
1. はじめに
ChatGPTを起点にAIに関心を持たれた方が多いと思います。そこで出てくるのがML(Machine Learning)と呼ばれる機械学習ですが、なかなかとっつきにくいと思います。
この記事では、そんな方に向けて機械学習の基礎的な部分をハンズオンをしながら学習できるようにまとめました。
なお、この記事では具体的なアルゴリズムの違いや特徴までは説明しません。ハンズオンを通して全体像を掴んだうえで、次のステップとして具体的なアルゴリズムについて学習を進めて頂ければと思います。なお、ランダムフォレスト(Random Forest)というアルゴリズムを使っています。
今回のハンズオンで構築するのは、「アヤメ」という植物について、花びら等の情報から種類を予測する仕組みです。構成は下記となります。

アーキテクチャ図
2. 環境構築
まずは、環境構築をしていきましょう。PythonやDockerの構築手順となります。既に環境が整っている方は飛ばしてください!
OS別に記載しています。
Linux (Ubuntu/Debian)
# 必要なパッケージのインストール
sudo apt update
sudo apt install -y python3 python3-pip python3-venv git curl
# Pythonバージョンの確認
python3 --version
# uvのインストール
pip3 install uv
# Docker CEのインストール
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt update
sudo apt install -y docker-ce
# Dockerサービスの開始と自動起動の設定
sudo systemctl start docker
sudo systemctl enable docker
# 現在のユーザーをdockerグループに追加(再ログインが必要)
sudo usermod -aG docker $USER
Linux (CentOS/RHEL/Fedora)
# 必要なパッケージのインストール
sudo dnf update
sudo dnf install -y python3 python3-pip git curl
# Pythonバージョンの確認
python3 --version
# uvのインストール
pip3 install uv
# Docker CEのインストール
sudo dnf install -y dnf-plugins-core
sudo dnf config-manager --add-repo https://download.docker.com/linux/fedora/docker-ce.repo
sudo dnf install -y docker-ce docker-ce-cli containerd.io
# Dockerサービスの開始と自動起動の設定
sudo systemctl start docker
sudo systemctl enable docker
# 現在のユーザーをdockerグループに追加(再ログインが必要)
sudo usermod -aG docker $USER
macOS
# Homebrewのインストール(まだインストールされていない場合)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# Pythonのインストール
brew install python
# Pythonバージョンの確認
python3 --version
# uvのインストール
pip3 install uv
# Dockerのインストール(Docker Desktop for Mac)
brew install --cask docker
# Docker Desktopを起動
open /Applications/Docker.app
または、公式サイトからDocker Desktop for Macをダウンロードしてインストールすることもできます。
Windows
1. Pythonのインストール
- Python公式サイトから最新のPythonインストーラーをダウンロード
- インストーラーを実行し、「Add Python to PATH」オプションを必ずチェック
- 「Install Now」をクリックしてインストール
- インストール完了後、コマンドプロンプトを開いて以下のコマンドでPythonとpipが正しくインストールされたか確認
python --version
pip --version
2. uvのインストール
コマンドプロンプトまたはPowerShellを開いて以下のコマンドを実行:
pip install uv
3. Gitのインストール(必要な場合)
- Git公式サイトからGitインストーラーをダウンロード
- インストーラーを実行し、デフォルト設定でインストール
4. Dockerのインストール
- Docker Desktop for Windowsをダウンロード
- インストーラーを実行
- WSL 2バックエンドを使用するオプションを選択(推奨)
- インストール完了後、Docker Desktopを起動
- コマンドプロンプトまたはPowerShellを開いて以下のコマンドでDockerが正しくインストールされたか確認
docker --version
3. 構成
まずは構成について理解しましょう。
ディレクトリ構成は以下の通りです:
ml_docker_project/
├── data/ # データセットと評価結果の保存先
├── model/ # 訓練済みモデルの保存先
├── scripts/ # Pythonスクリプト
│ ├── train_model.py # モデル訓練用スクリプト
│ ├── predict.py # CLI予測用スクリプト
│ └── app.py # Web API用スクリプト
├── Dockerfile # Dockerイメージ定義ファイル
└── requirements.txt # 必要なPythonライブラリ一覧
各ファイルの役割:
- train_model.py: アイリスデータセットを読み込み、ランダムフォレスト分類器を訓練し、モデルを保存します
- predict.py: 保存されたモデルを読み込み、コマンドライン引数から特徴量を受け取り、予測結果を出力します
- app.py: FastAPIを使用してWeb APIサーバーを提供し、JSONリクエストから予測を行います
- Dockerfile: Pythonベースイメージを使用し、必要なライブラリをインストールし、CLIとAPIの両方に対応したコンテナを定義します
4. セットアップ
いよいよセットアップしましょう。手順を踏みながら学習データを作成して、実際に予測を試してみます。
プロジェクトディレクトリの作成
# 環境変数設定
# Linux/macOS
export PATH="$HOME/.local/bin:$PATH"
# プロジェクトディレクトリの作成
mkdir -p ml_docker_project
cd ml_docker_project
mkdir -p model data scripts
# 仮想環境の作成と有効化
# Linux/macOS
uv venv
source .venv/bin/activate
# Windows (コマンドプロンプト)
uv venv
.venv\Scripts\activate.bat
# Windows (PowerShell)
uv venv
.venv\Scripts\Activate.ps1
必要なファイルの作成
requirements.txt
requirements.txt
cat > requirements.txt << 'EOF'
scikit-learn==1.2.2
pandas==2.0.3
numpy==1.24.3
joblib==1.3.2
matplotlib==3.7.2
seaborn==0.12.2
fastapi>=0.115.2
uvicorn>=0.23.2
pydantic>=2.7.2
starlette>=0.40.0
anyio>=4.7.0
langchain>=0.3.23
EOF
Windows環境では、requirements.txtファイルを手動で作成してください。
依存パッケージのインストール
# Linux/macOS
uv pip install -r requirements.txt
# Windows
uv pip install -r requirements.txt
5. モデルの訓練と実行
モデル訓練スクリプトの作成
scripts/train_model.pyファイルを作成し、以下の内容を記述します(各OSで共通):
scripts/train_model.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
アイリスデータセットを使用した機械学習モデルの訓練スクリプト
このスクリプトは以下の処理を行います:
1. アイリスデータセットの読み込み
2. データの前処理(トレーニングデータとテストデータに分割)
3. ランダムフォレスト分類器の訓練
4. モデルの評価
5. モデルの保存
"""
import os
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
import joblib
import matplotlib.pyplot as plt
import seaborn as sns
# 出力ディレクトリの設定
MODEL_DIR = "../model"
DATA_DIR = "../data"
os.makedirs(MODEL_DIR, exist_ok=True)
os.makedirs(DATA_DIR, exist_ok=True)
def load_and_prepare_data():
"""アイリスデータセットを読み込み、前処理を行う"""
print("データセットを読み込んでいます...")
# アイリスデータセットの読み込み
iris = load_iris()
X = iris.data
y = iris.target
feature_names = iris.feature_names
target_names = iris.target_names
# データフレームの作成
df = pd.DataFrame(X, columns=feature_names)
df['species'] = [target_names[i] for i in y]
df['target'] = y
# データの保存
df.to_csv(os.path.join(DATA_DIR, "iris_dataset.csv"), index=False)
print(f"データセットを {os.path.join(DATA_DIR, 'iris_dataset.csv')} に保存しました")
# データの可視化
plt.figure(figsize=(12, 10))
sns.pairplot(df, hue='species', vars=feature_names)
plt.savefig(os.path.join(DATA_DIR, "iris_visualization.png"))
print(f"データの可視化を {os.path.join(DATA_DIR, 'iris_visualization.png')} に保存しました")
# トレーニングデータとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
return X_train, X_test, y_train, y_test, feature_names, target_names
def train_model(X_train, y_train):
"""ランダムフォレスト分類器を訓練する"""
print("モデルを訓練しています...")
# ランダムフォレスト分類器の初期化
model = RandomForestClassifier(
n_estimators=100,
max_depth=5,
random_state=42
)
# モデルの訓練
model.fit(X_train, y_train)
return model
def evaluate_model(model, X_test, y_test, target_names):
"""モデルの評価を行う"""
print("モデルを評価しています...")
# テストデータでの予測
y_pred = model.predict(X_test)
# 精度の計算
accuracy = accuracy_score(y_test, y_pred)
print(f"精度: {accuracy:.4f}")
# 分類レポートの表示
report = classification_report(y_test, y_pred, target_names=target_names)
print("分類レポート:")
print(report)
# 評価結果をファイルに保存
with open(os.path.join(DATA_DIR, "model_evaluation.txt"), "w") as f:
f.write(f"精度: {accuracy:.4f}\n\n")
f.write("分類レポート:\n")
f.write(report)
print(f"評価結果を {os.path.join(DATA_DIR, 'model_evaluation.txt')} に保存しました")
return accuracy, report
def save_model(model, feature_names):
"""モデルを保存する"""
print("モデルを保存しています...")
# モデルの保存
model_path = os.path.join(MODEL_DIR, "iris_model.pkl")
joblib.dump(model, model_path)
print(f"モデルを {model_path} に保存しました")
# 特徴量の重要度の可視化
plt.figure(figsize=(10, 6))
importances = model.feature_importances_
indices = np.argsort(importances)[::-1]
plt.title('特徴量の重要度')
plt.bar(range(len(feature_names)), importances[indices], align='center')
plt.xticks(range(len(feature_names)), [feature_names[i] for i in indices], rotation=90)
plt.tight_layout()
plt.savefig(os.path.join(DATA_DIR, "feature_importance.png"))
print(f"特徴量の重要度を {os.path.join(DATA_DIR, 'feature_importance.png')} に保存しました")
def main():
"""メイン関数"""
print("アイリスデータセットを使用したモデル訓練を開始します...")
# データの読み込みと前処理
X_train, X_test, y_train, y_test, feature_names, target_names = load_and_prepare_data()
# モデルの訓練
model = train_model(X_train, y_train)
# モデルの評価
evaluate_model(model, X_test, y_test, target_names)
# モデルの保存
save_model(model, feature_names)
print("モデル訓練が完了しました!")
if __name__ == "__main__":
main()
CLI予測スクリプトの作成
scripts/predict.pyファイルを作成し、以下の内容を記述します:
scripts/predict.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
アイリスデータセットで訓練したモデルを使用した予測スクリプト
このスクリプトは以下の処理を行います:
1. 保存されたモデルの読み込み
2. コマンドライン引数から特徴量を受け取る
3. 予測の実行
4. 結果の出力
"""
import argparse
import joblib
import os
import numpy as np
# モデルファイルのパス
# Dockerコンテナ内と通常の実行環境の両方に対応
if os.path.exists("./iris_model.pkl"):
MODEL_PATH = "./iris_model.pkl"
else:
MODEL_PATH = "../model/iris_model.pkl"
def load_model():
"""保存されたモデルを読み込む"""
if not os.path.exists(MODEL_PATH):
raise FileNotFoundError(f"モデルファイルが見つかりません: {MODEL_PATH}")
return joblib.load(MODEL_PATH)
def predict(model, features):
"""特徴量を使用して予測を行う"""
# 特徴量を2次元配列に変換
features_array = np.array(features).reshape(1, -1)
# 予測の実行
prediction = model.predict(features_array)
probabilities = model.predict_proba(features_array)
return prediction[0], probabilities[0]
def main():
"""メイン関数"""
# コマンドライン引数の設定
parser = argparse.ArgumentParser(description="アイリスの品種を予測します")
parser.add_argument("--sepal_length", type=float, required=True, help="萼片の長さ (cm)")
parser.add_argument("--sepal_width", type=float, required=True, help="萼片の幅 (cm)")
parser.add_argument("--petal_length", type=float, required=True, help="花弁の長さ (cm)")
parser.add_argument("--petal_width", type=float, required=True, help="花弁の幅 (cm)")
args = parser.parse_args()
try:
# モデルの読み込み
model = load_model()
# 特徴量の取得
features = [
args.sepal_length,
args.sepal_width,
args.petal_length,
args.petal_width
]
# 予測の実行
prediction, probabilities = predict(model, features)
# アイリスの品種名
iris_species = ['setosa', 'versicolor', 'virginica']
# 結果の出力
print(f"予測結果: {iris_species[prediction]} (クラス {prediction})")
print("各クラスの確率:")
for i, species in enumerate(iris_species):
print(f" {species}: {probabilities[i]:.4f}")
except Exception as e:
print(f"エラーが発生しました: {e}")
return 1
return 0
if __name__ == "__main__":
exit(main())
Web APIスクリプトの作成
scripts/app.pyファイルを作成し、以下の内容を記述します:
scripts/app.py
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
アイリスデータセットで訓練したモデルを使用したWeb APIサーバー
このスクリプトは以下の処理を行います:
1. 保存されたモデルの読み込み
2. FastAPIを使用したWeb APIの提供
3. JSONリクエストからの特徴量の受け取り
4. 予測の実行と結果の返却
"""
import os
import joblib
import numpy as np
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import uvicorn
# モデルファイルのパス
# Dockerコンテナ内と通常の実行環境の両方に対応
if os.path.exists("./iris_model.pkl"):
MODEL_PATH = "./iris_model.pkl"
else:
MODEL_PATH = "../model/iris_model.pkl"
# モデルの読み込み
try:
model = joblib.load(MODEL_PATH)
print(f"モデルを読み込みました: {MODEL_PATH}")
except FileNotFoundError:
print(f"警告: モデルファイルが見つかりません: {MODEL_PATH}")
print("APIは起動しますが、予測エンドポイントは機能しません。")
model = None
# FastAPIアプリケーションの作成
app = FastAPI(
title="アイリス分類API",
description="アイリスの特徴量から品種を予測するAPI",
version="1.0.0"
)
# 入力データのスキーマ定義
class IrisFeatures(BaseModel):
sepal_length: float
sepal_width: float
petal_length: float
petal_width: float
# 出力データのスキーマ定義
class IrisPrediction(BaseModel):
species: str
species_id: int
probabilities: dict
# ルートエンドポイント
@app.get("/")
def read_root():
"""APIのルートエンドポイント"""
return {
"message": "アイリス分類APIへようこそ",
"status": "稼働中",
"endpoints": {
"/predict": "アイリスの品種を予測(POST)",
"/docs": "APIドキュメント(Swagger UI)"
}
}
# 予測エンドポイント
@app.post("/predict", response_model=IrisPrediction)
def predict(features: IrisFeatures):
"""アイリスの特徴量から品種を予測する"""
if model is None:
raise HTTPException(status_code=503, detail="モデルが読み込まれていません")
# 特徴量の取得
feature_array = np.array([
features.sepal_length,
features.sepal_width,
features.petal_length,
features.petal_width
]).reshape(1, -1)
# 予測の実行
prediction = model.predict(feature_array)[0]
probabilities = model.predict_proba(feature_array)[0]
# アイリスの品種名
iris_species = ['setosa', 'versicolor', 'virginica']
# 確率を辞書形式に変換
prob_dict = {species: float(prob) for species, prob in zip(iris_species, probabilities)}
# 結果の返却
return {
"species": iris_species[prediction],
"species_id": int(prediction),
"probabilities": prob_dict
}
# メイン関数(直接実行された場合)
if __name__ == "__main__":
uvicorn.run("app:app", host="0.0.0.0", port=8082, reload=True)
Dockerfileの作成
プロジェクトのルートディレクトリにDockerfileを作成し、以下の内容を記述します:
Dockerfile
# ベースイメージとしてPythonの軽量イメージを使用
FROM python:3.10-slim
# 作業ディレクトリの設定
WORKDIR /app
# 依存ライブラリリストをコピーしてインストール
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# ソースコードとモデルファイルをコンテナにコピー
COPY scripts/predict.py scripts/app.py ./
COPY model/iris_model.pkl ./
# コンテナ起動時のエントリーポイントをPythonに設定
ENTRYPOINT ["python"]
# デフォルトの実行コマンドをAPIサーバ起動に設定
CMD ["app.py"]
# Web API用途の場合に備えてポートを開放
EXPOSE 8082
モデルの訓練と実行
準備ができたところで、モデルを訓練しましょう。
cd scripts
python train_model.py
CLIでの予測実行
訓練した学習モデルで予測されているか確認しましょう。
python predict.py --sepal_length 5.1 --sepal_width 3.5 --petal_length 1.4 --petal_width 0.2
下記のように実行されるはずです!
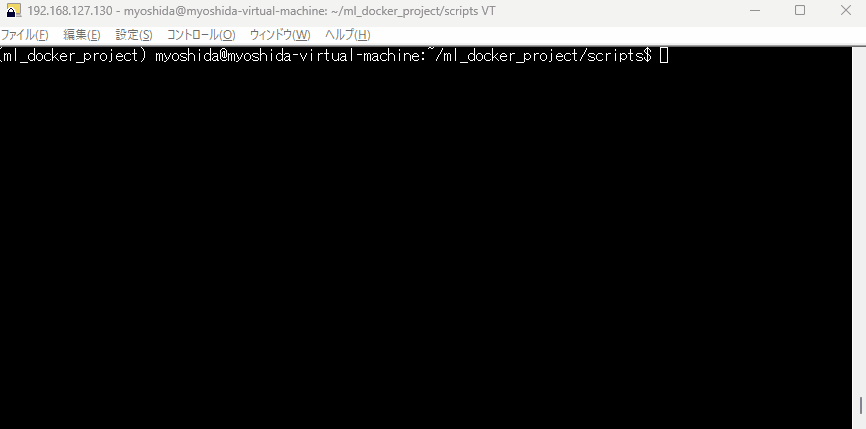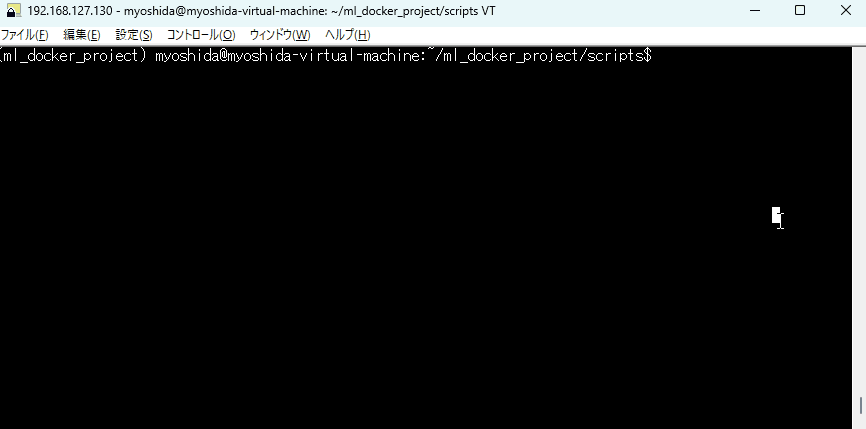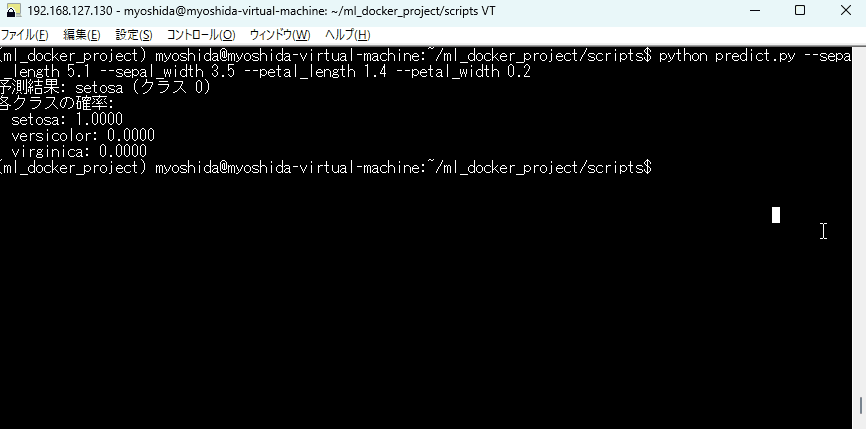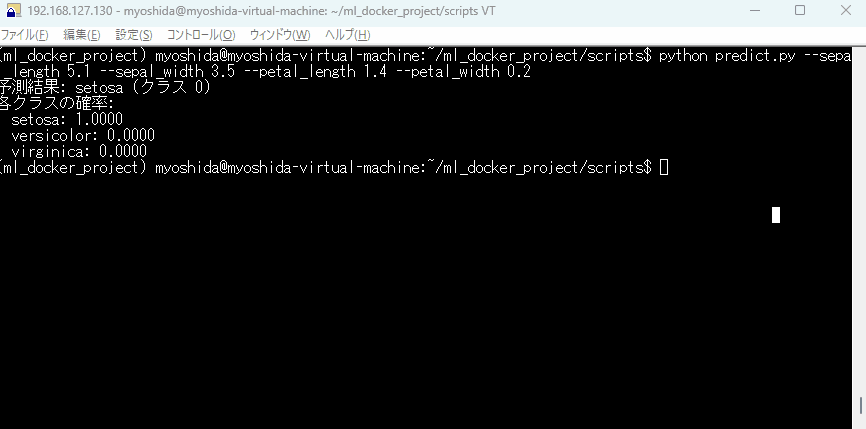
CLIでの予測実行の様子
Web APIサーバーの起動
python app.py
下記のように動かせるはずです!
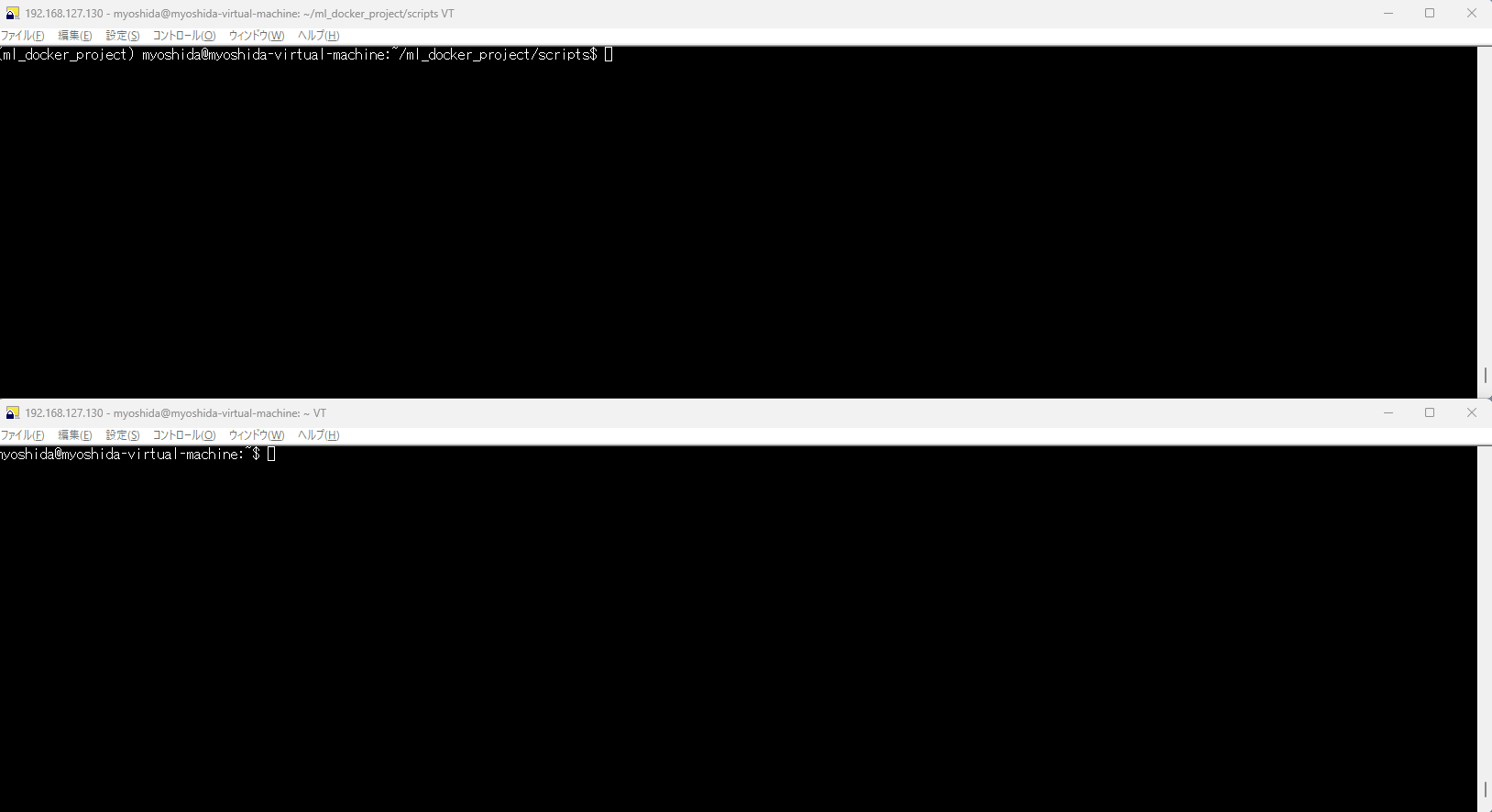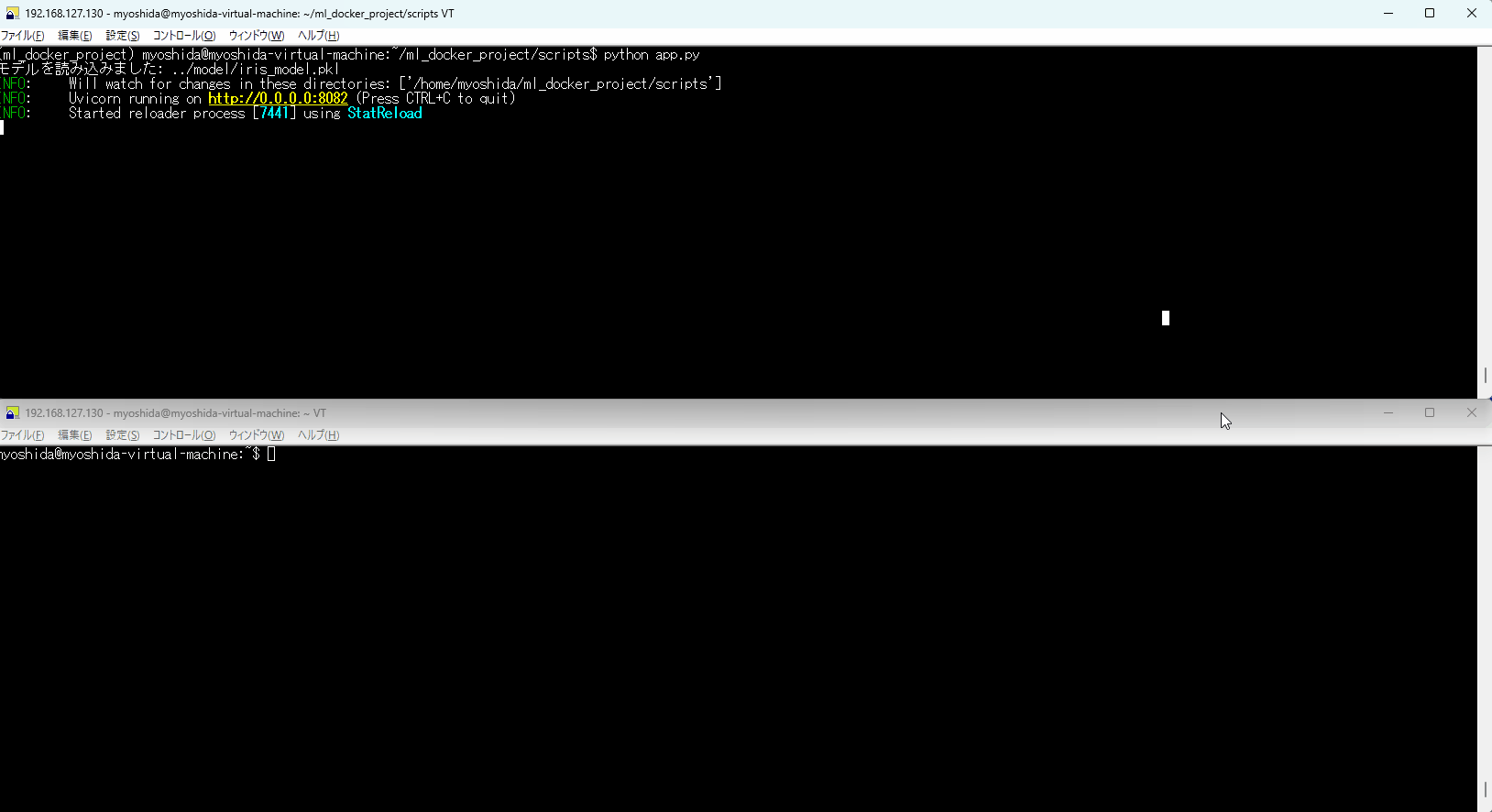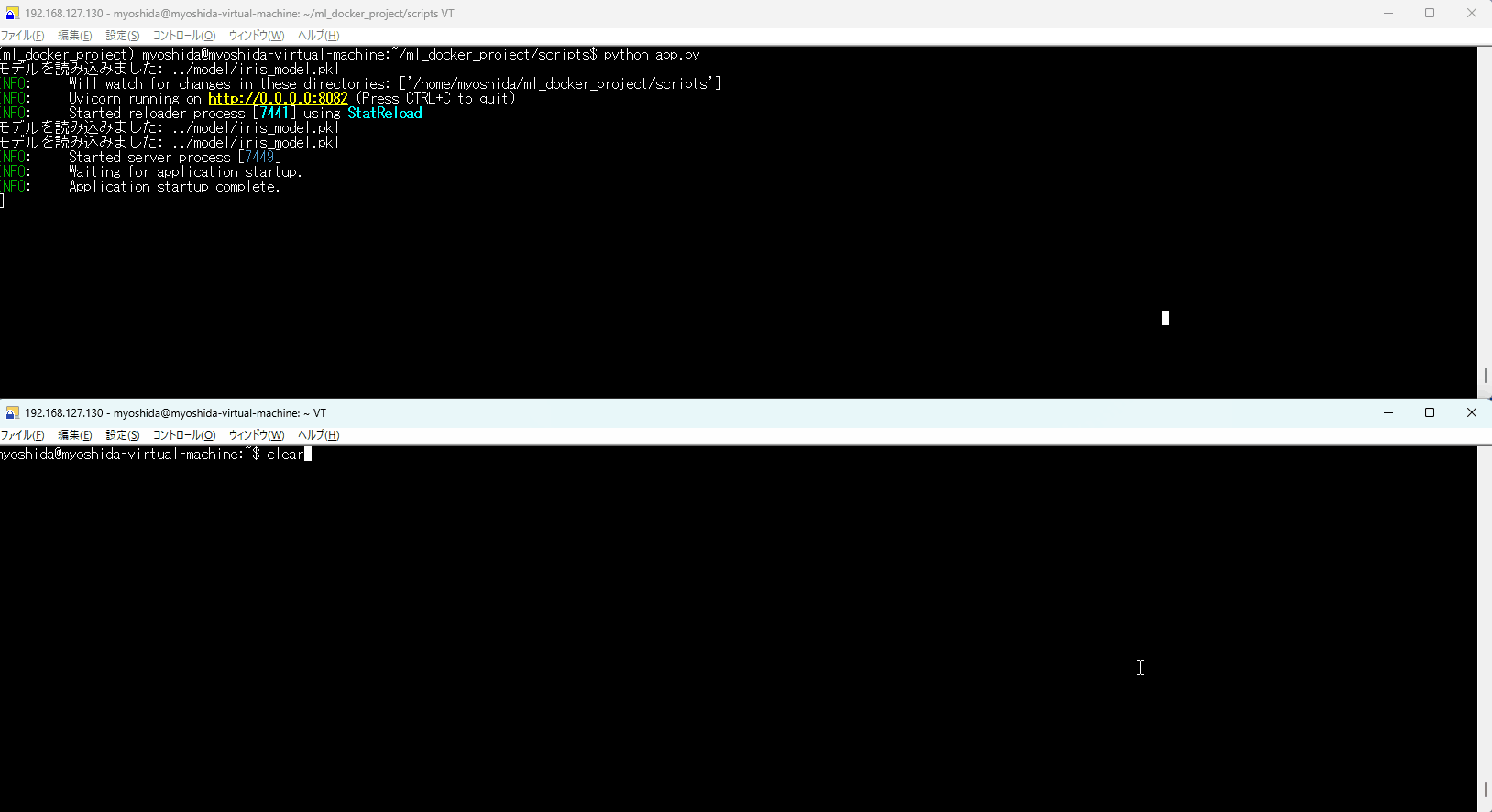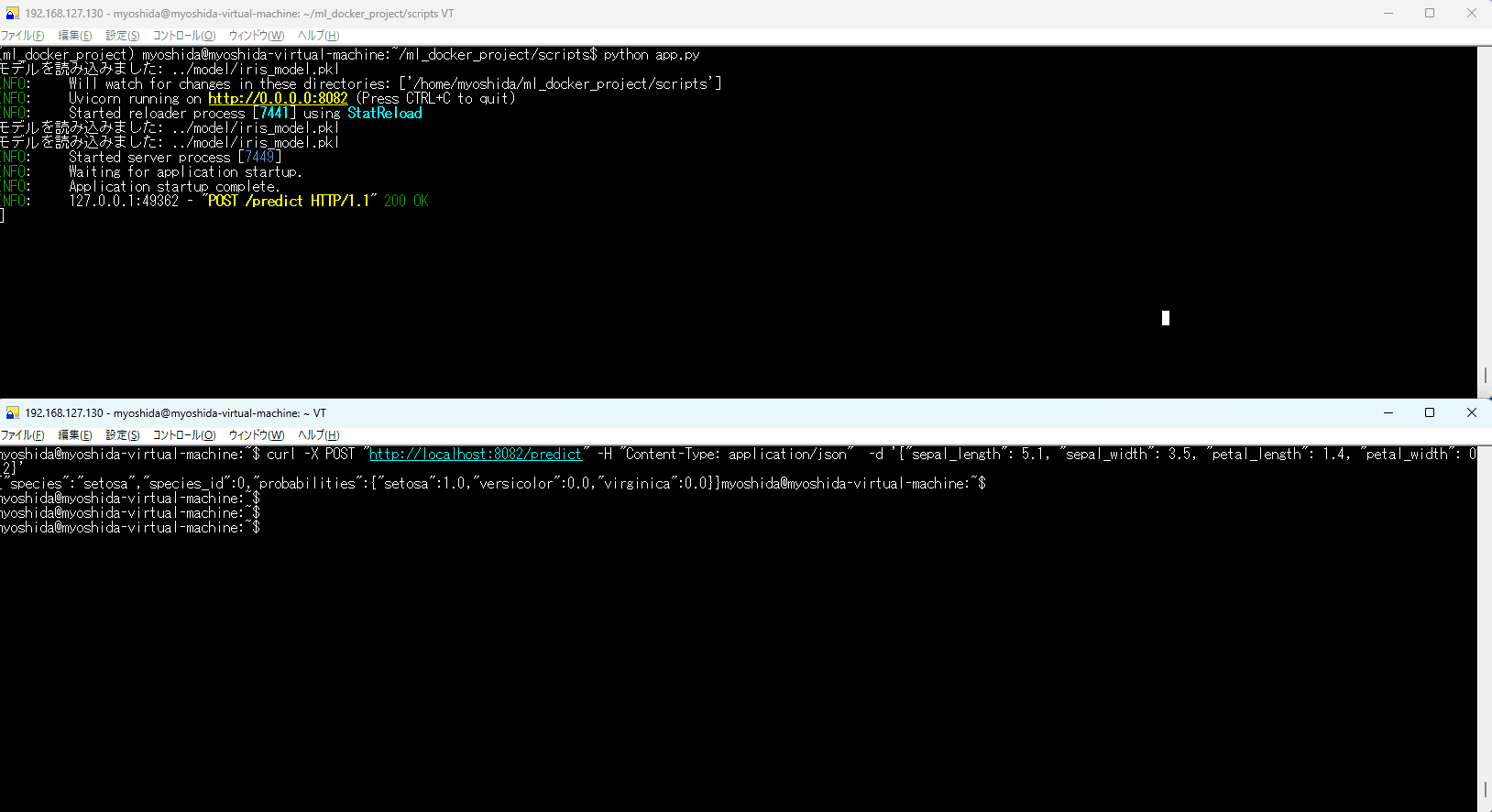
Web APIサーバ起動の様子
なお、API通信しているときのコマンドは下記となります。
curl -X POST "http://localhost:8082/predict" -H "Content-Type: application/json" -d '{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}'
6. Dockerイメージの作成と実行
それでは、作成した学習済みモデルやPythonをDockerイメージに格納しましょう!そして、Dockerコンテナを起動しましょう!
Dockerイメージのビルド
# プロジェクトのルートディレクトリに戻る
cd ..
# Dockerイメージのビルド(全OS共通)
docker build -t iris-ml-app:latest .
Docker上でのWeb APIサーバーの実行
# APIサーバーとして起動(全OS共通)
docker run -p 8082:8082 iris-ml-app:latest
Docker上でのCLI予測の実行
# CLIモードで予測を実行(全OS共通)
docker run --rm iris-ml-app:latest predict.py --sepal_length 5.1 --sepal_width 3.5 --petal_length 1.4 --petal_width 0.2
# APIで予測を実行(全OS共通)
curl -X POST "http://192.168.127.130:8082/predict" -H "Content-Type: application/json" -d '{"sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2}'
7. おわりに
いかがでしたか。この記事を参考にぜひ、機械学習の世界を体感頂けたらと思います!
なお、今回ランダムフォレストというアルゴリズムを使っています!
ランダムフォレストの説明
以下の特徴を持つ教師あり学習アルゴリズムです。
基本概念
- 複数の決定木(Decision Tree)モデルを組み合わせたアンサンブル学習手法
- 各決定木はデータセットからブートストラップサンプリング(重複を許した無作為抽出)で作成
- 各ノードの分割時に特徴量のサブセットをランダムに選択
技術的特徴
- バギング(Bagging: Bootstrap Aggregating)の一種で、複数モデルの平均化または多数決で予測を行う
- 各木が異なるデータサブセットと特徴量サブセットで学習するため、モデル間の相関が低減
- 分類問題では多数決、回帰問題では平均値で最終予測を決定
利点
- 過学習(オーバーフィッティング)に強い
- 外れ値に対して堅牢
- 特徴量の重要度を評価可能
- チューニングが比較的容易
- 並列処理に適している
アイリスの花の分類のような比較的シンプルなタスクから、より複雑な多クラス分類、回帰問題まで幅広く適用可能な、実用的かつ効果的なアルゴリズムです。
課題によっては使うアルゴリズムが異なるので、ぜひ課題に合わせてアルゴリズムを検討してみてください!

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion