致命的な障害を減らすための可用な設計入門 - 設計と算盤
概要
この記事では、システムが全体停止するような致命的な障害を減らして可用性を高める事を目指して、
- エラーやバグによる故障は、実績をベースに算数(算盤)で統計的に計算できる(ある程度は。)
- 作業量・アウトプットを増やすとエラー・バグは自然に増える
- 自然に増えるエラー・バグの影響は設計である程度抑えられる
- アプリケーションの設計には独立性や冗長性といった概念もある
- ビジネス(算盤)の継続性において、こうした設計の考え方が重要である
というような話をします。
一般論として、全く障害のないシステムを構築運用するのは難しいと思いますが、それでも様々なエラーが発生する中でもできる限り致命的な障害を回避するのは重要です。そこでこの記事では、単一障害点の概念を通して、機能数が増えると特別な対策をしなければ自然と障害が増えることと、システム全体が停止するのを避けるような設計について、入門的な考え方を記載します。
「設計と算盤」言いたかっただけちゃうんか
なお、システム全体が停止するような障害は、システムに関わる全ての人に影響します。従って、開発者・設計者のみならず、システムにかかる判断をする経営者も概念を理解しておくべきです。そこで、この記事は開発者、経営者、コード設計者のそれぞれへのメッセージを含んでいます。
開発者には、 機能設計時点での機能独立性への考慮や、「低い負荷で機能が実現できたらOK」と思って"データベース負荷などの真に致命的になり得るパフォーマンス問題"を軽視しないようにすること。また、単一障害点がなるべく少なくなるような設計を検討すること。
経営者には、 機能開発の量を単純に増やすと、単純なエラーやバグは作業量に比例して増えること。また、機能の間の関係性・構造が整っていなければ、そのバグが影響する範囲・期待値は機能数に応じてどんどん増えていくこと。従って、そうならないようにアーキテクチャ設計などを工夫する必要があり、それがゆくゆくはビジネスの要になること。
コード設計者には、 狭義のクラス設計に限らず、より包括的な概念として設計というものがあって、その一例として(コード・クラス設計でない)アーキテクチャ設計の考えがあるということ。また、アーキテクチャ設計によって、必ずしもアプリケーションの具体実装に立ち入らずにサービス品質を向上させられる場合があること。クラス設計とパフォーマンスは両立しない訳ではないが、コード可読性という観点でのクラス設計のみを是とすると、パフォーマンス等によってそれが問題となる場面もあること。
そういった事が伝わるといいなと思っています。
以下に骨子を示しますが、もし骨子がわかりにくい場合は、後ほど詳しく説明していくので気にせずに読み進めてください。
※情報を少し盛り込みすぎたかもしれないので、簡潔にわかりやすくまとめ直した記事の出現を期待しています!
骨子
- 単純に同じ作業の仕方を継続する場合、その作業に伴う誤り・エラーの総数の期待値は作業量に比例する。
- 従って、作業の仕方を変えずに2倍のペースで作業をしようとすると、その作業に伴うエラー数の期待値は2倍になる。
- その意味で、単純に作業量を増やすと障害が増えるのは当然のことで、サービスの成長を加速しながら障害を増やさない/減らすためには特別な工夫が求められる。
- エラーが即座に致命的になるか否かは設計によって少し変えられる。
- システムの設計上、追加した各機能のいずれか一つにエラーがあったら全体が壊れるような構造(=全ての機能が全体への単一障害点)であるとすると...
- 継続運用への影響:機能が
n r
n(1-(1-r)^n)=n({}_nC_1 r - {}_nC_2 r^2 + ...)\fallingdotseq n^2r
となる。(n,r nr - 改修への影響:機能追加時に、その機能が壊れるレベルのバグの混入率を
b nb - 従って、この構造の場合には、機能が増えるほどシステムは脆くなる。
- 継続運用への影響:機能が
- 一方、システムの設計上、追加した各機能がすべて独立で、単に追加した機能が壊れるだけの構造であるとすると...
- 継続運用への影響:機能が
n r nr - 改修への影響:機能追加時に、その機能が壊れるレベルのバグの混入率を
b b
- 継続運用への影響:機能が
- 性能に影響するような問題は、テストで検出しにくい場合があるが、時に致命的な影響を与える
- 性能問題というよりバグというべき状況がある
- 一般に、機能が独立であったり、冗長化された設計になっていれば、1機能・1部分の故障が全体に波及せずに済む。(影響の局所化)
- これは、アプリケーション/ミドルウェア/インフラを問わず、様々なレイヤーで対処できる。
- 例えば、全く同じWebアプリケーションプログラムを複数のサーバーで動かして、エンドポイントによって別のサーバーにアクセスさせるようにすれば、ある機能がアクセス過多になっても別の機能は動くといった状況を作れる場合がある。
- 裏側でデータベースを共通で使用していたら結局データベースが単一障害点となってしまう可能性はある。
- しかし、エンドポイント別でロードバランサーによってアクセス量を制限するなどすれば、アプリケーションプログラムそのものには手を入れずに負荷をコントロールできる。
- 並列処理の競合対策(ロック等)のような複雑な問題がなければ、負荷の概数は算数で計算できる。
- 特定のエンドポイントのみ応答停止させる、といった措置を取ればデータベース全体をダウンさせずに特定の機能の縮退だけで済む。
- このような対応は、複数のサーバー/インスタンス/コンテナでアプリケーションが動作するような設計になっていると行いやすい。
- アーキテクチャ的な設計によって耐障害性を高めることができる。
- このように「運用上各機能が独立になっているか」言い換えると「他の機能が故障してもその機能は影響を受けないか」「この機能の故障は他の機能に影響を与えないか」という事は、設計の時点で考慮されるべき。
- パフォーマンス問題は、時に単純なバグよりも致命的なシステム全停止を引き起こす。
- このような観点での設計が十分にできているか否かは、サービス規模が小さいうちは目立たないが、規模が大きくなると機能数
n
- つまり、設計によって、ビジネス(=算盤)の継続性に大きな影響が出る。
それでは、以下本論となります。
アウトプットが倍になれば、途中で生じるエラーも倍になる
私達は、なにかの作業をしていると、意図せぬ失敗をしてしまう事があります。
タイポなどはその典型的な例です。他にも、プログラムであれば変数名を間違えたり、不等号を間違えたり、アルゴリズムの順序や記述を間違えたり、代入先を間違えたり。何気ない行動が、結果的に誤っているという事はよくあります。
通常、よほどの精神力でも無い限りは、作業効率を落とさずにこのような失敗を極端に減らすことは難しいです。リラックスしたり集中したり、コンディションによって失敗率は増減しますが、ゼロにするのは困難です。エラーは減らした方が良いですが、その前提で、人間はどうしても失敗してしまいます。
これを踏まえて、システム開発におけるエラーについて考えてみます。いま、10人で開発しているシステムがあったとして、このシステムの開発速度を上げるために人数を倍の20人に増やしたとします。そうすると、このチームの体制がものすごく改善したとか、特殊なツールを導入したとか、そういった特別な工夫が無い限りでは、全員の作業で発生するエラーの数の合計は単純に倍になります。 これは、単純に自然の摂理のようなもので、疑いようは無いと思われます。1人あたり10エラーを生じるとしたら、20人になれば10*20=200のエラーが出るという算数の問題です。
ここで重要なのは、ある個人が発生させたエラーが直ちにバグになるとは限らない ということです。一般には、一個人の作業の中でエラーがあったとしても、それをレビュー等の工程で訂正することができれば、最終的にバグとして発現させずに済みます。従って、(途中で生じる)エラーの数が増えても、それが致命的なバグとして発現させないようにする仕組みを工夫すれば、エラーが致命的な影響を及ぼすことを避けられます。 この記事では、このようにエラーやバグをいかにして致命的にしないようにするか、という事を考えていきます。
エラーをバグにしない、バグを致命的にしない
エラーをバグにしないための取り組みとしては、上述のようにレビューを増やしたり、コンパイルエラーなどによってバグが生じる前に開発者が気付くようにする、といった事があります。例えば、プログラムを書いた時に、文法的に正しくない場合に開発者にわかるようにコンパイルエラーにすることで、エラーが発生したらすぐに開発者が気づけるという仕組みです。このような仕組みは、そもそもバグを発生させないという点で有効です。
一方で、バグが残ってしまった場合に、それを致命的にしないという仕組みもまた重要です。
というのも、例えばWebアプリケーションにおいてデータベース負荷がかかる処理を書いたコードがあった場合、普通はその問題点を指摘してくれたりはしません(一部のLinter等では、N+1問題の検出などはできるかもしれませんが)。コードレビューにおいても、レビュアーがスルーしてしまう可能性があります。そうすると、コードに潜在的なバグが残ったままリリースされてしまう事になります。
厄介な点は、単純な機能バグであればすぐに気付けたとしても、パフォーマンスに関しての問題の場合には気付けない場合が存在し得るということです。特に、元々パフォーマンス的に問題があると思われる処理はまだしも、パフォーマンスに問題があると思っていなかった処理について、実は深刻なパフォーマンス問題がある、というような場合はしばしば発生します。
少し込み入ったパフォーマンス問題の具体例
私が遭遇したものでは、DBのパフォーマンス問題で「あるテーブルについて、本番環境もステージング環境も同じインデックスを定義しているが、本番環境は(アプリケーションの機能を介して)一つのINSERT文で大量にデータを増やしてしまったため、アプリケーションの別の機能で登録したステージング環境とは異なって統計情報がすぐに最適化されず、深刻なパフォーマンス問題が発生した」というような事がありました。ステージング環境で本番と同等(になる想定)のデータでテストして、パフォーマンス的にOKであったが、本番環境ではいきなりパフォーマンス問題が発生する、という事象でした。
このときは特定のクエリが遅いというだけで済んだのですが、時によっては問題はもっと深刻になります。インデックスを使えないクエリによってDBのCPUを使用しすぎてしまい、DB全体のCPU負荷が高まり、結果的にすべてのDBへのアクセスが遅延、アプリケーションが完全に応答を停止するという事象まで考えられるのです。
こうなると事象は大変深刻で、この機能が単純にバグっていた場合の方がよっぽど軽症という事にもなります。このように単純なテストでは見つけられない、ステージングに本番と同じ環境を準備したつもりでも本番は実際には同じにならずにテストをすり抜ける、といった事象は確実に存在しています。
このような問題は、しばしば開発者のレベルでは軽視されてしまう事があるように感じますが、実際に引き起こす問題の大きさで言えばただのバグよりもはるかに重大です。
このような"バグ"が発生してしまう前提で、それを少しでも致命的でなくするには?ということを考えていきます。
システム全体を機能の集合体として捉える、単一障害点の把握
これからシステムが全体停止しない構造について考えていきますが、まずはシステムを「様々な機能・モジュールの集合体」として捉えることにします。
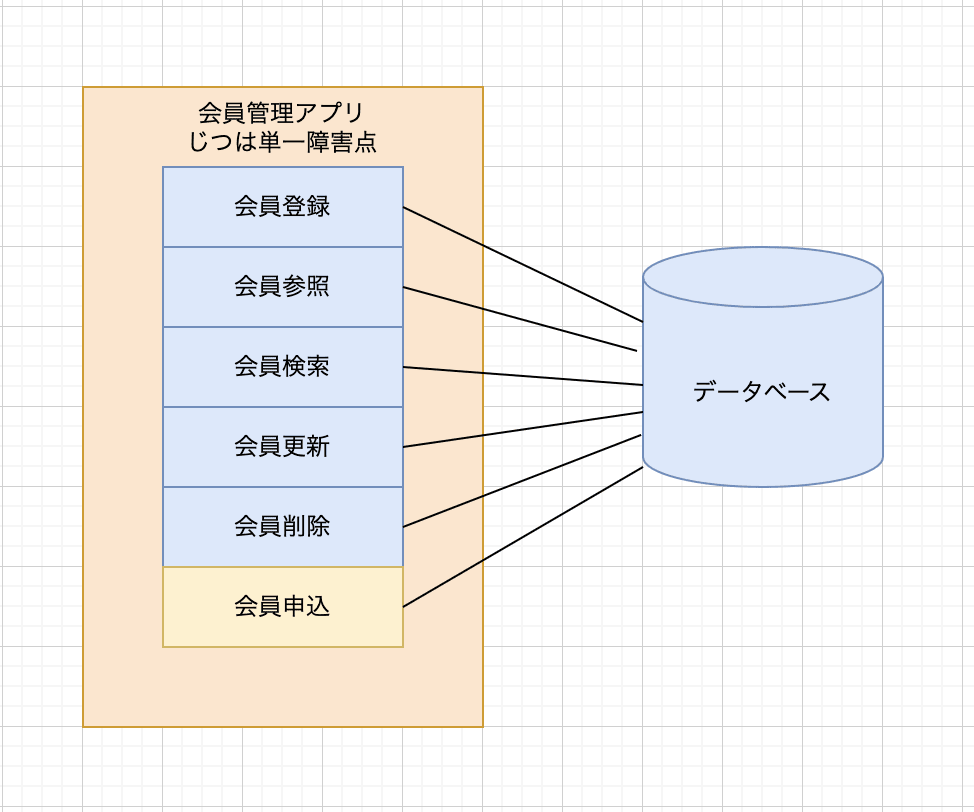
例えば会員管理システムであれば、会員登録機能、会員参照機能、会員検索機能、会員更新機能、会員削除機能、といった機能があります。ここでは、話を簡単にするため、会員の情報を保存するデータベースも単独で一つの機能として捉えることにします。

このとき、会員登録の画面のHTMLのコーディング時に、誤って登録ボタンを消してしまったとします。
当然、会員登録はできなくなりますが、これは会員登録にのみ影響するバグで、データベースや参照などの他の機能への影響はありません。
一方、運用担当が誤ってデータベースを停止してしまったとすると、全ての処理を行えなくなってしまいます。このように、ある機能やモジュール等が停止するとただちにシステム全体が停止してしまう場合、 単一障害点(Single Point Of Failure, SPOF) と言います。
この単一障害点を把握することは、バグを致命的にしないようにするために重要になります。というのは、単一障害点で機能停止するバグが発生したら、それはただちに全体を停止させてしまうからです。従って、まずは単一障害点の把握と、単一障害点に対して要求する処理の把握が重要になります。
「単一障害点に対して要求する処理」というのはあまり聞き慣れない概念と思いますが、次のようなことです。

このような場合には、会員登録機能はSPOFではないのですが、会員登録機能からの影響によってSPOFであるデータベースが停止して、結局システム全体が停止してしまいます。
このように、ある機能自体はSPOFでなくても、その機能がSPOFに作用して全体を停止させる というような事象は発生します。従って、SPOFに対する処理要求(ここでは、会員登録機能がデータを登録する要求を送ること)に対してはある程度慎重になる必要があります。
単一障害点ばかりのシステムと、真逆のシステムの、それぞれの壊れやすさ
では、単一障害点ばかりのシステムと、そうでないシステムにおいて、実際にどれぐらい障害の影響の差が出るのでしょうか?
システムの継続的な開発をしていて、機能を追加していくときに、
(A) システムの設計上、追加した各機能のいずれか一つにエラーがあったら全体が壊れるような構造(=全ての機能が全体への単一障害点)
(B) システムの設計上、追加した各機能がすべて独立で、単に追加した機能が壊れるだけの構造
この2つの場合について、障害の影響を受ける期待値を計算していきます。
継続運用への影響と、改修時の影響と、それぞれで考えましょう。
(A) システムの設計上、追加した各機能のいずれか一つにエラーがあったら全体が壊れるような構造
継続運用への影響: 機能が
となります。この右辺の
という計算になります。一般には近似できない場合もありますが、これは少なくとも
改修への影響: 機能追加時に、その機能が壊れるレベルのバグの混入率を
従って、この構造の場合には、機能数
(B) システムの設計上、追加した各機能がすべて独立で、単に追加した機能が壊れるだけの構造
継続運用への影響: 機能が
改修への影響: 機能追加時に、その機能が壊れるレベルのバグの混入率を
一般なシステムの構造は(A)と(B)の間の構造になりますが、できる限り(B)に近い構造を維持するようにすれば、機能数の影響を受けにくくなります。
こうして文章にするとすごく当たり前の話かもしれませんが、できる限り独立な機能になるように設計したほうが、一つの機能の影響が他に及ぶ事が少なくなります。
一般に、機能が独立であったり、冗長化された設計になっていれば、1機能・1部分の故障が全体に波及せずに済みます。このような影響の局所化を適切に行っていくことで、エラーが増えても少なくとも全体は停止しない・しにくいようにできます。
様々なレイヤーにおいてエラーを捕捉すること
これまで述べたような、1機能・1部分の故障が全体に波及しない設計という考え方は、アプリケーション/ミドルウェア/インフラを問わず、様々なレイヤーで対処できるものです。
ここでは、実際にアプリケーションレイヤー以外で対応する場合を考えてみます。
先程の例で用いた、たびたび障害が発生している会員管理システムですが、一般会員の会員申込機能を追加することにします。これまでは管理者ユーザーが会員を登録するだけだったのが、Webで会員申込を受付けるようにする、ということです。

さて、満を持してこの機能をリリースしましたが、会員申込に大量の人が殺到してしまいました。
このままでは、無限会員登録編の再来になってしまいます。めでたしめでたし
どうすればよいのでしょうか?
座してシステム完全停止を待つのみでしょうか??
独立な機能がSPOFに過剰な要求をする場合に、影響を制限する方法
この場合、サーバーリソース(アプリ、データベース)を増強するという事が対策の一つとして考えられますが、アーキテクチャによってはリソースを増やす対応をすぐに取れない場合もあります。
当初想定していたよりたくさんアクセスが来てしまった、という事実は変えられないので、そうすると全く無傷という事にはいかないでしょう。
しかし、対象業務領域をいくつか絞ることで、よりマシな対応は考えられます。
例えば、会員申込の機能のみ、データベースにアクセスして処理をさせずに、システムエラーを表示させるといった方法です。
そうすると、会員申込の機能は使えなくなりますが、SPOFであるところのデータベースを守ることはできます。
よりマシな方法としては、会員申込機能へのリクエストの一部を「おまちください」という画面表示に振り分けて、残りは普通に処理を行わせるという方法です。これは、データベースの負荷を計算して、また現在発生しているリクエストも調べて、どれぐらいなら耐えられるかを算数的に計算して処理継続する、というような方法です。
これは、アプリケーションで対応することも可能ですが、nginxやロードバランサーなどで設定対応することもできます。
ちなみに、もし「会員管理アプリ」が一つのWebサーバーで動いていたとしたら、実はこのサーバーもまた単一障害点となります。
つまり、会員申込へのリクエストがあまりに多すぎると、データベースへのアクセスの前に単純にサーバーがパンクしてしまうということです。
このような状況を改善する方法としては、会員申込のプロセスを別のサーバー/インスタンス/コンテナetc.で動作させる、といった方法があります。これは概念的に次の図のような構成にしてしまうということです。

これは具体的には、ロードバランサーを配置して、ロードバランサーでエンドポイントによって振り分け、(さらに会員申込のエンドポイントは負荷によってエラー画面を含む振り分け方法を調整)といった方法で対応ができます。
このような対応ができるためには、そもそも複数のサーバー/インスタンス/コンテナでアプリケーションが動作するような設計になっているという前提条件が必要となりますが、システム全体を停止させないという意味で効果的な対応となります。
なお、この例では大量アクセスにより単にデータベース(SPOF)への負荷が増えた場合を考えましたが、この手法は大量アクセスが原因でなくても、突然SPOFへの負荷が増えて許容量を超えた といったパターンの事象に対して有効な対策となります。
実際、この記事の初めの方で紹介したようなパフォーマンス問題が発生した場合にも、データベースで遅延しているクエリを調べたりエンドポイント別のレスポンスを調べたりすれば、どのエンドポイントが引き金となってパフォーマンス問題が発生しているのかはアタリを付けることができます。そのエンドポイントを一旦遮断するという対応は、緊急措置として有効です。
さきほどの無限登録の例についても有効です。仮にHTMLの不備で無限に会員が登録されているという具体的なメカニズムがわからなかったとしても、とりあえず会員登録が異常に発生していることさえわかれば、会員登録に蓋をしてしまえばその他の機能は使えるという事になります。
この手法を一般化する場合、負荷などでなにかトラブルが発生した場合にも、一次原因となっている機能がなにかを特定する方法を準備しておくことが必要 で、それができればこのような機能制限や分割などによって影響を局所化できる事になります。
機能的な冗長性の確保
そもそも、このような事態になることを避けるには、どうすればよかったのでしょうか?
一つは、リソースを柔軟に増強できるようにしておくという事があります。これは、素朴に物理サーバーを用いた仕組みだとすぐに対応することは難しいですが、仮想サーバーを用いた仕組みや、いわゆるサーバーレスと呼ばれる仕組みであれば、対応がしやすくなります。スケールやクラスタリングが可能なアーキテクチャを前提としてアプリケーションを構築していれば改善されます。
ただ、単純なアクセス増であれば、1台あたり/1インスタンスあたり/1プロセスあたり/1CPUあたりに捌けるアクセスをもとに必要なリソースを計算できますが、冒頭で示したパフォーマンス問題やその他のアプリケーションバグなどが根本的な原因であったとすれば、それを事前に察知することはできません(事前に察知できれば苦労はしない...)。仮にオートスケールするような仕組みにしていたとすると、意図せぬ負荷の発生によって無駄なリソース消費が発生してしまう可能性もあり、単に障害が起こるよりもむしろ被害が大きくなるといったケースまで発生します。あるいは、デッドロックの多発のようなアプリケーションの問題があったとすると、リソースを増やしても結局機能しないといった事もあります。これは、根本的にはアプリケーションの問題ですが、その実装の根本的な改善まで時間がかかってしまう場合もあります。
そのような場合の対策の一つとして、機能レベルで冗長性を確保する という事があります。
どういう事かというと、ある機能がうまく動作しない場合に、別の最低限の機能によって目的を達成するという事です。
例えば、会員申込にアクセスが殺到してしまった場合には、GoogleFormなどで簡易申込画面を作って、そちらに誘導するといった対応も考えられます。取得したデータを転記するなどの別の対応が必要になりますが、申込したい会員を取りこぼさないようにするという意味ではこのような対応も最低限の手法として選択肢になります。
広義の機能冗長性を満たす手法としては、切り戻しもあります。
新しい機能をリリースして問題が発生した場合、以前のバージョンに戻すことで動作が担保される場合があります。このとき、例えば新しいバージョンが動作する環境と以前のバージョンが動作する環境の2つを作り、以前のバージョンが動作する環境の方にアクセスを切り替えるとすれば、これは冗長構成にしておいて故障があった場合に待機系に切り替えることと同等です。このような対応が可能なアーキテクチャにしておくことも、一つの改善方法です。
まとめ
これまでに見てきたように、一つのエラーを全体のシステム停止に波及させないためには、次のことに気をつけておく必要があります。
- 「運用上各機能が独立になっているか」言い換えると「他の機能が故障してもその機能は影響を受けないか」「この機能の故障は他の機能に影響を与えないか」という事を設計の時点で考慮する。(機能的独立性)
- 障害が発生した場合に、SPOFへの影響を最小限に抑える対応を取る。また、そのような対応が必要となることを想定した設計にする。(SPOFへの影響の最小化)
こうした設計が十分にできていない場合、その影響は機能数
このような種類の障害が目立ってきた時は、そもそものサービス全体の設計が、エラーの影響を局所化するようにできているか見直しをした上で、有事の際に切り離すなどのシナリオを検討して、仮に部分的に縮退していても主機能は動作する、といた状況を担保できる構造を作ることが重要です。
エラーそのものは必ず発生して、かつそれが統計的に処理可能な事象であったとすれば、概数ぐらいは実績を元に算数で予測できます。これはビジネスの継続性にも関わる事でもあるので、ビジネスと同じように"算盤"を使って勘定するのが良いかなと思います。
発展・機能とアーキテクチャのそれぞれの軸でシステムを捉える
システムの可用性を考えるにあたって、これまで簡単にDBを一機能として捉える図を描いてきましたが、実はアプリケーション機能もWebサーバー/アプリケーション・サーバーとして抽象化すると一つのリソースと思うこともできました。
これを踏まえて、次の図のような見方をしてみます。

これまでの図は、アプリケーションで機能を実現するというイメージでの図でした。これは開発作業的には大きく間違っていないようにも思えますが、実際には機能は複数のアーキテクチャを跨って実現されます。この複数のアーキテクチャに跨るという概念を表現したのがこの図です。
この図では、アーキテクチャのレイヤーではアーキテクチャ間の結合が、機能のレイヤーでは機能間の結合が、それぞれ表現されているものと見ることができます。これは運用判断・障害特定のそれぞれで有用と感じたので、少しまとめます。
運用判断における機能・アーキテクチャレイヤー構造の意味
この図における、特定の機能を停止したり、特定のアーキテクチャを停止したり、といった行動をとった時にシステム全体への影響が出なくなるようにすることが、可用性を高めるために重要です。
また、さらに重要な観点として、特定の機能が停止せずに動作していたとしても、アーキテクチャ的な許容量を超える場合には意図的に機能を停止/縮退する という判断も必要になります。一般的には、アーキテクチャ的な可用性のみを考慮する場合、機能レベルでの停止は必ずしも議論されない場合もありますが、実際には必ずなにかの機能によって負荷が発生しているので、機能レイヤーでも可用性について検討する必要があります。
その場合には、特定の機能を停止させた場合にその機能がSPOFになっていないか といった事を検討する必要があり、機能的なSPOFを作らないようにする事が重要です。また、機能単位で停止させる事ができるような状況を確保しておく必要があります。(例えばWebアプリの場合、ロードバランサーで特定のパスを塞ぐなど。)
致命的な障害を減らすためには、このような運用判断が容易になる設計を事前に行うことが重要です。
障害特定における機能・アーキテクチャレイヤー構造の意味
致命的な障害の場合、基本的にはアーキテクチャレベルでどこかが破綻しています。各装置自体か、その間の接続か、少なくともいずれかは破綻しているのです。
そのため、アーキテクチャレイヤーで言うとどこに障害が発生しているのか、それを特定する事が障害の解決への一歩となります。
一方で、破綻したアーキテクチャを特定できたからといって、直ちに対応ができるとは限りません。
例えば、Webサーバーのプロセスが落ちていればWebサーバーを再起動を目指しますが、過負荷でプロセスが落ちたのであれば再起動で解決はしません。
そこで、機能の軸でも障害を捉えるようにします。アーキテクチャ的に過負荷が発生していたとしても、もしそれがある決まった機能によって引き起こされた事であれば、それが機能レイヤーでの障害の原因と特定でき、運用判断につなげることができます。
一般に、すべての機能についてこのような図を作ることは困難であると思いますが、図解しなくてもこのような機能とアーキテクチャのレイヤー構造が存在すると意識しておくことで、障害事象の全貌の把握がよりスムーズになると思いました。
余談
この記事は、全く別の文脈で、それぞれ少し関連性のあるような話をした結果、それらがつなぎ合わさって生まれました。具体的には
- エラー量が作業量に比例する話
- SPOFを避ける設計にするとダメージが軽減できる話
- アクセスが殺到した時にエンドポイント別でダメージを少なくする話
- コード設計=設計という事ではない話
これらは全て別の話でしたが、融合して一つのストーリーになりました。
経営的な立場からすると、開発規模とバグの量というのはイメージができてもあまりクリアではない可能性があります。特に、アーキテクチャの問題で各障害が独立ではなく、それによって障害が増えるという側面があることは自明ではないと思ったので、そのあたりを広義の「技術的負債」としてイメージできると良いのかな、と思いました。
Discussion