電話でChatGPTと文脈を読んだ会話ができるボイスボットを作る
こんにちわ。 ZUMA です。
ちょっと前に電話 GPT というサービスが話題になりましたね。
今回は Amazon Connect と AWS Amplify を使って電話で ChatGPT と会話できるボイスボットを作ってみました。
成果物
以下成果物となります。
動画は Amazon Connect のソフトフォンを使って電話をかけています。
ソフトフォンに表示されている電話番号は Amazon Connect で取得しており、実際にスマートフォンなどから電話をかける事ができます。
(動画内の電話番号は既に削除しています)
当初 ChatGPT の回答は GPT-4 API を使用していたのですが、どうしてもレスポンスが遅かったので動画では GPT-3.5 turbo を使用しています。
また、会話の履歴は DynamoDB に保存し、会話の履歴を含めたプロンプトを ChatGPT に投げて文脈を読んだ回答をするようにしています。
動画の中では「お腹が痛いんだけど夜ご飯は何を食べたら良い?」という文脈に対して、「おすすめのメニューはある?」や「病院は何科に行けば良い?」と質問しています。
ChatGPT は「お腹が痛い場合は・・・」とちゃんと会話の履歴から文脈を読んだ回答をしてくれました。
Amazon Lex 用語解説
Amazon Lex は自然言語処理(NLP)と音声認識を利用した会話型インターフェースの構築サービスです。
音声認識、文字起こしに関しては Amazon Transcribe で行っています。
Lex は文字起こしされた文章を認識し Lambda をキック、Lambda から文字起こし文をプロンプトとして ChatGPT API に投げています。
ChatGPT で推論した回答は Amazon Polly を使用して音声として応答しています。
Lex ではインテントとサンプル発話、スロット、フルフィルメントを設定します。
ボット作成で必要な要素となりますので、以下それぞれ用語の解説をします。
スロット
スロットとは、事前定義されたスロットタイプ(日付、数値、都市名など)と独自で作成できるカスタムスロットタイプからユーザーからの入力を正確に解釈し、適切な形式に変換します。
例えばピザの注文ボットで、ピザのサイズ Small, Medium, Large のカスタムスロットを作成したとします。
ユーザーから入力される「サイズは Small でお願いします」等自然言語からサイズは Small であると解釈し、サイズスロットを Small で埋めます。
ピザのサイズスロットが埋まったら次はピザのトッピングスロットを埋めて・・・を繰り返しピザの注文内容を揃えていく訳です。
インテント、サンプル発話、フルフィルメント
インテントは、ユーザーが提供する情報(発話)を解析し、対応する目的を特定します。
サンプル発話とはユーザーがインテントをトリガーする可能性のある自然言語のフレーズやパターンのことです。
Amazon Lex がユーザーの発話からインテントを正確に識別するために使用されます。
例えば、「OrderPizza」インテントのサンプル発話には、「ピザを注文したい」や「大きなペパロニピザを一つください」など注文する時に含まれる可能性のあるフレーズを設定します。
インテントは必要に応じてユーザーから追加情報(スロット)を取得します。
ピザ注文の例だとピザのサイズスロットやトッピングスロットですね。
フルフィルメント(実行)とは情報を使用して目的に応じたアクション(たとえば、データベースから情報を取得)を実行します。
フルフィルメントは Lambda 関数内で設定します。
インテントの要素をまとめると以下のようになります。
| 主要な要素 | 説明 |
|---|---|
| インテント名 | インテントを一意に識別する名前。例:「OrderPizza」、「BookFlight」など。 |
| サンプル発話 | トリガーされる可能性の自然言語フレーズ。Amazon Lex がユーザーの発話からインテントを識別するために使用される。例:「ピザを注文したい」、「大きなペパロニピザを一つください」 |
| スロット | インテント実行に必要な特定の情報を収集するパラメータ。例:「OrderPizza」インテントでは、サイズ、トッピング、配達先住所など。 |
| フルフィルメント(実行) | インテント識別後、必要なスロットが埋まった時に実行されるアクション。AWS Lambda 関数や Amazon Connect のコンタクトフロー設定でアクションを実行する。 |
例えば、ユーザーが「今日の東京の天気は??」と尋ねた場合、インテントは「天気情報を取得する」と特定されます。
そして場所や日付のスロットが埋まり次第、対応するアクション(天気情報を提供するウェブサービスへのクエリ)が実行され、ユーザーに応答が返されます。
以下インテントの例です。
| インテント名 | サンプル発話 | スロット | フルフィルメント |
|---|---|---|---|
| CheckWeather | 明日のニューヨークの天気は? | location, date | 天気情報 API にアクセス、結果をユーザーへ返す |
| BookAppointment | 月曜に歯医者の予約をしたい | day, serviceType | 予約システムへ登録、確認メッセージをユーザーへ返す |
| OrderPizza | 大きいピザを 2 枚頼みたい | size, quantity | 注文システムへ登録、注文確認メッセージをユーザーへ返す |
実装
前準備の Amazon Connect、Amplify などバックエンド環境の構築が長くなってしまったので、先に実装コードです。
ディレクトリ構成
Lambda Function の ディレクトリ構成は以下となります。
amplify/backend/function/chatGPTVoiceBotFunction
├── Pipfile
├── Pipfile.lock
├── amplify.state
├── chatGPTVoiceBotFunction-cloudformation-template.json
├── custom-policies.json
├── function-parameters.json
└── src
├── aws_systems_manager.py
├── chatgpt_api.py
├── const.py
├── db_accessor.py
├── event.json
├── index.py
├── message_repository.py
└── setup.py
OpenAI Completions API 実装
OpenAI の Completions API を実行するコードです。
ボイスボットはユーザーを離脱させない為、とにかく回答速度が重要になり、こちらを参考にしています。
ChatGPT モデルは GPT-3.5 turbo を使用します。
GPT-4 でも試したのですが、どうしてもレスポンスが遅かったです。
また、system プロンプトには 250 文字以内で回答するよう指示しています。
max_tokens で縛ると回答が途中で切れてしまうのでプロンプトで指示しています。
この指定を入れないとあまり要約されない推論を返してしまうので回答速度が遅くなってしまいます。
content は英語の方が精度が高いので英語で設定しています。
import openai
import const
# Model name
GPT_MODEL = 'gpt-3.5-turbo'
# Maximum number of tokens to generate
# MAX_TOKENS = 1024
# Create a new dict list of a system
SYSTEM_PROMPTS = [{'role': 'system', 'content': 'You are an excellent AI assistant. Please keep your answer within 250 characters.'}]
def completions(history_prompts):
messages = SYSTEM_PROMPTS + history_prompts
print(f"prompts:{messages}")
try:
openai.api_key = const.OPEN_AI_API_KEY
response = openai.ChatCompletion.create(
model=GPT_MODEL,
messages=messages,
# max_tokens=MAX_TOKENS
)
return response['choices'][0]['message']['content']
except Exception as e:
# Raise the exception
raise e
その他細かい Completions API のパラメーターについては OpenAI の こちら を参照ください。
DynamoDB 実装
DynamoDB へのアクセスは boto3 を利用します。
会話履歴を登録する PUT 関数、会話履歴を取得する QUERY 関数を作成しています。
import boto3
from datetime import datetime
import const
TABLE_NAME = f'VoiceMessages{const.DB_TABLE_NAME_POSTFIX}'
QUERY_INDEX_NAME = 'bySessionId'
dynamodb = boto3.client('dynamodb')
def query_by_session_id(session_id: str, limit: int) -> list:
# Create a dictionary of query parameters
query_params = {
'TableName': TABLE_NAME,
'IndexName': QUERY_INDEX_NAME,
# Use a named parameter for the key condition expression
'KeyConditionExpression': '#sessionId = :sessionId',
# Define an expression attribute name for the hash key
'ExpressionAttributeNames': {
'#sessionId': 'sessionId'
},
# Define an expression attribute value for the hash key
'ExpressionAttributeValues': {
':sessionId': {'S': session_id}
},
# Sort the results in descending order by sort key
'ScanIndexForward': False,
# Limit the number of results
'Limit': limit
}
try:
# Call the query method of the DynamoDB client with the query parameters
query_result = dynamodb.query(**query_params)
# Return the list of items from the query result
return query_result['Items']
except Exception as e:
# Raise any exception that occurs during the query operation
raise e
def put_message(partition_key: str, uid: str, role: str, content: str, now: datetime) -> None:
# Create a dictionary of options for put_item
options = {
'TableName': TABLE_NAME,
'Item': {
'id': {'S': partition_key},
'sessionId': {'S': uid},
'role': {'S': role},
'content': {'S': content},
'createdAt': {'S': now.isoformat()},
},
}
# Try to put the item into the table using dynamodb client
try:
dynamodb.put_item(**options)
# If an exception occurs, re-raise it
except Exception as e:
raise e
会話データ取得・登録・ChatGPT 推論実装
会話履歴テーブルからデータの取得、登録、ChatGPT API の推論実行〜推論結果取得をする関数です。
QUERY_LIMIT 定数の値は ChatGPT API の入力プロンプトに含める会話履歴数です。
この値を大きくするとより多くの user と assistant の会話履歴を入力プロンプトに含める事ができます。
QUERY_LIMIT を大きくしすぎるとトークン長が長くなりすぎエラーとなるので注意が必要です。
import uuid
from datetime import datetime
import chatgpt_api
import db_accessor
QUERY_LIMIT = 10
def _fetch_chat_histories_by_session_id(session_id, prompt_text):
try:
if session_id is None:
raise Exception('To query an element is none.')
# Query messages by Line user ID.
db_results = db_accessor.query_by_session_id(session_id, QUERY_LIMIT)
# Reverse messages
reserved_results = list(reversed(db_results))
# Create new dict list of a prompt
chat_histories = list(map(lambda item: {"role": item["role"]["S"], "content": item["content"]["S"]}, reserved_results))
# Create the list of a current user prompt
current_prompts = [{"role": "user", "content": prompt_text}]
# Join the lists
return chat_histories + current_prompts
except Exception as e:
# Raise the exception
raise e
def _insert_message(session_id, role, prompt_text):
try:
if prompt_text is None or role is None or session_id is None:
raise Exception('To insert elements are none.')
# Create a partition key
partition_key = str(uuid.uuid4())
# Put a record of the user into the Messages table.
db_accessor.put_message(partition_key, session_id, role, prompt_text, datetime.now())
except Exception as e:
# Raise the exception
raise e
def create_completed_text(session_id, prompt_text):
# Query messages by Line user ID.
chat_histories = _fetch_chat_histories_by_session_id(session_id, prompt_text)
# Call the GPT3 API to get the completed text
completed_text = chatgpt_api.completions(chat_histories)
# Put a record of the user into the Messages table.
_insert_message(session_id, 'user', prompt_text)
# Put a record of the assistant into the Messages table.
_insert_message(session_id, 'assistant', completed_text)
return completed_text
このトークン数の調整はトークン長カウンター、tokeniser である tiktoken を使えば出来そうです。
今回はこのトークン長オーバーのエラーハンドリングは省いていますが、この処理も別で記事にしたいと思います。
LINE トークン ・ OpenAI API キーをシークレットから取得する
LINE のチャネルトークンやシークレットトークン、OpenAI の API キーなど秘匿情報は AWS Systems Manager Parameter Store に登録して隠蔽します。
AWS Systems Manager のシークレットの登録方法は後述しますので、シークレットの値を取得するコードを先に出します。
boto3 で簡単に AWS System Manager から値を取得することが可能です。
import boto3
from botocore.exceptions import ClientError
# AWS region name
AWS_REGION = "ap-northeast-1"
def get_secret(secret_key):
try:
# Create a client for AWS Systems Manager
ssm = boto3.client('ssm', region_name=AWS_REGION)
# Get the secret from AWS SSM
response = ssm.get_parameter(
Name=secret_key,
WithDecryption=True
)
# Return the value of the secret
return response['Parameter']['Value']
except ClientError as e:
raise e
実装したモジュールを利用して、以下のように定数として取得出来るようにします。
import os
import aws_systems_manager
BASE_SECRET_PATH = os.environ.get('BASE_SECRET_PATH')
DB_TABLE_NAME_POSTFIX = os.environ.get('DB_TABLE_NAME_POSTFIX')
OPEN_AI_API_KEY = aws_systems_manager.get_secret(f'{BASE_SECRET_PATH}OPEN_AI_API_KEY')
Lambda の index.py 実装
最後に Lambda から最初に呼び出される index.py を実装します。
コードは こちら をベースにしています。
以下変数、関数の簡単な説明です。
| 項目 | 説明 |
|---|---|
| SLOT_DUMMY | Lex で必要なスロットにダミー値を入れる変数。質問内容は何でも聞けるように設定 |
| elicit_slot | Lex がスロットが埋まっていない場合に使用 |
| confirm_intent | スロットが全て埋まった時に使用 |
| close | インテント終了時に使用。クローズ時のプロンプトは、「終了」 |
| chatGPT_intent | API からのレスポンスで、ChatGPT の返答をテキスト形式で取得するために使用 |
INTENT_NAME は後ほど解説するインテント作成で自分で設定したインテント名を指定します。
SLOT_NAME は後ほど解説するインテントに設定するスロット作成の時に自分で設定したスロット名を指定します。
import message_repository
INTENT_NAME = 'ChatGPT'
SLOT_NAME = 'empty_slot'
SLOT_DUMMY = {
SLOT_NAME: {
'shape': 'Scalar',
'value': {
'originalValue': 'dummy',
'resolvedValues': ['dummy'],
'interpretedValue': 'dummy'
}
}
}
def elicit_slot(slot_to_elicit, intent_name, slots):
return {
'sessionState': {
'dialogAction': {
'type': 'ElicitSlot',
'slotToElicit': slot_to_elicit,
},
'intent': {
'name': intent_name,
'slots': slots,
'state': 'InProgress'
}
}
}
def confirm_intent(message_content, intent_name, slots):
return {
'messages': [{'contentType': 'PlainText', 'content': message_content}],
'sessionState': {
'dialogAction': {
'type': 'ConfirmIntent',
},
'intent': {
'name': intent_name,
'slots': slots,
'state': 'Fulfilled'
}
}
}
def close(fulfillment_state, message_content, intent_name, slots):
return {
'messages': [{'contentType': 'PlainText', 'content': message_content}],
'sessionState': {
'dialogAction': {
'type': 'Close',
},
'intent': {
'name': intent_name,
'slots': slots,
'state': fulfillment_state
}
}
}
def chatGPT_intent(event):
intent_name = event['sessionState']['intent']['name']
slots = event['sessionState']['intent']['slots']
input_text = event['inputTranscript']
session_id = event['sessionId']
if slots[SLOT_NAME] is None:
return elicit_slot(SLOT_NAME, intent_name, SLOT_DUMMY)
elif input_text == '終了':
return close('Fulfilled', 'ご利用ありがとうございました。またのご利用お待ちしております。', intent_name, slots)
completed_text = message_repository.create_completed_text(session_id, input_text)
print(f'Received input_text:{input_text}')
print(f'Received completed_text:{completed_text}')
return confirm_intent(completed_text, intent_name, slots)
def handler(event, context):
intent_name = event['sessionState']['intent']['name']
if intent_name == INTENT_NAME:
return chatGPT_intent(event)
次から実装前準備の手順となるので、まずは以降手順の完了後コードを実装してください。
バックエンド環境構築
ChatGPT API を実行する Lambda は AWS Amplify で構築します。
今回は前回の記事で作成した Amplify 環境をベースにします。
まずは以下記事のAmplify CLI でリソースを作成する以降を参照して環境構築をお願いします。
記事では Amplify の環境構築、REST API から DynamoDB の作成方法、 LINE 設定、OpenAI の API キー取得方法を解説しています。
作った環境に新たにボイスチャット用の Lambda 関数と DynamoDB に会話履歴保存テーブルを追加して ChatGPT と会話が出来るように実装します。
Lambda を作成する
ベースの環境を作ったプロジェクトのルートディレクトリで作業します。
ボイスチャット用の Lambda を作成する為にプロジェクトルートで以下コマンドを実行します。
amplify add function
Lambda function を選択します。
$ amplify add function
? Select which capability you want to add: (Use arrow keys)
❯ Lambda function (serverless function)
Lambda layer (shared code & resource used across functions)
Lambda Function 名を決めます。今回は chatGPTVoiceBotFunction と命名しました。
? Provide an AWS Lambda function name: chatGPTVoiceBotFunction
次に言語を選択します。 Python を選択します。
? Choose the runtime that you want to use:
.NET 6
Go
Java
NodeJS
❯ Python
詳細設定追加の有無を選択します。
Lambda Layers や Lambda の環境変数など作成できます。
こちらは後から追加するので N を入力します。
Only one template found - using Hello World by default.
Available advanced settings:
- Resource access permissions
- Scheduled recurring invocation
- Lambda layers configuration
- Environment variables configuration
- Secret values configuration
? Do you want to configure advanced settings? (y/N)
以下 Y とするとエディタが開きます。
Lambda のコードは後から修正するので N を入力します。
外部ライブラリをインストールする
今回使用する外部ライブラリをインストールします。
Lambda Layers を使用して複数の Lambda で外部ライブラリを共有する方法もありますが、今回は Lambda が一つしかないので pipenv で個別にインストールします。
Lambda Function のルートディレクトリに移動します。
cd amplify/backend/function/chatGPTVoiceBotFunction/
今回使う外部ライブラリをインストールします。
pipenv install boto3
pipenv install openai
AWS Systems Manager と DynamoDB のアクセス権限を設定する
AWS Systems Manager の パラメーターストアにアクセスできる権限や DynamoDB の権限が無いと API 実行時に以下エラーが発生します。
botocore.exceptions.ClientError: An error occurred (AccessDeniedException) when calling the GetParameters operation: User: arn:aws:iam::XXXXXXXXXXXX:user/ai-lab-amplify-cli-user is not authorized to perform: ssm:GetParameters on resource: arn:aws:ssm:ap-northeast-1:XXXXXXXXXXXX:parameter/OPEN_AI_API_KEY because no identity-based policy allows the ssm:GetParameters action
Lambda Function のルートディレクトリに custom-policies.json があるので、必要な権限を追加します。
以下パスのファイルを開きます。
vi amplify/backend/function/chatGPTVoiceBotFunction/custom-policies.json
以下記述します。Resource に記述するアクセス可能なパラーメーターは複数作成可能なので、ワイルドカードで定義します。
[
{
"Action": [
"ssm:GetParameters",
"ssm:GetParameter",
"dynamodb:PutItem",
"dynamodb:DeleteItem",
"dynamodb:GetItem",
"dynamodb:Scan",
"dynamodb:Query",
"dynamodb:UpdateItem"
],
"Resource": [
"arn:aws:ssm:ap-northeast-1:XXXXXXXXXXXX:parameter/*",
"arn:aws:dynamodb:ap-northeast-1:XXXXXXXXXXXX:table/*"
]
}
]
Lambda の Timeout 値を延長する
Amplify で作成する Lambda の Timeout 値はデフォルトで 25 秒です。
ユーザーの入力プロンプトの内容や ChatGPT のアクセス状況次第ですが、ChatGPT API のレスポンスが 1 分を超える事があります。
Timeout 値が 25 秒だとタイムアウトエラーになって処理しきれない場合があるので以下 cloudformation-template.json を編集します。
vi amplify/backend/function/chatGPTVoiceBotFunction/chatGPTVoiceBotFunction-cloudformation-template.json
Timeout を好きな数値に変更します。
Lambda に設定出来る最大の Timeout 値は 900 秒(15 分)です。
筆者の場合、60 秒(1 分) に設定しています。
"Runtime": "python3.8",
"Layers": [],
"Timeout": 25 -> 60
会話履歴テーブルを DynamoDB に追加する
前回記事の DynamoDB 用の Amplify API カテゴリを追加する 手順で schema.graphql が追加されているはずです。
今回は新たにボイスチャット用の会話履歴保存テーブルを作成します。
schema.graphql ファイルに以下スキーマを記述します。
type VoiceMessages @model {
id: ID!
sessionId: String! @index(name: "bySessionId", sortKeyFields: ["createdAt"])
content: String!
role: String!
createdAt: AWSDateTime!
updatedAt: AWSDateTime!
}
amplify push -y コマンドでクラウドに反映させます。
OpenAI API キーのシークレットを設定する
以下コマンドを実行します。
amplify update function
シークレットを設定する Lambda 関数を指定します。
$ amplify update function
? Select the Lambda function you want to update
chatGPTLineChatBotFunction
❯ chatGPTVoiceBotFunction
Secret values configuration を選択します。
? Which setting do you want to update?
Resource access permissions
Scheduled recurring invocation
Lambda layers configuration
Environment variables configuration
❯ Secret values configuration
キー名は OPEN_AI_API_KEY を入力します。
? Enter a secret name (this is the key used to look up the secret value): OPEN_AI_API_KEY
キーの値を入力します。
? Enter the value for OPEN_AI_API_KEY: [hidden]
キーの登録が終わったら作業を終了するので、 I'm done を選択、次の設問は N を入力します。
? What do you want to do? (Use arrow keys)
Add a secret
Update a secret
Remove secrets
❯ I'm done
Use the AWS SSM GetParameter API to retrieve secrets in your Lambda function.
More information can be found here: https://docs.aws.amazon.com/systems-manager/latest/APIReference/API_GetParameter.html
? Do you want to edit the local lambda function now? No
この時点で、 AWS Systems Manager Parameter Store に指定したキーと値からシークレットが登録されます。
AWS コンソールを開いて、AWS Systems Manager > アプリケーション管理 > パラメータストア から確認できます。

以下のキー名の prefix (パス部分)を後から環境変数に登録するので控えておきます。
/amplify/{AppID}/dev/AMPLIFY_chatGPTVoiceBotFunction_{KeyName}
シークレットのキー名 prefix と DynamoDB のテーブル名 postfix を Lambda の環境変数に設定する
先程控えたシークレットのキー名の prefix を Lambda の環境変数に設定します。
Lambda から環境変数に登録されたシークレットの prefix のキーを使って、AWS SDK 経由で AWS Systems Manager からシークレットの値を取得します。
また、amplify push 時に作成された DynamoDB のテーブル名には postfix の値が付与されています。
テーブル名は DynamoDB のコンソールで確認できます。
テーブル名の postfix -XXXXXXXXXXXXXXXXXX-dev 部分を環境変数に設定して Lambda から呼び出して使用します。
こちらの値は後ほど登録するので控えておいてください。
まずはシークレットのキー名 prefix を環境変数に設定します。
以下コマンドを実行してシークレットのキー名 prefix を環境変数に設定します。
amplify update function
シークレットを設定する Lambda 関数を指定します。
? Select the Lambda function you want to update
chatGPTLineChatBotFunction
❯ chatGPTVoiceBotFunction
Environment variables configuration を選択します。
? Which setting do you want to update?
Resource access permissions
Scheduled recurring invocation
Lambda layers configuration
❯ Environment variables configuration
Secret values configuration
環境変数に登録するキー名を入力します。今回は BASE_SECRET_PATH と命名しました。
? Enter the environment variable name: BASE_SECRET_PATH
キーの値を入力します。
先程控えておいたシークレットのキー名の {KeyName} を省いた prefix の値を入力します。
{AppID} は自分の環境の値を入力します。
/amplify/{AppID}/dev/AMPLIFY_chatGPTVoiceBotFunction_{KeyName}
→
/amplify/XXXXXXXXXX/dev/AMPLIFY_chatGPTVoiceBotFunction_
? Enter the environment variable value: /amplify/XXXXXXXXXX/dev/AMPLIFY_chatGPTVoiceBotFunction_
次に DynamoDB のテーブル名 postfix を環境変数に登録します。
Add new environment variable を選択します。
? Select what you want to do with environment variables: (Use arrow keys)
❯ Add new environment variable
Update existing environment variables
Remove existing environment variables
I'm done
? Do you want to edit the local lambda function now? No
DB_TABLE_NAME_POSTFIX と命名しました。
? Enter the environment variable name: DB_TABLE_NAME_POSTFIX
先程控えておいたテーブル名の postfix を入力します。
? Enter the environment variable value: -XXXXXXXXXXXXXXXXXXXXXX-dev
I'm done を選択し、次に N を入力し完了です。
? Select what you want to do with environment variables: (Use arrow keys)
Add new environment variable
Update existing environment variables
Remove existing environment variables
❯ I'm done
? Do you want to edit the local lambda function now? No
最後に amplify push -y を実行してクラウドに反映させてください。
Amazon Lex を設定する
次に Amazon Lex でボットを作成し、先程作成した Lambda との関連付け、インテントやスロットを設定します。
Amazon Lex でボットを作成する
Amazon Lex コンソールから ボットを作成する ボタン押下します。

空のボットを作成します を選択します。
ボット名、説明を入力します。
IAM アクセス許可は初めてボットを作成する場合 基本的な Amazon Lex 権限を持つロールを作成します。 を選択します。
児童オンラインプライバシー保護法 (COPPA)は はい を選択します。
次へ ボタンを押下します。

次に、言語は 日本語 を選択します。
音声による対話は複数種類用意されているボイスの選択が出来ます。
インテント分類信頼スコアのしきい値はデフォルト値の 0.40 とします。
この値は後から変更可能です。

音声サンプルは実際のボイスを聞く事ができます。
標準テキストとニューラルテキストの読み上げ音声がありますが、ニューラルテキストの方がより自然な発声をします。
過去の記事 でボイスの違いについて書いたので参照ください。
今回はニューラルテキストの Kazuha を選択しました。
完了 ボタンを押下してボットを作成します。
Amazon Lex と Lambda を関連付ける
Amazon Lex コンソールから作成したボットを選択します。

左カラムの デプロイ > エイリアス を選択します。

エイリアス名 TestBotAlias を選択します。

言語 Japanese (Japan) を選択します。

Lambda 関数 - オプションのソースに先程作成した Lambda 関数名を指定します。
保存 ボタンを押下します。

カスタムスロットタイプを作成する
Lex では、スロットに値を入れる必要があります。
今回は質問をする内容を何でも聞けるようにするために、ダミーの値を埋める空のスロットを作成します。
左カラムの ChatGPTBot > ドラフトバージョン > 全ての言語 > 日本語 > スロットタイプからスロットタイプ一覧画面を表示します。
スロットタイプの追加 ボタンを押下し、空のスロットタイプを追加 を選択します。

今回スロットタイプ名は empty とします。
追加 ボタンを押下します。
スロットタイプ値も empty を入力します。
価値を追加 ボタンを押下します。
スロットタイプを保存 ボタンを押下します。

インテントを作成する
それでは、インテントを作成するのですが、既にボット作成時にデフォルトで NewIntent が作成されているのでそれを編集します。
左カラムの ChatGPTBot > ボットのバージョン > ドラフトバージョン > 全ての言語 > 日本語 > インテントからインテント一覧画面を表示します。
一覧にある NewIntent を押下します。

インテント名に ChatGPT と説明を入力します。
サンプル発話 には 質問 と入力します。

スロットを追加 ボタンを押下します。
スロット名を入力します。
スロットタイプは先程作成したカスタムスロットを指定します。
スロットの値が取得できなかった場合のボットからユーザーに応答するプロンプトは今回 お気軽に何でも聞いて下さい としました。
追加 ボタンを押下します。

追加後はこのように表示されます。

コードフックアクションは有効にします。
有効にすることで、インテント使用中に Lambda が常に実行されます。
インテントを保存 ボタンを押下します。
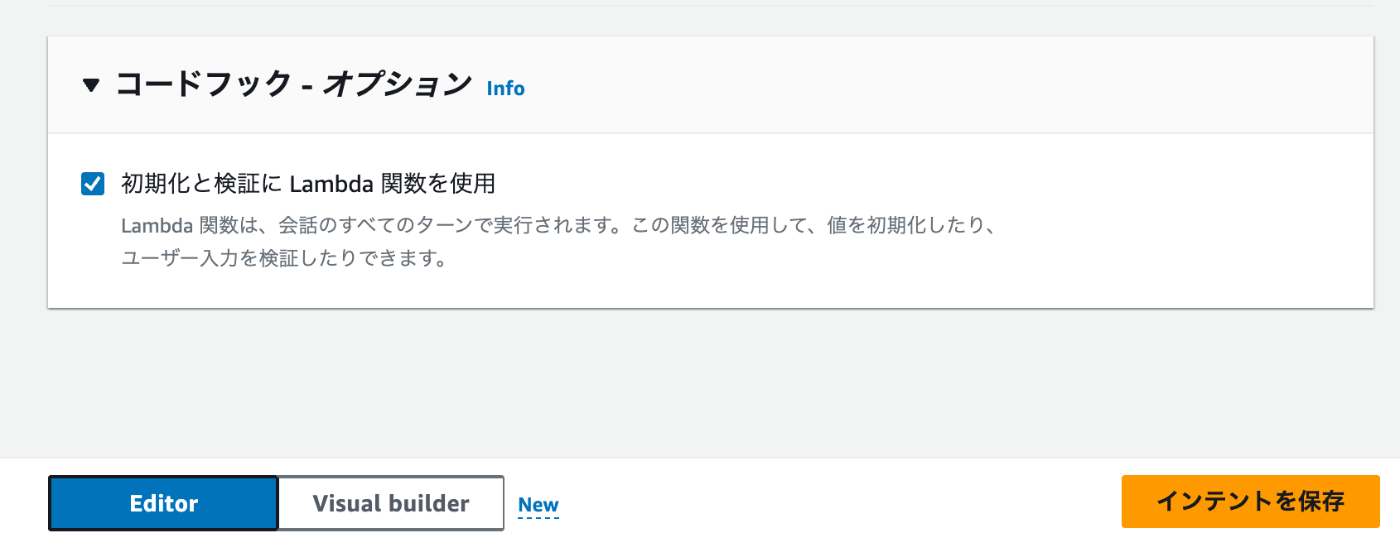
保存をした後は必ず画面左上の Build ボタンを押下してください。
Amazon Connect を構築する
最後に Amazon Connect の環境構築をします。
Amazon Connect インスタンスを作成する

Amazon Connect のコンソールから Create Instance ボタン押下します。
ID 管理は Amazon Connect にユーザーを保存 を選択します。
アクセス URL には任意のサブドメインを入力します。

次に全ての項目を入力して管理者を追加してください。

テレフォニーオプションはデフォルト 着信を許可する と 発信を許可する にチェックが入っているのでそのまま進みます。

データストレージもデフォルト値のまま次に進みます。

最後に確認画面が表示されるので入力に問題無いことを確認して インスタンスの作成 ボタンを押下します。
インスタンス作成が完了するまで 2〜3 分待ちます。
インスタンスが作成完了したら https://{instance-alias}.my.connect.aws/home にアクセスします。

Amazon Connect Contact Control Panel (以後 CCP) が表示されます。
Amazon Connect CCP ダッシュボードが表示されるので、言語設定を日本語に変えておきます。
ブラウザに Amazon Connect のマイク使用許諾のダイアログが表示されるので許可します。

Lex と Lambda を Connect インスタンスに紐付ける
Amazon Connect コンソールを表示し、作成したインスタンスを選択します。

左カラムの 問い合わせフロー を押下します。

Amazon Lex のリージョンが アジア・パシフィック:東京 となっている事を確認します。
先ほど作成したボットを選択します。
エイリアスには TestBotAlias を選択します。
Amazon Lex ボットを追加 ボタンを押下します。
次に作成済みの Lambda 関数を選択します。
Add Lambda Function ボタンを押下します。
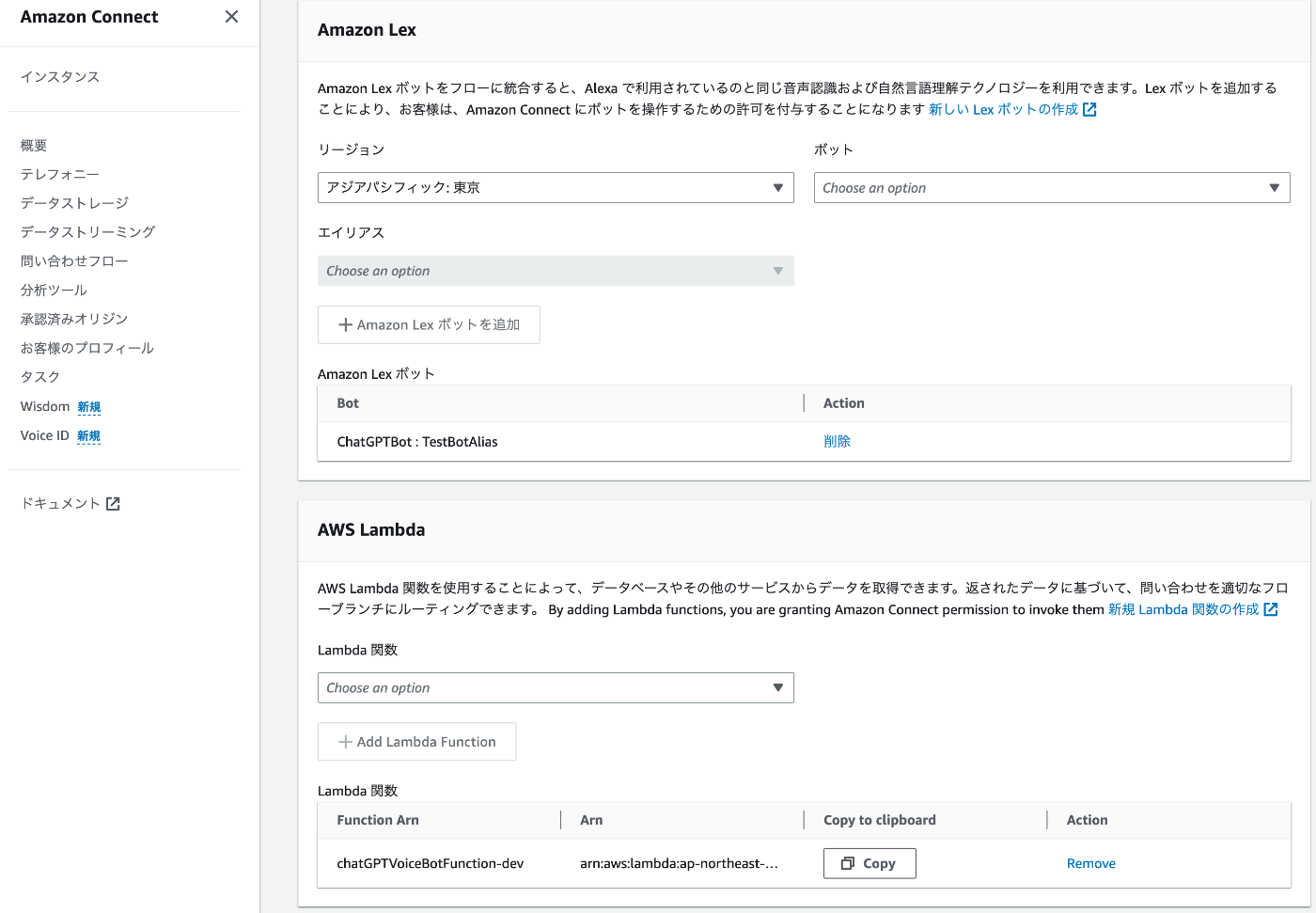
この作業は忘れがちなので必ず設定してください。
コンタクトフローを作成する
https://{instance-alias}.my.connect.aws/home にアクセスし Amazon Connect CCP を開きます。
左カラムのフローからコンタクトフロー画面を表示し コンタクトフローの作成 ボタンを押下します。
コンタクトフロー作成画面になるので、左上にあるコンタクトフロー名を任意で入力します。
今回は ChatGPT と命名しました。
以下コンタクトフローの完成図です。

以下それぞれの設定値です。
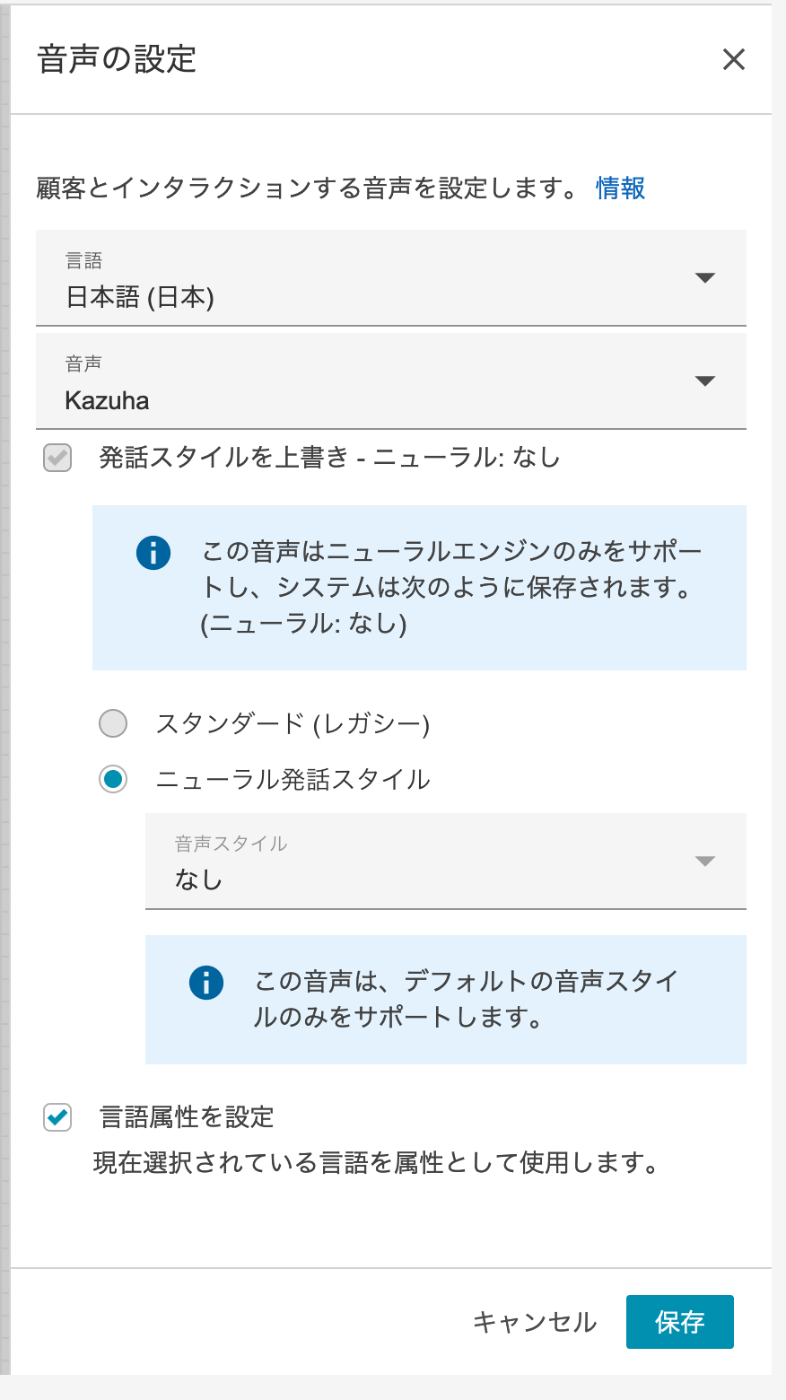
音声の設定 ブロックは言語を日本語、音声はお好みで良いのですが今回はニューラル発話の Kazuha を選択しました。
必ず 言語属性を設定 にチェックを入れてください。
顧客の入力を取得する ブロックは テキスト読み上げまたはチャットテキスト > 手動で設定 に 読み上げるテキストを入力してください。

次に Amazon Lex タブを選択し、 Lexボットを選択 に先程 Lex コンソールで作成した ChatGPTBot と TestBotAlias を選択します。
インテントには Lex コンソールで作成したインテント名 ChatGPT を手動で入力します。

コンタクトフローを作成、編集をしたら必ず画面右上の 保存 次に 公開 ボタンを押下してください。
電話番号を取得する
左カラムの電話番号を選択して電話番号の取得 ボタンを押下します。

次に電話番号と問い合わせフローを選択します。
日本国内の場合直通ダイヤルと料金無料通話は以下となります。
- 直通ダイヤル (DID) 番号
- DID 番号は市内局番。050 または 03 から始まる番号。
- 料金無料通話
- 0120 または 0800 から始まる番号。
2023 年 4 月現在日本の電話番号は追加出来ませんでした。
AWS の公式 に以下の記載があります。
アジアパシフィック (東京) リージョンで作成した Amazon Connect インスタンスの電話番号を取得するには、AWS サポートケースに問い合わせて、事業所が日本にあることを示すドキュメントを提出する必要があります。
事業用の電話番号のみ登録できます。個人用の電話番号は登録できません。
今回は個人の検証の為、US を選択しタイプは DID(直通ダイヤル) を選択します。
料金無料通話は日本国内からかけた場合、結局国際通話料がかかる上に AWS 料金も直通ダイヤルに比べて割高です。
Amazon Connect の料金形態は複雑な為、こちら が纏まってて参考になりました。
直通ダイヤルも料金無料通話も番号を持っているだけで料金が発生するので、検証が終わったら番号を破棄するか、インスタンスを削除するなりしましょう。
電話番号の候補が表示されるので、好きな番号を選択します。
問い合わせフロー/IVR は ChatGPT を選択します。
保存 ボタンを押下します。

これで ChatGPT のボイスボットの完成です。
取得した電話番号に電話をかけると ChatGPT ボイスボットと会話する事ができます。
Amazon Connect CCP の発話エラー発生対処方法
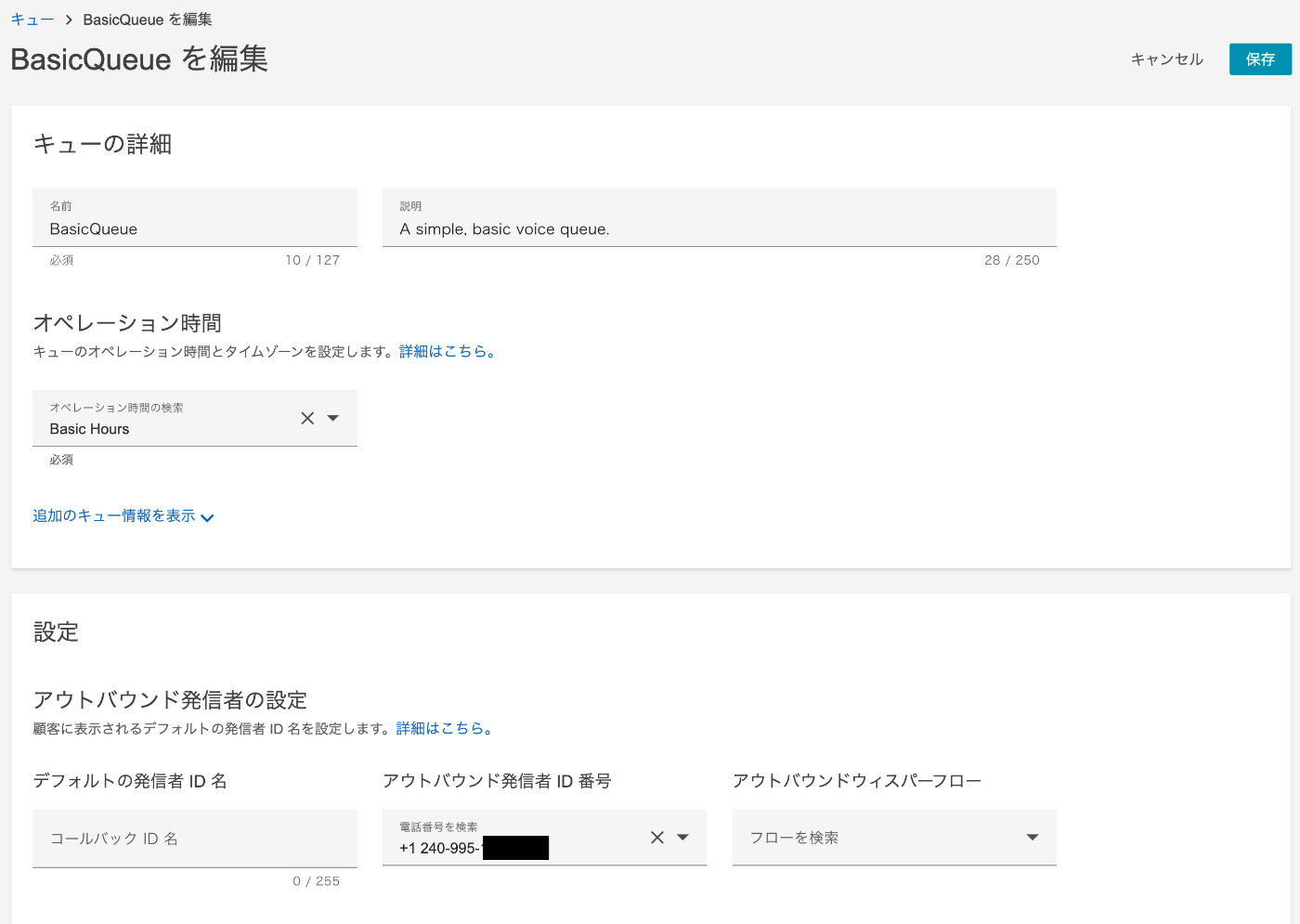
Amazon Connect の CCP(コンタクトコントロールパネル)で通話を発信した際に以下エラーが発生した場合の対処方法です。
無効なアウトバウンド設定
通話を発信する前に、電話番号をこのキューに関連付ける必要があります。管理者にお問い合わせください。

構築した Amazon Connect CPP へサインインし、ルーティング → キュー画面を開きます。
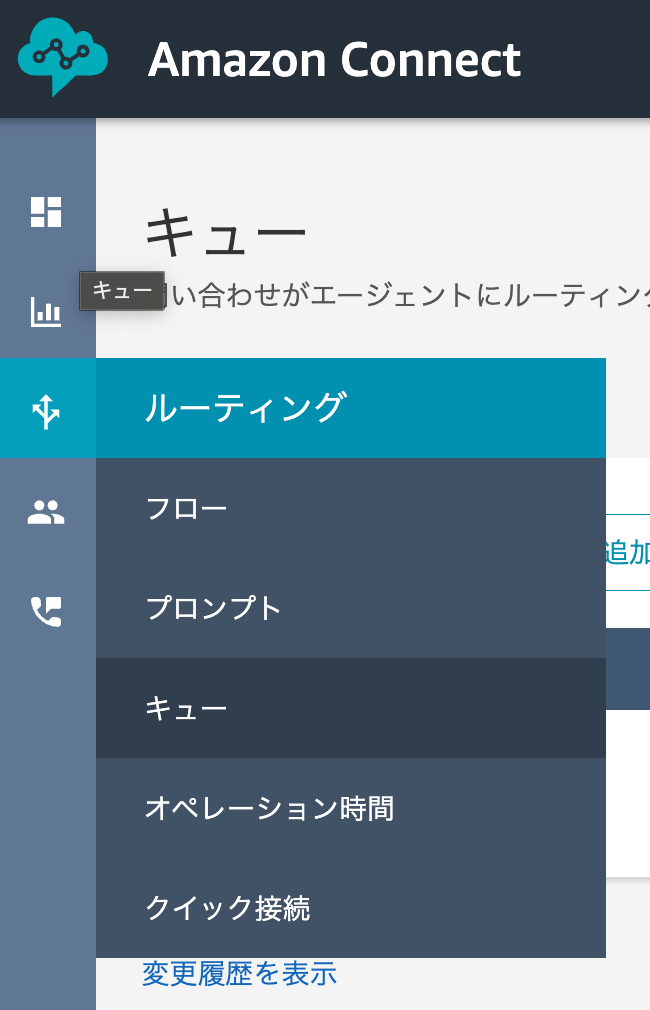
使用しているキュー名を押下します。

アウトバウンド発信者 ID 番号 に先程取得した電話番号を選択します。
保存 ボタンを押下します。
参考
Discussion