ChatGPT+LangChain| Elasticsearch公式ドキュメントのQ&Aを作ってみる
はじめに
この記事は、情報検索・検索技術 Advent Calendar 2023 の 11日目の記事です。
本記事では、最新のElasticsearchの公式ドキュメントの内容を元にQ&Aを行うチャットボットを、LLMとLangChain、さらには、Elasticsearchのベクトル検索機能を使って作成したので、実現方法や利用した技術について紹介します。
また、RAGを使ったWikipediaのQ&Aを作った話が、同アドベントカレンダーの4日目の記事で紹介されているので、気になる方はご参照ください。
概要
LLMの問題点
OpenAIが提供するGPTや他の大規模言語モデル(LLM)の登場によって、簡単な質問に対しても優れた回答を得られるようになり、知識の取得や整理が容易になりました。一方で、2023年12月現在、一般的に提供されているGPTのバージョン3.5では、2022年1月以降の情報がモデルに反映されていないため、最新の情報を元にした回答を得たいシーンでは利用できません。
例えば、ChatGPTに「Elasticsearchの非推奨な機能」について質問をした場合、下記のように、最新の情報を参照できないため曖昧な回答が返ってきます。

RAGについて
このような場合、よく用いられる手法として、RAG(Retrieval Augmented Generative) があります。RAG は、文章検索において関連する文章を抽出し、それをLLMにプロンプトとして提供する手法です。これは一般的に 「検索拡張生成」 とも呼ばれます。
この手法では、情報を外部のベクトルデータベースに保存し、ユーザが質問をした場合には、その質問に関連すると考えられる文書データを検索します。そして、この検索結果に関連する情報(コンテキスト)を取得し、LLMがこれを元に回答を生成します。
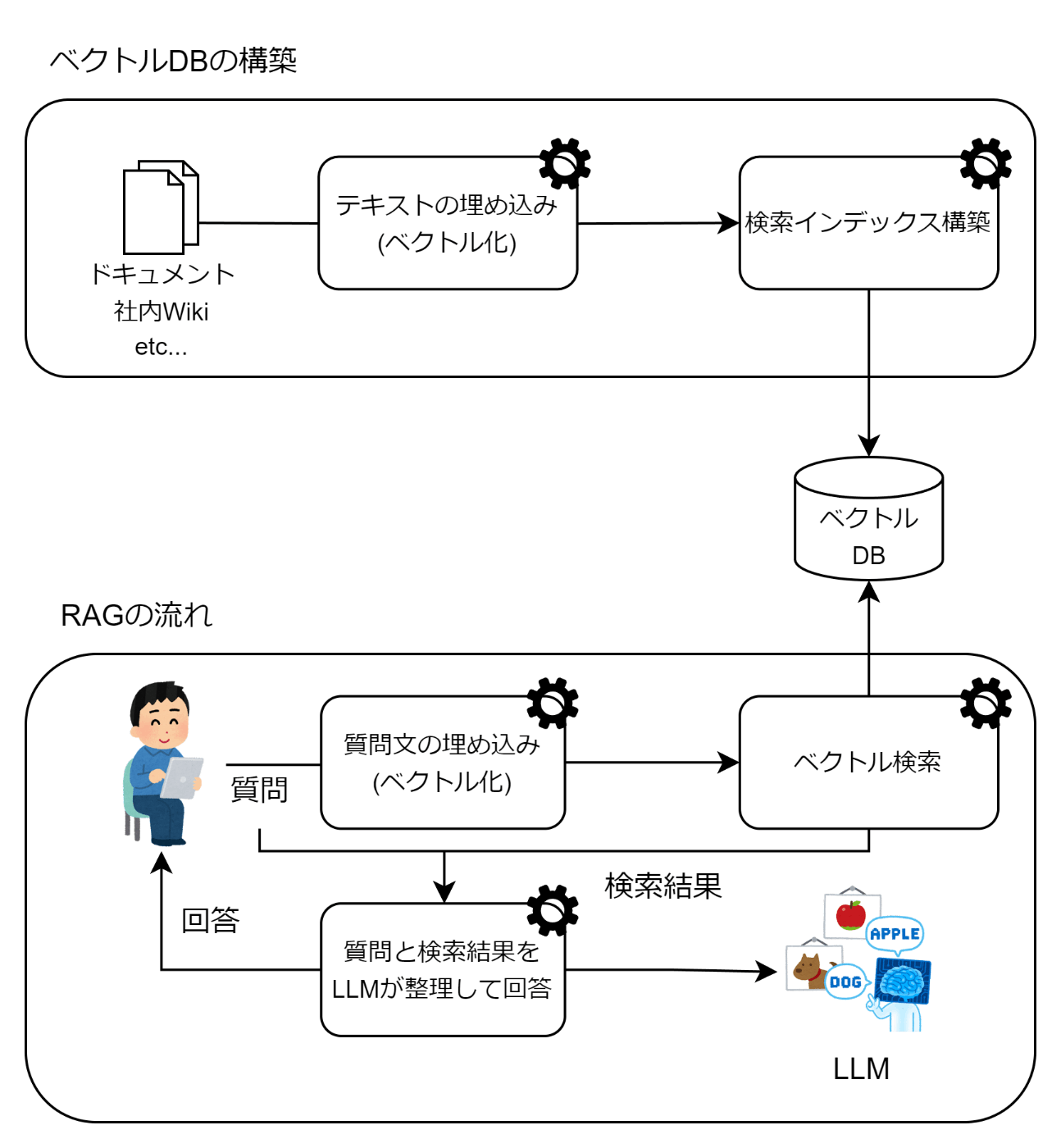
RAG を活用することで、最新の情報についても回答を得ることができます。
LangChainについて
RAGを実現する方法として、LangChainがあります。LangChain は、LLMを用いてアプリケーションを効率よく開発するためのフレームワークです。
文章の要約や質問に対する回答などの単純なタスクは従来どおりOpenAIが提供するChatGPTのAPI利用で事足りますが、それらのタスクを複雑に組み合わせる場合、LangChain は様々な機能を提供しているので開発が容易になります。
ベクトル検索について
ベクトル検索は、データを数値のベクトルで表現したベクトル空間モデル(ベクトルの各次元は単語やトピックなどの特定の要素を表し、その組み合わせによって文書全体を表現した空間)を使用して、データの類似性を計算し、関連するデータを見つける検索手法です。
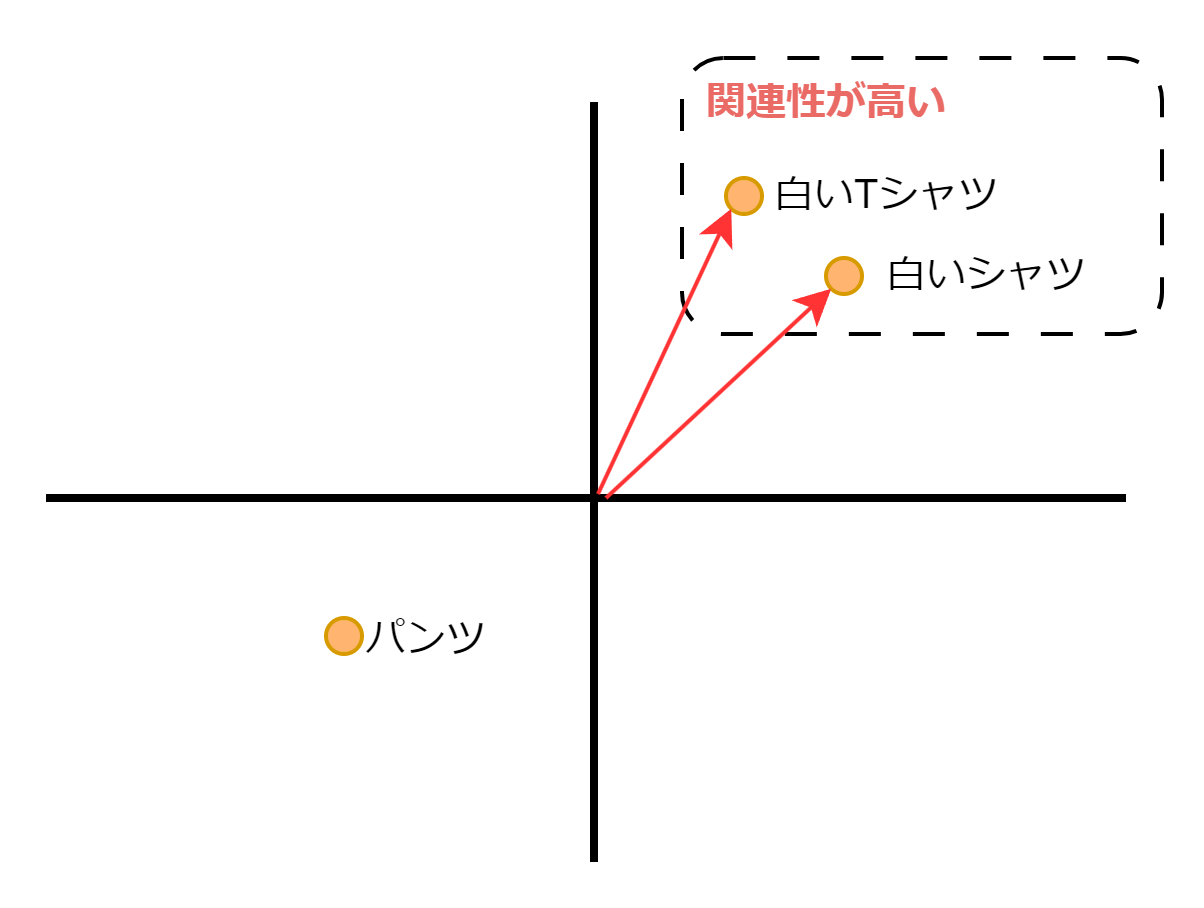
ベクトルの類似性を測る方法はいくつかあります。
- コサイン類似度
- ユークリッド距離
- 内積
ベクトルデーターベースごとに提供の有無はありますが、大体利用できるはずです。今回は、 コサイン類似度 を利用します。
LangChain対応のベクトルデータベース
2023年12月時点で、LangChainが対応しているベクトルデータベースは65個ほどあります。
以下は、代表的なものです
- Pinecone
- Weaviate
- Qdrant
- Elasticsearch
- Vespa
- faiss
下記記事では、これらのベクトルデータベースの比較を行っています。それぞれのメリットやデメリットが様々な視点から記載されているので、選定の参考になるはずです。
今回は、Elasticsearchを利用しますが、別のベクトルデータベースを採用しても、実装の差分はLangChainが吸収してくれるので、ほとんど変わらないはずです。
実装
関連技術についての説明が終わったので、いよいよコードベースで実装の説明をします。
利用技術
- 言語:Python(v3.11)
- パッケージ管理:Poetry()
- チャットUIフレームワーク:gradio
- LLM:ChatGPT(v3.5)
- LLMアプリケーション開発フレームワーク:LangChain
- ベクトルデータベース:Elasticsearch(v8.11.1)
- コンテナ:Docker
実装の目次
以降の流れとしては、「Pythonの実行環境やElasticsearchの起動などの環境構築」、「Elasticsearchの検索インデックス作成」、「Q&Aチャットボットの作成」の順で紹介します。
環境構築
プロジェクトフォルダを作成
$ mkdir es-docs-qa
$ cd es-docs-qa
パッケージのインストール
次に、Poetryを使って必要なパッケージをインストールし、環境を構築します。
必要なパッケージは以下の通りです。
[tool.poetry]
name = "es-docs-qa"
version = "0.1.0"
description = ""
authors = [""]
readme = "README.md"
[tool.poetry.dependencies]
python = "^3.11"
pydantic = "1.10.13"
langchain = "0.0.331"
beautifulsoup4 = "4.12.2"
unstructured = "0.10.28"
tiktoken = "^0.5.1"
python-decouple = "^3.8"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
これらをインストールします。
$ poetry install
利用パッケージの紹介
今回利用するパッケージについて紹介します
- pydantic:Pythonで型ヒントや型指定を扱えるようにするためのライブラリです。最近v2がリリースされ、処理速度が高速になりましたが、今回はv1を利用します。
- langchain:LangChainをPythonで扱うためのライブラリです。
- beautifulsoup4:Elasticsearchの公式ドキュメントはHTMLファイルなので情報をパースするために利用します。
- unstructured:LangChainでHTMLファイルを読み込むために利用します。
- tiktoken:OpenAIのトークナイザーを利用できます。
- python-decouple:環境変数を読み込むために利用します。python-dotenvよりもキレイに書けたりセキュアな書き方もできるので、個人的にこちらをよく利用します。
Elasticsearchの立ち上げ
プロジェクトフォルダにDockerfile.ymlとcompose.ymlを作成します
services:
build-es-docs:
container_name: build-es-docs
build:
context: .
volumes:
- ./src/assets:/usr/app/src/assets
elasticsearch:
container_name: elasticsearch-v8111
image: docker.elastic.co/elasticsearch/elasticsearch:8.11.1
ports:
- 9200:9200
environment:
- node.name=elasticsearch
- discovery.type=single-node
- "ES_JAVA_OPTS=-Xms4096m -Xmx4096m"
- xpack.security.enabled=false
- http.port=9200
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es-data:/usr/share/elasticsearch/data
kibana:
container_name: kibana-v8111
image: docker.elastic.co/kibana/kibana:8.11.1
environment:
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
ports:
- 5601:5601
volumes:
es-data: null
elasticsearchをシングルノードで立ち上げます。またindexの確認やElasticsearchの操作を簡単に行うためにkibanaも立ち上げました。
build-es-docsは、下記Dockerfileに具体的な動作を記載しています。
FROM debian:bookworm-slim
WORKDIR /usr/app/
# 依存関係のインストール
RUN apt-get update -qq \
&& apt-get install -y git \
&& rm -rf /var/lib/apt/lists/* \
&& apt-get clean
# ドキュメントのダウンロード
RUN git clone --filter=blob:none --sparse https://github.com/elastic/built-docs.git \
&& cd built-docs \
&& git sparse-checkout set ./raw/en/elasticsearch/reference/current
# ドキュメントのみをコピー
RUN mkdir -p /usr/app/src/assets
CMD cp ./built-docs/raw/en/elasticsearch/reference/current/*.html /usr/app/src/assets/
./src/assets/配下に最新のElasticsearch公式ドキュメントをダウンロードするためのだけに利用するコンテナです。
利用しているコマンドについては、下記記事で詳しく説明しているので、気になった方はご参照ください。
コンテナの構築と立ち上げを行います。
$ docker compose up -d --build
コンテナのステータスを確認
$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
elasticsearch-v8111 docker.elastic.co/elasticsearch/elasticsearch:8.11.1 "/bin/tini -- /usr/local/bin/docker-entrypoint.sh eswrapper" elasticsearch 15 seconds ago Up 13 seconds 0.0.0.0:9200->9200/tcp, 9300/tcp
kibana-v8111 docker.elastic.co/kibana/kibana:8.11.1 "/bin/tini -- /usr/local/bin/kibana-docker" kibana 15 seconds ago Up 13 seconds 0.0.0.0:5601->5601/tcp
elasticsearchとkibanaがupしていればokです。
また、./src/assets配下に複数のhtmlがあれば公式ドキュメントもダウンロードが成功です。
$ ls ./src/assets/ | head
_actions.html
_all_permission_check.html
_api_usage.html
_applying_a_policy_to_our_index.html
_client_jvm_check.html
_discovery_configuration_check.html
_early_access_check.html
_executing_searches.html
_explain_analyze.html
_file_descriptor_check.html
環境変数
.envを作成し、環境変数を記載します。
OPENAI_API_KEY=xxx
INDEX_NAME=es_docs
ELASTICSEARCH_HOST=http://localhost:9200
OPENAI_API_KEYには、OPENAIのAPIを扱うためのキーを記載してください。
未取得の方は、下記記事が参考になるはずです。
INDEX_NAMEはインデックス名、ELASTICSEARCH_HOSTはElasticsearchのホスト名を記載しています。
検索インデックスの用意
ドキュメントをチャンク分割
OpenAIのAPIをはじめ、各種LLMのAPIには1回のAPI呼び出しで処理できるトークンの上限が存在しています。それを越えると、例外として、以下のメッセージが返ってきます。
openai.error.InvalidRequestError: This model's maximum context length is 4097 tokens.
これを回避するために、ドキュメントをチャンク(かたまり)に分割します。
import glob
from langchain.docstore.document import Document
from langchain.document_loaders import BSHTMLLoader
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
def get_es_docs() -> list[Document]:
docs: list[Document] = []
files = glob.glob("./src/assets/*.html")
for file in files:
loader = BSHTMLLoader(file)
docs += text_splitter.split_documents(loader.load())
return docs
get_es_docsメソッドで./src/assets配下にある.html形式のドキュメントをBSHTMLLoaderで読み込み、チャンク分割を行っています。BSHTMLLoaderはLangChain用にbeautifulsoup4をラップしたものです。
チャンクはCharacterTextSplitterでchunk_size=500(上限500文字)と指定しています。chunk_overlapは、チャンクにまたがる文章をオーバーラップする文字数を指定できます。分割した前後で文脈がつながるようにしたいといったケースで利用します。
from decouple import config
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
# 環境変数読み込み
OPENAI_API_KEY = config("OPENAI_API_KEY")
INDEX_NAME = config("INDEX_NAME")
ELASTICSEARCH_HOST = config("ELASTICSEARCH_HOST")
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
vector_store = ElasticVectorSearch(
elasticsearch_url=ELASTICSEARCH_HOST,
index_name=INDEX_NAME,
embedding=embeddings
)
def create_index(vector_store: ElasticVectorSearch):
docs = get_es_docs()
print("=== add documents to index ===")
vector_store.add_documents(
docs,
bulk_kwargs={
"chunk_size": 500,
"max_chunk_bytes": 50000000,
}
)
if __name__ == "__main__":
create_index(vector_store)
create_indexメソッドでは、先程チャンク分割したドキュメントリストを使って、vector_store.add_documentsでそれらをElasticsearchにバルクインサート(Elasticsearchへ一度に送信するドキュメント数を500、最大バイトサイズを50MBで指定)します。
またその過程で、ドキュメントがベクトル化(エンベッティング)されます。エンベッティングはOpenAIが提供する機能を利用します。
embeddings = OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY)
デフォルトで使われているエンベッティングモデルは「text-embedding-ada-002」です。詳しくは下記記事をご参照ください。
インデックス作成
下記コマンドを実行すると、ドキュメントの読み込みやチャンク分割、インデックス作成が行われます。
$ poetry run python ./src/setting.py
作成したインデックスの確認
作成したes_docsインデックスをKibanaで確認します。
ローカルKibanaにアクセス:http://localhost:5601/app/dev_tools
GET /es_docs/_search
{
"size": 3,
"query": {"match_all": {}}
}
検索すると、下記のようにベクトルと対応するテキストや参照元が返ってきます。
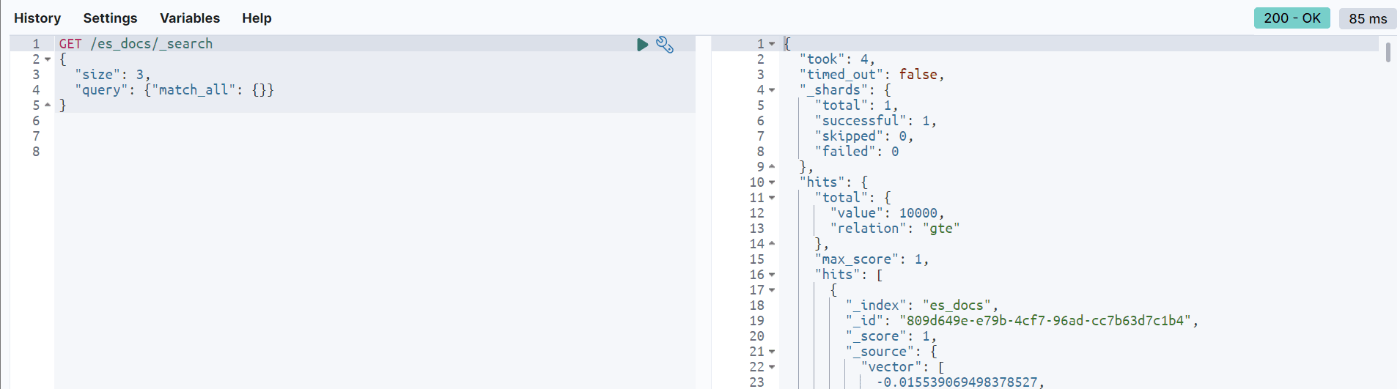
これで、ベクトルデータベースの準備は終わりました。
RAGの実装
ここからは、構築したベクトルデータベースを活用してRAGの実装を行います。
LLMの定義
定義したllmは至る所で利用するので、getメソッドで返せるようにします。
from langchain.chat_models import ChatOpenAI
def get_llm() -> ChatOpenAI:
return ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0, openai_api_key=OPENAI_API_KEY)
ベクトルデータベースの接続
chatメソッドでは、先程定義したLLMのモデルを使って、ベクトルデータベースとの連携を定義します。
from langchain import agents
from langchain.chains import VectorDBQAWithSourcesChain
def chat(message: str) -> str:
llm = setting.get_llm()
qa = VectorDBQAWithSourcesChain.from_chain_type(llm, chain_type="map_reduce", vectorstore=setting.get_vector_store())
LLMとベクトルデータベースの連携
次に、LangChainのAgentとToolsを定義します。この定義は、LLMとベクトルデータベースの連携の要になります。
Agentは、ユーザが指示したことを達成するために「思考→行動→観察」を行ってくれるまさにロボットのような機能です。入力テキストの内容に応じてどのToolを使えばよいかを考えてくれます。
そしてそのToolは今回の場合、上記のコードで定義した、「LLM(GPT)」と「ベクトルデータベース(Elasticsearch)」となります。
Toolには、nameとdescriptionを指定することで、Agentはこの内容を元にどのToolを使えばよいか判断します。また、これらは英語で記載したほうが誤作動が少ないようですが、LLMの精度が上がると改善されるかもしれません。
from langchain import agents
from langchain.agents import AgentType, Tool
def chat(message: str) -> str:
...
tools = [
Tool(
name="elasticsearch_searcher",
func=qa,
description="useful for when you need to answer questions about the most recent elasticsearch knowledge."
)
]
agent = agents.initialize_agent(tools, llm=llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
プロンプトテンプレートの定義
次に、LangChainのPromptTemplateを定義します。PromptTempleteはLLMに入力する質問文や回答文のフォーマット(プロンプト)のテンプレートを生成するための機能です。この定義によって、毎回同じフォーマットで回答を得ることができます。
下記のコードでは非常にシンプルなフォーマットにしていますが、その他、複数の入力を受け付けるテンプレートやチャットボットのようなフォーマットで出力するような定義も可能です。
from langchain.prompts import PromptTemplate
def _get_question_prompt(text: str) -> str:
translate_template = """
下記の質問に日本語で答えてください。また、参照元についても教えて下さい。
質問:{question}
回答:
"""
prompt = PromptTemplate(
input_variables=["question"],
template=translate_template,
)
return prompt.format(question=text)
最後に、message(質問文章)がプロンプトとして定義したフォーマットでAgentに渡されます。その後、AgentはToolsで定義されたLLMとベクトル検索を使い分けて、最終的な回答を生成するという処理が実行されます。
def chat(message: str) -> str:
...
question = _get_question_prompt(message)
answer = agent.run(question)
return answer
Q&Aチャットボットの実装
ここまでで、チャットボットのコアなロジック(RAG)が実装できたので、次は、UIを作成し、それらのロジックとつなぎ込みを行います。
今回は、「Gradio」というWeb UIを簡単に構築できるPython製ライブラリを使います。
例えば、ChatGPTのようなチャット形式のUIも数行で構築できてしまうので、簡単なデモレベルであれば十分に利用できます。ただ、UIの細かな調整は難しいのであくまでもデモレベルであればと言う感じです。
import gradio as gr
import chatbot_engine
# チャットのコアロジックと連携
def respond(message, chat_history):
bot_message = chatbot_engine.chat(message)
chat_history.append((message, bot_message))
return "", chat_history
# gradioの設定
with gr.Blocks() as demo:
# チャット表示用の画面
chatbot = gr.Chatbot()
# 入力用のテキストフィールド
msg = gr.Textbox()
# 初期化ボタン
clear = gr.Button("Clear")
# メッセージの送信時のアクション
msg.submit(respond, [msg, chatbot], [msg, chatbot])
# 入力したテキストやこれまでのチャットをクリア
clear.click(lambda: None, None, chatbot, queue=False)
if __name__ == "__main__":
demo.launch()
今回は、下記のUIコンポーネントを用意しました。
- チャット表示画面
- チャット入力用のテキストボックス
- チャットの初期化ボタン
これらが数行で用意できてしまいます。便利ですね
Gradioの起動
下記コマンドを実行すると、Webサーバーが起動します。
$ poetry run python ./src/main.py
下記URLでアクセスできます。
簡素ですが、これでChatGPTのようにチャット形式でQ&Aができるようになりました。
動作確認
下記メッセージを入力してみます。
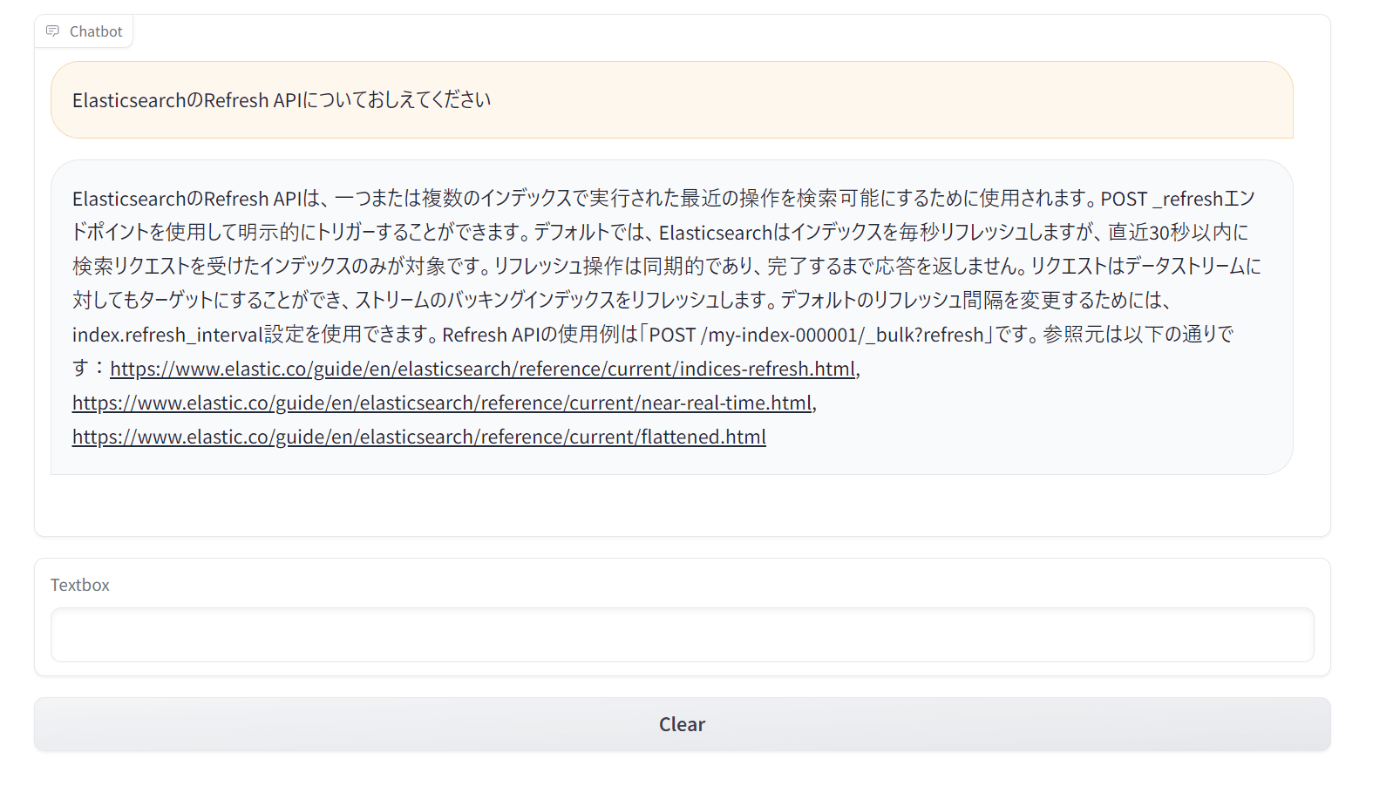
ElasticsearchのRefresh APIについておしえてください
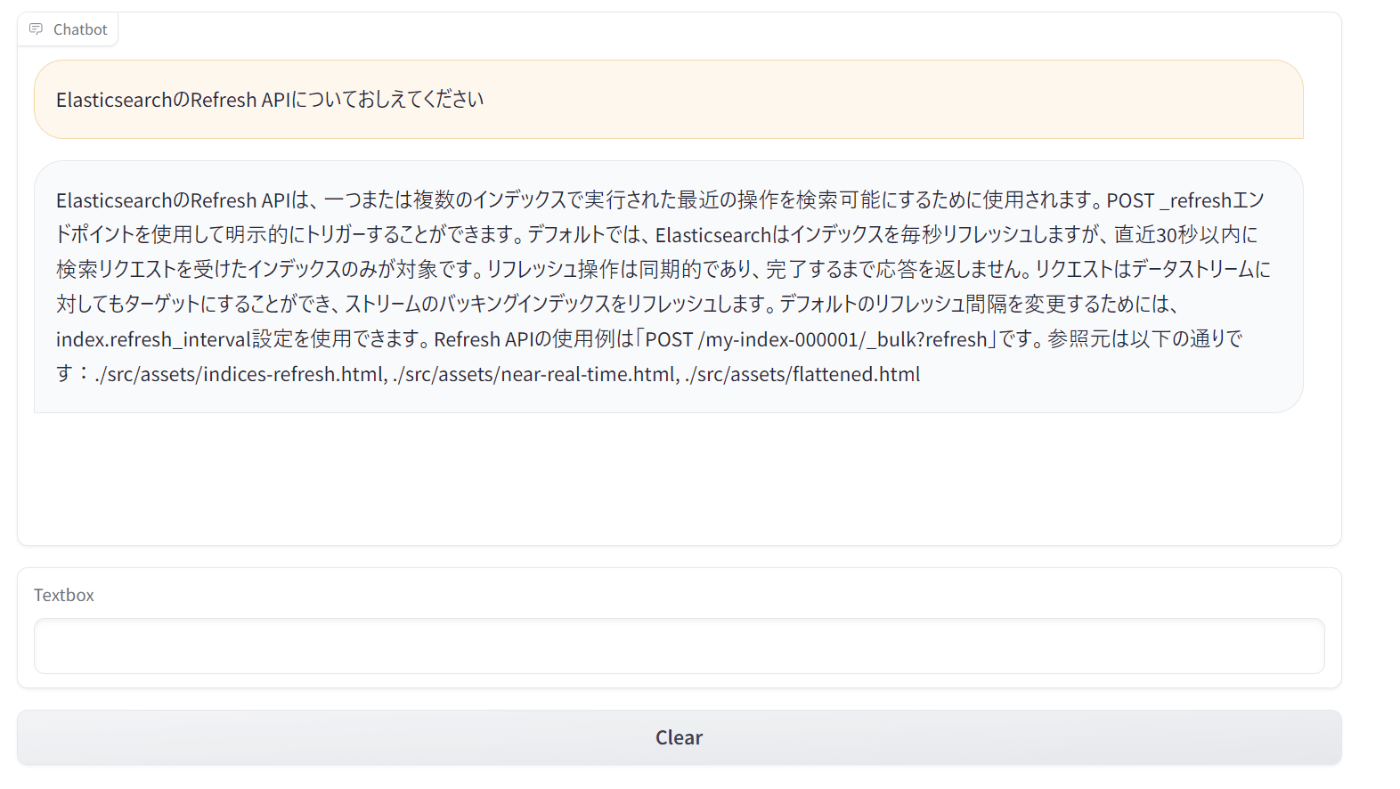
参照元付きで、Refresh APIについての回答が得られました。
また、出力されるログを見てみると、質問文に関連するRefresh API関連のドキュメントが記載されていることからRAGもうまく行われていることがわかります。
Prompt after formatting:
Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text verbatim.
Refresh API | Elasticsearch Guide [8.11] | Elastic
Elastic Docs
›Elasticsearch Guide [8.11]
›REST APIs
›Index APIs
« Open index API
Resolve index API »
Refresh APIedit
A refresh makes recent operations performed on one or more indices available for
search. For data streams, the API runs the refresh operation on the stream’s
backing indices. For more information about the refresh operation, see
Near real-time search.
Question: Elasticsearch Refresh API
Relevant text, if any:
Prompt after formatting:
Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text verbatim.
In Elasticsearch, this process of writing and opening a new segment is called a refresh. A refresh makes all operations performed on an index since the last refresh available for search. You can control refreshes through the following means:
Waiting for the refresh interval
Setting the ?refresh option
Using the Refresh API to explicitly complete a refresh (POST _refresh)
Question: Elasticsearch Refresh API
Relevant text, if any:
Prompt after formatting:
Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text verbatim.
Use the refresh API to explicitly make all operations performed on one or more
indices since the last refresh available for search.
If the request targets a data stream, it refreshes the stream’s backing indices.
By default, Elasticsearch periodically refreshes indices every second, but only on
indices that have received one search request or more in the last 30 seconds.
You can change this default interval
using the index.refresh_interval setting.
Refresh requests are synchronous and do not return a response until the
refresh operation completes.
Question: Elasticsearch Refresh API
Relevant text, if any:
Prompt after formatting:
Use the following portion of a long document to see if any of the text is relevant to answer the question.
Return any relevant text verbatim.
POST /my-index-000001/_bulk?refresh
{"index":{}}
{"title":"Something really urgent","labels":{"priority":"urgent","release":["v1.2.5","v1.3.0"],"timestamp":{"created":1541458026,"closed":1541457010}}}
{"index":{}}
{"title":"Somewhat less urgent","labels":{"priority":"high","release":["v1.3.0"],"timestamp":{"created":1541458026,"closed":1541457010}}}
{"index":{}}
{"title":"Not urgent","labels":{"priority":"low","release":["v1.2.0"],"timestamp":{"created":1541458026,"closed":1541457010}}}
Question: Elasticsearch Refresh API
Relevant text, if any:
> Finished chain.
最新の情報を元に回答が得られるか確認
冒頭でChatGPTの問題として挙げていた質問の回答が得られるか確認します。
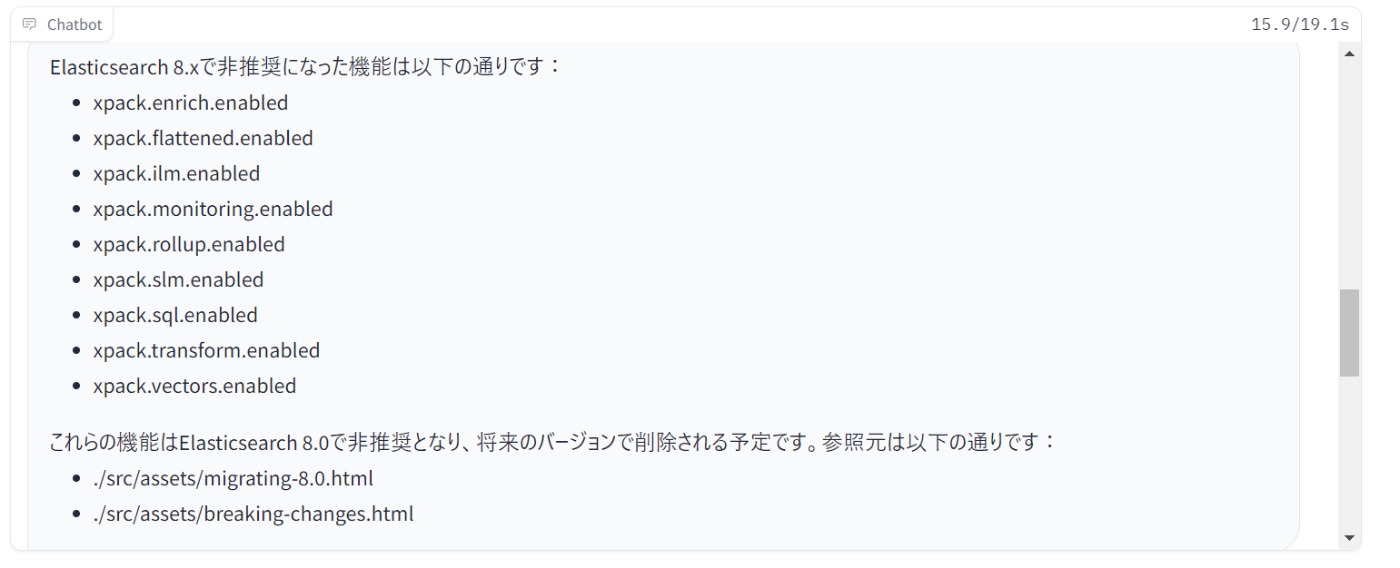
Elasticsearchの非推奨の機能を教えて下さい
ChatGPTでは、内包するデータが2021年以前のもので、曖昧な結果が返ってきました。
一方で、今回の場合はElasticsearch8系の非推奨事項が返ってきました。バージョン8のリリース日は2022/02/11なので、GPT3.5に含まれない情報です。目的だった最新の情報を元にしたQ&Aを実現できたことがわかります。
おまけ
バックログの出力
下記コードを記載することで、ステップごとにどのような処理が行われているかがログとして出力されるので、デバック時に利用すると便利です。
import langchain
langchain.verbose = True
参照元パスを公式ドキュメントのリンクに変更
参照元のパスをElasticsearch公式ドキュメントのホストとパスに変えれば、たどりやすくなります。
具体的には、./src/assets/→https://www.elastic.co/guide/en/elasticsearch/reference/current/に置き換える処理を追加しています。
def _from_path_to_es_url(text: str) -> str:
return text.replace("./src/assets/", "https://www.elastic.co/guide/en/elasticsearch/reference/current/")
def chat(message: str) -> str:
...
return _from_path_to_es_url(answer)
回答が下記のように変化しました。
また、プログラム上で処理しなくてもプロンプトテンプレートでパスの変換も指示すれば同様のことができるかもしれません。
おわりに
最新のElasticsearchの公式ドキュメントの内容を元にQ&Aを行うチャットボット作成し、その実装方法や利用している技術のLLM、LangChain、RAGについて紹介しました。
今回はHTMLを読み込みベクトル化しましたが、LangChainではPDFやmarkdownなど様々なファイル形式に対応しているので、ユースケースに合わせて少量のコード変更で対応できます。
また、回答の精度は改善点が多々あり、例えばデータの前処理をやっていなかったりチャンクサイズもデフォルトのものを利用しているので、これらをチューニングすることで改善が見込めるはずです。このあたりの知見が溜まったらまた記事にしたいと思います。
Discussion