[読書メモ]データ指向アプリケーションデザイン
いい感じ
1章 信頼性、スケーラビリティ、メンテナンス性に優れたアプリケーション
1.3 スケーラビリティ
1.3.1
Twitterを例にとってスケーラビリティについて書かれている
- ファンアウト
- 入力リクエストの処理に必要な他のサービスへのリクエスト数
- Twitterではファンアウトが課題(ツイートの読み込み)
- (1)単純にテーブル結合で取ってくる()読み込み時の処理多い)
- (2)ツイート→各フォロワーに配信する用のパイプラインに入れる(書き込み時の処理多い)
- 有名人のツイートは(2)で取得することで負荷低減
1.3.2
パフォーマンスの話。パーセンタイルとか
- head of line blocking
- マイクロサービスでも起こり得る
マイクロサービスにおけるテイルレイテンシの増幅
- マイクロサービスでも起こり得る
- ユーザーリクエストを捌くのに、複数のサービスへアクセスするような場合、1つでも遅いものがあると、結果的にユーザーへのレスポンスが遅れる
1.3.3
負荷への対処法について
- 万能アーキテクチャは存在しない
- 扱うアプリケーションに依存
- 処理の種類・頻度を推定する必要あり
- 開発初期段階ではスケーラブルなアーキテクチャを考えるのが難しい。→それよりもいてレーション回す方が大事(アジャイル)
1.4 メンテナンス性
運用性、単純性。拡張性が設計原理が重要
1.4.1 運用性:運用担当者への配慮
優れた運用チームの責任が書かれている。SREの仕事やね。
このあたりは息をするようにできるようになっておきたい。
1.4.2 単純さ: 複雑さの管理
抽象化で複雑さを取り除く
1.4.3 進化性: 変更への配慮
アジャイルで変化に対応
まとめ
- 信頼性
- スケーラビリティ
- メンテナンス性
のお話でした。
5章 レプリケーション
- レプリケーション:複数マシンに同じデータをコピーしておくこと
- レイテンシの低減
- 可用性の向上
- スループットの向上
につながる。
- 使用されるアルゴリズム
- シングルリーダー
- マルチリーダー
- リーダーレス
結果整合性や書き込み後読み取り、モノトニック読み取りの補償について述べられる。
5.1 リーダーとフォロワー
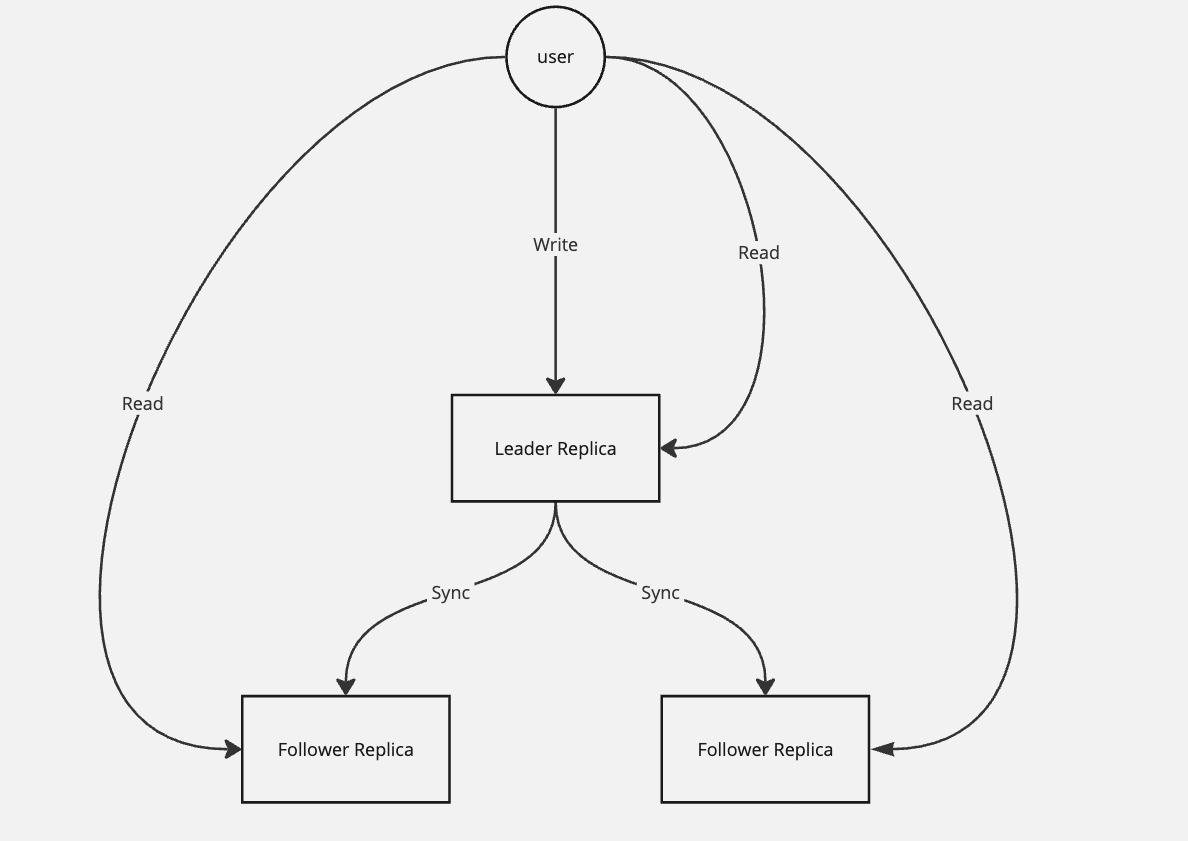
リーダーベースレプリケーション
例
- PostgreSQL
- MySQL
- Kafka
- RabibitMQ
5.1.1 同期or非同期
- リーダーベースレプリケーション
- 通常、1つのフォロワーを同期、それ以外を非同期にする。
- 2つノードに最新情報がある状態→準同期型(semi-synchronos)
- 全て非同期にすることもあるが、リーダーが壊れるとやばい
- 通常、1つのフォロワーを同期、それ以外を非同期にする。
5.1.2 新しいフォロワーのセットアップ
- 単純にノードからノードにデータコピー?
- 常に書き込みがあるので一貫性がなくなる
- ロックする?
- 可用性が失われる
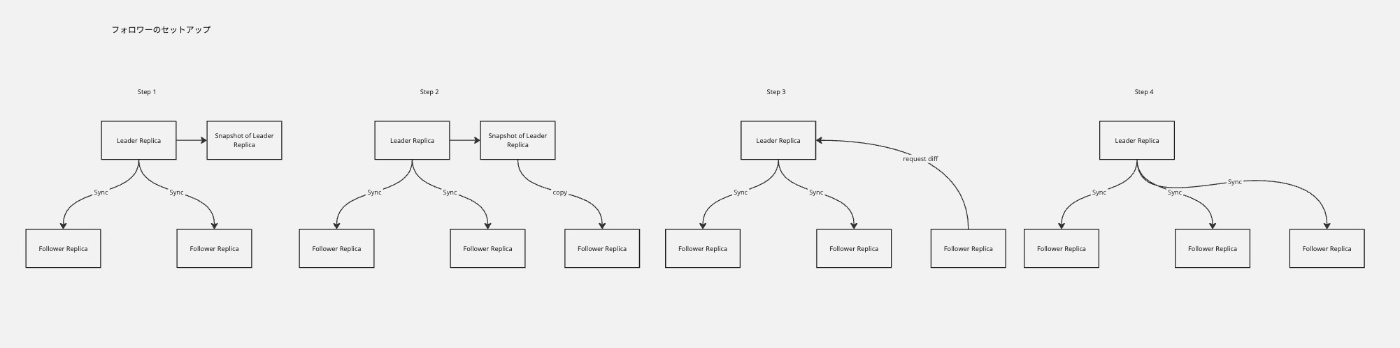
- リーダーのスナップショット取得
- スナップショットをフォロワーにコピー
- スナップショットを取得した以降のリーダーの変更をフォロワーが要求し、同期
- フォロワーを1つ増やせた
5.1.3 ノード障害への対応
フォロワーの障害:キャッチアップリカバリ
- フォロワーはリーダーから受信したデータのログをローカルディスクに持っている
- 障害が発生してダウンしても、ログを読んで、最後に処理したトランザクション以降のデータをリーダーに要求すれば復旧可能
リーダーの障害:フェイルオーバー
フォロワーのいずれかをリーダーに昇格させる
- リーダーに障害発生
- フォロワーからリーダー選出
- システムの再構築
という手順。ただし、問題が結構ある。
- リーダー選出されるフォロワーのデータが最新ではない可能性あり
- 壊れたリーダーが復活した際、 壊れたリーダーと新しいリーダーとのデータの整合性がとれなくなる
- →壊れたリーダーのレプリケーションされなかったデータは破棄するのが一般的
- 壊れたリーダーが復活した際、 壊れたリーダーと新しいリーダーとのデータの整合性がとれなくなる
- リーダーが2つになる(スプリットブレイン)
- 両方に書き込みがされる。
- この場合、どちらか一方をシャットダウンする必要あり(要注意)。
- リーダーが落ちていると判断する基準は?
- タイムアウトで判断するが、適切な値にする必要あり。
5.1.4 レプリケーションログの実装
5.1.4.1 ステートメントベースのレプリケーション
リーダーへの書き込みリクエスト(UPDATE,INSERT,DELETE)などをログに記録して、そのままフォロワーに送信。
この手法はあんまり。
5.1.4.2 write-aheadログ(WAL)の転送
PostgreSQLとoracleで利用されている。
WALをディスクに書き込むと同時に、フォロワーに転送
- WALとステートメントベースのログの違いは?
- WALの記載は低レベル。
わかりやすい
AIに聞いた
| 特徴 | WAL(Write-Ahead Logging) | ステートメントベースのログ |
|---|---|---|
| 記録内容 | データ変更内容(バイトレベル) | 実行されたSQLステートメント |
| リカバリの詳細度 | 高い(物理的なデータ変更の詳細を記録) | 低い(ステートメントの再実行が前提) |
| 具体例 | PostgreSQLやSQLiteのWAL | MySQLのバイナリログ、OracleのREDOログ |
| 動作タイミング | トランザクションの開始から終了まで | SQLステートメントの実行時 |
| 環境依存性 | 低い(変更内容をそのまま記録) | 高い(再実行結果が環境に依存する場合がある) |
5.1.4.3 論理(行ベース)ログレプリケーション
レプリケーションように別のログ(論理ログ)フォーマット使う。
ストレージエンジンから分離される。
外部のアプリケーションからパースしやすい。
5.1.4.4 トリガーベースレプリケーション
データベースが持っているトリガという機能を用いる。
書き込みが発生→トリガー起動→任意のロイジック実行
Amazon Aurora DB
分散ストレージ経由で同期しているっぽい
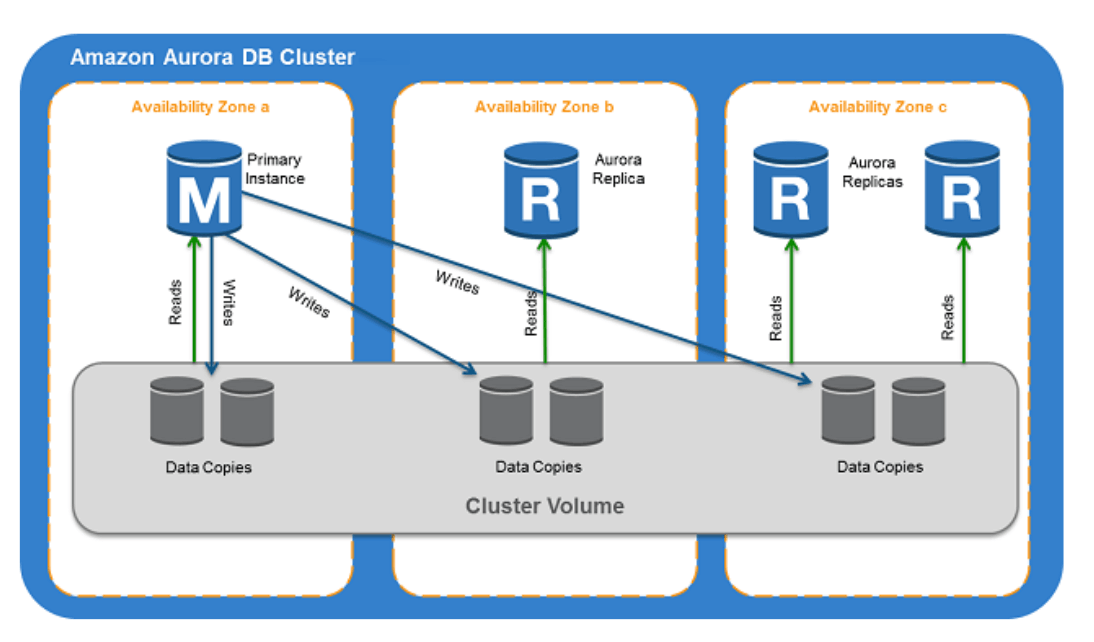
5.2 レプリケーションラグにまつわる問題
なぜレプリケーションするのか?
-
レイテンシの低減
-
可用性の向上
-
スループットの向上
-
結果整合性
- 時間が経てば、リーダーとフォロワーは同じデータを持つ元になる
- 逆にいうと、時間が立たないと、リーダーのデータがフォロワーに反映されない→最新情報の取得にラグが生じる
5.2.1 自分が書いた内容の読み取り
- read-after-write
- データが一度更新されると、同じクライアントがそのレコードを読み取ろうとした場合、更新された値が返されることをシステムが保証するというもの。
- Writeの直後に他のクライアントが更新された値を取得することを約束するものではなく、Writeが成功したことをユーザーに安心させるためのもの
- 実現方法はいくつかある。こちらがわかりやすい。
-
https://arpitbhayani.me/blogs/read-your-write-consistency/
- Synchronous Replication
- どれか1つのレプリカで書き込みに失敗すると、システム全体が停止
- 強力な一貫性は得られるが、書き込みのスループットと可用性を犠牲
- あんましよくない
- Pinning User to Master
- 一定時間(フォロワーにリーダーの最新情報が反映されるまでの時間)、最近Writeを実行したユーザーのリードをMasterに転送
- 書き込みが多いシステムだと、ほとんどのリクエストがリーダーに行き、ボトルネックになる
- Fragmented Pinning
- Pinning User to Masterの改良版
- 重要なRead(システムの要件次第)だけを選んでMasterにヒットさせる
- Master Fallback
- フォロワーにRead
- ヒットすれば、返却。ヒットしなければリーダーにRead
- リーダーには最新情報あるので返却
- Synchronous Replication
-
https://arpitbhayani.me/blogs/read-your-write-consistency/
5.2.2 モノトニックな読み取り
ユーザー2がユーザー1の投稿を読み取る時、
- (1回目)フォロワーレプリカ1から読み取る→"Hello"
- (2回目)フォロワーレプリカ2から読み取る→""
のようになることがある。これは、ユーザー1の投稿がレプリカ1に反映されているが、レプリカ2に反映されていない場合に起きる。
モノトニックな読み取りでは、こういった状況を防げる。
→同一レプリカから読み取らせる。ユーザーIDのハッシュなどを使って。
5.2.3 一貫性のあるプレフィックス読み取り
ある順序で一連の書き込みが行われた場合、それらを読み取る者には書き込まれた際と同じ順序で見えるようにする。
パーティッション化(シャーディング)されたデータベースで問題になる。
5.2.4 レプリケーションラグへの対処法
- トランザクション
- アプリケーションをシンプルにするために、データベースが強い保証を提供する方法
5.3 マルチリーダーレプリケーション
- シングルリーダー
- 全ての書き込みが、リーダー1つに集中する
- これを複数にすれば、可用性UP
- 全ての書き込みが、リーダー1つに集中する
5.3.1 マルチリーダーレプリケーションのユースケース
単一データセンター内では使う意味ない。メリット<複雑さ
- 5.3.1.1 マルチデータセンターでの運用
- リーダーをそれぞれのデータセンターに置く
- パフォーマンス
- マルチリーダーにすると、書き込みはローカルのデータセンターでできるのでいい感じ。
- 耐障害性(データセンター)
- データセンターが壊れても、フェイルオーバー(フォロワーをリーダーに昇格)させる必要ない。リーダーが複数あるので。
- 耐障害性(ネットワーク)
- マルチリーダー構成だと、他のデータセンターのフォロワーへの同期が、非同期(シングルリーダーよりもゆとりがある)なので、データセンター間のネットワークに対して耐性がある。
ただ、書き込みの衝突が起こる可能性がある。
可能であれば、マルチリーダーレプリケーションは避けるべき。
- 5.3.1.2 オフラインで運用されるクライアント
インターネットに接続されていない時も、アプリケーションが動作し続けなければいけない場合。
5.3.1.1 マルチデータセンターでの運用において、データセンターをデバイスに置き換えて考えた場合と一緒。
あんまりピンとこない。
飛ばす。 - 5.3.1.3 コラボレーティブな編集
特になし。
5.3.2 書き込みの衝突の処理
マルチリーダーレプリケーションの最大の問題= 書き込みの衝突
-
5.3.2.1 同期の衝突検出と非同期の衝突検出
- 同期
- リーダーへの書き込み→フォロワーへの同期→その後、ユーザーへ成功を通知。マルチリーダーにしている意味がない。
- 非同期
- マルチリーダーではこっち。
- 同期
-
5.3.2.2 衝突の回避
- 衝突の事前回避が推奨されるアプローチ
-
5.3.2.3 一貫した状態への収束
収束:すべてのレプリカが同じ状態になるようにする。- 書き込みにユニークIDを持たせる。大きい方を反映させる。タイムスタンプをユニークIDとするとき、last write wins(LWW)という。
- レプリカにユニークIDを持たせる。大きいIDを持っているレプリカの書き込みを優先・
- 値のマージ。AとBという書き込みがあれば、A/Bみたいに。意味わからん笑。
- すべての情報を持つデータ構造用意。前書き込みを登録しておいて、後で衝突修正。
-
5.3.2.4 カスタムの衝突解決ロジック
- アプリケーション側でろ衝突解決ロジックを書く
- 書き込み時に実行
- 読み込み時に実行
- この場合、書き込みは全部保存されて、読み込み時に複数とってきてユーザーに確認求めたりする。その後、確定したデータを書き込む。
- アプリケーション側でろ衝突解決ロジックを書く
-
Amazon Dynamoの例
-
Google Docの例(Operational Transformation)
-
5.3.2.5 衝突とは何か
予約システムとかだと、「空いてる部屋に同時に予約」みたいなことが起きる。
7,12章で見ていく。
5.3.3 マルチリーダーレプリケーションのトポロジー
リーダーが3つ以上になると、トポロジーがいくつか考えられる。
-
循環
- MySQL
-
スター
-
all to all
- 単一障害点ない。
バージョンベクトル
メモ取るのめんどなってきた
大事なところピンポイントで書くほうがいいな
5.4 リーダーレスレプリケーション
Cassandraがこのスタイル(DynamoDBはシングルリーダー)
CAP定理のうち、APを取っている。C(consistency)を重視していない。ゆえに高速。
一般的なRDBではCP取っている。
ユースケース
- 高可用性・低レイテンシ
- 一貫性はあまり重要じゃない
ようなケース
5.4.1 ノードがダウンしている状態でのデータベースへの書き込み
-
リーダーレスの場合、全ノードの書き込みがされる
-
2/3だけ成功したら、成功しなかったノードにはwriteされない。
-
読み取りに時、複数ノードに問い合わせてversionが最新のものを取得する
-
5.4.1.1
- 読み取り修復
- 読み取りに時、複数ノードに問い合わせてversionが最新のものを取得する→最新じゃないものに関しては、最新データを返す。
- 半エントロピー処理
- 差分をなくすためのバックグラウンドプロセスで一貫性を保とうするもの
- 読み取り修復
-
5.4.1.2
- クオラムの話
- w(書き込み数) + r(読み取り数) > n(node数)なら、最新の値が得られる。 wとrはn/2より大きく設定。
- クオラムの話
5.4.2 クオラムの一貫性の限界
w+r>nを満たしていても、古い値が返されるエッジケースある
オフロードしたほうがいいよな。
- 5.4.2.1 遅延のモニタリング
- 結果整合性の結果がいつ得られるのかモニタリングする必要あり
- リーダーレプリケーション
- レプリケーションラグに関するメトリクスが公開されているので使える
- リーダーレスレプリケーション
- 書き込みの順序が不明なのでモニタリングむずい。
5.4.3 いい加減なクオラムとヒント付きのハンドオフ
この記事がわかりやすい。
5.4.4 並行書き込みの検出
- 5.4.4.1 LWW
- LWW
- データが失われることが許容されない場合、よくない選択肢。
- キーをimuttableにする
- 一度しか更新されないようにする。
- cassandraはUUIDをキーにしている。
- LWW
- 5.4.4.2
AとBと言う操作がある時- Aが先か
- Bが先か
- AとBが並行か
のいずれか
- 5.4.4.3
並行をどうやって判断するか?
バージョンつける - 5.4.4.4
- sibling
- 平行に書き込まれた値。クライアントはよしなにmergeしないといけない。
- sibling
- 5.4.4.5
- バージョンベクトル
- 全てのレプリカから取得したバージョンの集合
- バージョンベクトル
6章 パーティショニング