【Kaggle】H&Mコンペ参加記(133rd/2952🥈)
こんにちは、ひぐです。Kaggle のH&M Personalized Fashion Recommendations(H&Mコンペ)に参加して銀圏(133rd/2952🥈)でした。


せっかく参加したので、やってきたことをまとめたいと思います。
コードはこちら↓
コンペの概要
タスク
本コンペのタスクは、article(商品)・customer・transactions(20/09/19までの購買履歴)のテーブルデータと商品画像データを使って、20/09/20~20/09/27にcustomerが購入するだろうarticleを12個予測することです。
予測には以下のデータを利用することができます。
article.csv

customer.csv

transactions.csv

https://www.kaggle.com/code/vanguarde/h-m-eda-first-look のNotebookを見ればデータの概要が掴めるかと思います。
H&Mコンペの特徴
自分で(学習/予測)対象を決める必要がある
機械学習コンペではどのレコードに対して、(学習/予測)するかはホスト側が事前に用意していることが多いです。(ex. train.csv, test.csv)
ただしこのコンペは、上記で紹介したデータしか用意されていないため、自分で(学習/予測)対象を決める必要があリます。
ナイーブにある(customer,article)ペアに購買が発生するかを予測するためには、以下のように(customer_id, article_id)ペアを作って購入する確信度を出力すれば良いです。
| customer_id | article_id | target |
|---|---|---|
| c1 | a1 | 0.1 |
| c1 | a2 | 0.2 |
| ... | ... | ... |
ただし、何も考えず全通り予測しようとすると130万 * 10万 = 1300億通り計算することになるため、これは現実的ではありません。まともに計算するにはcustomerが購入する可能性が高いアイテムだけを(学習/予測)対象とする必要があります。
この(学習/予測)対象を決める(=train_df, test_dfを作る)こと、そして作った(学習/予測)対象に対して特徴量を作成し、予測精度を高めるという2段階の作業が必要になることがこのコンペの特徴だったと思います。(推薦タスクでは一般的な手法かと思いますが)
弊チームの取り組み
以降、(学習/予測)対象を決める部分をCG(=Candidate Generation), 特徴量作成部分をFE(=Feautre Engineering)と省略して呼びます。
学習パイプライン
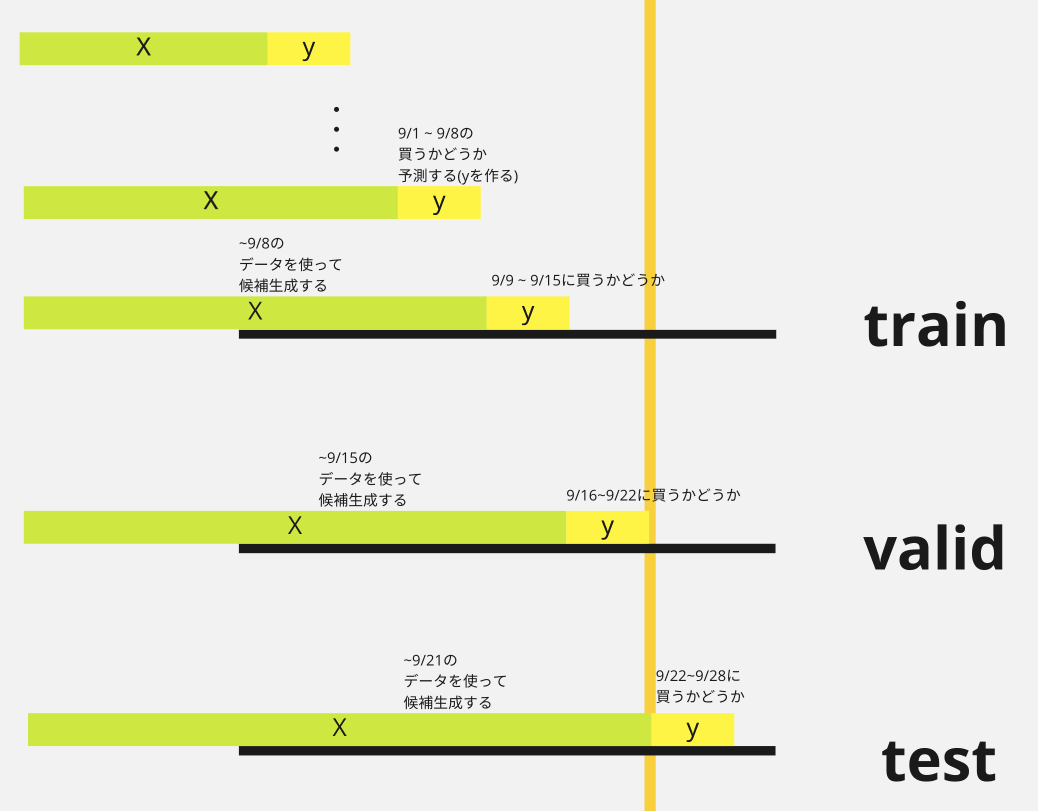
弊チームではtrain, valid, testデータは以下のように構築しました。ある週までのtransactionを使って、CG,FEを行い、その翌週にその(customer, article)ペアで購買が発生するかを予測するかをtargetとします。
図にするとこんな感じ。
表にするとこんな感じ

コードにするとこんな感じです。
def make_train_valid_df():
train_df, valid_df = pd.DataFrame(), pd.DataFrame()
for target_week in target_weeks:
phase = "validate" if target_week == 104 else "train"
clipped_trans_cdf = trans_cdf.query(
f"target_week - {train_duration_weeks} <= week < target_week"
) # 予測日の前週までのトランザクションが使える
y_cdf = make_target_df(clipped_trans_cdf)
base_df = candidate_generation(
candidate_blocks,
clipped_trans_cdf,
art_cdf,
cust_cdf,
y_cdf,
target_customers=None,
)
base_df = negative_sampling(base_df, clipped_trans_cdf, y_cdf)
art_feat_df, cust_feat_df, pair_feat_df = feature_generation(
feature_blocks,
clipped_trans_cdf,
art_cdf,
cust_cdf,
)
# 特徴量作成
base_df = base_df.merge(cust_feat_df, how="left", on="customer_id")
base_df = base_df.merge(art_feat_df, how="left", on="article_id")
base_df = base_df.merge(pair_feat_df, how="left", on=["article_id", "customer_id"])
base_df["target_week"] = target_week
base_df["y"] = (
base_df.merge(y_cdf, how="left", on=["customer_id", "article_id"])["y"]
.fillna(0)
.astype(int)
)
if phase == "train":
# 学習データは複数予測週があるのでconcatする
train_df = pd.concat([train_df, base_df])
elif phase == "validate":
valid_df = base_df.copy()
Candidate Generation
候補生成は以下のようなものを作りました。
- customerと同年代で人気なarticle top30
- customerが過去購入したarticle head30
- customerが過去購入したarticle と一緒に買われるarticle
- 予測週の前週最も人気だったarticle top30
- customerの特徴で作ったクラスタ(=kmeans)内で人気なアイテムtop30
Negative Sampling
上記のようにさまざまな候補生成をすると、(train/valid)_dfのレコード数は非常に増えてしまいます。そこで、(train/valid)_dfでは予測週に実際に購買が発生したユーザに絞る & 購買が発生しなかったペアはランダムに間引くことにしました。
このように間引くことで、学習時間の削減・inbalanceの解消ができました。なお、test phaseでは予測週の情報は使えないので、customerを絞ってバッチで予測しました。
Feature Engineering
特徴量は以下のようなものを作りました。
- articleに紐づく特徴
- 購入customerの(min,max,mean,std)年齢
- n回以上購入したcustomer数
- 色を表す単語を(RGB, HLS, YIQ, HSV)に変換
- 商品説明文 → Bert → UMAPで次元圧縮したベクトル
- customerに紐づく特徴
- 最終購入日, 購入間隔
- 購入articleの(min,max,mean,std)(price, RGB, etc.)
- (women/men)という文言が含まれた商品を買っている割合
- どの曜日・月・週によく購買するか
- article, customerペアに紐づく特徴
- customerの購入articleの平均価格 - 予測対象articleの価格
- その他
- どのCandidate Generation blockから取得されたレコードか
Feature Importanceはこんな感じです。

Train/Predict
LightGBMRankerを使ってランク学習をしました。パラメータはえいやで決めてます😇
800iterくらいでearly stopしました。
RANK_PARAM = {
"objective": "lambdarank",
"metric": "ndcg",
"eval_at": [12],
"verbosity": -1,
"boosting": "gbdt",
# "is_unbalance": True,
"seed": 42,
"learning_rate": 0.01,
"colsample_bytree": 0.5,
"subsample_freq": 3,
"subsample": 0.9,
"n_estimators": 10000,
"importance_type": "gain",
"reg_lambda": 1.5,
"reg_alpha": 0.1,
"max_depth": 6,
"num_leaves": 45,
}
アンサンブル
公開されているルールベースのNotebookと重みをつけてアンサンブルをしています。
def cust_blend(dt, W = [1,1,1,1,1]):
REC = []
# Second Try
REC.append(dt['prediction0'].split())
REC.append(dt['prediction1'].split())
res = {}
for M in range(len(REC)):
for n, v in enumerate(REC[M]):
if v in res:
res[v] += (W[M]/(n+1))
else:
res[v] = (W[M]/(n+1))
# Sort dictionary by item weights
res = list(dict(sorted(res.items(), key=lambda item: -item[1])).keys())
# Return the top 12 items only
return ' '.join(res[:12])
0.0245(銅圏) → 0.0250(銀圏)くらいには伸びました。
チームでの取り組み方
4人チームでしたが、Kaggleを完走した人が1人しかいなかったので、なるべく全員の認識がずれないように + モチベに差が生まれないように密に情報共有しながら進めました。
週1の定例MTGをしたり

Notionでやったことまとめたり

slackで連絡とったりしました。

他のチームで参加してる人はどうやって情報共有してるのか気になりました🤔
ふりかえり
よかったところ
loggerに情報を吐いて、デバッグしやすくした
loggerにCGの正例率・カバレッジ率などを出力することで、バグの検知・各CGの効率の良さなどをすぐに確認できました。
2022-05-09 11:48:39,475 - 019_add_color_feat.py - utils - 311 - INFO - ↓fit PopularItemsoftheEachAge
2022-05-09 11:48:40,155 - candidacies_dfs.py - utils - 81 - INFO - 候補集合内の正例率: 0.16%(2720/1697340)
2022-05-09 11:48:40,156 - candidacies_dfs.py - utils - 82 - INFO - 正例カバレッジ率: 1.27%(2720/213728)
2022-05-09 11:48:40,156 - candidacies_dfs.py - utils - 83 - INFO - ユニーク数: (customer:56578, article: 97)
2022-05-09 11:48:40,177 - utils.py - utils - 84 - INFO - ↑fitted PopularItemsoftheEachAge 0.701[s]
2022-05-09 11:48:40,177 - 019_add_color_feat.py - utils - 336 - INFO -
2022-05-09 11:48:40,177 - 019_add_color_feat.py - utils - 311 - INFO - ↓fit PopularItemsoftheEachCluster
2022-05-09 11:48:40,845 - candidacies_dfs.py - utils - 81 - INFO - 候補集合内の正例率: 0.205%(4242/2069490)
2022-05-09 11:48:40,846 - candidacies_dfs.py - utils - 82 - INFO - 正例カバレッジ率: 1.98%(4242/213728)
2022-05-09 11:48:40,846 - candidacies_dfs.py - utils - 83 - INFO - ユニーク数: (customer:68984, article: 1897)
2022-05-09 11:48:40,982 - utils.py - utils - 84 - INFO - ↑fitted
...
ブロックベースのコードにすることで作業を切り出せた
CG, FEはそれぞれ、複数作成する必要があったので、AbstractClassを書いて、その中身を複数用意する形をとっていました。
Blockごとにコードを切り出すことで、各メンバーの作業がコンフリクトせずに進めることができました。
class AbstractBaseBlock:
def __init__(self, use_cache):
self.use_cache = use_cache
self.name = self.__class__.__name__
self.cache_dir = Path("/home/kokoro/h_and_m/higu/input/features")
def fit(
self, trans_cdf, art_cdf, cust_cdf, base_cdf, y_cdf, target_customers, logger, target_week
) -> cudf.DataFrame:
file_name = self.cache_dir / f"{self.name}_{target_week}.pkl"
# キャッシュを使う & ファイルがあるなら読み出し
if os.path.isfile(str(file_name)) and self.use_cache:
with open(file_name, "rb") as f:
feature = pickle.load(f)
return feature
# そうでないならtransform実行 & ファイル保存
else:
feature = self.transform(
trans_cdf,
art_cdf,
cust_cdf,
base_cdf,
y_cdf,
target_customers,
logger,
target_week,
)
with open(file_name, "wb") as f:
pickle.dump(feature, f)
return feature
def transform(
self, trans_cdf, art_cdf, cust_cdf, base_cdf, y_cdf, target_customers, logger, target_week
) -> cudf.DataFrame:
raise NotImplementedError()
実装例
class EmbBlock(AbstractBaseBlock):
"""
{hoge_id:[List[int]],...}形式のdictをcudfに変換する
"""
def __init__(self, key_col, emb_dic, prefix, use_cache):
super().__init__(use_cache):
...
def transform(
self, trans_cdf, art_cdf, cust_cdf, base_cdf, y_cdf, target_customers, logger, target_week
):
out_cdf = ...
return out_cdf
ペアプロして一気に作業を進められた
終盤ガラッとコードベースを書き換えた時はvscodeのlive share機能とGoogle meetを使って、ペアプロしました。
1人だとだれてしまったり、バグに気づかなかったりするのですが、これで一気に楽しく進められました。
Ref:
もっと良くできたところ
H&Mのサイトを見て、推薦を再現する
H&Mのオンラインサイトを見ると、どのようなカテゴリで、どんなarticleが上位に来ているか、どのようなフィルタリング、検索ができるかがわかります。

基本的にユーザの購買履歴は、サイト上のarticleの表示順にバイアスを受けるため、この表示順を再現するようなCG,FEができていればよかったと思います。
(ex. スポーツウェアを買った人には、スポーツウェアの人気商品top20を候補生成に入れる、など)
システマチックにCG,FEの種類を管理する ・ アンサンブルする
アンサンブルをすると、かなり精度が上がったことがわかっていたため、もっとシステマティックにアンサンブルできたらよかったなと思います。今回のコンペは予測期間や各CGの追加量などはハイパーパラメータだったので、この辺りの値を変えてアンサンブルができたらよかったかなと思います。
入れたらよかったFE,CG
上位チームの解法を見ると、実装コストが小さく、かなり効くであろうFE,CGがいくつもありました。この辺りを取りこぼしたのはもったいなかったです。具体的には以下の通り。
- 各CG blcok内でのaricle順位
- 例えば(先週の人気アイテムtop nをCGとして追加するならそのnをfeatureとして入れる)
- Streak情報
- ある(customer/article)が何回連続で購買をしているか
- 協調フィルタリング系のCG,FE
おわりに
自由度が高く、やることが無限にあるコンペでした。ベースラインを作るためにかなりコードを書いたのでとても勉強になりました。
無事銀メダルを取ることができましたが、銀上位と下位では相当スコア差があり、まだまだ修行が必要だなぁとも感じました。一つのコンペを完走したおかげで、次回以降どうやって取り組むべきかだいぶ指針が立てやすくなったと思うので、今後も頑張っていきたいです🔥
また、業務でも参加して得られた知見を生かしていきたいです💪
おまけ(環境構築)
今回はcudfを使える環境かどうかで相当処理時間が変わってきたと思います。自分は以下の記事を参考にcudfが利用できるgcpのインスタンスを借りて作業をしていました。1日フルで使って2000円程度くらいでした。
gcloudコマンドを入れて、以下をterminalで実行するだけで立ち上がります。
export IMAGE_FAMILY="rapids-latest-gpu-experimental"
export ZONE="asia-east1-a"
export INSTANCE_NAME="rapids-instance-v2"
export INSTANCE_TYPE="custom-16-131072-ext"
gcloud compute instances create $INSTANCE_NAME --project "wantedly-individual-kokoro" --zone=$ZONE --image-family=$IMAGE_FAMILY --image-project=deeplearning-platform-release --maintenance-policy=TERMINATE --accelerator='type=nvidia-tesla-t4,count=1' --machine-type=$INSTANCE_TYPE --boot-disk-type='pd-ssd' --boot-disk-size=500GB --scopes=https://www.googleapis.com/auth/cloud-platform --metadata='install-nvidia-driver=True,proxy-mode=project_editors
(ただ、このvmだとcudfのversionが古いので、一部メソッドが生えていなかったり不便をするかもです。今はdockerで起動するのが良いらしい?)
なお、弊社Wantedlyでは自己研鑽のために月5万までgcpを利用して良いという福利厚生があり、こちらを使わせていただきました。ありがたいです🙏
また、節約するには自動シャットダウンの仕組みを入れると良いかと思います。
Discussion