S3バケット上のファイル処理をLambdaとGlueをStepFunctionsで連携して作る
やること
AWSを使ってデータを加工する一連の流れを作ってみました。このような処理は定期的に実行することが一般的なので、日々増分するデータを処理できるようにしました。
構成図
構成図と、構成図に処理フローを追記するとこのようになります。
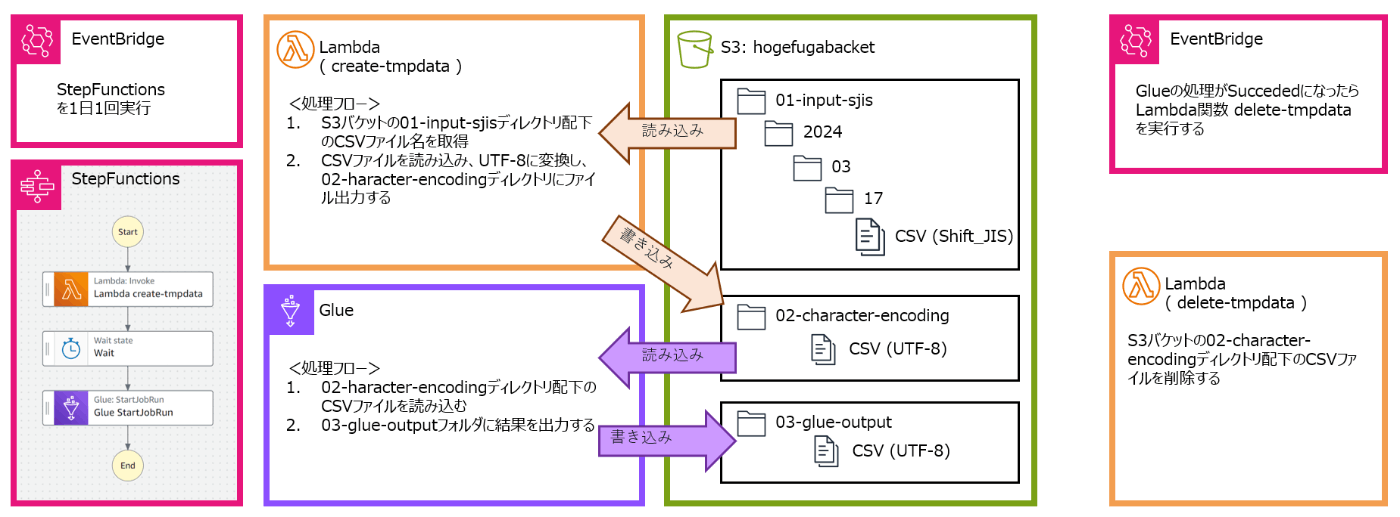
処理フロー概要
処理フローは、"データ加工"と"後かたづけ"の2つあります。
データ加工の処理フロー
LambdaとGlueでデータを加工します。
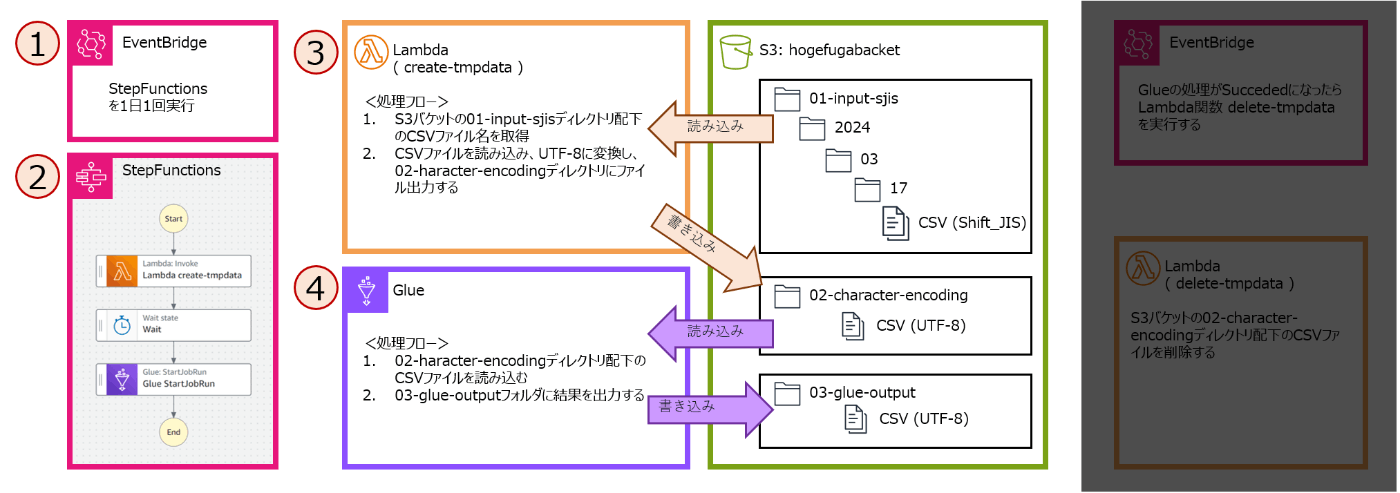
(1)EventBridge: 定期的(1日1回)にStepFunctionsを実行
(2)StepFunctions: データ加工のLambdaとGlueを順番に実行する
(3)Lambda: Glueが加工しやすいような中間データの作成
(4)Glue: データ加工。加工済みデータをS3に格納
後かたづけの処理フロー
Lambdaで不要になったデータを削除します。
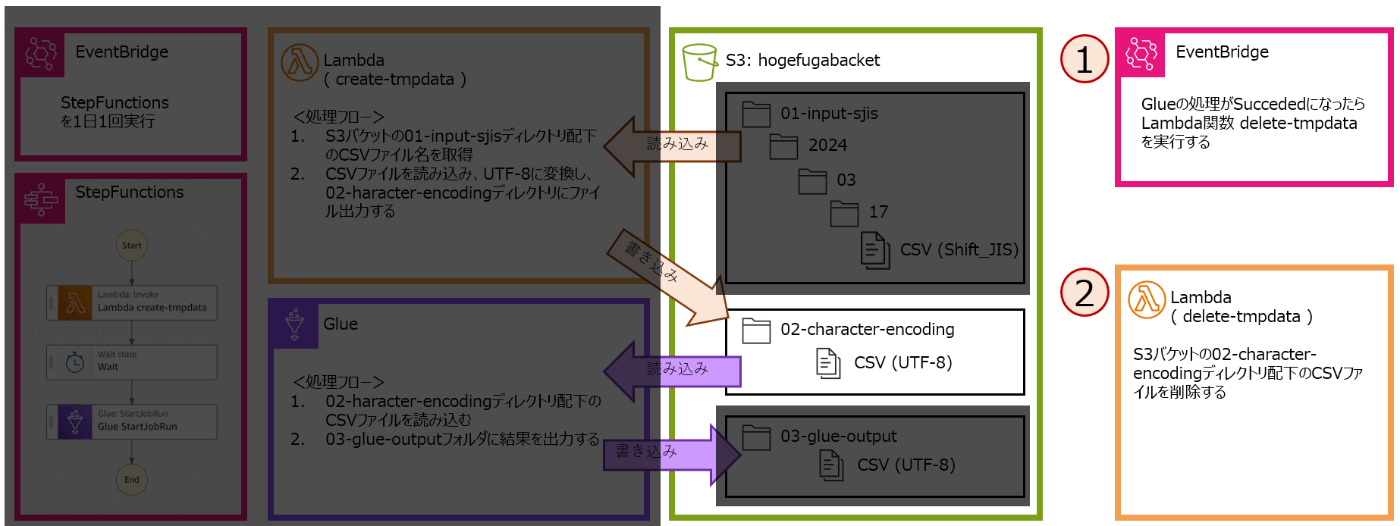
(1)EventBridge: Glueジョブが完了したことをトリガーにLambdaを実行
(2)Lambda: 中間データを削除。(中間データとは、02-character-encodingディレクトリ配下にあるCSVファイルのこと)
リソースごとの設定
構成図でしめした各AWSリソースの設定について書いていきます。
EventBridge
EventBridgeは2つあります。
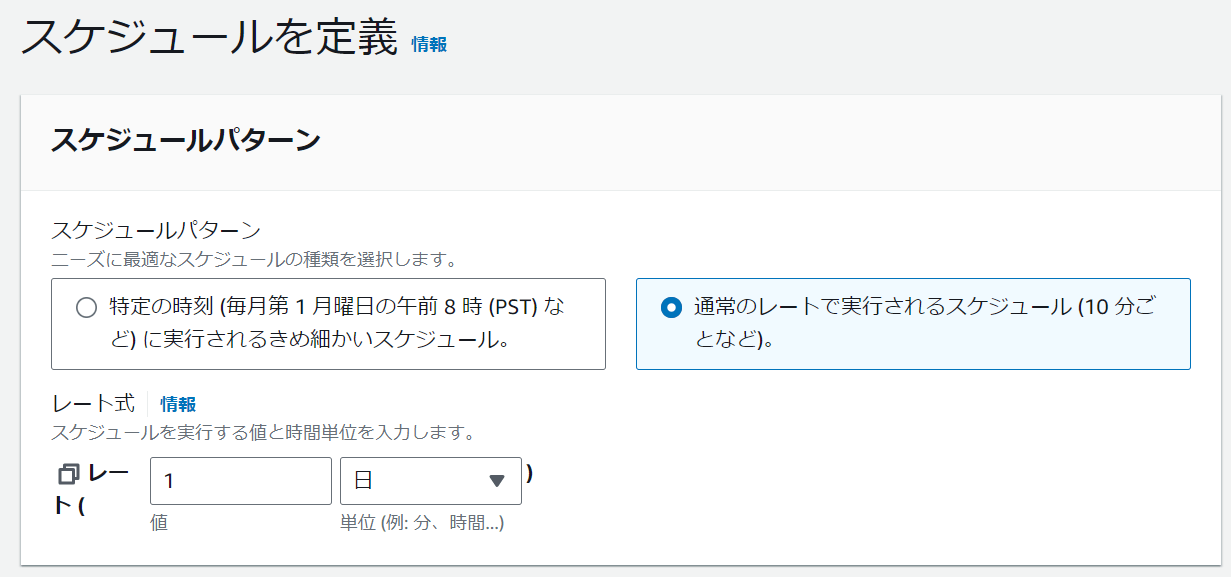
StepFunctionsを1日1回実行するEventBridge
このように1日1回実行するようにスケジュールを設定します。また、ターゲットはStepFunctionsのステートマシンを設定します。
Glue処理完了をトリガーにするEventBridge
Glueジョブの処理が成功したことをトリガーに実行するように設定します。
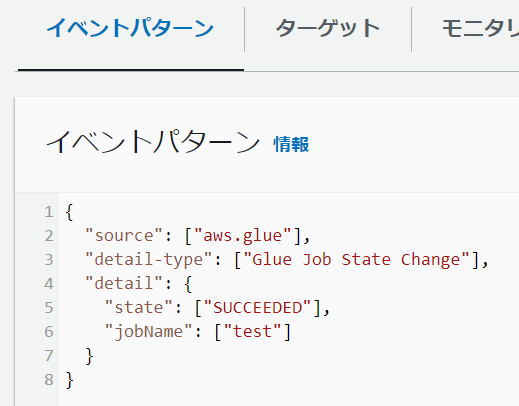
{
"source": ["aws.glue"],
"detail-type": ["Glue Job State Change"],
"detail": {
"state": ["SUCCEEDED"],
"jobName": ["test"]
}
}
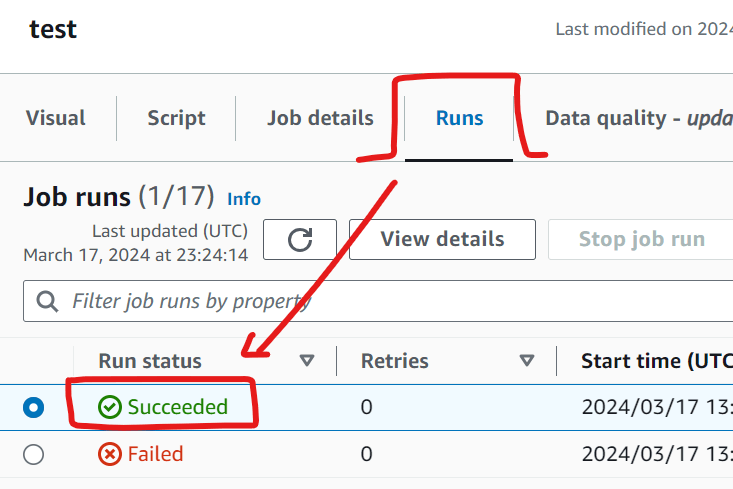
GlueジョブtestのステータスがSUCCEEDEDになったときがトリガーになるように設定しています。以下は、Glueの画面で実行結果の状態を表示しています。Glueジョブのステータスは、Run statusで確認できます。
このEventBridgeのターゲットは、"Glue処理後に不要データを削除するLambda関数"です。つまり、Glueジョブが完了した後に不要データを削除するような仕組みになっています。
StepFunctions
設定
StepFunctionsステートマシンを作り、Glue処理前のデータ加工をするLambdaとGlueを順番に実行できるようにします。
- Lambdaを実行するブロックの設定
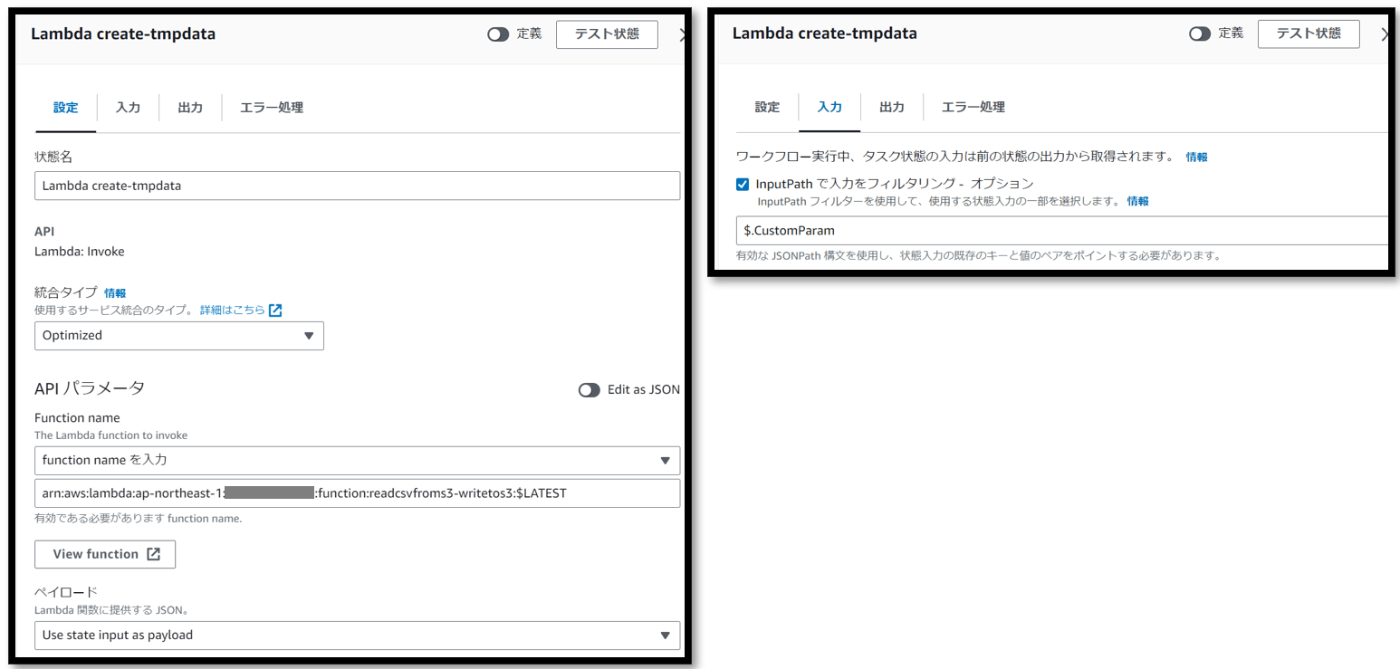
入力タブのところで$.CustomParamを設定します。この設定により、StepFunctionsステートマシン実行時に指定した入力パラメータの情報をLambdaに渡します。
- Glueジョブを実行するブロックの設定
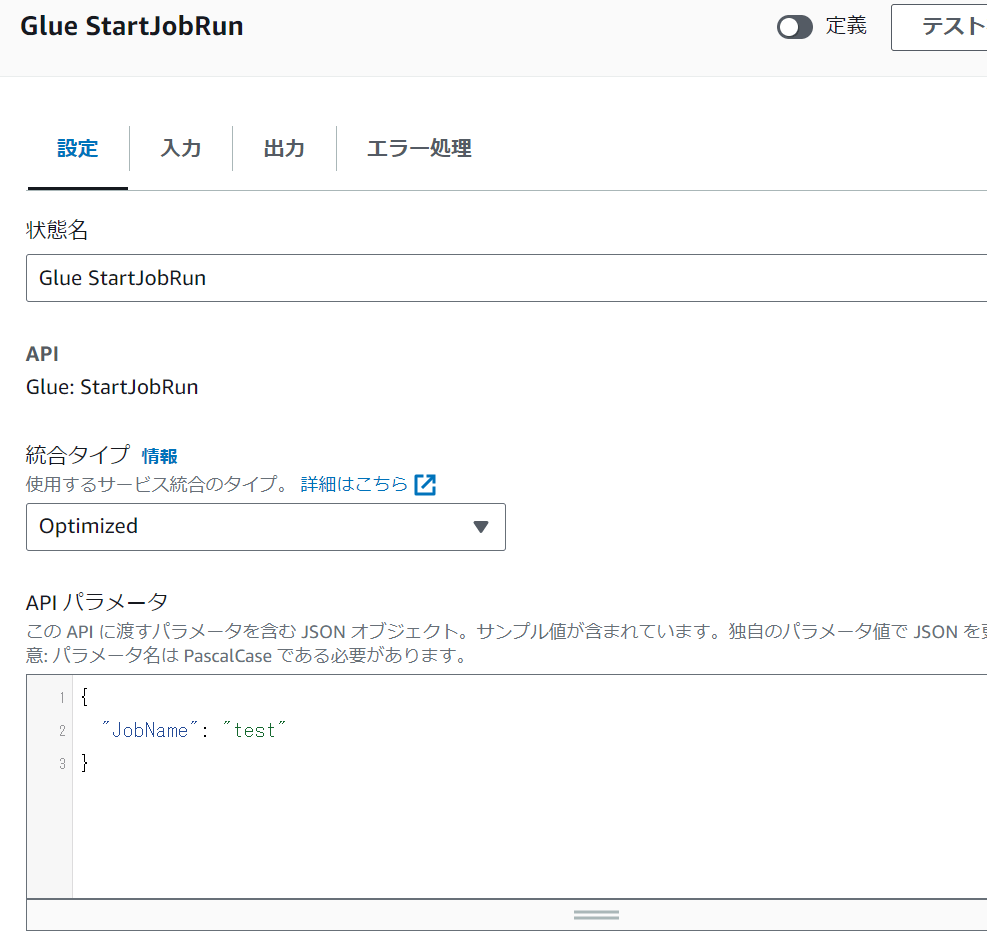
APIパラメータのJobName要素にGlueジョブ名を指定します。上図ではGlueジョブ名がtestになっています。
実行方法
基本は実行するだけで、実行時の入力オプションは何を設定してもかまいません。入力オプションが適当な場合、実行日の日付をもとに処理対象のCSVデータの格納パスが決まります。
例えば、2024年2月10日に実行した場合、CSVデータのパスは、01-input-sjis/2024/02/10/*.csvになります。
もし、他日時を指定して実行したい場合は、入力オプションに以下のように3つの要素を指定します。
{
"CustomParam": {
"year": "2024",
"month": "04",
"day": "09"
}
}
上記を入力オプションに指定した場合、CSVデータのパスは、01-input-sjis/2024/04/09/*.csvになります。
以下は入力オプションに指定して実行するときの画面

Lambda
Lambdaは、Glue処理前にデータ加工するLambda関数と、Glue処理後に不要データを削除するLambda関数の2つがあります。どちらもランタイムはPython3.11です。
Glue処理前にデータ加工するLambda関数
S3バケット上の01-input-sjisディレクトリ配下のCSVデータ(Shift_JIS)を読み取り、文字コードをUTF-8に変換し、変換したデータを02-character-encodingディレクトリ配下に出力します。
import boto3
import json
import datetime
def lambda_handler(event, context):
print(f"Lambda Start")
# バケット名とディレクトリパスを指定
bucket_name = 'hogefugabacket'
input_directory_head_path = '01-input-sjis/'
output_directory_path = '02-character-encoding/'
# 初期化
year = ""
month = ""
day = ""
if all(key in event for key in ('year', 'month', 'day')):
year = str(event['year'])
month = str(event['month'])
day = str(event['day'])
print(f"ParameterCustomSet {year}-{month}-{day}")
else:
today = datetime.date.today() # 現在の日付を取得
formatted_date = today.strftime("%Y年%m月%d日")
year = str(today.year)
month = str(today.month).zfill(2)
day = str(today.day).zfill(2)
print(f"ParameterSetFromToday {year}-{month}-{day}")
input_directory_path = f'{input_directory_head_path}{year}/{month}/{day}/'
print(f"input_directory_path = {input_directory_path}")
s3 = boto3.client('s3') # S3 クライアントを初期化
# 指定されたディレクトリ内のすべてのオブジェクトをリストアップ
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=input_directory_path)
# CSV ファイル名を抽出
csv_files = [obj['Key'] for obj in response.get('Contents', []) if obj['Key'].endswith('.csv')]
for csv_file in csv_files:
print(csv_file)
response = s3.get_object(Bucket=bucket_name, Key=csv_file)
csv_string = response['Body'].read().decode('shift_jis')
csv_string_utf8 = csv_string.encode('utf-8') # 文字コード変換 SJIS -> UTF-8
output_key = output_directory_path + csv_file.split('/')[-1] # 格納するS3バケットのパス設定
s3.put_object(Bucket=bucket_name, Key=output_key, Body=csv_string_utf8) # S3バケットの指定のパスにデータをput
print(f"Converted and put {output_key} to S3.")
return {
'statusCode': 200,
'body': json.dumps('Lambda create-tmpdata DONE')
}
補足ですが、Lambda実行時に以下のように年月日を指定すると、読み込むCSVデータのパスが変わります。
{
"year": "2024",
"month": "03",
"day": "17"
}
上記を入力オプションに指定した場合、CSVデータのパスは、01-input-sjis/2024/03/17/*.csvになります。
Glue処理後に不要データを削除するLambda関数
02-character-encodingディレクトリ配下にあるCSVデータを削除します。02-character-encodingディレクトリ配下のデータは中間データなのでGlueでの処理が終われば不要になるのでコスト削減になります。
また、不要になったデータを削除しておくことで次回、一連の処理が行われたときに処理不要なデータを再び処理することを防ぎます。
import boto3
import json
def lambda_handler(event, context):
s3 = boto3.client('s3') # S3 クライアントを初期化
# バケット名とディレクトリパスを指定
bucket_name = 'hogefugabacket'
target_directory_path = '02-character-encoding/'
# 指定されたディレクトリ内のすべてのオブジェクトをリストアップ
response = s3.list_objects_v2(Bucket=bucket_name, Prefix=target_directory_path)
# ファイルを削除
for obj in response.get('Contents', []):
# オブジェクトのキー(ファイル名)を取得
object_key = obj['Key']
# オブジェクトがCSVファイルかチェック
if object_key.lower().endswith('.csv'):
s3.delete_object(Bucket=bucket_name, Key=object_key)
return {
'statusCode': 200,
'body': json.dumps('Lambda delete-tmpdata DONE')
}
Glue
S3バケットの02-character-encodingディレクトリ配下のCSVを読み取り、加工データを03-glue-outputディレクトリ配下にファイル出力します。
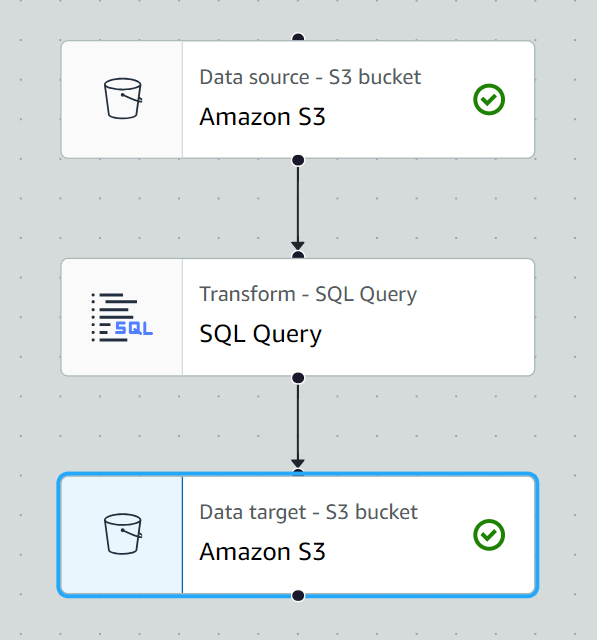
設定は単純で、S3バケットとディレクトリ指定くらいしかしてないので、設定紹介は割愛します。
S3
S3バケットの設定はデフォルトです。ファイルの格納パスを紹介します。
01-input-sjisディレクトリ配下には、加工対象のCSVデータが格納されている想定です。年月日でディレクトリをわけています。
- 01-input-sjis/
- 2024/
- 03/
- 17/
- data2024-01-01.csv
- data2024-01-02.csv
- data2024-01-03.csv
- 17/
- 03/
- 2024/
- 02-character-encoding/
- ※中間データが格納される※
- 03-glue-output/
- ※Glueで加工したデータが格納される※
設定紹介は以上です。
補足
足りてないもの
ここで紹介した仕組みには、エラー発生時の処理や、Lambdaの最長実行時間(15分)で処理できなかった場合などの対応などが不足しています。
StepFunctionsでCSV削除の処理を連携しなかった理由
StepFunctionsステートマシンについて、以下のようにGlueジョブ処理後に実施するようにしていたのですがこれはやめました。
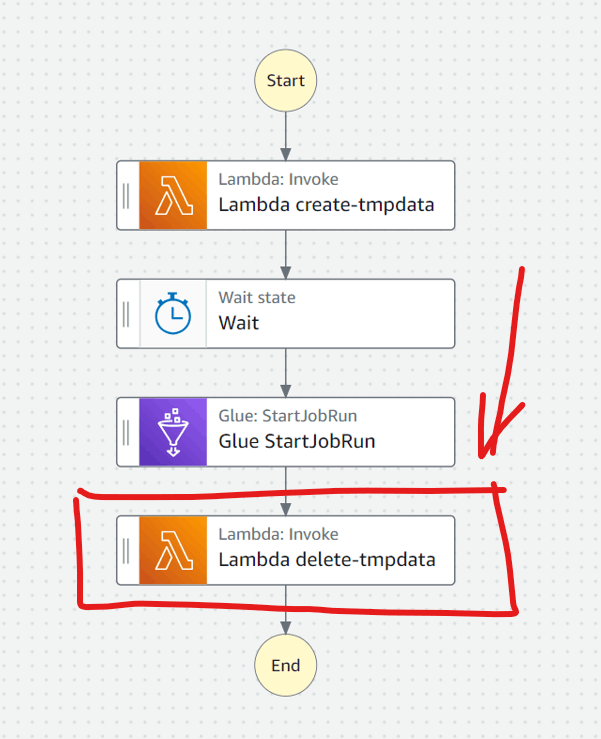
動作検証したところ、StepFunctionsはGlueジョブを呼び出すと、Glueジョブが処理完了を待たずに次の処理に進むことがわかりました。そのため、Glueジョブの処理中に、中間データを削除するLambda関数が実行されてしまい、その結果Glueジョブが加工データをファイル出力しない現象が発生しました。
この現象を回避するために、Glueジョブの処理完了をトリガーに中間データを削除する仕組みにしました。
Discussion