はじめに
私の投稿も90件を超えてきて、調べたい事が探しづらい課題が顕在化しようとしています。そこで、Zenn記事をRAGにつめこんでDifyで記事を検索するアプリを作ってみました。どのように作ったのか、特にRAGにおいて気づいた示唆をお伝えできればと考えています。
内容が難しいと感じた方は、下記記事をまず読んでみてください!
DifyでRAGを活用したチャットボットを構築する(簡易編)
https://zenn.dev/acntechjp/articles/0b2891bbcb6152
全体像
作ったアプリの全体像はこんな感じです。
アーキテクチャはいたってシンプルです。
ただ、「Zenn記事データ」がRAGの部分になるのですが、どのように作るか、チューニングするかが重要になってきます。

チャットボットの回答イメージです。
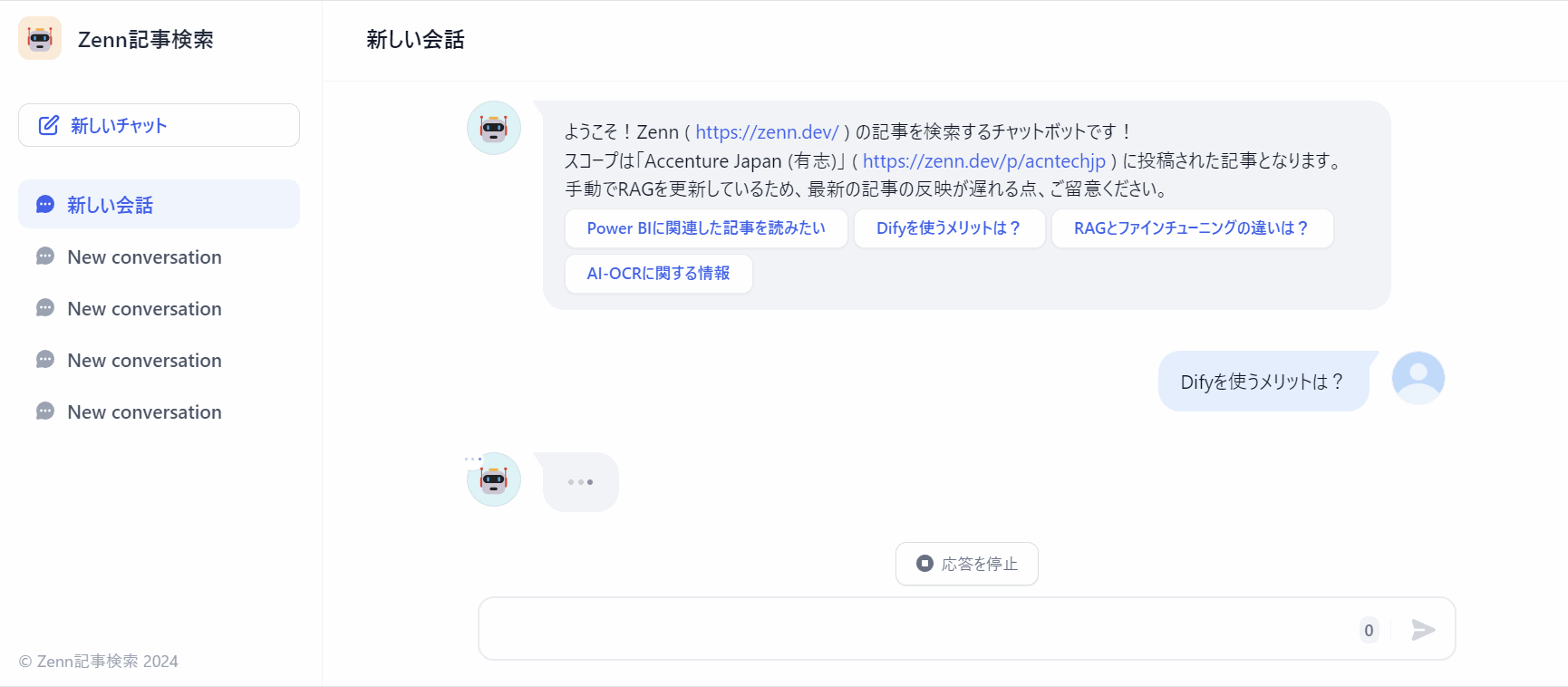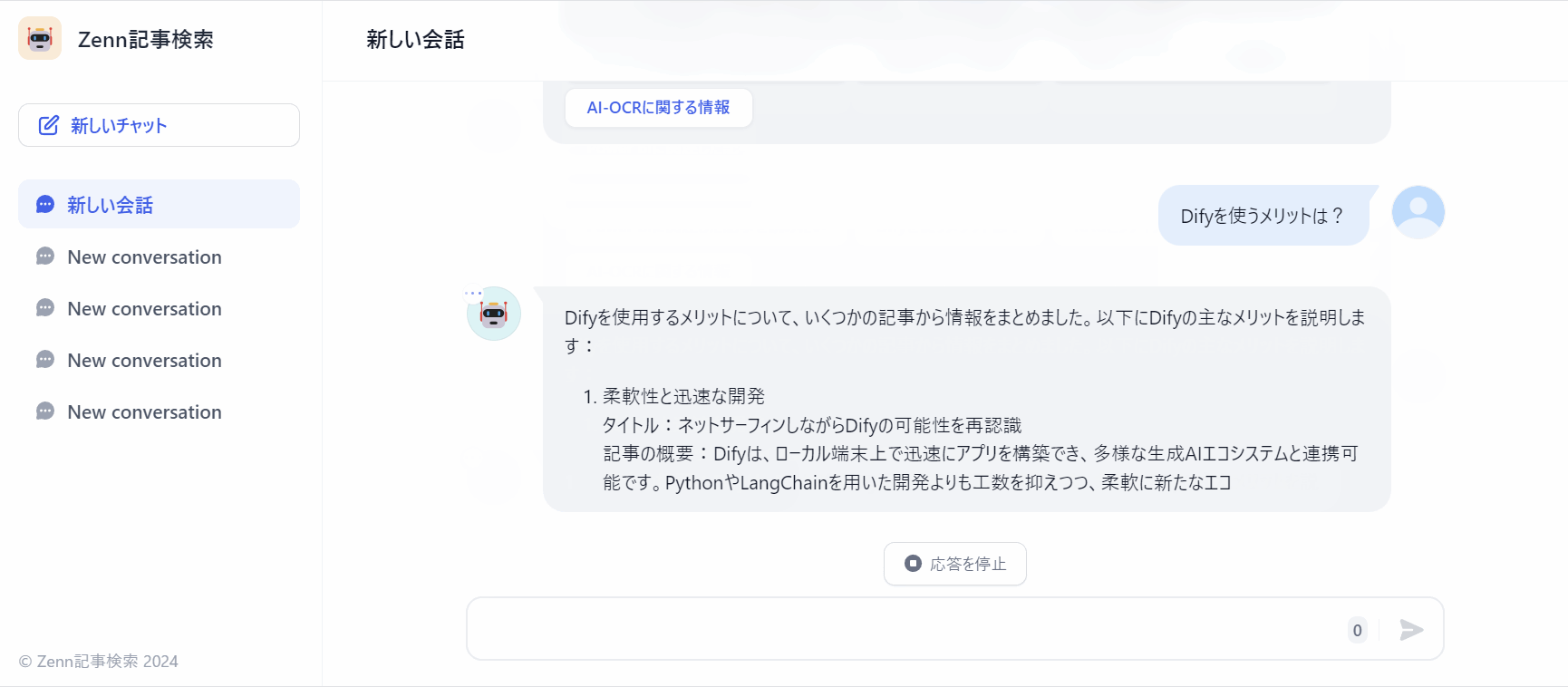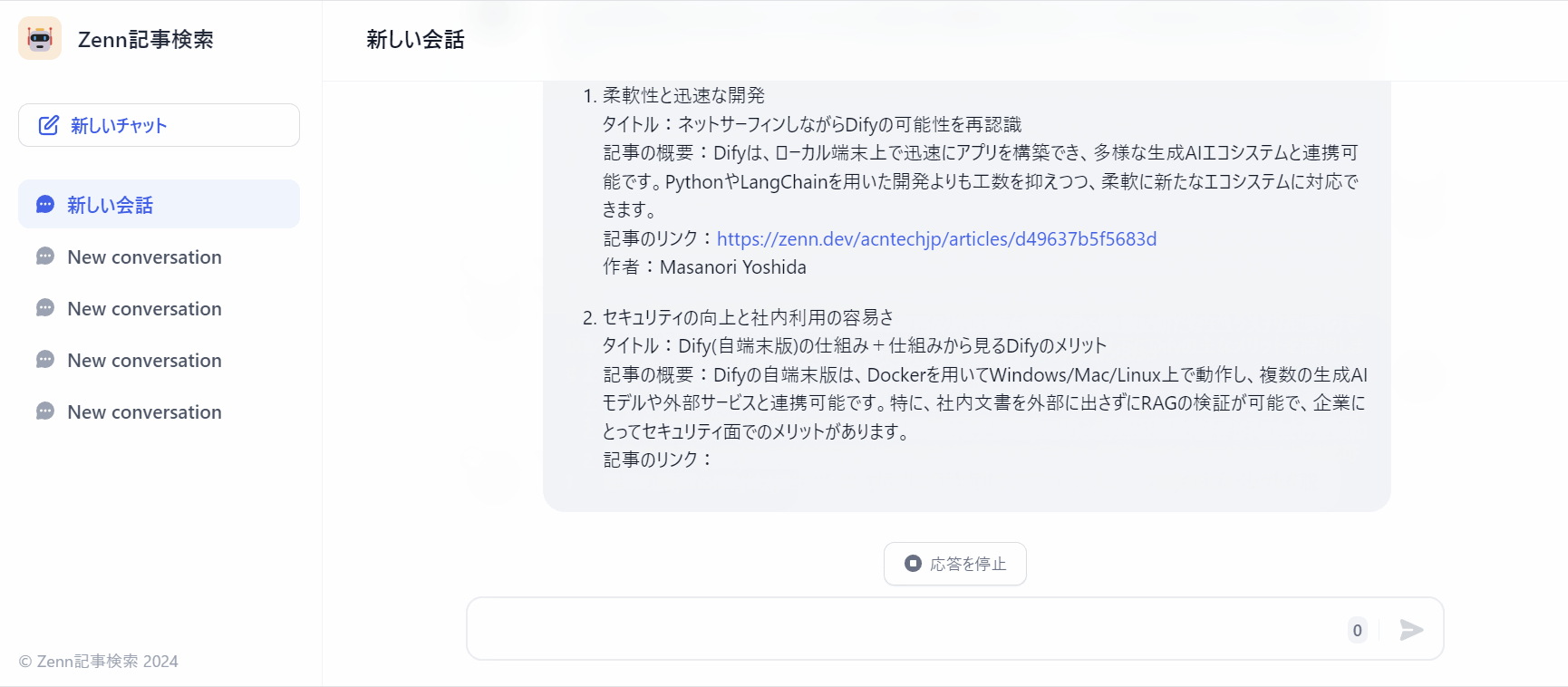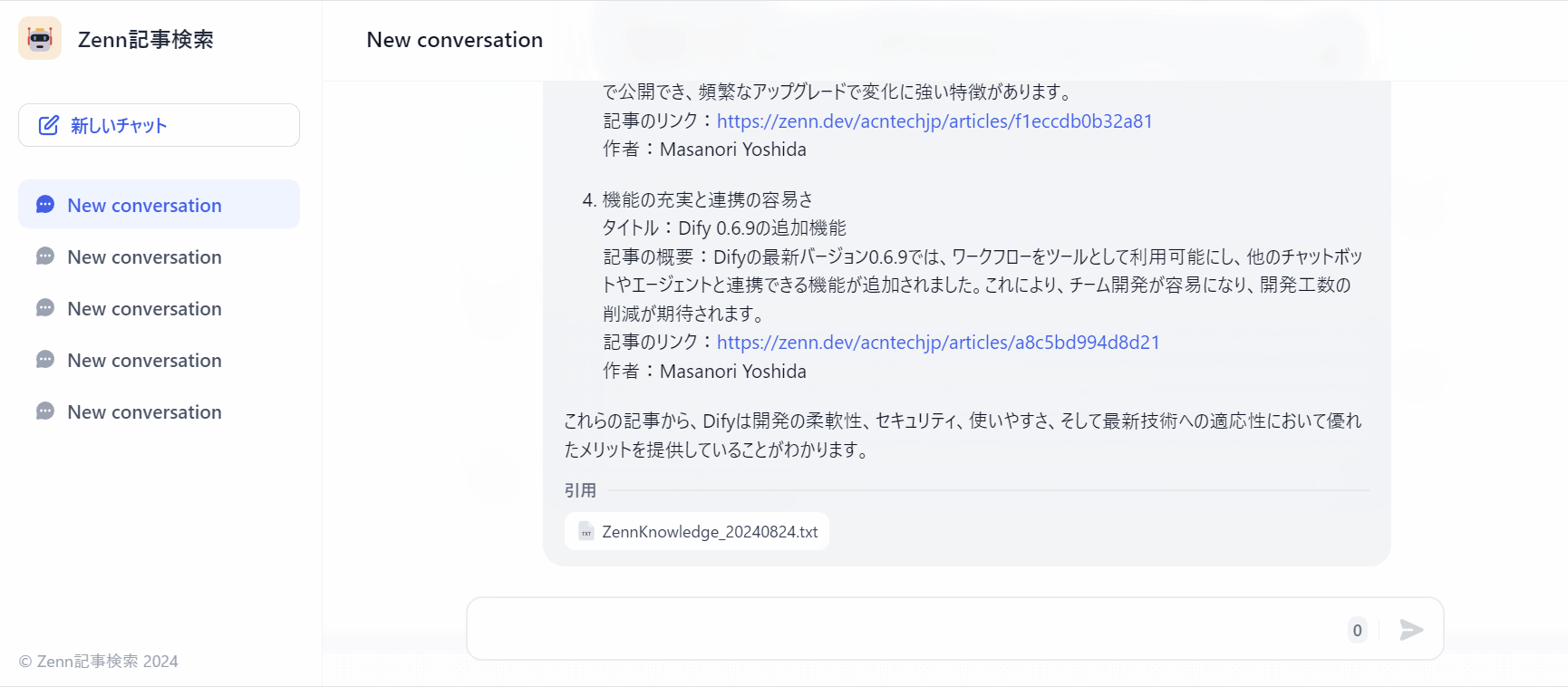
「タイトル」「記事の概要」「記事のリンク」「作者」を回答に含めるようにします。

RAGは魔法の仕組みじゃない
まずは、このDifyを作ったときに改めて感じたことを伝えたく思います。
「業務データをRAGに入れて~」という会話をよく耳にしますが、RAGは魔法の仕組みではなく、ただ業務データをつっこめば、あとは生成AIがなんでもやってくれるというのは間違いです。
RAGは、下記のように業務データを分割(チャンクと呼びます)して、ベクトルデータベース化して、LLMの問い合わせに近い文言のチャンクを取得して、LLMに取得したチャンク情報を渡す仕組みです。
なので、画像のように関連するURLも一緒に返すとなるとデータが分断されて、返すべきURLがLLMがわからない事態が起きてしまいます。

RAGのチューニングが肝
ベクトルデータの特性を踏まえたRAGのチューニングが肝要となります。
大きく分けて、「データの形式」と「設定」「プロンプト」となります。
データの形式
先ほどの図で示した通り、ただ業務データやFAQデータをRAGにしてもうまくいきません。
チャンクに分割する特徴を踏まえたデータ形式の検討が必要になります。
例えば、このDifyアプリでは下記のようなデータ形式でベクトルデータベースを作りました。

抽象化して示すと、下記情報を1記事1行で持ちます。
"ZennID":"<Zenn記事の一意のID>";"Title":"<Zenn記事のタイトル>";"記事概要":"<Zenn記事の概要>";"作者":"<Zenn記事の執筆者>"
あと、1つのチャンクの最大文字数が決まっているようで、Difyだと1000でした。なので1行あたりの文字数が1000未満になるようにデータを作る必要があります。特に記事概要は文字数が大きくなりがちなので気を付けました。
このデータですが下記順序でデータを取得して整形しています。
#1-#3は記事にしています。#4はExcelの数式「CONCAT」を使って「データ形式」の文字列を作っています。
- RSSを使ってZenn記事リストをGoogleスプレッドシートに出力する
- Google App Scriptを使って#1のZenn記事リストに対して記事全文をスクレイピングする
- Google App Scriptを使って#2の全文に対してGPT-4oで180文字程度に概要を出力する
- 数式を使って#3の情報から上記の「データ形式」の文字列を作る
#1に対応する記事 #2に対応する記事 #3に対応する記事
設定 (Difyのナレッジ設定画面)
Difyのナレッジ画面でまずはチャンク設定をしていきますが、今回のチャットボットの目的やデータ形式を考えると、「自動」を選択してもうまくいきません。
明示的に最大チャンク長や、チャンクを区切るべき文字をカスタムで指定する必要があります。(このデータ形式は1記事1行なので、改行でチャンクを区切るべきであり「セグメント識別子」を「\n」と指定しました。)
最大チャンク長は、最大の1000にしています。こちらもチャットボットの目的やデータ形式を踏まえて検討すべき項目と考えます。

データをベクトル化エンジンも評判のよいcohereにしていますし、検索設定もハイブリッドでRerankできるようにしてより回答精度を上げられるようにしています。

プロンプト
プロンプトも期待する回答が返答されるようにしています。

プロンプトは下記になります。
回答の要件をしっかり書いたのとRAGに登録されているチャンクごとのデータ構造を「ナレッジの形式」として明示的に書いています。
また、回答フォーマットを指定することでLLMからの回答のブレを防いでいます。
あなたは優秀なZenn記事の解説者です。
ユーザの質問について、コンテキストからナレッジを検索して、そこから回答してください。
## 回答の要件
・重要:ユーザの質問への回答の前に、必ずコンテキストを検索してください。
・回答は、ユーザの質問に対して、できるだけ具体的な内容になるようにしてください。
・参考として、リンクURLを記載してください。
・重要:わからないものは「わからない」と回答してください。
・複数該当記事がある場合は、複数記事回答する
・記事のリンクのURLは下記形式で作ってください
https://zenn.dev/acntechjp/articles/{ZennID}
## ナレッジの形式
"ZennID":"bc21a1bea374dd";"Title":"DifyとNotionで領収書をOCRして管理! - Claude 3.5 Sonnet編";"記事概要":"DifyとNotionを使用し、Claude 3.5 Sonnetを利用して領収書をOCRで管理する方法を紹介。Difyの設定を変更し、JSON形式で出力するよう調整することで、簡単にLLMを切り替えて利用可能に。実際の運用でインボイス登録番号の誤りが発生したが、手軽なOCR管理が可能であることを示す。興味がある方は試してみる価値がある。";"作者":"Masanori Yoshida"
## 回答フォーマット
タイトル
記事の概要
記事のリンク
作者
会話の開始も下記のようにして、チャットボットの目的をきちんと記載して想定外の質問をされないように工夫しています。(わざと想定外の質問をされるケースもあるが、そこの対策は優先度劣後で。)
作成したDifyアプリを動かしてみる
実際に動かしたときの挙動は下記になります。
ひとまず、いい感じに回答できているかと!
さいごに
今回、Zenn記事の投稿数がだいぶ増えてきたのをきっかけに、Difyアプリを作りました。
その中でうまく回答が得られずにRAGに関するチューニングの重要性を再度認識しました。
この記事でみなさんがDifyでRAGを活用したアプリを作るきっかけになったり、RAGのチューニングの参考になれたら幸いです。

アクセンチュア株式会社に所属する社員有志による運営です。アクセンチュアの社員による様々な発信をまとめています。なお、投稿内容は社員個人の見解であり、所属する組織を代表するものではありません。
Discussion