はじめに
皆さんこんにちは。株式会社アイデミー・データサイエンティストの藤井(X | LinkedIn)です。
本記事は、画像系異常検知モデルの中身について解説するシリーズの第三弾です。
第一弾で画像系異常検知モデルの始祖・SPADE について、第二弾で SPADE をベースに改良を加えたモデル・PaDiM についてそれぞれ解説してきました。まだ読まれていない方は、ぜひこちらから読むことをオススメします。
前回の PaDiM と同様、今回取り上げる PatchCore も SPADE の推論速度の問題を解決することを主眼に置いたモデルです。
GitHub リポジトリ
例によってこちらのリポジトリを使用します。
モデルの詳細解説
PatchCore モデルのコード全体はこちら
class PatchCore(KNNExtractor):
def __init__(
self,
f_coreset: float = 0.01, # fraction the number of training samples
backbone_name : str = "resnet18",
coreset_eps: float = 0.90, # sparse projection parameter
):
super().__init__(
backbone_name=backbone_name,
out_indices=(2,3),
)
self.f_coreset = f_coreset
self.coreset_eps = coreset_eps
self.image_size = 224
self.average = torch.nn.AvgPool2d(3, stride=1)
self.blur = GaussianBlur(4)
self.n_reweight = 3
self.patch_lib = []
self.resize = None
def fit(self, train_dl):
for sample, _ in tqdm(train_dl, **get_tqdm_params()):
feature_maps = self(sample)
if self.resize is None:
largest_fmap_size = feature_maps[0].shape[-2:]
self.resize = torch.nn.AdaptiveAvgPool2d(largest_fmap_size)
resized_maps = [self.resize(self.average(fmap)) for fmap in feature_maps]
patch = torch.cat(resized_maps, 1)
patch = patch.reshape(patch.shape[1], -1).T
self.patch_lib.append(patch)
self.patch_lib = torch.cat(self.patch_lib, 0)
if self.f_coreset < 1:
self.coreset_idx = get_coreset_idx_randomp(
self.patch_lib,
n=int(self.f_coreset * self.patch_lib.shape[0]),
eps=self.coreset_eps,
)
self.patch_lib = self.patch_lib[self.coreset_idx]
def predict(self, sample):
feature_maps = self(sample)
resized_maps = [self.resize(self.average(fmap)) for fmap in feature_maps]
patch = torch.cat(resized_maps, 1)
patch = patch.reshape(patch.shape[1], -1).T
dist = torch.cdist(patch, self.patch_lib)
min_val, min_idx = torch.min(dist, dim=1)
s_idx = torch.argmax(min_val)
s_star = torch.max(min_val)
# reweighting
m_test = patch[s_idx].unsqueeze(0) # anomalous patch
m_star = self.patch_lib[min_idx[s_idx]].unsqueeze(0) # closest neighbour
w_dist = torch.cdist(m_star, self.patch_lib) # find knn to m_star pt.1
_, nn_idx = torch.topk(w_dist, k=self.n_reweight, largest=False) # pt.2
# equation 7 from the paper
m_star_knn = torch.linalg.norm(m_test-self.patch_lib[nn_idx[0,1:]], dim=1)
# Softmax normalization trick as in transformers.
# As the patch vectors grow larger, their norm might differ a lot.
# exp(norm) can give infinities.
D = torch.sqrt(torch.tensor(patch.shape[1]))
w = 1-(torch.exp(s_star/D)/(torch.sum(torch.exp(m_star_knn/D))))
s = w*s_star
# segmentation map
s_map = min_val.view(1,1,*feature_maps[0].shape[-2:])
s_map = torch.nn.functional.interpolate(
s_map, size=(self.image_size,self.image_size), mode='bilinear'
)
s_map = self.blur(s_map)
return s, s_map
特徴量抽出器
画像から特徴量を抽出する部分については、前々回記事と同じです。
PatchCore モデル - 学習
PatchCore の学習プロセスfit()では、大まかに以下の3つの処理を行い、最終的に異常度判定用パッチpatch_libを作成します。
以降で各処理について詳細に解説します。
F1. 特徴量マップの抽出
次のF2. リサイズと合わせて、該当箇所のコードは以下の部分です。
for sample, _ in tqdm(train_dl, **get_tqdm_params()):
feature_maps = self(sample)
if self.resize is None:
largest_fmap_size = feature_maps[0].shape[-2:]
self.resize = torch.nn.AdaptiveAvgPool2d(largest_fmap_size)
resized_maps = [self.resize(self.average(fmap)) for fmap in feature_maps]
patch = torch.cat(resized_maps, 1)
patch = patch.reshape(patch.shape[1], -1).T
self.patch_lib.append(patch)
self.patch_lib = torch.cat(self.patch_lib, 0)
PatchCore では、backbone モデルとしてresnet18を使用し、その 2、3 層目の出力を特徴量マップとして取り出します。
取り出した特徴量マップの形状(1 画像単位)はそれぞれ以下の通りです。
Layer 2: [1, 512, 28, 28]
Layer 3: [1, 1024, 14, 14]
第 3, 4 次元が画像のタテ、ヨコのサイズに相当し、第 2 次元が特徴量マップの枚数に対応します。また、第 1 次元は画像の枚数を示しています。
F2. リサイズ
リサイズの処理は、以下の流れです。
- F2-1. 全ての層の出力を最も大きな画像サイズ(28 x 28)に揃える
- F2-2. 全ての層を第 2 次元で結合して、画像ごとに 1 つの特徴量マップにまとめる
- F2-3. 4 次元構造([画像数, 特徴量マップ枚数, 画像タテ, 画像ヨコ])の特徴量マップを、2 次元構造に圧縮する
各処理で特徴量マップの形状は以下のように変化します。
F2-1: Layer 2: [1, 512, 28, 28]
Layer 3: [1, 1024, 14, 14]
F2-2 : [画像数, 1536, 28, 28]
F2-3 : [画像数 x 784, 1536]
F2-1 では、torch.nn.AdaptiveAvgPool2dに通すことで画像サイズの小さなより深い層の出力を引き伸ばしています。
F2-3 では、1 画像あたり 28x28 の特徴量平面が 1536 枚積み重なっている特徴量マップの構造を、ピクセル単位でバラして 28x28=784 行, 1536 列の 2 次元構造へと変形しています(図 1)。
この処理は画像のタテ・ヨコに対応する 2 次元構造を 1 次元構造に落とすものであり、ピクセル単位で見ると情報に欠落や変化が無い点は重要です。
最終的に全ての画像について第 1 次元で結合し、2 次元構造の特徴量マップを得ます。
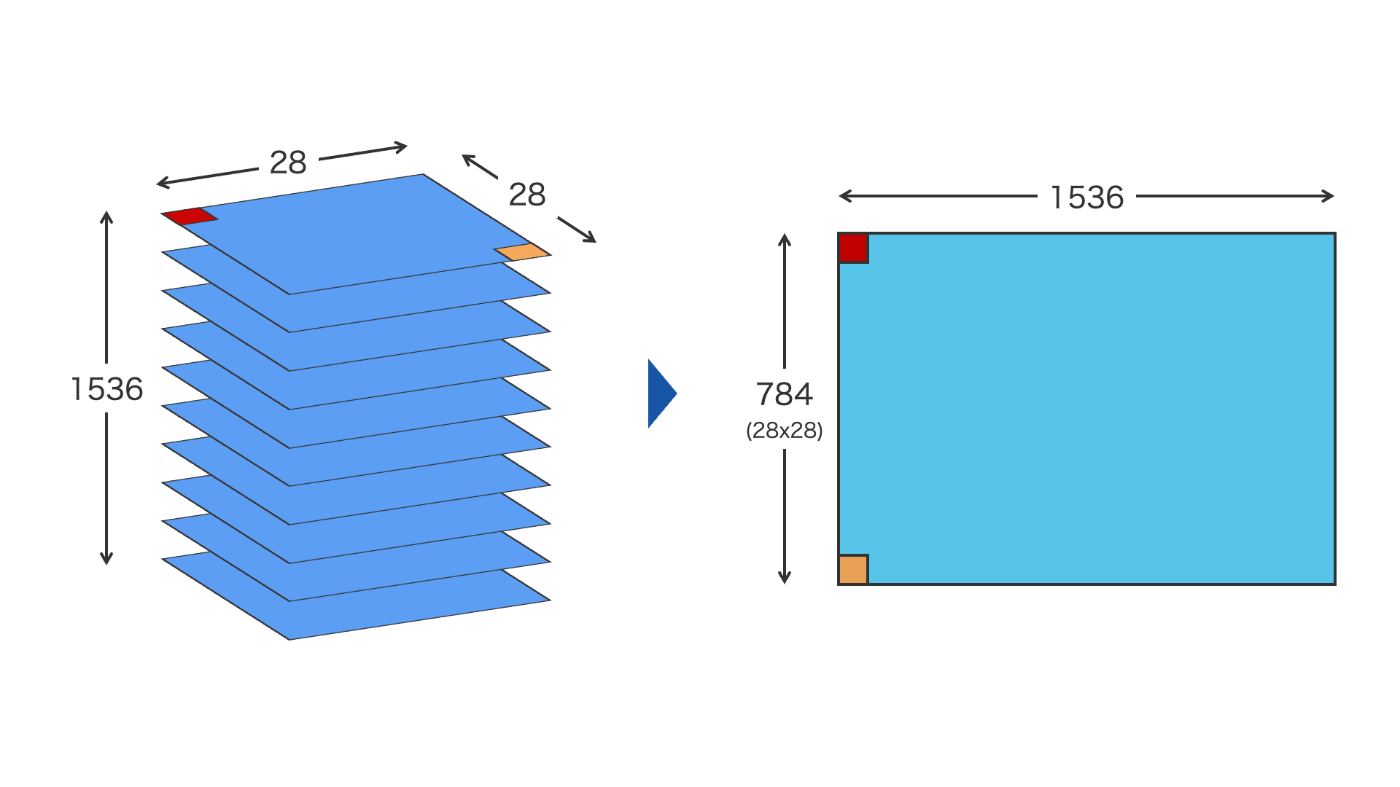
図 1 特徴量マップの次元圧縮
F3. 情報量削減
続いて、得られた特徴量マップをget_coreset_idx_randomp()関数に通して情報量の削減を行います。
get_coreset_idx_randomp()関数では、以下の一連の操作によって特徴量マップの情報量削減を行っています。
- F3-1. スパース・ランダム射影による圧縮
- F3-2. ピクセルごとに他ピクセルとのユークリッド距離を計算
- F3-3. 他ピクセルとの距離が比較的遠いピクセルをピックアップ
- F3-4. 選ばれたピクセルのインデックスを記録した
coreset_idxを返す
F3-1. スパース・ランダム射影による圧縮
該当コードは以下です。
try:
transformer = random_projection.SparseRandomProjection(eps=eps)
z_lib = torch.tensor(transformer.fit_transform(z_lib))
print(f" DONE. Transformed dim = {z_lib.shape}.")
except ValueError:
print( " Error: could not project vectors. Please increase `eps`.")
ランダム射影(random_projection.SparseRandomProjection())によって、特徴量マップの要素数を削減します。
処理前後の特徴量マップの形状は以下の通りです。
処理前: [画像数 x 784, 1536]
処理後: [画像数 x 784, 191]
形状の変化を見るとわかるように、ここではピクセル数を表す次元には変化がなく、各ピクセルの特徴量に関する次元の要素数が削減されています。
F3-2. ピクセルごとに他ピクセルとのユークリッド距離を計算
次のF3-3. 他ピクセルとの距離が比較的遠いピクセルをピックアップと合わせて、コードでは以下の部分が該当します。
select_idx = 0
last_item = z_lib[select_idx:select_idx+1]
coreset_idx = [torch.tensor(select_idx)]
min_distances = torch.linalg.norm(z_lib-last_item, dim=1, keepdims=True)
for _ in tqdm(range(n-1), **TQDM_PARAMS):
distances = torch.linalg.norm(z_lib-last_item, dim=1, keepdims=True) # broadcasting step
# distances = torch.sum(torch.pow(z_lib-last_item, 2), dim=1, keepdims=True) # broadcasting step
min_distances = torch.minimum(distances, min_distances) # iterative step
select_idx = torch.argmax(min_distances) # selection step
# bookkeeping
last_item = z_lib[select_idx:select_idx+1]
min_distances[select_idx] = 0
coreset_idx.append(select_idx.to("cpu"))
ここでは、ランダム射影処理後のz_libについて、ある一つのピクセル(形状: [1, 191])に注目し、そのピクセルとz_lib中の全てのピクセル(形状: [画像数 x 784, 191])とのユークリッド距離を計算します。
計算結果の形状は[画像数 x 784, 1]となります。
これをmin_distancesとして保持します。
F3-3. 他ピクセルとの距離が比較的遠いピクセルをピックアップ
続いて、以下の操作を規定した回数繰り返します。
-
F3-3-1. 別のピクセルについても
z_lib中の全てのピクセルとのユークリッド距離を計算し、[画像数 x 784, 1]のベクトルを得る -
F3-3-2. 得られたベクトルを
min_distancesと比較し、各要素でより値の小さい(距離の近い)方をピックアップしてmin_distancesを更新する -
F3-3-3.
min_distancesにおいて最も値の大きい(距離の遠い)要素のインデックスを取得して、それをcoreset_idxに追加する -
F3-3-4. 取得したインデックスの
min_distancesの値を 0 に変更して、以降のイテレーションで再選択されないようにする - F3-3-5. 次は取得したインデックスのピクセルに対して、F3-3-1から一連の処理を行う
この一連の操作はすなわち、ある適当なピクセルから最も距離の遠い(≒ 性質の遠い)ピクセルをピックアップして coreset を作成することを意味しています。
「比較的他のピクセルと性質の離れたピクセルを coreset として持っておき、推論画像の特徴量と比較したときにそれらよりも距離の遠いピクセルが見つかったらそれは異常箇所っぽいよね」というロジックです。
なお、ピックアップ数は引数f_coreset(0〜1)によってコントロールされ、例えばf_coreset=0.1の場合は、全ピクセル(画像数 x 784)から 10%がピックアップされることになります。
F3-4. 選ばれたピクセルのインデックスを記録したcoreset_idxを返す
最終的に、coreset_idxにてピックアップされたピクセルを特徴量マップから取り出して、patch_libとして保持します。
patch_libの形状は以下の通りです。
patch_lib: torch.size([画像数 x 784 x f_coreset, 1536])
ここで注意すべきは、最終的なpatch_libは、元の特徴量マップからピクセルの情報のみを削っている点です。
上記のF3-1. スパース・ランダム射影による圧縮ではピクセルの情報ではなく特徴量の情報を削っていましたが、これは効率よくcoreset_idxを抽出するために行った操作であり、ここで削られた特徴量の情報は最終的なpatch_libには反映されていません。混同しないよう注意してください。
学習の処理まとめ
ここまで非常に複雑な処理だったので、最後にもう一度fit()関数で行っていることをざっくりおさらいしておきます。
fit()で行っている処理は、大まかに以下の 3 点です。
- 学習済みモデルに正常画像を通して特徴量マップを抽出する
- 特徴量マップを扱いやすいようリサイズする
- 画像の中で特徴的なピクセルをピックアップして
patch_libとして保持する
PatchCore モデル - 推論
続いて、推論を行う関数predict()について見ていきましょう。
predict()関数は、以下の処理で構成されています。
以降で各処理について詳しく見ていきます。
P1. 特徴量マップの抽出と変形
まずは前処理として、以下に示すコードで推論用画像から特徴量マップの抽出と変形を行い、形状[784, 1536]のpatchを得ます。
ここは学習時とほぼ同じ動きです。
feature_maps = self(sample)
resized_maps = [self.resize(self.average(fmap)) for fmap in feature_maps]
patch = torch.cat(resized_maps, 1)
patch = patch.reshape(patch.shape[1], -1).T
P2. ピクセル単位の異常度の計算
ピクセル単位の異常度を得る計算は非常にシンプルです。
該当箇所のコードは以下の通りです。
dist = torch.cdist(patch, self.patch_lib)
min_val, min_idx = torch.min(dist, dim=1)
# ===中略===
s_map = min_val.view(1,1,*feature_maps[0].shape[-2:])
s_map = torch.nn.functional.interpolate(
s_map, size=(self.image_size,self.image_size), mode='bilinear'
)
s_map = self.blur(s_map)
処理は以下の流れです。
-
P2-1.
torch.cdist()を用いて、推論画像のpatchと保持しているpatch_libとの距離を計算し、距離ベクトルdistを得る -
P2-2.
distの各行で最小値となる要素とそのインデックスを取得し、それぞれmin_valおよびmin_idxとする -
P3-3.
min_valを成形・元画像サイズに引き伸ばしてピクセル単位の異常度マップとする
各ベクトルの形状はそれぞれ以下の通りです。
patch : [784, 1536]
self.patch_lib: [画像数 x 784 x f_coreset, 1536]
dist : [784, 画像数 x 784 x f_coreset]
min_val : [784]
min_idx : [784]
この一連の操作は、patchの各ピクセル単位で、patch_libの中から最も距離の近い(≒ 性質の近い)ピクセルのインデックスとその距離を得ることを意味します。
「patch_libから一番近そうなピクセルを拾ってきたにも関わらず、そのピクセルと判定対象ピクセルとの距離が遠いのであれば、その当該ピクセルは異常である可能性が高い」というロジックです。
P3. 画像単位の異常度の計算
最後に、画像単位の異常度を計算します。
ここでは、min_valの最大値に重みを掛けた値を画像単位の異常度sとして出力しています。
重みの定義が少し複雑なので、詳細は以下のトグルに収納しておきます。より深く知りたい方はご覧ください。
重みの定義について
該当コードは以下の通りです。
s_idx = torch.argmax(min_val)
s_star = torch.max(min_val)
m_test = patch[s_idx].unsqueeze(0)
m_star = self.patch_lib[min_idx[s_idx]].unsqueeze(0)
w_dist = torch.cdist(m_star, self.patch_lib)
_, nn_idx = torch.topk(w_dist, k=self.n_reweight, largest=False)
m_star_knn = torch.linalg.norm(m_test-self.patch_lib[nn_idx[0,1:]], dim=1)
D = torch.sqrt(torch.tensor(patch.shape[1]))
w = 1-(torch.exp(s_star/D)/(torch.sum(torch.exp(m_star_knn/D))))
s = w*s_star
重みの計算手順は以下です。
-
P3-1.
min_valの最大値s_starおよびそのインデックスs_idxを取得する-
patch_libとの距離が最も遠いピクセルを特定している
-
-
P3-2.
s_starの算出に関わったpatch内のピクセルの特徴量とpatch_lib内のピクセルの特徴量を取得し、それぞれm_test、m_starとする- どちらもサイズは
[1, 1536]
- どちらもサイズは
-
P3-3.
m_starとpatch_libの各ピクセルとの距離を計算してw_distとする-
torch.cdist()を使用 -
w_distのサイズ:[1, 画像数 x 784 x f_coreset]
-
-
P3-4.
w_distが最も小さい k 個のインデックスを取得する- k =
self.n_reweight -
m_starに最も性質の近いピクセルを k 個参照することを意味する
- k =
-
P3-5. 得られた k 個のピクセルと
m_testとの距離を計算してm_star_knnとする- ただし、
w_distが最小のピクセルは除く- それが
m_star自身である可能性が高いため
- それが
-
self.n_reweight - 1個のスカラー(距離の値)が得られる
- ただし、
-
P3-6.
s_starとs_star_knnから重みwを生成する
w を計算する式: w = 1-(torch.exp(s_star/D)/(torch.sum(torch.exp(m_star_knn/D))))において、m_star_knnが小さい(=m_starと近傍データの距離が近い)ほど重みwの値は 0 に近づき、逆にm_star_knnが大きいほど重みwの値は 1 に近づきます。
誤解を恐れずにざっくり解釈すると、patch_lib内の参照ピクセルが他のピクセルと性質がほとんど同じ場合は、推論用画像にちょっと異常っぽいピクセルがあってもノイズっぽいからあんまり重視しませんよ〜といった感じです。
一方で判定対象のピクセルが異常箇所の場合、正常画像から最も性質の近いピクセルを参照しようとすると、その中で最もユニークなピクセルが選択される可能性が高く、その際には異常箇所とpatch_lib各ピクセルとの距離が重視されるべきである、といった意図を反映した重みの設計になっていると考えられます。
出力結果を見てみよう
得られたピクセル単位の異常度マップを元画像にオーバーレイさせた画像を以下に示します。

図 2 異常度マップの例
使用データセット: https://www.mvtec.com/company/research/datasets/mvtec-ad
まとめ
以下に PatchCore モデルが行う一連の処理をまとめます。
- 学習
- backend として学習済みモデルを呼び出し、正常画像を入力して第 2, 3 層目の出力を特徴量マップとして取り出す
- 特徴量マップを 2 次元形状に変形する
- 画像内で比較的ユニークなピクセルをピックアップして
patch_libを作成する
- 推論
- 学習時と同様に推論用画像から特徴量マップを抽出し、2 次元形状に変形する
-
patch_libとの距離を計算し、ピクセルごとにその最小値を取得してピクセル単位の異常度マップを得る - ピクセル単位の異常度マップから最大値を取得して、重みを掛けて画像単位の異常度を得る
結構複雑な内容でしたが、最後まで読んでいただきありがとうございました!
上手くまとめられているか自信はありませんが、誰かの学習の助けになれば幸いです。
今後も引き続き業務で得た学びや自己学習のまとめなどを発信していこうと思います!

Discussion