Open7
LLMOpsツールを色々使ってみる
LLMOpsツールを調べる。
自分のニーズ
- プロンプトとアウトプットを一元管理したい
- アウトプットの品質を簡単に見比べたい
- 過去の実験結果をあとから見返したい
- 計測のための実装が軽量であってほしい
- 破壊的変更が小さいと嬉しい
- Notebookでも使いたい
- 無料が良い
- 複数人でシェアしたい
関連資料
Weave
基本情報
- 開発元: wandb + open source
- version: 0.50.9
- スター数: 598
概要(readme.mdより翻訳)
Weaveを使用して以下のことができます:
- 言語モデルの入力、出力、およびトレースのログ記録とデバッグ
- 言語モデルのユースケースに対する厳密な、同じ条件での評価の構築
- 実験から評価、本番環境まで、LLMワークフロー全体で生成されるすべての情報の整理
私たちの目標は、認知的オーバーヘッドを導入することなく、本質的に実験的なプロセスである生成AIソフトウェアの開発に、厳密さ、ベストプラクティス、および組み合わせ可能性をもたらすことです。
Installation
pip install weave
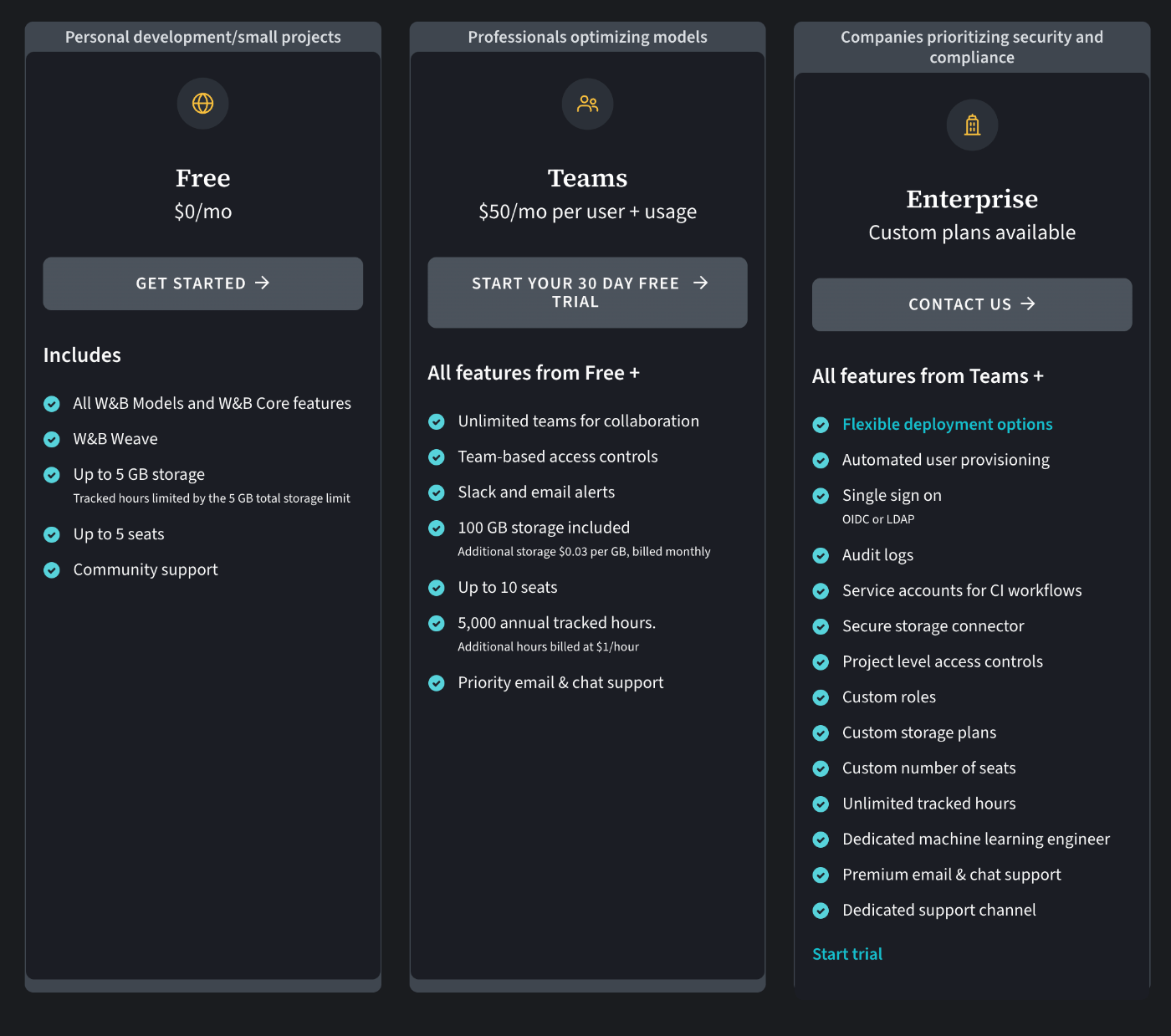
Pricing
- 無料枠は5seats
https://wandb.ai/site/pricing
使い方
- 計測したいメソッドに
@weave.op()デコレーターを追加する- メソッドの引数にpromptを、返り値に出力を指定する
-
weave.init(...)でwandb内のprojectを指定し、メソッドを実行することで計測可能
import weave
import json
from openai import OpenAI
@weave.op()
def extract_fruit(sentence: str) -> dict:
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
messages=[
{
"role": "system",
"content": "You will be provided with unstructured data, and your task is to parse it one JSON dictionary with fruit, color and flavor as keys."
},
{
"role": "user",
"content": sentence
}
],
temperature=0.7,
response_format={ "type": "json_object" }
)
extracted = response.choices[0].message.content
return json.loads(extracted)
weave.init('intro-example')
sentence = "There are many fruits that were found on the recently discovered planet Goocrux. There are neoskizzles that grow there, which are purple and taste like candy."
extract_fruit(sentence)
- Modelというclassを作ることで入出力のバージョン管理も可能
- プロンプトと正解データのペアを作っておき、weave.Evaluationというメソッドを使うことで定量評価も可能
from weave.flow.scorer import MultiTaskBinaryClassificationF1
sentences = [
"最近発見されたグークラックス惑星では、多くの果物が見つかりました。そこにはネオスキズルという果物が育っており、紫色でキャンディのような味がします。",
"パウニッツは鮮やかな緑色で、甘いというよりも風味豊かです。",
"最後に、グロウルという果物があり、非常に酸っぱくて苦い味わいで酸性と刺激性があり、淡いオレンジ色を帯びています。"
]
labels = [
{'fruit': 'ネオスキズル', 'color': '紫色', 'flavor': 'キャンディのような'},
{'fruit': 'パウニッツ', 'color': '鮮やかな緑色', 'flavor': '風味豊か'},
{'fruit': 'グロウル', 'color': '淡いオレンジ色', 'flavor': '酸っぱくて苦い'}
]
examples = [
{'id': '0', 'sentence': sentences[0], 'target': labels[0]},
{'id': '1', 'sentence': sentences[1], 'target': labels[1]},
{'id': '2', 'sentence': sentences[2], 'target': labels[2]}
]
@weave.op()
def fruit_name_score(target: dict, model_output: dict) -> dict:
return {'correct': target['fruit'] == model_output['fruit']}
model = ExtractFruitsModel(model_name='gpt-3.5-turbo-1106',
prompt_template='以下の文章から("fruit": <文字列>、"color": <文字列>、"flavor": <文字列>)の情報をJSON形式で抽出してください: {sentence}')
# Finally, we run an evaluation of this model.
# This will generate a prediction for each input example, and then score it with each scoring function.
evaluation = weave.Evaluation(
name='fruit_eval',
dataset=examples, scorers=[MultiTaskBinaryClassificationF1(class_names=["fruit", "color", "flavor"]), fruit_name_score],
)
# if you're in a Jupyter Notebook, run:
await evaluation.evaluate(model)
Evaluation summary
{
'MultiTaskBinaryClassificationF1': {
'fruit': {'f1': 1.0, 'precision': 1.0, 'recall': 1.0},
'color': {'f1': 1.0, 'precision': 1.0, 'recall': 1.0},
'flavor': {'f1': 0.5, 'precision': 0.3333333333333333, 'recall': 1.0}
},
'fruit_name_score': {'correct': {'true_count': 3, 'true_fraction': 1.0}},
'model_latency': {'mean': 5.273736238479614}
}

所感
- wandbのアセットを利用出来る 👍
- モダンなUI
- 認証の仕組みやアカウントが同じ
- Dashboardが自動でホスティングされる
- トークン数やレイテンシーが自動で計測されるのが便利
- デコレーターだけで計測できるので、サッと試すのに良さそう
- ドキュメントもわかりやすい
- RAGに関する機能もあるみたい
- Dashboard上に表示される情報が多いので、どこに何があるか把握する必要あり
Promptfoo
基本情報
- open source
- version 0.70.1
概要(readme.mdより翻訳)
promptfooは、LLM(大規模言語モデル)アプリケーションのテストと評価のためのツールです。
promptfooを使用することで、以下のことが可能になります:
- 信頼性の高いプロンプト、モデル、RAG(Retrieval-Augmented Generation)システムの構築:ユースケースに特化したベンチマークを用いて評価できます。
- 評価の高速化:キャッシング、並行処理、ライブリローディングにより、評価プロセスを迅速化します。
- 出力の自動スコアリング:メトリクスを定義することで出力を自動的に評価し、自動化された「レッドチーミング」(脆弱性の探索)を実行できます。
- 多様な使用方法:CLIツール、ライブラリ、またはCI/CDパイプラインで使用できます。
- 幅広いモデルのサポート:OpenAI、Anthropic、Azure、Google、HuggingFaceのモデルや、Llamaのようなオープンソースモデルを使用できます。また、任意のLLM APIのためのカスタムAPIプロバイダを統合することも可能です。
目標
promptfooの目標は、試行錯誤ではなく、テスト駆動のLLM開発を実現することです。
promptfooを選ぶ理由(readme.mdより翻訳)
- 開発者フレンドリー:promptfooは高速で、ライブリロードやキャッシングなどの開発者の生活の質を向上させる機能を備えています。
- 実戦で証明済み:元々、本番環境で1000万人以上のユーザーにサービスを提供するLLMアプリ用に構築されました。私たちのツールは柔軟で、多くのセットアップに適応できます。
- シンプルで宣言的なテストケース:コードを書いたり、重いノートブックを扱ったりすることなく、評価を定義できます。
- 言語に依存しない:Python、JavaScript、その他どの言語でも使用できます。
-共有とコラボレーション:チームメイトと作業するための組み込みの共有機能とWebビューアを提供しています。
-オープンソース:LLM評価はコモディティであり、完全にオープンソースのプロジェクトによって、無条件で提供されるべきです。 - プライバシー:このソフトウェアは完全にローカルで動作します。評価はあなたのマシン上で実行され、LLMと直接通信します。
Installation
npx promptfoo@latest init
参考資料
Langsmith
Langfuse
Aimstack