はじめに
アクセンチュアでテクノロジー・アーキテクトとして活動している渡邊と申します。本日はアクセンチュアにおいて、複数人のテクノロジー・アーキテクトが集結し、Google Cloudをフル活用して課題解決に取り組んだプロジェクトについてご紹介します。
アクセンチュアには技術に深い造詣を持ち、システムの全体設計や方針の策定を行うメンバーをテクノロジー・アーキテクトと呼び、その専門の部署が存在します。今回はこの部署のメンバーがかかわった、お客様の基幹系システムをオンプレミスからクラウドへ移行するにあたってのPoCをご紹介します。
このプロジェクトは単純なリフト&シフトではなく、非機能要件を維持するために既存のアーキテクチャの刷新も含めた検討が必要となったため、アーキテクトの参画が求められました。Cloud Spannerをはじめとする様々なGoogle Cloudのサービスを活用して要件を実現しています。都度発生する課題もGoogle Cloudが提供するサービスを駆使しながら解決しており、その様子をお伝えできればと思います。
プロジェクト背景
今回のお客様は、年々増大するトランザクションを捌くためにオンプレミスで稼働する基幹系システムのハードウェア投資を続けてきました。クラウド化によって柔軟なリソース拡張を可能にすることで対応にかかるリードタイムやIT投資を削減すべく、今回のPoCに至りました。
今回対象となるシステムを構築する上でのポイントは以下の通りです。
- 高可用性およびデータ整合性: 基幹系システムということもあって、クラウド化においても高い可用性とデータロストやレプリケーションラグを極力防ぐことが大きな要件でした。
- 複雑な接続要件: 接続要件が異なる複数の他システムと接続するため、それぞれの要件を満たすワークロード選定が必要でした。
- スケーラビリティの確保: 検討の出発点になったトランザクション量に応じた動的なスケーリングが必要でした。
Google Cloud上で設計したアーキテクチャについて
今回はIT投資コストを抑えつつ高可用かつ強いデータ整合性を達成する必要があったため、マネージドサービスの中でこの要件を満たすDBとしてCloud Spannerを採用し、これを有するGoogle Cloudを中心にサービス選定を行いました。
前述の要件に対応するため、以下のようなサービス選定を行いました。
- 高可用性およびデータ整合性
- Cloud Spannerを採用しマルチリージョンでACT-ACT構成となるようにシステム全体を構成しました。
- システムはコンポーネントごとに分割・冗長化し、間の通信は分散メッセージング処理基盤を用いて耐障害性を高めました。基盤はマネージドサービスの上限によるスケール性の懸念から、自分たちでチューニングが可能なKafkaを採用しました。
- 複雑なクエリのないコンポーネントのDB はコストメリットが出ることを期待してFirestore(Datastoreモード)を採用ました。
- 複雑な接続要件
- 対外システムと接続するアプリケーションのワークロードはGoogle Kubernetes Engine, Google Compute Engineから接続要件に合わせたものを採用しました。
- スケーラビリティの確保:
- 水平スケールが可能な処理にはCloud Runを採用して、スケーラビリティを担保しつつ管理コストを削減しました。
Google Cloud上に乗せるアプリケーションには、パフォーマンスが優れ、コンテナとの親和性が高いGo言語を採用しました。また、インフラ構築にはTerraform, Helm, VM Manager を利用してテンプレート化し、開発効率の向上を図りました。
これらのアプリケーションを構築した後、PoCとして性能試験を行い、非機能要件に合わせてトランザクションを段階的に増やしても、スケールアウトして 所定のリクエストを処理できることを確認しました。
その他 Google Cloudを活用したところ
性能試験の実施においてはいくつかの課題に直面しており、その都度Google Cloudのサービスを活用しながら解決策を見出しています。特に今回苦労した点は以下の2つです。
- 本番環境相当のデータ投入
- 試験後の結果分析
今回、複数のデータベースを採用していたため、それぞれに本番環境相当の大量データを事前に準備するのが課題でした。Google CloudではCloud Dataflowで実行可能なデータのインポートジョブを提供しており、データのテンプレートファイルからSpannerおよびFirestore用のジョブに適したインプットを成型し、ジョブの起動までを一貫して行うツールを作成することで、データ投入を半自動化しました。
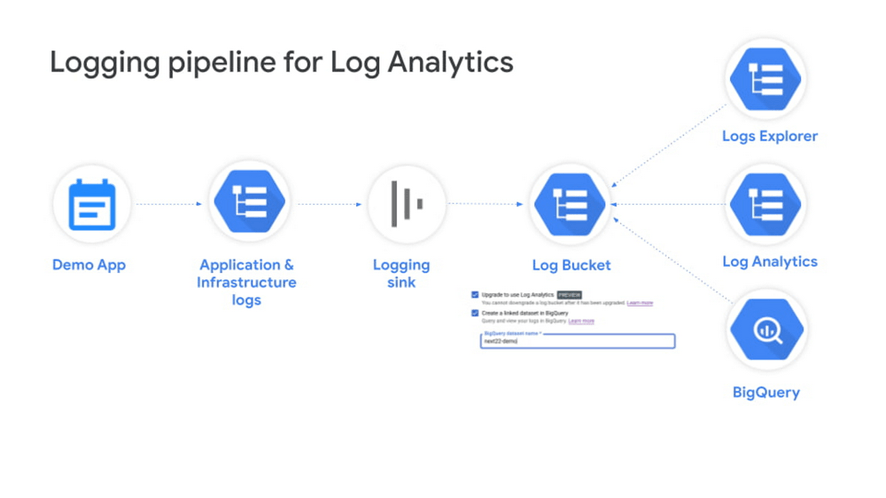
また、PoCの結果を整理する際には大量のログ分析が必要となることがわかり、途中でLog Analyticsの導入を行いました。大きなコスト増もなく、通常のSQLと同様なクエリで情報抽出・集計ができたため、使い勝手の良いサービスであると感じました。今回は入社3年目の若手メンバーが提案からプロダクトの構成・コスト感の調査まで含めて検討してくれた点もとても良かったと思います。
まとめ
今回は基幹系システムのクラウド移行のPoCとして、高可用かつスケーラビリティを備えたアーキテクチャとなるよう、Cloud Spannerを筆頭した様々なGoogle Cloudの製品を組み合わせて設計し、PoCを行いました。
プロジェクトを進める上で様々な課題はありましたが、都度Google Cloudのサービスを適切に利用しながら解決し、最終的に完遂することが出来ました。
アクセンチュアでは、このプロジェクトのように難しい要件を自ら手を動かしながら技術力で乗り越えていく意欲のあるメンバーを随時募集しています。興味がある方はぜひお問い合わせください。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion