Logstash の代わりに Vector でログをフィルタリングする
以前に書いた以下の記事では filebeat, losgtash, elasticsearch, kibana を使って k8s クラスタ上のログを収集・可視化する方法を紹介しました。
上記の組み合わせは ELK スタックと呼ばれ、elasticsearch をログの分析・可視化基盤として使う際によく使用される組み合わせになっています。参考: https://aws.amazon.com/jp/what-is/elk-stack/
機能的にはこれで十分なのですが、logstash には以下のような欠点?もあります。
- ログの parse や整形処理を記述する際に独自の conf ファイルを使用するため初期の学習コストがやや高い
- ドキュメント の記述量が多く、設定の調整やトラブルシューティングが難しいことがある。
- jvm ベースのアプリケーションでなのでリソース使用量が多くなることがある(規模や設定にもよりますが)。
そこで logstash の機能が代替できる Product がないか探していたところ Vector が良さそうだったので、今回は logstash の代わりに vector を使ってログの収集・フィルタリング・整形を行う方法を調べてみます。
概要
Vector とは
vector は observability パイプラインを構成するための Rust 製 OSS ツールとなっています。エージェントや aggregator として機能し、ログだけでなくメトリクスやトレースなどのデータを収集し、加工・整形して様々なデータストアに送信することができます。ざっくりまとめると filebeat や fluentd、 prometheus の exporter などの機能を組み合わせたツールといったイメージです。
Rust 製だけあってパフォーマンスの高さも強調されており、github comparison に filebeat や logstash, fluentd など既存のエージェントツールとの比較が記載されています。
| Test | Vector | Filebeat | FluentBit | FluentD | Logstash | SplunkUF | SplunkHF |
|---|---|---|---|---|---|---|---|
| TCP to Blackhole | 86mib/s | n/a | 64.4mib/s | 27.7mib/s | 40.6mib/s | n/a | n/a |
| File to TCP | 76.7mib/s | 7.8mib/s | 35mib/s | 26.1mib/s | 3.1mib/s | 40.1mib/s | 39mib/s |
| Regex Parsing | 13.2mib/s | n/a | 20.5mib/s | 2.6mib/s | 4.6mib/s | n/a | 7.8mib/s |
| TCP to HTTP | 26.7mib/s | n/a | 19.6mib/s | <1mib/s | 2.7mib/s | n/a | n/a |
| TCP to TCP | 69.9mib/s | 5mib/s | 67.1mib/s | 3.9mib/s | 10mib/s | 70.4mib/s | 7.6mib/s |
もちろん具体的な数値に関しては環境や設定によって変わるので vector が最適とは断言できませんが、総合的に見て既存のツールよりも高い性能が出そうな雰囲気が伺えます。
デプロイロール
Vector ではログを収集するために Daemon, Sidecar, Aggregator という 3 つのデプロイパターンが提供されており、ドキュメントでは Deployment Role と呼んでいます。
Daemon
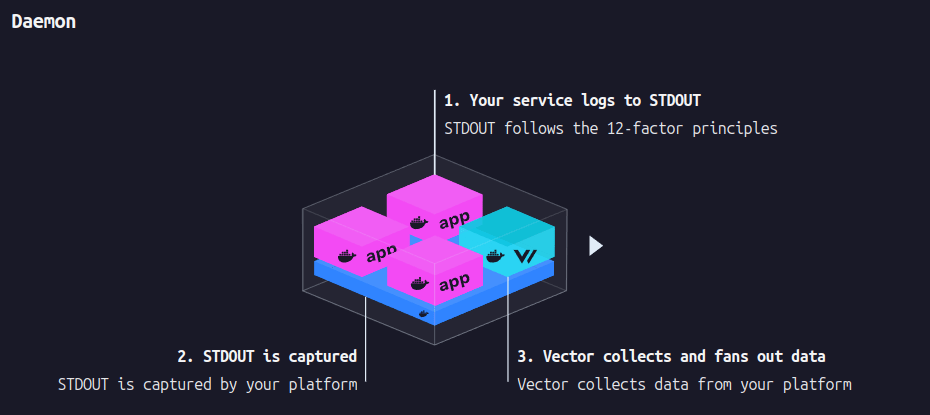
引用: https://vector.dev/docs/setup/deployment/roles/
Daemon ではノード毎に vector をデプロイして、ノード上の /var/log/pod などに出力された pod ログやその他 node レベルのログを収集・送信する方式です。これは前記事の filebeat と同様の方式で、効率よくログを収集できるため基本的にこれが推奨されるとのこと。
Sidecar
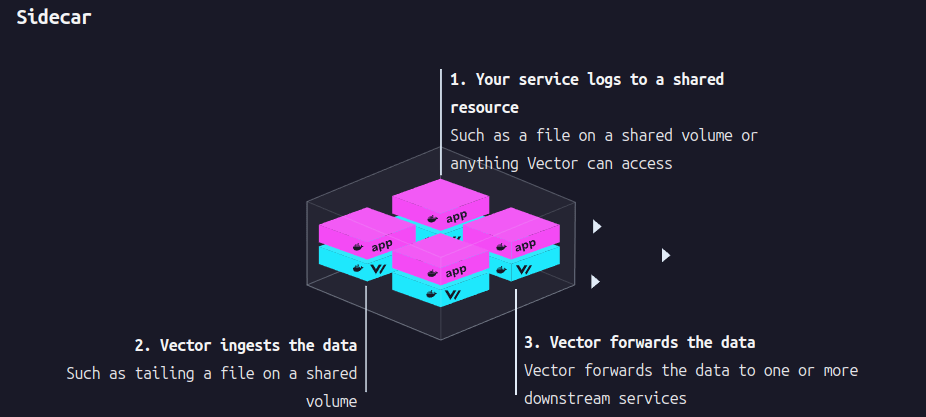
引用: https://vector.dev/docs/setup/deployment/roles/
Sidecar は k8s の Sidecar container with a logging agent のように pod 内に vector コンテナを入れてログを収集する方式です。基本的には上記の Daemon 方式が推奨されていますが、アプリケーションコンテナが stdout/stderr ではなくファイルに出力したログを収集する際など一部のユースケースでは有効。
Aggregator

引用: https://vector.dev/docs/setup/deployment/roles/
Aggregator は上記の 2 つの方式とは異なり、別のデータソースから受信したログの整形、フィルタリング、集計などを行って別のデータソースに送信する役割となっています。前回の構成でいうと logstash の部分に相当。
ドキュメントにも書いてありますが、vector は filebeat のような logging エージェントの役割だけでなく logstash や elasticsearch のような aggregator の機能も持っていることが特徴的となっています。
For Vector, this role should be reserved for exactly that: cross-host aggregation and analysis. Vector is unique in the fact that it can serve both as an Agent and an Aggregator. This makes it possible to distribute processing along the edge (recommended).
daemon, aggregator については helm でインストールする際のパラメータで切り替えることが可能です。参考: https://vector.dev/docs/setup/installation/package-managers/helm/
sidecar は自分で vector 設定ファイルと vector pod の定義を既存の pod に追加してデプロイする方法になっています。以下を参考。
- https://blog.cubieserver.de/2023/vector-logging-sidecar/
- https://github.com/vectordotdev/vector/issues/5254
検証構成
今回は logstash の機能を vector で代替するため、前の記事と同様に filebeat が k8s クラスタから収集したログを vector で受信し、elasticsearch に送信する構成を検証します。

構成図
vector にも kubernetes logs を収集できる機能 があるので filebeat も置き換えることができますが、ひとまず上記の構成で動作を見ていきます。上記の vector はデプロイロールでいうと aggregator に相当します。
インストール
vector は 以下の 3 通り で k8s クラスタ上にデプロイできます。
- マニフェストを直接適用する
- helm でインストールする
- vector operator でインストールする
最初は vector operator を使ったインストール方法を試しましたが後述の vector 設定がうまく反映されない問題があったので、ここでは helm を使ってインストールします。
設定のカスタマイズを行うため helm chart の values をファイルに書き出します。
helm repo add vector https://helm.vector.dev
helm show values vector/vector > values.yml
vector 設定のカスタマイズ
filebeat から送信されたログを vector で受け取るためには logstash source を利用します。
Sources の名前は logstash となっていますが、 example に記載の通り filebeat や heartbeat などの beat agent から直接データを受け取れるようになっているため、logstash を利用しない場合もこの source でログを受信できます。設定項目は type と受信を待ち受ける address を指定すれば ok.
sources:
filebeat:
address: 0.0.0.0:9000
type: logstash
vector では上記のようなデータの送受信や加工に関する設定は configuration に記載します。helm chart によるインストールではデフォルトの configuration が自動で configmap として作成されますが、 values の existingConfigMaps や customConfig を通じて設定をカスタマイズできるようになっています。
# existingConfigMaps -- List of existing ConfigMaps for Vector's configuration instead of creating a new one. Requires
# dataDir to be set. Additionally, containerPorts, service.ports, and serviceHeadless.ports should be specified based on
# your supplied configuration. If set, this parameter takes precedence over customConfig and the chart's default configs.
existingConfigMaps: []
# customConfig -- Override Vector's default configs, if used **all** options need to be specified. This section supports
# using helm templates to populate dynamic values. See Vector's [configuration documentation](https://vector.dev/docs/reference/configuration/)
# for all options.
customConfig: {}
# data_dir: /vector-data-dir
helm での指定方法はこちらも参照。
どちらを使ってもいいですが、ここでは事前に設定ファイルを configmap として作成して existingConfigMaps に指定する方法にします。
vector が受信したログは前回と同様に elasticsearch に送信するため、elasticsearch sink を使ってログ送信します。
パラメータは次のように設定。
- bulk.index: ログを保存する elasticsearch の index 名
- endpoints: elasticsearch のホスト名とポート番号
- inputs: ログを受信する source の名前。ここでは上記の source の
filebeatを指定 - type: elasticsearch を指定
sinks:
elasticsearch:
type: elasticsearch
bulk:
index: vector-%Y-%m-%d
endpoints:
- http://192.168.3.180:9200
inputs:
- filebeat
ここでは宛先 elasticsearch は http 接続、認証なしの設定にしています。認証や https で通信する場合は auth など対応する項目を追加する必要があります。
ここまでの設定項目をまとめると、vector の configuration に対応する configmap は以下のようになります(api 等はデフォルト設定をもとに指定)。
apiVersion: v1
kind: ConfigMap
metadata:
name: vector
namespace: vector
data:
vector.yaml: |
api:
address: 127.0.0.1:8686
enabled: true
playground: true
data_dir: /vector-data-dir
sources:
filebeat:
address: 0.0.0.0:9000
type: logstash
sinks:
elasticsearch:
bulk:
index: vector-%Y-%m-%d
endpoints:
- http://192.168.3.180:9200
inputs:
- filebeat
type: elasticsearch
kubectl apply -f vector.yml で configmap を作成。
values.yml では上記で作成した configmap 名を existingConfigMaps に指定します。また、existingConfigMaps を指定する場合は以下の設定も必要になります。
- dataDir: vector のデータディレクトリ
- services.ports: vector pod に関連付けられる service の port 設定。ここでは api と source logstash の port を指定。
existingConfigMaps:
- vector
services:
ports:
- name: api
port: 8686
protocol: TCP
targetPort: 8686
- name: logstash
port: 9000
protocol: TCP
targetPort: 9000
dataDir: /vector-data-dir
まだログの parse 処理は設定していませんが、いったん vector をデプロイして動作を確認します。
helm install vector vector/vector \
--namespace vector \
--create-namespace \
--values values.yml
これにより vector pod が起動し、filebeat からのログを受信して elasticsearch に送信する設定が完了します。pod ログより port 9000 で beat からの通信を待ち受けていることが確認できます。
$ k logs vector-0 vector
2025-01-27T10:54:31.534682Z INFO vector::app: Log level is enabled. level="info"
2025-01-27T10:54:31.535147Z INFO vector::app: Loading configs. paths=["/etc/vector"]
2025-01-27T10:54:31.564484Z INFO vector::topology::running: Running healthchecks.
2025-01-27T10:54:31.564569Z INFO vector: Vector has started. debug="false" version="0.44.0" arch="x86_64" revision="3cdc7c3 2025-01-13 21:26:04.735691656"
2025-01-27T10:54:31.564734Z INFO source{component_kind="source" component_id=filebeat component_type=logstash}: vector::sources::util::net::tcp: Listening. addr=0.0.0.0:9000
2025-01-27T10:54:31.565351Z INFO vector::internal_events::api: API server running. address=127.0.0.1:8686 playground=http://127.0.0.1:8686/playground graphql=http://127.0.0.1:8686/graphql
2025-01-27T10:54:31.566941Z INFO vector::topology::builder: Healthcheck passed.
filebeat の設定
filebeat は 前回の記事 と同じで helm を使ってデプロイします。
設定は上記記事とほぼ同じですが、output には logstash を設定し、vector の svc 名、port を指定します。
output.logstash:
host: '${NODE_NAME}'
hosts: ["vector:9000"]
values.yml の中身は以下
values.yml
daemonset:
...
extraEnvs: []
# - name: "ELASTICSEARCH_USERNAME"
# valueFrom:
# secretKeyRef:
# name: elasticsearch-master-credentials
# key: username
# - name: "ELASTICSEARCH_PASSWORD"
# valueFrom:
# secretKeyRef:
# name: elasticsearch-master-credentials
# key: password
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: filestream
paths:
- /var/log/syslog
include_lines:
- 'kubelet'
tags:
- kubelet
processors:
- add_fields:
target: ""
fields:
cluster: k8s-control
- type: container
paths:
- /var/log/containers/*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- add_fields:
target: ""
fields:
cluster: k8s-cluster
output.logstash:
host: '${NODE_NAME}'
hosts: ["vector:9000"]
secretMounts: []
# - name: elasticsearch-master-certs
# secretName: elasticsearch-master-certs
# path: /usr/share/filebeat/certs/
# - name: filebeat-certificates
# secretName: filebeat-certificates
# path: /usr/share/filebeat/certs
filebeat をデプロイ。
helm install filebeat elastic/filebeat \
--namespace vector \
--values values.yml
ログの確認
これで k8s pod のログが filebeat → vector → elasticsearch に送信されるので kibana から確認できるようになります。
ログの整形や加工はまだ行っていないので、送信されたログは生のログメッセージ + filebeat や vector によって設定されたフィールドが含まれています。試しに etcd pod のログを見てみると以下のような内容となっています。
etcd のログ
pod のメッセージは message に対応
_index: vector-2025-01-26
_id: 9_KeopQBmjaOKqG9cLZE
_version: 1
_ignored:
- message.keyword
_source:
'@metadata':
beat: filebeat
type: _doc
version: 8.5.1
'@timestamp': "2025-01-26T12:37:54.567Z"
agent:
ephemeral_id: 6850ba87-f4f3-4534-b935-e7a9b2e4e99c
id: 3265a7ee-08db-42e7-8224-299ca0582b39
name: filebeat-filebeat-zxm9v
type: filebeat
version: 8.5.1
cluster: k8s-cluster
container:
id: f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd
image:
name: registry.k8s.io/etcd:3.5.15-0
runtime: containerd
ecs:
version: 8.0.0
host:
name: filebeat-filebeat-zxm9v
input:
type: container
kubernetes:
container:
name: etcd
labels:
component: etcd
tier: control-plane
namespace: kube-system
namespace_labels:
kubernetes_io/metadata_name: kube-system
namespace_uid: e366417f-78ef-4175-a721-d78a7602481a
node:
hostname: k8s-m1
labels:
beta_kubernetes_io/arch: amd64
beta_kubernetes_io/os: linux
kubernetes_io/arch: amd64
kubernetes_io/hostname: k8s-m1
kubernetes_io/os: linux
node-role_kubernetes_io/control-plane: ""
node_kubernetes_io/exclude-from-external-load-balancers: ""
name: k8s-m1
uid: e76bf0f2-d222-4233-9cd3-f39e03fc2091
pod:
ip: 10.0.0.40
name: etcd-k8s-m1
uid: fc260fad-d780-4ac2-be72-8af1cb125e8b
log:
file:
path: /var/log/containers/etcd-k8s-m1_kube-system_etcd-f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd.log
offset: 5162710
message: '{"level":"info","ts":"2025-01-26T12:37:54.566933Z","caller":"traceutil/trace.go:171","msg":"trace[1718877744] transaction","detail":"{read_only:false; response_revision:4895789; number_of_response:1; }","duration":"132.491495ms","start":"2025-01-26T12:37:54.434417Z","end":"2025-01-26T12:37:54.566908Z","steps":["trace[1718877744] ''process raft request'' (duration: 109.983011ms)","trace[1718877744] ''compare'' (duration: 22.392708ms)"],"step_count":2}'
source_type: logstash
stream: stderr
timestamp: "2025-01-26T12:37:54.567Z"
fields:
agent.version.keyword:
- 8.5.1
cluster:
- k8s-cluster
kubernetes.node.uid:
- e76bf0f2-d222-4233-9cd3-f39e03fc2091
kubernetes.namespace_uid.keyword:
- e366417f-78ef-4175-a721-d78a7602481a
host.name.keyword:
- filebeat-filebeat-zxm9v
kubernetes.namespace_uid:
- e366417f-78ef-4175-a721-d78a7602481a
kubernetes.node.labels.kubernetes_io/os:
- linux
container.id:
- f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd
kubernetes.labels.component.keyword:
- etcd
kubernetes.node.labels.kubernetes_io/os.keyword:
- linux
ecs.version.keyword:
- 8.0.0
container.image.name:
- registry.k8s.io/etcd:3.5.15-0
kubernetes.container.name.keyword:
- etcd
kubernetes.namespace:
- kube-system
kubernetes.node.labels.beta_kubernetes_io/os:
- linux
kubernetes.pod.name.keyword:
- etcd-k8s-m1
agent.name:
- filebeat-filebeat-zxm9v
host.name:
- filebeat-filebeat-zxm9v
kubernetes.node.labels.kubernetes_io/hostname.keyword:
- k8s-m1
agent.id.keyword:
- 3265a7ee-08db-42e7-8224-299ca0582b39
kubernetes.node.labels.node-role_kubernetes_io/control-plane.keyword:
- ""
input.type:
- container
kubernetes.node.uid.keyword:
- e76bf0f2-d222-4233-9cd3-f39e03fc2091
source_type:
- logstash
log.offset:
- 5162710
'@metadata.version':
- 8.5.1
container.runtime:
- containerd
agent.id:
- 3265a7ee-08db-42e7-8224-299ca0582b39
'@metadata.type':
- _doc
ecs.version:
- 8.0.0
'@metadata.beat':
- filebeat
kubernetes.node.labels.node-role_kubernetes_io/control-plane:
- ""
agent.version:
- 8.5.1
kubernetes.labels.tier.keyword:
- control-plane
kubernetes.namespace.keyword:
- kube-system
kubernetes.node.name:
- k8s-m1
input.type.keyword:
- container
stream.keyword:
- stderr
kubernetes.node.hostname:
- k8s-m1
'@metadata.version.keyword':
- 8.5.1
kubernetes.node.name.keyword:
- k8s-m1
kubernetes.pod.uid:
- fc260fad-d780-4ac2-be72-8af1cb125e8b
kubernetes.node.hostname.keyword:
- k8s-m1
'@metadata.beat.keyword':
- filebeat
agent.type:
- filebeat
stream:
- stderr
kubernetes.node.labels.kubernetes_io/arch.keyword:
- amd64
kubernetes.pod.name:
- etcd-k8s-m1
source_type.keyword:
- logstash
container.image.name.keyword:
- registry.k8s.io/etcd:3.5.15-0
log.file.path.keyword:
- /var/log/containers/etcd-k8s-m1_kube-system_etcd-f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd.log
agent.type.keyword:
- filebeat
kubernetes.pod.ip:
- 10.0.0.40
timestamp:
- "2025-01-26T12:37:54.567Z"
agent.ephemeral_id.keyword:
- 6850ba87-f4f3-4534-b935-e7a9b2e4e99c
kubernetes.container.name:
- etcd
agent.name.keyword:
- filebeat-filebeat-zxm9v
kubernetes.node.labels.beta_kubernetes_io/arch.keyword:
- amd64
kubernetes.namespace_labels.kubernetes_io/metadata_name:
- kube-system
cluster.keyword:
- k8s-cluster
message:
- '{"level":"info","ts":"2025-01-26T12:37:54.566933Z","caller":"traceutil/trace.go:171","msg":"trace[1718877744] transaction","detail":"{read_only:false; response_revision:4895789; number_of_response:1; }","duration":"132.491495ms","start":"2025-01-26T12:37:54.434417Z","end":"2025-01-26T12:37:54.566908Z","steps":["trace[1718877744] ''process raft request'' (duration: 109.983011ms)","trace[1718877744] ''compare'' (duration: 22.392708ms)"],"step_count":2}'
kubernetes.labels.tier:
- control-plane
kubernetes.node.labels.kubernetes_io/hostname:
- k8s-m1
kubernetes.labels.component:
- etcd
kubernetes.node.labels.beta_kubernetes_io/arch:
- amd64
'@timestamp':
- "2025-01-26T12:37:54.567Z"
kubernetes.pod.uid.keyword:
- fc260fad-d780-4ac2-be72-8af1cb125e8b
container.runtime.keyword:
- containerd
kubernetes.namespace_labels.kubernetes_io/metadata_name.keyword:
- kube-system
kubernetes.node.labels.node_kubernetes_io/exclude-from-external-load-balancers.keyword:
- ""
log.file.path:
- /var/log/containers/etcd-k8s-m1_kube-system_etcd-f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd.log
agent.ephemeral_id:
- 6850ba87-f4f3-4534-b935-e7a9b2e4e99c
kubernetes.node.labels.kubernetes_io/arch:
- amd64
container.id.keyword:
- f1ef45444698b5dd23745bd92452e431819fa5d203c27272b8c26869968a8ccd
kubernetes.node.labels.beta_kubernetes_io/os.keyword:
- linux
kubernetes.node.labels.node_kubernetes_io/exclude-from-external-load-balancers:
- ""
kubernetes.pod.ip.keyword:
- 10.0.0.40
'@metadata.type.keyword':
- _doc
ignored_field_values:
message.keyword:
- '{"level":"info","ts":"2025-01-26T12:37:54.566933Z","caller":"traceutil/trace.go:171","msg":"trace[1718877744] transaction","detail":"{read_only:false; response_revision:4895789; number_of_response:1; }","duration":"132.491495ms","start":"2025-01-26T12:37:54.434417Z","end":"2025-01-26T12:37:54.566908Z","steps":["trace[1718877744] ''process raft request'' (duration: 109.983011ms)","trace[1718877744] ''compare'' (duration: 22.392708ms)"],"step_count":2}'
ログを parse する
vector を介したログ送受信が確認できたので、次に vector を使ってログのフィルタリングや整形をやっていきます。vector では transform で受信したデータを送信する前にフィルタリングや整形、集計などの操作を実行できるようになっています。
transform にもいくつか種類がありますが、ログデータの抽出・加工には Vector Remap Language (VRL) による remap を使うのが有効です。詳細はこちら https://vector.dev/blog/vector-remap-language/
filebeat から受信したログを parse するにはログの形式に合わせた VRL を記述する必要がありますが、VRL playground ではブラウザ上で動作を確認できるようになっているので、まずはこれで対象ログの形式と VRL の動作を確認するところから始めるのがおすすめです。
例えば、以下のような k8s pod のログを見やすくするためにフィールド毎に抽出することを考えます。
{
"message": "{\"level\":\"info\",\"ts\":\"2025-01-26T13:53:41.337903Z\",\"caller\":\"traceutil/trace.go:171\",\"msg\":\"trace[1296786419] transaction\",\"detail\":\"{read_only:false; response_revision:4909691; number_of_response:1; }\",\"duration\":\"157.30959ms\",\"start\":\"2025-01-26T13:53:41.180574Z\",\"end\":\"2025-01-26T13:53:41.337883Z\",\"steps\":[\"trace[1296786419] 'process raft request' (duration: 156.747673ms)\"],\"step_count\":1}"
}
VRL では syslog, json, klog など有名どころのログ形式を処理するための parse_xxx 関数が事前に用意されており、ある程度は自分でログ抽出のパターンを書かなくても適切に抽出できるようになっています。
上記のような json 形式の文字列は parse_json を使うことで key-value 形式に変換できます。その他に VRL の記述では以下のような記述でフィールドの新規追加や整形・不要なフィールドを削除できるようになっています。
.json, err = parse_json(.message)
if !is_null(err) {
abort
}
.json_level = .json.level
.json_ts = .json.ts
.json_caller = .json.caller
.json_msg = .json.msg
.json_revision = .json.revision
del(.message)
-
.json, err = parse_json(.message)で .message の文字列を parse して json フィールドに設定 - VRL では
.[var_name]で既存のフィールドを参照する。存在しない場合は新規にフィールドを追加する。 - もとの message は不要なので
del(.message)で削除
playground 上の Program に上記の VRL を書いて Run program を実行すると、もとの message に含まれていた値が json フィールド以下に設定され、トップレベルに json_xxxx というフィールドが新規追加されることがわかります。
{
"json": {
"caller": "traceutil/trace.go:171",
"detail": "{read_only:false; response_revision:4909691; number_of_response:1; }",
"duration": "157.30959ms",
"end": "2025-01-26T13:53:41.337883Z",
"level": "info",
"msg": "trace[1296786419] transaction",
"start": "2025-01-26T13:53:41.180574Z",
"step_count": 1,
"steps": [
"trace[1296786419] 'process raft request' (duration: 156.747673ms)"
],
"ts": "2025-01-26T13:53:41.337903Z"
},
"json_caller": "traceutil/trace.go:171",
"json_level": "info",
"json_msg": "trace[1296786419] transaction",
"json_revision": null,
"json_ts": "2025-01-26T13:53:41.337903Z"
}
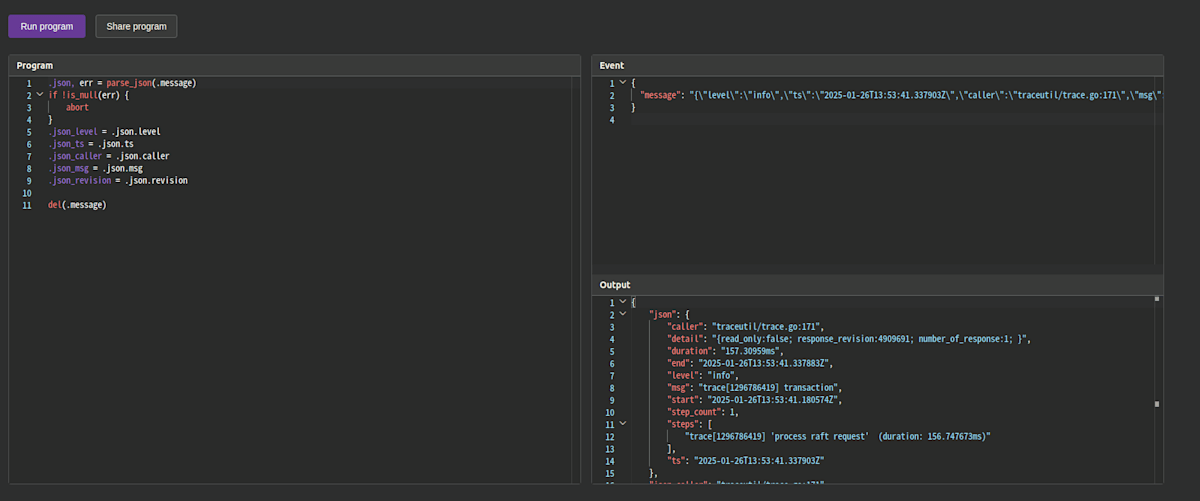
playground 上の実行結果
このように VRL を使うことでログの加工やフィルタリングが柔軟に行えるようになります。
etcd pod はちょうど上記の parse_json で抽出できる形式のログになっているので、実際に elasticsearch 上に送信されたログのフィールドが適切に抽出されることを確認してみます。上記の VRL を適用するため先ほど作成した configmap を以下のように変更。
apiVersion: v1
kind: ConfigMap
metadata:
name: vector
namespace: vector
data:
vector.yaml: |
api:
address: 127.0.0.1:8686
enabled: true
playground: true
data_dir: /vector-data-dir
sources:
filebeat:
address: 0.0.0.0:9000
type: logstash
+ transform:
+ etcd_filter:
+ type: filter
+ inputs:
+ - filebeat
+ condition: '.kubernetes.labels.component == "etcd"'
+ etcd_parse:
+ type: remap
+ inputs:
+ - filebeat
+ source: |
+ .json, err = parse_json(.message)
+ if !is_null(err) {
+ abort
+ }
+ del(.message)
sinks:
elasticsearch:
bulk:
index: vector-%Y-%m-%d
endpoints:
- http://192.168.3.180:9200
inputs:
- - filebeat
+ + etcd_parse
type: elasticsearch
stdout:
encoding:
codec: json
inputs:
- filebeat
type: console
configmap を変更したら pod を一度削除して変更を適用します。
k apply -f vector.yml
k delete pod vector-0
kibana で elasticsearch に送信されたログを見てみると、たしかに json 以下のフィールドに caller や level, msg が parse されていることが確認できます。

このように VRL を使うことでログの加工やフィルタリングが柔軟に行えるようになっています。
カスタムログの parse
既存の parse_xxx に当てはまらない形式のログに関しては parse_regex を使うことで正規表現形式で各フィールドを抽出できるようになっています。
例えば、以下のような自作アプリケーションのログを vector で parse することを考えてみます。
import logging
import random
import time
# Configure logging
logging.basicConfig(
level=logging.DEBUG,
format="[%(asctime)s] [%(levelname)s] %(message)s",
datefmt="%Y-%m-%dT%H:%M:%SZ",
)
def main():
log_levels = [logging.INFO, logging.WARNING, logging.ERROR, logging.DEBUG]
while True:
log_level = random.choice(log_levels)
logging.log(log_level, "test message")
time.sleep(5) # Wait for 5 seconds before the next log
if __name__ == "__main__":
main()
このアプリのログは以下のような形式になっています。
[2025-01-27T13:54:19Z] [DEBUG] test message
[2025-01-27T13:54:24Z] [WARNING] test message
[2025-01-27T13:54:29Z] [ERROR] test message
[2025-01-27T13:54:34Z] [INFO] test message
これは parse_regex を使った以下のような VRL で各フィールドを抽出できます。
.|= parse_regex!(
.message,
r'^\[(?P<timestamp>\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}Z)\] \[(?P<loglevel>[A-Z]+)\] (?P<logmessage>.*)$'
)
.timestamp = parse_timestamp(.timestamp, "%Y-%m-%d %H:%M:%S") ?? now()
.loglevel = downcase(.loglevel)
del(.message)
transform でログ整形用の type: remap を複数指定する場合は filter transform と condition を組み合わせることで、特定の条件を満たすログのみフィルタを適用することができます。
-
.kubernetes.labels.component == "etcd"のラベルがついているログは etcd_parse を適用 - 上記の自作 app の
.kubernetes.labels.app == "vector-sample"のラベルがついているログは myapp_parse を適用 - 上記に一致しないログには filter を適用しない
transforms:
etcd_filter:
type: filter
inputs:
- filebeat
condition: '.kubernetes.labels.component == "etcd"'
etcd_parse:
type: remap
inputs:
- filebeat
source: |
.json, err = parse_json(.message)
del(.message)
myapp_filter:
type: filter
inputs:
- filebeat
condition: '.kubernetes.labels.app == "vector-sample"'
myapp_parse:
type: remap
inputs:
- myapp_filter
source: |
.|= parse_grok!(.message, "\\[%{TIMESTAMP_ISO8601:timestamp}\\] \\[%{LOGLEVEL:loglevel}\\] %{GREEDYDATA:logmessage}")
.timestamp = parse_timestamp(.timestamp, "%Y-%m-%YT%H:%M:%SZ") ?? now()
del(.message)
others:
type: filter
inputs:
- filebeat
condition: '.kubernetes.labels.component != "etcd" && .kubernetes.labels.app != "vector-sample"'
sinks:
elasticsearch:
type: elasticsearch
bulk:
index: vector-%Y-%m-%d
endpoints:
- http://192.168.3.180:9200
inputs:
- etcd_parse
- myapp_parse
- others
これで etcd pod のログは parse_json で、vector-sample アプリのログは parse_grok でフィールドが抽出されるようになります。
kibana でログを確認すると、どちらも想定通りにフィールドを抽出できていることが確認できます。

myapp のログ。logmessage, loglevel, timestamp が抽出されている。

etcd pod のログ。json.caller や json.msg など json フィールド以下に抽出されている。
OpenObserve にログ送信する
以前の記事では filebeat + logstash のログ送信先として elasticsearch の代わりに openobserve を使う方法について書きました。
o2 用の vector sink は現時点でサポートされていませんが(issue はある)、o2 側のドキュメント に記載の通り http sink か elasticsearch sink を使うことで vector から o2 にデータを送信できるようになっています。ここでは elasticsearch sink を使って送信するため vector.yml を以下のように修正します。
data:
vector.yaml: |
sinks:
elasticsearch:
type: elasticsearch
bulk:
index: vector-%Y-%m-%d
endpoints:
- http://o2-openobserve-router.openobserve:5080/api/myorg # o2 の router のアドレス/api/[org]
inputs:
- etcd_parse
- myapp_parse
- others
auth:
strategy: basic
user: "root@example.com" # o2 のユーザ名
password: "Complexpass#123" # o2 のパスワード
compression: gzip
healthcheck:
enabled: false
o2 は簡単のため最小構成の helm でインストールします。
kubectl apply --server-side -f \
https://raw.githubusercontent.com/cloudnative-pg/cloudnative-pg/release-1.23/releases/cnpg-1.23.1.yaml
helm repo add openobserve https://charts.openobserve.ai
helm repo update
helm install -n openobserve o2 openobserve/openobserve --create-namespace
o2 の web UI (router) にログインして org: myorg, ストリーム: vector-[%Y-%m-%d] に設定してクエリを実行すると、elasticsearch と同様にログが確認できます。
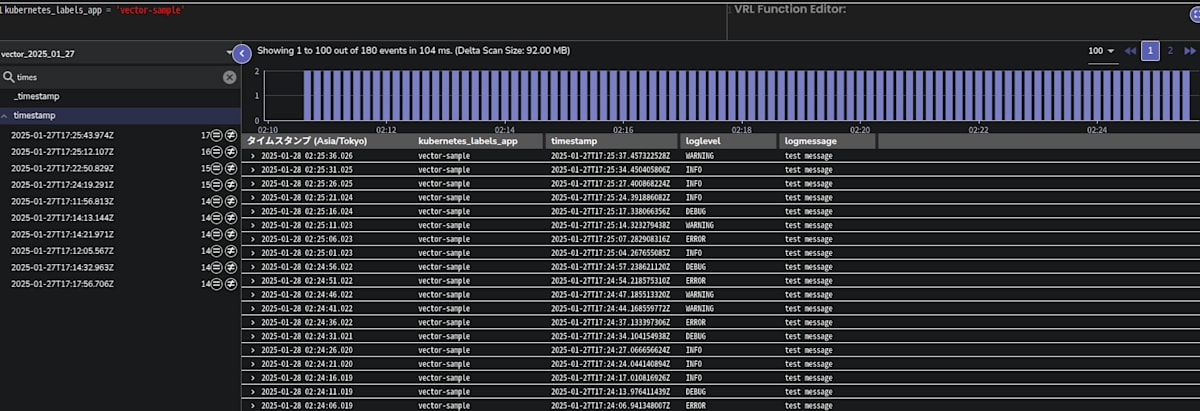
o2 に送信された myapp のログ
o2 自体が elasticsearch との互換性が高いので sink を少し書き換えるだけで簡単に移行できます。
その他
vector でログ収集
Vector デプロイパターンで見たように Daemon では filebeat と同様に pod ログ、および node レベルのログを収集することができます。
helm インストール時に daemon でデプロイするには values.yml で role: "Agent" を指定します。
# Each role is created with the following workloads:
# Agent = DaemonSet
# Aggregator = StatefulSet
# Stateless-Aggregator = Deployment
role: "Agent"
control plane ノード上に配置されるように tolerations も設定
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
これによりクラスタ内の各ノードに daemonset として vector pod が作成されるようになります。
この状態で helm install した際に作成される configmap 内の 設定では以下の要素が収集されます。
-
kubernetes_logs source による
/var/log/pod以下の pod ログ - host metrics source によるノードのメトリクス。メトリクスは rust コードで heim あたりを利用して収集している。https://github.com/vectordotdev/vector/tree/master/src/sources/host_metrics
- internal_metrics source による vector 自身のメトリクス
- 上記のメトリクスは prometheus_exporter で公開。port 9000 /metrics にアクセスすることで prometheus 形式のメトリクスが取得できる。
data:
agent.yaml: |
data_dir: /vector-data-dir
api:
enabled: true
address: 127.0.0.1:8686
playground: false
sources:
kubernetes_logs:
type: kubernetes_logs
host_metrics:
filesystem:
devices:
excludes: [binfmt_misc]
filesystems:
excludes: [binfmt_misc]
mountpoints:
excludes: ["*/proc/sys/fs/binfmt_misc"]
type: host_metrics
internal_metrics:
type: internal_metrics
sinks:
prom_exporter:
type: prometheus_exporter
inputs: [host_metrics, internal_metrics]
address: 0.0.0.0:9090
stdout:
type: console
inputs: [kubernetes_logs]
encoding:
codec: json
kubernetes_logs では /var/log/pod 以下のログのみが収集対象となるのでデフォルトでは node ログは収集されません。収集するには file source で収集対象のログのパスを追加する必要があります。
sources:
kube:
type: kubernetes_logs
syslog:
type: file
include:
- /var/log/syslog
デフォルトでノード上の /var/log などを pod にマウントするように設定されるので volume や mount の設定は不要。
Containers:
vector:
Image: timberio/vector:0.44.0-distroless-libc
Port: <none>
Host Port: <none>
Args:
--config-dir
/etc/vector/
Environment:
VECTOR_LOG: info
VECTOR_SELF_NODE_NAME: (v1:spec.nodeName)
VECTOR_SELF_POD_NAME: (v1:metadata.name)
VECTOR_SELF_POD_NAMESPACE: (v1:metadata.namespace)
PROCFS_ROOT: /host/proc
SYSFS_ROOT: /host/sys
Mounts:
/etc/vector/ from config (ro)
/host/proc from procfs (ro)
/host/sys from sysfs (ro)
/var/lib from var-lib (ro)
/var/log/ from var-log (ro)
/vector-data-dir from data (rw)
上記の設定で pod, node 上のログが収集できるようになります。config に transform も書けば 1 つの vector でログ収集・整形・送信が実行できるため、filebeat + logstash と比べてよりコンパクトな構成になります。
Vector でメトリクス収集
Vector 単体ではメトリクスに関する以下の Source がサポートされています。
Host metrics では Vector pod が稼働するノード上の CPU やメモリ、ディスクなどのリソース使用量に関するメトリクスを収集します。収集されるメトリクス一覧は以下を参照。
これにより Vector を各ノード上のメトリクスを収集するメトリクス収集エージェントとして利用できるようになりますが、クラスタ内の全ノードから収集するにはデプロイロールを Daemon に指定して DaemonSet でデプロイしておく必要があります。
internal_metrics では Vector 自体のアプリケーションに関するメトリクスを収集します。収集される一覧は以下を参照。
出力はいろいろな形式がサポートされていますが、メトリクスで標準的な Prometheus 形式での export, remote write に対応しています。Vector 上でメトリクスを公開して別の prometheus client で scrape する場合には Prometheus Exporter sink を利用し、別の Prometheus エンドポイントにメトリクスを送信する場合は Prometheus Remote Write sink を使います。
例えば o2 では Prometheus Remote Write でのメトリクス送信に対応しているので、Vector pod で収集したメトリクスを o2 に送信する際の config は以下のようになります。
customConfig:
sources:
host_metrics:
type: host_metrics
scrape_interval_secs: 10
filesystem:
devices:
excludes: [binfmt_misc]
filesystems:
excludes: [binfmt_misc]
mountpoints:
excludes: ["*/proc/sys/fs/binfmt_misc"]
internal_metrics:
type: internal_metrics
scrape_interval_secs: 5
sinks:
prom_remote:
type: prometheus_remote_write
inputs:
- host_metrics
- internal_metrics
endpoint: http://o2-openobserve-router.o2:5080/api/k8s-control-plane/prometheus/api/v1/write # o2 の endpoint/api/[org]/prometheus/api/v1/write
auth:
strategy: basic
user: "root@example.com" # o2 のユーザ名
password: "Complexpass#123" # o2 のパスワード
healthcheck:
enabled: false
まとめ
vector では yaml 形式で設定を記載できるため、logstash の config 設定よりも可読性が良く、yaml なので他ツールによる format やポリシーチェックのような統合もやりやすいかと感じました。VRL remap でログの加工やフィルタリングも柔軟に行えるので機能的な面でも特に不足はなく、公表されているパフォーマンスも filebeat や logstash などの既存ツールより優れているため、総合的に見て vector は logstash からの移行先として有力な選択肢になりそうです。
Discussion