Reactの技術選定においてルーティングとデータ取得は特に重要な役割を担っています。
もちろんNext.jsやRemixのようなフレームワークを採用すれば、個別のライブラリを追加することなくルーティングからデータ取得までフレームワークが提供するAPIを使って実装することができます。
しかし、AI ShiftのようなBtoBのサービスにおいてはSPAで十分なことがほとんどで、Next.jsなどのフレームワークの採用がtoo muchになりかねません。
この記事は2024年2月時点の技術選定において、TanStack RouterがSPAのルーティングライブラリとして非常に有力な候補であることを紹介します。
はじめに
TanStack RouterとTanStack Queryの採用がSPAアプリケーションにおける最適解の一つになりうることをその特徴と実際の設計例をもとに解説します。
TanStack RouterはSSRの機能も提供しています。しかし、本記事ではSPAで使用されるケースを想定した解説を行います。
また、今回は特にTanStack Routerに焦点を絞り、TanStack Queryに関する紹介は最小限に行います。もしTanStack Queryに関する内容に興味がある方は下記の本にて解説していますのでぜひご覧ください。
対象読者
- ReactでSPAの技術選定を考えている方
- Type Safeな開発体験を求めている方
- Next.jsのようなフレームワークの採用がtoo muchに感じる方
- React + Viteのライブラリを探している方
TanStack Routerについて
TanStack Routerは2023年のクリスマスにversionが1.0になった比較的新しいライブラリです。このTweetに掲載されている動画がまさにその特徴をわかりやすく説明していますので、ぜひ一度ご覧ください。
🐠 型安全でシンプルなルーティング
TanStack Routerの大きな特徴の一つがType Safeであることです。<Link />やuseNavigateを使用した画面遷移をする際にコード補完してくれます。また、パスの補完だけでなくpath paramsやsearch paramsについても型安全に扱うことができるのがとても強力です。
さらに提供されているAPIは非常にシンプルで分かりやすいことも使用していて開発体験が高いと感じる要因の一つです。
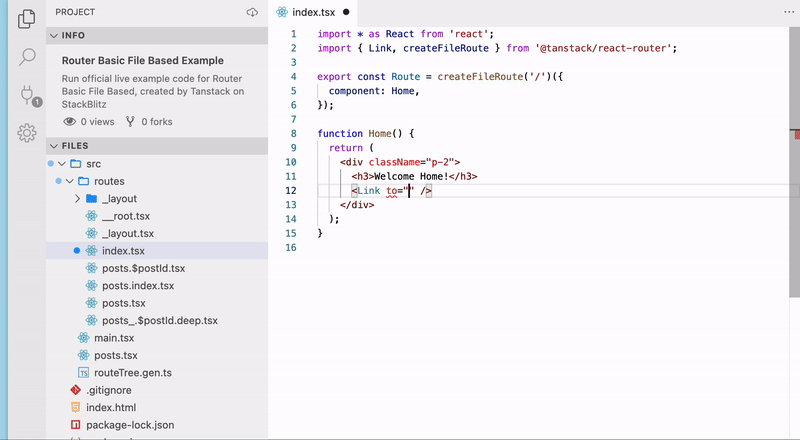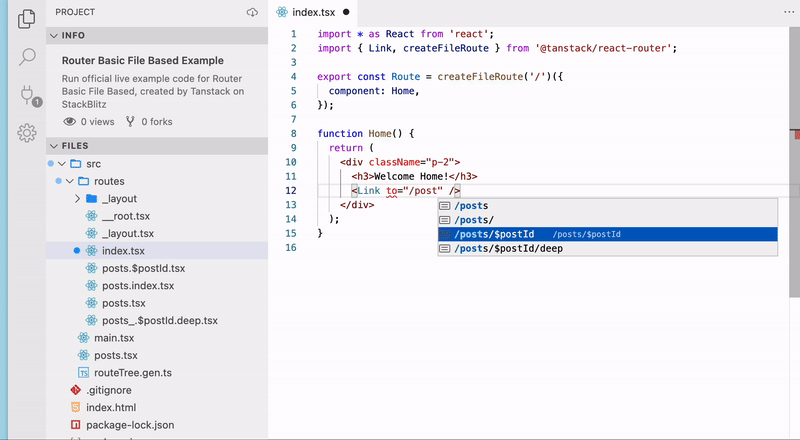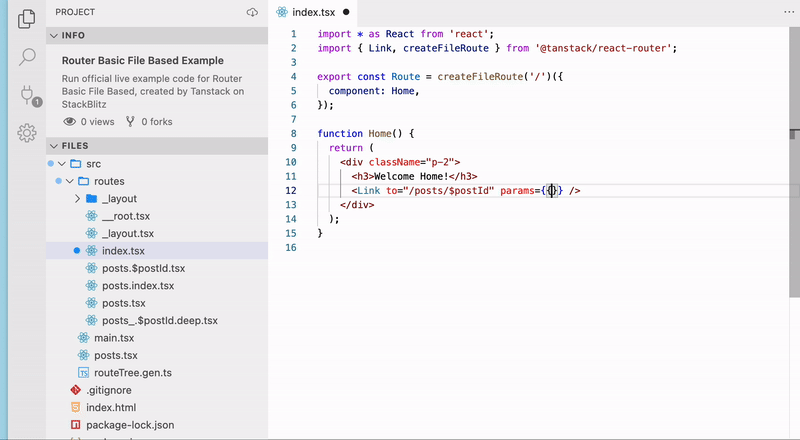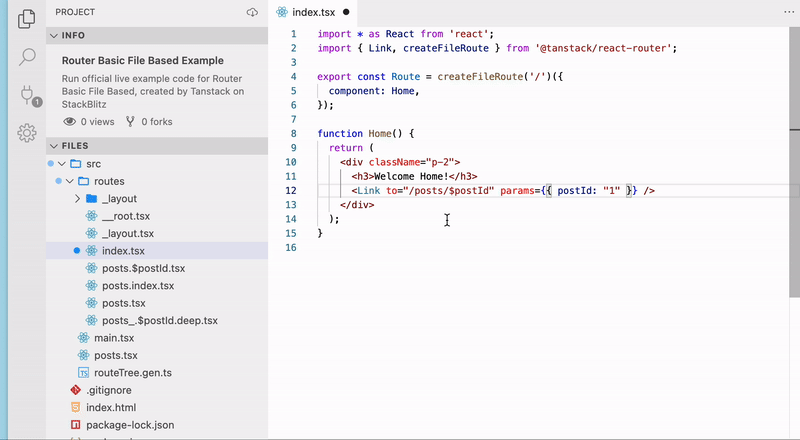
🐳 File-Basedなルート生成
私がTanStack Routerで特に魅力的に感じるのがFile-Basedなルーティングとその自動生成です。つまり、Next.jsのApp RouterやRemixのようにFileによってルーティングを定義することができ、コードベースでルーティングを実装する必要がなくなります。
もちろんコードベースでルーティングを実装することもできますが、公式でもFile-Basedなルーティングを推奨しています。
注)本記事ではFlat RoutesではなくDirectory Routesの形式で紹介を行います。
__root.tsx // rootファイルは全ルートに適用される
posts/
route.tsx // `/posts`
$postId/
route.tsx // `/posts/$postId`
例えば上のようなディレクトリ構成だと、/postsと/posts/$postIdというルーティングが生成されます。また、TanStack Router独自のファイル定義が存在するため、特に重要なものに絞って紹介します。
特殊な役割を持つFile名
__root.tsx
全てのルートに適用されるファイルです。特定のパスを持つことはなく、ここで定義されたcomponentは常にレンダリングされます。
import { createRootRoute } from '@tanstack/react-router'
export const Route = createRootRoute()
また、createRootRouteの代わりにcreateRootRouteWithContextAPIを使用することでDependency Injection(依存性の注入)をすることも可能です。
TanStack QueryのclientをDIする例
import { createRootRouteWithContext, createRouter } from '@tanstack/react-router'
interface MyRouterContext {
queryClient: QueryClient
}
const rootRoute = createRootRouteWithContext<MyRouterContext>()({
component: App,
})
const queryClient = new QueryClient()
const router = createRouter({
routeTree: rootRoute,
context: {
queryClient,
},
})
export const Route = createFileRoute('/todos')({
component: Todos,
loader: ({ context }) => {
await context.queryClient.ensureQueryData({
queryKey: ['todos', { userId: user.id }],
queryFn: fetchTodos,
})
},
})
$token(ex. $postId)
$をprefixに使用するとURL pathnameとして使用されます。また、マッチしたpath paramsはloader関数やコンポーネントの中で参照することができます。
path paramsを扱う例
import { createFileRoute } from '@tanstack/react-router'
export const Route = createFileRoute('/posts/$postId')({
loader: async ({ params }) => {
return fetchPost(params.postId)
},
})
export const Route = createFileRoute('/posts/$postId')({
component: PostComponent,
})
function PostComponent() {
const { postId } = Route.useParams()
return <div>Post {postId}</div>
}
_ prefix
_をprefixに使用した場合はレイアウトルートとして使用され、URL pathnameには反映されません。つまり、以下のようなディレクトリ構成とルーティングの対応になります。
_layout/
layout-a.tsx // → /layout-a
layout-b.tsx // → /layout-b
これによって関心の近いルート同士を凝集させることができます。
RouteOptions type
ルートを作成する際にcreateFileRouteAPIなどを用いますが、そこで扱うことのできるオプションを整理します。ここでは特に解説したいものに絞って行います。
// routes/posts.tsx
export const Route = createFileRoute('/posts')({
component, // skip
loader,
errorComponent,
pendingComponent,
validateSearch,
})
loader
type loader = ({/** 省略 */}) => Promise<TLoaderData> | TLoaderData | void
Remix/React-Routerのloadersに似た機能です。ルートがよばれるタイミングで発火し、失敗した場合はerrorをthrowします。
loaderがPromiseを返却したときにルートはpending状態になり、Promiseが解決するまでレンダリングは中断されます。また、Promiseがrejectされるとルートはエラー状態になります。
errorComponent, pendingComponent
上記のloader関数ではPromiseの状態によってレンダリングが中断されたり、エラー状態になることを説明しました。そこでTanStack Routerでは各ルートごとにerror時、pending時のコンポーネントを定義することができます。
// routes/posts.tsx
export const Route = createFileRoute('/posts')({
component, // 通常コンポーネント
errorComponent, // エラー時のコンポーネント
pendingComponent, // pending時のコンポーネント
})
validateSearch
validateSearchを使用するとsearch paramsをvalidationし、型安全に扱うことができます。また、zodのようなvaliationライブラリとの組み合わせも可能です。
import { z } from 'zod'
const productSearchSchema = z.object({
page: z.number().catch(1),
filter: z.string().catch(''),
sort: z.enum(['newest', 'oldest', 'price']).catch('newest'),
})
type ProductSearch = z.infer<typeof productSearchSchema>
export const Route = createFileRoute('/shop/products')({
validateSearch: (search) => productSearchSchema.parse(search),
})
🦑 バンドルサイズを軽減するCode Splitting
TanStack Routerは組み込みでCode Splitをする機能が備わっています。Code Split(Lazy Loading)する目的は大きく3つあります。
- 初回ページ読み込みに必要なコード量を減らす
- 対象コードが必要になったときに読み込む
- チャンク分割することでより細かい単位でキャッシュを可能にする
Code Splittingする方法
TanStack RouterでCode Splittingする方法はシンプルです。
これにより、Critical RouteとLazy Routeを使い分けることが可能になります。
- Critical Route
- 初回にロードされるコード
- Lazy Route
- 必要になった際に遅延してロードされるコード
では、どのような基準でCode Splitする対象を選択するのがいいでしょうか?TanStack Routerのドキュメント内でその基準が明確化されていました。
Critical Route(route.tsx)の対象
- Path Parsing/Serialization
- Search Param Validation
- Loaders, Before Load
- Route Context
- Meta
- Links
- Scripts
- Styles
- All other route configuration not listed below
Lazy Route(route.lazy.tsx)の対象
- Route Component
- Error Component
- Pending Component
- Not-found Component
loaderはCode Splitの対象ではないのか?
loaderをLazy Routeにしない理由は以下の3つです。
- loaderを対象にするとloader自体のchunkの取得とその実行で2回の往復が必要になる。
- 比較的loaderのコードはサイズが小さいため、バンドルサイズの軽減に貢献しない。
- ルートにとってloaderはpreloadするための重要な要素である。
🦋 Search Paramsによる状態管理
TanStack RouterではSearch ParamsをGlobalな状態と捉え、型安全でValidation可能にする機能を持っています。?page=3や?filter-name=tannerといったsearch paramsは紛れもなくGlobalな状態です。
例えばユーザの目線では以下ケースでも状態が保持されるべきです。
-
Cmd/Ctrl + Clickなどで新規タブを開いた時 - ブックマークやリンクを共有した時
- ページをリフレッシュした時
また、開発者目線では他の状態管理ライブラリのように柔軟で、型安全に、Validation可能にすることでより効率的にsearch paramsを扱うことができます。
なぜURLSearchParamsを使わないのか?
URLSearchParamsには以下の欠点があります。
しかし、search paramsをGlobalな状態と捉えた場合、上記の欠点は大きな課題となります。
これらの課題をTanstack Routerは解決しています。
JSON-first Search Params
TanStack Routerはsearch paramsを構造化されたJSONに自動変換する強力なparserを持っています。つまり、JSONでシリアライズ可能なデータをsearch paramsに使用することができます。
const link = (
<Link
to="/shop"
search={{
pageIndex: 3,
includeCategories: ['electronics', 'gifts'],
sortBy: 'price',
desc: true,
}}
/>
)
// → /shop?pageIndex=3&includeCategories=%5B%22electronics%22%2C%22gifts%22%5D&sortBy=price&desc=true
Validationと型定義
search paramsのvalidationと型定義はcreateFileRouteAPIのvalidateSearch optionを使用します。これによりコンポーネントでsearch paramsを取得・操作する際に型安全に扱うことができるようになります。
// /routes/shop.products.tsx
type ProductSearchSortOptions = 'newest' | 'oldest' | 'price'
type ProductSearch = {
page: number
filter: string
sort: ProductSearchSortOptions
}
export const Route = createFileRoute('/shop/products')({
validateSearch: (search: Record<string, unknown>): ProductSearch => {
// validate and parse the search params into a typed state
return {
page: Number(search?.page ?? 1),
filter: (search.filter as string) || '',
sort: (search.sort as ProductSearchSortOptions) || 'newest',
}
},
})
🦆 キャッシュを備えたData Loading
TanStack Routerは単純なloaderの役割を超えて、インメモリに保存されるSWRキャッシングの機能を備えています。この機能によってデータをpreloadしてキャッシュしたデータを表示したり、以前取得したデータをキャッシュして再度使用することができます。
Dependency-based Stale-While-Revalidate Caching
キャッシュはルートのdependenciesによって制御されます。ここでいうdependenciesとは以下の要素です。
キャッシュの制御
TanStack RouterのキャッシュはTanStack Queryと似ており、TanStack Queryに慣れている人であれば学習コストを低く扱うことができます。
-
staleTime
- キャッシュしたデータをstale状態にするまでの時間。
- defaultは
0
-
gcTime
- 使用されなくなったキャッシュを破棄するまでの時間。
- defaultは
30 min
loaderDepsを用いたsearch paramsへのアクセス
search paramsは通常loaderAPIの中で直接参照することができません。これはTanStack Router側が意図した挙動です。
先ほどのDependency-based SWR Cachingの項目でキャッシュはルートのパス名とloaderDepsによって提供された追加の依存要素によって制御されることを説明しました。
つまり、私たちがsearch paramsを直接loader内で参照した場合、TanStack Rotuerはsearch paramsを使用した際のキャッシュを識別することができなくなります。例えば、/postsと/posts?page=1のキャッシュは同一のものと認識してしまいます。
そのため、search paramsとloaderの間で依存関係を明確にすることでキャッシュによるバグを防ぐことが必要です。
// /routes/users.user.tsx
export const Route = createFileRoute('/users/user')({
validateSearch: (search) =>
search as {
userId: string
},
loaderDeps: ({ search: { userId } }) => ({
userId,
}),
loader: async ({ deps: { userId } }) => getUser(userId),
})
TanStack QueryのSuspense
今までTanStack Routerの解説を行ってきましたが、ここでTanStack Query v5からstableになったsuspense機能について触れたいと思います。
通常のuseQueryとuseSuspenseQueryの大きな違いはdataがundefinedな状態を考慮する必要がなくなったことです。
私たちはTanStack Queryを使用する際、dataが存在しない場合はpendingComponentを表示し、エラーが発生した場合はerrorComponentを表示する実装を行っていました。以下のコードがその例です。
通常のuseQueryを使用した例
function Todos() {
const query = useQuery({ queryKey: ['todos'], queryFn: getTodos })
if (query.status === "pending") {
return <Pending />
}
if (query.status === "error") {
return <Error />
}
return (
<div>
Todo Items
</div>
)
}
しかし、useSuspenseQueryを使用した場合、dataがundefinedな状態を考慮する必要がなくなるため、以下のコードのように変わります。
function Todos() {
const { data } = useSuspenseQuery({
queryKey: ['todos'],
queryFn: fetchTodos,
})
// 🎉 no need to handle loading or error states
return (
<div>
{ /* TypeScript knows data can't be undefined */ }
{data.map((todo) => (
<div>{todo.title}</div>
))}
</div>
)
}
function App() {
// 🚀 Boundaries handle loading and error states
return (
<Suspense fallback={<div>Loading...</div>}>
<ErrorBoundary fallback={<div>On no!</div>}>
<Todos />
</ErrorBoundary>
</Suspense>
)
}
今までstatusが"pending"と"error"の状態をそれぞれComponent内で処理する必要があったところから、それぞれ関心を切り出して管理することができるようになりました。
- pending状態
- Suspenseのfallback
- error状態
- ErrorBoundaryのfallback
ここでお気づきの方もいるかもしれませんが、この関心の切り分けはTanStack RouterのFile-Basedなアプローチととても相性がいいです。TanStack Routerでは各ルートごとにcomponent, pendingComponent, errorComponentを定義することができました。
export const Route = createFileRoute('/posts')({
component, // 通常コンポーネント
errorComponent, // エラー時のコンポーネント
pendingComponent, // pending時のコンポーネント
})
つまり、component内で使用したuseSuspenseQueryのpending状態とerror状態の処理をTanStack Routerのルート単位で設定することができるのです。
loaderかTanStack Queryどちらを使う?
TanStack Queryのsuspense機能がTanStack Routerと相性がいいことを説明しました。しかし、データ取得という観点ではTanStack Routerのloaderでも可能ですし、SWRキャッシュの機能も持っています。
では、これらをどのように使い分ければいいのでしょうか?
公式のドキュメントにてTanStack RouterのCacheのメリット/デメリットが記載されていました。
TanStack Router Cacheのメリット
- 組み込みで使いやすい
- ルートごとに重複排除、プリロード、ローディングなどの処理が可能
- 自動的なガベージコレクション対応
TanStack Router Cacheのデメリット
- 永続化のためのアダプターやモデルがない
- ルート間でのキャッシュの共有や重複排除がない
- 更新系のAPIがない
そのため、アプリケーションの状態管理としてTanStack Queryの存在は必要であり、TanStack Routerとうまく組み合わせることが求められます。
キャッシュデータをpreloadする
TanStack Routerは組み込みでpreloadの機能を持っています。例えば、<Link>で画面遷移をしようとユーザがリンクをhoverすると、そのルートで必要なデータを事前読み込みしてくれます。
この機能は非常に強力であり、TanStack Queryと組み合わせることでデータ取得を効率的にし、時にはwaterfall問題を解消してくれます。
実際のコード例は以下の通りです。
TanStack Routerのloaderでデータを事前に用意してTanStack Queryのキャッシュに保存します。そのため、useSuspenseQueryが呼ばれるタイミングではデータが確保された状態になります。
// src/routes/posts.tsx
const postsQueryOptions = queryOptions({
queryKey: 'posts',
queryFn: () => fetchPosts,
})
export const Route = createFileRoute('/posts')({
// Use the `loader` option to ensure that the data is loaded
loader: () => queryClient.ensureQueryData(postsQueryOptions),
component: () => {
// Read the data from the cache and subscribe to updates
const posts = useSuspenseQuery(postsQueryOptions)
return (
<div>
{posts.map((post) => (
<Post key={post.id} post={post} />
))}
</div>
)
},
})
TanStack Routerのディレクトリ設計
これまでTanStack Routerの特徴とTanStack Queryとの相性の良さについて解説してきました。最後に、AI Shift内でも運用しているTanStack Routerのディレクトリ設計について紹介し、その特徴とメリットについて解説します。
以下のようなディレクトリ設計です。
.
├── __root.tsx // root file
├── posts
│ ├── -components // 🐢 ルート内で使用されるUIコンポーネント
│ ├── -api // 🦋 ルート/内で使用されるAPI通信Hooks
│ ├── -types // 🐠 ルート内で使用される型定義
│ ├── -functions // 🦐 ルート内で使用される関数
│ ├── route.lazy.tsx // 🐕 Lazy Routeの対象
│ ├── route.tsx // 🦈 Critical Route
│ └── $postId // posts/と同様
│ ├── -components
│ ├── -api
│ ├── -types
│ ├── -functions
│ ├── route.lazy.tsx
│ └── route.tsx
route.tsx
export const Route = createFileRoute('/posts/$postId')({
validateSearch: (
input: {
postId: number
color?: 'white' | 'red' | 'green'
} & SearchSchemaInput,
) =>
z
.object({
postId: z.number().catch(1),
color: z.enum(['white', 'red', 'green']).catch('white'),
})
.parse(input),
loaderDeps: ({ search: { postId } }) => ({
postId,
}),
loader: ({ deps: { postId } }) => fetchPost(postId),
})
route.lazy.tsx
export const Route = createLazyFileRoute('/posts/$postId')({
component: PostComponent,
errorComponent: PostErrorComponent,
notFoundComponent: PostNotFoundComponent,
})
特徴1. feature-basedなディレクトリ構成になる
上記の例では各ルート内に以下のディレクトリを配置しました。
-
-components
- ルート内で使用されるUIコンポーネント
-
-api
- ルート内で使用されるAPI通信のためのHooks
- TanStack QueryなどのAPIはここで使用する
-
-types
- ルート内で使用される型定義
-
-functions
- ルート内で使用される関数
- 各関数ごとに単体テストを実装する
これによって、topの階層にcomponentやapiなどのディレクトリを配置するlayer-basedなアプローチではなくfeature-basedな設計に対応することができます。
もちろん全てのfeatureがルートと一致するわけではありませんので、そのような場合には_prefixを使用して関心をまとめるのも一つの手段かもしれません。
特徴2. Route Hooksの使用が対象のルート内に限定される
TanStack Routerでは各ルートごとに対応したRouteのHooksを使用することで型安全にpath paramsやsearch paramsを扱うことができます。
export const Route = createFileRoute('/posts/$postId')({
component: PostComponent,
})
function PostComponent() {
const { postId } = Route.useParams()
return <div>Post {postId}</div>
}
上記のディレクトリ設計のようにルートの中で使用されるコンポーネントが閉じている場合、/posts以下では当然/postsに対するRoute Hooksが使用されることがわかります。
では、仮にlayer-basedなディレクトリ構成を考えてみます。
.
├── pages
├── components
│ ├── Post.tsx // /postsのRoute Hooksが使われる???
│ ├── Todo.tsx // /todosのRoute Hooksが使われる???
│ ├── Form.tsx // ???
│ └── Card.tsx // ???
少し極端な例かもしれませんが、上記のようなトップ階層にcomponentsを配置する設計ではどこでどのRoute Hooksが使用されているのかが判断できません。
.
├── posts
│ ├── -components // /postsのRoute Hooksが使用される
│ │ ├── Card.tsx
│ │ └── Form.tsx
│ └── $postId
│ └── -components // /posts/$postsIdのRoute Hooksが使用される
特徴3. Suspenseの境界が明確になる
TanStack QueryのuseSuspenseQueryを使用すると、pending状態とerror状態の関心を外に切り出して、component側ではdataのundefiendなケースを想定する必要がなくなることを解説しました。
改めてTanStack Routerとの相性がいい理由として、ルートごとにpendingComponentとerrorComponentが定義できることから、Suspenseの境界を独自に定義する必要がなくなることがあります。
TanStack Routerのドキュメントに掲載されているサンプルを参照します。

上の画像では、赤枠と青枠でそれぞれSuspense境界が存在します。つまり、青枠で発生したpendingとerror状態は/post/$postIdのルートで定義した処理を、赤枠で発生したpendingとerror状態は/postsのルートで定義した処理を実行させることができるのです。
(↓は実際のコード例)
まとめ
今回はTanStack Routerの特徴とTanStack Queryと相性がいいことを解説し、最後にディレクトリ設計を紹介しました。Next.jsやRemixなどフレームワークの進化が目覚ましい一方で、ReactでSPA開発をする際の課題がなかなか解決されていない感覚がありました。
しかし、今回紹介したTanStack RouterのFile-BasedでDXの高いアプローチはReactのライブラリ選定において有効な選択肢になるのではないでしょうか。

Discussion
tanstack-routerのdiscussionにあるように、pathやparamではないstate(HistoryState)を
型安全に渡したい場合、型定義をglobalに定義する必要があり、propsが必要ない箇所でも汚染するのと、interfaceが肥大化してしまうと思うんですが、この辺りって何かうまく対応されていたりしますか?
コメントいただきありがとうございます!
TanStack Routerでhistory stateを活用するケースにまだ遭遇していなかったため、私なりの回答を持っておらず申し訳ありません。
こちらはおっしゃる通りかなと思っており、添付いただいたDiscussionによると、v2でRouteごとにstateを定義できるよう改善する方向が示されていますね。
v2でrouteごとにstateが定義できればglobalな型定義やinterfaceの肥大化も一定防げるのかなと感じました👀
返信ありがとうございます!
ということは、ページを跨いで値を受け渡しするときは
Path Params と Search Paramsを使い、それ以外は利用していない。ということでしょうか?
現時点ではPath ParamsとSearch Paramsでルーティングに関心のある状態は管理できていますね...
その上でGlobalに状態を管理したい場合はJotaiなどのライブラリを別途採用しています
(回答になっていたら幸いです!)