ChainlitとLangGraphを活用してAgentによる画像認識を実現する方法
はじめに
5月13日にGPT-4oがOpenAIから発表されました。
この発表以降、Xでも多くの方がGPT-4oを試した感想を書いていました。
その中で画像認識の精度が上がって、かなり使える機能になってきているとの話があり、気になったのでまずはAPIから使えるようにしてみました。
OpenAIのモデルがVisionに対応したのはだいぶ前になりますが、
値段の割にあんまり精度が良くなさそうだったので、お恥ずかしながら今まで試したことがありませんでした。
なので今回は、
- VisionのAPIドキュメントを一通り読む
- Chainlitのマルチモーダル機能の挙動を確認する
- 以前作成したChainlitとLangGraphのAgentアプリで画像認識をできるようにする
という手順でやっていきたいと思います。
Vision APIのドキュメント確認
まずはVisionの使い方やコストについて、OpenAIのドキュメントを確認します。
リンクは以下です。
Quick start
画像の渡し方は2つあり、URLで渡す方法と、base64でエンコードして渡す方法があるようです。
ドキュメントには両方のサンプルコードが用意されているので、実装で困ることはなさそうです。
注意点として、モデルは画像の中のあるオブジェクトの位置情報を認識するのが不得手であると書かれています。
今回はChainlitのチャットに貼られた画像を使用したいので、base64の方を使用します。
Multiple image inputs
このAPIは、1つのプロンプトに対して、複数の画像を渡して回答を得ることができるようです。
Low or high fidelity image understanding
detailオプションで、low, high, autoのオプションを指定できます。
この設定次第でコストがかなり変わってきそうです。
-
low- 渡された画像を512px × 512pxのサイズに変換して処理される
- 1画像85トークン固定 ($0.000425 = 約0.07円)
- レスポンスが高速
-
high- まず512px × 512pxのサイズに変換した画像を見る
- 2048px × 768pxに収まるように画像をスケーリング
- スケーリングした画像を512px × 512pxのタイルに分割して処理する
- 1画像あたり 85トークン + (512px × 512pxのタイル数) ×170トークン ($0.001275~$0.007225 = 約0.2円~1.1円)
-
auto(default)- 画像の入力サイズを見て、
lowかhighが自動選択される(詳細条件不明)
- 画像の入力サイズを見て、
Managing images
チャットAPIはステートフルではないため、モデルに渡すメッセージは自分で管理する必要があります。
つまり画像をもとに継続会話をしたい場合は、APIにリクエストするたびに画像も渡す必要があります。
長期の会話を行う場合は、base64よりURL渡しの方が、おすすめらしいです。
また、モデルに渡す前に上限サイズにリサイズして渡すことで、レイテンシの改善が期待できます。
(lowなら512px × 512px以下、highなら2048px × 768px以下)
画像は処理された後はOpenAIのサーバーから削除され、保持されず、モデルのトレーニングにも使用されないと明記されています。
Limitations
モデルの制限事項が書かれています。
自分のユースケースと照らし合わせて、実際に使えるかの検討が必要です。
Calculating costs
具体的なコストの計算例が書かれています。
OpenAIのPricingページにも計算器が有るので、予算立てに活用しましょう。
FAQ
書いてある内容をまとめると以下の通り
- fine-tuningはできない
- 画像の生成はできない
- 対応ファイル形式は.png, .jpeg, .jpg, .webp, .gif(.gifは非アニメーションのみ)
- ファイルサイズは1ファイル20MBまで
- アップロードされた画像は処理後自動削除される
- GPT-4 with Visionの注意点はこちら
- レートリミットはtokens per minute(TPM)に基づく
- モデルは画像のメタデータを受け取らない
- 画像が不鮮明の場合は回答精度は下がる(人間と同じ)
ドキュメント確認のまとめ
detailをlowにすれば画像1枚当たり85トークン(約0.07円)しか掛からないとのことで、
1日100枚やっても月に200円程度なので、イメージしてたより全然安かったです。
一方highに設定すると、1枚当たり3倍~17倍のコストになるので、
lowではどうしてもだめな場合のみに限定して使った方が良さそうですね。
また、継続的に会話を続けたい場合は、毎回APIリクエストに画像を含める必要があるみたいなので、実装がちょっとめんどくさそうです。
今回はAgentのToolの一つとして実装することで、Agentが必要に応じて自動で画像を読み込むようにしたいと思います。
Chainlitのマルチモーダル機能の確認
ChainlitはPythonだけで簡単にチャットアプリを構築できる、非常に便利なライブラリです。
チャットアプリのUIに必要な基本的な機能が初めから準備されているので、細かいUI機能の実装を自分でする必要が無く、
チャットボット自体の開発に集中できます。
このChainlitにはマルチモーダルに対応するための機能も備わっており、今回はそちらを利用して実装を行います。
ドキュメントはこちらになります。
前半のVoice Assistantの項目は、音声によるチャットボットとのやり取りについてなので無視して、Spontaneous File Uploads以降の項目を確認します。
ただし、ドキュメントにはあまり細かい情報が書かれていないため、ここは実際に動かしながら確認していきます。
添付ファイルの有効化と設定
ユーザーからのチャット送信に画像を添付できるようにするためには、.chainlit/config.tomlにて設定を行います。
関係する設定値は以下です。
# Authorize users to spontaneously upload files with messages
[features.spontaneous_file_upload]
enabled = true # 添付ファイル機能の有効/無効
accept = ["*/*"] # 添付可能なファイル形式の設定
max_files = 20 # 添付できるファイルの数
max_size_mb = 500 # 添付ファイルの1ファイル当たりのサイズ上限(MB)
enabledはデフォルトで有効なので、変更していなければ触る必要はありません。
accept, max_files, max_size_mbを、先ほど確認したAPI側の仕様に合わせて設定します。
リクエストに渡せる画像の枚数はドキュメントに書かれていませんでしたので、仮で3と設定しておきます。
変更後の設定値は以下の通りです。
# Authorize users to spontaneously upload files with messages
[features.spontaneous_file_upload]
enabled = true # 添付ファイル機能の有効/無効
> accept = ["image/jpeg", "image/png", "image/gif", "image/webp"] # 添付可能なファイル形式の設定
> max_files = 3 # 添付できるファイルの数
> max_size_mb = 20 # 添付ファイルの1ファイル当たりのサイズ上限(MB)
これでチャットの入力欄に「📎」アイコンが表示されて、そこから添付ファイルを選択できるようになります。
ドラッグアンドドロップでの追加も可能ですし、うれしいことにスクリーンショットなどを撮ったクリップボードからペーストで添付もできます。
アップロードしたファイルの取り扱い
ファイルを添付して送信すると、プロジェクト内に.filesというフォルダが自動で作成され、その中にランダムな文字列のフォルダがあり、さらにその中にランダムな文字列にファイル名が変更された、添付ファイルが置かれます。
例えば以下のような形です。
アップロードファイルの取り扱い
このランダムな文字列ですが、フォルダ名はこのチャットのセッションIDが使われているようです。
ファイル名はおそらく同名ファイルがアップロードされた時のために、重複しないようランダム値に置き換えていると思われます。
このファイルは「new chat」で新しいセッションを開始すると、セッションIDのフォルダごと削除されます。
ただ、タブを「×」で閉じたりすると削除が行われないようです。
Chainlitのサーバーを停止すると、.filesフォルダそのものが削除されるので、これによって不要になったファイルは削除されるようになっています。
アップロードしたファイルがどうなるかは分かったので、実装に移ります。
画像認識tool(vision tool)の実装
今回は以前記事で紹介した、ChainlitとLangGraphの組み合わせのAgentチャットアプリを改造していきます。
記事
リポジトリ
添付ファイル情報の受け取り
まず添付ファイルの情報がどのように受け取れるかを確認します。
添付ファイルの情報は、on_message関数の引数であるmsgに含まれており、
msg.elementsで確認できます。
main.pyのon_message関数に以下のように追記します。
@cl.on_message
async def on_message(msg: cl.Message):
+ print(msg.elements)
# メッセージを受け取ったら、セッションからエージェントとメッセージの履歴を取得
app = cl.user_session.get("app")
inputs = cl.user_session.get("inputs")
この状態で3つファイルを添付してメッセージを送信すると以下のような出力を得られました。
[
Image(
name='zenn-may-chan.jpg',
id='96e0d4af-aca3-4d0e-9946-7a95bed39469',
chainlit_key='96e0d4af-aca3-4d0e-9946-7a95bed39469',
url=None,
object_key=None,
path='/workspace/.files/92ee7448-4d10-4a85-9675-f09b8fb05042/96e0d4af-aca3-4d0e-9946-7a95bed39469.jpg',
content=None,
display='inline',
size='medium',
for_id=None,
language=None,
mime='image/jpeg'
),
Image(
name='zenn-may-chan.jpg',
id='a2d55d60-da42-41d9-8329-33c25122dc7a',
chainlit_key='a2d55d60-da42-41d9-8329-33c25122dc7a',
url=None,
object_key=None,
path='/workspace/.files/92ee7448-4d10-4a85-9675-f09b8fb05042/a2d55d60-da42-41d9-8329-33c25122dc7a.jpg',
content=None,
display='inline',
size='medium',
for_id=None,
language=None,
mime='image/jpeg'
),
Image(
name='zenn-may-chan.jpg',
id='5588e041-af17-4c37-8468-8e47f347a591',
chainlit_key='5588e041-af17-4c37-8468-8e47f347a591',
url=None,
object_key=None,
path='/workspace/.files/92ee7448-4d10-4a85-9675-f09b8fb05042/5588e041-af17-4c37-8468-8e47f347a591.jpg',
content=None,
display='inline',
size='medium',
for_id=None,
language=None,
mime='image/jpeg'
)
]
nameにもともとのファイル名、idとchainlit_keyに同じ値が入っていますが、これがファイル名になっているようです。
必要となるのはもともとのファイル名とpathで、このpathをもとにファイルを指定して画像認識APIに投げるToolを実装すれば良さそうです。
そのためにはLLMにファイル名とpathもメッセージと合わせて渡してやる必要があるので、main.pyを以下のように変更します。
cl.on_message
async def on_message(msg: cl.Message):
# メッセージを受け取ったら、セッションからエージェントとメッセージの履歴を取得
app = cl.user_session.get("app")
inputs = cl.user_session.get("inputs")
+ attachment_file_text = ""
+
+ for element in msg.elements:
+ attachment_file_text += f"- {element.name} (path: {element.path.replace("/workspace", ".")})\n" # agentが参照するときは./files/***/***.pngのようになるので、それに合わせる
+
+ content = msg.content
+
+ if attachment_file_text:
+ content += f"\n\n添付ファイル\n{attachment_file_text}"
# ユーザーのメッセージを履歴に追加
< inputs["messages"].append(HumanMessage(content=msg.content))
> inputs["messages"].append(HumanMessage(content=content))
この変更で、添付ファイルのファイル名とパスが、ユーザー入力メッセージの末尾に追加され、Agentに渡されるようになります。
画像認識Toolの実装
次に画像認識Toolを実装します。
OpenAIのドキュメントのサンプルコードを参考に、以下のように実装しました。
+ import base64
+ import os
+ import requests
...
+ def encode_image(image_path):
+ with open(image_path, "rb") as image_file:
+ return base64.b64encode(image_file.read()).decode('utf-8')
+
+ @tool
+ async def vision(prompt: str, image_paths: Sequence[str]) -> str:
+ """Pass multiple images to the multimodal AI to get results"""
+ headers = {
+ "Content-Type": "application/json",
+ "Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}"
+ }
+
+ payload = {
+ "model": "gpt-4o",
+ "messages": [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "text",
+ "text": prompt
+ },
+ ]
+ }
+ ],
+ "max_tokens": 300
+ }
+
+ for image_path in image_paths:
+ base64_image = encode_image(image_path)
+ payload["messages"][0]["content"].append({
+ "type": "image_url",
+ "image_url": {
+ "url": f"data:image/jpeg;base64,{base64_image}",
+ "detail": "low"
+ }
+ })
+
+ response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=payload)
+
+ return response.json()["choices"][0]["message"]["content"]
# toolを配列にまとめて、ToolExecutorに渡す
# toolを追加した場合は、忘れずにここに追加してください
< tools = [ddg_search]
> tools = [ddg_search, vision]
tool_executor = ToolExecutor(tools)
...
このToolは、promptと画像のパスを受け取り、promptをそのまま渡して、画像はbase64エンコードしてAPIに渡しています。
画像のエンコードはencode_image関数で行っています。
コスト面を考慮して、detailはlowに設定しています。
このToolをAgentに追加するために、toolsリストに追加しています。
これでAgentに画像認識Tool(vision tool)が追加されたので、必要に応じてこのToolを使って回答してくれるようになったはずです。
AgentのToolを使って画像認識を試す
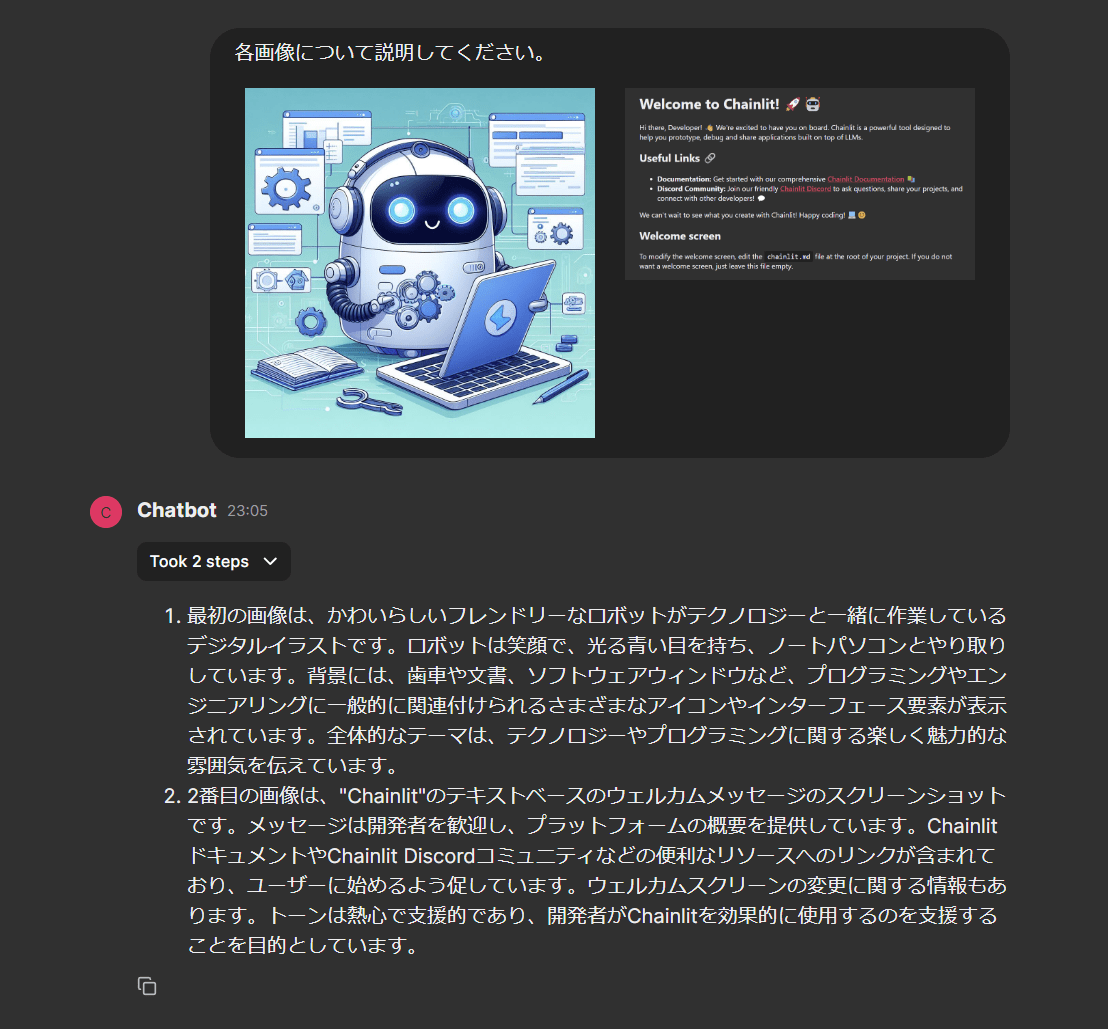
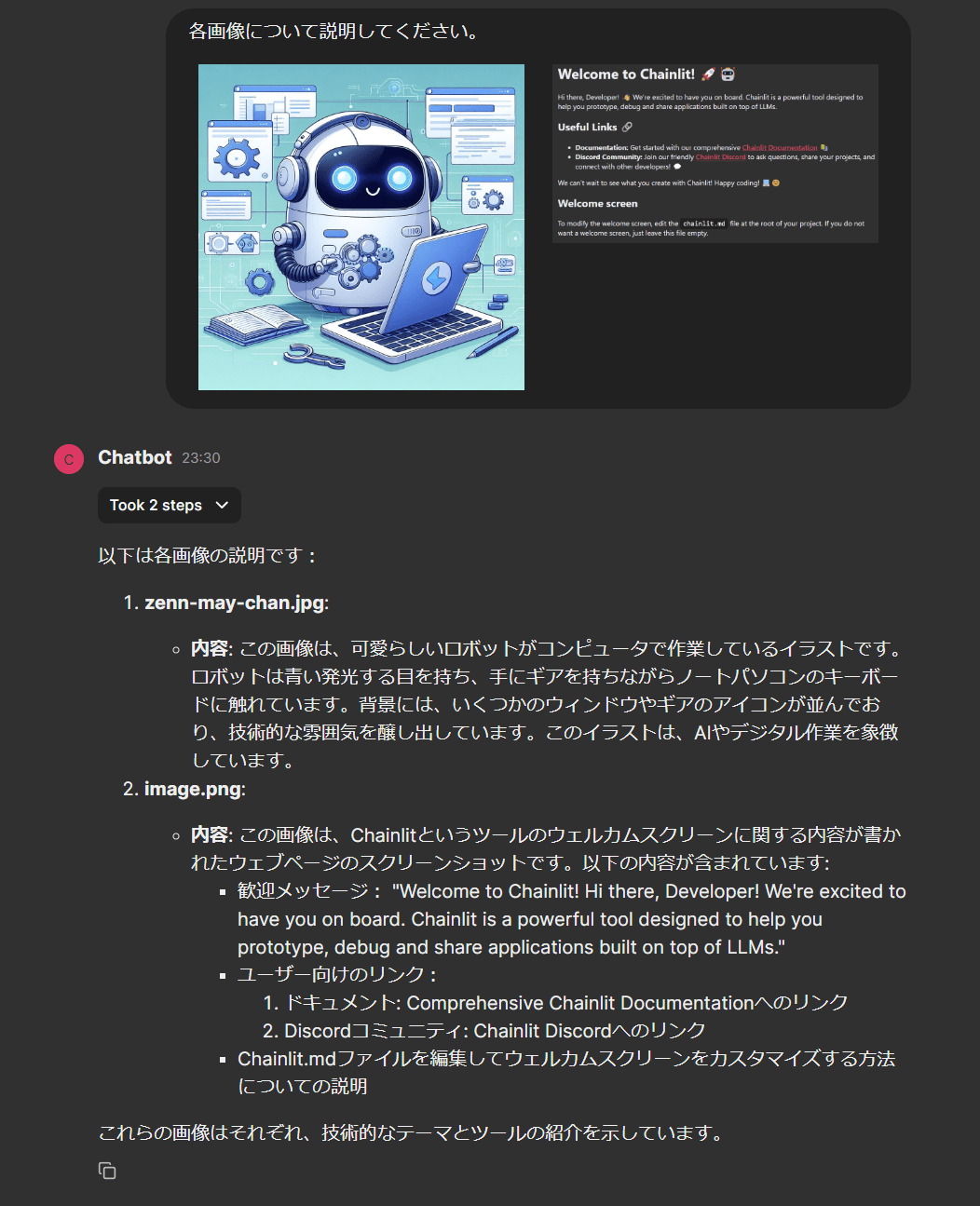
実際にAgentに画像認識を依頼してみます。
画像は2枚用意し、それぞれを添付してメッセージを送信しました。
結果は以下の画像の通りです。
画像認識トライ結果
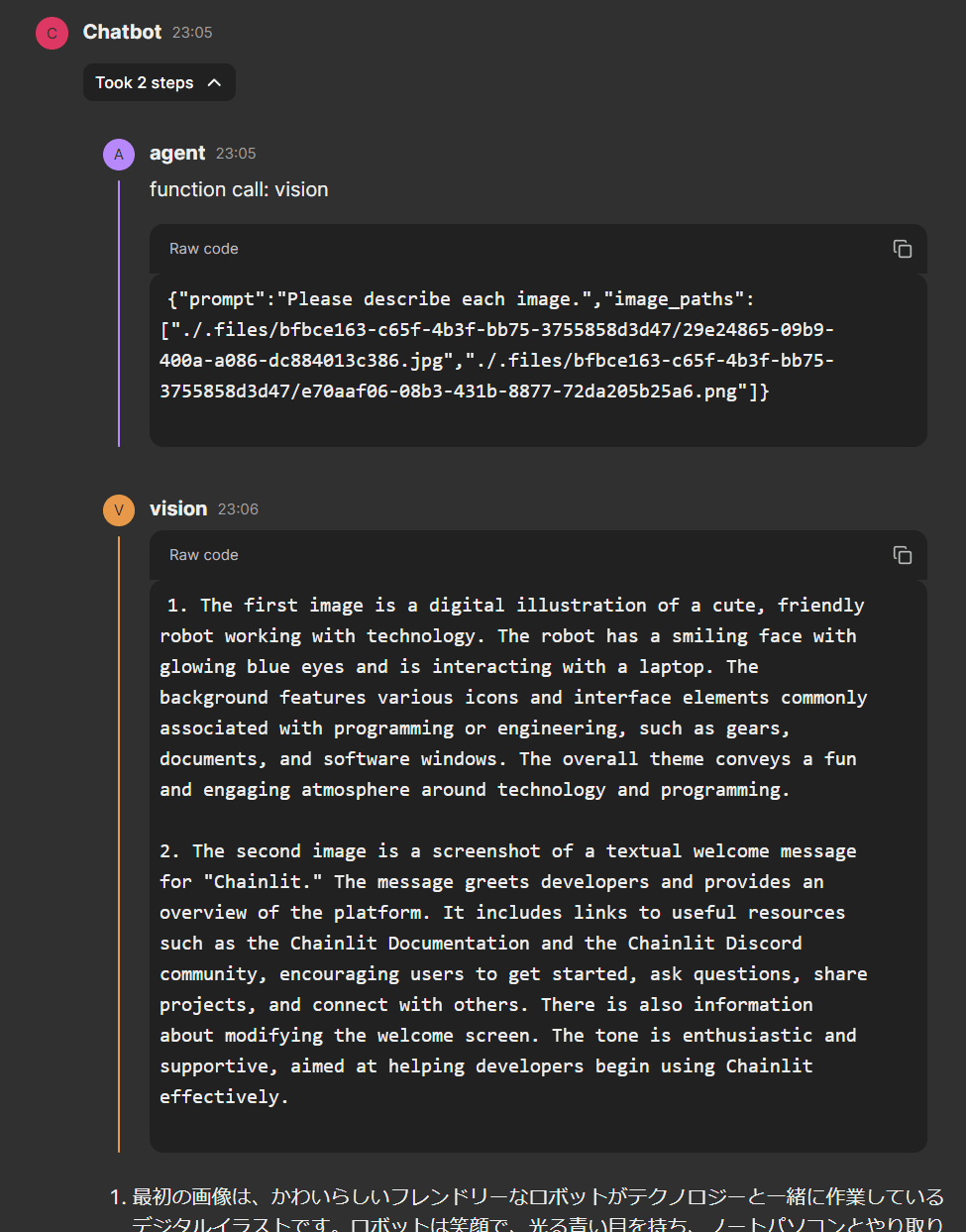
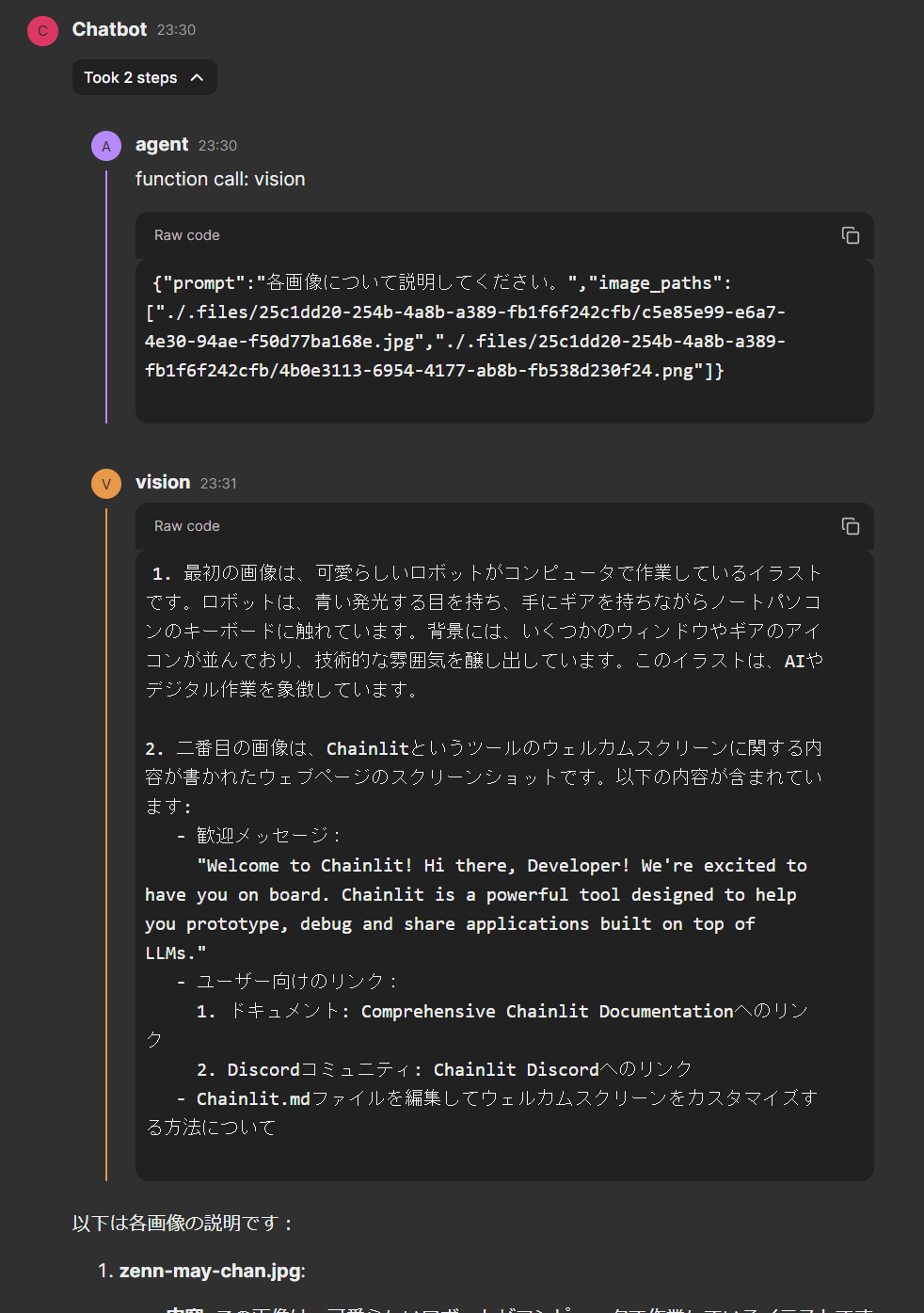
中間ステップ
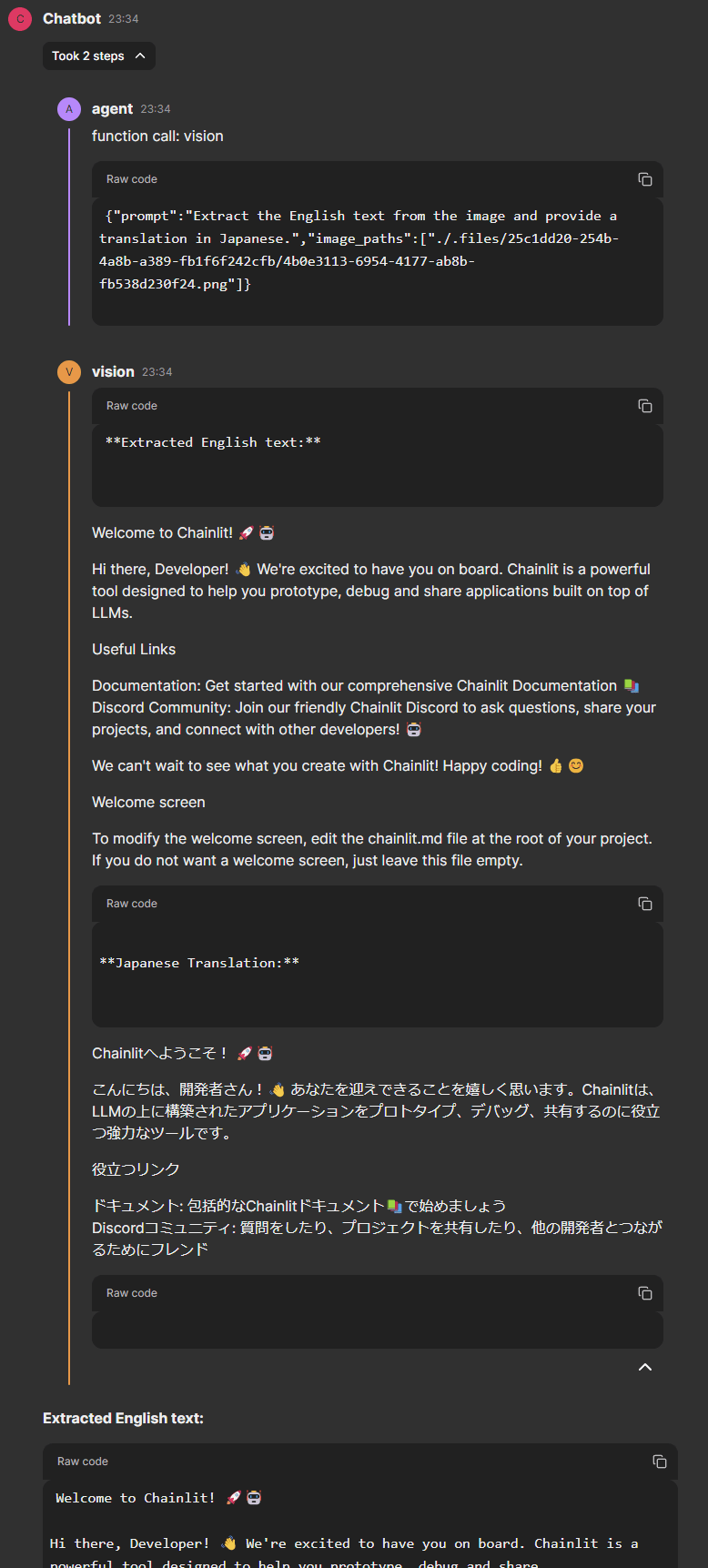
作成したvision toolを使って、画像認識が行われていることが中間ステップの内容から確認できます。
アップロードした2枚の画像に対して、Toolの使用が1度で処理され、引数として両方のパスが渡されていることも確認できます。
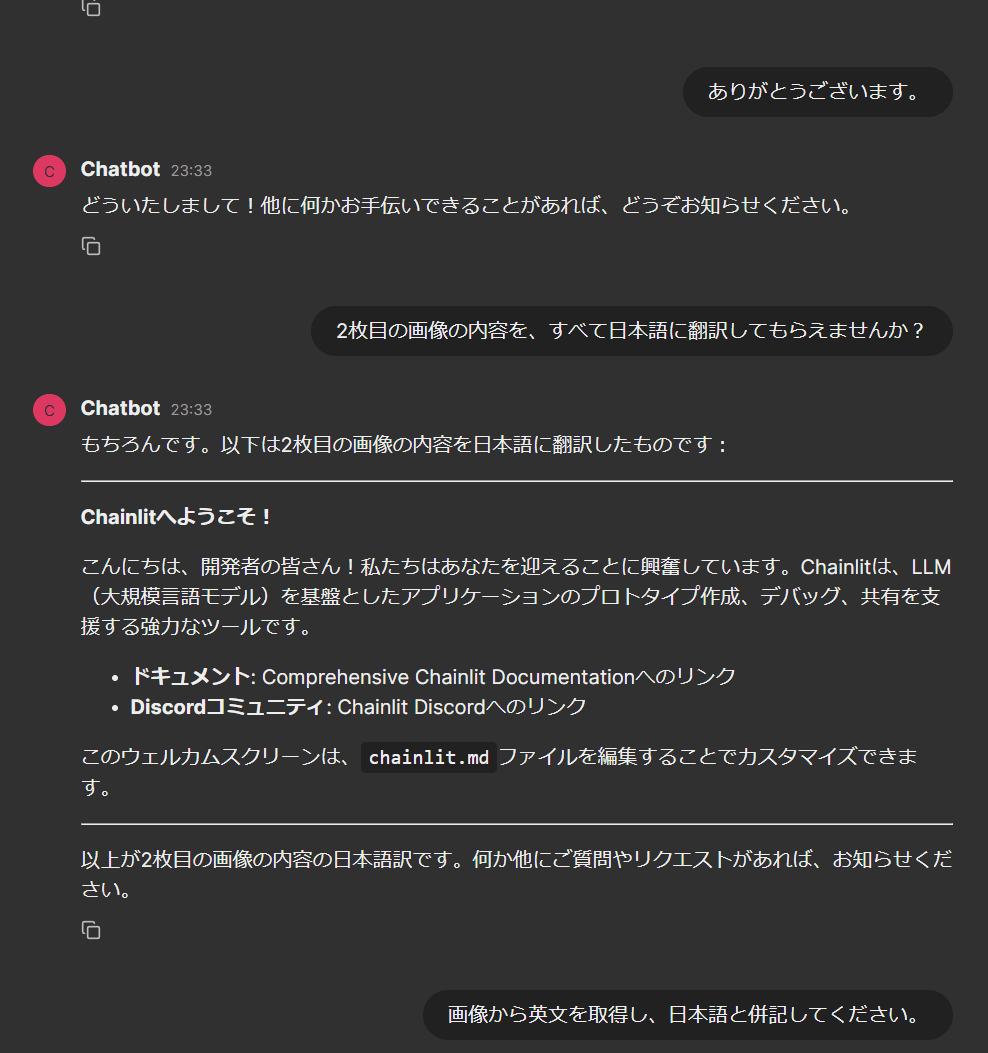
また、継続会話で上手く機能するかを確認するために、一度関係ないメッセージを送信して、再度画像に関する依頼をしてみました。

継続会話テスト
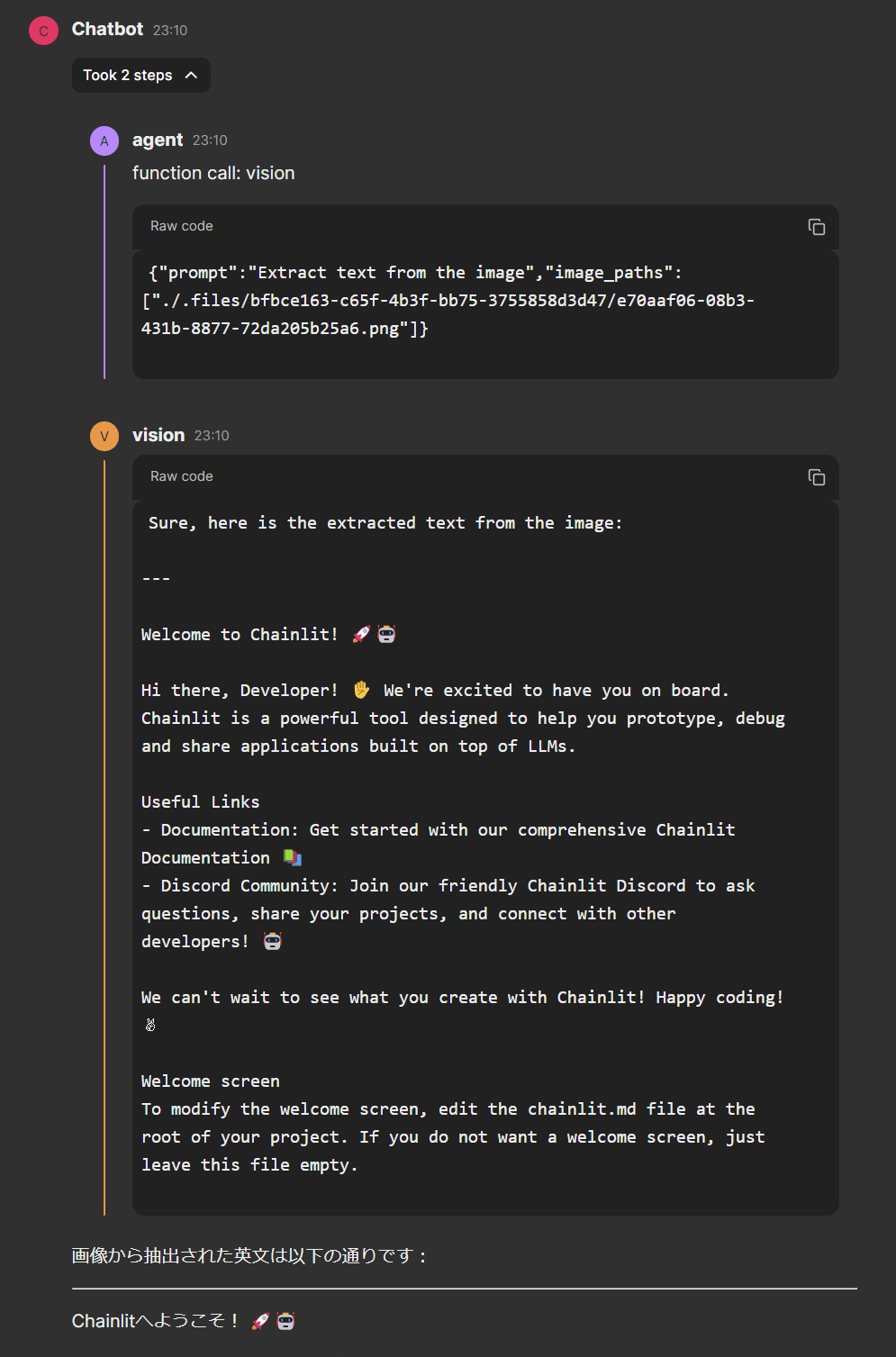
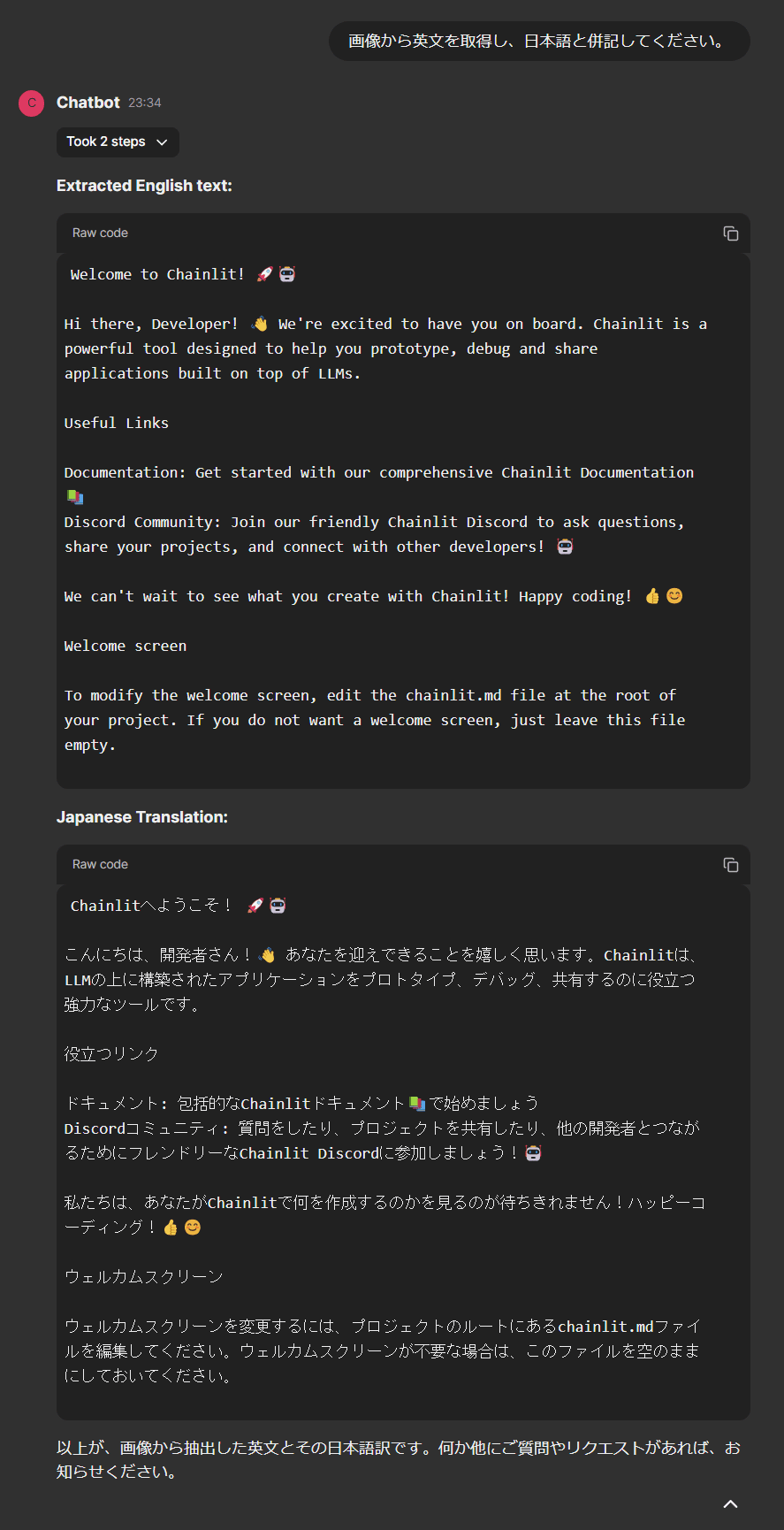
継続会話の中間ステップ
最終応答が狙った感じのものになっていないのですが、これはAgentのベースモデルがGPT-3.5-Turboであるためかもしれません。
ただ、最終応答の中間ステップを見ると、再度vision toolが呼ばれ、2枚目の画像に対してのみ処理が行われていることがわかります。
promptも依頼に合わせて変更されていることが確認できました。
これでやりたかったAgentのマルチモーダル対応が完了しました。
【おまけ】AgentのベースモデルをGPT-4oに変えた場合の結果
AgentのベースモデルをGPT-4oに変更して同じことをやってみました。
画像認識トライ結果(GPT-4o)
中間ステップ(GPT-4o)
継続会話テスト1(GPT-4o)
継続会話テスト2(GPT-4o)
継続会話の中間ステップ(GPT-4o)
見づらくて申し訳ありませんが、最終応答が目論見通りのものになっていることが確認できました。
やはりGPT-3.5-Turboでは、雑な聞き方では思った通りの回答をさせるのは難しいようです。
ユーザーの依頼の仕方次第で目的の応答を引き出すことは可能だと思いますが、
その試行錯誤の時間を考えたら、GPT-4oを使った方が効率的かもしれません。
まとめ
今回は、OpenAIのVision APIを使って画像認識を行う方法を確認し、
Chainlitのマルチモーダル機能を使ってLangGraphのAgentに画像認識を実装しました。
Vision APIのコストは、detailをlowに設定すれば1枚当たり85トークン(約0.07円)しか掛からないので、下手に文章で説明するよりもコストを圧縮できる可能性があるなと感じました。
実際に試した感じだと、画像認識の精度はかなり高いと感じました。
これから実際に色々な画像を試してみて、実用性を確かめていきたいと思います。
今回作成したコードは以下のリポジトリにあります。
OpenAIのAPIキーさえあれば試すことができますので、興味があれば試してみてください。
Discussion