最小二乗法と仲良くなりたい①

3行まとめ
- 最小二乗法は残差平方和(誤差の二乗和)が最小となる回帰式を求める手法。
- 簡単のために変数が1つのケースを具体例として最小二乗法で回帰式を求めてみる。
- 最小二乗法で推定した係数は推定量として適切なのかが気になってくる。
きっかけ
きちんと統計学を勉強したい、というモチベーションで、赤本 → 緑本と進み、現在は*標準とは?*で有名な標準ベイズ統計学を読み進めているところ…なのですが、線型回帰の章に入って「オレは何も最小二乗法のことをわかってなかった…」と痛感するばかりの日々を送っています[1]。
というわけで、今回からは、単変量の最小二乗法、いわゆる単回帰を取り上げて反芻していきたいと思います。
参考書籍
上述の通り、きっかけは標準ベイズですが、今回はいわゆる頻度論的な解釈で復習したいと思いますので、入門詐欺本として名高い統計学入門 a.k.a 赤本 の範疇の内容になります。
序文 : 点の中に線を引くのってキモチイイ
最小二乗法って、人間の本能にとてもよくマッチした推定方法だと感じています(個人の感想です)。
ほら、子供の頃から点を結んで絵を作るやる、アホほどやるじゃないですか?
点を見つけると線を引きたくなるのって、人間の本能だと思うんですよね。
もちろんアカデミアだったり、企業研究者だってちゃんとリテラシを持った人であればそんなことはないとは思いますが、私の前職とかだと、ブワァっとある点の集合にもっともらしい線が引かれて、小数点以下4桁とかの数値を出して「ゆるい相関があります」とかっていうのが横行するわけです。
エクセルでグラフを書いてちょちょいのちょい、とすると、モットモらしい線とモットモらしい式が出てくるんでね、なんかすごく頭がいいことを言っているような気になるんですよね[2]。
そういう観点でモットモらしく線を引く、という行為に対して数学的な妥当性を与えてくれる最小二乗法はすごい発明だなぁ、と勉強するたびに感嘆してしまいます。
そういえば遠い記憶で、大学1年のコンピュータリテラシの授業でも最初に最小二乗法を扱っていた気がします[3]。
そんな大学時代〜前職での思い出に浸りつつ、真面目に最小二乗法を咀嚼していきたいと思います。
最小二乗法って何してるん?
最小二乗法は、回帰式を求めるための手法の一つです。
回帰というのは、予測したかったり解釈したかったり、といった分析者が興味を持っている数値のデータが
そして、両者の関係を表す数式のことを回帰式、と呼ぶのでした。
ただし、どうしたって測定誤差が出てしまうだとか、持っていないデータの中にも重要なデータがあったかも知れない[4]だとか、回帰式だけでは表現しきれない要素はどうしてもあるよね、ということで、それをまるっと誤差項(
最小二乗法は、一言で言ってしまえば、n個のデータの誤差項の合計が最も小さくなるような回帰式を求めよう、というコンセプトです。
とはいえ誤差はプラスだったりマイナスだったりして、単純に合計を取るとお互いに打ち消しあってしまうので、符号を無視するために二乗してから足し合わせよう、という工夫をしています。
この誤差の二乗を足し合わせた数のことを、残差平方和(Sum of Squared Residuals;SSR)と呼びます。
広義でいえば、回帰モデルが線型だろうが非線形だろうが関係なく、残差平方和を最小にするような回帰式を求めることが最小二乗法の定義になります。
ただし、一般的には回帰式が線型で表される(と仮定できる)ときに最小二乗法を適応するケースがほとんどかと思います。
これは線型回帰を仮定すると残差平方和が
この時の回帰式やそれによって描かれる直線を回帰直線[5]、回帰式の係数である
一般的には定数項の導入するために、
これはいわゆるy軸切片でして、「必ずしもこの
これに倣い、以降も
具体例で考える
これからの議論で使うことができる、ちょっとした例を考えてみましょう。
まずは単純に、
<例>
牛乳メーカーのマーケティング担当者が、「牛乳をしっかり飲ませて子供の背を伸ばしましょう」みたいなキャンペーンを打ちたいので、子供の身長と1週間あたりの牛乳の摂取量の関係を知りたい、と思ったとしましょう。
その関係を見つけるために、10歳児をランダムに
このとき、興味の対象は子供の身長であって、
そして「身長と牛乳摂取量は比例関係にあるはず」という仮説から
導出過程
より、
ここで
を代入することで以下を得る。
を解いて
さて、今回は120人の10歳児に協力をしてもらってデータを集めて(つまり
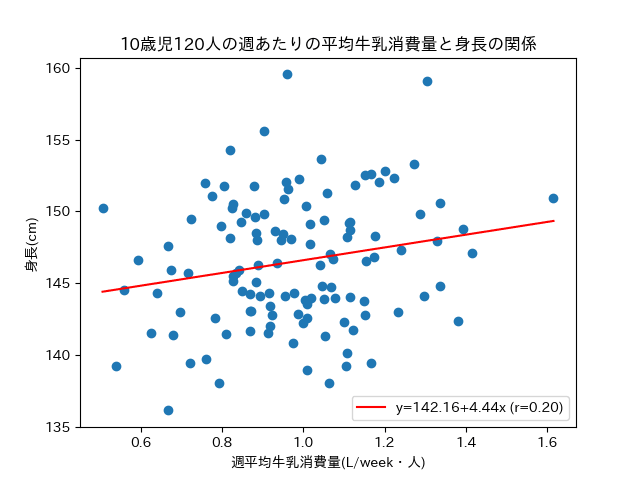
相関係数は0.2で、弱いながらも相関はありそうですね。
ところで、今算出した
そうなると、前回議論した、点推定が満たしておいてほしい2つの性質、一致性と不偏性が気になってきます。もしも不偏性や一致性を満たしていなかったら、どんなにサンプルを増やしても、どれだけ調査を繰り返しても、真の
次回からはこのデータを使ってもう少し上記の点を考えていきたいと思います。
終わりに
線型回帰って、点の中にうまく線を引く、と言うとっつきやすいイメージで理解した気になってしまうのですが、知れば知るほどなかなか使えなくなってきてしまいます…
とはいえ「こういう仮定を敷いている」ということをしっかり理解しておくのが大事だと思いますので、備忘のためにアウトプットをさせていただきたく。
以上、ご確認のほど、よろしくお願いいたします。
-
というか、全般的に「オレは何もわかってなかった…」という感じでございまして、それ自体がこのブログを始めたきっかけだったりします。 ↩︎
-
あくまで私の感想を述べているに過ぎないことにご注意賜りたく。皆々様におかれましてはそんなことあるはずがなかろう!と思われること必至かと思いますので、どこか遠い国のお話だったり、筆者の夢の中のお話だったり、反実仮想の話だと思ってお読みいただければと思います。というか、そうです。 ↩︎
-
当時は計算機室にずらっと並ぶmacで、ぐるぐると虹色に回るアイコンを見ながら、よくわからないままにmatlabをいじいじしていた記憶です。 ↩︎
-
厳密にいうとこの誤差項の性質によってこのあと議論する仮定が成り立たなくなったりするのですが、ここでは割愛したく。 ↩︎
-
回帰"直線"というとxとyのグラフにビシッと真っ直ぐな線が惹かれることを想定するかと思いますが、この線型回帰式の
X_{ip} y=ax^4+b (x,y) (x^4,y) -
頻度論的な解釈ですが、真の
\beta_1 \beta_2 \hat{\beta_1} \hat{\beta_2} -
最小二乗法(Ordinary Least Squares)を使って求めた推定量なので、
\hat{\beta_1} \hat{\beta_2}
Discussion