はじめに
No.1に続き第2回となります。
インターネットを調べていく中で、結果的に下記記事に行きつきました。
Open AIの資料を読む
LLMの精度の最適化アプローチとして、「コンテキスト最適化」「LLM最適化」を2つの考え方があるそうです。
「コンテキスト最適化」は、LLMの回答を分析した結果、LLMの知識が少ないケースが言えます。
「LLM最適化」は、LLMの回答がフォーマットが一貫していない(要件次第ですが)といった動作が一貫していないケースが言えます。
まずは、プロンプトを頑張り、「コンテキスト最適化」「LLM最適化」の観点でチューニングしていくイメージです。「コンテキスト最適化」はRAGを使うと良く、「LLM最適化」はファインチューニングを使うと良いとのことです。
ただ、大量データをRAGする場合、特にベクトル検索ではうまく回答を出せないケースもあり、「コンテキスト最適化」を検討する場合だとしても、私としてはファインチューニングも選択肢と考えています。
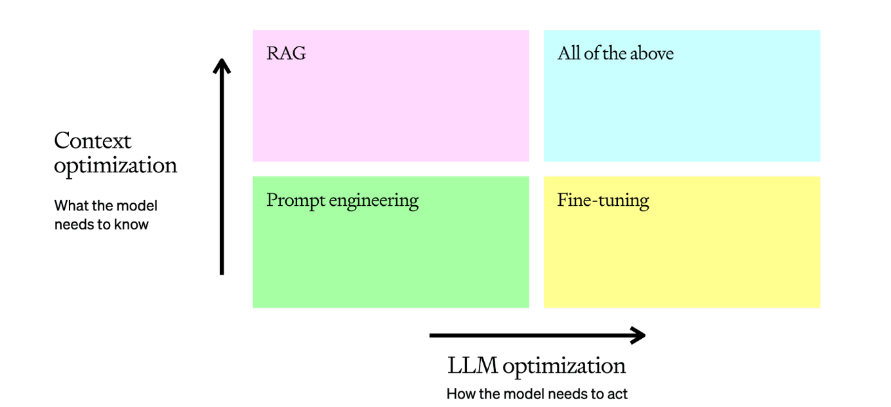
精度の最適化のアプローチ手順を可視化したものが下記となります。なんとなくイメージつきますね。

また、今回のトピックから外れる話題ですが、この記事を読み進めるともう1つ重要なことが記載されています。
最初の要件についてです。
LLMを導入する際、「回答生成がうまくいった場合の効果」「失敗した場合の損失」「うまくいく確率」を明確にしていくことです。
これは、事前に利用者ときちんとシュミレーションして合意をとることが重要だと考えています。
いずれにせよ、100%の精度で回答することは難しく、期待値コントルールが重要ですね。

違いを整理してみる
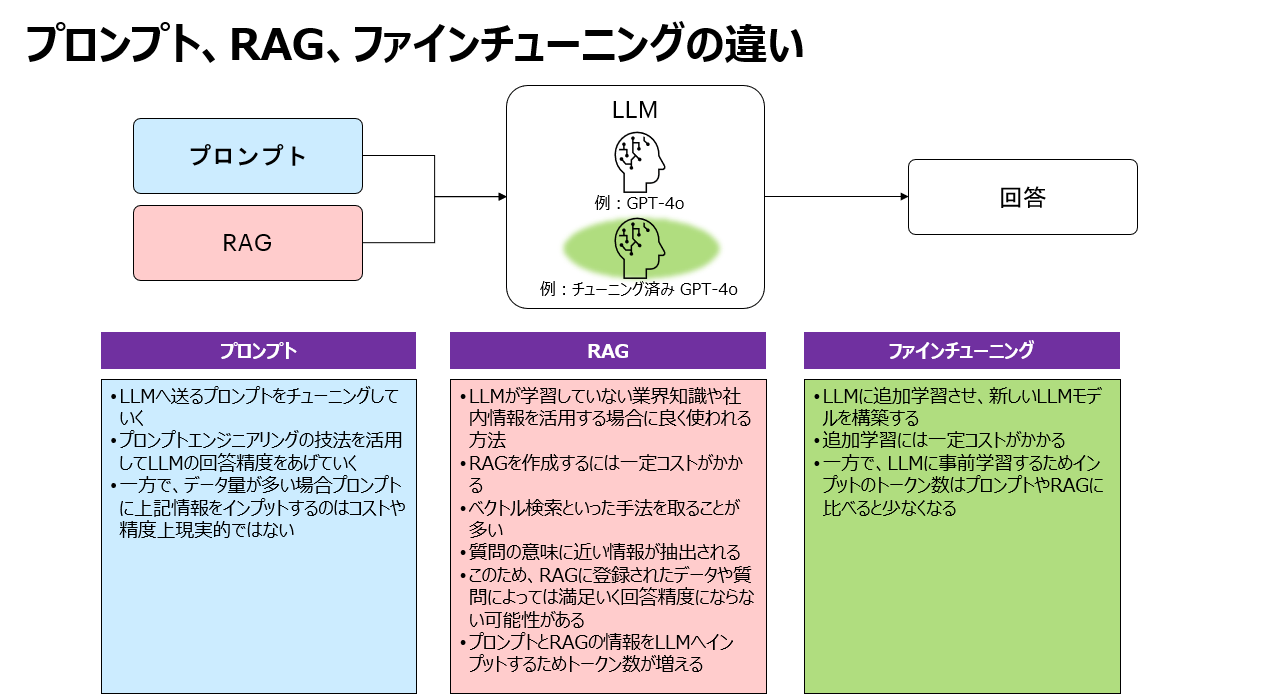
それぞれの違いを整理してみると下記のようになりました。
前述のOpen AIの記事を読んでもわかりますが、それぞれのアプローチでメリット/デメリットがあります。組み合わせのアプローチももちろんとれるので、組み合わせもぜひ検討していきましょう。
応答時間やトークン数
最近、RAGが注目されていますが、前述のとおりファインチューニングも侮れません。LLMへ連携するトークン数はファインチューニングが少なくなります。また、RAGが苦手なケースもあります。RAG一本足打法ではなく、「プロンプト」「RAG」「ファインチューニング」の特徴を理解して取捨選択や組み合わせていくことが重要です。
RAGに変わるナレッジGraph RAG
RAGのベクトル検索が故に、データや質問によっては回答にたどり着きにくい課題に対して、Graph RAGという技術にも注目が集まっています。
下記記事が大変参考になったので、ぜひ皆さんもご覧になってください。
また、富士通が「エンタープライズ生成AIフレームワーク」を提供するプレスリリースを発表しました。この中で「ナレッジグラフ拡張RAG」という記載があり、恐らくGraph RAGを応用したものと考えています。
さいごに
この記事では「プロンプト」「RAG」「ファインチューニング」の違いについて記載してきましたが、「RAG」1つとっても欠点を補う新しい考え方や技術が日々発表されています。
ぜひぜひ、私含めて日々勉強していきましょう!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion