【初心者向け】Amazon DynamoDB 入門!完全ガイド
Amazon DynamoDB

☘️ はじめに
本ページは、AWS に関する個人の勉強および勉強会で使用することを目的に、AWS ドキュメントなどを参照し作成しておりますが、記載の誤り等が含まれる場合がございます。
最新の情報については、AWS 公式ドキュメントをご参照ください。
👀 Contents
- Amazon DynamoDB とは
- Amazon DynamoDB のユースケース
- Amazon DynamoDB の料金
- Amazon DynamoDB の基本
- Amazon DynamoDB のストレージ
- Amazon DynamoDB の耐久性
- Amazon DynamoDB の読み込み整合性
- Amazon DynamoDB のパフォーマンス
- 暗号化
- DynamoDB のテーブル操作
- DynamoDB の項目操作
- DynamoDB ストリーム
- TTL(Time to Live)
- トランザクション
- グローバルテーブル
- DynamoDB Accelerator (DAX)
- 条件付き書き込み
- アトミックカウンター
- 並列スキャン
- バックアップ
- DynamoDB のポイントインタイムリカバリ(PITR)
- DynamoDB 用の NoSQL Workbench
- 設計
- 📖 まとめ
Amazon DynamoDB とは
1 桁ミリ秒単位で規模に応じたパフォーマンスを実現する高速で柔軟な NoSQL データベースのフルマネージドサービスです。
CAP 定理という、「一貫性(Consistency)」「可用性(Availability)」「ネットワーク分断耐性(Partition-tolerance)」をすべて達成することはできない、という決まりがあります。
DynamoDB は、「可用性(Availability)」「ネットワーク分断耐性(Partition-tolerance)」を重視して開発されています。
DynamoDB は、「値」とそれを取得するための「キー」だけを格納するというシンプルな機能を持った「キーバリュー型」の形式でデータを格納します。
【AWS Black Belt Online Seminar】Amazon DocumentDB (with MongoDB Compatibility)(YouTube)(41:38)

【AWS Black Belt Online Seminar】Amazon DynamoDB Advanced Design Pattern(YouTube)(49:37)

【AWS Tech 再演】AWS の NoSQL 入門 〜Amazon ElastiCache, Amazon DynamoDB〜| AWS Summit Tokyo 2017(40:01)

Amazon DynamoDB のユースケース
- ユーザー情報
- 広告やゲームなどのユーザー行動履歴
- モバイルアプリのバックエンド
- クリックストリーム
- IoT データの蓄積
- RDB のキャッシュ
よくある構成は、「API Gateway / Lambda / DynamoDB」の組み合わせです。
結合や集計処理や大量データの読み書きが必要なユースケースの場合には RDB の利用を検討します。
Amazon DynamoDB の料金
「データストレージ」「読み込み/書き込み要求」によって課金されます。その他、使用したオプション機能によって追加で課金が発生します。
また、「オンデマンド」と「プロビジョニング済み」のキャパシティーモードそれぞれで料金体系が異なります。
詳しくは、料金表を参照してください。
Amazon DynamoDB の基本
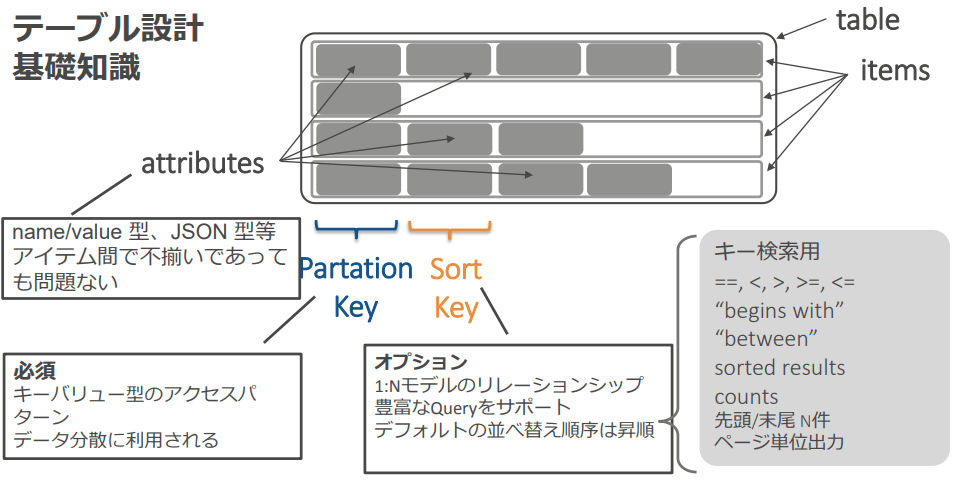
- パーティションキー
- キーに設定した属性のハッシュ値によって、テーブルの Item はパーティションと呼ばれる領域に分散して配置されます
- パーティションとデータ分散
- テーブルに1つしか設定できません
- 各パーティションへのアクセスが均一になるような設計を行う
- パーティションキーを効率的に設計し、使用するためのベストプラクティス
- 偏った状態では、「ホットパーティション問題」が発生します。DynamoDB では、スループットはテーブル全体の設定でパーティションごとに均等に割り当てられる。パーティションに偏りがある場合、アクセスが集中しているパーティションのスループットが枯渇してしまいます。
- ソートキー
- 範囲の指定やソートを行うために必要なキー
- パーティション内でソートされ物理的に近い位置に配置されます
- 指定は任意です
- ソートキーを使用してデータを整理するためのベストプラクティス
- プライマリキー
- 「パーティションキー」または、「パーティションキーとソートキーの複合キー」のこと。
- グローバルセカンダリインデックス(GSI)
- テーブルとパーティションキーまたはパーティション/ソートキーが異なるインデックスです。
- 例えば、プライマリパーティションキーが CustomerID で、GSI のパーティションキーが郵便番号
- 1 テーブルあたり最大で 20 つの GSI を作成できます。
- 上限緩和申請で増やすことが可能
- 既存テーブルに追加・削除ができます。
- スループットやストレージ容量を追加で必要となります。インデックスが増えると書き込みコストが上がります。
- GSI は結果整合性の読み取りのみサポートします。
- GSI に依存するテーブル設計であれば、RDS の利用も検討したほうがよい。
- DynamoDB でセカンダリインデックスを使用するためのベストプラクティス
- ローカルセカンダリインデックス(LSI)
- テーブルとパーティションキーは同じですが、ソートキーが異なるインデックスです。
- LSI への読み込み・書き込みはテーブルのキャパシティが消費されます。
- 1 テーブルあたり最大で 5 つの LSI を作成できます。
- GSI と違い、テーブル作成時にしか追加できず、既存テーブルに追加・削除ができません。
- GIS と違い、LSI は強い結果整合性をサポートします。
ConsistentReadをtrueにすることで強い結果整合性の読み取りができます。 - セカンダリインデックスを使用したデータアクセス性の向上
Amazon DynamoDB のストレージ
DynamoDB のストレージは、容量制限がありません。自動的に拡張していきます。1GB 単位で課金されていきます。
東京リージョンでは、0.285 USD/GB (標準ストレージクラス)です。
同じデータベースサービスである Aurora は 0.11 USD/GB ですので、2 倍です。
S3(Standard) は、0.025 USD/GB ですので 10 倍となります。
ストレージ料金としては、決して安くないサービスであるので大容量のデータ保管には向いていないと言えます。
ただ、ストレージクラスは以下の2つが選択できますので、利用用途によってはかなり料金を抑えられる可能性があります。
- 標準(Standard)
- 従来からあるストレージクラス
- 標準 - 低頻度アクセス(Standard - IA)
- アクセス頻度が低いデータの保存に適したストレージクラス
- 標準より コストを 60 % 削減できる
Amazon DynamoDB の耐久性
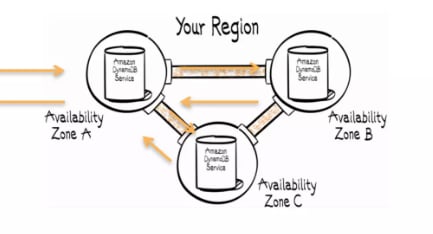
3 つの AZ にデータがレプリケートされることで冗長化されます。書き込みについては、少なくとも 2AZ に書き込みが完了した時点で、応答(Ack)が返却されます。
最終的に、全ての AZ に反映されます。
Amazon DynamoDB の読み込み整合性
先に述べたように、DynamoDB は CAP 定理「一貫性(Consistency)」「可用性(Availability)」「ネットワーク分断耐性(Partition-tolerance)」のうち、「可用性(Availability)」「ネットワーク分断耐性(Partition-tolerance)」を重視した設計となっているため、リレーショナルデータベースのような「一貫性」は保証されておらず、データはいつか必ず書き込まれる(通常は 1 秒以内)という動作になります。
そのため、デフォルトでは 結果整合性のある読み込み となります。この読み取りでは、最新の書き込み結果が反映されていない場合がある読み込みです。
もう一つの読み込みとして、強い整合性のある読み込み があります。Consistent Read オプションを付けたリクエストでは、この読み込みが行われ、リクエストを受け取る前までの最新のデータを読み取ることができます。Consistent Read オプションを付けられるのは、「GetItem, Query, Scan」です。
また、強い整合性のある読み込み は、結果整合性のある読み込み に比べてスループットキャパシティ(後述)の消費が大きくなります。
Amazon DynamoDB のパフォーマンス
スループットキャパシティといった、1 秒間の読み取り、書き込みに必要なスループットキャパシティをテーブル単位で割り当てることができます。
-
読み取りキャパシティ(RCU:Read Capacity Unit)
読み取りのスループットは、RCU(Read Capacity Unit)という単位で割り当てます。1 RCU は、4 KB の項目に対して、結果整合性のある読み取りの場合 2 回/秒、強い整合性のある読み取りの場合 1 回/秒、といった読み取り性能を表す単位です。
-
書き込みキャパシティ(WCU:Write Capacity Unit)
書き込みのスループットは、WCU(Write Capacity Unit)という単位で割り当てます。1 WCU は、最大 1KB の項目に対して、1 回/秒の書き込み性能を表す単位です。
DynamoDB を利用する場合は、テーブルごとに RCU と WCU を設計する必要があります。ただし、どれだけ必要か事前に見積もることが困難な場合が多いです。
そのような用途のために、「オンデマンド」と「プロビジョニング済み」という 2 種類のキャパシティーモードがあります。
キャパシティモード
キャパシティモードは 24 時間に 1 回だけ相互に変更することができます。
「プロビジョニング済み」から「オンデマンド」に変更すると、Auto Scaling の設定が削除されるので、もう一度「プロビジョニング済み」に戻す場合は注意が必要です。
- オンデマンドキャパシティモード
- アクセスのピークが予測困難な場合に適したモードで、事前のキャパシティの設定が不要です
- 使用したユニット数に応じた従量課金となるため、要求が多いとコストが増加します
- 自動的にキャパシティが調整されますが、一度キャパシティが自動調整されたのち、30 分以内に前回のピークの 2 倍を超えるトラフィックが発生するとスロットリング(一時的なキャパシティ不足)が発生します
- プロビジョニング済みキャパシティーモード
- 安定したアクセスが見込まれる場合に適したモードで、事前に予想されるキャパシティを設定しておきます
- テーブルにパーティションがある場合は、読み取り、書き込みはパーティションごとに均等に割り当てられます。
- 設定したキャパシティを超えた場合は、スロットリングが発生します
- スロットリングの発生を回避する仕組みとして、アダプティブキャパシティとバーストキャパシティがあります。
- Auto Scaling を使用することで利用率に応じてキャパシティを自動調整でき、スロットリングの発生を回避できます。ただし、即応性はないので急激な負荷には対応できない場合もあります
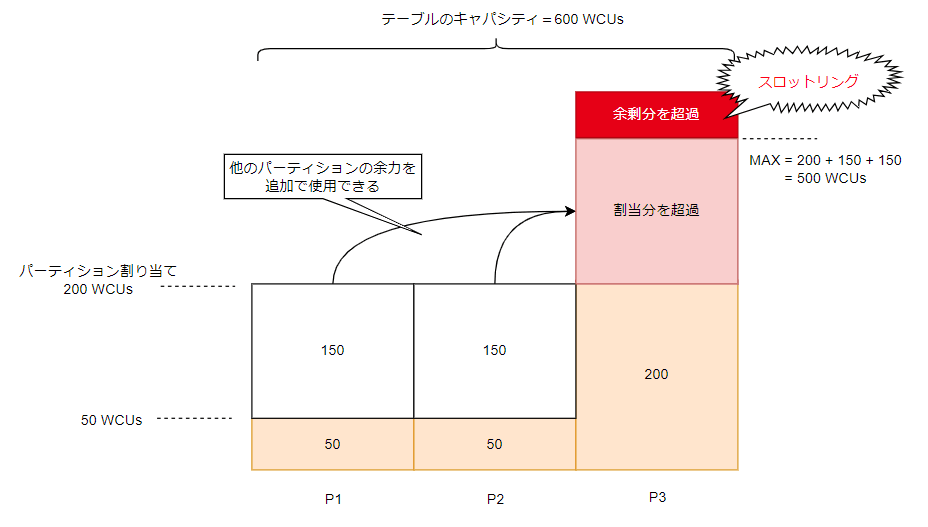
アダブティブキャパシティ
パーティション分割されているテーブルの場合、キャパシティは均一に割り当てられますが、アクセスが常に均一であるとは限りません。
ホットパーティションという、他に比べてアクセスが集中するパーティションが発生する可能性があります。
そのような場合にスループットを発生させないようにする仕組みとして、「アダブティブキャパシティ」があります。
次のように 3 つのパーティションに分かれているテーブルで、テーブルに割り当てられているキャパシティは 600 WCU だったとします。
パーティション1つずつのキャパシティは 600÷3 == 200 WCU になります。
瞬間的にパーティション「P3」のトラフィックが増えて、パーティションに割り当てられたキャパシティを超えたとします。
この時、他のパーティションは 50 WCU しか使っておらず、余力があります。
このようなとき、余力分を使用することでパーティション「P3」でスロットリングの発生を抑止することができます。
ただし、余力以上のトラフィックが発生したときには、スロットリングが発生してしまいます。
バーストキャパシティ
直近 5 分(300 秒)間の未使用分を使用して、急激なトラフィックの増加に対応する機能です。
テーブルに 150 RCU がプロビジョニングされており、5 分間全く使用されなかった場合は、150 × 300 = 45,000 RCU の容量があります。
その状態で 200 RCU のトラフィックが発生した場合、最大で 15 分間トラフィックを処理することができるようになります。
45,000 RCU ÷ [実際のトラフィック 200 RCU - テーブルキャパシティ 150 RCU) = 900 秒 = 15 分 (参考:Amazon DynamoDB はスパイクな負荷を短い間隔でどのように処理しますか?|re:Post)
ただし、バーストキャパシティはベストエフォートで提供されるもので、保証はありません。そのため、バーストキャパシティを期待した設計は行わないようにします。

Auto Scaling
EC2 の Auto Scaling と同じで、RCU、WCU を増減させてくれる。EC2 と同じように、即座に拡大するわけではないので、瞬間的にスパイクには対応できず、スロットリングが発生する可能性があります。
オンデマンドモードか、DynamoDB Accelerator (DAX)を使用したアーキテクチャを検討します。
Amazon DynamoDB Auto Scaling: 規模を問わないパフォーマンスとコストの最適化|AWS Blog
暗号化
保管データの暗号化(サーバサイド暗号化)
DynamoDB はサーバサイド暗号化がデフォルトで有効になってます。
作成時にデフォルトのままだと、AWS 所有の KMS キーで暗号化されます。
これ以外は、AWS マネージドキー(aws/dynamodb)や CMK を使用することができます。
転送データの暗号化
DynamoDB は SSL/TLS で接続するため、常に暗号化されています。
DynamoDB のテーブル操作
詳細は、Amazon DynamoDB API Reference
- list-tables: テーブル一覧
aws dynamodb list-tables
# response
{
"TableNames": [
"users",
:
]
}
- create-table: テーブル作成
aws dynamodb create-table \
--table-name 'users' \
--attribute-definitions '[{ "AttributeName": "user_id", "AttributeType": "N"}, { "AttributeName": "created_at", "AttributeType": "S" }, { "AttributeName": "post_id", "AttributeType": "N" }]' \
--key-schema '[{ "AttributeName": "user_id", "KeyType": "HASH" }, { "AttributeName": "created_at", "KeyType": "RANGE" }]' \
--local-secondary-indexes '[{ "IndexName": "post_local_index", "Projection": { "ProjectionType": "ALL" }, "KeySchema": [{ "AttributeName": "user_id", "KeyType": "HASH" }, { "AttributeName": "post_id", "KeyType": "RANGE" }]}]' \
--global-secondary-indexes '[{ "IndexName": "post_global_index", "Projection": { "ProjectionType": "ALL" }, "KeySchema": [{ "AttributeName": "post_id", "KeyType": "HASH" }], "ProvisionedThroughput": { "ReadCapacityUnits": 10, "WriteCapacityUnits": 10 }}]' \
--provisioned-throughput '{"ReadCapacityUnits": 10, "WriteCapacityUnits": 10}'
# response
{
"TableDescription": {
"TableArn": "arn:aws:dynamodb:ap-northest-1:123456789012:table/users",
"AttributeDefinitions": [
:
],
"ProvisionedThroughput": {...},
"TableClassSummary": {...},
:
}
}
- describe-table: テーブル詳細
aws dynamodb describe-table --table-name users
# response
{
"Table": {
"AttributeDefinitions": [
:
],
:
}
}
- update-table: テーブル変更
aws dynamodb update-table \
--table-name users \
--provisioned-throughput '{"ReadCapacityUnits": 3, "WriteCapacityUnits": 5}'
--return-values ALL_NEW
# response
{
"TableDescription": {
"AttributeDefinitions": [
:
],
"ProvisionedThroughput": {...},
"TableClassSummary": {...},
:
}
}
- delete-table: テーブル削除
aws dynamodb delete-table --table-name users
# response
{
"TableDescription": {
"TableName": "users",
"TableStatus": "DELETING",
:
}
}
# 完全に削除されたかどうかは、describe-table で確認します。
DynamoDB の項目操作
詳細は、Amazon DynamoDB API Reference
- help: 利用できるコマンドの確認
aws dynamodb help
# response
batch-get-item
batch-write-item
create-backup
create-global-table
create-table
:
- PutItem: 作成
aws dynamodb put-item \
--table-name users \
--item file://item.json
# response
なし
- GetItem: 読み込み
aws dynamodb get-item \
--table-name users \
--key '{"user_id":{"N":"1"}}'
# response
{
"Item": {
"message": {
"S": "dddddddddddddd"
},
"user_id": {
"N": "1"
},
"created_at": {
"S": "1544752292"
},
"post_id": {
"N": "5"
}
}
}
- UpdateItem: 更新
aws dynamodb update-item \
--table-name users \
--key file://key.json \
--update-expression "SET Answered = :zero, Replies = :zero, LastPostedBy = :lastpostedby" \
--expression-attribute-values file://expression-attribute-values.json \
--return-values ALL_NEW
# response
{
"Attributes": {
"message": {
"S": "update_xxxxxxxxxxxxxxx"
},
"user_id": {
"N": "3"
},
"created_at": {
"S": "1544748692"
},
"post_id": {
"N": "100"
}
}
}
- DeleteItem: 削除
aws dynamodb delete-item \
--table-name users \
--key '{ "user_id": { "N": "1" }, "created_at": { "S": "1544752292" } }'
aws dynamodb delete-item \
--table-name users \
--key file://key.json
# response
なし
- query: 条件に一致する項目の取得
expression-attribute-values は、コロン(:)から始まる変数を置き換える場合に指定します。
query が検索できるのは Key のみとなっています。同様の操作が出来るものに、scan のフィルタ式 がありますが、scan のほうは全件走査された上で、属性(パーティションキーおよびその他の属性)によるフィルターが行われる点で異なっています。
aws dynamodb query \
--table-name users \
--index-name xxxx-index \ ※GSI を指定する場合
--key-condition-expression 'user_id = :user_id and created_at >= :created_at' \
--expression-attribute-values '{ ":user_id": { "N": "1" }, ":created_at": { "S": "1544752292" } }'
# response
{
"Items": [
{
"message": {
"S": "dddddddddddddd"
},
"user_id": {
"N": "1"
},
"created_at": {
"S": "1544752292"
},
"post_id": {
"N": "5"
}
}
],
"Count": 1,
"ScannedCount": 1,
"ConsumedCapacity": null
}
- scan: 全項目 or 条件に一致する項目の取得
scan は全件走査の API です。これを多用すると、キャパシティが枯渇します。
aws dynamodb scan \
--table-name users
# response
{
"Items": [
{
"message": {
"S": "cccccccccccccc"
},
"user_id": {
"N": "3"
},
"created_at": {
"S": "1544748692"
},
"post_id": {
"N": "3"
}
},
:
}
query と同じような操作ができますが、そもそも scan は全件走査の API です。全データを取得した後、指定した属性(Attribute)で結果を絞り込むものです。そのため、キャパシティの枯渇に注意が必要です。
aws dynamodb scan \
--table-name users \
--filter-expression 'message = :message' \
--expression-attribute-values '{ ":message": { "S": "cccccccccccccc" } }'
# response
{
"Items": [
{
"message": {
"S": "cccccccccccccc"
},
"user_id": {
"N": "3"
},
"created_at": {
"S": "1544748692"
},
"post_id": {
"N": "3"
}
}
],
"Count": 1,
"ScannedCount": 5,
"ConsumedCapacity": null
}
DynamoDB ストリーム
テーブルの変更履歴を記録するフローで、変更の順番は厳密に記録されます。この情報は最大 24 時間保存されます。
DynamoDB ストリームを利用することで、イベントドリブンなアプリケーションを実装することができます。
ストリームは非同期的に動作するため、テーブルのパフォーマンスへの影響はありません。
ストリームの設定は、テーブル作成時、既存テーブルに対してもいつでも有効または無効にすることができます。
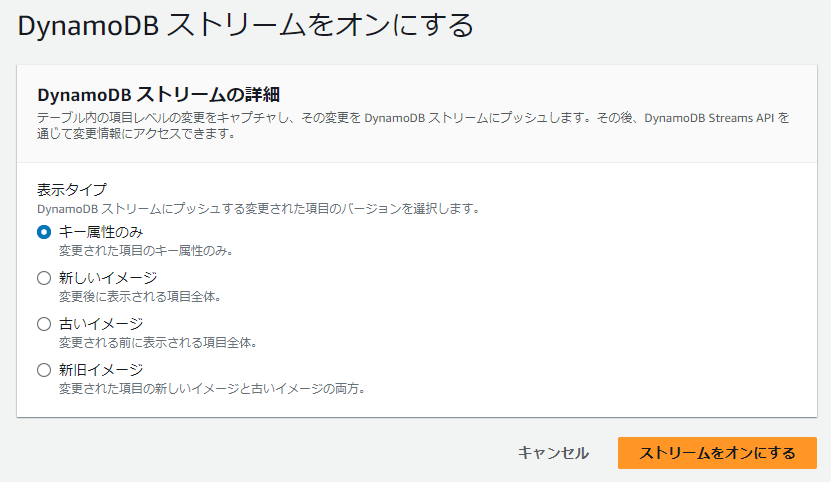
DynamoDB ストリームから「Lambda」や「Kinesis Firehose」を呼び出したりする用途が考えられます。

TTL(Time to Live)
DynamoDB の有効期限 (TTL) を使用して項目を期限切れにする
テーブルのレコードの有効期限を設定でき、有効期限が過ぎるとレコードが自動的に削除されます。
削除処理はバックグラウンドで動き、通常のトラフィックに影響を与えません。またデータは 48 時間以内に削除されます。
そのため、API リクエストの結果、期限切れになっているが削除されていないレコードも返ってくることがあります。「スキャンのフィルタ式」で、フィルタする必要があります。
TTL を使用するには、有効期限切れと判定する項目が必要になります。項目の属性は、Number 型で、格納する値は Unixtime(ミリ秒無し)である必要があります。

TTL の項目を追加したら、「追加の設定」から有効化することができます。

DynamoDB ストリームを使うことで、有効期限切れのデータをアーカイブすることもできます。

トランザクション
RDB のようなトランザクションまでは期待できないが、複数テーブルに対する操作をグループ化できます。
複雑なトランザクションは、設計に依存する部分が大きいので、ベストプラクティスを参考にしながら最適な設計を行う必要があります。
また、制約もあるため、利用する場合は確認しておきます。
- トランザクションには、100 件を超えるアクションを含めることはできない
- トランザクションに 4MB を超えるデータを含めることはできない
- 同一テーブルに 2 つのアクションを実行できない など
グローバルテーブル
グローバルテーブル – DynamoDB の複数リージョンレプリケーション
指定したリージョンに DynamoDB テーブルを自動的にレプリケートする機能です。グローバルに分散したユーザーがいる場合など、大規模にスケールされたアプリケーションを使用する場合に最適です。
レプリケーションは全てのテーブルに 1 秒以内に行われます。近いリージョンはそれ以下になることもあります。
また、同じ項目が複数のリージョンからほぼ同時に行われた場合、1 回目の書き込みよりも 2 回目の書き込みが「優先」されます。
これを回避するためには、最終書き込みタイムスタンプを使って、最初に取得した時点より大きい場合に書き込みを行わないように制御することが推奨されます。詳しくは、「条件付きの書き込み」を参照してください。

DynamoDB Accelerator (DAX)
DynamoDB Accelerator (DAX) とインメモリアクセラレーション
DynamoDB と互換性のある高可用性インメモリキャッシュを提供するフルマネージドサービスで、VPC 内に DynamoDB のキャッシュクラスターを作成します。
レスポンスをミリ秒単位からマイクロ秒単位まで高速化することが可能になります。

条件付き書き込み
デフォルトの DynamoDB の書き込み(PutItem、UpdateItem、DeleteItem)は無条件であるため、指定したプライマリキーをもつ項目が上書きされます。
これは複数人でデータを更新するような処理(たとえば、商品の在庫を減らす、訪問者数のカウンタなど)では、前の更新内容が失われてしまう場合が発生します。
それを防ぐために、条件付き書き込みという機能を利用します。簡単にいうと楽観的排他制御(楽観ロック)です。
下記のように、「update-expression」の更新が「condition-expression」の条件を満たす場合のみ実行されるようになります。
aws dynamodb update-item \
--table-name ProductCatalog \
--key '{"Id":{"N":"1"}}' \
--update-expression "SET Price = :newval" \
--condition-expression "Price = :currval" \
--expression-attribute-values file://values.json
{
":newval": { "N": "8" },
":currval": { "N": "10" }
}
アトミックカウンター
条件付き書き込みとは別に、アトミックカウンターというものが利用できます。この機能は、「UpdateItem」を利用して実現されます。インクリメントの他、デクリメントも可能です。
ただし、「UpdateItem」は失敗すると再試行する仕様であるため、二重実行される可能性があります。そのため、訪問者数のカウンタなど誤差が許容できるような場合にのみ使用し、厳密な数値が必要な場合には利用しないほうがよいです。
下記例の場合、「:incr」で指定した値を金額に加算していくものです。この更新処理は冪等ではありません。つまり、実行するたびに加算されていきます。
aws dynamodb update-item \
--table-name ProductCatalog \
--key '{"Id": { "N": "601" }}' \
--update-expression "SET Price = Price + :incr" \
--expression-attribute-values '{":incr":{"N":"5"}}' \
--return-values UPDATED_NEW
並列スキャン
DynamoDB の scan は全件走査 API です。ベストプラクティスは、query を使うものですが、どうしても全レコードに対する処理が必要になるケースがあります。
そのような時、並列スキャンを利用することで、効率よくスキャンすることができます。
並列スキャンを行うには、scan コマンドに次のパラメータを追加します。
通常の scan では、一度に1つのパーティションしか読み込むことが出来ません。
- TotalSegments:テーブルに同時にアクセスするワーカーの数
- Segment:コールしているワーカーによってアクセスされたテーブルのセグメント
複数のスレッドでセグメント分割したデータを取得するため、指数関数的にパフォーマンスが向上しますが、CPU のパフォーマンス、コア数、帯域幅の制約、テーブルの読み込みユニットによりパフォーマンス向上に限界があります。
バックアップ
DynamoDB のオンデマンドバックアップおよび復元の使用
バックアップ機能を使用し、バックアップを保存することができます。バックアップは Management コンソールか、API を使うことで、バックアップおよび復元することができます。バックアップや復元はテーブルのパフォーマンスや可用性に影響を与えません。
バックアップのオプションは次の2つです。
バックアップからリストアする場合、新しいテーブルにリストアされます。
また、この方法で復元されたテーブルには手動で下記の項目を設定しなければなりません。詳しくは復元を参照してください。
- Auto Scaling ポリシー
- AWS Identity and Access Management (IAM) ポリシー
- Amazon CloudWatch メトリクスおよびアラーム
- タグ
- ストリーム設定
- 有効期限 (TTL) 設定
- 削除保護設定
- ポイントインタイムリカバリ (PITR) 設定
DynamoDB のポイントインタイムリカバリ(PITR)
PITRを使用すれば、過去 35 日間の任意の時点にテーブルを復元することができます。
PITR で復元する場合、新しいテーブルに復元されます。
それ以上の期間を保持したい場合は、AWS Backup を利用してバックアップすることで 35 日を超えたデータを使って復元することができます。
DynamoDB 用の NoSQL Workbench
Amazon DynamoDB 用の NoSQL Workbench は、最新のデータベース開発および運用向けのクロスプラットフォームのクライアント側 GUI アプリケーションです。
macOS、Windows、Linux で利用できます。
どんな画面なのかは、プレビュー時の記事で確認できます。
NoSQL Workbench for Amazon DynamoDB – プレビューの使用が可能になりました(2019-9-19)
設計
DynamoDB を使用した設計とアーキテクチャの設計に関するベストプラクティス
リレーショナルデータベースと比べると様々な相違点があります。それらを考慮した上で、適切な設計を行わないと DynamoDB の能力を発揮できません。
ベストプラクティスのドキュメントを読み、 NoSQL に最適な設計をしましょう。
📖 まとめ

Discussion
GSIの作成上限は1 テーブルあたり最大で 20 個の GSI を作成できますね
上限数5個はLSIです
サービスクォータの緩和申請もできそうです。
ちなみに、AWS的にも現在はLSIではなくGSIを作成することが推奨されますね~
気付くの遅くなって申し訳ありません!
ご指摘ありがとうございます!助かります!