[週次報告] 第5回 Team JINIAC (4月25日)



1. 開発テーマ・概要
記載者: 中村 仁
-
本プロジェクトでは、日本語の特性を適切に捉えられる大規模言語モデル(LLM)の開発を目指します。
-
この目標達成に向けて、以下の3つの領域に対し、重点的に注力しております。
-
データセット
- 良質な日本語データセットの構築が日本語理解の質を大きく左右する。
- 本プロジェクトでは以下のデータを収集し、最適化を図る。
- 政府文書
- 国会答弁
- 学術論文
- 知識転移を見据えた独自データセット
- ヒンディー語
- 政府文書
-
モデル構造
- Mixtures of Experts(MoE)を活用する。
- Mamba等を活用したMoEについての検討も行う。
-
学習手法
- データの学習順序の変更等の導入により、モデルの理解力向上を目指す。
-
データセット
-
加えて、以下のプロジェクト運営面での工夫も行っています。
- トップダウンとボトムアップの両立
- Notionを活用したプロジェクト管理の最適化
- チームメンバーの心理的安全性の確保
- コミュニケーションの活性化
-
プロジェクトの目標を達成できれば、以下の成果が期待できると考えています。
- チームメンバーによる共同執筆での論文発表
- NoteやGitHubを通じた積極的な情報公開とLLM人材の育成
-
日本が世界に誇れるAI技術を持つためには、日本語の豊かな表現を捉えられるLLMの実現が不可欠です。
-
本プロジェクトはその実現に向け、全力を尽くしてまいります。
2. チーム全体の開発状況
記載者: 中村 仁
-
チーム組成が完了し、各サブチームにおける本格的な開発が開始しました。
-
経済産業省・NEDOにより「本番環境」が提供されるまでの期間に提供される「プレ環境」において、大規模モデル開発開始のための準備を進めて参りました。
- データ班により、従来のデータセットよりも高品質なデータセットが準備されつつあります。
- モデル班により、モデルの選定と実装、シングルノードでの実行確認が行われました。
- 学習班により、インフラ周りのセッティングを行われました。
-
2024年4月22日(月)経済産業省・NEDOにより「本番環境」が提供されました。
- 本番環境の時間を無駄にしないため、「本番環境」提供後の3~4日間については次の方針を定めました。
-
標準コードの事前学習を実行する
- 概要
- データチーム、モデルチーム、学習チームからの少人数の「遊撃隊」を組成し、松尾研から提供されている「標準コード」を事前学習させる
- 期間
- 4月22日(月)~ 4月25日(木)
- 延長の可能性あり
- 目的
- 「プレ環境」において行うことができなったマルチノードでの実行を確認する必要があるため
- 標準コードを学習させておくことで、本命のMoEにおける学習がうまくいかなかった際、継続事前学習を実行するセーフティネットとしての活用できるようにしておくため
- Google Cloudの特性を把握し、本線での学習をスムーズに行うための知見を収集するため
- 流れ
- 本番環境へのログイン、実行までの手順の確認
- 標準コード実行のための環境構築
- 標準コード学習に必要なデータの転送
- 実行確認後のモデルのHuggingfaceへのアップロード
- 概要
-
標準コードの事前学習の後、MoEの事前学習を実行する
- モデルをDeepSeekMoEに定め、4月25日(木)までを目標として実装中
- 終わり次第、実行
-
標準コードの事前学習を実行する
- 本番環境の時間を無駄にしないため、「本番環境」提供後の3~4日間については次の方針を定めました。
-
wandb等、学習をモニタリングするツール等についての勉強会や、トークナイザーに関する勉強会も行っています。その他、有志での勉強会や調査会も行われています。
- GitHub等の準備についても順調に進んでおり、安定した開発を行えるよう準備中です。
- wandbとSlackの連帯等、本番環境のメンテナンス対応についても同時に進行中です。
-
現在行うべき課題については順調に対処できていますが、モデルの実装に遅れがみられているため、標準コードの事前学習を少し長引かせる等で対処して参りたいと考えています。
-
開発とは別に、各サブチームにおける活動をサポートし、チーム全体としての調整をする活動も行っています。
- 次のマネジメントチームの発足させました。
- 情報調査チーム
- 情報収集、情報分析、情報の可視化
- 外務チーム
- 情報の発信、文書の公開範囲設定
- 内務チーム
- チーム内の方(及びチームへ加入される予定の方)に対するマネジメント、勉強会の調整
- 情報調査チーム
- 次のマネジメントチームの発足させました。
-
マネジメントチームにより、Notionにおける情報管理や、コミュニティメンバーの加入についてのフローがほぼ確立しました。
- 新しいメンバー4名の受け入れやについても順調に進み、40名ほどのメンバーが各々の興味に基づいて開発できる環境の整備を進めています。
-
新しいメンバー4名の受け入れやについても順調に進み、内部での調整や、外部との連絡についても順調に進んでいます。
- ヒンディー語のデータセット構築の際には、大阪大学大学院人文学研究科の虫賀幹華先生によるご協力を賜りつつ、構築を進めています。
-
スケジュール:
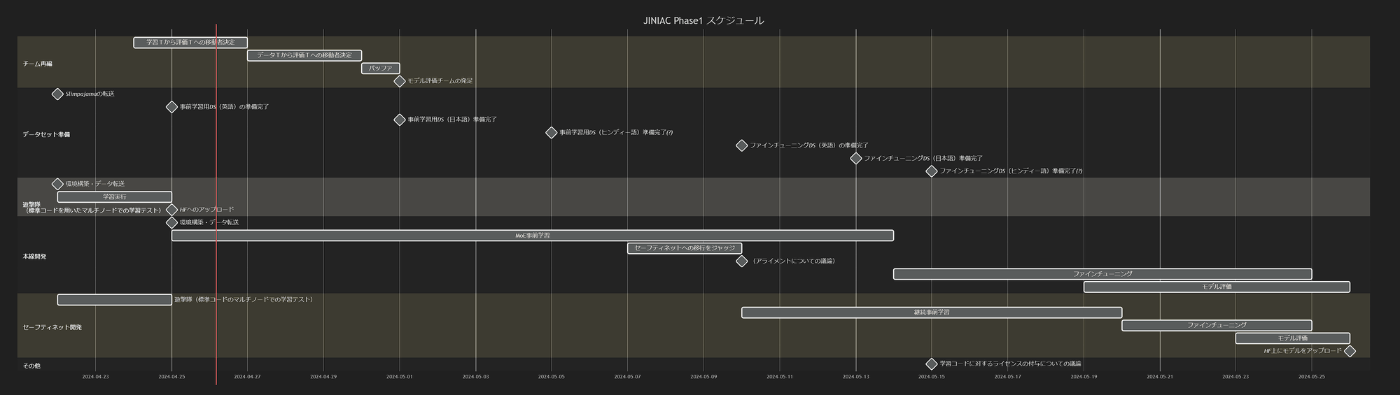
3. サブチームからの情報共有
3.1 データ班
記載者: y_morinaga, 佐野敏幸
3.1.1 やったこと
- CulturaX,slimpajamaを中心に,wikiや国会議事録さらにヒンディーのデータをプレ環境の共有領域に準備し、slimpajamaを本番環境へ移行させた
- CulturaXに個人情報が含まれていたため、hojicharでフィルタリング
- ヒンディー語データセットを外部有識者(大阪大学 虫賀幹華 助教)に確認いただき評価
3.1.2 分かったこと
- 開発環境のstrageが5TBで、モデルのチェックポイントの保存領域の確保を考えると、用意する予定のコードデータを含めると全て移行できない。学習が終わったデータを削除する必要がある。
- フィルタリングを行いたいデータがあるが、開発環境は学習優先のため、使用できないので、他の方法を検討する必要あり
- ヒンディーのデータを学習に使用するかはディスカッションが必要
- ヒンディー語データセット8個それぞれの品質
3.1.3 次やること
- Slimpajama以外の事前学習用データの本番環境への移行
- 事後学習用データの準備
- コードデータのフィルタリング、移行
- 北九州市のデータ、HuggingFaceFW/finewebなど品質が高いデータを事前学習用に準備
- ヒンディー語データセットのうち良質なものの選択
3.2 学習・コード班
記載者: @Shoji Iwanaga
3.2.1 やったこと
- モデル班に対するメンバーの応援および補助
- WandBのアラートを導入
- トークナイザーの語彙数調査
3.2.2 分かったこと
- データセットチームから学習チームへのデータの受け渡し方法をjsonl形式に指定
- トークナイザーの語彙数調査
- 32000以上の語彙数で、学習速度に5%程度の影響あり
- 推論速度は影響ない
- WandBのアラート
- Runがクラッシュした場合にSlackへアラートが飛ぶようになった
- Lossを監視し、アラートを出せるように今後実装を重ねる
3.2.3 次やること
- モデル評価班を発足
- ファインチューニング手法に関する調査、実装
- WandBのアラート管理
- プロジェクト管理用ページの作成
3.3 モデル班
記載者: @菊池満帆 @尽誠 白石
3.3.1 やったこと
- 条件⓵:1node8GPUにて2×300millionで学習させた(deepspeed zero stage3を使用)
- 条件②:1node8GPUにて4×300millionで学習させた(deepspeed zero stage3を使用)
3.3.2 分かったこと
- 条件⓵でGPUメモリの占有率はギリギリ
- 条件②ではOOM
3.3.3 次やること
- 本番環境が始まる前までに、deepseekmoeのgatingの実装を試みる(間に合えば本番環境に組み込む)
- 本番環境では、まず標準コード1~2日で立ち上げ動作確認し、その後deepseekmoeモデルを実行する
- ハイパーパラメータは、モデルの論文を参考にしながら、学習班と共同し決めていく。
4. ディスカッション
- 特になし
5. 開発のマイルストーン
<主要なマイルストーンと現在地について記入>
-
データ準備
記載者: @morikoromori(y_morinaga)
- 事前学習
- データとして以下のデータを準備
-
日本語
CommonCrawlPDFJa
japanese2010
wikipedia-20240101
CulturaX
国会議事録
法律データ
判例データ(ja)
青空文庫
Syosetu711K
-
英語
open-web-math
Slimpajama
JINIAC/en_wiki_20220301
loubnabnl/github-code-more-filtering(準備中)
-
ヒンディー
-
- 現在Slimpajamaを学習中
- 次の学習データに関して議論中
- データとして以下のデータを準備
- 事後学習
- 事後学習に必要なデータ量を見積もり
- 事後学習データセットに関してはメンバーが特色あるデータセットを各々用意しています.
- 事前学習
-
モデル学習コード準備
記載者: @尽誠 白石
- 本番開始直前に急遽DeepSeekMoEアーキテクチャを採用する方針に転換.急ピッチで実装を進めた.
- pretrainのためのGithubリポジトリの整備を進めて,円滑に事前学習ができるよう準備している.
- セーフティネットとして標準コードもMoEの前に実行,ハイパラ調整やRoPEの検討などを行う.
-
シングルGPUでの稼働確認、実績
記載者: @尽誠 白石
- MoE
- mixtralについて,小規模のものはプレ環境で動くことを確認した.
- DeepSeekMoEの実装・学習に失敗した場合に用いる可能性がある.
- DeepSeekMoEは,本番環境において1.5B程度のものの動作はひとまず確認できた.あとは,うまくスケールできるよう調整を加える.
- mixtralについて,小規模のものはプレ環境で動くことを確認した.
- 標準コード
- プレ環境では、トークナイザーの語彙数による性能の違いを評価
- 本番環境では、モデルサイズアップ、バッチサイズの調整、最適なCPU数の探索などを実施中
- MoE
-
マルチノードでの稼働確認、実績
記載者: 堀江
- プレ環境では,マルチノードでの検証は行なっていない.
- 本番環境では、実施に向けた環境構築中
-
うまくいきそうか計画の確信度
- 計画・準備は順調だが、達成への不確実性は依然として高い
6.その他
特になし
7.直近1週間でやったこと
記載者: 中村 仁
- 国会答弁や学術論文を含む高品質な日本語データセットを準備が進行中です。
- NEDOからご提供いただいた「本番環境」にて、標準コードを段階的にスケールさせる実験が進行中です。
- DeepSeekMoEの実装が進行中です。
Discussion