はじめに
皆さんこんにちは。株式会社アイデミー・データサイエンティストの藤井(X | LinkedIn)です。この度初めて記事を投稿させていただきます。
弊社のDX伴走支援サービスModeloyでは製造業のお客様を支援させていただくことが多く、中でも製品の不良検査に関するご相談をいただくことがしばしばあります。
製造現場において製品の良/不良をAIによって判定したいという需要は多い一方で、一般的に不良品は絶対数が少ないため、AIに学習させるためのサンプル数を十分に得ることが難しい点が課題です。
この課題に対して、「異常検知(Anomaly Detection)」は有効なアプローチの一つです。異常検知とは、ざっくり言うと「正常データの特徴量を学習しておいて、それらの特徴量から大きく外れたサンプルを異常と判定する」技術です。学習に用いるデータは比較的入手しやすい正常サンプルだけでよいため、製造業の現場においてもスピーディにモデルを構築しやすい利点があります。
本シリーズでは、異常検知モデルがどのような仕組みで動いているのか調べるために、特に有力な3つのモデル(SPADE/PaDiM/PatchCore)の中身を見ていきます。
第1回は、画像系異常検知モデルの共通部分の仕組みとともに、SPADEについて取り上げます。SPADEは現在の画像系異常検知モデルの基礎となるモデルですので、その仕組みを理解しておくことは重要です。
GitHubリポジトリ
SPADE、PaDiM、PatchCoreの全てを同時に実装してくれている神のようなGitHubリポジトリがありましたので、今回はそちらを使用します。
異常検知モデルの概要
詳しい説明に入る前に、異常検知モデルがどのように異常度を判定しているのか簡単に説明します。
現在主流となっている異常検知のモデルは、いわゆる「距離的アプローチ」によってtest画像の異常度を判定するものです。
まず準備段階として、ResNetなどの学習済みモデルにたくさんの正常画像を入力して特徴量を抽出し、それらを特徴量マップとしてストックしておきます。推論時には、test画像を同様にモデルに入力して特徴量を抽出し、それらが正常画像の特徴量マップと「距離的にどの程度離れているか」という観点で異常度を評価します(図1)。異常画像の特徴量は正常画像のそれとは異なる(=距離が遠い)性質を持つよね〜というコンセプトです。

図1 異常検知の概要 (https://commons.wikimedia.org/wiki/File:ResNet50.png より引用・改変)
一連の記事で紹介するSPADE、PaDiM、PatchCoreはいずれもこの距離的アプローチに基づいて画像の異常度を判定するモデルになっています。PaDiMとPatchCoreはSPADEをベースにしており、主にSPADEが抱える推論速度の問題を解決することをスコープとしたモデルです。
モデル解説
特徴量抽出器(共通部分)
それではモデルの中身を詳細に見ていきます。まずは、モデルのキモとなる特徴量抽出器の部分です。
先ほども述べた通り、異常検知ではまず学習済みモデルに正常画像を入力して特徴量マップを抽出しますが、ここで言うところの「特徴量マップ」とは、画像をモデルに入力して最初の数層から出力されるテンソル(入力画像を畳み込んで要約したもの、みたいなイメージ)を指します。図2に、特徴量抽出の簡単なイメージ図を示します。
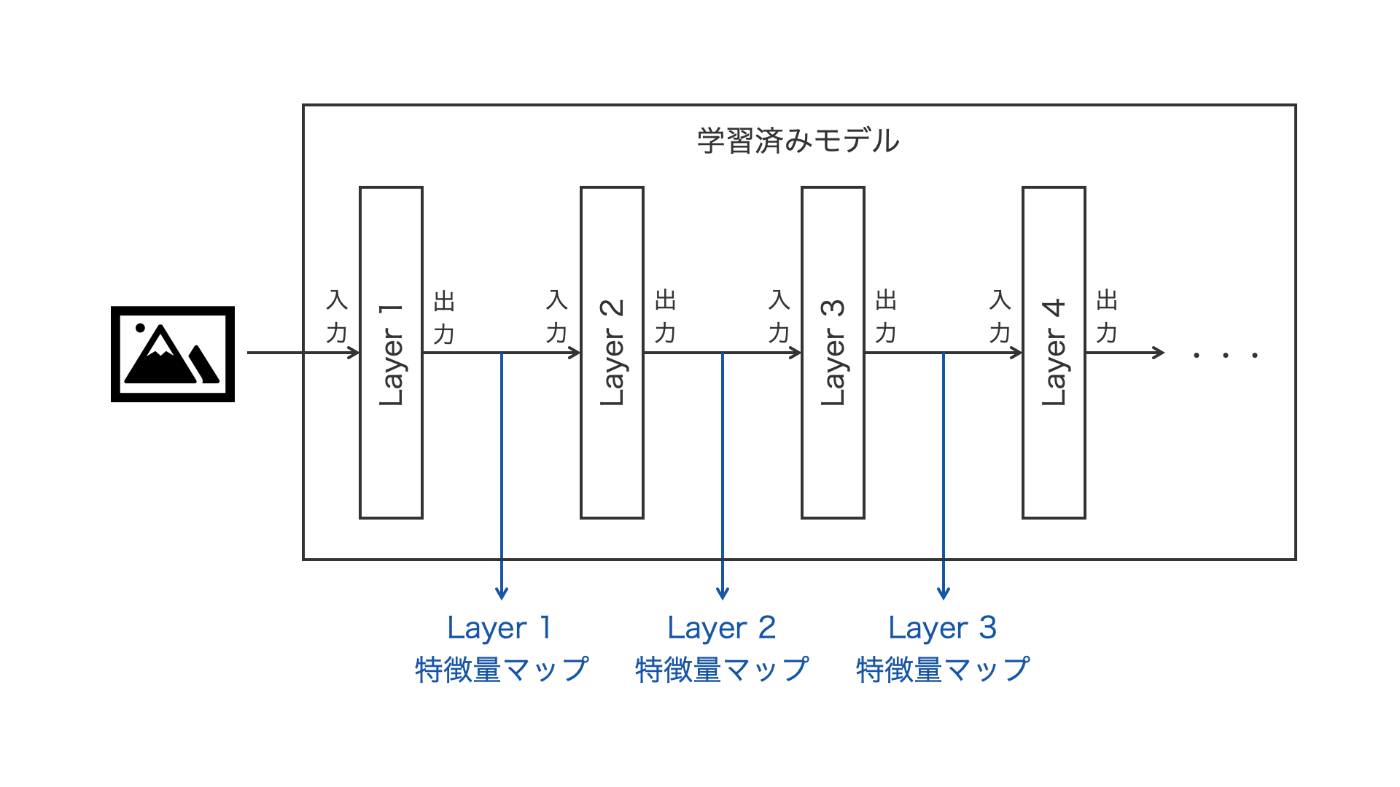
図2 異常検知における特徴量抽出のイメージ
本コードでは、この特徴量を抽出する機構をKNNExtractorとして定義し、3つの異常検知モデルは共通してこれを継承する形で実装されています。
実際のコードはこちら。
class KNNExtractor(torch.nn.Module):
def __init__(
self,
backbone_name : str = "resnet50",
out_indices : Tuple = None,
pool_last : bool = False,
):
super().__init__()
self.feature_extractor = timm.create_model(
backbone_name,
out_indices=out_indices,
features_only=True,
pretrained=True,
)
for param in self.feature_extractor.parameters():
param.requires_grad = False
self.feature_extractor.eval()
self.pool = torch.nn.AdaptiveAvgPool2d(1) if pool_last else None
self.backbone_name = backbone_name # for results metadata
self.out_indices = out_indices
self.device = "cuda" if torch.cuda.is_available() else "cpu"
self.feature_extractor = self.feature_extractor.to(self.device)
def __call__(self, x: tensor):
with torch.no_grad():
feature_maps = self.feature_extractor(x.to(self.device))
feature_maps = [fmap.to("cpu") for fmap in feature_maps]
if self.pool:
# spit into fmaps and z
return feature_maps[:-1], self.pool(feature_maps[-1])
else:
return feature_maps
def fit(self, _: DataLoader):
raise NotImplementedError
def predict(self, _: tensor):
raise NotImplementedError
def evaluate(self, test_dl: DataLoader) -> Tuple[float, float]:
"""Calls predict step for each test sample."""
image_preds = []
image_labels = []
pixel_preds = []
pixel_labels = []
for sample, mask, label in tqdm(test_dl, **get_tqdm_params()):
z_score, fmap = self.predict(sample)
image_preds.append(z_score.numpy())
image_labels.append(label)
pixel_preds.extend(fmap.flatten().numpy())
pixel_labels.extend(mask.flatten().numpy())
image_labels = np.stack(image_labels)
image_preds = np.stack(image_preds)
image_rocauc = roc_auc_score(image_labels, image_preds)
pixel_rocauc = roc_auc_score(pixel_labels, pixel_preds)
return image_rocauc, pixel_rocauc
KNNExtractorの役割は主に以下の3です。
1 学習済みモデルを呼び出す(__init__())
timmモジュールを用いて、backbone_nameで指定した学習済みモデルの構造とパラメータをbackboneとして呼び出します。
この時、引数としてfeatures_only=Trueとすることで、引数out_indicesで指定した層番号の出力を取り出すことができるようになります。
self.feature_extractor = timm.create_model(
backbone_name,
out_indices=out_indices, # 異常度の算出に用いる出力層の番号を指定
features_only=True, # Trueとすることでout_indicesで指定した層の出力を取り出すことができるようになる
pretrained=True,
)
2 画像を受け取って特徴量マップを出力する(__call__())
out_indicesで指定した層の出力をlist形式にまとめて返します。試しに、backboneとしてwide_resnet50_2を指定した時に第1, 2, 3層の出力がどのような形状になっているか調べてみます。なお、入力画像サイズは224x224で、1枚単位でモデルに入力しています。結果は以下の通りです。
Image size: torch.Size([1, 3, 224, 224])
Layer 1: torch.Size([1, 256, 56, 56])
Layer 2: torch.Size([1, 512, 28, 28])
Layer 3: torch.Size([1, 1024, 14, 14])
各層の出力の形状について、1次元目は画像の枚数、3次元目と4次元目は画像のタテとヨコのピクセル数をそれぞれ表しています。2次元目は特徴量マップの枚数を表します。層を経るごとに画像のサイズが圧縮(要約)されていき、特徴量マップの枚数が増加していることがイメージできます。これを図示すると、図3のようになります。

図3 特徴量マップ抽出のイメージ
3 モデルの評価値を出力する(evaluate())
①画像単位のROC-AUC、②ピクセル単位のROC-AUCをそれぞれ計算して出力します。
SPADEモデル
SPADEは現在の画像系異常検知モデルの原点とも呼べるモデルで、ピクセル単位の異常度を評価できるようにした点が画期的でした。
実際のコードはこちら
class SPADE(KNNExtractor):
def __init__(
self,
k: int = 5,
backbone_name: str = "resnet18",
):
super().__init__(
backbone_name=backbone_name,
out_indices=(1,2,3,-1),
pool_last=True,
)
self.k = k
self.image_size = 224
self.z_lib = []
self.feature_maps = []
self.threshold_z = None
self.threshold_fmaps = None
self.blur = GaussianBlur(4)
def fit(self, train_dl):
for sample, _ in tqdm(train_dl, **get_tqdm_params()):
feature_maps, z = self(sample)
# z vector
self.z_lib.append(z)
# feature maps
if len(self.feature_maps) == 0:
for fmap in feature_maps:
self.feature_maps.append([fmap])
else:
for idx, fmap in enumerate(feature_maps):
self.feature_maps[idx].append(fmap)
self.z_lib = torch.vstack(self.z_lib)
for idx, fmap in enumerate(self.feature_maps):
self.feature_maps[idx] = torch.vstack(fmap)
def predict(self, sample):
feature_maps, z = self(sample)
distances = torch.linalg.norm(self.z_lib - z, dim=1)
values, indices = torch.topk(distances.squeeze(), self.k, largest=False)
z_score = values.mean()
# Build the feature gallery out of the k nearest neighbours.
# The authors migh have concatenated all features maps first, then check the minimum norm per pixel.
# Here, we check for the minimum norm first, then concatenate (sum) in the final layer.
scaled_s_map = torch.zeros(1,1,self.image_size,self.image_size)
for idx, fmap in enumerate(feature_maps):
nearest_fmaps = torch.index_select(self.feature_maps[idx], 0, indices)
# min() because kappa=1 in the paper
s_map, _ = torch.min(torch.linalg.norm(nearest_fmaps - fmap, dim=1), 0, keepdims=True)
scaled_s_map += torch.nn.functional.interpolate(
s_map.unsqueeze(0), size=(self.image_size,self.image_size), mode='bilinear'
)
scaled_s_map = self.blur(scaled_s_map)
return z_score, scaled_s_map
先ほどの特徴量抽出器KNNExtractorを継承してSPADEクラスが定義されています。
では、SPADEモデルの各関数について詳しく見ていきましょう。
特徴量マップの抽出(fit())
SPADEで用いる出力層は、以下out_indicesで規定する通り1, 2, 3および最終層です。
super().__init__(
backbone_name=backbone_name,
out_indices=(1,2,3,-1),
pool_last=True,
)
このうち1~3層はピクセルごとの異常度を評価するために用います。
最終層については、プーリング層を経由してさらに圧縮し、画像単位の異常度を評価するために用います。
各層の出力の形状は以下の通りです。
Layer 1: torch.Size([1, 256, 56, 56])
Layer 2: torch.Size([1, 512, 28, 28])
Layer 3: torch.Size([1, 1024, 14, 14])
Layer -1: torch.Size([1, 2048, 1, 1])
各層の出力はそれぞれすべての画像についてスタックされ、正常画像の特徴量として保持されます。
異常度の評価(predict())
test画像についても同様に学習済みモデルに入力して、1, 2, 3および最終層の出力を得ます。
得られた特徴量をそれぞれfit()で得た正常画像の特徴量と比較して、画像単位およびピクセル単位の異常度を評価します。
画像単位の異常度
test画像の最終層の出力(z)を、正常画像の最終層の特徴量(self.z_lib)と比較します。異常度の値は単純に両者のユークリッド距離の値とし、torch.linalg.norm()を用いて算出します。結果として学習に用いた正常画像枚数分のスカラー値が得られます。
続いて、指定したkの値に基づいてk個の最近傍距離をそれぞれ取得し、それらの平均値を取って異常度の数値とします。すなわち、test画像に最も性質の近いk枚の正常画像が平均してどの程度距離的に離れているかを見ていることになります。
この一連の処理は、コード中で以下のように記載されています。
# self.z_libとzとの距離を計算
distances = torch.linalg.norm(self.z_lib - z, dim=1)
# 距離が最も近いk個の値とそのインデックスを取得
values, indices = torch.topk(distances.squeeze(), self.k, largest=False)
# k個の距離の値を平均してz_scoreとする
z_score = values.mean()
ピクセル単位の異常度
test画像の第1, 2, 3層の出力を取得し、正常画像の特徴量マップself.feature_mapsと比較します。比較には、画像単位の異常度を算出するために用いたものと同じ、test画像に最も性質の近いk枚の正常画像を用います。
コードの該当部分は以下の通りです。
scaled_s_map = torch.zeros(1,1,self.image_size,self.image_size)
for idx, fmap in enumerate(feature_maps):
nearest_fmaps = torch.index_select(self.feature_maps[idx], 0, indices)
# min() because kappa=1 in the paper
s_map, _ = torch.min(torch.linalg.norm(nearest_fmaps - fmap, dim=1), 0, keepdims=True)
scaled_s_map += torch.nn.functional.interpolate(
s_map.unsqueeze(0), size=(self.image_size,self.image_size), mode='bilinear'
)
test画像とk枚の正常画像の各層の出力について、それぞれtorch.linalg.norm()によってピクセル単位でユークリッド距離を算出します。文章での説明ではわかりにくいと思うので、例として第1層の出力について各ステップで得られるテンソルの形状を追ってみましょう。
fmap : [1, 256, 56, 56] # test画像の特徴量マップ
nearest_fmaps : [k, 256, 56, 56] # test画像に性質の近いk枚の特徴量マップ
torch.linalg.norm: [k, 56, 56] # 両者の距離マップ
s_map : [1, 56, 56] # ピクセルごとに距離の最小値を取った異常度マップ
テンソルの形状の変化から、各ピクセルについて、要素数256のベクトル同士の距離として1つのスカラーを得る処理を行っていることが読み取れます。k枚の特徴量マップとの距離をそれぞれ計算し、最終的にそれらの最小値を該当ピクセルの異常度としています。図4にこの処理のイメージを示します。
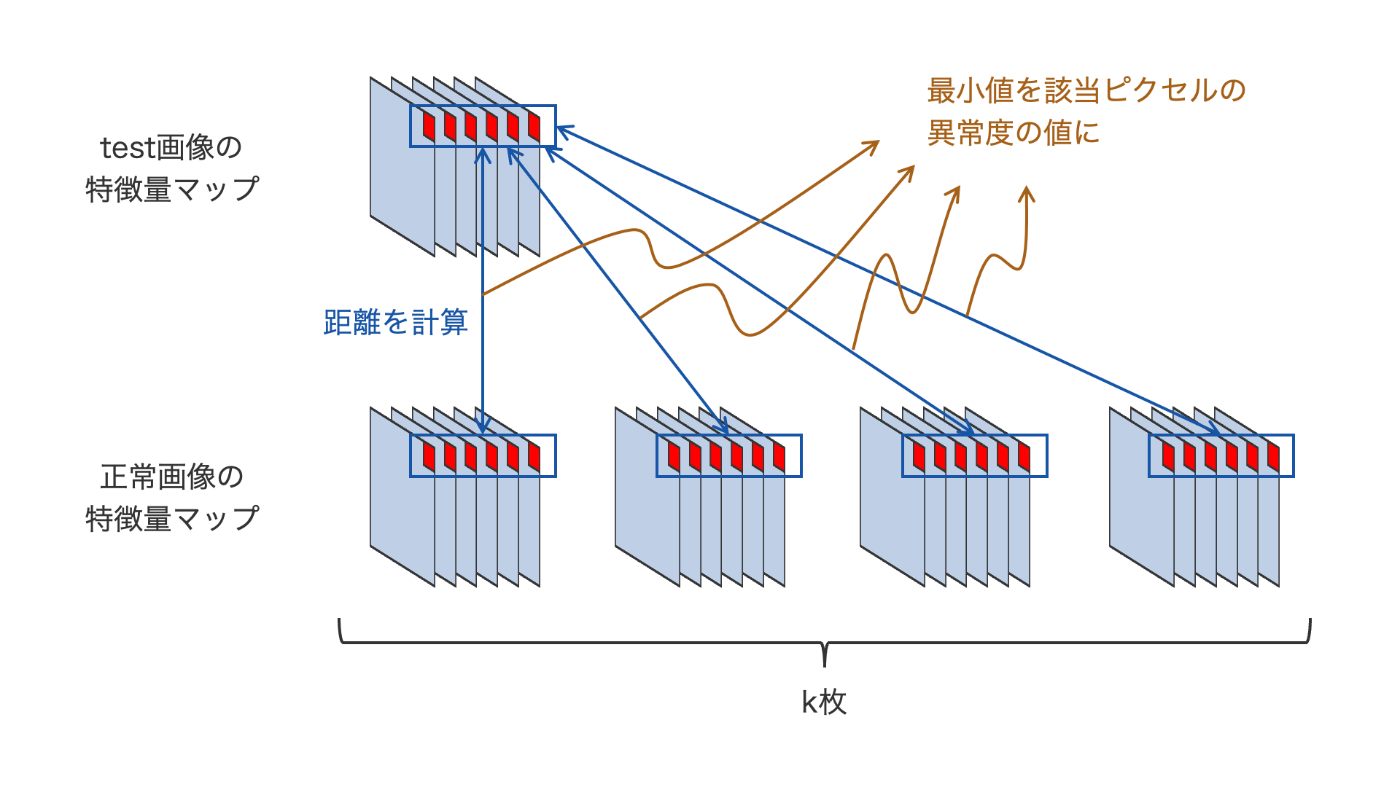
図4 ピクセル単位の距離計算イメージ
最後に、以下の処理によって異常度マップを元の画像サイズ(224x224)に引き伸ばして、ピクセル単位の異常度マップを出力します。
scaled_s_map += torch.nn.functional.interpolate(
s_map.unsqueeze(0), size=(self.image_size,self.image_size), mode='bilinear'
)
出力結果を見てみよう
ピクセル単位の異常度は、元画像と同じサイズの2次元配列として出力されます。これにカラーマップを適用して元画像にオーバーレイすることで、下のような画像を作成することができます。

図5 異常度マップの例
左が元画像、右が異常度マップをオーバーレイした画像です。異常度マップは赤に近づくほど異常度が高いことを表しています。ちゃんとナッツの殻が剥がれた部分やヒビの部分が異常として認識されていることがわかります。
使用データセット: https://www.mvtec.com/company/research/datasets/mvtec-ad
まとめ
以下にSPADEモデルが行う一連の処理をまとめます。
- 特徴量の抽出
- backendとして学習済みモデルを呼び出し、正常画像を入力する
- 第1, 2, 3層および最終層の出力を特徴量マップとして取り出して保持する
- 異常度の評価(推論)
- 画像単位の異常度: test画像と正常画像で最終層の出力どうしの距離を計算し、距離が最も近いk枚の距離の値を平均して異常度とする
- ピクセル単位の異常度: test画像とk枚の正常画像で対応するピクセルどうしの距離を計算し、その最小値を該当ピクセルの異常度とする
最後まで読んでいただきありがとうございました。
次回はSPADEの発展系であるPaDiMを取り上げたいと思います!

Discussion