最小二乗法と仲良くなりたい③

3行まとめ
- 誤差の分布を正規分布だと仮定することで推定量の分布形状を議論できる
- 推定量の分布形状を議論することで、推定量に関する検定が実施できる
- スクラッチで単回帰の推定量導出から検定まで実施してみました
今回は
前回の記事では、最小二乗法によって推定される係数(=最小二乗推定量)の期待値と分散を計算することで、不偏性と一致性を満たすことを証明しました。
これによって最小二乗推定量は有用な点推定量だと見做せる一方で、そのばらつきによっては、今回の実験データから得られた推定量が(本来は小さいのにも関わらず)たまたま大きかったのかもしれませんし、得られるべくして大きい値が得られたのかもしれません。
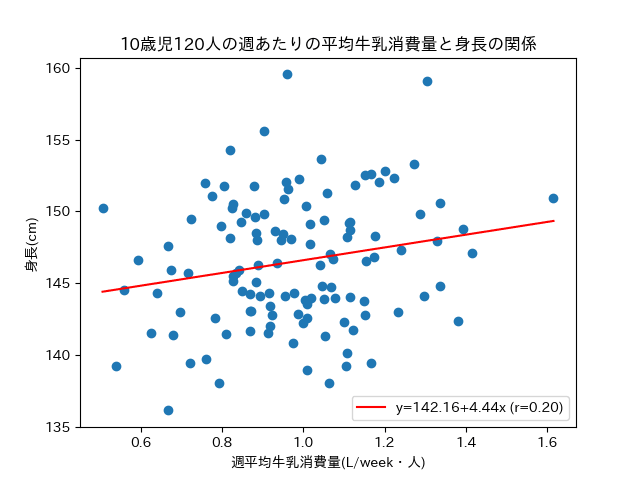
例えば、前々回に例として出した牛乳と背丈の関係でいえば、牛乳摂取量にかかる係数である
今回はここについて、誤差項にさらに仮定を敷きつつ検討して行きたいと思います。
参考書籍
引き続き統計学入門 a.k.a 赤本 の範疇の内容でございますー。
方針
得られたデータがたまたまだったのか、なるべくしてそうなったのかを、(頻度主義的)統計学に則って議論するための手法といえば、統計的仮説検定ですね。
統計的仮説検定は、ある気になっている事柄に対してあって欲しい結論を否定するような帰無仮説をたて、あらかじめ設定した閾値(有意水準)を元に帰無仮説の確率的な尤もらしさを評価し、帰無仮説が棄却できればあって欲しい結論を採択することができる、という取り組みです。
そして検定を実施する際に、気になっている事柄の背後にパラメトリックな確率分布を仮定する検定をパラメトリック検定、確率分布を仮定しない検定をノンパラメトリック検定と呼びます。
今回であれば、気になっている事象は
この
現時点でわかっていること
「
ここから検定、特にパラメトリック検定に持ち込むために、
これまでの仮定と追加の仮定
これまでの議論の中では、確率変数である誤差
仮定①:誤差
仮定②:誤差の分散は常に一定である
仮定③:誤差間に相関はないものとする
今回、
そして、ちょっとずるい気もしますが[2]、一般的に測定誤差は中心極限定理により正規分布に従うことが知られる、ということを使って、以下のように仮定を敷くことにします。
仮定④:誤差
これまでの仮定と組み合わせると、誤差
この仮定を元にすると、
\sigma^2
ということで、
そもそも、
真の値は神のみぞ知る値なので、我々人間ができることは推定、でしたね。
推定するときは不偏性と一致性を満たしていてほしい、でしたね。
母分散の点推定量としてふさわしいのは不偏分散、でしたね。
ということで、真の
ここで、一旦振り返りましょう。
そもそも最小二乗法を使って
細かい導出は過去記事に戻っていただくとして、以下に整えた連立方程式を再掲します。
これによって、
ここで
このブログではまだ取り扱っていませんが、正規母集団を仮定した確率変数を期待値と標本不偏分散で標準化(と同じような計算)をした値がt統計量と呼ばれ、不偏分散と同じ自由度のt分布に従うことが一般的に知られています。
t検定を実施
ここまできたらほとんどゴールですね。
帰無仮説
また、設定したパーセント点を用いて、以下のように不等式を設定し、
この推定区間に0を含まないということと、検定で帰無仮説
牛乳摂取量と身長のデータから実際に計算してみる
もちろん、Rにせよpythonにせよ、サクッと最小二乗推定を行なって検定までしてくれるライブラリはありますが、今回は勉強のために実際に計算してみます。
コードに関して
以下、実験や製図に使用したコードをトグルにて記述します。
python3.10.11でjupyter notebook上で実施していますが、大したコードではないので細かいパッケージのバージョン情報は割愛します。
また、すべて冒頭で以下のパッケージ、ライブラリをインポートしていることが前提で記載しています。
前々回に使ったダミーデータを使います(欲しい人などいないと思いますが、一応データはgithubにあります)。
コード
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import scipy.stats as stats
# データフレームをdfとして読み込んだところからスタートします。
# x,yを設定
x = df.milk
y = df.height
# xの分散と共分散を算出
v_x, cov_xy = np.cov(x,y,ddof=0)[0]
# OLS推定量を算出
beta_2 = cov_xy/v_x
beta_1 = np.mean(y) - beta_2*np.mean(x)
# yの推定値から標本誤差を求め、OLS推定量の標準誤差を算出
y_hat = beta_1 + beta_2 * x
error = y_hat - y
s_2 = np.var(error,ddof=2)
se_beta_2 = np.sqrt(s_2/np.sum(np.power(x-np.mean(x),2)))
# t検定量を算出
t = beta_2/se_beta_2
dof = len(x)-2
x_t = np.linspace(-5,5,1000)
y_t = stats.t.pdf(x_t,dof)
p = 0.05
upper_limit = stats.t.ppf(q=1-p/2,df = dof)
plt.plot(x_t,y_t,c='gray',label = 'pdf')
plt.vlines(ymin=0,ymax=np.max(y_t),x=upper_limit,linestyles='--',color='red',label='significant level')
plt.vlines(ymin=0,ymax=np.max(y_t),x=-upper_limit,linestyles='--',color='red')
plt.fill_between(x_t,y_t,where=x_t<-upper_limit,facecolor='red',alpha=.5,label = f'reject area(p<.05)')
plt.fill_between(x_t,y_t,where=x_t>upper_limit,facecolor='red',alpha=.5)
plt.vlines(ymin=0,ymax=np.max(y_t),x=t,linestyles='-',color='c',label='t_value')
plt.title(f't distribution(dof = {dof})')
plt.legend(
loc='upper left',
bbox_to_anchor=(1, 1),
ncol=1,
)
beta_bottom = beta_2 - upper_limit*se_beta_2
beta_top = beta_2 + upper_limit*se_beta_2
print(f'beta_2の95%信頼区間は{beta_bottom:.3f}~{beta_top:.3f}')
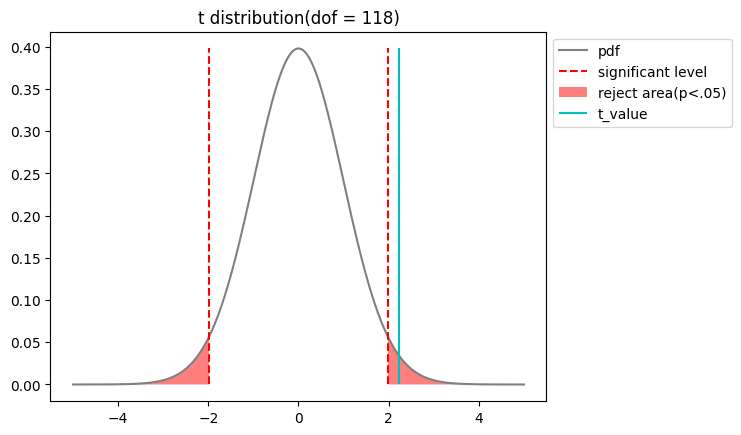
以上の結果から、有意水準5%においては
終わりに
今回はあくまで単回帰というシンプルなケースを例に証明や導出を行なってきましたが、変数が複数個になる重回帰分析においても基本的には同じような考え方で検討することになります。
実際の分析においては単回帰を使うケースはあまりないように思います...関係がありそうな変数(共変量)もデータを入手しておいて、交互作用を考えたりドメイン知識から変数選択をしたり、RidgeやLassoなどの正則化を用いた変数選択のテクニックを使ったり、ということをしながら重回帰分析をしていく感じですかね。
実は重回帰分析やベイズ線型回帰にも使えるかと思って、今回のデータセット作成においては、身長に効く共変量として親の身長や運動習慣などを入れ込んでいたのですが、一旦最小二乗法についてはここで区切りとしたいと思います。
本当はベイズ線型回帰についてもまとめたいなーと思いつつ・・・
以上、ご確認のほど、よろしくお願いいたします。
-
今回は負の作用がないとも限らない、という立場に立って両側検定を行います。対立仮説は
\beta_2 \neq 0 \beta_2 X Y X Y X Y \beta_2 > 0 -
何か測定器具で測るようなことに対する測定誤差については正規分布でもっともらしいように思うのですが、今回の例で言えば、例えば身長を牛乳摂取量で回帰した時に、牛乳摂取量だけでは表しきれない特徴が全て誤差として表現されてしまいます。例えば、月齢とか、運動習慣とか、それらの交互作用とか。中心極限定理を背景として誤差を正規分布と仮定している以上、誤差の構成要素は類似した母集団分布に従う独立な確率変数である必要があります。しかしながら、回帰する上で重要な説明変数が抜け落ちていたりすると、中心極限定理を導入するための仮定が成り立たないことになってしまったりします。 ↩︎
Discussion