボットなどの開発をしてきました。当時はAIチームの研究力がプロダクトの強みとしてダイレクトに反映されており、開発チームとしても如何にその研究力をプロダクトに活かすかが重要な視点でした。

しかし、2024年頃からのLLMの進化に伴ってAIチームによるR&Dのスピード感とビックテックのリリース速度による市場の変化にずれが生まれてしまった印象を持ちました。それに伴い開発チームとしては如何に早くその時点でベストなLLMをAPIとして組み込むかが重要になり、今までのR&Dを強みとしていたAIチームとの連携が薄れてしまっていました。
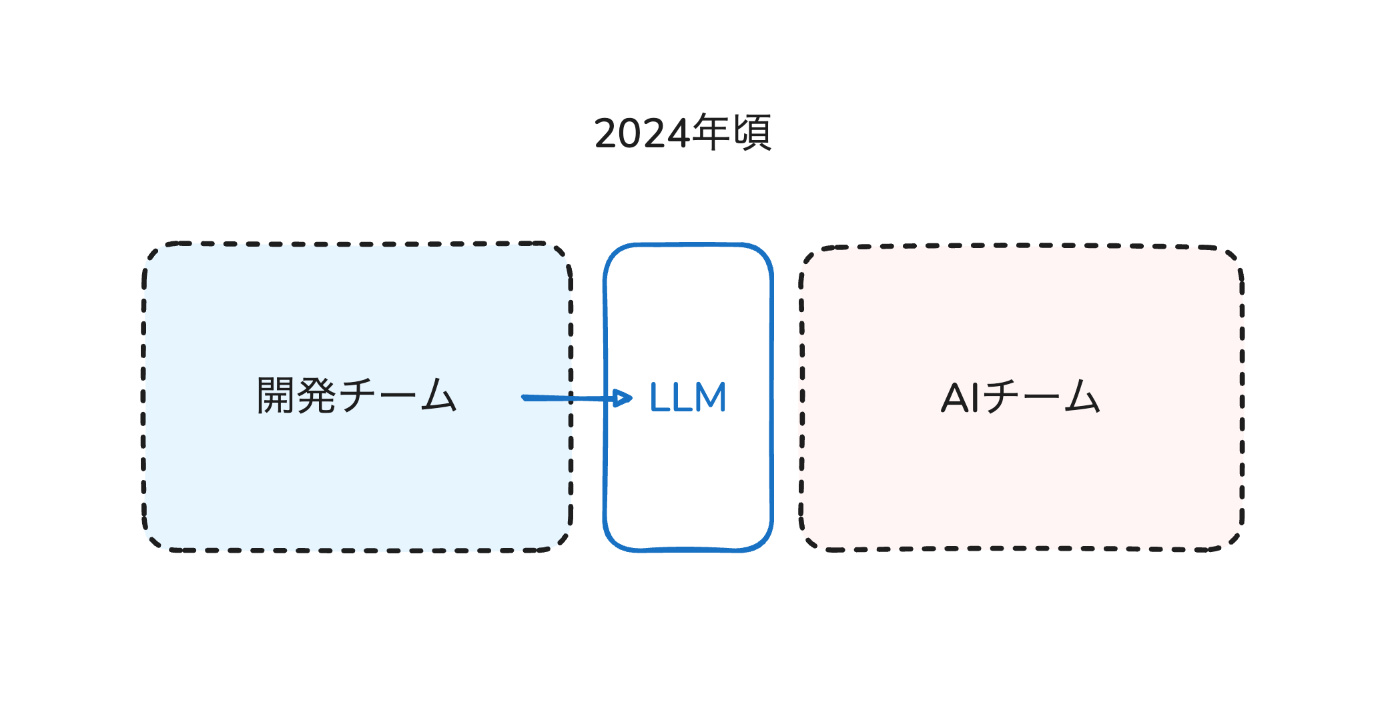
2024年ごろに勃興したチャットベースのLLMアプリケーションにおいては、もちろんRAGのような専門性が必要とされる領域もあったものの、AIチームの強みを100%活かしきれているとは言えませんでした。
しかし2025年になり"AIエージェント元年"と市場から注目されるようになったことでこの状況は変わっています。
我々開発者が日常的に使っているCodingのAIエージェントなどを見ても、単にLLMを活用するだけでは不十分で、多様なツール実行やメモリの管理など構成する要素は様々です。

しかし、前提が少し変わっています。LLMを活用すること自体は大前提にあり、APIとしてLLMを使用するだけであれば開発チームが責務を持った方がスムーズです。一方で、AIチームの専門性をプロダクトに落とすためには開発の責務が重複してしまいます。
AIエージェントの開発においては、開発チームもAIの専門領域に踏み込む必要がありますし、AIチームも開発のノウハウを得てプロダクト開発に踏み込む必要が生まれました。
長くなりましたが、このような前提のもとに組織の強みを最大限活かせるよう模索したアーキテクチャ設計並びに技術の選定を紹介します。
責務をサービスで分断しない
AI WorkerはAIエージェント構築プラットフォームのため、大きく分けて3つのサービスが存在します。
- エージェントを利用するサービス
- エージェントを構築するサービス
- 構築したエージェントを実行するサービス

この中でAIチームが主に責務を持つのは構築したエージェントを実行するサービスです。そして、この実行エンジンがAIエージェントの精度そのものに影響します。
素直に考えれば、下図のようにエージェントを利用、構築するサービスを開発が責務を持ち、実行エンジンをAIチームに責務を持ってもらうことがいいように見えます。
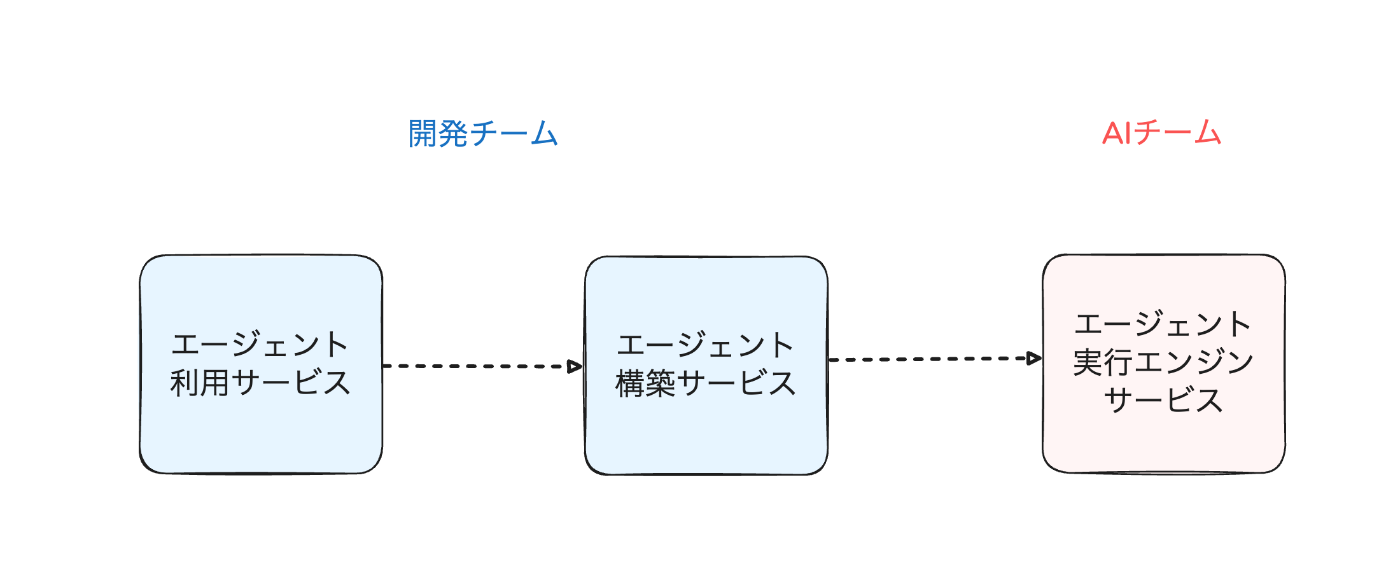
しかし、先ほど説明した通りAIエージェント開発の時代においてAIチームの責務は、よりアプリケーション層まで求められるようになっています。
例えば、AIエージェントの記憶領域を確保するためにはDBの選定から始める必要がありますし、世の中にある様々なAIエージェントのフレームワークを選定した上で、HTTPサーバの構築をする必要があります。
これらは明らかに開発チームが責務をもつ領域であり、R&Dの要素からはかけ離れた実装です。そこで、お互いの歩み寄りでAIチームと開発チームを統合し、さらにサービスの中で開発チームが担う責務と、AIチームが持つ責務を明確化しました。

開発言語の統一
次に我々が行ったのが開発言語の統一です。AI Shiftでは元々AIチームのサービスにPythonをメインの言語としてきました。もちろん豊富なライブラリが魅力で今でもAI系の開発では最前線の言語だと思います。
しかし、我々の開発チームはサーバサイドにTypeScript(Node.js)を採用しており、全てをmonorepoで管理しています。その前提に立つと、エージェントの実行エンジンサービスもTypeScriptで統一するメリットの方がPythonを選択する以上に大きいと判断しました。
私の思う言語の統一メリットは以下の通りです。
- 他サービスのアーキテクチャを参考にして実装できる
- 開発 / AI間でナレッジの共有ができ横断しやすくなる
またAI Shiftの別の事業部で開発チームとAIチームの言語を統一したことにより、開発速度の向上とチーム間の連携強化が得られた実績がすでにありました。
私たちの事業部にとってもこの事例は非常に参考になり、同様の効果を期待してTypeScriptで統一する判断をしました。
詳しくはこちらの記事で解説されています。
AIエージェントのフレームワークにMastraを採用
エージェント実行エンジンをTypeScriptで統一し、フレームワークにはMastraを採用しました。
MastraはTypeScriptでAIエージェントを構築するためのフレームワークです。エージェント、ワークフロー、RAG、評価といった主要機能だけでなく、直感的にデバッグ可能なplayground uiや運用を見据えたOpsの機能なども豊富に備わっています。
MastraはElastic License 2.0(ELv2)のライセンスで提供されています。このライセンスのもとでは、Mastra自体を第三者に対してホスティング型またはマネージドサービスとして提供することは制限されていますが、自社プロダクトに組み込んで商用利用することは可能です。
より具体的なAIエージェントの設計についてはこちらの記事で深く解説をしているためぜひご覧ください。
AI Workerでは、自律性とガードレールによる制約のバランスを調整するためにMastraのワークフローの上に自律的なエージェントを配置することで、システム的な制約を守りつつ、AIエージェントの自律性を最大限保証することを意識しています。

フレームワークとの向き合い方
Mastraを採用したことによって、AIエージェント開発の初速が間違いなく上がりました。しかし、voltagentを含めてTypeScript製のAIエージェントフレームワークは今後も選択肢が増えると考えています。
そして、AIエージェントの領域は毎週のように変化があり、時には新たなプロトコルが発表されます。そのスピード感に遅れないようにフレームワークに乗るのは有効ですが、同時にその時々で最もFitするフレームワークを選択することも重要です。
2025/06現在、TypeScriptでAIエージェントを開発する上ではMastraが最も我々のプロダクトにFitしたライブラリであることは間違いありませんが、それが1年、2年後もそうであるとは限りません。
そのため、いつでもフレームワークを剥がして最適な選択を取れるように準備をする必要があると考えています。そして、その周期がとても早いのがAIエージェント開発の特徴です。
例えば、MastraにStorageの機能がありますが、我々はこの機能を使用していません。代わりに独自でPostgreSQLのDBを用意して、短期記憶などの永続化をしています。
この背景としては、DB Schemaがフレームワークに依存すると柔軟にTable設計ができなくなることと、先ほど述べたフレームワークを乗り換える未来に備えた判断です。
当然、一部フレームワークに乗らない機能は独自に実装をする必要があるため、スピードとのトレードオフが伴いますが、このバランスはAIエージェント開発におけるフレームワークとの向き合い方で重要な観点かと思います。
しかし、この判断が正しかったかはまだわからないため数年プロダクトを運用する中で改めて反省する時間を作りたいと思います。
依存性の逆転を徹底し、疎結合に責務の分離を実現する
次にアーキテクチャの設計で最も意識したことが「依存性の逆転」と「疎結合に責務の分離をする」ことです。
先ほども解説した通り、エージェントを実行するサービスにおいては開発チームとAIチームが同じソースコードに関わります。
そこでイメージとして、MastraのWorkflowをusecase層、短期記憶などをinfra層とみなし、それぞれ抽象に依存する形で実装することで各モジュールを疎結合に保つようにしています。
当然このような疎結合に責務の分離をすることで、各層におけるテスタビリティも向上しますし、仮にAIチームが短期記憶の検証、改善をする場合でもhttp層、usecase層への影響はありません。

同一サービスを異なるチームが開発する環境においては、コードベースでも適切な責務の分離が必須でありそれ自体が開発生産性を上げてスピードを保つ重要な要素だと思います。
MastraのruntimeContextを活用する
上記のようなアーキテクチャの場合、usecase層(MastraのWorkflow)はインターフェースに依存し、infra層の実装は外部から注入されることを期待します。
その場合、MastraのruntimeContextが活用できます。
type WorkflowRuntimeContext = {
repository: IRepository;
};
const runtimeContext = new RuntimeContext<WorkflowRuntimeContext>();
runtimeContext.set("repository", repository);
await start({
triggerData,
runtimeContext,
});
runtimeContextは私がMastraを採用した当初は無かった機能で、最も待望していた改善でした。
Feature Flagを用いた高速な検証サイクル基盤の構築
次にAIエージェント開発において重要なのは実装と検証のスピード感です。特にLLMにおける不確実性要素が大きいため、すぐに検証環境に上げて試し、改善するフィードバックサイクルを回す必要があります。
しかし、検証コードをbase branchへMergeしてしまうと、そのまま本番環境へ適用されるかデプロイをブロックしてしまいます。そこでFeature Flagを用いてリリース対象を制御します。
AI ShiftではDevCycleというFeature Flagを管理するツールを用いており、GUIでFeature Flagの管理をすることができます。
また、先ほど解説した「依存性の逆転」と「疎結合に責務の分離をする」二つを意識することでFeature Flagによる制御を容易に行うことができます。

今回はMastraのWorkflowで本番環境とは別に、新たなフローを検証環境で試すことを想定します。その場合でも、MastraのWorkflow(usecase層)が同一のインターフェースに依存していればFactoryでどちらのWorkflowを使用するか分岐させることは容易です。
特にこのFeature Flagを活用した実装は効果的で、AIエージェントのWorkflow(usecase層)を改善して振る舞いを刷新するプロジェクトを約1ヶ月程度で完走し、本番環境への影響を0でリリースまですることができました。
そして何よりもこの高速な検証サイクル基盤の構築をアーキテクチャ設計の初期から考慮できていたことで長期的にもR&Dを高速に行える準備ができたと考えます。
まとめ
今回はAIエージェント開発における組織の強みを活かすためのアーキテクチャ設計について紹介しました。LLMの進化に伴って開発とAIの責務は曖昧になり双方の横断する意識が重要になっています。
そんな中でも堅牢にスピード感を持って開発するためには、疎結合に責務の分離ができたアーキテクチャ設計は必須です。
さらにはFeature Flagを用いた高速な検証環境を整備することにより、市場でも負けないスピード感を持って改善、検証のサイクルを回すことができます。

Discussion