Geminiのバッチ予測
「バッチ」とは、大規模なデータを処理することを意味します。Geminiモデルのバッチ予測とは、一度に多数のマルチモーダルのプロンプトをGeminiに送信できることを意味します。
バッチデータをGeminiに送信して予測することで、時間と計算リソースを節約できます。それは、ドキュメントによると、
「Gemini モデルのバッチ リクエストは、標準リクエストより 50% 割引される」
からです。
なぜバッチリクエストは割引されるのか。これはあくまでも私見ですが、Googleがデータを自分たちのクラウドに寄せる戦略の一旦かもしれません。パブリッククラウドベンダーはデータを保管するストレージの料金を安く抑えることでデータを呼び込み、その上のサービスの利用料を稼ぐ戦略を取っていると思います。
ITの世界は情報処理の自動化が目的です。情報処理が扱うのはデータです。最近では別のクラウドのデータも分析できるような機能が各ベンダーからだされていますが、いかに自分たちの陣営にデータを引き込むか、は重要な戦略です。
このブログでは、Gemini のバッチ予測を取得するで紹介されている手順を詳細に見ていきます。今回は、ローカルマシンのVS Codeで実施します。
事前準備
ローカル環境での認証設定
PythonのコードからGoogleのAPIを呼ぶ場合に、誰の権限で呼ぶかです。まずローカルで動作確認をするので自分のアカウントで呼ぶことにします。今回は自分はプロジェクトに対してオーナー権限を持っているとします。
- Terminalを開きます。なお、ここではpipなどのPythonのコマンドを打つことができます。
- Terminalで次のコマンドを打ちます。

[Your Browser has been opened to visit]の下に、URLが表示されます。これをクリックするとGoogle アカウントの認証画面に行きます。
3.次の画面に行き、許可を押すして[gcloud CLIの認証が完了しました]の画面が表示されれば成功です。


- Terminalで、以下のコマンドを実行し、Vertex AI SDK for Pythonと Vertex AI Python クライアント ライブラリをインストールします。
pip install --upgrade google-cloud-aiplatform
入力の準備
入力を準備するを参考にします。
以下の内容を記載したファイルをJSON形式で作成します。上記のページから1行目を直接ファイルにコピーしました。
{"request":{"contents": [{"role": "user", "parts": [{"text": "What is the relation between the following video and image samples?"}, {"file_data": {"file_uri": "gs://cloud-samples-data/generative-ai/video/animals.mp4", "mime_type": "video/mp4"}}, {"file_data": {"file_uri": "gs://cloud-samples-data/generative-ai/image/cricket.jpeg", "mime_type": "image/jpeg"}}]}]}}
{"request":{"contents": [{"role": "user", "parts": [{"text": "Describe what is happening in this video."}, {"file_data": {"file_uri": "gs://cloud-samples-data/generative-ai/video/another_video.mov", "mime_type": "video/mov"}}]}]}}
1つめのrequestを見てみます。このJSONは、Googleのバッチ予測リクエストであり、特定のビデオに関する説明を生成するためのものです。roleはuserであり、これはユーザーからのリクエストであることを示しています。また、partsは2つの要素を含んでいます。最初の要素はtextキーを持ち、ビデオの内容を説明するように指示するテキストが含まれています。2番目の要素はfile_dataキーを持ち、ビデオファイルのURIとMIMEタイプ(textやmp4といったファイルの種類を示す)が含まれています。
jsonの構文を間違えると次のエラーが出ます。これはParse error while creating BigQuery table using a JSON file with an autodetect flagにあるように、BigQueryと同じくCloud Storageは1 行につき 1 つの完全な JSON オブジェクトを受け入れるからのようです。詳しくは原因を参照ください。
message: "Failed to import data. Query error: Schema has no fields. Failed to parse JSON file for Load Data Statement at [1:1]"
2.上記のjasonファイルをCloud Storageのバケットに保存します。
以下のようなuriを得ることができます。
gs://[バケット名]/[フォルダ名]/sample.json
このuriは、jsonファイルをCloud Storage内でクリックすると以下の画面から得ることができます。

サンプルコードの記述と実行
サンプルコードの記述
バッチレスポンスをリクエストするで示されているサンプルコードを少し変えて実装します。これを新しいPythonのファイルにコピーして、1-10を参考に必要な個所を修正してください。
1.新規にPythonのファイルを作成します。VS Codeのツールバーで[File]>[New File]を選択します。その後、[Python File]を選択します。

2.ファイル名を変えて保存します。ここではbatch.pyとしています。

2. ここからサンプルコードを解説していきます。まず、必要なライブラリをimportします。
import time
import vertexai
from vertexai.batch_prediction import BatchPredictionJob
3.データのソースを指定します。BUCKETやOUTPUTにはご自身で作ったバケットやJSONファイル名を入れます。output_uriはinput_uriと同じバケットもよいです。
input_uri ="gs://[BUCKET]/[OUTPUT].json"
output_uri ="gs://[BUCKET]"
4.Vertex AIのオブジェクトをプログラムで操作できるようにインスタンス化し初期化します。
PROJECT_IDはご自身のProject IDを設定してください。
# Initialize vertexai
vertexai.init(project=PROJECT_ID, location="asia-northeast1")
ここで注意すべきことがあります。LocationはCloud Storageのバケットと同じにしてください。異なるlocationにすると、例えば実行中に以下のメッセージが出ます。これはCloud StorageのLocationがasia-northeast1で,ここで指定したvertexaiのlocationがus-central1の時に出るエラーとなります。
message: "Failed to import data. Invalid value: Cannot read and write in different locations: source: asia-northeast1, destination: us-central1 at [1:1]"
5.BatchPredictionJobクラスのsubmitメソッドを使用してバッチ予測ジョブを作成および送信しています。Geminiのモデルを指定し、バッチ予測を取得行します。あらかじめ定義してたinput_uriとoutput_uriを使います。ここでは"gemini-1.5-flash-002"というモデルを使用します。
# Submit a batch prediction job with Gemini model
batch_prediction_job = BatchPredictionJob.submit(
source_model="gemini-1.5-flash-002",
input_dataset=input_uri,
output_uri_prefix=output_uri,
)
指定されたモデルと入力データセット(input_uri)を使用してバッチ予測ジョブが作成され、結果が指定された場所(output_uri)に保存されます。
6. ジョブの状況を出力します。
次の3つの情報を出力しています:
batch_prediction_job.resource_name:ジョブのリソース名を表示します。
batch_prediction_job.model_name:ジョブに関連付けられているモデルのリソース名を表示します。
batch_prediction_job.state.name:ジョブの現在の状態を表示します。
# Check job status
print(f"Job resource name: {batch_prediction_job.resource_name}")
print(f"Model resource name with the job: {batch_prediction_job.model_name}")
print(f"Job state: {batch_prediction_job.state.name}")
- このループは、ジョブが完了するまで5秒ごとにジョブの状態を更新し続けます。batch_prediction_job.has_endedがFalseである間、ループを続けます。つまり、ジョブが終了していない間はループが続きます。また、5秒待った後、batch_prediction_job.refresh()でジョブの状態を更新します。これにより、ジョブの最新の状態を取得します。
# Refresh the job until complete
while not batch_prediction_job.has_ended:
time.sleep(5)
batch_prediction_job.refresh()
8.ジョブの実行結果を表示します。
# Check if the job succeeds
if batch_prediction_job.has_succeeded:
print("Job succeeded!")
else:
print(f"Job failed: {batch_prediction_job.error}")
- ジョブのアウトプットの場所を出力します。
# Check the location of the output
print(f"Job output location: {batch_prediction_job.output_location}")
10.サンプルには以下のコードがありますが、関数として返すわけではないので削除します。※コメントアウトしています。
# return batch_prediction_job
サンプルコードの実行
- Pythonのコードを実行します。次のように、Job succeeded!が出れば成功です。

2.生成されたファイルを参照します。Cloud Storageに次のような[incremenrtal_predictions]フォルダが作成されています。

3.predictions.jsonlのtextフィールドに、以下の回答が出力されています。
"This video is an advertisement for Google Photos. It shows how the app automatically backs up photos even when the camera is handled roughly, dropped in the water, or otherwise misused.\n\nThe inspiration for the video comes from the Disney movie Zootopia, where animals use technology like humans. The video shows various animals at the Los Angeles Zoo interacting with waterproofed cameras containing the Google Photos app. A sampling of the photos taken by the animals is shown."
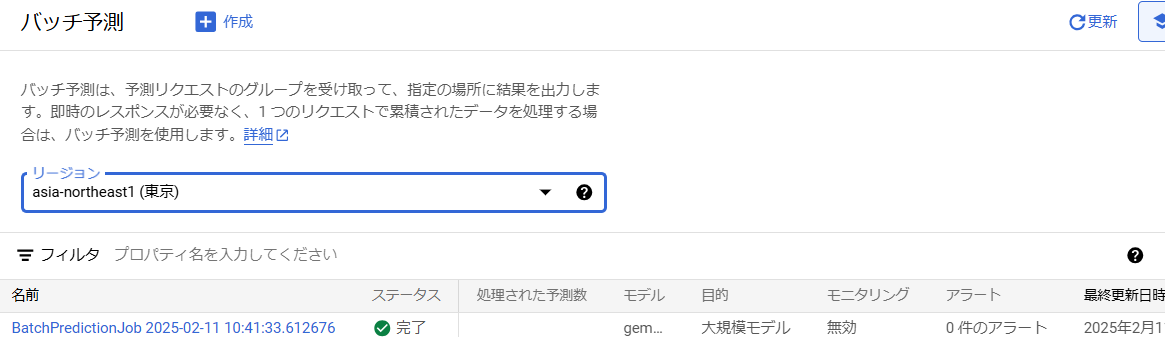
4.また、Vertx AIのバッチ予測タブに行くと、バッチの結果を見ることができます。
参考情報

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion