良いコード/悪いコードで学ぶ設計入門の感想垂れ流しまとめ
Twitterで適当に垂れ流した感想が、(私のTwitter力のなさにより)スレッド分断されて散り散りになっているので、一旦こちらにまとめる。おそらく最も重要なValue Object / Domain Primitiveの混乱については末尾に記載している。
このスクラップは、別途語尾を調整するなどして記事にする予定。その際のタイトルは良いコード/悪いコードで学ぶ設計入門の感想と改善点(仮)
最終的な記事はこちら↓
良いコード/悪いコードで学ぶ設計入門の感想と注意点
命名スタイルについて
いろんな命名が出てくるが、これがオリジナルなのか一般的なのかはもうちょっとあっても良い気がする。ただ、数学書も引用付きで示していなければオリジナルかどうかを厳密に判定する方法はない気がするので、めくじら立てなくても案件かもしれないが。
データクラスについて
ストラクチャー(構造体)にやたら否定的な感じを受けるが、必ずしもオブジェクトに生えるべきメソッドが全てではない。異なるクラスAとBについて、AとBを引数とする関数がAに生えるべきかBに生えるべきか別のところにあるべきかは決して自明ではない。
これはもちろん、データとロジックを集められるシチュエーションでは集めた方が見通しが良い場合が多いという事を否定しているわけではない。ただ、強い言葉で否定するスタンスはちょっと違うのかなというやつ。
データとロジックが離れていると、実装済機能との重複が生まれやすくなるという主張について
すでに実装済機能があるのに云々というのは、例えばa+bみたいな単純な計算を全てまとめるべきか否かという事と大きく関連するので、あまり簡単な話ではない。
再代入について
2.2、再代入については、再代入をした方がバグらないコードも結構ある。例えば、同じような処理を繰り返す場合で、かつ関数に分けにくい/分けた方が読みにくくなる場合は、一つの変数で結果を受け続けた方が登場人物が増えず頭のメモリを無駄遣いしない場合がある。
ただし、そもそもそのようなコードは関数に分けられるのではという指摘は十分にありえる(シャドーしてよい変数がある部分は、本質的に別スコープで行ける可能性があるということ)
サンプルのメソッド名について
sumUpPlayerAttackPowerみたいなやつは、そもそも名前がプレイヤーの攻撃力を合計するみたいな名前で、それの意味が不明という点で技術駆動命名である。目的は一体?攻撃力を出すならsumUpではなくて計算とかだと思うし、ダメージを出すには相手の守備力とか必要だから閉じてないし、計算ロジックで腕力と武器の力と守備力について、前者の合計を云々できる計算式でなくなったら、例えば人間とか敵とかを個別のクラスに分けてメソッドを生やすという考え方が破綻してしまう。
たぶんそれが理由で、ここでは敵と味方を扱うクラスの中で二つのメソッドが定義されてるけど、この時点でその事への説明はないので、2.3については私個人的にはめちゃくちゃ違和感しかない。
"Value Object" / Domain Primitivesを徹底することについて
2.4もだけど、HitPointを表すクラスは私には無理。もちろん、頭の体操としての効果を否定するわけではないが...
単純な+や-でなくなることで、読む時に実態として何をしているのか調べないといけなくなるのが厳しい。
「クラス単体で正常に動作するよう設計する」ことについて
指摘ばかり書いているとアレなので、3.1の最初とかは抽象論としては正しいと思う。ただ、3.1.1は賛同しかねるが...(言いたいことはわかるけど、クラスメソッド全否定みたいな否定が先立つ書き方に否定的になっちゃう)
3.2.1(コンストラクタで確実に正常値を設定する)はできる限り守るべきという意味で正しい。3.2.2(計算ロジックをデータ保持側に寄せる、の例として書いてあるMoneyのaddメソッド等)は、私は可読性が損なわれるとする立場なので、一長一短。ただし、常に悪い事だというわけではないし、そのような方法があると知る事は悪いことではない。
元のmoneyが再利用不要なときに
money = money.add(100);
と
money.destructiveAdd(100);
と
otherMoney = money.add(100);
のどれが読みやすいかは、難しい。
otherMoneyは頭のメモリ負担があり、moneyを使ってはいけないバグが出ることもある。
金額の乗算は、金額同士だと一般的な用途ではあまりないと思うけど、相手がintであれば定数倍なので需要はある。それは趣旨がわかりにくくなってそう、3.2.7のタイトル(現実の営みにはないメソッドを追加しないこと)がミスリードというか。
可読性は明らかに低下してるでしょって思うけど、まあそれは人の能力とかもあって、自称国語力がない筆者と、自称国語力がある私だとまあ主観は変わっちゃうだろうね。
Value Objectの定義について
Value Objectの定義はたしかにひどくて、これはまあ...
最近翻訳で書き下ろされた(byくまぎさん)これが基本的に正しい
これ、7/9時点の最新版でも直ってないけど、直さないのかな?まあこれはね...
値オブジェクト(Value Object)とは、値をクラス(型)として表現する設計パターンです。
ちがうよ、同一性がそれを構成する値によってのみもたらされるようなもののことだよ。いわゆるメモリの位置と説明されるオブジェクトとして等価かどうかとか、その他のidが等しいかどうかとかじゃないやつ。
他の人が散々指摘してはいるけど、例えば商品名が値オブジェクトって何、みたいなね。そりゃあストリングを値みたいなものと思えば(値っぽく振る舞う言語は多くある)何も言わずとも値オブジェクトではあるんだが。
なんというか、値オブジェクトは「このStringは何の種類ですか」みたいな概念ではない。
※このような概念は、出典の中にあるSecure by designで Domain Primitive と呼ばれる概念だけど、これについては後述する。
これは金額とか日付とかでもそうで、金額が値オブジェクトの例であるというのは、例えば本体価格、税金額、原価がそれぞれを意味するクラスであるべきという主張ではない。少なくとも、当初のValue Objectに関しては。
例えば、それらの値であるところの金額型は、通常はidで区別されるが、そうじゃなくて実質的な値で評価したいと言っている。
finalについて
可読性だけでいうと、finalつけるのは可読性落ちると思う。
というのは、finalついてるからこの変数覚えてなくていいという事ではないので頭のメモリ解放はできなくて、単に再代入されないとわかるだけで、これは書く時に誤らせない方法なんだよね。
ただ、あらゆるものを基本finalにして、そうでないものだけが変わり得る、という読み方もできる。でも、それも基本的には「この値を変えたらバグるから変えないでね」であって、可読性の向上ではなくてフールプルーフ。
可変インスタンスの使い回しについて
4.2.1とかは言ってる事がめちゃくちゃで、可変インスタンスの使い回しで書いてるやつ、(可変か不変かじゃなくて)使い回しの問題だと書いてる上に、不変であれば使い回しても渡した値を変えられないので正しく動くので、むしろ不変にする方に倒すべきで、それがまた後で出てくる。私は無理なやつ。
ところで、このサンプルコードのWeaponの引数がintでなくて、AttackPowerの引数がintなのはなんでなんだっけ...
これはマジで意味がわからん
どういう設計意図?
※AttackPowerのコンストラクタはint、WeaponクラスのコンストラクタはAttackPowerを引数にとる、それぞれ1つしかプライベートフィールドを持たないDomain Primitiveなクラス
「どんなとき可変にしてよいか」の内容について
グローバルでないスコープは全てある意味において局所的だと思うんだが、スコープが局所的なケースとは。
これmutableと再代入が混ざってる気がしていて、値のfinalは確かにimmutable的だし、immutableなオブジェクトを作るためにfinalは使うが、finalの効果は再代入禁止。
その上で、スコープが局所的ならmutableでもいいというのは...
(1) 本当にmutableの事なら「そのスコープの中で使用するクラスの定義の中ではfinalを使わなくていい」ということで、クラス定義の方ではそのクラスがどういうスコープで使われるか自明ではなく、破綻してる
(2) finalのことなら、散々再代入は悪みたいに言ってた事とも矛盾する
という事で、日本語として論理的にかなり意味不明に見える。
ここの時点までのまとめ
・不完全なオブジェクトがなるべくできないようにしよう
・なるべくデータとロジックを近くに書こう
・名前をちゃんとつけよう
これらは正しい。
抽象的な方針はともかく、もしこのサンプルコードを良しとするとしたら、とりあえず私はリファクタ依頼できないわとなってる。
もちろんこういうコードが求められる環境もあるんだろうと思う、ただ私には無理。
私には抽象化がすごく歪に見えて、私と説明の筋が噛み合わず、全体の構成や説明に違和感がある。
かつ、個別の具体論も美的に違和感がある。
行儀が悪い書き方ができなくするという考え方自体は正しいが、それを実践しているコードの行儀が悪いみたいなところがある
「5.2.2 生成ロジックが増えすぎたらファクトリクラスを検討すること」について
生成ロジックが増えたらファクトリメソッドを検討するという考えは正しいが、それを実際にサンプルコードとして挙げられている3000と10000の2パターンしかないポイントでやるなら、それはただの定数でやれって感じもある。
別に生成をする必要がない。
データとロジックの書く場所の整理について
データとロジックを近くに書くべきというのはあるんだけど、課題として
v = a.methodA()
w = b.methodB()
x = c.methodC()
みたいな時に、このメソッドを軸にしてコードを把握するために読む箇所がバラバラになってしまう事がある。このmethodA, methodB, methodCが本質的に多相性を利用するようなものであれば仕方がないところもあるが、多相性が必要なものではなくこのメソッドの中でだけ利用するような種類のものだとしたら、敢えてクラスの定義の方には書かないほうが見通しが良い場合もある。
さらに付け加えると、こういうときに、実質的には数値のDomain Primitiveについて、+とか-とかじゃなくて、独自定義のadd()とかだと実際の処理は何って把握に時間がかかる場合がある。これは、
- 共通の言語仕様によるわかりわすさ/なんでもできちゃう事
- 個別の定義のわかりにくさ/やる事が制限される事
のわかりやすさと制限のトレードオフ的なものがある。(常にすべてがトレードオフだという事ではないが)
(必ずしもこの本の内容ではないが)多相性は便利なんだけど、定義がどこにあるか目の前のコードでは確定しないという事はコードリーディングで解決しにくく、可読性が下がるんだな。
メソッドチェーンについて
メソッドチェーンは私も好きではないが、とはいえライブラリによっては一つのインスタンスをいじり倒したい場合もあり、インスタンスはステートを持たざるを得ない事もある。
その辺、今作ってるのは汎用的な材料なのか、具体的な実装なのか、という意識が必要。
サンプルコードの品質、ポリシーについて
コード断片だけだと設計意図が全然見えないという質のコードが並んでるのが厳しいな。
たとえば、MagicPointクラスは、差分をリストで管理するのが、いろいろな上昇補正を考えると合理的にも思えるが、一方でそれはintのリストでいいのか(パーセンテージと固定数値と両方保持しておかないと、例えばレベルアップした時にパーセンテージ補正は全部リストを作る元ネタを参照して計算し直すのかとか)みたいな事を考えると粗が目立っちゃう。
設計意図が断片から伝わってこないんだよな。
本質的な設計という事でいうと、このMPのやつ、HPMP入れ替えマテリアはどう実装するんだろうね。つまり、HPとMP入れ替えられる仕様にして、というのが来たときどうするのか。
オールセブンフィーバーとかもどの層で実装するのかは興味がある。
こういう、初期に予見できない無茶振りに対して、その設計はどれぐらい通用するのか?
そういう事も考えないといけない。もちろん、無茶振りに常に対応しないといけないという事ではないが、現実にはそのような当初想定外の仕様が付け加わるという事はある。作り込みすぎる事によって、ある特定の閾値を超えると途端に修正がしにくくなる、という事もある。そのバランスをどこに置くか、みたいな事がサンプルコードから伝わらない。
Equipmentsとか、なんでArmor/Head/Armをクラスとして分けずにEquipmentにしてるのか理解し難い。
HitPointとMagicPointはクラスが違うのに、それらは同じEquipmentなのはなぜ?
設計意図がまじで全然わからん、徹底してなさすぎるというか。
なんというか、めちゃくちゃ言葉を選ばずに言うと、「グランドデザインのない作業員が作業のために最適化したコード設計」みたいな感じ
もちろん一つ一つのテクニックは効果的にも使えるが、グランドデザイン不在で目先の対応みたいな。
そもそも私にはEquipmentクラスがある状態でEquipmentsクラスを作るというのがむむむって感じすぎてつらいが...
というのは、Equipmentの単純なリストみたいなのを想像しちゃうクラスに、ある一人の人の装備品みたいな意味を持たせるのがつらく、Members Equipmentとか、なんか人とひもづく事を明示するとか、そういうのがないと名前が不適切。
名前を大事にする本のはずなのに、名前を大事にしてないように感じる。
条件分岐に対する抽象的な考え方について
6章、switch文と単一責任選択の原則について冒頭に書いてある抽象論は正しい。この辺は少し安心して読める。(ただし、interfaceについては...以下)
interfaceをどう定義するかということについて
「なんの仲間であるか」がinterface命名の決め手
Fire、Shiden、HellFireからMagicというinterfaceを"導出"しているが、これは設計が先に無いという点において、唯一の命名法としては承諾しかねる。つまり、現在のコードを見て決める場合にはそういう決め方は確かにあるが、このような場合には本質的な設計が先立つ事のほうが多いと思う。
その場合「なんの仲間であるか」というのもあるが、「何を期待するか」という機能的な考え方もよくある(例えばJavaではSerializable、Cloneable、(Androidだけど)Percelableとか)
この辺、ボトムアップな命名法に言及しつつトップダウン/機能的な考え方がなくて、グランドデザインなしの設計が前提になってるように見える。
まさしく「グランドデザインなしのテクニカルなリファクタ用」みたいな感じというか。
そういうコードを書かないということでは無いので、当然書かないといけない場面はあるんだけど、根本的にはそっちじゃないみたいなやつ。
多少うがった見方では、この例の場合「火属性魔法」とかにならないように敢えて紫電というのを入れていると思うけど、そういうところがなんかね。なんの仲間であるか、という観点だと「火属性魔法」みたいなのも全然ありえてしまうけど、この場で求められている意味・機能性から「Magic」という落し所に暗黙のうちに落とされている。
switchの代わりのMapについて
確かにコードの見た目ではswitchによる分岐は消えるが、結局コードの本質はMapを定義するところでswtichで分岐しているのと同じで、本質的な違いがあるわけではない。循環的複雑度(CC)は下がるので、単にCCを下げるためだけのハックにはなるが。これはツールを騙すためのテクニックのような気はする。
コードカバレッジはむしろみにくくなる。関数がマップされているタイプであればコードカバレッジに反映されるが、これは生成したインスタンスがマップされているので、まさにこのマップのこのパターンを通過した、というものはコードカバレッジに出ない。
classの数が増えることについて
あとHellFireとかのクラス、どこまでプログラムなのか難しいけど、200こ魔法があったら200クラス作るかどうかだよな。
まあ効果が特殊だから個別に定義必要という説はあるが...
こういうの、構造体の配列とかで済ませたくなる事はあるよね。それはどういうゲームを作るか次第なんだろうけど。
interfaceと未実装について
interfaceを使うと未実装のままリリースされる事がなくなるというのは嘘で、適当なスタブを書いてコンパイルを通される可能性はある。そんなに本質的ではない。
7.2のサンプルコードについて
従来の論調だと毒の処理はmembersのメソッドであるべきではという事を思うが、そうなっていない。HP>0の判定がいろんなところで行われているし、そもそもHPに対してはisZero()みたいなの作ってたはずが、使ってないじゃん。
これこそ、似たような判定がいろんなところで行われる実例では??
これ、2.4とかでHitPointクラスつくってたのにmemberのhitPointはそのクラスじゃないのか
それは控えめに言って悪いコードじゃん!
こういうのが、グランドデザイン/設計ポリシーがないという感じ。
目先で対応しても、結局そういう悪いコードを書いちゃってる、というように見えてしまう。サンプル同士の関連はないと言いたいかもしれないが、一見して一貫性がありそうな似たようなテーマでサンプルを作っておいて、こちらはHitPointクラスを使う(しかもintをそのまま使うことをかなり批判した上で)、一方ではHitPointクラスを使わない、みたいなのはDomain Primitiveの考え方を徹底するとしてもしないとしても、いずれにしても一貫性のなさを強く感じる。
やや極論すると、コードに一貫性がなくても良い、というメッセージを発信しているようにすら見えてしまう。
最大の謎は、この本の確認した人たくさんいると思うけど、その人たちこれらの山ほどある気になりポイントが何一つ気にならなかったのだろうか?ということ。
私がコードレビューしたら、山ほど指摘つけてしまうが...
イメージ的には、100行のPRで5〜15コメントぐらいかな。
直感では10〜15ぐらいではと思ったけど、まあ100行の内容にもよるかなと思い。
全体的な設計に対する違和感について
この設計の大きな違和感の一つは、ロジックの概形と分岐させたいポイントを抽出してから設計する、というのがたりないところ。
金額や種類を抽象化して、普遍的に行う作業がなにかを概念化して、それを個別のクラスで実装できるように切り出すという設計の仕方が私にはすんなりとくるが、そこが違う。(もちろんボトムアップになる場合もあるが。)
ちょっとわかったのが、データの役割を設計できてない部分があるんだな。
永続化するデータとか、入稿するデータとか、要はプログラマが直接書く外でできるデータをどう扱うかの設計。
たとえば通常割引と夏季特別割引を含む割引の仕様なんて、システム的には柔軟な仕組みで設計しておいて、業務ユーザーが金額などを最終設計するということが普通によくある。
このあたりの全体設計不在という事については、他にもサンプルコードの「PositiveFeelings」などもある。
(PositiveFeelingsという感情によって行動の効果が上昇するという仕組みについてのサンプルコード)
PositiveFeelingsは内部的な制御ではあるが、それ以前にゲームシステムであって設計であり、根本的。
たとえばファイアーエムブレムみたいに隣同士で戦うとPositiveFeelingsが上がるとか、PositiveFeelingsのCRUDのようなものを考えないといけない。それを、付け焼き刃というかこういう切り取り方で説明するのは、私からすると本質的でない。
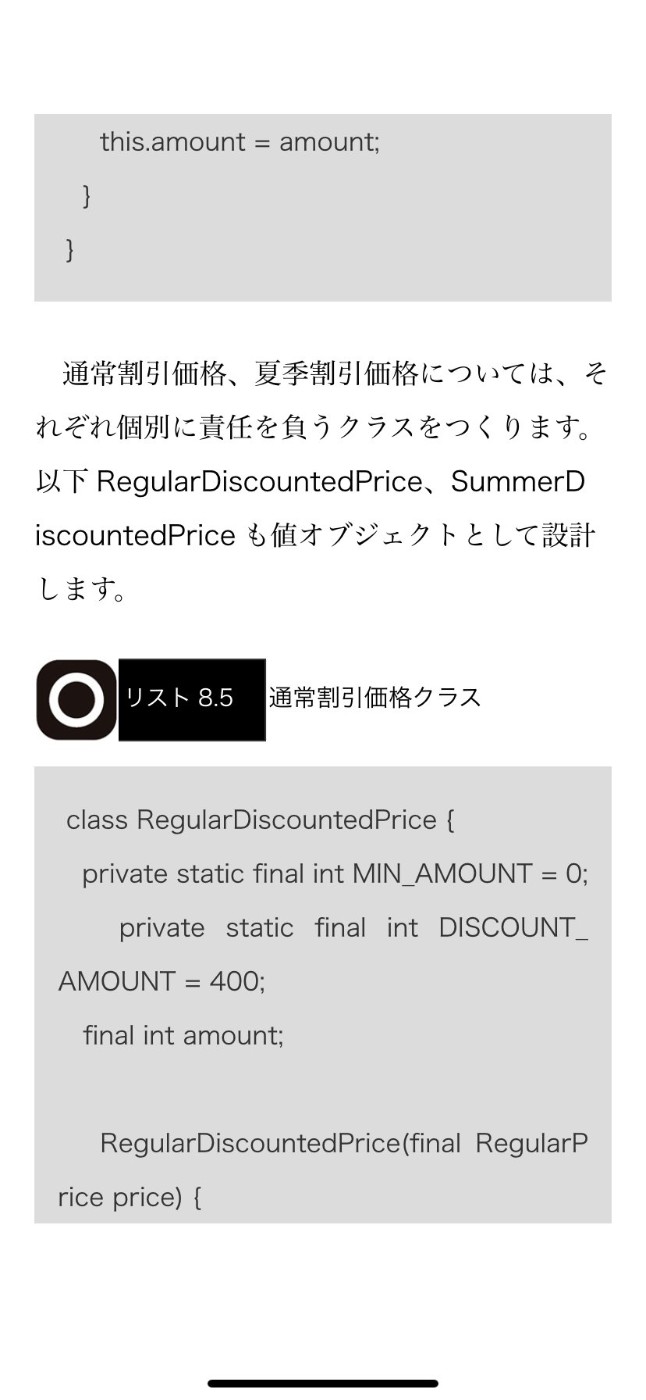
通常割引と夏季特別割引について
通常割引と夏季特別割引を別物として実装するか否かという話があるが、他に割引が沢山出て、その度に実装しないで済むようにするためには、汎用割引/値引クラスに、分岐せずに済むように名前と割引/値引方法と金額や比率などを入れればよい。
それぞれでクラスを作るという考えは必ずしも適切ではない。(場面による)
サンプルコードのインデントについて
iPhoneのKindleだからかなと思ったけど、インデントぐちゃぐちゃだな。
コメントもフォーマット統一されてないし、意図的にJavadocじゃないにしても、なんかもうちょっとあるだろう。
せめてlinter通るコードにしてほしい。
どっちも正解のコードだけど、インデントめちゃくちゃだし、コメントもあったりなかったり。
例)

「9.8 設計秩序を破壊するメタプログラミング」について
濫用するとよくないというのはわかるので、濫用よくないという主張は否定しないが、実際に破壊されているのは設計秩序というよりテクニカルなリファクタのしやすさ。
ここにクラス名を文字列として使っている、みたいに読んで構造がわかる書き方をしているなら、仮に静的解析できなくても秩序はある。
名前設計の考え方について
名前で関心を分離するということ、それ自体は正しいので10.1と10.2は主張としてはわかる。
ただし問題は、実際の画面においてはその分割された商品という情報+α以上がすべて一画面で処理されるような場合が多々あるということ。その一つの画面の実装を理解するために、個別の定義を見るのかという認知的な負荷の上昇について、構造が細かく分割されている事と比較してどう評価するか?というのは難しい。
驚き最小の原則のサンプルコードの命名について
tryAddGiftPoint()というメソッドがあるが、私はtryと言われると失敗するのかなと思っちゃう(判定条件がどうこうとかじゃなくて、try/catchが中で使われるとかそういうやつ)
個人的には、文法的に意味のある単語はなるべく違う意味で使わないでほしい。
もし私が名前をつけるとしたら、addGiftPointIfNeededとかそういうやつかな。
コードの読み方への違和感について
以下のような記述があった。

これ、名詞の形容詞的用法だろ、みたいな揚げ足取りもあるが、とりあえずそれは置いておく。
名詞の修飾は形容詞か名詞なので、この指摘は本質的には「複数の名詞が必要な時点で複合概念であって、分解可能な場合がある」という指摘になると思っていて、それは正しいと思う。
ただ、ここの書き方については、なんというか、「文を単語で見る」みたいな、真っ当な国語的な読み方 ではない 、超断片的な認知方法を感じている。「AI vs. 教科書が読めない子どもたち」で示されるような、国語力が無い人の「わかる単語だけを拾って、その他を切り捨てて文意を理解しようとする読み方」に通じるような"読解方法"のような。
この考え方は、実はその前の例題から気になってて、
int maxHitPoint = member.maxHitPoint + accessory.maxHitPointIncrements();
というコードがあってその下の別の箇所で
maxHitPoint = member.maxHitPoint + armor.maxHitPointIncrements();
って書いて間違えるというバグの例を書いていて、これは流石に定義を読めば普通の状態であればわかるので、もっと違う対策をすべき事だろう(テストを書いて検算をするなど)と思っていた。
でも、その変数の定義を見ないとすれば確かに自然にこのパターンの間違いが生まれてしまう。
それって、おそらく国語の問題を読むときに、単語を自分の思うように繋げて理解するのと同じで、それってつまり...みたいな気持ちになった。
これが、さっきの名詞の単語で見るみたいな話と繋がっていて、つまり、
プログラマはコードを読んでいない!!!!単語で想像して書いてる!!!
という事なのかと思ってしまい、ちょっと戦慄していた。
そんな人にメンテされるコード、まじでやばくないか????みたいな気持ちと、そんな人にでもメンテできるコードを、なんとかかんとか本質的ではないにしても創り出すみたいな気持ちと、...
と考えて、深く考え込んでしまった。
どこまでオブジェクト指向を徹底するか / 関数とメソッドの使い分けをすべきか否か?という事について
私がもし、上記のような読解力を前提としたメンバーで編成するとしたら、やっぱりオブジェクト指向的な色をなるべく薄くして、普通の関数で済ませるようにするな。
必ずしもメンバーの読解力として上記のような水準を仮定してはいないが、実際そうしてきたけど...
私はwebアプリを作っているが、webアプリにどこまでポリモーフィズムが必要か、というのは結構難しい。
ポリモーフィックでないなら、普通に関数呼び出しでよい。
この本にもあるように、いつも同じパターンで分岐が発生するみたいな時とか、ループで様々な型の中身のリストを処理したいみたいな時はポリモーフィズムが有効なんだけど、シチュエーションによってはデバッグで追いかけにくくなることがある。
11の「退化コメント」について
退化コメントについての指摘は非常に正しい。10と11は大意としては正しいと思う、サンプルの品質を除いて。
ここまでのまとめ
11まで読んでの感想としては、
大意としては正しいこともあるが、サンプルがイマイチすぎる。ポリシーが感じられないし、少なくとも私はこの正解コードをあげてくる人にリファクタや大域的な設計は任せられない。新しい考え方が無いわけではないが、もっと良いコードの本を読んだ方がよいのでは。
ただ、これは筆者一人の問題という事ではない。この本をレビューした多くの人が全員、重大なポイントをスルーしているというのが、非常に深刻で、本当に設計にこだわってコードを書いている人がレビューしたのかという気持ちが湧き上がる。全く理解できない。
といった感じ。
モデルの定義やモデリングの考え方について
13章に出てくるモデルの定義、
動作原理やしくみをかんたんに理解・説明するために、物事の特徴や関係性を図式化したものをモデル
システム構造を説明するために、単純な箱で図式化したものをモデルといいます。
これはちょっとはてな。図式はあくまでもモデルの図式であって、モデル自体は抽象化された存在の事であると思うが、まあ図式とモデルが同型だから図式の事をモデルという、という言い方も成立しなくはないので、ギリギリ許容範囲かもしれない。私の感性とはちょっと違うけど。
また、
ここで、商品はどういうモデルになるでしょうか。商品にはさまざまな付帯要素(情報)があります。
(中略)
これらすべてを盛り込むと、モデルの目的がわからなくなります。取り扱うデータが爆発的に増え、現実的ではありません。
これはある側面では正しくて、関係ないものは当然分解していくべきだし、困難は分割せよという前提はあるが、一方で、そもそもシステムはできる限り多くのものを統合して簡便に扱えるとしたら相対的に優れたシステムになり得る。多くの性質を持つ要素を、その瞬間瞬間では着目すべき部分を限定しながらも、全体では統合されたモデルというのは優れたモデルであり得る。
そのような背景を踏まえて、ある程度は統合したシステムの設計を目指す場合に、分割する事自体にコストがあったり、そもそも分割すべき概念か否かの判定というのが難しいという事がある。
例えば、何度も出てくる夏季割引価格は、割引という汎用概念のうちの時期指定割引として整理ができて、それは普通に割引に登録できる内容として線を引く事もできる。
こういう場合に、どこに概念として分割する線を引くかは設計の本質的なテクニックであって、DDDにおいて「ドメインと向き合う」というのは、まさにそのような線引きを実際のドメインにおける線引きと一致するように為されるべき、ということ。
やや極論でいうと、ドメインエキスパート/実際の利用者の頭が、割引を同列に扱っているなら同列に扱える仕組みが望まれるし、異なる扱いをしているなら、異なる扱いをする仕組みが望まれる。
※ただし、実際には新しい設計を導入してそれに合わせてドメインエキスパートを教育するという事も考えられるので、必ずしも今まさに実践されている事がベストという事ではない。ただ、最終的にシステム利用者の頭がどうなるか、ということ。
それを踏まえて、様々な考えられる線引きのメリデメをきちんと論じて、例えば今回は夏季割引を分ける、みたいな話ならわかるけど、そういう話の仕方ではなくて、一面的にそのような解釈ができるという事だけを根拠にして夏季割引とその他割引を分割せずに扱うことをNGとしているのが、ある種の宗教みたいになってしまっている。
必ずしも最終的な結論として夏季割引を分けるか分けないかのどちらかであるべきだという主張ではなくて、きちんとした検討や対話を経てその結論を出すというアプローチであるべき、ということ。このあたりを、ロールプレイ的に別の考え方についても検討をした上での結論として書いていないので、私はこの本のアプローチに同意できない。
逆にこの本のどういった部分は尊重できるか、何を期待して読んでいるか
上述のように、私はこの本の説明の多くは論理的な説明として正しいと思っていないが、ただ、実体験としてめちゃくちゃ修正しにくいコードがあった、というその体験自体は本物なので、それ自体は尊重すべきだと思っている。
例えばその解決策が、脳のメモリを増やす事なのか、目的や意図を持って読む事なのか、正確に書いてることをシミュレートできるようになる事なのか、書き方を変える事なのか、どの答であるべきなのか?という事についてはなんともわからないが、書き方を変えるというのも一つの答ではあり得ると思う。そのため、書き方を変えるというアプローチそのものについては、一つの洗練された方法に至る可能性があり、その洗練された方法を断片的に示した本にはなっているであろう、と思って読んでいる。実際、全く正しくないことだけという訳ではないと思う。思っていたよりも、間違っているように感じられる内容が多くあることは事実だけれど。
可読性について
この本ではよく可読性という言葉が出てくるが、そもそも本書で推奨される手法、例えばDomain Primitive(この本の中ではValue Objectと書かれている)を徹底することで可読性が上がるかというと、 むしろ可読性は下がる場合がある。 この事をあまりはっきりと書いていないが、これは重要な観点なので注意する。
「可読性」という指標はおそらく全順序ではなくて、かつ読み手にも依存するのだが、それを差し引いても、「ある種のダイアグラムがわかると意味がわかるが、ダイアグラムがないと読み解けないコード」の可読性が高いと言えるのかは謎。そういうところ。
例えば、純粋に宣言的な定義になっていれば、プログラムはその定義の箇所を見たり追いかけたりでどうにかなる。しかし、実際にはステートがあるし、何よりシステムが実際に動くという場面では「どこで誤ったデータが混入したのか」みたいな事を特定する必要はどうしても出てくる。そのような場合においては、極論すると巨大関数のほうがまだ読みやすい事もある。(巨大関数がよいとは言っていない。念の為。)
ただし、巨大関数だと読み解くために必要な変数とかが大変なことになるので、関数で分割されていたほうが基本的にはよみやすい(構造を把握しやすい)。
少なくとも、呼び出される関数がソースコードの時点で明確になっているなら、関数で分割されていたほうがいい。
※関数・メソッドについては、ポリモーフィズムとかでどの関数か一意でない場合のデバッグのほうが(他の条件が同じなら)難しくなる。実行時になるまで、実際にいま呼ばれる関数がなにか、という事がはっきりしないパターン。その意味で、単純な関数による実装で済むような場合には、単純な関数で書かれていることにも相応のメリットがある。
14章の大意について
14章の大意、テストを書いてから意味を把握してリファクタしていくという流れ自体は正しい。
14.5も抽象論として正しい。
14章のサンプルコードについて
14章ではなんで最終的に3章で定義したMoneyクラスを使うようにリファクタしてないんだっけ。3章「一方、Money型のように独自の型を用いると、異なる型の値が渡された場合にコンパイルエラーで弾くことができます。」
ここで使ってない理由は?コンパイルエラーで弾かなくていいのか??
このあたりが一貫性が無いように感じられる。
15章の大意について
抽象論としてはあまり間違っていないとは思うが、知識以外に何とトレードオフになって技術的負債が生じるのか、という事を論じないと片手落ちではあるように感じる。
無限に時間がない、というコメントはあるけど、そういう事だけではなく。
また、技術的負債という言葉の定義があるが、「状態を負債とはいわんだろ」みたいな日本語レベルでの話がある(これは揚げ足取りレベルだけど...)
動くコードを速く書くことについて
「動くコードを速く書くこと」についての話があるけど、私の経験では、確かに一部例外的に「早いけどコードめちゃくちゃ」という人はいるが、経験的にコードを書く速さと正確性は正相関があるように感じる。
やり方として、テストコードを先に書くほうが効率が良いか、後に書くほうが効率が良いかは難しいが、大体の場合は速く書けること自体は正義。
言い方を変えると、速く書けないという事は多分その人にとって難しい/シンプルではない事をやろうとしているという事なので、そのような難しいコードを書くべきでない。
実装や保守の時間を最適化することについて
たった一度の設計では、良き構造は見いだせません。
というのは、そういう部分はあると思うけど、まさしくこの本に書いてあるとおり時間は無限にないので、そのような"時間不足"を踏まえてどこまで設計を丁寧にやるのか、判断して決めないといけない。
パフォーマンスが落ちるからクラスを追加しない
というあたりは、最初から明らかにパフォーマンスに影響する箇所とそうでない箇所のあたりぐらいはつけるべき時がいくらでもあって、そのあたりが合っていれば大幅に後で効率化する時間を減らせる場合がある。
ただし、正しいコードを速く書くこと自体は必要だから、正しいことを保証するための時間を評価してクラスを追加したほうが速ければ、一旦クラスを追加しておいてから、リファクタでクラスのないコードも作って、そちらを動かす(ただしテストとしてクラスを残す)みたいな事はありえる。
心理的安全性に関する即落ち2コマ
本書より、

レビューの心理的安全性についてのコメント、

あかんやん!
即落ち2コマと言ったな?あれは嘘だ


このポエム、矛盾しててめちゃくちゃ面白いな。
つまり、レビュイーに十分な能力があって善意であると仮定するなら、「管理は管理でいいじゃないですか」でおしまい。
仕様変更時の課題になりそうと言っているが、実際に仕様変更が発生しやすいか否かなどの根拠もなく、説明不足。
にも関わらず、レビューがまともに機能しない、設計力がない、などと他責的な結論に至っている。設計力の問題なのか前提の違いや判断方法の差なのかはこれだけだとわからない。説得が一番は飛躍しすぎで、まずはもっときちんと話をしろ案件でしかない。
真に心理的安全性のあるチームであれば、レビュイーが自分の意見を主張するのは当たり前のことで、それを自分が正しいのに相手が理解しないみたいな姿勢で話すのは根本的に間違っている。なぜ本書のレビュアーの誰もこんな大事なことを指摘しなかったのか。
Value ObjectとDomain Primitiveの混乱について
これはValue Objectに関する記述の補足。
参考文献にsecure by designが挙げられているが、
これで紹介されているDomain Primitiveの考え方を、ただちにValue Objectの定義として扱ってしまっているように見受けられる部分がある。
Domain Primitiveとは、secure by designによると
What you end up with is a value object so strict in its definition that, if it exists, it’ll also be valid. If it’s not valid, then it can’t exist. This type of value object is what we refer to as a domain primitive.
というもので、つまり作成時からずっと不変であって、かつ不正な値を保持して存在することはあってはならないモノのこと。良いコード/悪いコードの本でValue Objectのなるべく満たすべき条件としていたのが、まさに不変性と不正な値で存在できない事であって、このDomain Primitiveの性質という事になる。
なお、このsecure by designでは
Nothing in a domain model should be represented by a language primitive or a generic type.
とまで書かれており、ドメインモデルのすべての要素はその言語のprimitiveで表現されるべきでないとまで言われている。私は個人的にはこれに全く賛同できないが、ただ、これを主張する背景にある目的はsecureであるという事であって、決して可読性や変更容易性ではない。
実際、secure by designでは
| Section | Problem area |
|---|---|
| Domain primitives and invariants | Security issues caused by inexact, error-prone, and ambiguous code |
| (後略) |
という事がかかれており、secureであることを目的としてのDomain Primitiveの考え方になっている。
この実装によってバグが減るので結果的に変更容易になるみたいな主張もあり得るとは思うが、少なくとも直接的に変更容易性を上げるようなものではないし、実際にドメインモデルのフィールドすべてをprimitiveではないものにしたら、そのコードを読むときにも修正するときにも時間は確実にかかる。大規模なシステムにおける効果などは議論の余地はあるが。
特に日本においては、これをそのままValue Objectの性質として扱ってしまっている界隈もあったりするので特別に混乱しているようにも見えるが、Domain Primitiveという考え方自体は日本特有という事でもなく、DDDと切り離してスタンドアローンで導入できる良い方法であるとするQualcommの.NET開発者の方のブログ記事などもあったりする。
(私は、場面において有用なケースの存在を否定はしないが、全体的に強いルールで導入することにはあまり賛同しないという立場)
Domain Primitiveの考え方は、Value Objectのうちの特に強い性質を持つものとして定義されているものの、個人的にはDDDのモデリングに関する本質的な部分ではないと思っている。
何をシステムの本質とするのは非常に難しく、システムが安全・厳重に動くという事もまた本質ではないのかと言われると強く反論することはできないのだが、少なくとも機能設計とは対処する領域が異なる。つまり、「Domain Primitiveを使おう!」という事は、新機能の機能的な設計そのものには全く寄与しない。
もちろん、Domain Primitiveを使った設計という概念は存在して、Domain Primitiveを使って実際にものを組み上げるための設計をする事を否定はしないし、それはそれで有用・意味のある事ではあると思うが、「DDDの最も重要な部分」などではないと思う。
Domain Primitiveのようなテクニックは、機能性の概念と独立に/補うような形のテクニックであって、軽んじられるべきではないが、しかしDDDの核心という事ではない。