Pyroscope による継続的プロファイリングを試す
はじめに
プロファイリングについて
今までの記事では Observability の 3 大要素として Logs, Metrics, Traces を強調してきましたが、近年ではシステムにおける内部情報をより効率的かつ詳細に観測するための手段として他の種類の情報も収集・監視するべきという声もあります。
例えば CNCF が管理する Tag Observability の Whitepaper では、3 大要素に加えて新しいシグナルとして Profile と Dump について記述しています。
In the next sections, we will help you make this decision by digging deeper into each signal, starting with the people's favourites: metrics, logs, and traces, and then the two newly emerging signals: application profiles and crash dumps.
以下の medium の記事では 3 大要素に Profile, Exception, Event を加えた Six Pillar を Observability の要とし、その頭文字をとって TEMPLE と総称しています。この記事の著者は tracing 分野で有名な jaeger の開発者の 1 人となっています。
また、Google Cloud Observability では 3 大要素に加えて Error Reporting, Cloud Profiler を提示しています。
Observability の中でも注目するカテゴリや監視の対象、文脈によって表記は異なりますが、基本的には 3 大要素 +
やや古いですが 2022 年の CNCF のブログ What is continuous profiling でも継続的プロファイリングについて記載されており、ブログ内の画像より 2020 ~ 2022 にかけて主要クラウドプロバイダーのみならず、Data Dog, Elastic, New Relic のような Observability や監視サービスを提供する SaaS でも継続的プロファイリングのための投資や機能が開発されていることがわかります。
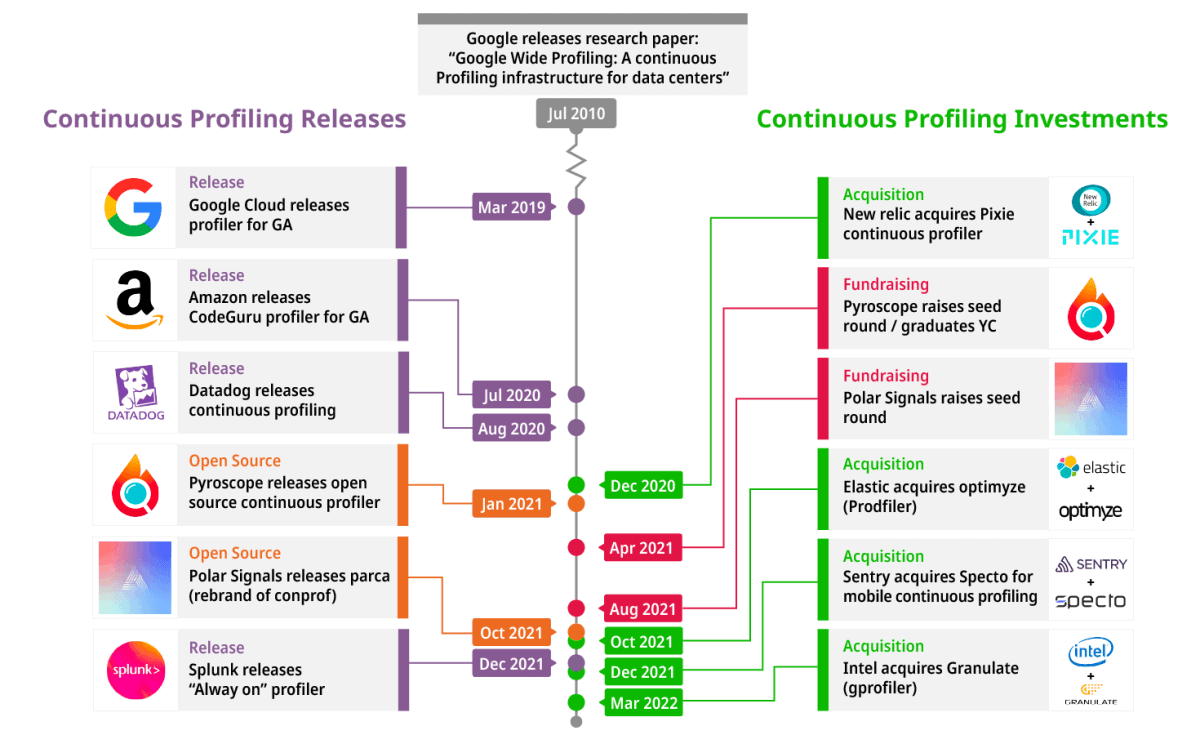
上記のようにアプリケーションの CPU やメモリ使用量を監視し、継続に改善を続けていくにはプロファイリングの重要性が増していることが読み取れます。
Pyroscope
Pyroscope はアプリケーションの継続的プロファイリングを行うための OSS プロジェクトです。上の画像でも書いてありますが、2021 年に OSS としてリリースされた後、2022 年に Grafana が管理する Phlare というプロジェクトと合併され、現在は Grafana が提供する継続的プロファイリングのための OSS プロジェクトという位置づけになっています。
Grafana Pyroscope was formed by the merger of two open source continuous profiling projects: Phlare, which was launched by Grafana Labs in 2022, and Pyroscope, which was founded by Ryan Perry and Dmitry Filimonov in 2021.
Grafana では Observability の 3 大要素をカバーするプロジェクトがそれぞれ存在しており、Pyroscope はこれらと統合してシームレスな設計、データの取り込みができることがアピールされています。
とはいえ Pyroscope は OSS なのでもちろん単体でも使用可能であり、既に logging や tracing に他のプロダクトを利用している場合、継続的プロファイリングの領域は Pyroscope でカバーすると言うようなユースケースも可能です。
また、Pyroscope は継続的プロファイリングの機能を実現するための各コンポーネントがマイクロサービスとして分割されているため、k8s クラスタ上で稼働させることで可用性や Scalability のメリットを享受することができます。Helm により容易に構築できるので、今回は k8s クラスタに pyroscope を構築し、デモアプリケーションを使ってどのようなデータが取れるか見てみます。
インストール
ドキュメントでは docker で単一の Pyroscope コンテナを建てる方法と、helm を使って k8s クラスタにデプロイするする方法が記載されています。
今回は helm でインストールします。ドキュメントでは helm install 時にシングル構成とマイクロサービス構成が選択できますが、ここではシングル構成を選択します。
helm repo add grafana https://grafana.github.io/helm-charts
helm repo update
helm -n pyroscope install pyroscope grafana/pyroscope --create-namespace
ドキュメントの Query profiles in Grafana 以降のセクションでは k8s 上に grafana をインストールし、 pyroscope で収集した profile を grafana 上で確認する方法を記載していますが、grafana が不要だったりすでに構築済みの場合はスキップできます。データは pyroscope の UI からでも確認できるので今回はスキップします。
シングル構成では server と agent pod が 1 つずつ起動します。
pyroscope-0 が pyroscope 本体となっており、profile データの受信、クエリの実行、web UI などが 1 pod にまとまっています。
agent の方は対象のアプリケーションに対して Auto-instrumentation により profile を収集するためのコンポーネントですが今回は使用しません。
$ k get all
NAME READY STATUS RESTARTS AGE
pod/pyroscope-0 1/1 Running 0 33s
pod/pyroscope-agent-0 2/2 Running 0 33s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/pyroscope ClusterIP 10.109.110.186 <none> 4040/TCP 33s
service/pyroscope-agent ClusterIP 10.100.191.57 <none> 80/TCP 33s
service/pyroscope-agent-cluster ClusterIP None <none> 80/TCP 33s
service/pyroscope-headless ClusterIP None <none> 4040/TCP 33s
service/pyroscope-memberlist ClusterIP None <none> 7946/TCP 33s
NAME READY AGE
statefulset.apps/pyroscope 1/1 33s
statefulset.apps/pyroscope-agent 1/1 33s
pod 起動後は service/pyroscope から web UI にアクセス可能できます。この段階では profile 収集対象のアプリケーションがないので pyroscope と pyroscope agent 自身の profile 情報のみが収集されています。
python デモアプリケーションで動作を確認する
アプリケーションから profile データを収集して pyroscope 上で確認するには 2 通りの方法があります。
- 各言語毎に存在する SDK を使ってアプリケーションから pyroscope に profile データを送信する。
- Grafana agent によってアプリケーションに Auto-instrumentation して profile データを収集する。

https://grafana.com/docs/pyroscope/latest/configure-client/ より引用
ドキュメントに 各言語における SDK の使い方の記載があり、Github に各言語毎のデモアプリケーションが用意されているので、まずはこちらを使ってどのようなデータが取れるか見てみます。
python のデモアプリケーションは pyroscope/examples/language-sdk-instrumentation/python/ にあります。デモアプリケーションはユーザが乗り物を必要とする際に注文を行い、car や bike などを手配する Ride share サービスを模擬した内容となっています(本家 Uber みたいなもの)。Github のデモでは以下のサービスをそれぞれ docker コンテナとして作成します。
- 注文を行う client
- 注文を受けて乗り物を手配するサービス (3 リージョン分)
アプリケーションのディレクトリを見ると django, fastapi, flask 用のコードがそれぞれ用意されていますが、今回は flask を使用します。まず Github レポジトリを clone して以下のディレクトリに移動。
git clone --depth 1 https://github.com/grafana/pyroscope.git
cd pyroscope/examples/language-sdk-instrumentation/python/rideshare/flask
pyroscope の送信先は lib/server.py の以下の行で指定されており、デフォルトでは docker compose 時に作成される pyroscope コンテナに送信するよう設定されています。
今回は k8s クラスタ上に構築した pyroscope に送信するので svc のアドレス、または ingress 宛のドメイン名に書き換えます。
また、docker-compose.yml ではローカルに pyroscope コンテナを作成するよう定義されていますが、今回はこの部分は不要なのでコメントアウトします。
変更したら docker compose up -d でデモアプリケーションを作成。これにより load-generator という client に相当するコンテナ、各リージョンの server に対応するコンテナがそれぞれ起動します。
$ docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
flask-ap-south-1 flask-ap-south "python lib/server.py" ap-south 46 seconds ago Up 45 seconds 0.0.0.0:32778->5000/tcp, :::32778->5000/tcp
flask-eu-north-1 flask-eu-north "python lib/server.py" eu-north 46 seconds ago Up 45 seconds 0.0.0.0:32779->5000/tcp, :::32779->5000/tcp
flask-load-generator-1 flask-load-generator "python load-generat…" load-generator 46 seconds ago Up 45 seconds
flask-us-east-1 flask-us-east "python lib/server.py" us-east 46 seconds ago Up 45 seconds 0.0.0.0:32777->5000/tcp, :::32777->5000/tcp
起動が完了すると、 load-generator コンテナから各リージョンに対応するコンテナにリクエストが定期的に送信され、アプリケーションの profile データが k8s 上の pyroscope に送信されます。
データの確認
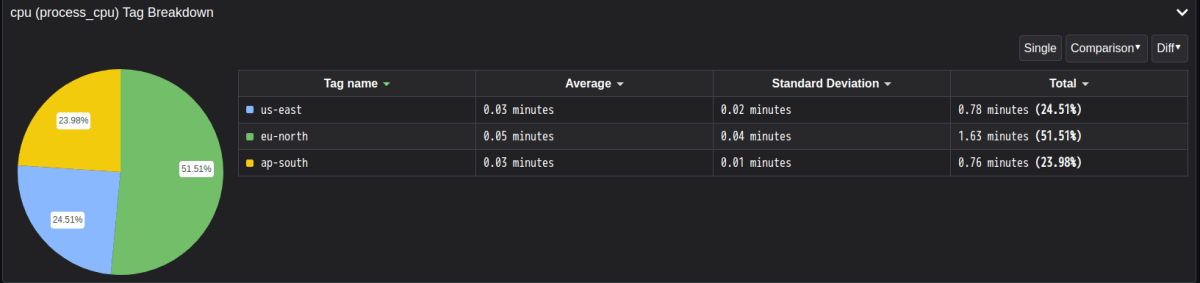
pyroscope UI から収集された profile データを見てみると、アプリケーションに flask-ride-sharing-app > cpu (process_cpu) が追加されていることが確認できます。
左側のメニューにある Tag Explorer では収集された profile データをタグによってフィルタリングすることができます。例えば tag = vehicle を選択すると、アプリケーション内で各 vehicle を注文する際に要した cpu 時間の割合が vehicle 毎に表示されます。
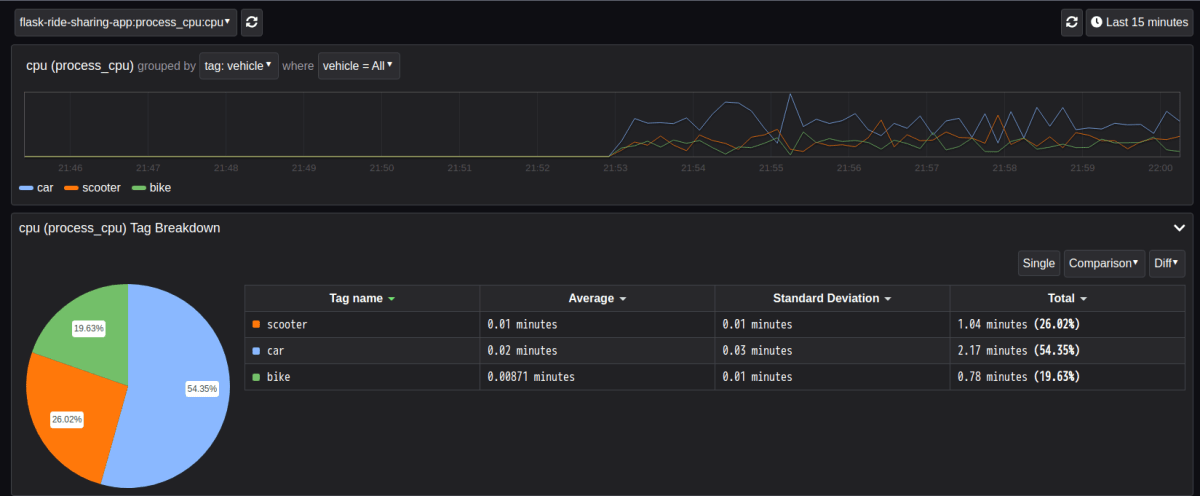
この円グラフでは cpu 時間が長い順に car > scooter > bike となっていますが、デモアプリケーションでは意図的に差が発生するようにコード上で処理を記載していることが原因です。主な原因は以下は原因。
-
server.pyでこの順にorder_xxx()で重み付けをしており、find_nearest_vehicleにかかる時間が長くなる。https://github.com/grafana/pyroscope/blob/main/examples/language-sdk-instrumentation/python/rideshare/flask/lib/server.py#L44-L60 - car の場合は
check_driver_availability関数を追加で実行するため、他の vehicle と比較して長くなる。https://github.com/grafana/pyroscope/blob/4837be642ac3521fa30a9faaf7bc7f4a357f853d/examples/language-sdk-instrumentation/python/rideshare/flask/lib/utility/utility.py#L34-L35
テーブル
Tag Breakdown の下に表示されるテーブルではモジュールや関数毎の CPU 時間が確認できます。テーブルでは self と total がありますが、self はその関数単体の cpu 時間、total はその関数内で call される関数の cpu 時間も含めた値となっています。詳細は Understand ‘self’ vs. ’total’ metrics in profiling with Pyroscope を参照。
self で見るとfind_nearest_vehicle が最も時間がかかっていることがわかりますが、コード的に関数の call 関係としては find_nearest_vehicle → check_driver_availability となっているため、total は find_nearest_vehicle と check_driver_availability self を合わせた値になっています。
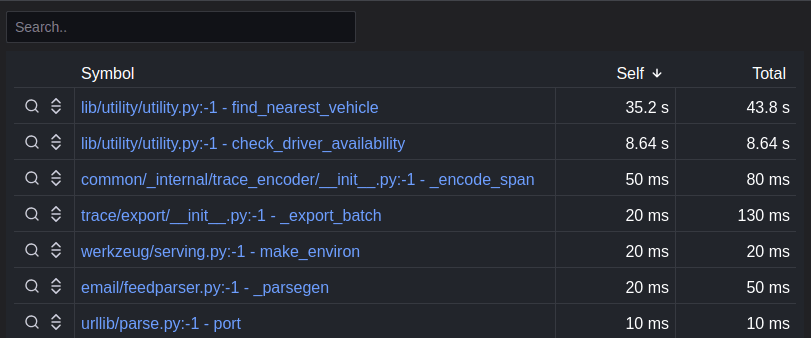
一方で eu-north リージョンの場合、上記の結果とは異なり mutex_lock が最も大きくなっています。

mutex_lock が定義されているコードを見ると、リクエストを送信するリージョンが eu-north のときのみ追加で mutex_lock を実行することがわかります。
self では mutex_lock が最も大きいですが、total では find_nearest_vehicle が大きくなっています。リージョンが eu-north のときの call 関係は find_nearest_vehicle → check_driver_availability → mutex_lock となるため、find_nearest_vehicle の total はこれらの self を足した値になっています。
このようにテーブルからは個々の関数が使用するリソースの情報を把握することが可能です。
Flame Graph
テーブルの横に表示される色付きのグラフは Profile の分野でよく使用される Flame Graph となっており、収集した profile データ内における関数の call, caller の関係を視覚化したものとなっています。
Pyroscope における Flame Graph もこれと同じで、テーブル等を合わせて関数毎の cpu 使用量や関数の call 関係を視覚的に理解するのに役立ちます。読み方や情報については以下のあたりを参照。
- https://grafana.com/docs/pyroscope/latest/view-and-analyze-profile-data/flamegraphs/
- https://grafana.com/docs/grafana-cloud/visualizations/panels-visualizations/visualizations/flame-graph/
例えば、リージョンが eu-north のときの profile を Flame Graph で見ると以下のようになっています。

グラフの下部に注目すると、client からのリクエストに応じて server.py から bike, car, scouter の 3 つの vehicle に対応する関数が call されていることがわかります。この内 bike と scouter では find_nearest_vehicle しか実行されていませんが、car の場合は find_nearest_vehicle → check_driver_availability → mutex_lock と call されていることが確認できます。先程はソースコードからこれらの関数の call 関係を確認しましたが、Flame Graph を使うことで関数の call, caller 関係が一目で把握できるようになっています。
Comparison View
先程は vehicle タグでフィルタリングして car のみ cpu 時間が大きくなっていることを確認しましたが、今度は tag = region でリージョン間の差異を見ると、us-east, ap-north はほぼ同程度ですが eu-north が他リージョンと比較して大きくなっていることがわかります。
この原因を profile データから特定することを考える場合、tag viewer ではどの部分で差が発生しているか確認するのが難しいため、このような場合は Comparison View が活用できます。Comparison View では異なるタグや時間帯におけるデータを並べて表示できるため、タグ毎にリソース消費に異なる傾向があるかどうかを調べたり、時系列に基づいてリソース消費が増えているかどうかを比較する際に便利です。
Comparison View で左に region=eu-north, 右に region=eu-north タグを指定して両者を比較すると、eu-north では mutex_lock が 52.4 s で self では最も大きくなっていますが、ap-south ではこの関数が実行されていないことが flame graph やテーブルから確認できます。
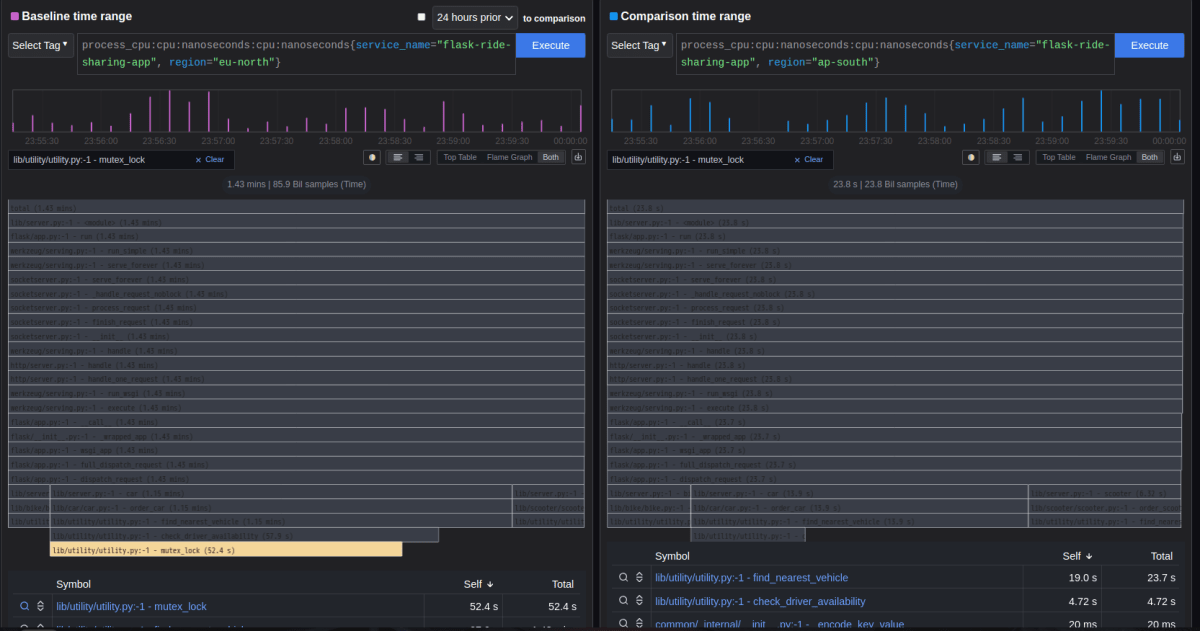
両者を Comparison View で比較した図。左の eu-north では mutex_lock (色のついている部分) が実行されているが、右の ap-south ではこれに該当する関数が実行されていない
Flame graph の call stack より mutex_lock は check_driver_availability から call されていることがわかるので、ソースコードとしては mutex_lock や check_driver_availability が定義されている箇所を見て原因を調査すれば良いことがわかります。上記で見たように eu-north のみ mutex_lock を実行する処理が記載されていることが原因ですが、Comparison View を使うことでタグ毎のデータの比較が可能となり、原因特定のためにどの箇所を調査すればよいか見通しをたてるのに役立ちます。
このように適切にタグ付けされたアプリケーション profile データを収集・分析することで、関数毎にかかる時間やリクエストのパラメータによる処理の差異、ボトルネックとなっている箇所の特定などが行えます。
タグについて
上記で見たリージョンや vehicle のタグはそれぞれ以下の箇所で定義されています。
リージョン
リージョンはコンテナごとに環境変数で設定されており、デモアプリを起動する際の pyroscope configure のセットアップ時に環境変数から読み取って指定されています。
vehicle
vehicle の具体的な値は client → デモアプリにリクエストを送信する際のエンドポイント /car, /bike 等で指定されます。
いずれのエンドポイントでも find_nearest_vehicle 関数は実行されるようになっているので、この中で pyroscope.tag_wrapper により追加でタグを設定するように指定されています。
上記のように SDK では任意の箇所で好きな Tag を柔軟に設定できます。逆に言えば profile の分析においてタグを有効に活用するには適切な場所にタグを設定する必要があります。
Go のデモアプリケーション
ところで python の pyroscope SDK では CPU 時間しか収集できていませんが、これは現時点で python SDK では CPU 収集しかサポートされていないことが原因です。各 SDK でサポートされている profile の種類はドキュメントにまとまっています。
表によると go ではメモリ使用量の収集もサポートされているのでこちらも試してみます。
go のデモアプリケーションは examples/language-sdk-instrumentation/golang-push にあります。内容は python と同じで Ride Share のアプリケーションとなっており、docker compose で構築できます。
go では docker-compose.yml の環境変数 PYROSCOPE_SERVER_ADDRESS で送信先 pyroscope を指定しているので、python の時と同様に k8s 上の pyroscope に送信するよう変更しておきます。
コンテナの作成後、pyroscope UI で確認すると ride-share-app が追加され、cpu の他にメモリに関する情報が収集されていることが確認できます。
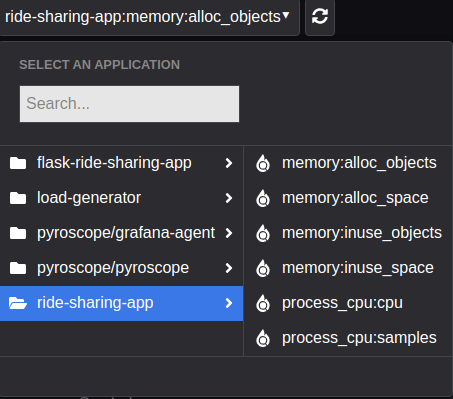
メモリに関する profile データは 4 種類収集されていますが、go の SDK では net/http/pprof で収集したデータを pyroscope に送信しているので、各データは以下のような値に対応しています。
inuse_space — amount of memory allocated and not released yet
inuse_objects — amount of objects allocated and not released yet
alloc_space — total amount of memory allocated (regardless of released)
alloc_objects — total amount of objects allocated (regardless of released)
参考:
- https://www.neteye-blog.com/2019/06/go-pprof-how-to-understand-where-there-is-memory-retention/
- https://pkg.go.dev/runtime/pprof
CPU 時間
まずは python のときと同様に cpu 時間について見てみます。eu-north リージョンのみ処理が多いため割合が一番大きくなっている点は python と同じです。
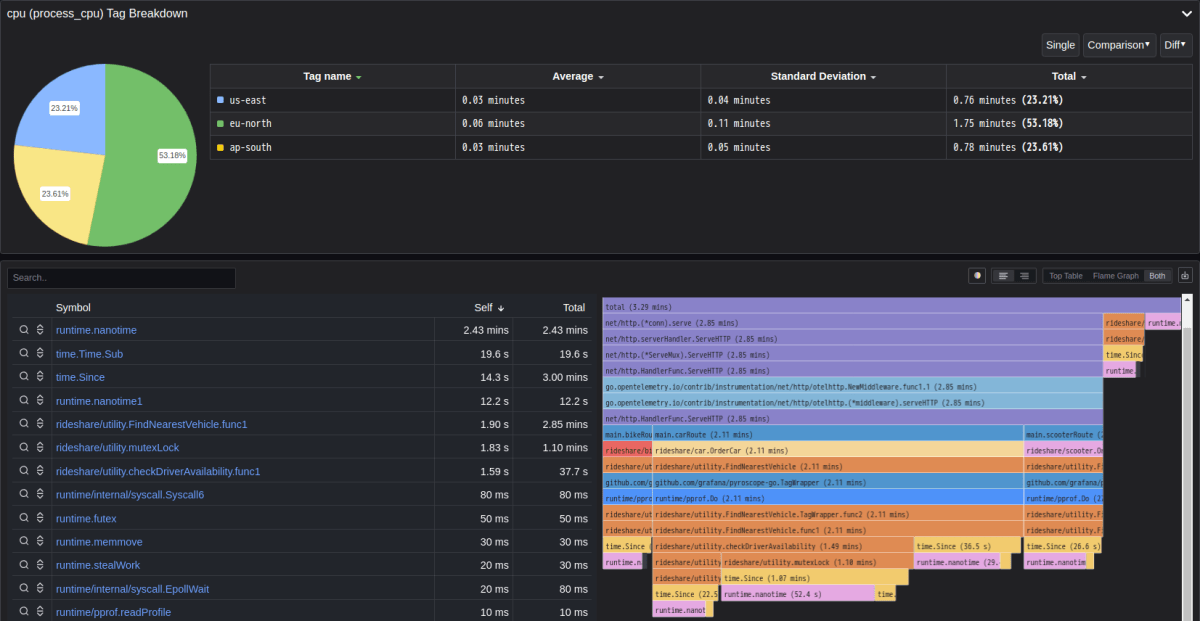
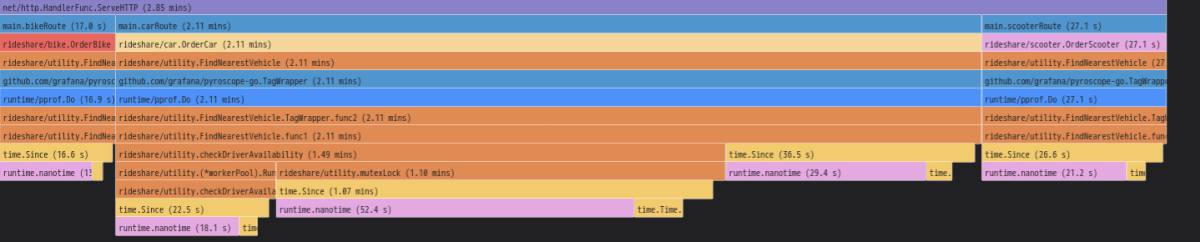
テーブルの self でみると FindNearestVehicle や mutexLock が多い点は python と同じですが、それよりも time.Since, time.Time.Sub, runtime.nanotime などに多くの時間がかかっていることもわかります。コードを見ると FindNearestVehicle や mutexLock の処理内で時間を調整するために time.Since を実行しています。
さらに time.Since のコードを見ると、この内で Sub や nanotime に関する処理を実行しているため、profile データではこれらの cpu 時間も測定されているようです。
// Since returns the time elapsed since t.
// It is shorthand for time.Now().Sub(t).
func Since(t Time) Duration {
if t.wall&hasMonotonic != 0 {
// Common case optimization: if t has monotonic time, then Sub will use only it.
return subMono(runtimeNano()-startNano, t.ext)
}
return Now().Sub(t)
}
また Flame Graph からでも check_driver_availability や mutexLock から time.Since > time.Sub, runtime.nanotime がコールされていることが確認できます。
メモリ使用量
メモリに関する profile のうちアプリケーションに割り当てられたメモリ総量に対応する alloc_space を見ると、 us-east リージョンに対応するコンテナが最も多くメモリを消費していることがわかります。
こちらも Comparison View でどのような関数がメモリを多く消費しているのかを見てみます。左を us-east, 右を ap-south リージョンでそれぞれ見ると
us-east-1 では rideshare/utility.(*workerPool).doWork という関数が 1 GB 近く使用していますが、ap-south ではこれに相当する関数が全く実行されていないことがわかります。
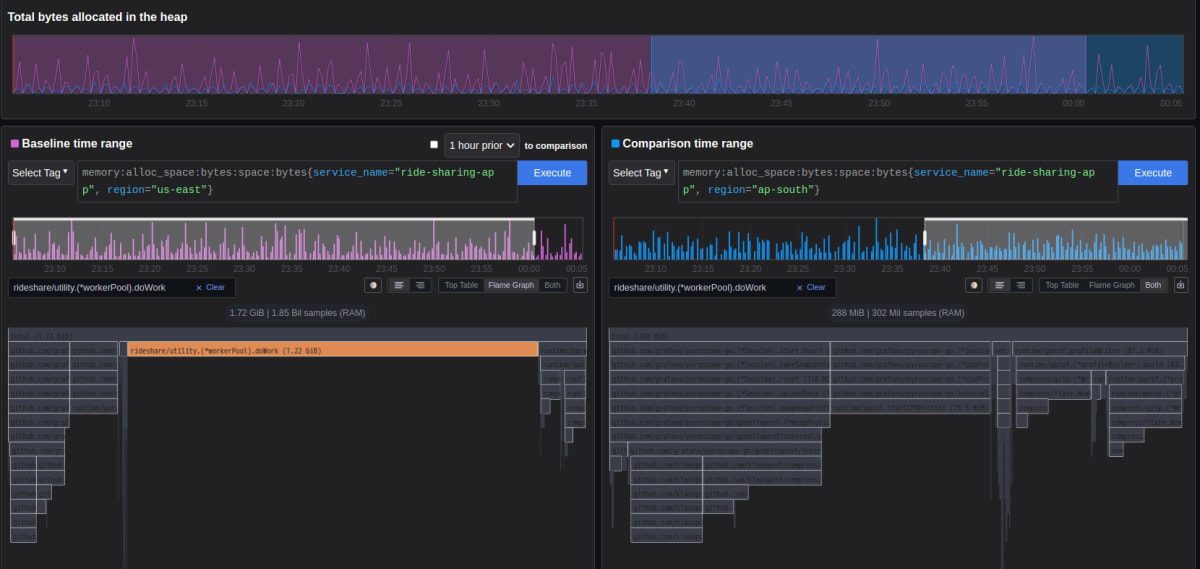
Flame Graph からでは doWork がどのような関数から call されているか判断できないため、doWork が定義されている rideshare/utility を見てみます。doWork を含む pool に関する処理は rideshare/utility/pool.go で定義されており、Run 関数の中で us-east リージョンのときのみ doWork を実行してメモリリークを発生させる処理が含まれています。
us-east リージョンだけ意図的にメモリを多く使用している処理が入っていることにより、us-east リージョンのコンテナが最も多くメモリを消費しているというがわかりました。cpu 時間と同様にメモリ使用量が多い関数や処理を特定する際も Flame Graph や Comparison View を用いた分析が有用です。
その他
マイクロサービス構成
今回の手順では pyroscope に必要な機能が 1 pod にまとまった All-in-one 構成で作成しましたが、Helm install 時の Option B の方法の通り values.yaml を修正して helm install することで機能毎に pod を分割して pyroscope を構成することも可能です。ドキュメントでは Microservices mode と記載されており、機能毎に pod が起動するためスケーリングが容易となり、本番環境でもこちらの構成が推奨されています。
構築手順はドキュメントの通り values.yml の内容を取得して helm install 時に指定するだけですが、本番環境の運用を想定して resource limit などが高めに設定されているので k8s クラスタの規模によっては resources や replicaCount を調整する必要があります。
compactor:
kind: StatefulSet
replicaCount: 3
terminationGracePeriodSeconds: 1200
persistence:
enabled: false
resources:
limits:
memory: 16Gi
requests:
memory: 8Gi
cpu: 1
この方法で pyroscope を構築すると以下のような pod が起動します。
$ k get pod
NAME READY STATUS RESTARTS AGE
pyroscope-agent-0 2/2 Running 0 76s
pyroscope-compactor-0 1/1 Running 0 76s
pyroscope-compactor-1 1/1 Running 0 76s
pyroscope-distributor-7877d6f6c9-p7bj4 1/1 Running 0 76s
pyroscope-distributor-7877d6f6c9-x7b44 1/1 Running 0 76s
pyroscope-ingester-0 1/1 Running 0 76s
pyroscope-ingester-1 1/1 Running 0 76s
pyroscope-minio-0 1/1 Running 0 76s
pyroscope-querier-848895bf45-4mk2r 1/1 Running 0 76s
pyroscope-querier-848895bf45-rg55w 1/1 Running 0 76s
pyroscope-querier-848895bf45-v9hww 1/1 Running 0 76s
pyroscope-query-frontend-59dfccb757-lgqk7 1/1 Running 0 76s
pyroscope-query-frontend-59dfccb757-x9mgx 1/1 Running 0 76s
pyroscope-query-scheduler-7fb5bc8f8c-877c4 1/1 Running 0 76s
pyroscope-query-scheduler-7fb5bc8f8c-wq4ck 1/1 Running 0 76s
pyroscope-store-gateway-0 1/1 Running 0 76s
pyroscope-store-gateway-1 1/1 Running 0 76s
各コンポーネントの機能については ドキュメント にまとまっています。簡単にまとめると以下。
| component | Description |
|---|---|
| Distributor | Agent から受信した profile データを Ingester に送信する。 |
| Ingester | 受信した profile データを永続ストレージに書き込む前にローカルのメモリやディスクに保存し、ストレージへの書き込みを調整する。 |
| Querier | 指定したクエリに基づいて保存した profiler データを検索、取得する。 |
| Query-frontend | ユーザーが指定したクエリを受信する。scheduler と合わせて使う。 |
| Querier-scheduler | query frontend が受信したクエリを効率よくスケジュールする。 |
| Compactor | 保存された profile データを効率よく圧縮する。 |
| Store-Gateway | オブジェクトストレージに保存した profile データをクエリする。 |
その他、データ永続用ストレージとしてオブジェクトストレージの minio もインストールされます。
アーキテクチャ
上記のコンポーネントによる Pyroscope のアーキテクチャは About the Pyroscope architecture に記載されています。
外部からの profile データの投入に専用の Ingester、データのクエリに querier を使用する点、オブジェクトストレージに保存されたデータを store-gateway で取得する点、Compactor でデータを効率よく圧縮して保存するというような点は、k8s メトリクス収集の際に記事にした Thanos のアーキテクチャ と共通しています。
記事内ではアーキテクチャについてはあまり触れませんでしたが、Thanos のアーキテクチャ でも queries でクエリを行う、compactor でデータ圧縮を行うなど名称も含めていくつか共通している部分があります。もちろん細かい処理は異なっていますが、Pyroscope でも大まかに見れば同じようなアーキテクチャで profile を収集・保存するため、扱うデータをメトリクスから profile に読み替えることでアーキテクチャが理解しやすくなるかと思います。
活用事例
デモアプリケーションで実際の profile データを分析することでアプリケーションのボトルネックの特定等に活用できることが確認できました。とはいえ実際のアプリケーションはデモアプリほど単純ではないので、Pyroscope を使って継続的プロファイリングを行いアプリケーションの改善に活用することはなかなかイメージしづらい部分もあります。 Pyroscope の活用事例を検索すると実際の業務アプリケーションで利用している例がいくつか出てくるので、どのような事象で活用できるのか簡潔に見てみます。
Pyroscopeを使ったContinuous Profilingの活用事例
この事例では kotlin (java) のアプリケーションで時々 CPU 使用率の上昇が見られるという事象に対して、pyroscope を使うことでボトルネックとなっていた処理を特定、改善したというケースになっています。
- 対象時刻付近で mysql, redis 等の他サービスや API 呼び出し処理でのレイテンシは見られない、
- 事象は数秒から数十秒
- 1 日に数回程度不定期に発生する
上記のような状況から事象の原因となる箇所の特定が難しいという問題でしたが、pyroscope の Flame Graph から CPU 時間が長くなっている関数を特定し、その中の validation ロジックを改善することで事象が解決できたということのようです。
Pyroscope の Continuous Profiling により Go サーバーのメモリリークを調査・改善した話
この事例では go のアプリケーションでメモリ使用率が時間とともに上昇するというケースです。
こちらも Flame Graph より想定よりも多くのメモリを使用しているモジュールを特定し、異なる時間帯における profile を比較することでそのモジュールのメモリ使用量が時間とともに増加している原因を追求したとのことです。
特定の時間帯のみで profile を収集する従来の (継続的でない) プロファイリングでは時間で変化するような事象の原因特定は難しいですが、Pyroscope のような継続的プロファイリングでは時間変化に関連する動作まで追うことができるため、Pyroscope の分析が活用できる事象であるとも言えます。
上記のような事例を見ると、主に CPU 使用率やメモリ使用率がボトルネックとなっている事象に関して、どのライブラリやモジュールがボトルネックとなっているか特定したい場合に Flame Graph を活用するのが有効なようです。
また、継続的プロファイリングでは文字通り継続的に profile を収集するため、時間変化で症状が悪化するような事象の分析に特に効果的です。Pyroscope による継続的プロファイリングの利点は以下にまとまっているので、このような事象に対しては特に効果を発揮することが期待されます。
おわりに
- pyroscope ではアプリケーションの継続的プロファイリングを行い、CPU やメモリ使用量のボトルネックとなる箇所の分析や原因特定に活用できます。CPU やメモリ使用量自体は Metrics でも収集できますが、profile では関数やパッケージ毎の使用量などのより細部まで見ることができ、Flame Graph による関数の Call stack 等も確認できるので、Observability の 3 大要素と合わせて活用することで Observability の強化、アプリケーションの継続的な改善に役立ちます。
- pyroscope は単体のコンテナでも動作しますが helm でマイクロサービス構成を k8s クラスタ上に展開できるので、k8s の持つ可用性やスケール性を享受できます。そのため HA な profile 分析基盤が比較的容易に構築・運用できるかと思われます。
- profile として収集される内容に関しては、Go, Java, .NET あたりは CPU やメモリを含む色々な profile 情報に対応していますが、それ以外の言語では CPU しか収集できない状況なのでその点は今後の機能拡張が期待されます。
Discussion