【Kaggle】OTTOコンペ参加記(22th/2587th)🥈
Kaggleで開催されていたottoコンペの概要説明と、チームのSolutionについて紹介します。
KaggleにもSolutionを公開しているので、よければそちらも合わせてお読みください:pray:
コンペの概要
本コンペのタスクは、ドイツのECサイト"otto"において、各ユーザが将来、どの商品へインタラクション(クリック, カート, オーダー)するか当てるというものです。
利用できるデータは非常にシンプルで、下記のように、各ユーザ(session)がどのアイテム(aid)にいつ(ts)どんな(type)インタラクションをしたか、という情報だけです。

データセットはとても大きく、180万のアイテム、1200万ユーザ、2.2億のインタラクションが含まれています。
12M real-world anonymized user sessions
220M events, consiting of clicks, carts and orders
1.8M unique articles in the catalogue
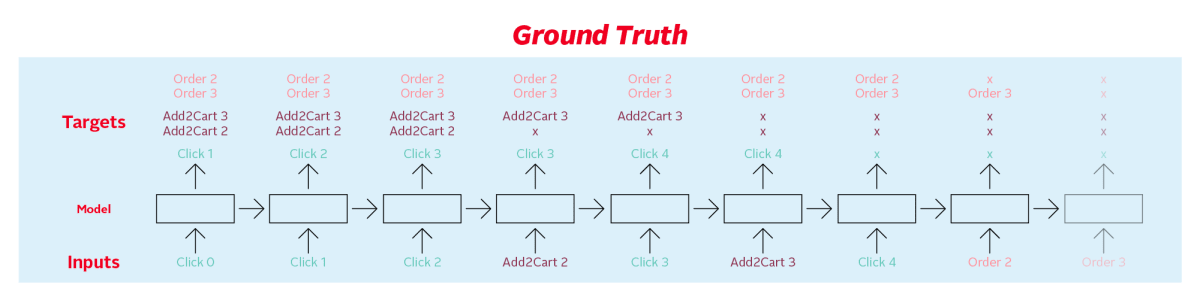
データは4週間のインタラクション履歴からなり、最初の3週間がtrain, 最後の1週間がtestデータとして渡されています。なお、train, testデータに含まれるユーザには被りがないです。
また、testデータのユーザのセッションはランダムな時点以降がdropされており、このdropされた期間にインタラクションしたアイテムを予測します。
実線までが入力データとして与えられ、点線以降のインタラクションを予測する感じです。

ランダムな時点でdropされるので、入力データが少なく、予測対象が多いユーザや逆もあり、簡単に当てられるユーザ・そうでないユーザがいるのが特徴です。
評価は各インタラクションのRecall@20の重み付き和で計算されます。

Clickのみ、drop後に最初にインタラクションしたアイテムのみが正解となります。
解法
概要
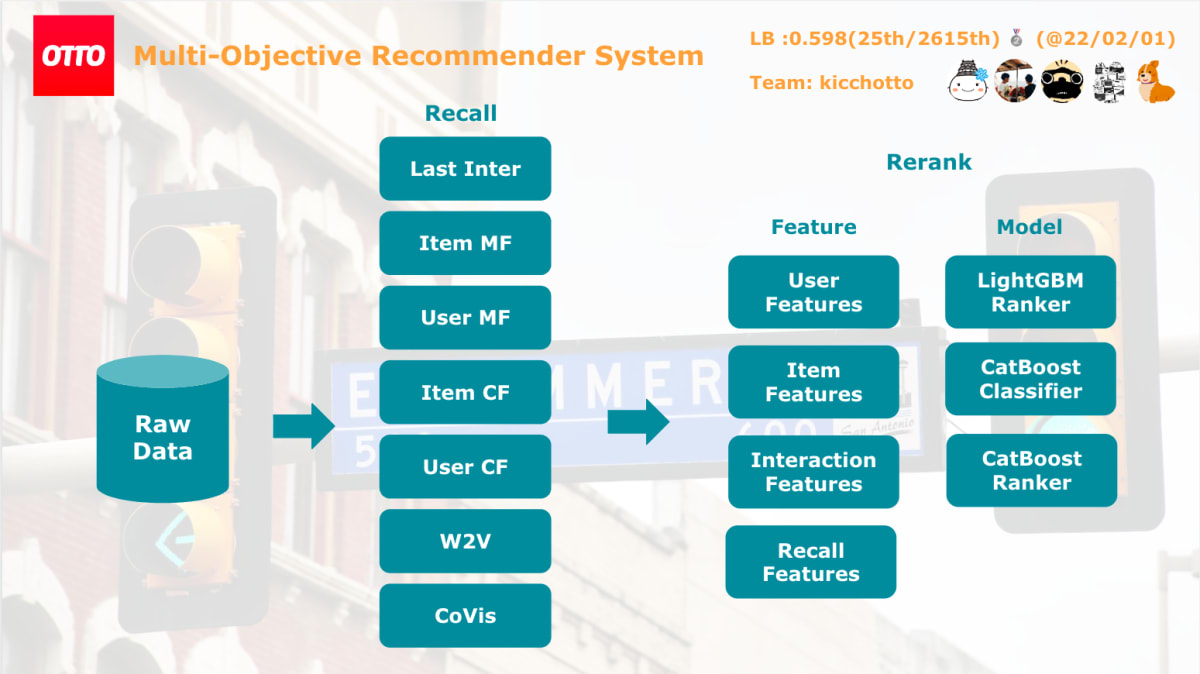
各ユーザにインタラクションしそうなアイテムを推薦候補対象として与えるCandidate Generationとその推論候補を並び替えるRerankの2stage modelで実装しました。
ざっくりとこんな感じ。
CV Strategy
CV時は与えられたtrainデータの最終1週間をtestデータ(図のValidationData)として利用することで計算しました。利用するデータは下記のように用途によって変えています。
(ランダムな時点でdropされた以前をDataB,それ以降をDataAと表現しています。)

| Step | CV | LB |
|---|---|---|
| Candidate Generation | TrainData + ValidDataA | TrainData + ValidDataA + ValidDataB + TestDataA |
| User Feature Creation | ValidDataA | TestDataA |
| Item Feature Creation | TrainData + ValidDataA | TrainData + ValidDataA + ValidDataB + TestDataA |
| User-Item Feature Creation | ValidDataA | TestDataA |
| Re-Ranking | ValidDataA | TestDataA |
また、検証時は5%のユーザを使って実験を高速化して行っていました。このサブセットとcv,lbの相関が取れていたので、サクサク仮説検証ができました。
Candidate Generation
複数のロジックでユーザーがインタラクションしそうな候補を選び、それをouter joinして学習・推論データを用意します。下記のように各ロジックのスコアや、ロジック内の順位、いくつのロジックで選ばれたか、なども特徴量に含めています。
各ロジックで40件程度取得してきて、1ユーザ最大300件程度の候補を与えています。
| session | aid | cg_selected_cnt | cg_A_score | cg_A_rank | cg_B_score |
|---|---|---|---|---|---|
| s1 | a1 | 5 | 0.9 | 1 | null |
| s1 | a2 | 4 | 0.6 | 2 | 0.7 |
| s1 | a3 | 2 | 0.3 | 3 | 0.3 |
以下にそれぞれ利用した、候補集合ロジックについて紹介します。
Item Collaboration Filtering
まず各itemペアに類似度を計算します。下記の気持ちを込めて定式化してます。
- 近い時刻同士にインタラクションしてるアイテムは類似度が高くする
- 人気のアイテムの影響度は小さくする
- たくさんインタラクションしている人の影響度は小さくする
その後、ユーザがインタラクションしたアイテムに上記の類似度を使って、近いitemをjoinし、集約することでユーザが関心あるアイテム選びます。
MatrixFactorization
nn.Embeddingの積が正例>負例となるようにBPRLoss()で最適化し、学習を行いました。こちらもitemCFと同様に人気バイアスを打ち消すような項を追加することで精度向上しました。
class ItemMFPopBiasModel(nn.Module):
def __init__(self, n_aid: int, n_factors: int):
super().__init__()
self.n_factors = n_factors
self.n_aid = n_aid
self.aid_embeddings = nn.Embedding(self.n_aid, self.n_factors, sparse=False)
self.criterion = BPRLoss()
# self.dropout = nn.Dropout(0.2)
nn.init.normal_(self.aid_embeddings.weight.data, mean=0, std=1.0 / self.n_factors)
def forward(self, aid_x, aid_y, size_x, size_y):
aid_x = self.aid_embeddings(aid_x)
aid_y = self.aid_embeddings(aid_y)
return (aid_x * aid_y).sum(dim=1) * size_x * size_y
def calc_loss(self, aid_x, aid_y, size_x, size_y):
rand_idx = torch.randperm(aid_y.size(0))
output_pos = self.forward(aid_x, aid_y, size_x, size_y)
output_neg = self.forward(aid_x, aid_y[rand_idx], size_x, size_y[rand_idx])
loss = self.criterion(output_pos, output_neg)
return loss
候補アイテムの選出には、ユーザが最後にインタラクションしたアイテムをクエリにしたり、session全体のアイテムをクエリにしたり、バリエーションをもたせています。
その他
他にも下記のような手法で候補を選定しました。
- 共起行列
- 過去にユーザがインタラクションしたアイテム
- Word2Vec
- UserMF
- UserCF
Feature
時刻や出現回数、候補集合のスコアの集約関数等を使ってFeatureを生成しました。精度への寄与率は候補の質 > Featureの質、という感じでした。
- pl.col(’ts’).agg([mean,min,max,std]).over({’session’ or ‘aid’})
- candidate_selected_(count, rank)
- candidate_(score, rank, selected)
- (inter, click, cart, order)_hour_mean.over({’session’ or ‘aid’})
- (inter, click, cart, order)_count.over({’session’ or ‘aid’})@(3d, 7d, 14d, 21d)
- aid_multi_(inter,click,cart,order)_prob
下記がlightGBMのFeature Imporatanceです。

Model
下記で学習した結果をアンサンブルして提出しました。
予測はclick,cart,orderそれぞれを0,1で予測したり cart+orderで予測したりしたものを混ぜてます。
- LightGBM Ranker (lambdarank)
- CatBoost Classifier (Logloss)
- CatBoost Ranker (YetiRank)
やったけど効かなかったこと
- Transformers
- GRU
- CDAE
- RecVAE
- Implicit(ALS, BPR)
- Clustering by item embeddings
- Popular items
- Stacking
- Psuedo Labeling
- CV抜きでのフルデータ学習
やりたかったけどできなかったこと
- 更新式の計算量を落としたiALSを実装して大きなn_factorsで実験
- Transformerを含むNN系での学習の収斂
- wandbとかできれいに実験管理
- 各候補集合の優先度や取得候補数の最適化
学び
- Polars早いし使いやすい
- Transformer等のアーキテクチャ云々より、lossやweight設計にどんなアイテムを推薦したいかの気持ちを乗せるのが大事
- Candidate, Featureの中間出力を都度保存すると実験サイクルを早く回せる
- 特に各classにexp_nameを含んだ状態で、pathを隠蔽すると、呼び出し側で意識しないで実験できる
- 計算機を休ませないような仕組みをもっと作ればsubしやすかったかも
感想
実装量が多く、非常にやりがいのあるコンペでした。。。
省メモリ方法や各Candidateの手法、どうすれば精度に効くか、など理解できたので、しっかり復習して業務にも生かしていきたいです 💪
チームのメンバー、特にリーダーの@kiccho101くんにはずっとチームをリードしてもらい感謝です、、ありがとうございました!
Discussion