Webブラウザとクラウドサービスを使った遠隔仮想環境でゲーム用の低予算バックエンドを拵える話 (その4)
概要
ネットワークの事前知識がそれほどない(これから勉強していきたい!)という前提で、ゲームにネットワークの要素をなんとか低予算で導入したいと考えている方に向けて、地道に進めるバックエンド環境構築例を紹介します。途中、以下のサービスやテクノロジーが登場します。(記載内容は2021年10月中旬時点の情報となります)
- Google Cloud Platform(以下、GCP), Google Compute Engine(以下、GCE), Cloud Shell, Cloud Shell Editor
- Linux, Debian
- PostgreSQL, PhpPgAdimin, SQL
- Node.js, Expressフレームワーク, fsモジュール, node-postgres(pg)モジュール
- HTTP, HTTPS
実現すること
- 手元の開発環境(PC,ネットワーク)の影響を極力受けない状態でバックエンドを用意する(Webブラウザ=HTTP,HTTPSのみ、SSHクライアントは使用しない)
- アプリケーションサーバ(Webサーバ+サーバサイド言語処理環境)を用意する
- データベースサーバを用意する
- 各サーバ用のデータ作成とデータ編集が行える環境を整える
- お金(費用)はなるべくかけない
作業のステップ
作業をいくつかのステップに分け、順番に紹介してきます。
- 事前準備+GCEで遠隔仮想環境を構築
- テキスト編集環境を用意する
- アプリケーションサーバを用意する
- データベースサーバを用意する
- 取り回しの良さを向上させる
4回目の今回は「データベースサーバを用意する」編となります。
おさらい
仮想環境にNode.jsをインストールし、通信用のモジュールを加えた簡素なプログラム処理(アプリケーション)を実装したことにより、即座にアプリケーションサーバを実現することが出来ました。
ここまで構築されたものでゲーム用のバックエンドを実現することも出来ますが、もう一歩踏み込んでデータベースサーバを実現する部分にまで手を出していきましょう。
データベースサーバ
「データベース」とは大量のデータを効率的に記録し、必要な時に必要なデータを素早く取り出すことのできる技術のことを指します。データベースサーバは、データベースの機能を持ったサーバということになるわけですが、それをすることに一体どんなメリットが存在するのでしょう?
なぜサーバにデータベースなのか
ゲームを例に挙げると、大量の所持アイテムやモンスターの情報や各種パラメーターなどが存在するため、ユーザに近い「クライアント」がデータベースを持っていても問題はなさそうです。ではなぜ開発者側に近い「サーバ」にデータベースの機能を持たせるのでしょう? 理由は様々ですが、総じて「そうするだけのメリットがあった」からだったと考えることが出来ます。以下に筆者が知るいくつかのメリットを紹介します。
| 理由 | メリット |
|---|---|
| データを一箇所にまとめられる | 管理が楽になる データの重複、不足を気にしなくて良くなる |
| 管理側でデータを保護できる | 他人(クライアント)が勝手に中を変更出来ない 緊急事態が起きた時に停止できる |
| 管理側でデータを操作できる | 緊急事態が起きた時にデータを確認できる 緊急事態が起きた時にデータを変更できる 緊急事態が起きた時にデータを遡って元に戻すことができる |
ゲームに関して言えば、データベースサーバを実現していることで次のようなトラブルによる被害を軽減することができると考えられます。
- ユーザーのチート行為(異常な強化、アイテム複製、ゲーム内通貨複製)
- アイテム配布のミス
- ゲームバランスを破壊するアップデート
データベースの種類
データベースはざっくりと、2極化しています。
| 種類 | 特徴、製品例 |
|---|---|
| リレーショナル型 | 現在、最も広く用いられているデータベース。 行列(表)構造を持つ複数のテーブルにデータを分けて記録。 シェアが非常に高く、同じリレーショナル型の データベースであれば似ている操作も多い。 製品としては次のものが有名。 Oracle MySQL Microsoft SQL Server |
| リレーショナルでない型 | 様々な種類のデータベースが存在する。 それぞれのデータベースが独自設計をしているケースが高く、 それ専用で学習する必要が出てくる。 製品としては次のものが有名。 MongoDB Redis |
当記事では、応用の利くリレーショナル型でかつ無料利用が可能な「PostgreSQL」を紹介します。
PostgreSQL
PostgreSQL(ポストグレス キューエル)は象のアイコンが特徴的なオープンソースソフトウェアの「リレーショナル型データベースマネジメントシステム(RDBMS)」です。「マネジメントシステム」の言葉がくっついていますが、これはデータベースを操作しやすくするための「管理機能」が付与されているというもので、近年ではどのデータベースにも当たり前のように付与されています。
PostgreSQLはWindows,Mac,Linuxの各種OSで動作し、多くのアプリケーションやWebサービスでの採用実績があります。
インストール
早速、PostgreSQLを仮想環境にインストールしていきましょう。公式を踏襲しつつも、GCEで構築した仮想環境のインストール内容に合わせて次の手順でインストールを進めると良いでしょう。
sudo apt-get update
仮想環境内にプリインストールされているソフトウェアを更新します。仮想環境を構築後に初めて実行する場合は、5分〜10分ほどかかるかもしれません。
sudo apt-get install -y wget
wgetと呼ばれるソフトウェアをインストールします。この後、実行するコマンドに必要となります。
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get -y install postgresql
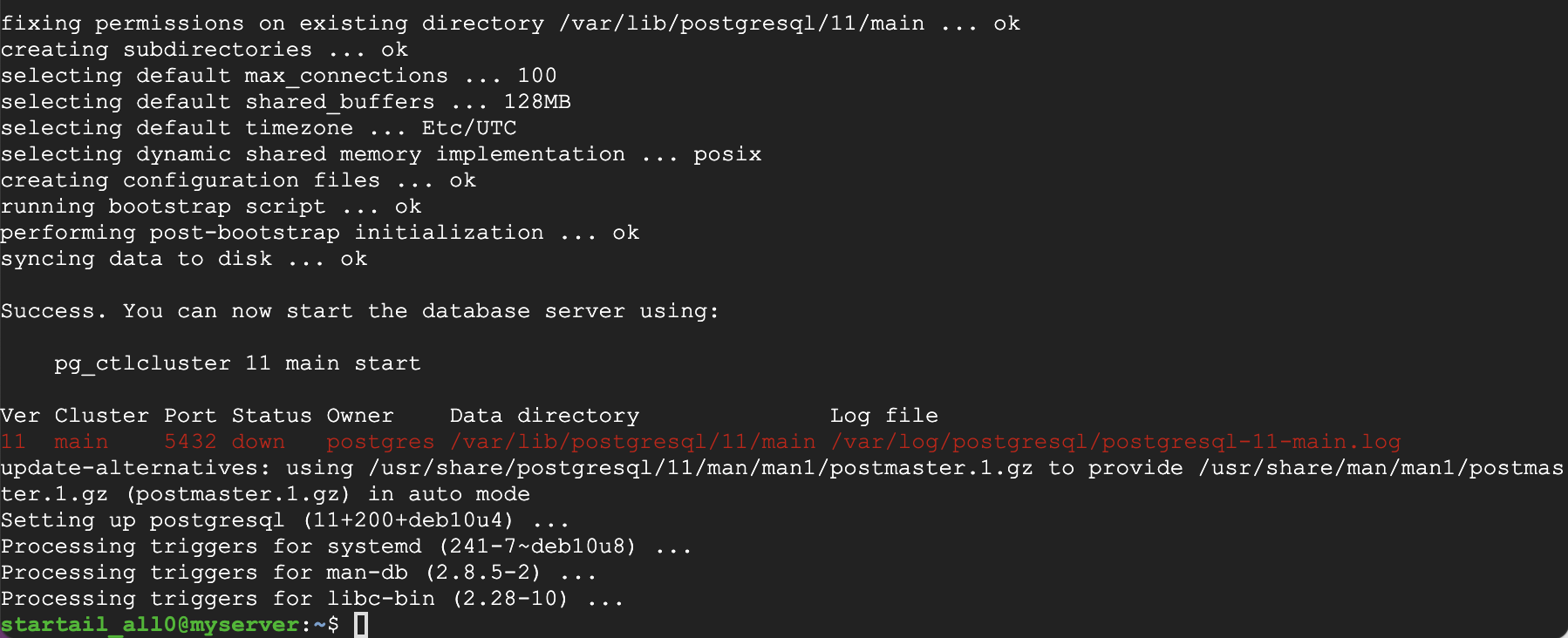
色々なインストール作業の末、画面にSuccessの文字が見えれば成功です
インストールがきちんと行えたかどうかは、psqlコマンドが利用できるようになったかどうかでわかります。以下のコマンドを入力してPostgreSQLのバージョンが表示されるかどうか確認してみましょう。
psql --version
筆者の環境では、 「psql (PostgreSQL) 11.13 (Debian 11.13-0+deb10ul)」と表示されました。
基本設定と事前準備
データベースを使い始める前にいくつか設定を行う必要があります。
データベース操作用のアカウントを制御する
PostgreSQLをインストールすると、自動でデータベースを操作する用のアカウントがDebian上に追加されます。
アカウント
「アカウント?なんのこと?」と、感じてる方もいると思います。以前、sudoコマンドの扱いについて注意を促したことを覚えているでしょうか?まだデータベースに大事な情報を入れてはいませんが、データベースをビジネスで利用するケースでは、他者に見られたり覗かれたりすると困るデータを入れるというケースもあります。データベースを操作する時は、操作者がどのような権利を持ったユーザーであるのかはっきりと制御する必要があるわけです。
Debian(Linux OS)には元々、CUIを操作している人物を把握するために「アカウント」という仕組みが存在します。アカウントは大きく分けると、次の2種類に分けられます。
- rootアカウント(スーパーユーザーとも呼ぶ。管理者権限をもつ。)
- 一般アカウント
仮想環境(Debian)起動時は通常、一般アカウントでログインして利用します。コマンドを入力する時、入力場所の左側に表示される文字列が気になったことはありませんか? それには次の意味があります。
startail_all0@myserver:~$
| 表示例 | 意味(役割) |
|---|---|
| startail_all0 | あなたのアカウントの名称。記載の文字は人によって異なります。 表示例は著者のもの |
| myserver | このコンピュータ(仮想環境)の名称 |
| ~ | 現在見ているフォルダ。 ~は一般ユーザーのデフォルトフォルダ(homeフォルダ)を指す特別な記号 |
| $ | 一般ユーザーであることを表す記号 rootユーザーの場合は#マークに表示が変わる |
データベース操作用のアカウントに切り替える
前述したように、PostgreSQLをインストールすると新しい一般ユーザー「postgres」が追加されています。
まず、アカウント「postgres」の権限をデフォルトのアカウント並に引き上げます。これは今後データベースを操作する際に、このアカウント「postgres」を使用するためです。
sudo gpasswd -a postgres sudo
続けて、新しく追加されたアカウント「postgres」にはデフォルトでパスワードが設定されていますが、そのままだとセキュリティ的な意味合いで危険となりますので、このパスワードを次のコマンドを入力することで別のものへと変更します。
sudo passwd postgres
コマンドをEnterキーで確定すると、続け様に「New password:」という文字と点滅するカーソルが表示されるので新しいパスワードを入力します。注意が必要なのが、「入力経過が目に見えない」ことです。どこまで入力したかわからなくなった場合は、バックスペースキーなどを連打して文字を全部消し切れたと思ったところから再度入力してみると良いでしょう。新しいパスワードは再入力を求められるので、同じパスワードを再度入力します。「passwd: passwords updated successfully」と表示されれば問題ありません。(パスワードはしっかり覚えておきましょう!)
続けて、現在のアカウントから新しいアカウントに切り替えるコマンドを入力します。
su - postgres
パスワードの入力を求められますので、先ほど作った新しいパスワードを入力してください。コマンド欄のアカウント名が次のサンプルのように変わっていれば成功です
postgres@myserver:~$
ちなみに、元のアカウント(例:postgres→startail_all0)に戻る場合は、次のようにexitコマンドを入力しましょう。
exit
データベースにログインする
続けて、データベースにログインを行います。postgresアカウントであることが間違いない状態で次のコマンドを入力します。
psql データベース名
データベース名 の部分には作成済のデータベース名を指定しますが、インストールしたばかりなので「デフォルトのデータベース」しか用意されていません。次のコマンドを入力することで仮想環境内に存在するPostgreSQLのデータベースを確認することができます
psql -l
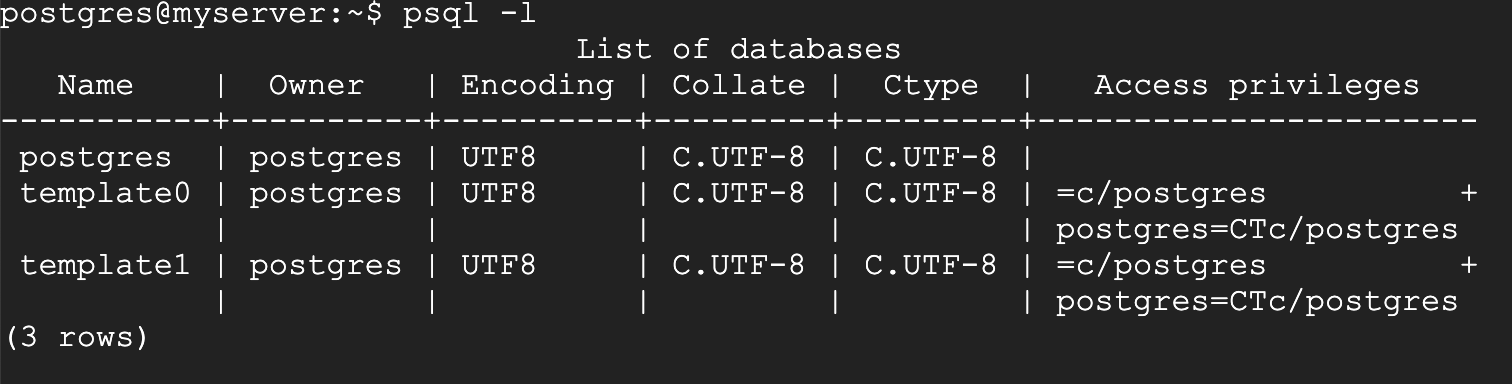
デフォルトで作成されているデータベースの一覧
今回は、デフォルトで作成済の中からデータベースpostgresへログインします。
psql postgres
このコマンドを入力すると、CUIの表示が次のように若干変化します。これがデータベースにログインした状態です。
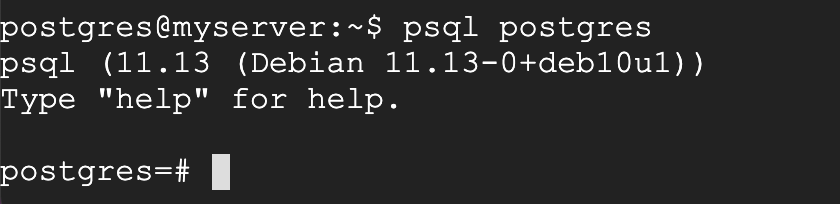
PostgreSQLのデータベースpostgresにログインできたところ
過去の例でいえば、テキストエディタを起動した時と同じような状態です。(テキストエディタの場合はDebianのCUI画面が全部隠れていましたが、こちらは全部隠れない仕様です)
データベースからログアウトしたい(ソフトウェアを終了したい)場合は、「postgres=#」に続けて、次のようなコマンドを入力します。
quit;
データベースユーザーのパスワードを設定する
さて、データベースにログインできたところでもう一つ実施すべき作業があります。それは、「パスワードを設定する」ことです。
少しややこしいのですが、現在「Debianのpostgresアカウント」から「postgresと呼ぶ名称のデータベース」へ「デフォルトのデータベースユーザーpostgresがログインしている」状態です。整理すると、次の通りです。
| 登場したpostgres達 | 詳細 |
|---|---|
| アカウントの "postgres" |
PostgreSQLインストールによって追加されたOSのアカウント。 先ほどパスワードを設定した。 |
| データベースの "postgres" |
デフォルトで作成されていたデータベース。 他のデータベース作成などもこのデータベースにログインしている状態から行う。 |
| データベースユーザーの "postgres" |
PostgreSQLを利用するためのユーザーのひとつ。 初回ログインする際にデフォルトユーザーとして設定されている。 データベース全ての管理権限を持つ。 これからパスワードを設定する。 |
今回設定するのは、PostgreSQLのデータベースユーザー"postgres"のパスワードです。
今後このデータベースは、Node.jsをはじめとした”外部”から制御する予定です。OSのアカウントとしてのアクセスではなく、データベースというソフトウェアへ直接アクセスすることを想定しているため、「データベースユーザーpostgresのパスワード」がセキュリティ上必要になります。
ログインは既に行なっていますので、「postgres=#」に続けて以下のコマンドを入力します。
ALTER USER postgres with password '任意のパスワード';
任意のパスワード の部分は好きな英数字のパスワードにしてください。(半角のシングルクォーテーションで必ず挟んでください)
これで、「データベースユーザーpostgresのパスワード」の設定が済みました。
テーブルの設計をする
ここからは、実際のデータを格納する手順です。(新しくデータベースやデータベースユーザーを作成する方がセキュリティ的に好ましいのですが、説明を簡素にするため省略します。)
最初のステップは、格納したいデータ(例:アイテムマスター)をイメージして次のような表(縦と横のマス目、行列構造)を思い浮かべます。ノートに書き出したり、Excelなどの表計算ソフトを使って整理します。
多くのリレーショナルデータベースでは、次のルールでデータを整理します。
- 先頭の行は、各列にどんな情報が格納されるかの目安である名称(例:id)が記載されている
- 列に同じ形式の情報を記述する(例:nameの列は、「アイテム名」を必ず文字で書いている)
- 行にひとつのデータの塊を記述する(例:idが3の行は「ミスリル」に関する情報をまとめている)
| id | name | detail | weight | rarity |
|---|---|---|---|---|
| 1 | 綺麗なメダル | 熱狂的なコレクターがいる | 0.1 | 5 |
| 2 | アイアンソード | 切れ味はまぁまぁの鉄の剣 | 10.0 | 1 |
| 3 | ミスリル | 高い耐久性を持つ鉱物 | 1.0 | 2 |
| 4 | 魔法のスクロール | 魔法を封印した魔法紙 | 2.5 | 2 |
| 5 | 魔法石 | 魔法を封印した石。ほのかに温かい | 4.0 | 3 |
リレーショナル型データベースでは、このように格納したいデータを表に整理したものを「テーブル」と呼び、テーブルにデータを追加したり、複数のテーブルで連携することで効率的なデータの制御を実現します。
それでは上記のテーブル設計をもとに仮想環境(データベースにログインしている状態)で様々な操作を行なっていきましょう。
テーブルを作成する
続いてのステップは、「テーブルを作成する」です。「テーブルを作成する」といっても先ほど設計した表の内容を丸々一度にドカっ!と実現するわけではありません。「ファイルを新規作成する」感覚に近いです。
データベースにログインしている状態で次のようなコマンドを入力します。
CREATE TABLE テーブル名(
1列目の名称 データ型,
2列目の名称 データ型,
・・・(略)・・・
最後の列の名称 データ型
);
「データ型」とは、データの種類を表すキーワードです。(各種プログラミング言語に存在するデータ型とほぼ同じです)。詳しく知りたい方は、是非PostgreSQLの日本語ドキュメントなどを参考にしてください。一部抜粋します。
| データ型 | 説明 |
|---|---|
| bytea | バイナリデータ(「バイトの配列(byte array)」) |
| integer | 4バイト符号付き整数。int,int4と記載可能。 |
| real | 単精度浮動小数点(4バイト)。float4と記載可能。 |
| text | 可変長文字列 |
| timestamp | 日付と時刻。例:'1999-01-08 04:05:06' |
前述のアイテムマスターを実現するために実際に入力したものが以下になります。
CREATE TABLE item_master(
id integer,
name text,
detail text,
weight real,
rarity integer
);
1行目の行末(CREATE TABLE item_master(の直後)でEnterキーを押すと左端に自動で添えられている「postgres=#」の文字列が「postgres(#」に変更しますが、問題ありませんので最後まで1行づつEnterキーで改行しながら入力を進めてください。
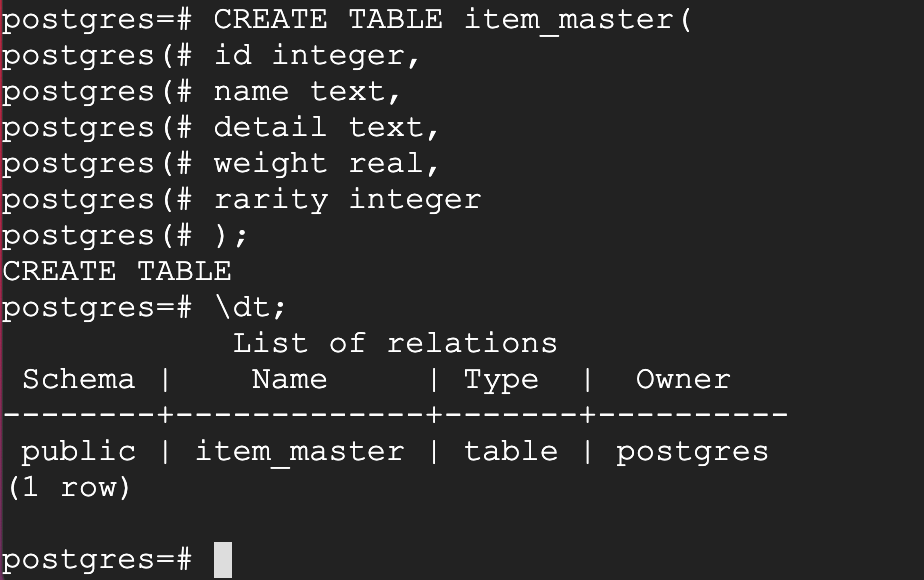
図にも表示されていますが、データベースにログインしている状態で「\dt;」と入力すると現在作成済のテーブル一覧が確認可能です。(悲しいことに筆者のMac環境ではDebian上で半角バックスラッシュが一発で打てない・・・)
これで、テーブルの外枠が形になりました。
データを格納する
続けて、作成されたテーブルに中身を格納していきます。次のコマンドを入力します。
INSERT INTO テーブル名 (列名1, 列名2, ・・・略・・・, 最後の列名) VALUES (列名1のデータ型に合うデータ, 列名1のデータ型に合うデータ, ・・・略・・・, 最後の列のデータ型に合うデータ);
前述のアイテムマスターを実現するために実際に入力したものが次になります。(アイテムが4種類あったので、4回繰り返しています)
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES (1, '綺麗なメダル', '熱狂的なコレクターがいる', 0.1, 5);
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES (2, 'アイアンソード', '切れ味はまぁまぁの鉄の剣', 10.0, 1);
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES (3, 'ミスリル', '高い耐久性を持つ鉱物', 1.0, 2);
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES (4, '魔法のスクロール', '魔法を封印した魔法紙', 2.5, 2);
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES (5, '魔法石', '魔法を封印した石。ほのかに温かい', 4.0, 3);
実は、次のように省略して記述することも可能です。
INSERT INTO item_master (id, name, detail, weight, rarity) VALUES
(1, '綺麗なメダル', '熱狂的なコレクターがいる', 0.1, 5),
(2, 'アイアンソード', '切れ味はまぁまぁの鉄の剣', 10.0, 1),
(3, 'ミスリル', '高い耐久性を持つ鉱物', 1.0, 2),
(4, '魔法のスクロール', '魔法を封印した魔法紙', 2.5, 2),
(5, '魔法石', '魔法を封印した石。ほのかに温かい', 4.0, 3);
テーブル作成時と同様に記述が複数行にわたるときは、Enterキーを押すたびに左側に「postgres-#」が挿入されますが特に問題はありません。
データの格納に成功すると、「INSERT 0 5」と表示されます。

筆者環境でのINSERT INTO処理の様子
筆者の環境では日本語入力に問題があったのか、表示が少し変です。データを格納する作業は少し大変ですが、これは後ほど外部と連携することで解決します。
データを更新する
続けて、格納していたデータにミスや変更があった場合に修正を行う方法を紹介します。
次のコマンドを入力してデータを更新してみましょう。
UPDATE テーブル名 SET 変更内容 WHERE 変更対象行の情報;
前述のアイテムマスターの内容を変更する場合は、次のようにします
UPDATE item_master SET name='小さなコイン' WHERE name='綺麗なメダル';
他にも、「変更内容」と「変更対象行の情報」を上手に指定することで、まとめて一度に更新を行う手法も存在します。以下に例を紹介しますが、やり方が気になる方は調べてみてください。
UPDATE item_master SET weight=12.0, rarity=3 WHERE id=2;
UPDATE item_master SET weight=1.5 WHERE rarity<3;
それぞれの更新処理を実行すると、結果として更新された行数が表示されます。例えば、最後の2つの更新作業の結果は次のように表示されます。

筆者環境でデータ更新を行なった結果
データを削除する
不要なデータのまとまりを削除したい時もあると思います。次のコマンドを入力することでデータを削除することが可能です。なお、誤って必要なデータを削除しないように慎重に実施してください。
DELETE FROM テーブル名 WHERE 削除対象行の情報;
前述のアイテムマスターを利用して実際に入力したものが以下になります。
DELETE FROM item_master WHERE id = 4;
削除に成功すると削除できた行数が「DELETE 1」のように表示されます。
次のように削除対象行を指定せずに削除を実行すると、テーブル内の全てのデータが消し飛ぶので注意してください。
DELETE FROM item_master;
データを抽出する
今までの作業結果を確認するために、テーブルの中身を抽出します。こういった時には次のコマンドを入力します。
SELECT * FROM テーブル名;
前述のアイテムマスターを利用すると以下のようになります。
SELECT * FROM item_master;
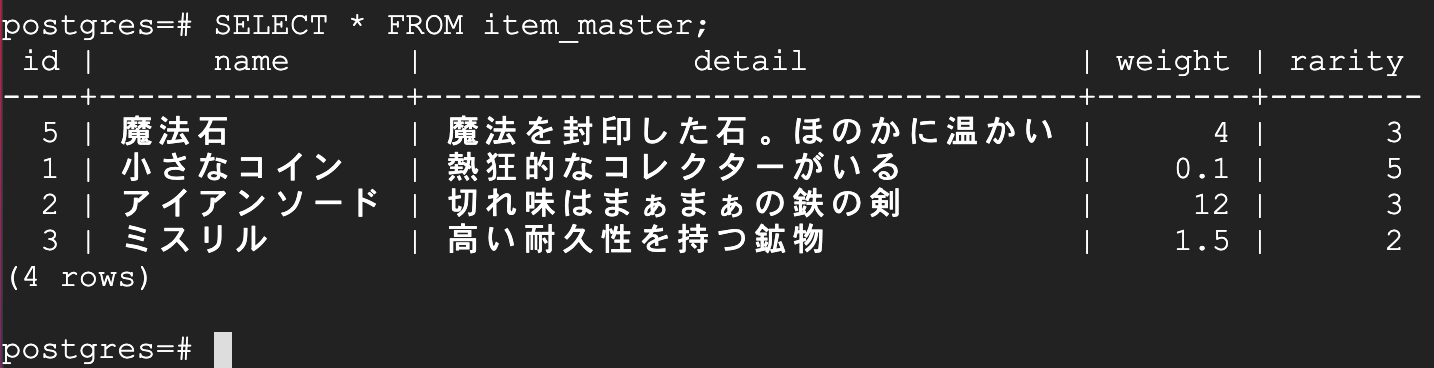
抽出結果のサンプル1
抽出時には、次のようにコマンドに加えると、検索条件に当てはまる対象のみを抽出して表示することが可能です。
SELECT * FROM テーブル名 WHERE 検索条件;
例えば、前述のアイテムマスターを利用し、「rarity(レアリティ)が3以上のアイテム」のみを抽出したい場合は、次のように入力します。
SELECT * FROM item_master WHERE rarity>=3;

抽出結果のサンプル2
以上がデータベースの基本的な操作方法となります。
アプリケーションとデータベースを連携させる
さて先ほどまでの作業はデータベースの中身を編集していただけで、「データベースサーバ」としては機能していませんでした。言い換えるとサーバが持つべき役割、「クライアント(外部)と連携する機能」がない状態です。 これを解決し、Node.jsからデータベースにアクセスする方法を説明します。
データベースサーバの起動と停止
PostgreSQLにはデータベースを外部と連携させるために、「起動」と「停止」と呼ばれる操作を行うことができます。「起動」によってデータベースサーバが動き出せば、データベース外部から何通りかの決まった方法でアクセスすることが可能になります。「停止」を行うと外部との連携は途切れてしまいますが、設定を変更した際やデータベースサーバの利用がない間は「停止」していた方が良いでしょう。
「起動」と「停止」を行う前には一度、データベースからログアウトし、DebianのCUIでpostgresアカウントになっている状態まで戻る必要があります。
データベースにログイン中であれば次のように入力します。(もしくは\q;)
quit;
また仮想環境を起動したての場合などは、アカウントをpostgresに切り替えます。
su - postgres
データベースサーバの起動
「起動」と「停止」はDebianのCUIから「pg_ctlcluster」コマンドを使って操作します。(他にもpostgresコマンドやpd_ctlコマンドでも同じ動作が可能ですが事前設定が大変です。Debianではpg_ctlclusterの利用が推奨されていることに加え、最も簡単に実行できたのでこちらを採用しました。)
sudo pg_ctlcluster 11 main start
Enterキーで決定すると、アカウントの"postgres"のパスワードを求められるので入力してください。なお、11の数値はインストールしているPostgreSQLのバージョンに依存します。
データベースサーバの状態を確認する
データベースサーバの起動が成功した場合でも特に何も表示されません。きちんと稼働しているかどうかは次のコマンドを入力することで確認可能です。
sudo pg_lsclusters
次のように、Statusの項目が「online」と表示されていれば、きちんとデータベースサーバが稼働しています。

著者環境での状態確認結果
データベースサーバの停止
データベースサーバを停止する際は、次のコマンドを入力します。起動時と同様にアカウントの"postgres"のパスワードを求められるので入力してください。
sudo pg_ctlcluster 11 main stop
念の為、きちんと停止しているか確認するため、再度「sudo pg_lsclusters」と、コマンドを入力して結果を確認します。

著者環境での状態確認結果
Statusが赤字で「down」と表示されていれば停止ができています。
node-postgres(pg)モジュール
続けて、「起動」の済んだデータベースサーバにNode.jsの環境からのアクセスを試みます。Node.jsには、postgreSQLのデータベースサーバにプログラムからアクセスし、直接ログインした時とほぼ同じ制御を可能にするモジュールが提供されています。今回はこれを使用し、先ほど作ったばかりのテーブルに対してデータ抽出を行なってみます。
node-postgres(pg)モジュールのインストール
node-postgresモジュール(以下、pgモジュール)はNode.jsからPostgreSQLのデータベースサーバへのアクセスと制御を行うことを可能にするモジュールです。デフォルトでインストールされていないモジュールのため、npmコマンドを利用することで入手します。
まずは任意のアカウント、任意の作業フォルダへ移動します。(データベースサーバを起動した直後であればアカウントがpostgresのままと思われるので、exitコマンドなどで元のデフォルトアカウントに戻ると良いでしょう。)
今回はdbtestの名称でフォルダを作成し、その中まで移動します。
mkdir dbtest
cd dbtest
続けて、次のコマンドを入力します。
npm init -y
npmは、Node.jsをインストールした際に使用できるようになったコマンドの一つです。モジュールを管理するためのコマンドで、新たなモジュール(やモジュールを束ねたパッケージ)のインストールや不要なモジュールの削除などを制御できます。aptのように、「npm ○○」という形で利用します。
「npm init」コマンドは現在みているフォルダに
- npm用の設定ファイル生成
- 管理対象のモジュールを保存するフォルダ生成
など、これからモジュールの追加と削除を行うために必要な情報を初期化するコマンドです。(本来は色々な質問をされ、逐一答えないと各種ファイルが生成されないのですが、簡略化のため、質問に全てYESと答える-yオプションをセットで指定します。)
続けて、今回必要となるpgモジュールのインストールを行います。
npm install pg
インストールされたモジュールは次のコマンドで内容を確認できます。
npm list
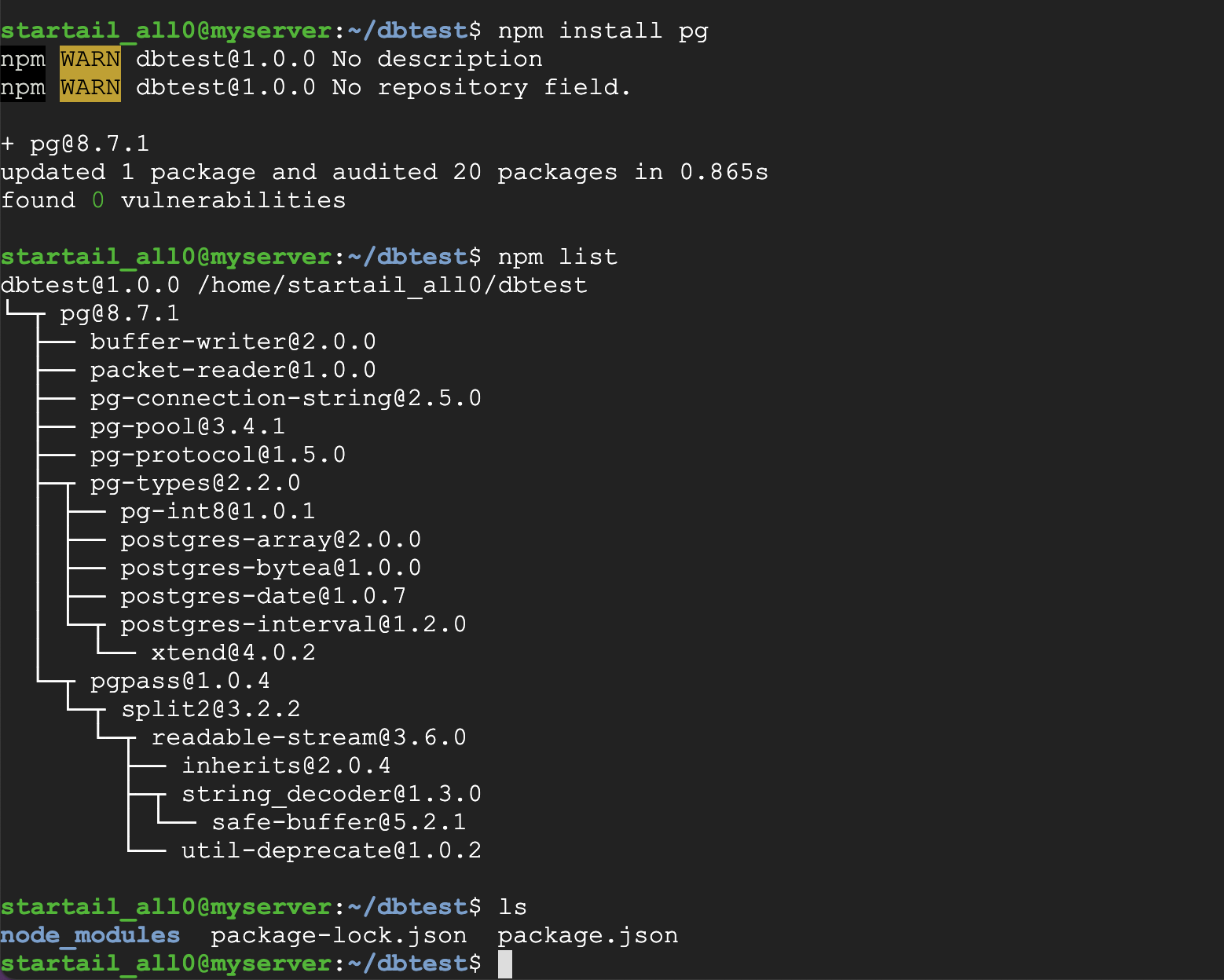
筆者環境でnpmコマンドを実行した結果
データベースを制御するサンプルプログラム
続けて、pgモジュールを利用したサンプルプログラムを作成します。当記事にて取り上げたテキストエディタを使用した方法やファイルのダウンロードとアップロードを組み合わせた方法でも構いません。
var {Client} = require('pg');
var client = new Client({
user: 'postgres',
host: 'localhost',
database: 'postgres',
password: '@@@@@@@@',
port: 5432
});
client.connect();
client.query('SELECT * FROM item_master', (err, res) => {
console.log(res);
client.end();
});
サンプルプログラムが完成した後は、DebianのCUI上で実行しましょう。
node sample3.js
上記のサンプルプログラムで重要な部分を表にまとめます。
| プログラム | 意味 |
|---|---|
| user: 'postgres' | データベースユーザーの"postgres"。他のデータベースユーザーの場合は'と'の間にその名称を記載。 |
| host: 'localhost' | 接続先のデータベースサーバの所在地を'と'の間にドメインもしくはIPアドレスで指定する。データベースサーバが同じコンピュータ上の時はlocalhostと記載可能。 |
| database: 'postgres' | データベースの"postgres"。他のデータベースにアクセスする場合は'と'の間にその名称を記載 |
| password: '@@@@@@@@' | データベースユーザーpostgresのパスワードを'と'の間に記載する。表示例はあくまでサンプルです。自分で設定したものを入力してください。 |
| port: 5432 | 接続先のデータベースサーバが待ち受けている出入口(ポート)の番号。pg_lsclustersの表示結果に記載されている。デフォルトは5432。 |
| client.connect() | 前述の情報を使ってデータベースサーバにアクセスを実施する命令。上記の設定が正しくない場合、エラーが発生してアクセス失敗する。 |
| client.query('SELECT * FROM item_master', (err, res) => { console.log(res);client.end();}); | データベースを操作する処理。SELECT * FROM item_masterは前述の抽出処理そのまま。(err,res)から後半の部分は制御の失敗結果、成功結果を元にどのような処理を行うかを記載している部分。errに失敗結果、resに成功結果が格納されている。 |
Node.jsとPostgreSQLを連携させたサンプルプログラム
データベースサーバにNode.jsからアクセスできることがわかったところで、最後に双方を組み合わせたプログラムを実行します。内容としては、sample2.jsとsample3.jsを組み合わせて整理したものです。
var http = require('http');
var {Client} = require('pg');
var server = http.createServer( function(httpReq,httpRes){
httpRes.writeHead(200, {'Content-Type': 'text/html;charset=utf-8'});
var client = new Client({
user: 'postgres',
host: 'localhost',
database: 'postgres',
password: '@@@@@@@@',
port: 5432
});
client.connect();
client.query('SELECT * FROM item_master', (dbErr,dbRes)=>{
for(row=0;row<dbRes.rows.length;row++){
httpRes.write(JSON.stringify(dbRes.rows[row]));
}
httpRes.end();
client.end();
});
});
server.listen(55555);
上記のサンプルプログラムで重要な部分を表にまとめます。sample1.jsやsample2.jsと異なり、reqをhttpReq,resをhttpResに置き換えていますが効果は一緒です。同様に、sample3.jsと異なり、errをdbErr,resをdbResに置き換えています。
| プログラム | 意味 |
|---|---|
| httpRes.writeHead(200, {'Content-Type': 'text/html;charset=utf-8'}); | HTTPレスポンスに、「このデータは文字コードがUTF-8のテキスト情報です」と記す処理。この指定を忘れるとデータベースから取り出した日本語などが「文字化け」する。 |
| dbRes.rows | dbResはデータベースの操作結果。dbRes.rowsはデータベースの操作結果を1行ごとに並べた配列を格納している変数。長さを確認して、繰り返し処理と組み合わせることで結果を1行ずつ抽出する。 |
| dbRes.rows[row] dbRes.rows[0] dbRes.rows[0].id |
上記dbRes.rows配列のrow番目(=抽出結果の○行目)を具体的に指定する記述。dbRes.rows[0]で抽出結果の1行目を取得。さらに抽出結果の中身が具体的にわかる場合は、続けて「.列名」と指定することで指定列に格納されたデータを取り出すこともできる |
| JSON.stringify(dbRes.rows[row]) | 引数で指定したデータをJSON形式の文字列に変換する関数。今回は抽出した情報を1行ずつJSONに変換してHTTPレスポンスに書き込むことで、クライアントにデータベース内部の情報を伝達した。 |
node sample4.js
続けて自身のPCでWebブラウザを起動し、sample2.jsと同様の形でURLを指定してEnterキーで決定してください。(詳しくは「Webブラウザとクラウドサービスを使った遠隔仮想環境でゲーム用の低予算バックエンドを拵える話 (その3)」をご確認ください。)

sample4.jsの動作結果がクライアントのWebブラウザに表示されたところ
なお動作結果については、ブラウザの幅を調整して綺麗に見えるようにしていますが、実際のところは改行が入っていないので繋がって表示されます。
まとめ
- データベースサーバの基本事項への理解
- PostgreSQLをインストール
- データベースにログインしてデータ整理
- Node.jsにnpmコマンドでモジュールを追加
- Node.jsからデータベースを制御
という盛り沢山な内容について説明を行いましたが、以上で今回の「データベースサーバを用意する」編は終わりとなります。
アプリケーションサーバを用意することで好きな処理をサーバ側に用意することができるようになったことに加え、データベースサーバを使うことで様々な情報の蓄積と利用ができるようになりました。
実際のところ、ここまでバックエンドが構築できると「後はあなたのアレンジ次第!」となりますが、現時点でも
- セキュリティ的な課題
- パフォーマンス的な課題
などの様々な問題要素をはじめ、
- あれもできるのでは?
- これはどうやるの?
という様々な発展要素への期待もあるのではないでしょうか?
次はいよいよ最終回「取り回しの良さを向上させる」編となります。お楽しみに。
Discussion