This article was written as the Day 6 entry of the TimeTree Inc. Advent Calendar 2023.
If there was one topic during the last year in tech that nobody could escape from, it was AI and ChatGPT. So of course at TimeTree, we also looked at what the technology could do for us and our users.
Idea
When talking to users of TimeTree, one of the biggest issue is entering the appointments and events that you want to manage in the first place. Even if you are one of the diligent few that always keep their calendar up to date, that does not help much if your shared calendar partner forgets to put in their events properly and you end up with missed appointments and double bookings.
So we are always looking into ways into making the creation of events as fast and painless as possible. One such idea is is to allow users to take pictures of leaflets, schedules and so on and then have this photo "magically" turn into the desired event in their calendar, without any additional input required.

To stick with the theme of this article, this image was generated with DALL·E
The pre-AI approach would have been to extract the text on the client side using OCR and then use some form of pattern matching to extract event data which then can then be used to create appointments.
However when using ChatGPT, we should be able to just throw the OCR text to ChatGPT and have it extract schedule information for us!
Prompt
So before we did anything else we needed to create a proof of concept and see if we could get usable results.
We used the Chat Completion endpoint at POST https://api.openai.com/v1/chat/completions as described by the OpenAI documentation.
The following is a very basic prompt.
Your task is to extract schedule information from a given text string and
return it as a valid json object in the following form:
{
"title": "A concise even title",
"start_time": "A valid timestamp",
"end_time": "A valid timestamp"
}
Obey the following rules:
1. Assume the current time is Tue, 5th December 2023
2. Only return a single valid json object, no other text and no questions
asking for clarification
The given text:
Summer School Bash August, 12th, 10:00 - 12:00, Our beloved Summer School
Bash is back! Bring your family, bring your friends! Entry is $5.
Which in the above case yields the following result:
{
"title": "Summer School Bash",
"start_time": "2023-08-12T10:00:00",
"end_time": "2023-08-12T12:00:00"
}
We basically just tell ChatGPT to find an event in the provided text and return it as a json object. Note that this is a very abbreviated example and lots of prompt tuning is necessary. ChatGPT not only really wants to add some clarifying text to the answer really badly, there are also several caveats that have to be kept in mind:
- Time Even though ChatGPT can now look up the current time online if you use the new Assistant feature we want to avoid that to receive a faster response and keep costs down. If the current time is not provided, the timestamp will have the wrong year or information like "next Wednesday" will not be extracted right.
- Timezone You either need to pass the user's timezone or factor in the time zone difference into the resulting timestamp.
- Multiple Events The scanned image can contain information for more than one event. It is possible to slightly change the prompt to receive a list of JSON objects in stead, however this can severely increase the generation time as we will see later.
- Output language Unless instructed otherwise, ChatGPT tends to translate content into English, even if the prompt wasn't in English to begin with.
Privacy And Laws
People interested in reading this article obviously know about government actions against AI software in Italy or China for example. But there is also the issue of privacy in general. If you are going to send user provided information to the OpenAI servers, you probably need to update your privacy statements and make it clear to the users that using this functionality will send their data to the external OpenAI service.
Do you have users from Europe? Are you adhering to GDPR? Can you even offer this service to them?
At the time of writing of this article, we are offering this feature only to our Japanese user base.
Implementation and Release
Obviously we could not send the requests directly to ChatGPT since this
- would require storing the api access token on the client side
- does not allow us to centrally disable the functionality (for example in case of exploding costs or changes to the OpenAI TOS)
So we had to route the requests through our backend API servers. In summary the process looks like this:
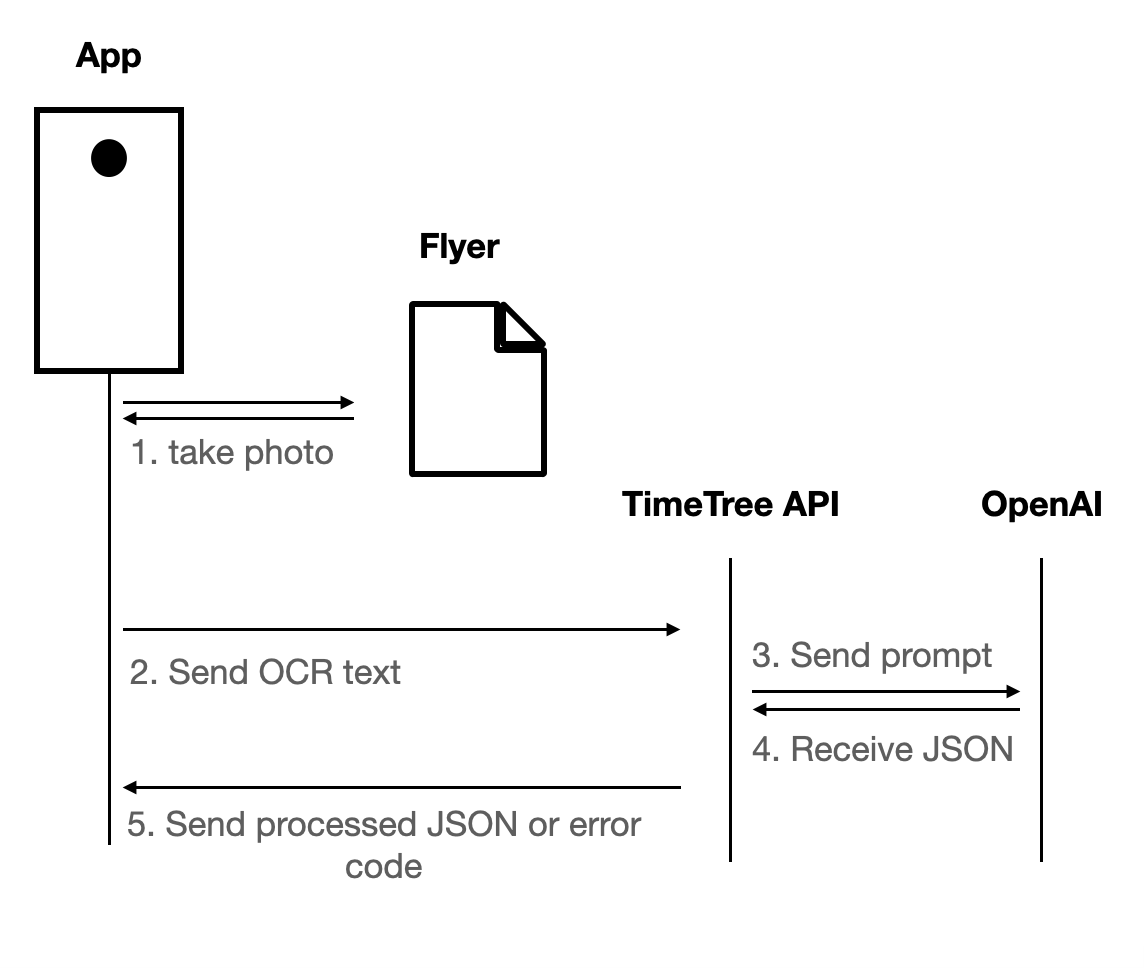
The results for our testing data looked promising, the result generation took a bit of time (around 6-8 seconds), but extracted schedules were mostly correct.
However, we noticed that a portion of the requests ran into our server side request timeout of 20s, so we increased the timeout to 30s for this service. When we released it as a beta feature to some of our users, we soon noticed the following:
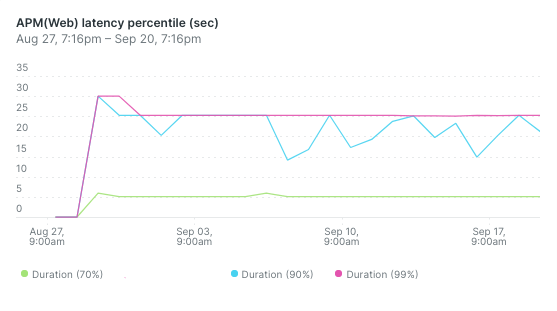
70% of requests are handled in under 6 seconds, but timeouts happen regularly
And 20-30% of users are experiencing server errors!
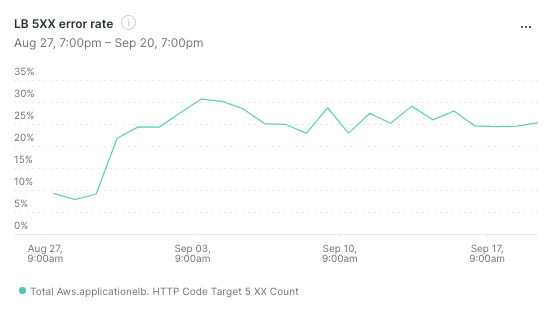
Percentage of requests leading to a 5xx error
A keen observer will already have noticed that the timeout seems to be 25s and not 30s. 25s is the time we are willing to wait for ChatGPT to generate a reply after we sent them our chat completion request. Our timeout settings for Ruby's Net::HTTP library at the time:
TIMEOUT_OPEN = 3.seconds
TIMEOUT_WRITE = 1.seconds
TIMEOUT_READ = 25.seconds
The dominant 25s indicated that we mostly failed while waiting for an OpenAI server response (which we also confirmed in our sentry logging).
But why did the response generation take so much longer than our testing indicated?
Problems in execution time
While we neither have the time to go into the specifics of how ChatGPT works (nor am I qualified to talk about it), at its most basic, the result generation process for text completion looks like this:
- Turn input into a list of Tokens (Can be single letters, groups of letters and even words)
- Predict the most likely token to follow the given list.
- Add the new token to list and if no end condition is reached, repeat from 2.
- Return all new tokens as the new completion.
Essentially this means, that the execution time will scale linearly with the amount of text generated. So the more text is generated, the longer it will take.
In the examples above, users scanned images with a lot of schedule information (concert tour list, school timetables, etc) and at the same time our (then latest) prompt version supported extraction of multiple events. So if the image contained four events, generating the response would take roughly four times longer assuming equal text length.
So how did we the tackle this problem?
- Increasing the timeout was not a solution for us. Waiting 25 seconds for a response is already uncomfortably long. In fact we reduced it to 20 seconds instead.
- Update our ChatGPT model from
gpt-3.5-turbo-0613togpt-3.5-turbo-16k-0613which seemed to have slightly faster response times while yielding better results - Changing our prompt to only return the first and most prominent event found in the given data. This is not an ideal solution, but in the short term it seemed better to give the user at least one result quickly instead of having them wait 25 seconds for an error message. With the current response speed of ChatGPT it is just not feasible to generate long replies without incurring unreasonably long wait times.
In our case, this solved our timeout issue and lead to a noticeable faster user experience.
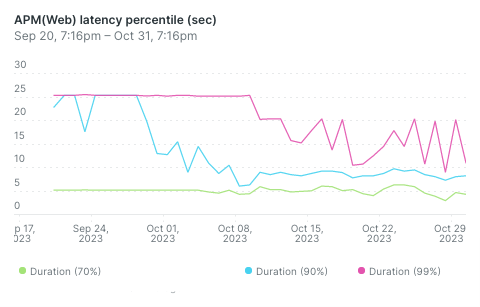
Very few requests fail
Only a handful of 5xx errors remain and these are caused by upstream issues on the OpenAI side.
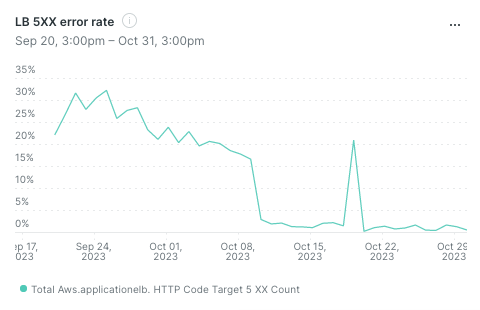
Very few requests fail
That spike around the 19th? OpenAI Server issues.
Where to go from here
With the recently released Assistants Beta, you can ask ChatGPT questions about images. Obviously this means we could skip the OCR part and just send the image directly. Since this requires using a ChatGPT-4 model, this is also means that the cost per request is going to increase substantially.
In the meantime we are going to update to the latest model (gpt-3.5-turbo-1106) which offers a JSON mode and promises to better obey the prompt.
TimeTree is Recruiting
If you are interested in working for TimeTree, please visit our Company Deck and Careers pages!
Company Deck(Introducing our Company)
TimeTree Recruitment page

TimeTreeのエンジニアによる記事です。メンバーのインタビューはこちらで発信中! note.com/timetree_inc/m/m4735531db852
Discussion