[読書メモ] AWS運用入門 押さえておきたいAWSの基本と運用ノウハウ
この書籍についての個人的メモ
Azureと比較しながら理解を深めていく
入門編
AWSのWell-Architected Frameworkにはサステナビリティの柱がある
Azureだと基本構成の利用でルートテーブルの存在をあまり意識しないけど、AWSでは割と常識
ルートテーブルでInternet Gatewayへのルーティングがあると通称"Public Subnet"と呼ばれる
ルートテーブルの"local"がAzureの"VirtualNetwork"のサービスタグぽい?
L4FWとしては、リソース単位で利用するセキュリティグループとサブネット単位で利用するネットワークACLがある。
ネットワークACLが位置づけ的にはAzureのNSGに近いかもしれないが、ステートレスなので戻りの通信規則も設定する必要がある
セキュリティグループのほうはステートフルなので楽ではある
->セキュリティグループが主流って言われたことがあるのはこのせいか?
- あと、セキュリティグループはWhiteリスト方式なので許可しか入れない
- ネットワークACLは拒否を入れられる
- ネットワークACLでゆるーく制限をかけて、セキュリティグループで厳しく制限するのがコツらしい
- ネットワークACLはルールの上限が40なのでそもそも細かく制御するには使いづらいところがある
EC2 = VM
AMI = Image
Elastic IP: 固定IP、起動中のEC2に使う場合は無料。使ってないなら返却して節約。
Public IP:動的IP
ENI = NIC:IPを紐づける
Amazon EBS = Azure Managed Disk?
EC2のデータを保存するブロックストレージ
ファイルやデータを固定サイズのブロック単位で保持しているため、ファイルの更新や修正が効率的に行える
ネットワーク経由でEC2にマウントする。ここも同じ。
EC2インスタンスへのDetach/Attachが可能
スナップショットとってそこから別のEBS作成できる
S3 = Blob Storage
容量無制限の11x9%の耐久
S3.ストレージクラス=Blob.アクセス層
S3.ライフサイクルルール=Blob.ライフサイクル管理
バケットポリシー:バケットごとのFW+操作権限設定のようなものか?
S3.ブロックパブリックアクセス=Blob.ストレージアカウント側の公開設定でパブリック拒否
RDS:Relational Database Service
PaaSのRDBだけどVPCにデプロイする必要がある(できる)
OSへのログインはできない
RDSでもストレージの選択が必要:汎用SSD,プロビジョンSSD,マグネティック
マルチAZ配置がRDS側の機能で可能
呼び出すときはIPではなくAWSが管理するRDSのエンドポイントを指定することで障害発生時にDNSベースでDBインスタンスがセカンダリに自動で切り替わる
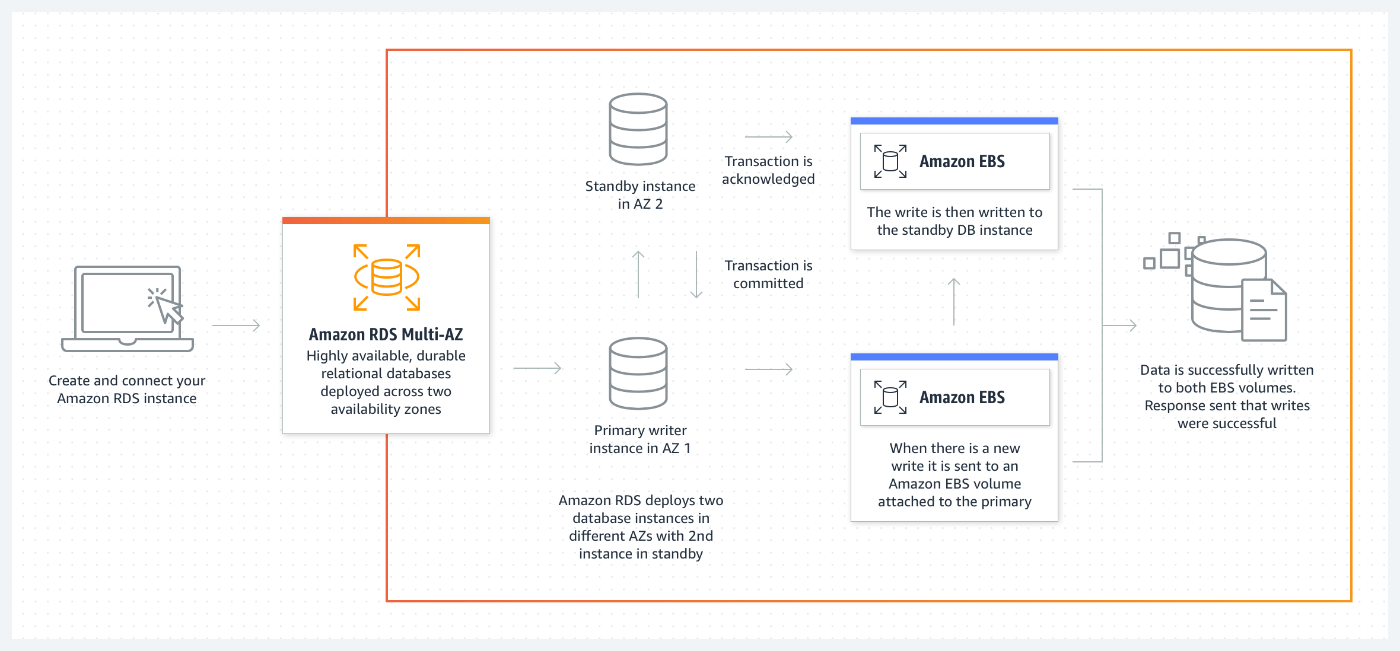
DBインスタンスのリネームの機能によってアプリケーションの変更をすることなく呼び出すDBインスタンスを変更させることも可能
- アプリではprod.xxx.amazonaws.comを常に見る
- prod.xxx.amazonaws.comとprod2.xxx.amazonaws.comでDBインスタンスを2台稼働させておき、全社が死んだ場合に後者をリネームしてエンドポイントをprod.xxx.amazonaws.comにする
- すると応答するDBインスタンスが生きているものになる
ELB:Elastic Load Balancer
=Azure Load Balancer?ではない
ELBの中にALB(Application LB = Azure AppGW)とNLB(Network LB = Azure Load Balancer)がある
裏側で冗長構成になっているため単一障害点ではない
ELB自体の負荷が増えるとスケールアップやスケールアウトする
ALB = Azure AppGW
Webサーバの負荷分散
パスベースルーティング
Public Subnet(Internet Gatewayへのルーティングがあるサブネット)に基本配置
HTTPSリスナーを用意する際は証明書必要
ALB.ターゲットグループ = AppGW.バックエンドプール
ALB.ヘルスチェック = AppGW.正常性プローブ
NLB = Azure LB
Webサーバ以外の負荷分散
Chapter 4 アカウント運用
AWSアカウントを作成した直後ではルートユーザでサインインして作業をする
ルートユーザー:
AWSアカウント作成時に指定したメールアドレスとパスワードでログインできるユーザ
すべてのサービスへのアクセス権を持つ
ー>Azureでいうところのグローバル管理者?サブスクリプション所有者?にあたる?
AWS IAM
- IAMユーザ:認証単位
- IAMグループ:IAMユーザをまとめる、AADのセキュリティグループ
- IAMロール:AWSリソースがほかのAWSリソースを操作するために必要。Azure RBACロール的な存在ではなく、どちらかというとユーザ割り当てマネージドIDに近い
- IAMポリシー:操作権限の認可を行う仕組み、Azureのカスタムロールに近い。IAMポリシーはIAMロールやIAMユーザ・グループと関連付ける
ルートユーザでIAMユーザを払い出して認証単位を作成し、個々人にはIAMユーザでサインインしてもらう感じ
個々のIAMユーザには必要最小限の認可を受けている
- AWSの場合アカウントの中にユーザがいる(認証がAWSアカウントに紐づく)という感じになるので、複数アカウントの運用が結構面倒
- 素の状態だとAWSアカウントを複数管理したい場合にはそれぞれに認証情報を持つことになるため、管理する資格情報がいたずらに増える
- AzureであればAADというIDP上で管理されているユーザが複数のサブスクリプションを管理することができる
とはいえ、AWSのIAMユーザがAWSアカウントをまたがる認証ができないかというとそうではなくて、「ロールの切り替え」という機能を使えば一応できる
IAMユーザでログインして、ほかのAWSアカウントについては権限をIAMロール(MID)に切り替えてログインし、そのIAMロールに紐づいた権限でそのAWSアカウントを管理

アクセス先アカウントのIAMロールの信頼ポリシーで、アクセス元AWSアカウント上のIAMユーザを許可する
踏み台アカウントのIAMユーザにはIAMポリシーとしてアクセス先アカウントのIAMロールを設定する
->sts:AssumeRoleアクション
IAMユーザとIAMグループを利用すると、管理先の外部のAWSアカウントが複数ある場合の運用が楽になる
以下のイメージを描くのにdrawioを利用したけどこれは便利だ
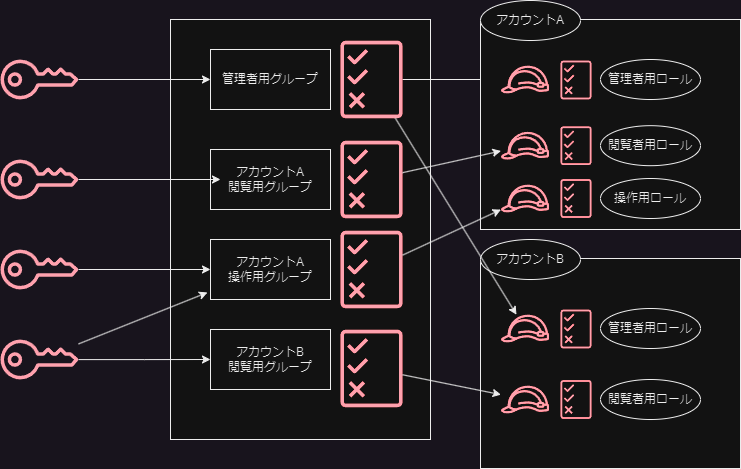
-
ルートユーザはメアド+パスワード認証がデフォルト
- ただし、MFAが推奨
- Azureにおけるブレイクグラスアカウントの利用が推奨とかはない?(あれも利用されているかは怪しい)
-
オンプレADとかもいないのでSSPRもまあ楽
- IAMの変更権限を持つIAMユーザ≒ユーザアクセス管理者
- IAMの運用はIAM Policy Simulatorで影響を調べながら行う
- これめっちゃ楽なのでは?Azureにはない?
- 組み込みロールの中のアクションの管理とかも含めてリソース種別ごとに見れるし、、、!
アクセスアドバイザー
IAMエンティティがアクセス可能なAWSサービスに最後にいつアクセスしたか把握
IAM Access Analyzer
- AWS CloudTrailに記録されたIAMエンティティの操作履歴を最大90日間さかのぼって分析し、利用された権限に絞って最小権限のIAMポリシーを生成する機能
- Azureにも確かあった:Entra Permissions Management
AWS Organizations
-
複数アカウントの運用では、AWS Organizationsも利用される
- AWS管理アカウントと、その配下になるAWSメンバーアカウント
- 外部のAWSアカウントをメンバーアカウントとして追加もできる
- Azureでは、「管理グループ」に近しい
-
内部にOUを作り、OUに対してサービスコントロールポリシー(SCP、実態はIAMポリシーと等しい)をかけることで、そのOUは以下のAWSメンバーアカウントにそのIAMポリシーが引き継がれる
-
AWSメンバーアカウントの管理については、AWS管理アカウントを踏み台にして、「ロールの切り替え」によって実現する
- 管理アカウント上のIAMユーザがメンバーアカウント側のIAMロールに入って操作するイメージ
Chapter 5. ログ
AWSサービスのログの例
前提:CloudWatch Logsにデータをためる=Azure Log Analyticsにためるイメージ、というよりむしろAzure Monitor Logsか?
- VPC:VPCフローログ
- EC2:EC2内のログはCloudWatchエージェントを入れてCloudWatchに流す
- RDS:リソースログがとれる
- ALB:アクセスログをS3に流せる
- NLB:アクセスログをS3に流せる
ためたログの分析はAmazon Athenaなどのクエリ実行サービスで行う
違うかも?
ログの取得:各リソース
ログ転送:Kinesis Data Firehose
ログ保管:S3、CloudWatch Logs
ログ利用:Athena、CloudWatch Logs Insights
CloudWatch Metrics = Azure Monitor Metrics
CloudWathc Logs = Azure Monitor Logs
CloudWatch Logs Insights = Log Analytics ワークスペース(のクエリ機能?)
Kinesis Data Firehose = Azure Event Hubs
CloudWatchエージェントをEC2に入れる場合には、、、
- EC2がインターネットと通信できるようにする
- EC2のIAMロールにCloudWatchへの出力権限を含むIAMポリシーを入れておく
- VPC Flow LogsはVPCのENI間で行き来するIPトラフィックについて情報をキャプチャできる機能
- なので、ENIがつけられるリソースについてキャプチャ可能
- AzureのNSGフローログよりVNETフローログに近いか
CloudWatch Logs Insightsは専用のクエリコマンドを使う
- display
- Filter
- Fields ...etc
CloudWatch Logs Insightsでスキャンしたデータ量に応じて課金
- 5GBまでスキャン無料、以降0.0076USD/GB
Athena
- Athenaはあれか、データレイクにクエリかけられる的なものか
- S3に対して標準的なSQLクエリをかけられる
- つまり、S3に吐き出したAWSリソースのログに対してクエリがかけられる
- 何でもかんでもクエリできるわけではなく、テーブル定義が必要
- Athena上で、S3の外部テーブル的なものを作るわけか
Athenaにはワークグループという論理グループの概念がある
- これにより、保存したクエリやS3出力を分離できる
- IAMユーザがアクセスできる先をIAMポリシーにより制御する
CloudWatch Logs Insights or Amazon Athena?
CloudWatch Logs Insights
- CloudWatch Logsに保管している少量のログをクエリかけたい場合
- CloudWatch Logsにのみ出力をサポートしているAWSサービス(RDS)に対してクエリ実行したい場合
- CloudWatch Logs -> S3は費用が発生
Athena
- S3内に保管されている大量のデータに対して標準SQLを利用してクエリをかけたい場合
- だからAzure Synapseの比較としても出てくる
- CloudWatch Logsに大量データを取り込むと結構高い
- CloudWatch Logs Insightsでサポートされていないログ形式のファイルに対してクエリをかけたい場合
- 同一クエリを日時実行したい場合
- クエリ結果の再利用が可能であるため
-
EC2インスタンスが多数ある場合にログ設定を個別にやるのはさすがに面倒だよね
- AWS System Manager Parameter Storeにその設定をJSON形式で保管しておくことができる
-
AWS Systems Manager Run Command
- EC2インスタンスにOSログインすることなくコマンドやスクリプトをリモートで実行することができる=Azureでいう実行コマンドの話っぽい
-
これらは前提条件としてEC2にSSMエージェントを入れる必要がある
- AWSのマネージドイメージ(AMI)には既定でインストールされている
- Azureでいうところの仮想マシンエージェントに近いんかな?
-
他にも、SSMのエンドポイントとの通信経路の確保も必要
-
IAMロール(AzureのMID的なもの)を使用してEC2がSSMと通信するためのポリシーを付与
VPCエンドポイント
= Azureでのプライベートエンドポイントに近い
- インターフェイスエンドポイント
- Gateway Loadbalancerエンドポイント
- ゲートウェイエンドポイント
がある
Azureのイメージに近いのはインターフェイスエンドポイント
- Privateサブネットの中に専用のENIを作成しそこ経由でVPC外のAWSリソースにアクセスする
AWS Session Manager
キーペアなしでAWSのコンソールからEC2にRDP・SSHできる仕組み
AzureでいうとBastionの機能に相当するのか?
ただ、サブネットにインスタンスを立てなくてもよくいので、おそらくBastionよりも安価
Chapter 6. 監視
サーバでpingが通らない=サービス停止
CPU使用率が閾値を超える=すぐにサービス停止とはならない
正常性モデリングの検討材料となるので、重要
Amazon CloudWatch Metrics = Azure Monitor Metrics
無料提供
統合CloudWatchエージェント
これは、Azure Monitor Agentに等しい
Azure同様、CloudWatch Metricsはデフォルトで取得されるが、統合CloudWatchエージェントを利用するとOSレイヤのメトリクスも収集可能
Amazon CloudWatch Alarm=Azure Monitorのアラート機能
- アラームが発砲されたら担当者に通知をする
- それの通知にAmazon SNSを利用する
Amazon SNS=たぶん、Azure Monitorのアクショングループ的な位置づけ
定期的に確認するダッシュボード機能としてはAWS CloudWatchダッシュボードがある
AWS CloudWatch Metricの可視化機能は不十分
Amazon CloudWatch Logs = Azure Monitor Logs(Log Analytics)
オートリカバリーがネイティブの機能としてある
- アラームをトリガーに自動でEC2インスタンスの停止・起動・復旧をする
- どうじにSNSトピックによる通知も設定することで担当者が把握することができる
AWS Health
- AWSの基盤側でのメンテナンスとか、障害情報とか、リソースに関係あるイベントの検知
- Service Health
- 各AWSサービスのリージョン単位での障害情報、AWSコンソールログイン不要
- Azureの状態、と同じ
- Your Account Health
- ユーザが実際に現在利用しているリソースのうちに、イベントの詳細や影響を受けるリソース・イベントへ対応するための推奨事項が出る
- 計画メンテの情報もわかる
EC2にはリタイアの概念がある
- EC2インスタンスが載っている物理サーバ機器の入れ替えのタイミングがある
- Azureではライブマイグレーションで勝手にやってくれるところもあるが、、、?
- リタイアが通知されると、期日までにEC2の停止・起動を実行する必要があり、それまでに実行しないと強制適用
- つまりAzureVMの計画メンテナンスに近い?
Chapter 7. パッチ適用
IaaSにおいてはOS以上の管理はユーザに委任される=OS・ミドルウェア・アプリケーションのパッチ適用についてはユーザ側の責任
AWS Systems Manager Patch Manager: OSやアプリへのパッチ適用を自動化するツール
パッチベースラインを作って利用する、基本的にOSについてはデフォルトのベースライン、が指定されている
->パッチベースラインだけでは適用までやってくれないので、パッチポリシーを作成する
AzureではAzure Update Managementに相当
特定の重要度以上で適用されていないパッチを"コンプライアンスレポート"として一覧で確認できる
CVE: Common Vulnerbilities and Exposures
CVE-IDという形で各ベンダーから発表されたり、セキュリティ監査法人から上げられたりする
Azure Update ManagementもAWS Patch Managerもパッチの適用を自動化するだけのサービス
=「そのパッチの影響や動作確認は自分たちの責任で行う必要がある」
一般的には、検証環境が用意されている場合にはパッチ適用についても検証環境を通してから本番に適用する。検証用と本番用でパッチベースライン・パッチポリシーを分け、問題が生じたときに本番に影響が出ないようにする。
Chapter 8. バックアップ・リストア運用
バックアップの種類
-
オフラインバックアップ
- システムを停止した状態で取得する
- 頻繁なバックアップが不要な場合に利用する
- 週1回や月1回くらい
- 停止を伴うので、停止していい時間とバックアップ取得にかかる時間を抑える必要がある
-
オンラインバックアップ
- システムを稼働させたまま取得するバックアップ
- データの更新頻度が高い場合
- システム稼働負荷に加えてバックアップの取得のための負荷がかかる
- ストレージへの書き込みが多いシステムだとデータの不整合が生じる可能性がある
- データの更新頻度が少ない時間帯にバックアップを取得するなどの対処
バックアップの取得単位
- ファイル単位:オフラインバックアップが推奨
- システム内にあるデータのみの取得なので、システムが壊れればそのデータは意味なくなる
- イメージ単位のバックアップ
- イメージ=ファイルやフォルダの構造を保ったまま複製・保存したデータ
- WindowsでいえばVHDに当たる
- システムが保存しているデータだけでなく、メタデータも取得
- システム自体が破損しても復旧可能
- イメージ=ファイルやフォルダの構造を保ったまま複製・保存したデータ
AWSではイメージ単位でのバックアップが主流
バックアップの世代管理
最新のバックアップだけではなく、それ以前のバックアップをどこまで残しておくかの話
例:日次バックアップを取っていて、保存期間が7日間であるならば、7世代分のバックアップを取得していることになる
フルバックアップ:すべてのデータをバックアップとして取得
差分バックアップ:前回のフルバックアップデータから更新されたデータのみをバックアップ
増分バックアップ:前回のバックアップデータから更新されたデータをバックアップとして取得する。バックアップデータの量は少なくて済むが、すべての増分バックアップを適用して初めてリストア完了となる
AWSではほとんどの場合増分バックアップを利用する
RTO = Recovery Time Objective:復旧までにかかる時間、「復旧までにどれくらい時間がかかるか」
RPO = Recovery Point Objective:復旧できる時点、「どの時点までのデータに戻せるか」
AWSにおけるバックアップソリューション
基本AWS Backupを利用することで、AWSリソースのバックアップが一元的に行える
EC2のバックアップ
- EBSスナップショット = Azure Diskスナップショット的なもの。EBSのデータのみをバックアップしたいときはこっちがいい。
- Amazon AMIの取得 = EC2全体をキャプチャするようなもの。複数のEBSもまとめていける。
RDS/Aurora
- 自動日時バックアップ
- 35日間保持
- スナップショット
- 保持期間はなく、明示的に削除されるまで残る
- Auroraでは操作の巻き戻しを最大24時間可能
- こいつらは、自前でバックアップ機能を持っているので、AWS Backupとどっちがいいのかは要検討
AWS Backup
- いわゆるAzure Backup的な
- バックアッププラン(スケジュール等の設定)を作成してアタッチする感じ
- 増分バックアップ
- バックアッププランに対してリソースを割り当て
- EC2だけが対象ではない
- サービスとしては一つだが、データの保管先がバックアップボールトとして分けることが可能
- 基本Defaultだが、作成してそっち側に保存することができる
- バックアッププランの中の「バックアップルール」で、データを別のリージョンにコピーする設定やストレージの層を変更するライフサイクル管理も可能
AWS BackupはIAMロール(にアタッチされたポリシー)として「AWSのリソースをバックアップできる権限」を付与されている
Amazon Data Lifecycle Manager
- AMIとEBSスナップショットのライフサイクル管理を行うサービス
- これまた、AWS Backupとどっちがいいのか要検討
AWSの場合、PaaSのバックアップも同じAWS Backupが窓口になっているのが特徴
また、システムがいくつかある場合はそれぞれにタグをつけて管理しておき、システムごとにバックアッププランを作る(要件が異なるので)
Chapter 9. セキュリティ
セキュリティの三要素
- 機密性:許可された個人・コンピュータのみがシステムやデータを利用できる
- 完全性:データに対して改ざんや破壊がなく正確なこと
- 可用性:障害発生時にも影響を最小限にして稼働を続けること
セキュリティは目に見えない+利益を生み出すものではないため導入コストのメリットを理解されづらい。よって業界基準が使われがち。
- NISC:政府機関の情報セキュリティ
- FISC:金融機関
- NIST:サイバーセキュリティ
- PCI DSS:クレカ系
社内の人間の人為的ミスにより情報漏洩することもある>CSPMが必要
AWS Well-Architected Framework
- AWSのWAFに従って考えることが多い
memo:WAFの6個目の柱がサステナビリティ
- オンプレよりもクラウド使う方が77%CO2削減できるらしい
- 実際に、現在のAWS利用に基づくCO2予測排出量を見るツールもある
転送中のデータセキュリティ
AWS Certificate Manager
- SSL/TSL証明書のプロビジョニング・管理・デプロイを一元的に行える
- 通信相手が本人であることを確認し、通信を暗号化する
- 通常は認証局が発行
- ACMでは、無償でSSL/TLS証明書を発行できる
- 認証局としてはAmazonが自前のAmazon Trust Servicesから発行
- とはいえDV証明書なので信頼性は低い
- もっと高信頼性の証明書が必要な場合はDigiCertとかから購入する
- まあ当たり前だけどAWSサービスへの証明書の組み込みはコンソールからできる
- ACMで発行した証明書は自動更新が可能
- 外部で発行した証明書も管理はできる
ネットワークセキュリティ
セキュリティグループ
- セキュリティグループはVPCが提供する機能の位置づけ
- 特徴
- ステートフル。戻りの通信は自動でルール追加。
- 許可するルールのみを記述。拒否ルールは作れない。
- 作成時に作成先のVPCを指定する。よって、VPCまたぎで再利用はできない。
- ソースとして、セキュリティグループのIDを指定できる。
- セキュリティグループAのアタッチされたリソースからの接続が許可されるようなイメージ
- 不思議な感じやな
- セキュリティグループAで外部からのTCP:443許可
- セキュリティグループBでセキュリティグループAからのTCP:80許可
- セキュリティグループCでセキュリティグループBからのTCP:1433許可
- みたいなイメージ
VPCにはマネージドプレフィックスリストというCIDRアドレス空間を複数まとめてグループ化できる機能がある、ルールの記述が楽になる。Azureのアプリケーションセキュリティグループの上位互換って感じかな。もしくはAVNMかも。
セキュリティグループのルールを変更するのではなく、そのアドレスがプレフィックスリストに参加しているか否かで適用されるルールが変わる。
AWS WAF
- セキュリティグループはL4なので、パケットの中身まで見ることはできない。それをするのがL7 WAFのお仕事
- Amazon CloudFront/APIGateway/AppSyncにWeb Access Control List(WebACL)を付与することで動作する。AzureのWAFと似たようなイメージ。WAFなしでも使えるし、アタッチもできる。
- Web ACLはAWSマネージドなものとカスタムのものを利用できる。
サーバーサイド暗号化
AWS KMS
- データ保護に利用する鍵の作成から運用まで行うサービス
- KMSで管理しているキーをCustomer Data Key(CDK)
- CDKを暗号化するためのキーをCustomer Master Key(CMK)という
- ユーザが管理するのはCMK、CDKは透過的に都度生成される
- んで、さらにCMKにはAWSマネージドCMKとCustomer Managed CMKの概念がある
- AWSが用意しているか、顧客で用意するかの違い
- CM-CMKは削除ができるが、削除すると元データは復元できなくなる
- 慎重にやれ
CSPM系のサービス
AWS Config Rules
- AWSアカウント上で記録・管理している構成情報に対してルールを設け、準拠した状態になっているか判定=Azure Policy的なサービスか
- マネージドルールとカスタムルールがある
- 非準拠のものには修復アクションを適用できる
リソースの管理者とガバナンス管理者の別れ方でパターン選択
- Config Rules側では検知のみ、修復は現場側に渡すパターン
- Config Rules側で検知と修復を行うパターン
AWS Security Hub
まあ、Defender for Cloud的な立ち位置のサービス
セキュリティ標準が基本5つある。Initiative的な奴。
- AWSのべスプラのやつ->Microsoft Cloud Security Benchmark的な奴
- CISベンチマーク->バージョン違いでx2
- PCIDSS
- NIST
AWS Guard Duty
- AWSの機械学習機能を活用して継続的なデータ分析及びセキュリティ監視を行い可視化まで実施する>Sentinelに近い?もしくはDefender for Cloudの攻撃検知
- 機械学習って何?> "脅威インテリジェンス"
- じゃあそれは何?>AWSセキュリティチームとCrowdStrikeなどのプロバイダが協力してメンテしているもの
- まあブラックボックス
- メインターゲットはEC2/IAM/Kubernetes/S3
Amazon SNS
- Azure Event Hub的なもの
- トピックを用意しておいて、Publisherはそこへ投げ込み、Subscriberはそこからメッセージを取得する
- Subscriberのメッセージの受け取り方はいろいろ、メールでもHTTPでも
Amazon EventBridge
- Azure Stream Analytics的なもの?
AWS Trusted Advisor
- AWSのべスプラに基づいて推奨事項を提示する
- 以下の観点
- コスト
- パフォーマンス
- セキュリティ
- 耐障害性
- サービス制限
- まさにAzure Advisor
Chapter 10. 監査
AWS自体の監査については、AWS Artifact上で公開されている
ユーザ側のAWSの使用についての監査については、ホワイトペーパーが公開されているため、そこに記載の観点で評価をしていく
AWS CloudTrail
- サポートしているすべてのAWSサービスに対するAPI操作のアクティビティを記録・保持する
- Azure Activity Logと同じやな。90日間保存されるってところも同じ。
- 監査として使う以上、データの完全性が保たれないといけないので、AWS側の機能として、「ログファイルの検証」というものがある
- これは改ざん検知の仕組み
AWSにもCloudShellがある。「AWSCloudShellFullAccess」で自由に使える
AWS Config
AWS 上で構築したサービスの構成情報・変更履歴を記録管理する
- Azure Resource GraphとかARMテンプレートを定期的にキャプチャするようなイメージに近いか?
- 過去に削除された構成も見れるため、誤ってAWSリソースを削除していても設定は確認できる
- しかもリソース間の依存関係(EC2とEBSなど)も取得してくれている
特定期間における構成記録をするConfiguration Historyと、オンデマンドでスナップショットをとるConfiguration Snapshotがある
AWS Artifact
- AWS自体が第三者機関から受けた監査のレポートなどが取得可能なサービス
- AWS ISO認定・PCI・SOCレポート
Chapter 11. コスト最適化
AWSのWAFにおけるコスト最適化で語られる観点
- 料金体系の理解
- AWS利用料の把握と不要リソースの削除
- 適切なAWSサービスおよびスペックの選択
- 負荷状況に応じたリソースのスケーリング
- 継続的なコスト最適化の実行
コスト最適化=コスト削減ではない
コスト削減の結果、スペックが足りずに処理に時間がかかりそこがボトルネックになり別のタスクに遅れが生じることがある。この場合、スペックを上げて処理時間を最短にするのが最適なこともある。
コスト最適化が必要な理由
- オンプレでは買い切りが基本になるため、Maxの需要に耐えられるように資産を選定する
- クラウドでは必要な時にスケーリングすればいいっていう話
- 利用者側が常に最適な利用方法を考える必要がある
- EC2においては、最新世代のサーバほど費用対効果が大きいのでアップデートするべきって話
- スペックの変更には停止を伴うのでタイミングの見極めは大事
- そもそも新しいAWSサービスがリリースされることで、今のアーキテクチャが最適でなくなることが多々あるから。
- 例えば、Labmdaの登場によってEC2をわざわざ起動する必要はなくなった
- ドキュメント履歴を確認することで、最新情報にキャッチアップ
Chapter 11. コスト最適化
コスト最適化には実行の壁がある
- インフラ部門とサービス提供部門が分かれている場合
- 場合によってはシステムが停止する
- サービス提供部門としてはいいSKUを使いたいという心理
- 組織内での稟議の通し方、特にRIなどを今まで使ってこなかった場合
- 効果測定として、どれくらい削減できたのかのレポーティングが必要
一方、クラウドにおけるコスト最適化が人事評価につながらない企業が多く、ベストエフォートでしか実施されないことが多い。それによりクラウド活用も停滞するということがある。これを打破するのがCCoE。
AWS Cost Explorer
- Azure Cost Management的なサービス
- Cost Anomaly Detectionの機能もある
- Azureにもある
AWS Budgets
- Azure Cost Managementの[予算]の部分
- アクションも実行できる
- 定期的なレポートを出力可能
AWSにおけるタグ
- Azureのようにリソースグループがないので、タグで仮想的なグループを表現
- コスト配分のタグを用意することで配賦が可能
- コスト配分タグはAzure同様繁栄までにMax24時間かかる
AWS Comupute Optimizer
- 最大14日間のCloudWatchメトリクスの値を分析することでコンピューティングリソースのスペックが最適かどうかを判断し、推奨する
- Trusted Advisor?Azure Advisorぽいけど。
Reserved Instance
- 常時稼働が前提となっている
- AWSでもRIは購入後にキャンセルができない
- 「キャパシティ予約」のオプションも利用可能(RI価格でいつでもリソースを確実に立てられるように確保しておく)
- 一方で従量課金の価格でハードウェアを確保する「オンデマンドキャパシティ予約」もある
- 「インスタンスサイズの柔軟性」という考え方もある=Azureでは「柔軟性グループ」といわれるもの
- RIの期限切れに気付けるようにアラートを設定しておくのがよい。いかんせん1年とか3年とか期間が長いので
Savings Plan
- AzureのSavings Planとほぼ同じ考え方
- 「OSとインスタンスタイプの組み合わせ」を指定するのではなく、「割引適用後の1hあたりの利用料($)」を指定して購入する。まぁ金額的なコミットになる。
- Savings Planにも種類がある
- Compute Savings Plans:EC2/Lambda/Fargate、EC2のリージョン・ファミリーはすべて対応
- EC2 Instance Savings Plans:EC2のみ、特定リージョン、特定ファミリーのみ
- Machine Learning Savings Plans:Sagemakerの利用者が利用するもの
- 「更新予約」によって、実質自動更新がかけられる
- 過去の利用料に基づく推奨コミット金額を提示する機能もある=Azureにもある
RIとSPがある場合はRIが先に適用されて、残りのリソースに対してSPが適用される
RIとSPで割引率はさほど変わらないので、EC2などのコンピュートリソースに対してはCompute Savings Plansを利用するのがよい。ただSavings PlanはRDSには利用できないので、RDSに使うなら必然的にRIになる。