こんにちは。AI ShiftでWebフロントエンドエンジニアをしている安井です。今回はAIエージェントを実現するにあたって試行錯誤した設計と実装に関する筆者の考えを整理したいと思います。
はじめに
AIエージェントは現在大きな注目を集めており、新しいサービスも次々と登場しています。しかしながら、実際にAIエージェントを開発するための具体的な方法論については情報が十分に共有されておらず、依然として不明瞭な部分が多いように感じています。
そこで今回はAIエージェントを開発する上で重要になるであろうポイントを3つ整理して解説したいと思います。
- 不確実なエージェントの振る舞いを可能な限り分解する
- 自律性とガードレールによる制約のバランスを調整する
- 非同期を前提にして、ユーザへ細かくフィードバックする
使用する技術
今回はAIエージェントを構築するフレームワークであるMastraを前提に解説をします。ですが、本記事の目的はMastra自体の紹介ではなくAIエージェントの設計と実装に焦点を当てているため、具体的なフレームワークの解説は行いません。
そもそもAIエージェントとは
具体的な実装を紹介する前にまずはAIエージェントとは何か前提を揃えたいと思います。
ここで想定するAIエージェントは「個性」「記憶」「計画」「行動」の4つの特徴を持ちます。
- 個性
- エージェントはそれぞれ固有の役割や専門性を持って設計されています。
- 記憶
- エージェントは長期的な記憶領域を持ち、過去の経験を蓄積・活用します。
- 計画
- エージェントは最終目標を達成するために、目標をサブタスクに分解し、実行順序や優先順位を決定します。
- 行動
- エージェントは外部環境との相互作用を通じて、計画に基づいた具体的なアクションを実行します。
つまり、個性を持ったエージェントが自律的にプランを計画し、その計画に基づいてアクションを実行して適切に記憶と経験を蓄積します。
この振る舞いをAIエージェントの土台として前提にした場合、私たち開発者はさまざまなポイントに注意をする必要があります。
それでは具体的な設計に話を進めていきましょう。
不確実なAIエージェントの振る舞いを可能な限り分解する
AIエージェントの振る舞いは以下の要素によって分解できます。
*それぞれの用語はあくまで本記事での表現です。
AIエージェントの出力 = instruction(エージェントの個性) + model(LLM Model) + memory(エージェントの記憶) + tools(エージェントの道具)
- instruction(エージェントの個性)
- model(LLM Model)
- memory(エージェントの記憶)
- tools(エージェントの道具)
export const weatherAgent = new Agent({
name: "Weather Agent",
instructions:
"あなたは天気情報を提供する、アシスタントです。",
model: openai("gpt-4"),
memory,
tools: {
weatherInfo,
},
});
それぞれの解説
まずは分解した4つの要素について説明をします。
instruction(エージェントの個性)
AIエージェントの振る舞いに対して大きな影響を与えるのが「個性」です。これはuser roleプロンプトのように自由な値が入るわけではなく、事前に定義されたエージェントの特性を示すプロンプトが設定されます。
例)あなたは天気情報を提供する、アシスタントです。
このinstructionを適切に設定することによって、エージェントの振る舞いを制御し、目的に合わせて最適化することができます。
model(LLM Model)
使用するLLMのModelがAIエージェントの振る舞いに影響することは想像に難くないと思います。当然旧来のGPT-3.5系を使うよりも最新のモデルを使った方が精度が高いことは普段ChatGPTなどを使っていれば体感できます。
ですが、モデルによってそれぞれ得意とする領域があることは注意が必要です。
例えばAIエージェントの計画を考える段階に関してはo1など(Reasoning models)を使用した方がGPT-4oなどのモデルよりも得意である傾向があります。一方で、GPT系のモデルは解き方が明確になっているタスクの実行が得意とされ、レイテンシやコストにおいて優れています。
そのため、適切な場面で適切なモデルを選定することは非常に重要なポイントです。

https://platform.openai.com/docs/guides/reasoning-best-practices
memory(エージェントの記憶)
次にAIエージェントの振る舞いに大きく影響するのが「記憶」です。
LLMアプリケーションでは、スレッド内の過去のやり取りを踏まえて回答することが重要であり、毎回会話の履歴を忘れていては、ユーザーのニーズを満たせません。この過去の会話記憶を短期記憶とした場合、AIエージェントでは長期的な記憶領域の確保も必要になります。
例えば自律型ソフトウェアエンジニアリングのAIエージェントであるDevinを参考にします。
Devinは過去に行ったタスクの履歴からKnowledgeとして記憶してチーム間で共通のmemoryを共有することができます。このようにしてDevinはタスクをこなすごとに、チームにとって最適化されていきます。
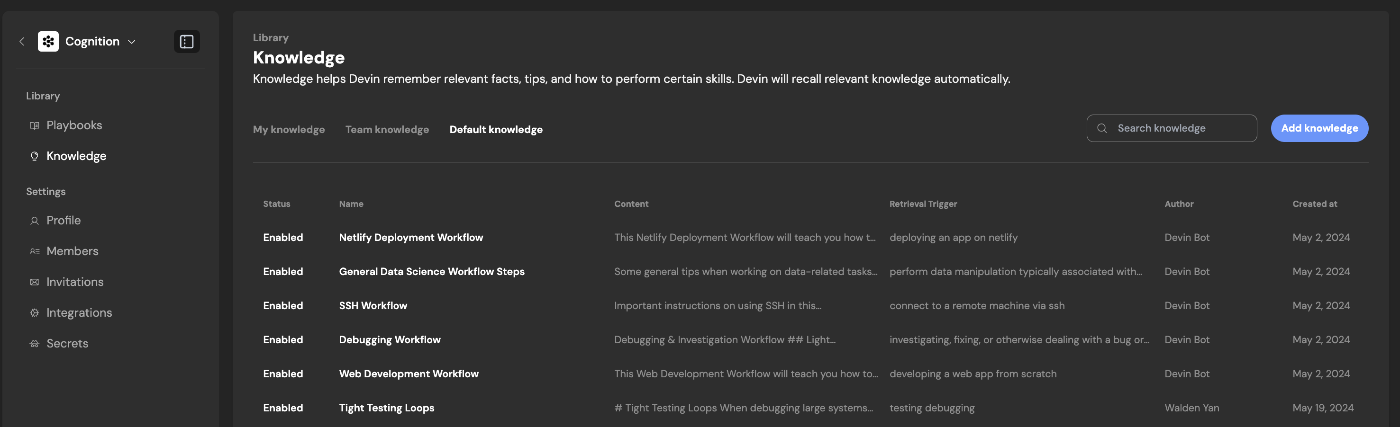
https://docs.devin.ai/product-guides/knowledge
このAIエージェントの記憶の管理に関しては、より専門的な知識が必要になるため、本記事で詳しく解説することはできませんが、記憶の管理を改善することによってAIエージェントがユーザにとってより最適化されていきます。
tools(エージェントの道具)
最後にAIエージェントにtoolを渡すことでより「行動」の範囲を広げることができます。
上記の天気予報を例にすると、LLMだけでは外部環境に作用することができないため、今日の天気予報をすることはできません。そのため、API経由で天気予報を取得するtoolをAIエージェントに渡す必要があります。
このようにLLMだけでは不十分な場合でも、toolとして様々な道具を渡すことによってAIエージェントの行動の範囲を広げて、複雑なタスクを実現することができます。
また、toolにMCPを連携させることもできます。例えばMastraではMCPConfigurationというAPIが公開されており、接続したいMCP Serverを設定するだけで、複数のMCP Clientを管理することなく連携することができます。
const mcp = new MCPConfiguration({
servers: {
weather: {
url: new URL("http://localhost:8080/sse"),
requestInit: {
headers: {
Authorization: "Bearer your-token",
},
},
},
},
});
const agent = new Agent({
name: "Assistant",
instructions: "You help users with tasks",
model: openai("gpt-4o-mini"),
tools: await mcp.getTools(), // Tools are fixed at agent creation
});
なぜAIエージェントの振る舞いを分解するのか
さらに細かく分解することも可能かと思いますが、ここではAIエージェントの振る舞いは上記4つの要素によって成り立つと整理しました。
このように要素を整理した理由は、問題が発生した際の切り分けが容易になると考えるためです。
AIエージェントの強みはその自律性であり柔軟性です。しかしその一方で、AIエージェントが期待した挙動にならなかった場合、問題の特定が非常に困難になります。
そのためAIエージェントの要素を分解することで、どの要素が影響して現在の挙動に至っているのかを把握しやすくすることができます。

テスタビリティを向上させる
また、各要素を適切に分解することでそれぞれの振る舞いをテストすることができます。仮にAIエージェントそのものの期待挙動をテストしようとした場合、テストの観点がわからないだけでなく、LLMの不確実性に依存しているため非常に困難です。
これは従来のアプリケーション開発におけるE2Eテストの難しさとも通ずる点があります。そこで、要素を分解することでまずはテストができる対象を整理します。
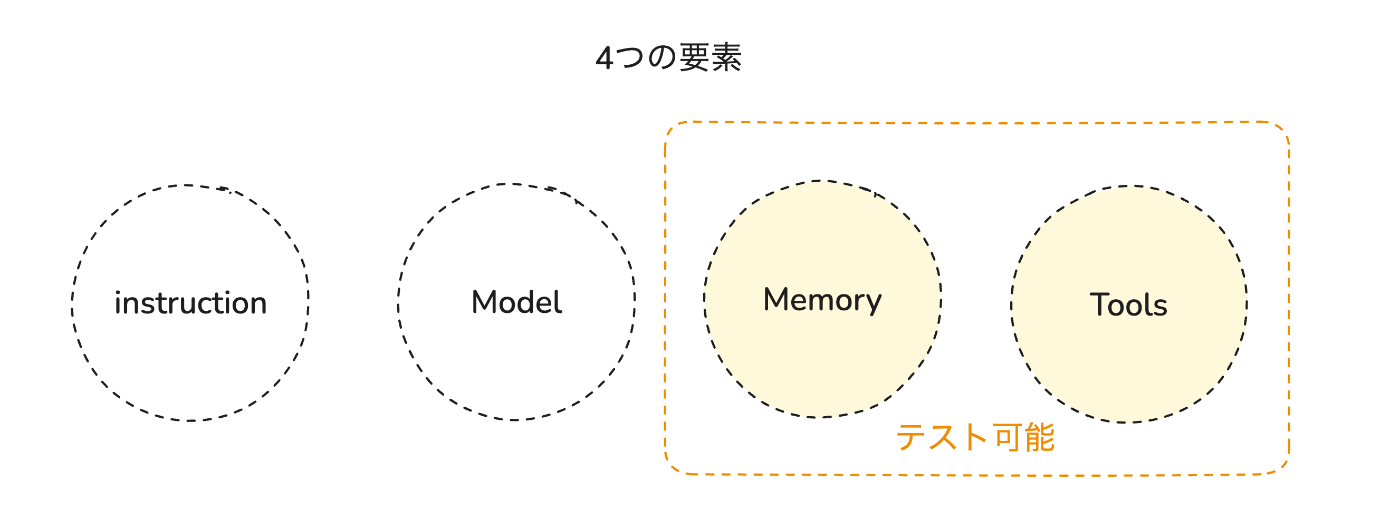
すると、「memory」と「tools」に関してはテストが可能な対象であると考えることができます。
memoryに関しては、例えば適切なタイミングで期待する内容がDBに保存されているかなどをテストすることが可能です。
toolsに関しては、各ツールごとに単体でテストが可能です。特にtoolの中でロジックを持つケースが往々にしてあるため、toolごとにテストをすることでシステム上の振る舞いを保証することができます。
自律性とガードレールによる制約のバランスを調整する
先ほどはAIエージェントの特徴について整理し、その要素を4つに分解して理解しました。次にAIエージェントを実装する上で重要な自律性の制御について考えていきたいと思います。
例えば、ユーザの入力に対して必ず最初に計画を立てて、一度ユーザに確認を求めてから実行するAIエージェントを実装したいとします。
この場合、エージェントのinstructionだけでこれらのシステム要件を制御するには限界があると考えます。
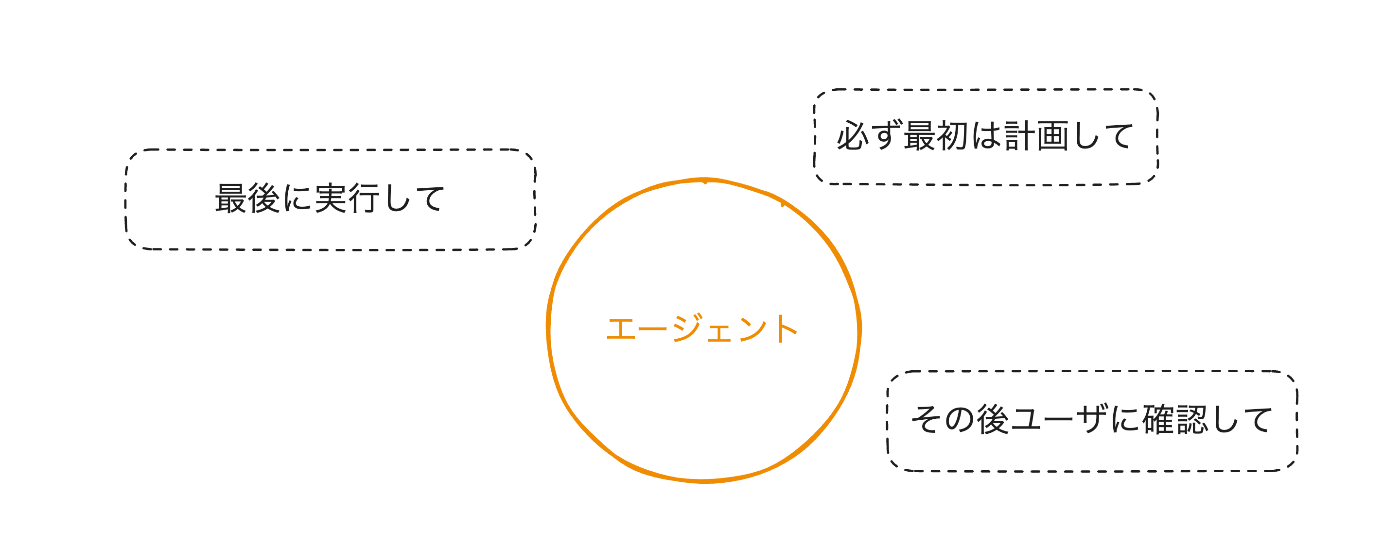
そのため、適切なガードレールを敷き、その上に自律的なAIエージェントを配置することによってシステム要件を満たしつつ、エージェント自身の自律性を最大限に引き出すことができます。

Agentic Workflowに自律的なエージェントを組み込む
少し抽象的な説明だったため、具体的な実装をもとに解説をします。
例えばMastraにはAgentic WorkflowをGraph Basedに構築するための機能があります。
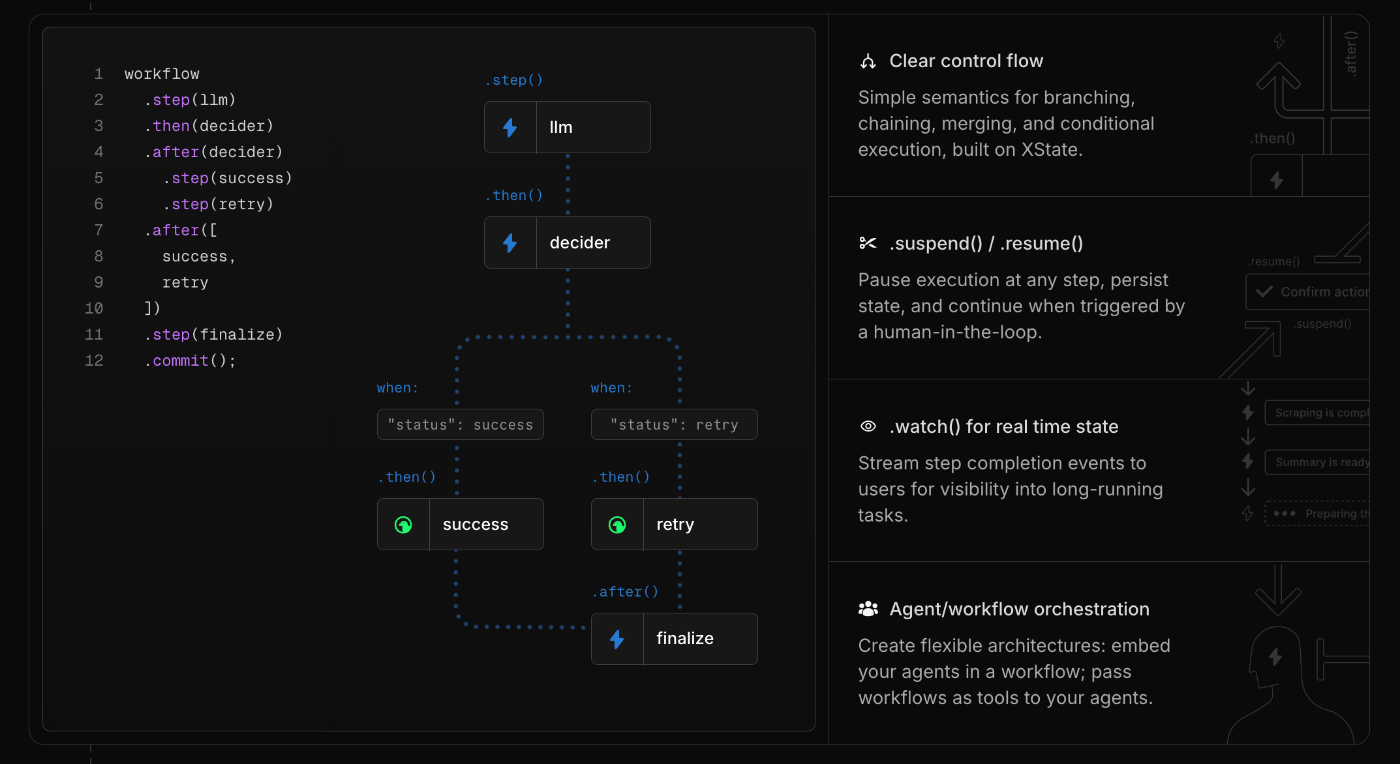
このAgentic Workflowを用いると、まずはPlanを実行するエージェントを実行し、その内容をユーザに確認をして、問題なければエージェントがtoolを用いて結果を出力する、といったフローを制御することができます。
workflow
.step(planAgent)
.step(checkToHuman)
.step(generateAgent)
.commit()
ワークフローを複雑化させない
先ほどシステムの要件を満たすためにAgentic Workflowの上に自律的なエージェントを載せることで制御する重要性を解説しました。
しかしその一方で、Agentic Workflowの制約が増えれば増えるほど従来のワークフロー型のエージェントのように条件分岐が大量に発生し、かえって制御が困難になります。
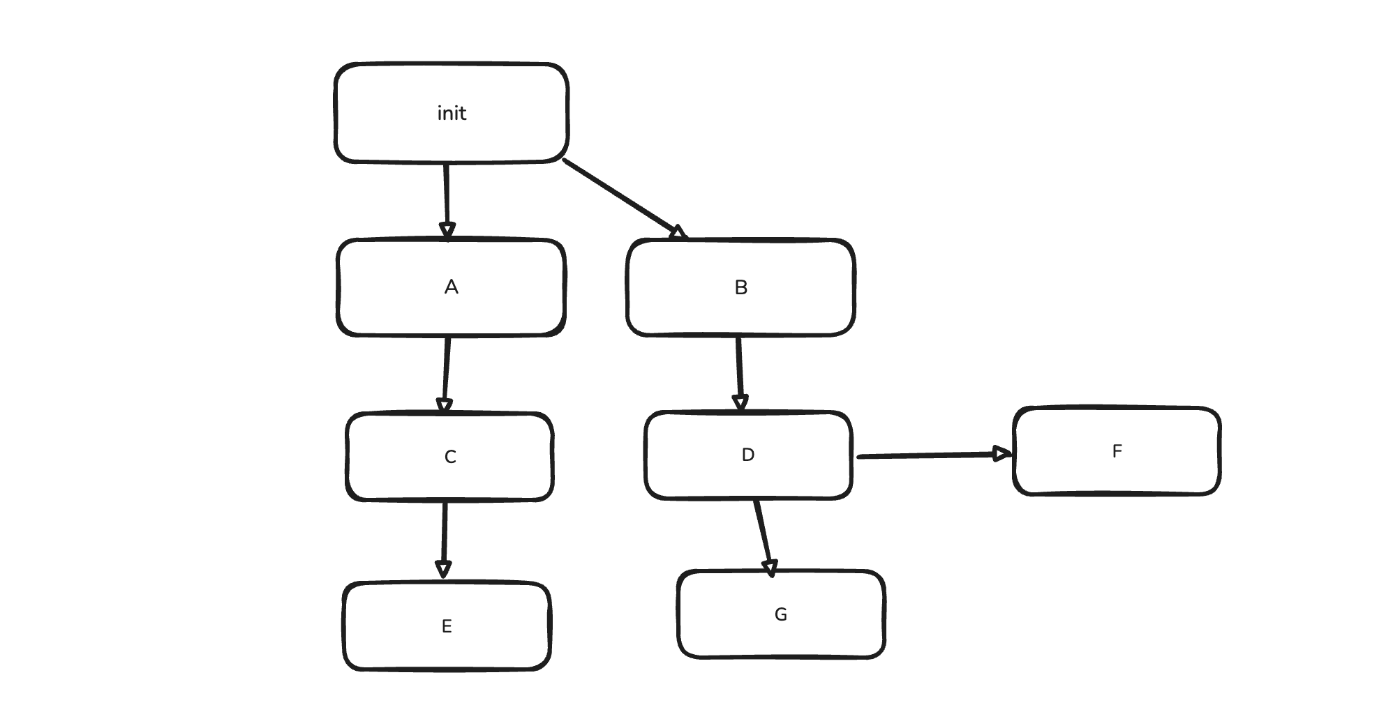
そのため、システム上絶対に欠かせない要件のみを整理してワークフローに落とし込み、ある程度エージェントの自律性に任せても問題ない点に関しては、なるべくワークフローのStepではなくエージェントの自律性に寄せることが大切だと考えます。
非同期を前提にして、ユーザへ細かくフィードバックする
これまではAIエージェントを実装するための内容を扱ってきましたが、ここからはUXの側面からAIエージェントのサービスに不可欠な要素を整理したいと思います。
ユーザへのフィードバックは素早く、詳細に行う
改めて、AIエージェントは「個性を持ち自律的にプランを計画して、その計画に基づいてアクションを実行して適切に記憶と経験を蓄積」する特徴を持っています。
つまり、ユーザの依頼に対して回答が出力されるまでには様々なプロセスを経て行われます。そのため、ユーザからすると「期待通りAIエージェントは動いているのか...」、「システムの障害で止まっていないか...」など不安が生まれます。
例えばDevinではユーザの依頼に対して、「今実行しているタスク」や「実行した内容とその結果」などを細かくユーザへ反映してタスクを遂行します。これによって私たちユーザはタスクの進捗状況を細かく把握して、問題があれば軌道修正することができます。

https://docs.devin.ai/get-started/devin-intro
最低でも以下の内容はユーザに対してフィードバックする必要があると考えています。
-
計画の内容
- これから何をするのか
-
計画に沿った実行の詳細
- 各計画のStepを実行する報告
- 実行した結果
- 最終的な出力
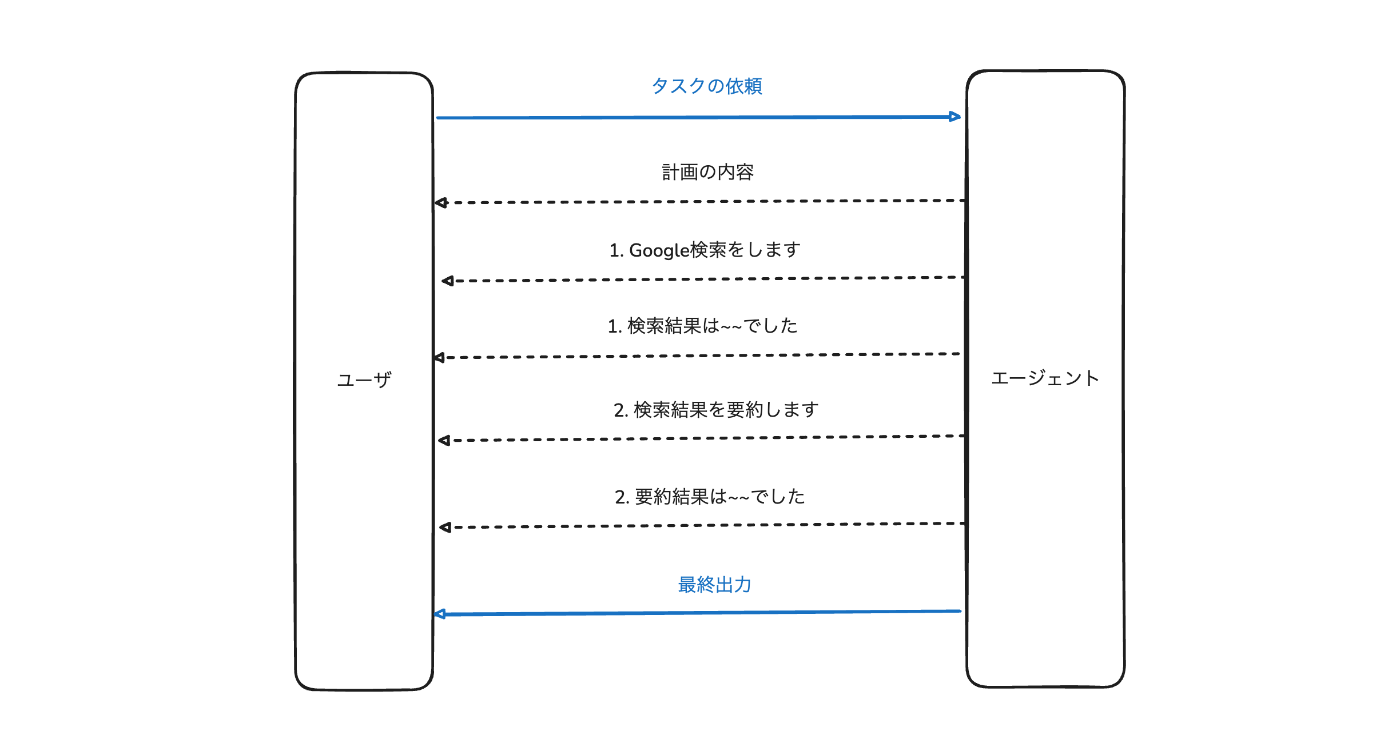
現実の業務においても報連相がしっかりできると上司が安心してタスクを任せられるのと同様で、AIエージェントにおいても報連相を徹底することで、ユーザはエージェントの動作を把握して安心してタスクを任せることができるようになります。
非同期を前提にユーザがサービスを開いていなくても動作を保証する
UXの側面から、ユーザに対して細かいフィードバックをすることが必要であると説明しました。それに加えて必須の要件が「非同期性」であると考えています。
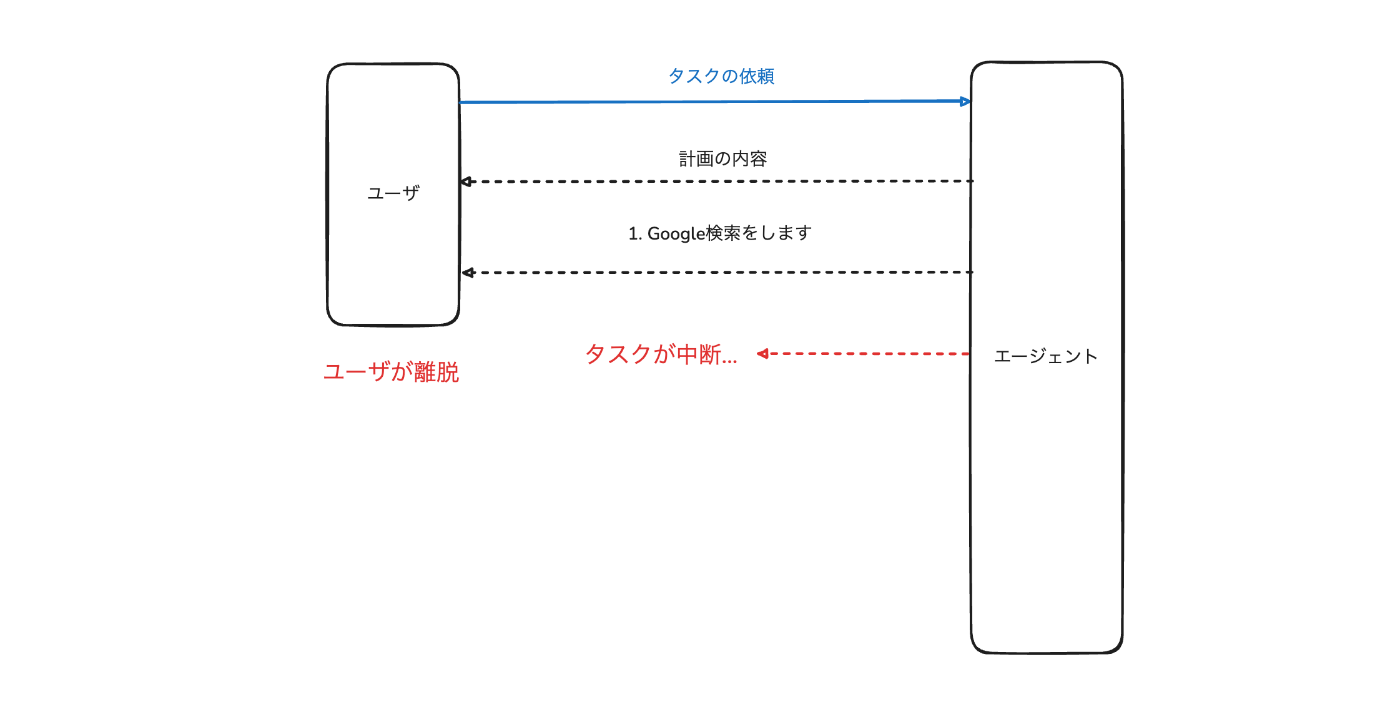
同期的に実装した場合
仮に先ほどのAIエージェントが同期的に実装されていたとします。すると、ユーザがタスクを依頼して、AIエージェントがタスクを開始しても、途中でユーザが離脱した場合そのタスクが中断されてしまいます。
しかし、ユーザがAIエージェントを使う際に常にエージェントを監視するユースケースは少なく、タスクを投げて放置することも往々にしてあります。
だからこそ非同期性は重要であり、その上でユーザに対して細かいフィードバックすることも欠かしてはいけません。
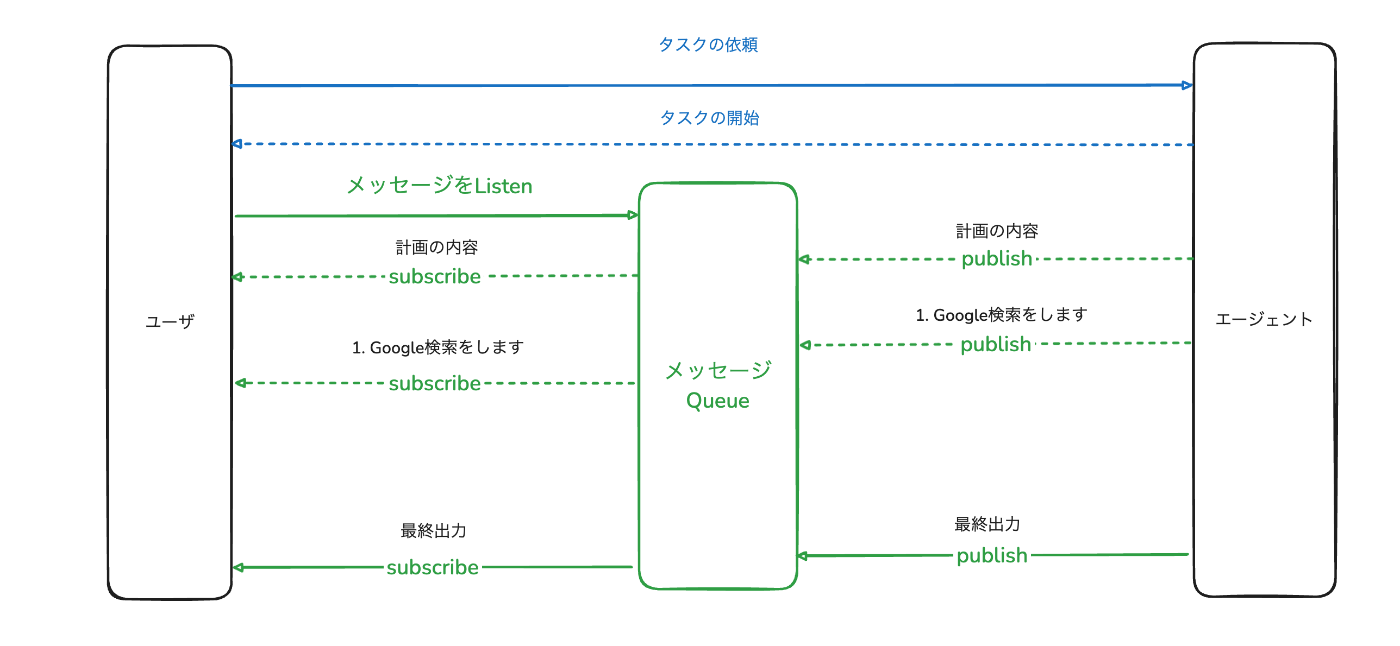
Pub/Subを用いる場合
実装の一例としてユーザとAIエージェントの間にメッセージを受け取るQueueを置いて、常にメッセージをSubscribeするという選択肢があります。
この場合では、以下のような実装フローになります。
- ユーザがタスクを依頼する
- AIエージェントが依頼を受け取り、タスクを開始する
3. それと同時にユーザへタスクを受け取ったことを知らせる - ユーザはメッセージのQueueをSubscribeして、エージェントからのフィードバックを監視する
- AIエージェントは各Stepが実行されるたびにメッセージのQueueにPublishして、ユーザに通知する
このようにすることで仮にユーザが離脱しても非同期でAIエージェントはタスクを継続し、ユーザが復帰したタイミングでメッセージのQueueからフィードバックを受け取ることができます。
具体的な実装は抽象化して説明をしましたが、ここで伝えたいことはAIエージェントが非同期で実行され、ユーザの離脱によってタスクが中断されないことの重要性です。
まとめ
今回はAIエージェントの開発において重要だと考えるポイントを整理しました。AIエージェントはその自律的であるがゆえ、開発者としては適切に制御する必要があります。
そのためにAIエージェントの要素を4つに分解して、各要素を整理しつつテスト可能性について言及しました。また、AIエージェントをシステムの制約に従わせるためには、Agentic Workflowのガードレールの上にエージェントを乗せることで、自律性と制御のバランスを保つことも必要です。
次にUXの観点から大切なポイントとして非同期を前提にした、ユーザへの細かいフィードバックについて解説をしました。AIエージェントが実業務で活躍するためにはこれらのポイントは必要不可欠であると考えています。

Discussion