高速で持続可能な開発のためのソフトウェア工学と機械学習への適用
こんにちは、Wantedlyで推薦システムを開発している樋口です。Kaggleや実務での機械学習の開発にて、過去に下記のような失敗がありました。
- 精度改善のために実験を繰り返し追加したら、PRが巨大になり、レビューに時間がかかった
- 学習結果を確認したら、パラメータを一部だけ間違えていて、再度長い実験をやり直した
このような悩みを解決するために、書籍や経験で学んだプラクティスを取り組んできました。例をあげると以下のようなのものがあります。
- 小さい単位でPRを作成する
- パラメータを設定ファイルに切り出して、ヌケモレを減らす
- 学習データをサンプリングして、実行時間を短縮して結果を素早く確認する
これらのプラクティスに取り組む中で、もっと "高速で正確な開発を行うための知見や方法が体系化されているのではないか" という疑問が湧きました。
この疑問を解決するべく"継続的デリバリーのためのソフトウェア工学”という書籍を読んだのですが、非常に役立つと感じました。
そこで本ブログでは、参考にした書籍の内容を基に高速で正確な開発を行うためのソフトウェア工学の各プラクティス を説明したいと思います。後半ではそれらのプラクティスを機械学習開発に紐づけた具体例を紹介したいと思います。
私自身はデータサイエンティスト以外の経験はあまりないので、間違っている部分があればご指摘いただければと思います。
ソフトウェア工学とはなにか?
それではまず、本ブログで取り扱うソフトウェア工学について定義します。ここでは以下のように書籍での定義に従います。
"ソフトウェアの現実的な問題に対する効率的、経済的な解を見つけるための経験的、科学的なアプローチの応用"
David Farley, 「継続的デリバリーのソフトウェア工学 もっと早く、もっと良いソフトウェアを作るための秘訣」, 2022, p.20
定義に「現実的な問題に対する効率的、経済的な解を見つけるための経験的、科学的なアプローチ 」とあるように実務やKaggleなどでの諸問題に対して、実践的かつ体系だったプラクティスを学ぶことができそうです。
そもそもソフトウェア開発ってどんな性質を持つのか?
そもそも、なぜ“PRが巨大になり、レビューに時間がかかる”といったソフトウェア開発特有の問題に直面するのでしょうか。
それはソフトウェア開発が独特の複雑さを持ち、特別な性質を考慮する必要があるからです。
ここでは従来の製造業の開発プロセスと比較することで、ソフトウェア開発の特性を明らかにし、どのような性質があるかを理解したいと思います。
下記はソフトウェア開発と伝統的な製造業の比較を行った表です。
| 特徴 | ソフトウェア開発 | 製造業 |
|---|---|---|
| 構造の可視性 | 低い。ソフトウェアの構造は不可視で、抽象的な概念を理解し表現する必要がある。 | 高い。物理的な製品は目で見て確認でき、その構造や動きが直感的に理解できる。 |
| 変更の容易さ | 高い。ソフトウェアは柔軟で、プログラムコードの変更により容易に機能を追加、修正、削除できる。 | 低い。製造設備の変更はコストがかかり、時間も必要。また、物理的な制約がある。 |
| 結果の不確定性 | 高い。ユーザーのニーズを探索したり、新しい技術を取り入れるためにゴールや結果が変わりやすい。 | 低い。製造プロセスの変更は非常に時間がかかるため、製造目標や結果は通常、事前に明確に定義される。 |
この比較からソフトウェア開発の独特な性質、つまり要求が逐次的に変化する、柔軟に編集できる、複雑性に上限がない、 といった特性があることがわかります。
これらは、ソフトウェア開発が独自の困難さを持つ一因であり、それに対応するための特別な対策が必要となる理由です。
高速で正確なソフトウェア開発に必要な要素
ソフトウェア開発の独特な性質、つまり要求が逐次的に変化する、柔軟に編集できる、複雑性に上限がないことを考慮に入れると、どのような要素が高速で正確な開発を可能にするのでしょうか?
本書では、ソフトウェア開発は探索と発見のプロセスであり、そのためには学習と複雑さの管理のエキスパートになる必要があると述べています。
確かに、要求が逐次的に変化するなかで良いものを作るには、新たな知識を逐次的に学び、迅速に取り入れ、変更する必要があります。
その実現のためには、複雑性に上限がないソフトウェアの複雑性を制御、管理する能力も必要です。
以下では、スコープを絞り、「学習のエキスパート」になるための要素に焦点を当てて解説します。
学びのエキスパートになるための要素
学習のエキスパートになるための要素をそれぞれ紹介します。これらの要素は互いに関連し、作用しています。
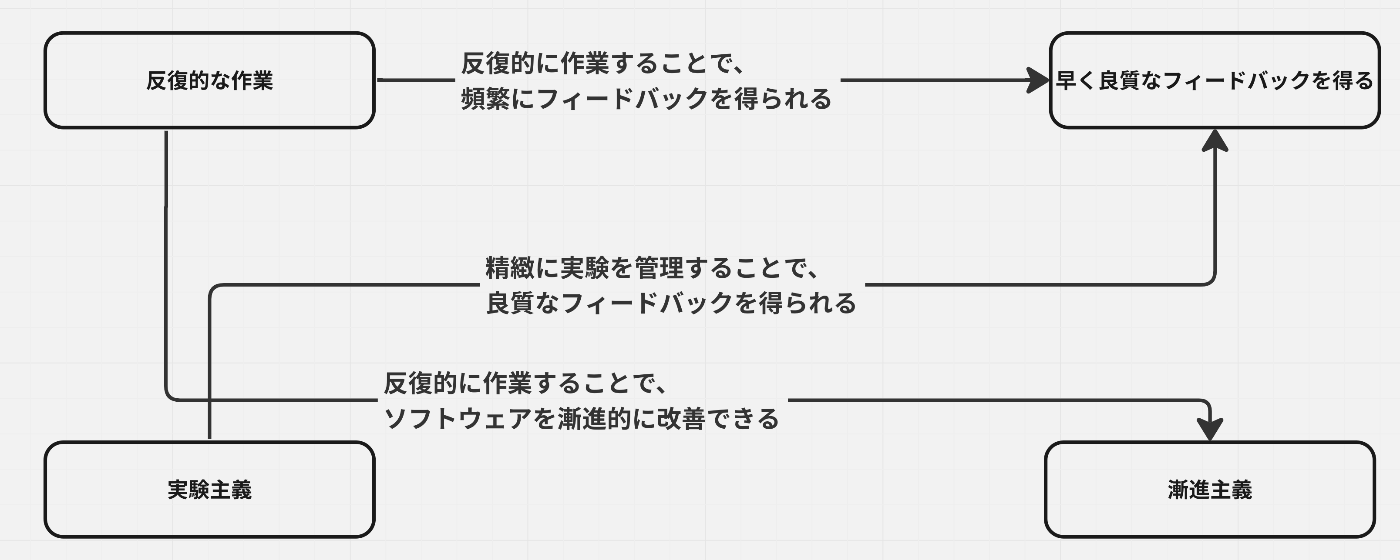
反復的な作業
何を意味するのか
”反復的な作業”とは最初から全ての要件を定義し、一度に作り上げるのではなく、反復的に作業を行い、段階的に理想の結果に近づくことを指します。
下記のように、一度に設計→実行ではなく、計画、実行、確認、改善(PDCA)のサイクルを回して反復的に作業するイメージです。
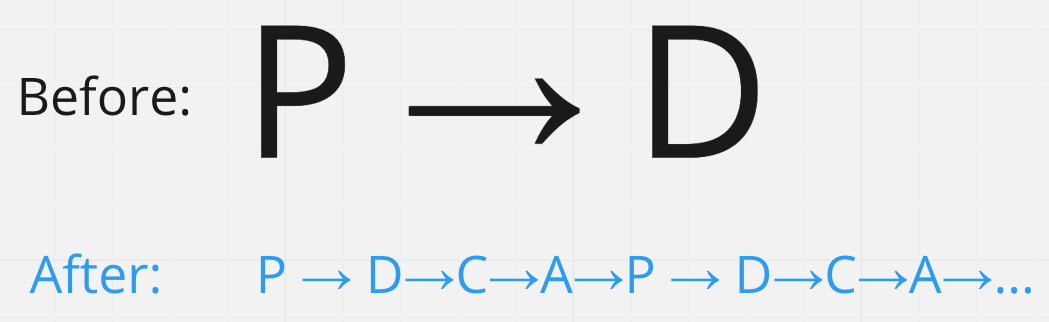
なぜ重要なのか
ソフトウェア開発は、"ユーザにA/Bテストで機能リリースしたら想定外の効果があった"といったことがあるように、探索と発見のプロセスであり、間違いは日常的に起こるものだからです。
このような状態では、予想外の問題が発生することはしょっちゅうあるので、意思決定の誤りの影響を小さくするために、PDCAのサイクルを小さく、反復的に行うことが必要です。
プロジェクト開始時は最も知識が少ない状態で方針を決めるので、学びを進めるごとに徐々にキャリブレーションする必要があるとも言えます。
また、反復的な作業は、自動的に注目する焦点を絞り込み、小さな単位で考えるように導く効果もあります。
どのように実行するか
反復的な作業は、さまざまなレベルで実行できます。
プロジェクト管理の観点からは、一度に全てを設計・開発するウォーターフォール型開発ではなく、反復的な作業を前提としたアジャイル開発を取り入れることが考えられます。
プロジェクト内の各タスクへの取り組み方においても、作業を可能な限り細分化し、進行中のタスクを制限し、焦点を絞り、各タスクの完了を確認することで、手戻りを防ぐことが可能になります。
また、コーディングにおいても、小さなタスクを反復的に行い、結果をチェックできるようにすることができます。例えば、CI/CDを導入してリリースや変更に対する検証を簡単に行えるようにしたり、小さな実装単位でテストを書くといった手法がとれます。
早く良質なフィードバックを得る
何を意味するのか
フィードバックとは、行動や成果に対する評価を行い、その結果を評価された主体に伝える行為です。学習や改善を進めるためには、良質なフィードバックを早く得ることが重要です。
PDCAサイクルにおけるC(検証)の質を高め、D→C間の時間を短くすることとも言えます。

なぜ重要なのか
早く良質なフィードバックを得ることで、意思決定の根拠を明確にし、予測に依存せずに迅速かつ正確に学習を進めることができます。また、問題や改善点を早期に発見し、リスクを最小限に抑えることが可能となります。
また反復的に作業し、漸進的に改善するためには、どの方向に舵を切るかという判断根拠として正確なフィードバックが必要になります。
どのように実行するか
早く良質なフィードバックを得るための手段は、開発の各フェーズに適応できます。
コーディングフェーズ:
コーディング時にはIDEにLinterを導入することでスペルミスや構文エラーを自動的に検出できます。
些細な内容でも、即時にフィードバックを得られるか、実行まで検出されないかでは、長い目でみて効率が変わってくるでしょう。
さらにユニットテストを用いると、各コンポーネントが正しく動作するか?という小さい単位に対して、反復的にフィードバックを得られます。
インテグレーションフェーズ:
コード統合時にはCI/CDの導入による早期フィードバックの獲得が可能です。コードpush時に自動的にテストセットやビルドシステムが起動し、コード全体が正しく書かれているか、本番環境で実行できるか、というフィードバックが得られます。
また同僚からコードレビューでフィードバックを得て、視点の多様性を確保し、より優れた解決策を見つける機会を増やすこともできます。
設計フェーズ:
設計時には、テストを書くことで、コードの振る舞いを簡単に検証できるか設計になっているか、というフィードバックが得られます。
テストが容易なアーキテクチャは、特定の振る舞いを切り出してテストできる時点で、実装自体が関心の分離・モジュラー性・高い凝集度など、複雑さを管理する性質を持っています。なぜならテストが書きづらい場合、あるメソッドなどのコンポーネントに必要な入力の用意が難しい、翻ってコンポーネント間が密結合しているなどのサインになるためです。
このように、テストはコンポーネントの振る舞い自体に対してだけでなく、設計自体にもフィードバックを得ることができます。
組織や文化に対する適用:
ソフトウェアの実装や設計だけでなく、組織や文化に対してフィードバックを適用することもできます。アジャイル開発の例を挙げると、KPT(Keep, Problem, Try)の手法を用いて施策に対する振り返りを行います。アジャイル原則は、"プロセスやツールよりも個人と対話を重視する"と強調しており、対話を通じて相互にフィードバックを得ることが推奨されています。
実験主義
何を意味するのか
実験主義は、意思決定を行う際に仮説を立て、それを計測し、その結果に基づいて判断を下す姿勢を指します。また、これにより、PDCAサイクルの「Check」を定量的に行うことが可能になります。
PDCAサイクルでいうと、Dで加える変更を管理し、Cを定量的に図る姿勢と言えます。

なぜ重要なのか
開発中の不確定性を扱いつつ、最善の解決策を見つけ出すためには、可能な限り多くのアプローチを試し、その結果を測定・評価することが必要なためです。
どのように実行するか
変数の管理を行い、仮説を立て、その結果を測定し、フィードバックを元に改善を行います。
より具体的に言うと、なにかを改善する場合、直感によって修正方法を決めて実装するのではなく、現在のどんな課題を解決するのかという仮説を立て、その結果、変化する指標を定め、何を変えたかを明確に表記し、その結果を測定するということです。
簡単な例ですが、下記のように何を変え、どうなったかを正確に知るために、課題や変数と明記し変更するというイメージです。
- メール施策
- 解決する課題: ユーザが興味を引くタイトルにする
- 変数: メールタイトル
- 変化する指標: CTR
- 測定方法: A/Bテスト
- 推薦施策
- 解決する課題: 同じアイテムばかり推薦されないようにする
- 変数: モデルの損失関数
- 変化する指標: カバレッジ
- 測定方法: A/Bテスト
- コーディング
- 解決する課題: APIから取得したデータの形式が正しく、予期せぬエラーを防ぐ
- 変数: APIから取得するデータの形式を検証するコード
- 変化する指標: テストのfail数
- 測定方法: ユニットテスト
また、このような実験主義は正確なフィードバックを得るために行っているので、実験終了後はそのフィードバックを得て改善に繋げられるとよいでしょう。
漸進主義
何を意味するのか
漸進主義は、価値やシステムを小さなステップで段階的に構築し、進歩していくアプローチを指します。頻繁かつ小規模なリリースを行い、一つ一つのステップが次の進歩に向けた土台となるようにします。
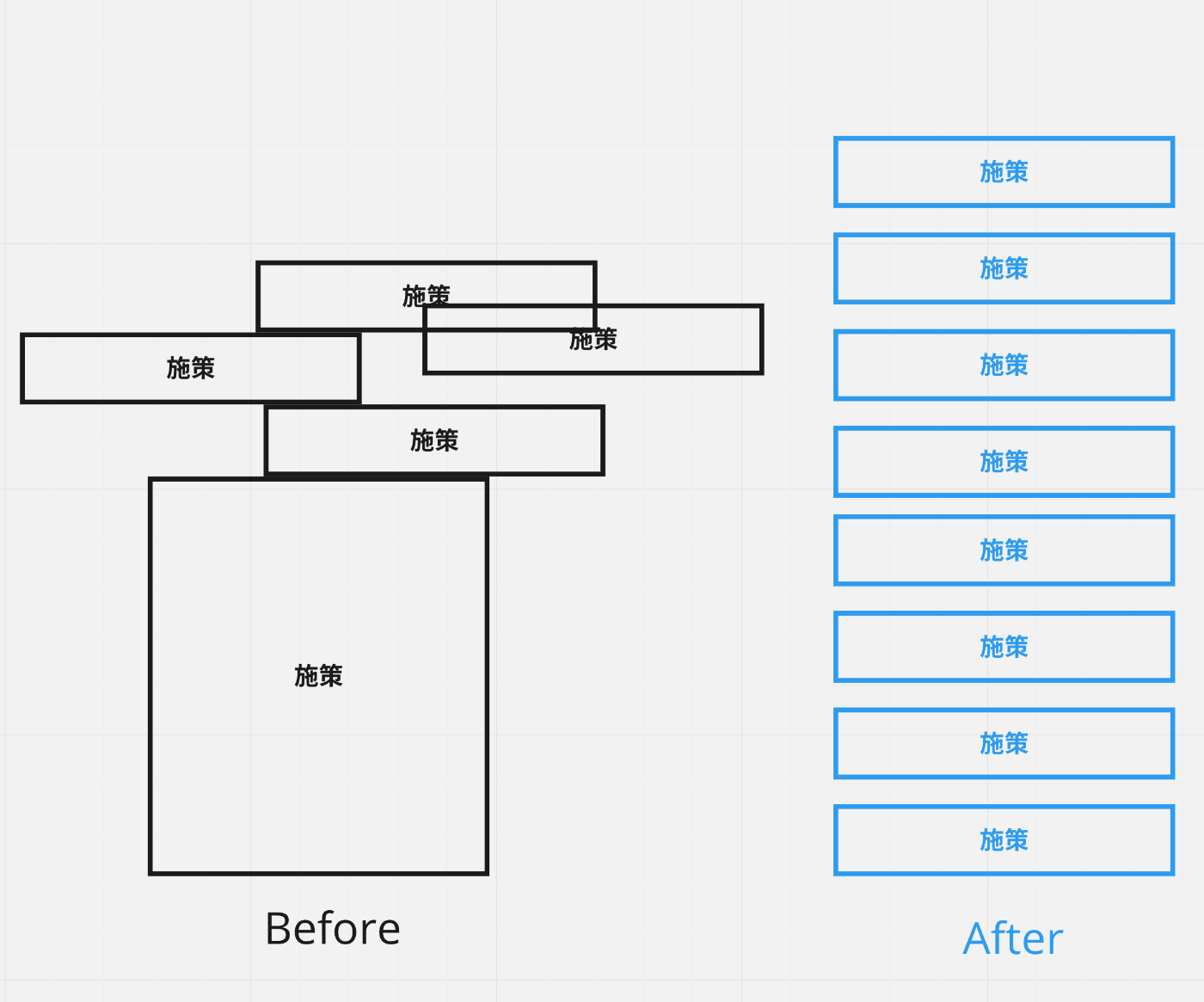
なぜ重要なのか
リスクの分散と早期の価値提供のために重要です。複雑なシステムでも、成果物を頻繁にリリースしながら構築することで、持続可能で安定した開発を実現することができます。
また、早期に価値をユーザに提供できるため、顧客満足度の向上やフィードバックも早期に取得可能となります。
どのように実行するか
漸進主義を実行するには、逐次改善できる、つまりコンポーネント単位で修正・追加できる実装構成が不可欠です。
また、コンポーネント単位での改善が容易にするには、コンポーネント間は疎結合かつ、関心の分離されていること求められます。関心が分離されていないと、あるコンポーネントの変更が別の箇所に波及し、変更コストが高まってしまいます。
漸進主義を達成するにはチームなど組織構成にも工夫が必要です。例えばチームの変更に対して、多数の関係者に承認が必要な組織だと、承認がボトルネックとなり、漸進的に改善するのは難しくなってしまいます。
上記要素を満たした機械学習開発
上記の各要素を械学習開発プロセスに活用した例を紹介します。前提として、機械学習開発においては私の経験上、学びの観点では、下記のような問題を抱えやすいと考えています。
まず、バックエンドなどの開発に比べ、大きなデータに対して長い時間をかけた学習が必要なことが多いので、フィードバックループが長くなりやすく、その結果、反復的な作業も回数をこなすのが難しいです。
また、モデルの設計やデータの前処理などの多様なパラメータがあり、かつデータのドリフトやモデル内のランダムネスにより、結果が非決定的になりやすいです。そのため、適切な実験を選ぶこと、その結果を正しく測ること、つまり実験主義で進めるのが難しくなりやすいです。
さらに、あるデータセットに対して、収集→前処理→学習→後処理のように一連の処理を施すため、各処理がデータセットを起点に密結合しやすく、コンポーネント単位での修正=漸進的な改善が難しくなりやすいです。
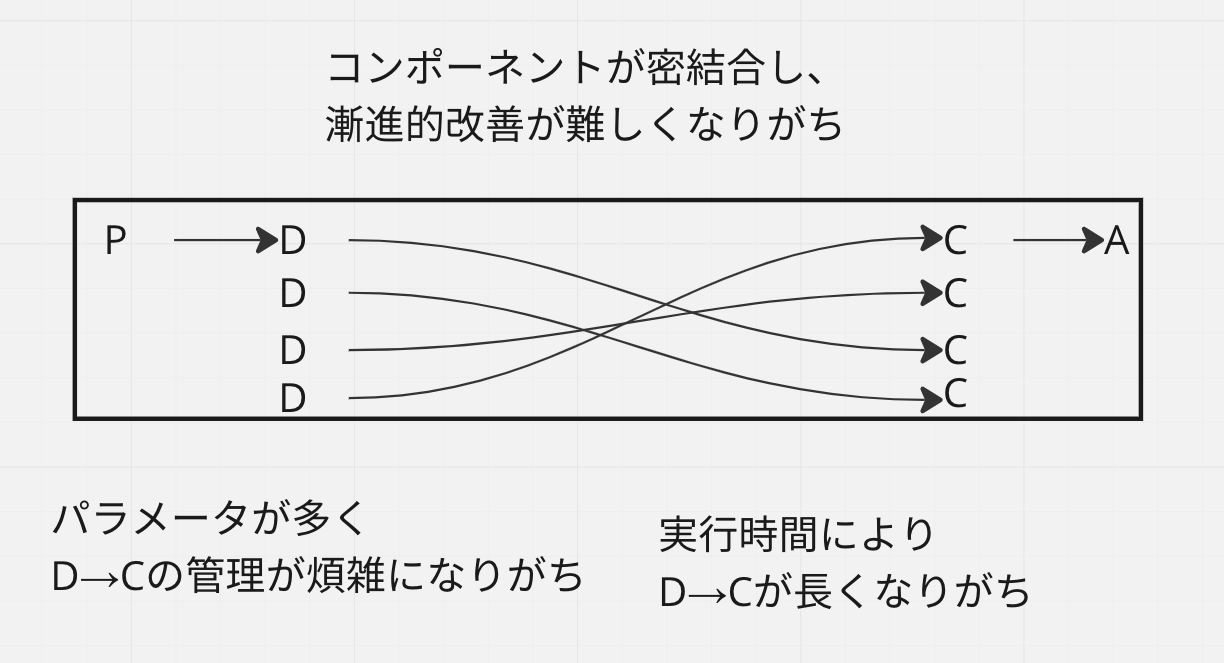
これらの機械学習で起きがちな問題に対して、ソフトウェア工学のプラクティスを使った改善を意識しまします。
1. 設計・計画フェーズ - 反復的な作業 & 実験主義
ユーザのニーズやモデルの精度が悪い原因に対して仮説をだして深掘りし、それを元に改善箇所を定めます。この際、具体的な改善指標(数値)を設定し、それを向上させるという見通しもたてるとよいでしょう。これは「実験主義」の原則にも繋がる部分で、多様なパラメータがある中で、どのような結果が期待され、それが実際に得られるかを見極めることで、次のイテレーションの方針を正確に定めることができます。
2. コーディングフェーズ - フィードバックを得る
コーディングフェーズでは早く正確にフィードバックを得る方法がいくつもあります。Pythonならmypyやblackなどのツールを活用し、IDEやCIを通じてコードが規約を満たしているか逐次確認できます。
設計においては、実験主義、漸進主義を適用できるように、コンポーネント間が密結合を防ぎつつ変数を管理できるように、依存関係の逆転を適応して、安定度の低いコンポーネントに全体のjobが依存しないようにする、実験パラメータを切り出して管理する、などを特に意識できるとよいでしょう。
また、機械学習開発固有の待ち時間の長さに対する工夫し、フィードバックループを縮め、多くの実験を行うことも大切です。
ここには様々なテクニックがあります。キャッシュ機構を導入して中間生成物の再生成をスキップする、ユニットテストとサンプルデータを用意し、コンポーネント単位で処理を確認する、pdbなどのデバッグツールで必要な箇所だけjobを走らせて挙動を確認する、多数のマシンをクラウドで借りて並列で実行し、終了時に通知を送る、高速なライブラリやデータフォーマットを用いる、などが挙げられます。
3. リリースフェーズ - 実験主義 & 漸進主義
リリースフェーズでは、前述の「実験主義」に基づき、主要な指標をモニタリングします。これらの指標を用いて、新たな機能や改良が導入されるかを判断します。
このときは、ユニットテスト・オフラインテスト・オンラインテストなど、複数のコストと得られるフィードバックの長さが異なるテストを組み合わせることでより早く正確な測定が可能になります。
また、コーディングフェーズに記載した待ち時間の長さに対する工夫を凝らし、短い時間で多くの実験を行い、前処理や特徴量の改善を繰り返し、最善の方法を見つけ出します。
特徴量など試行錯誤を必要とする部分は、後に漸進的に改善することを見越して、Feature classなど、関心の分離ができるコンポーネントに切り出し、後の変更コストが小さくなるように意識して開発できると良いでしょう。
4. フィードバック・反省フェーズ - 反復的な作業
プロジェクトの終了時には、施策が意図通りに機能したかをKPTなどで振り返ります。この振り返りは、学んだことを次のプロジェクトに活かすための重要なステップとなります。
まとめ
ソフトウェア開発の独特な性質、要求が逐次的に変化する、柔軟に編集できる、複雑性に上限がない があるなかで、高速で正確な開発を行うためのソフトウェア工学の各プラクティス を説明しました。また、これらのプラクティスと機械学習開発プロセスを紐づけた例を紹介しました。
もちろん機械学習開発においては、データ可視化のための書き捨てのコードを書いたり、あえて質をおとしてスピード最優先で実験することもあります。
そういったトレードオフを意識しつつ、継続改善を行うフェーズでは、ぜひプラクティスを取り入れて見ていただけたらと思います。
今後は今回のプラクティスの中心にある、単体テストの書き方なども言語化してブログにしたいと思っています。継続的に発信を続けたいと思っているので良ければTwitterもフォローしていただけると嬉しいです!
参考資料
このブログを書く上で参考にした書籍を紹介します。
ちょうぜつソフトウェア設計入門――PHPで理解するオブジェクト指向の活用
複雑さを管理しつつ、設計するための具体的な方法が記述されています。
SOLID原則・クリーンアーキテクチャ・TDDのような思想がどのように相互作用しているかを理解しつつ、コードに落とし込むための方法が学べます。
単体テストの考え方/使い方
高品質なソフトウェア開発において中心的な役割を果たす単体テストについての書籍です。テストコードの書き方だけでなく、なぜ書くのか?どうやって何に対して、どれくらいのテストを書くべきなのか、なぜユニットテストが設計に対して良いフィードバックを与えるのか、などを包括的に学べます。
LeanとDevOpsの科学
今回示した学びと複雑さの管理などが、組織のパフォーマンスに対してどのように影響するのか、パフォーマンスが高い企業とそうでない企業の違いはどのように現れるのか、などの研究を本にまとめた書籍です。
今回示した各プラクティスが組織運営などのより大きな枠組みでどのように重要かを理解できる様になると思います。
Discussion