Karmada による k8s マルチクラスタ管理を試す
karmada とは
karmada は k8s マルチクラスタ管理を実現するための OSS プロジェクトです。Github star は現時点で 4 k 程で CNCF の Incubating project となっています。
元はスマホ等で有名なファーウェイのクラウド企業 HUAWEI Cloud で開発されていましたが、2021 年 9 月に CNCF に寄贈されました。2023/12 には CNCF の blog にも記事が投稿されています。
karmada では複数クラスタを管理するための karmada control-plane を構成し、管理下のクラスタに対してリソースをデプロイしたり pod スケジュールを行うことでマルチクラスタ管理を実現するアーキテクチャとなっています。
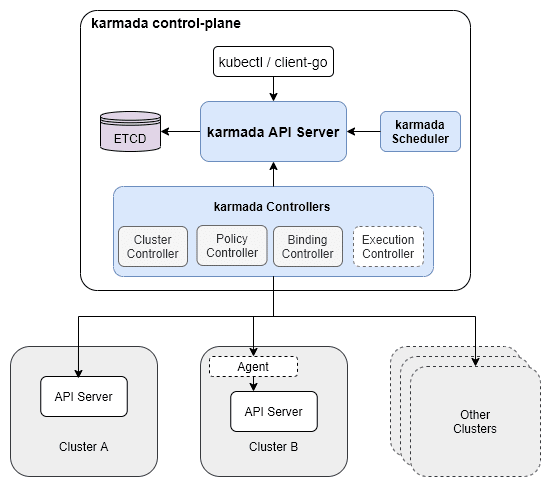
karmada のアーキテクチャ。https://karmada.io/docs/core-concepts/architecture より引用
karmada の主な特徴は Key Features にまとまっています。
- マルチクラウド・マルチクラスタ管理
- karmada control-plane から管理下のクラスタへの通信は kube-apiserver もしくは karmada agent を利用するため、特定のクラウドプロパイダーに制限されない。よって AWS や Azure, オンプレミスの k8s クラスタをまとめて管理することが可能。
- マルチクラスタへのデプロイ
- 管理下のクラスタに同時にリソースをデプロイでき、override Policy と呼ばれる CRD によって展開先クラスタに応じて一部のプロパティを動的に変更するといったことが可能。
- クラスタ間の高度なスケジュール、Failover
- クラスタ間で Affinity, Splitting/Rebalancing などを適用し、通常の k8s クラスタにおける pod 配置戦略やノード不具合時の Failover をクラスタレベルで実現できる。
- クラスタ間サービスディスカバリー・AutoScaling
- submariner などのクラスタ間ネットワークを実現する外部機能を利用することで、クラスタ間のサービスディカバリーや Auto Scaling などを実現できる。
なお、k8s ではマルチクラスタ管理として Kubernetes Federation V2 (kubefed) というものがありましたが、karmada は これらの後継としての開発 が進められているようです。
Notice: this project is developed in continuation of Kubernetes Federation v1 and v2. Some basic concepts are inherited from these two versions.
Karmada の構築
実際に karmada control-plane と管理対象のクラスタを用意してどのようなマルチクラスタ管理ができるのか体験してみます。
作業環境
今回は karmada によるマルチクラスタ管理の動作を確認するために 3 つの k8s クラスタを用意し、1 つは karmada control-plane の構築用、残りは karmada で管理するクラスタとして使用します。各クラスタは control-plane 用のノード 1 台、worker ノード 1 台のシンプルな構成にします。
検証用クラスタの構成
karmada インストール
karmada は ドキュメントのインストール手順 にあるように、構築用スクリプト、helm、operator など様々な方法でインストールできるようになっています。ここでは karmada operator をインストールした後、CRD で karmada instance を作成することで構築します。
Operator のインストール
Operator のインストール手順
operator は helm でインストールできるようになっていますが、chart repository には登録されていないので chart を含む git repository を clone してローカルからインストールする手順となっています。まずは clone を実行。
git clone https://github.com/karmada-io/karmada.git
cd karmada
あとは helm install でインストールできますが、現時点の最新バージョンで進めていると途中でエラーにより正常にインストールが完了しなかったため、今回は v1.10.0 のバージョンを使用します。operator のバージョンを変更するには operator 用の chart value 内のイメージタグを以下のように書き換えます。
operator:
image:
registry: docker.io
repository: karmada/karmada-operator
- tag: latest
+ tag: v1.10.0
helm install を実行
helm install karmada-operator -n karmada-system --create-namespace --dependency-update ./charts/karmada-operator --debug
これにより karmada-system namespace に operator pod が作成されます。インストール時に使用するため kubeconfig の内容を secret として作成。
kubectl create secret generic my-kubeconfig --from-file=$HOME/.kube/config -n karmada-system
operator 起動後は Karmada Instance と呼ばれる CRD を作成することで karmada control-plane の構築に必要なコンポーネントが作成されます。
kubectl create namespace test
kubectl apply -f - <<EOF
apiVersion: operator.karmada.io/v1alpha1
kind: Karmada
metadata:
name: karmada-demo
namespace: test
EOF
ただ、ここでは karmada の各コンポーネントも v1.10.0 に合わせるため、Karmada Instance マニフェストのサンプル https://github.com/karmada-io/karmada/blob/master/operator/config/samples/karmada.yaml を元に各コンポーネントのイメージタグを v1.10.0 に書き換えます。
apiVersion: operator.karmada.io/v1alpha1
kind: Karmada
metadata:
name: karmada
namespace: karmada
spec:
components:
etcd:
local:
imageRepository: registry.k8s.io/etcd
imageTag: 3.5.13-0
replicas: 1
volumeData:
# hostPath:
# type: DirectoryOrCreate
# path: /var/lib/karmada/etcd/karmada-demo
volumeClaim:
metadata:
name: etcd-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
karmadaAPIServer:
imageRepository: registry.k8s.io/kube-apiserver
imageTag: v1.28.9
replicas: 1
serviceType: NodePort
serviceSubnet: 10.96.0.0/12
karmadaAggregatedAPIServer:
imageRepository: docker.io/karmada/karmada-aggregated-apiserver
imageTag: v1.10.0
replicas: 1
karmadaControllerManager:
imageRepository: docker.io/karmada/karmada-controller-manager
imageTag: v1.10.0
replicas: 1
karmadaScheduler:
imageRepository: docker.io/karmada/karmada-scheduler
imageTag: v1.10.0
replicas: 1
karmadaWebhook:
imageRepository: docker.io/karmada/karmada-webhook
imageTag: v1.10.0
replicas: 1
kubeControllerManager:
imageRepository: registry.k8s.io/kube-controller-manager
imageTag: v1.28.9
replicas: 1
karmadaMetricsAdapter:
imageRepository: docker.io/karmada/karmada-metrics-adapter
imageTag: v1.10.0
replicas: 2
# karmadaSearch: # the component `Karmadasearch` is not installed by default, if you need to install it, uncomment it and note the formatting
# imageRepository: docker.io/karmada/karmada-search
# imageTag: v1.10.0
# replicas: 1
# karmadaDescheduler: # the component `KarmadaDescheduler` is not installed by default, if you need to install it, uncomment it and note the formatting
# imageRepository: docker.io/karmada/karmada-descheduler
# imageTag: v1.10.0
# replicas: 1
hostCluster:
networking:
dnsDomain: cluster.local
これをデプロイ。
kubectl create ns karmada
kubectl apply -f karmada.yml
デプロイが正常に完了すると karmada control-plane を構成する pod が起動します。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
karmada-aggregated-apiserver-58b4558c96-ld8dq 1/1 Running 0 2m54s
karmada-apiserver-86648f5476-g6kn9 1/1 Running 0 3m5s
karmada-controller-manager-754496f5bf-xnr68 1/1 Running 0 2m50s
karmada-etcd-0 1/1 Running 0 3m6s
karmada-kube-controller-manager-74f76db4c8-9fdg5 1/1 Running 0 2m50s
karmada-metrics-adapter-69cc7c74f5-mpml9 1/1 Running 0 2m50s
karmada-metrics-adapter-69cc7c74f5-zt7st 1/1 Running 0 2m50s
karmada-scheduler-76bb67cb4d-ptvk7 1/1 Running 0 2m50s
karmada-webhook-7f78445f89-s42l6 1/1 Running 0 2m50s
また、karmada に関する操作は基本的に karmada 専用の CLI (karmadactl) を使って行うためこちらもインストールします。インストール方法 はいくつかありますが、krew を使っている場合は以下でインストールするのが楽です。
kubectl krew install karmada
karmada-apiserver について
karmada control-plane の構築が完了すると指定した namespace に karmada-admin-config という secret が作成されます。中身は karmada-apiserver と通信するための設定ファイルとなっており、基本的に kubeconfig と同じですが server が karmada-apiserver 宛になっていたり(以下の例では karmada-apiserver の nodePort)、certificate 関連が karmada 構築時の認証情報になっているなどの差分があります。
$ k get secrets karmada-admin-config -o yaml | yq -r ".data.kubeconfig" | base64 -d
apiVersion: v1
clusters:
- cluster:
certificate-authority-data:
...
server: https://10.0.0.40:30238
name: karmada-apiserver
contexts:
- context:
cluster: karmada-apiserver
user: karmada-admin
name: karmada-admin@karmada-apiserver
current-context: karmada-admin@karmada-apiserver
kind: Config
preferences: {}
users:
- name: karmada-admin
user:
client-certificate-data:
...
client-key-data:
...
ドキュメントにおいて --kubeconfig=<karmada kubeconfig> と表記されている箇所は基本的にこの karmada-apiserver 向けの config のことを指しています。今後の作業ではデフォルトの kubeconfig と karmada の kubeconfig を切り替える場面が多いので、アクセスを容易にするために secret から内容をコピーしてホスト側のファイルに保存しておくと便利です。
ここで karmada-apiserver について簡単に触れておきます。karmada control-plane では 通常の k8s クラスタにおける kube-apiserver のように karmada-apiserver が karmada 関連の API を処理する構成になっています。また、以下の通り通常の kubernetes API との互換性も持ち合わせています。
Karmada API server directly uses the implementation of kube-apiserver from Kubernetes, which is the reason why Karmada is naturally compatible with Kubernetes API. That makes integration with the Kubernetes ecosystem very simple for Karmada, such as allowing users to use kubectl to operate Karmada, integrating with ArgoCD, integrating with Flux and so on.
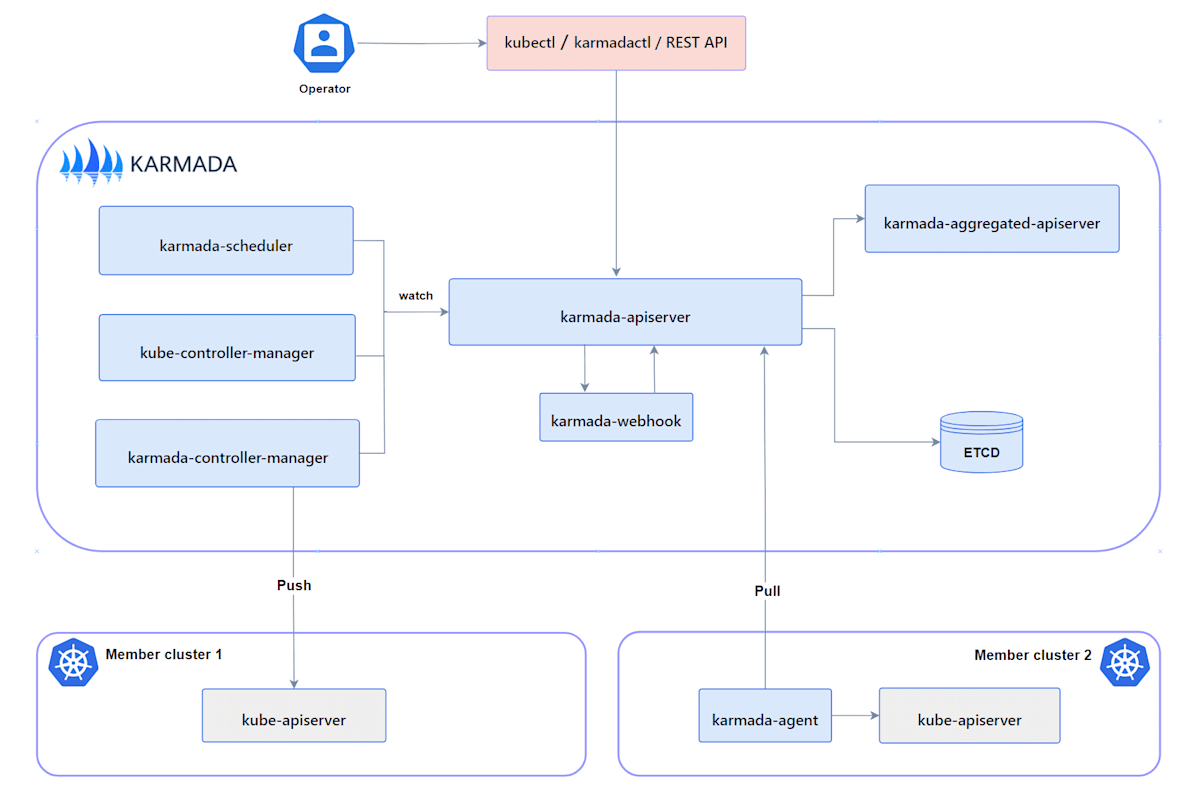
karmada-apiserver が通常の k8s クラスタにおける kube-apiserver の役割を果たしている。https://karmada.io/docs/core-concepts/components#karmada-apiserver より引用
karmada API を使って karmada で管理する対象のクラスタにデプロイ等の操作を行う際は karmada-apiserver と通信を行う必要があるため、上記の通り karmada-apiserver 向けの kubeconfig が必要となっています。
また、アーキテクチャ図では etcd にデータを保存するようになっていますが、こちらは karmada control-plane に作成される pod に保存されるようになっており、k8s クラスタにデフォルトで存在する etcd とは別の保存先になっています。そのため、kubeconfig と karmada kubeconfig で context を切り替えた際に表示される pod が異なる点に注意が必要です。
クラスタの登録
karmada control-plane の構築が完了したので、次に管理対象のクラスタを登録します。クラスタの登録・管理方法は Cluster Mode として Push 型、Pull 型の 2 種類が用意されています。https://karmada.io/docs/userguide/clustermanager/cluster-registration
- Push 型
- karmada control-plane が管理対象の k8s クラスタ上の kube-apiserver と直接通信を行う。
- Pull 型
- 管理対象の k8s クラスタ上に
karmada-agentをインストールし、karmada-agent から karmada control-plane に通信することで登録・管理を行う。
- 管理対象の k8s クラスタ上に
クラスタ登録はどちらの方法でも可能ですが、Pull 型では karmada control-plane とクラスタ外部の通信が可能となるよう追加の設定が必要になります。手順が増えてやや面倒なのでここでは Push 型でクラスタを登録します。
クラスタの登録はドキュメントの通り karmada join コマンドで実行できますが、<member1 kubeconfig> として対象クラスタの kube-apiserver にアクセスするための kubeconfig が必要となるので作業環境に内容をコピーしておきます。
今回は作業環境を karmada クラスタの control-plane node とし、karmada kubeconfig と対象クラスタの kubeconfig をノード上の以下のパスに保存します。
- karmada kubeconfig:
~/.kube/karmada.config - 対象クラスタの kubeconfig:
~/.kube/sub1.config
クラスタを管理対象に参加させる際のコマンドの書式は以下。
kubectl karmada join <cluster_name> --kubeconfig=<karmada kubeconfig> --cluster-kubeconfig=<member1 kubeconfig>
今回は対象クラスタを member1 という名前で登録します。コマンド実行後に joined successfully が表示されれば登録に成功。
$ kubectl karmada join member1 --kubeconfig=/home/ubuntu/.kube/karmada.config --cluster-kubeconfig=/home/ubuntu/.kube/sub1.config -v 5
I0615 06:13:22.627225 312437 join.go:158] Joining cluster. cluster name: member1
I0615 06:13:22.627268 312437 join.go:159] Joining cluster. cluster namespace: karmada-cluster
I0615 06:13:22.628820 312437 join.go:183] Joining cluster config. endpoint: https://10.0.0.30:6443
cluster(member1) is joined successfully
karmada API 関連の操作を実行する場合は基本的に --kubeconfig で karmada config を指定する必要があります。いちいち指定するのは面倒なので使用する際は export KUBECONFIG に設定すると楽です(context に追加して kubectx で切り替えてもいいですが)。
export KUBECONFIG=/home/ubuntu/.kube/karmada.config
同様の方法でもう一つのクラスタの kubeconfig を ~/.kube/sub2.config としてノード上にコピーし、 member2 として登録します。
$ kubectl karmada join member2 --kubeconfig=/home/ubuntu/.kube/karmada.config --cluster-kubeconfig=/home/ubuntu/.kube/sub2.config -v 5
これにより 2 つのクラスタを管理対象に追加できました。クラスタの登録状況は kubectl get clusters で確認できます。
$ k get clusters
NAME VERSION MODE READY AGE
member1 v1.29.6 Push True 2d6h
member2 v1.29.6 Push True 2d6h
複数クラスタにリソースをデプロイする
karmada でマルチクラスタにリソースをデプロイする際は PropagationPolicy と呼ばれる CRD を使って実現します。手順を簡単にまとめると以下のようなシンプルな構成になっています。
- デプロイしたいリソースを定義。作成する。
- PropagationPolicy で上記のリソースを指定し、対象クラスタにデプロイする。
Resource Propagating に簡単なチュートリアルがあるのでこちらを試してみます。
まずはデプロイ対象リソースである nginx deployment のマニフェストを作成します。これに関しては karmada 独自の記述はなく通常の k8s マニフェストとして作成できます。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: default
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
これを karmada control-plane 側にデプロイします。
$ export KUBECONFIG=/home/ubuntu/.kube/karmada.config
$ k apply -f nginx.yml
この時点では karmada クラスタにもメンバークラスタにも pod は作成されません。karmada 側では deployment リソース自体は作成されていますが、pod 数は 0 に設定されています。
$ k get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 0/2 0 0 95s
次に PropagationPolicy CRD を作成して上記の deployment をメンバークラスタにデプロイします。
- デプロイするリソースは
resourceSelectorsで指定。ここではデプロイ対象リソースの kind や name を指定する。 - namespace はデプロイ先クラスタでリソースを作成する namespace を指定する。
- デプロイ対象のクラスタは
placementで指定。クラスタ名を直接指定したり、pod 配置のように label selector などを指定できる。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx # The default namespace is `default`.
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx # If no namespace is specified, the namespace is inherited from the parent object scope.
namespace: default
placement:
clusterAffinity:
clusterNames:
- member1
- member2
デプロイ。
$ k apply -f propagate.yml
propagationpolicy.policy.karmada.io/nginx created
管理下のクラスタにデプロイされたリソースは通常の kubectl と同様に kubectl karmada get [resource] で取得できます。本来はこれで取得できるのですが、試したところエラーが発生しました。
$ k karmada get pod
cluster(member2) is inaccessible, please check authorization or network
cluster(member1) is inaccessible, please check authorization or network
karmada コマンドでは kubectl と同様に -v で詳細レベルを設定可能です。エラーが発生する場合は -v の指定がないと情報が少なすぎるので -v 5 以上を指定することを推奨。
-v 10 にして実行した結果が以下。
I0621 08:02:46.549252 2522618 round_trippers.go:553] GET https://10.0.0.40:30238/apis/cluster.karmada.io/v1alpha1/clusters/member1/proxy/api 403 Forbidden in 7 milliseconds
I0621 08:02:46.549351 2522618 round_trippers.go:570] HTTP Statistics: GetConnection 0 ms ServerProcessing 7 ms Duration 7 ms
I0621 08:02:46.549363 2522618 round_trippers.go:577] Response Headers:
I0621 08:02:46.549370 2522618 round_trippers.go:580] Cache-Control: no-cache, private
I0621 08:02:46.549375 2522618 round_trippers.go:580] Cache-Control: no-cache, private
I0621 08:02:46.549380 2522618 round_trippers.go:580] Cache-Control: no-cache, private
I0621 08:02:46.549385 2522618 round_trippers.go:580] Content-Type: application/json
I0621 08:02:46.549390 2522618 round_trippers.go:580] Date: Fri, 21 Jun 2024 08:02:46 GMT
I0621 08:02:46.549448 2522618 round_trippers.go:580] Content-Length: 344
I0621 08:02:46.549513 2522618 round_trippers.go:580] Audit-Id: a2ef0b6e-420d-44dd-8d2b-63d349e3922d
I0621 08:02:46.549574 2522618 round_trippers.go:580] Audit-Id: a2ef0b6e-420d-44dd-8d2b-63d349e3922d
I0621 08:02:46.549633 2522618 round_trippers.go:580] Audit-Id: a2ef0b6e-420d-44dd-8d2b-63d349e3922d
I0621 08:02:46.549692 2522618 round_trippers.go:580] X-Content-Type-Options: nosniff
I0621 08:02:46.549769 2522618 request.go:1212] Response Body: {"kind":"Status","apiVersion":"v1","metadata":{},"status":"Failure","message":"users \"system:admin\" is forbidden: User \"system:serviceaccount:karmada-cluster:karmada-impersonator\" cannot impersonate resource \"users\" in API group \"\" at the cluster scope","reason":"Forbidden","details":{"name":"system:admin","kind":"users"},"code":403}
どうやらメンバークラスタの情報を取得する際に 403 となっており、Response Body にあるとおり system:serviceaccount:karmada-cluster:karmada-impersonator の SA に system:admin の許可が不足しているようです。
実際に member1 クラスタ側で SA と clusterRole を確認すると確かに権限が不足しています。
$ k get clusterrole karmada-impersonator -o yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
resourcetemplate.karmada.io/managed-annotations: resourcetemplate.karmada.io/managed-annotations,resourcetemplate.karmada.io/managed-labels,resourcetemplate.karmada.io/uid,work.karmada.io/name,work.karmada.io/namespace
resourcetemplate.karmada.io/managed-labels: karmada.io/managed,work.karmada.io/permanent-id
resourcetemplate.karmada.io/uid: ""
work.karmada.io/name: karmada-impersonator-7cbb6bd5c9
work.karmada.io/namespace: karmada-es-member1
creationTimestamp: "2024-06-21T08:00:21Z"
labels:
karmada.io/managed: "true"
work.karmada.io/permanent-id: ae904d66-7c0f-4347-ba4d-a65c26e25688
name: karmada-impersonator
resourceVersion: "2073"
uid: d44d0d8e-a765-49b7-b7a9-b18032939361
rules:
- apiGroups:
- ""
resourceNames:
- system:kube-controller-manager
resources:
- users
verbs:
- impersonate
- apiGroups:
- ""
resourceNames:
- generic-garbage-collector
- namespace-controller
- resourcequota-controller
resources:
- serviceaccounts
verbs:
- impersonate
- apiGroups:
- ""
resourceNames:
- system:masters
resources:
- groups
verbs:
- impersonate
なぜ不足しているかは不明ですが、今回はあくまで検証なので直接 clusterRole を編集して権限を追加します。ただ内部的にリソースを karmada で管理しているらしくそのまま edit を実行しても内容が変化しないため、label の karmada.io/managed: "true" を削除する必要があります。
$ k edit clusterrole karmada-impersonator
metadata:
labels:
- karmada.io/managed: "true"
work.karmada.io/permanent-id: ae904d66-7c0f-4347-ba4d-a65c26e25688
name: karmada-impersonator
resourceVersion: "3496"
uid: d44d0d8e-a765-49b7-b7a9-b18032939361
rules:
- apiGroups:
- ""
resourceNames:
- system:kube-controller-manager
+ - system:admin
resources:
- users
verbs:
- impersonate
memebr1, memebr2 クラスタでそれぞれ上記の対応を実行することで通信できるようになり、各クラスタにデプロイされた pod が確認できるようになります。マニフェストのレプリカ数で指定したとおり、各メンバークラスタ member1, member2 の worker node に pod が 2 つずつデプロイされていることが確認できます。
$ k karmada get pod -o wide
NAME CLUSTER READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION
nginx-77d8468669-2d4tr member1 1/1 Running 0 4d3h 10.244.1.122 k8s-w1 <none> <none> N
nginx-77d8468669-c2v8v member1 1/1 Running 0 4d3h 10.244.1.121 k8s-w1 <none> <none> N
nginx-86dcfdf4c6-kzrd5 member2 1/1 Running 0 4d3h 10.244.1.8 sub1-w1 <none> <none> N
nginx-86dcfdf4c6-pdxb9 member2 1/1 Running 0 4d3h 10.244.1.7 sub1-w1 <none> <none> N
このように PropagationPolicy を使うことで管理対象のクラスタにまとめてリソースをデプロイできます。
マルチクラスタ Failover を試す
karmada における Failover は、管理対象クラスタのいずれかがダウンした際に生き残っているクラスタに pod などのワークロードを移行する機能となっています。通常の k8s クラスタでは worker node がダウンした際に残りの node で pod が起動する動作となっていますが、それをクラスタレベルに拡張したものをイメージすれば分かりやすいと思います。
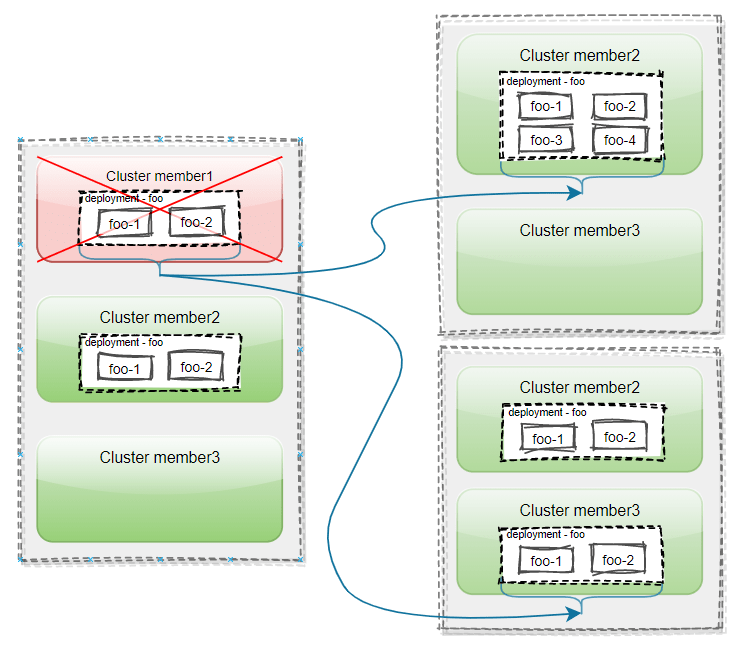
Failover の概要図。Cluster member1 がダウンすると PropagationPolicy の設定に基づいて member2 か member3 上で新しい Pod が起動する。Failover Overview より引用。
こちらの機能についても動作を確認してみます。
まず nginx pod を 10 個起動するマニフェストを作成し、これをメンバークラスタにデプロイする PropagationPolicy を作成します。
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx # The default namespace is `default`.
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx # If no namespace is specified, the namespace is inherited from the parent object scope.
namespace: default
placement:
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
先程の PropagationPolicy との違いは、各クラスタに pod を均等に配置するように placement.replicaScheduling を設定している点となっています(詳細はMultiple strategies of replica Scheduling を参照)。上記のように replicaScheduling を設定すると、targetCluster に指定したクラスタの weight に基づいて pod が分割して起動します。今回の場合 2 クラスタの weight をいずれも 1 に設定しているため、10 pod のうち 1 クラスタに 5 pod ずつ起動するようになります。
実際に PropagationPolicy をデプロイすると member1, member2 のクラスタに 5 pod ずつ 起動することが確認できます。
$ k karmada get pod -o wide
NAME CLUSTER READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION
nginx-76749dc54c-846qb member1 1/1 Running 0 35s 10.244.1.98 sub1-w1 <none> <none> N
nginx-76749dc54c-b4p9k member1 1/1 Running 0 35s 10.244.1.99 sub1-w1 <none> <none> N
nginx-76749dc54c-hm9lj member1 1/1 Running 0 35s 10.244.1.100 sub1-w1 <none> <none> N
nginx-76749dc54c-mmlpq member1 1/1 Running 0 35s 10.244.1.97 sub1-w1 <none> <none> N
nginx-76749dc54c-tnj4k member1 1/1 Running 0 35s 10.244.1.101 sub1-w1 <none> <none> N
nginx-76749dc54c-76n6w member2 1/1 Running 0 35s 10.244.1.89 sub2-w1 <none> <none> N
nginx-76749dc54c-9d54j member2 1/1 Running 0 35s 10.244.1.90 sub2-w1 <none> <none> N
nginx-76749dc54c-hm96h member2 1/1 Running 0 35s 10.244.1.92 sub2-w1 <none> <none> N
nginx-76749dc54c-jl25p member2 1/1 Running 0 35s 10.244.1.93 sub2-w1 <none> <none> N
nginx-76749dc54c-rqm2n member2 1/1 Running 0 35s 10.244.1.91 sub2-w1 <none> <none> N
内部的には weight に基づいて replica を分割した deployment が各クラスタに作成されているようです。
$ k get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 10/10 10 10 63s
$ k karmada get deployments.apps
NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE ADOPTION
nginx member1 5/5 5 5 71s Y
nginx member2 5/5 5 5 71s Y
次に、クラスタ障害により member2 クラスタに接続できなくなるような状況を模擬するため、member2 クラスタの control-plane node ノード上で sudo shutdown now を実行してシャットダウンします。
少し待つと karmada cluster から member2 クラスタへ通信できなくなるため、member2 クラスタのステータスは ready: false になります。
$ k get cluster
NAME VERSION MODE READY AGE
member1 v1.29.6 Push True 3d5h
member2 v1.29.6 Push False 3d5h
member2 クラスタとの通信ができなくなると、deployment のレプリカ数 10 を満たすために member2 クラスタ上で稼働していた pod が Failover により member1 クラスタで起動されます。同時に新規に pod を配置しないよう member2 クラスタに taint が設定されます。これは k describe cluster member2 の Event で確認できます。
$ k describe cluster member2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal TaintClusterSucceed 46s (x3 over 3d5h) cluster-controller Taint cluster succeed: cluster now has taints([{Key:cluster.karmada.io/not-ready,Effect:NoSchedule}]).
Normal TaintClusterSucceed 15s (x2 over 3d4h) cluster-controller Taint cluster succeed: cluster now has taints([{Key:cluster.karmada.io/not-ready,Effect:NoSchedule},{Key:cluster.karmada.io/not-ready,Effect:NoExecute}]).
member1 クラスタの pod を確認すると pod 数が 10 になっており、AGE 3m29s となっているものが新規に起動した pod となっています。
$ k karmada get pod -o wide
NAME CLUSTER READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION
nginx-76749dc54c-27fxb member1 1/1 Running 0 3m29s 10.244.1.104 sub1-w1 <none> <none> N
nginx-76749dc54c-846qb member1 1/1 Running 0 12m 10.244.1.98 sub1-w1 <none> <none> N
nginx-76749dc54c-8zt7h member1 1/1 Running 0 3m29s 10.244.1.102 sub1-w1 <none> <none> N
nginx-76749dc54c-b4p9k member1 1/1 Running 0 12m 10.244.1.99 sub1-w1 <none> <none> N
nginx-76749dc54c-hm9lj member1 1/1 Running 0 12m 10.244.1.100 sub1-w1 <none> <none> N
nginx-76749dc54c-kj5hs member1 1/1 Running 0 3m29s 10.244.1.106 sub1-w1 <none> <none> N
nginx-76749dc54c-lp9nn member1 1/1 Running 0 3m29s 10.244.1.105 sub1-w1 <none> <none> N
nginx-76749dc54c-mmlpq member1 1/1 Running 0 12m 10.244.1.97 sub1-w1 <none> <none> N
nginx-76749dc54c-tnj4k member1 1/1 Running 0 12m 10.244.1.101 sub1-w1 <none> <none> N
nginx-76749dc54c-zb98z member1 1/1 Running 0 3m29s 10.244.1.103 sub1-w1 <none> <none> N
error: cluster(member2) is inaccessible, please check authorization or network
なお、member2 クラスタでは kube-apiserver を含む control-plane node はダウンした状態となっていますが、worker node で起動している pod (コンテナ) は起動したままの状態となっています。これはノード上のコンテナを調べることで確認できます。
$ sudo nerdctl -n k8s.io ps | grep nginx:latest
19b82ddf0372 docker.io/library/nginx:latest "/docker-entrypoint.…" 18 minutes ago Up k8s://default/nginx-76749dc54c-rqm2n/nginx
614267ce0264 docker.io/library/nginx:latest "/docker-entrypoint.…" 18 minutes ago Up k8s://default/nginx-76749dc54c-hm96h/nginx
8d7684a71103 docker.io/library/nginx:latest "/docker-entrypoint.…" 18 minutes ago Up k8s://default/nginx-76749dc54c-76n6w/nginx
9620b39596e5 docker.io/library/nginx:latest "/docker-entrypoint.…" 18 minutes ago Up k8s://default/nginx-76749dc54c-9d54j/nginx
b7d10132fedc docker.io/library/nginx:latest "/docker-entrypoint.…" 18 minutes ago Up k8s://default/nginx-76749dc54c-jl25p/nginx
そのため deployment のステータスとしての pod 数は (もともとあった 10 pod) + (Failover によって新規に起動した 5 pod) = 15 pod となり、一時的にマニフェストの 10 pod よりも多くなっていることが確認できます。
$ k get deployments.apps nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 15/10 15 15 14m
$ k karmada get deployments.apps
NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE ADOPTION
nginx member1 10/10 10 10 14m Y
error: cluster(member2) is inaccessible, please check authorization or network
このように稼働中のクラスタが障害によりダウンすると Failover により他のクラスタで pod が起動するようになっています。
さて、先程シャットダウンした member2 クラスタのノードを再起動してみます。karmada control-plane と対象クラスタの kube-apiserver 間の通信が通るようになるとクラスタステータスは再び READY: True に戻ります。
$ k get cluster
NAME VERSION MODE READY AGE
member1 v1.29.6 Push True 3d5h
member2 v1.29.6 Push True 3d5h
ダウンしていたクラスタが使えるようになっても pod の再配置等は実行されないため、member1 クラスタ上の pod 数は 10 のままであり、member2 クラスタでもダウン前に起動していた 5 pod はそのままとなっています。
NAME CLUSTER READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION
nginx-76749dc54c-27fxb member1 1/1 Running 0 16m 10.244.1.104 sub1-w1 <none> <none> N
nginx-76749dc54c-846qb member1 1/1 Running 0 25m 10.244.1.98 sub1-w1 <none> <none> N
nginx-76749dc54c-8zt7h member1 1/1 Running 0 16m 10.244.1.102 sub1-w1 <none> <none> N
nginx-76749dc54c-b4p9k member1 1/1 Running 0 25m 10.244.1.99 sub1-w1 <none> <none> N
nginx-76749dc54c-hm9lj member1 1/1 Running 0 25m 10.244.1.100 sub1-w1 <none> <none> N
nginx-76749dc54c-kj5hs member1 1/1 Running 0 16m 10.244.1.106 sub1-w1 <none> <none> N
nginx-76749dc54c-lp9nn member1 1/1 Running 0 16m 10.244.1.105 sub1-w1 <none> <none> N
nginx-76749dc54c-mmlpq member1 1/1 Running 0 25m 10.244.1.97 sub1-w1 <none> <none> N
nginx-76749dc54c-tnj4k member1 1/1 Running 0 25m 10.244.1.101 sub1-w1 <none> <none> N
nginx-76749dc54c-zb98z member1 1/1 Running 0 16m 10.244.1.103 sub1-w1 <none> <none> N
nginx-76749dc54c-76n6w member2 1/1 Running 0 25m 10.244.1.89 sub2-w1 <none> <none> N
nginx-76749dc54c-9d54j member2 1/1 Running 0 25m 10.244.1.90 sub2-w1 <none> <none> N
nginx-76749dc54c-hm96h member2 1/1 Running 0 25m 10.244.1.92 sub2-w1 <none> <none> N
nginx-76749dc54c-jl25p member2 1/1 Running 0 25m 10.244.1.93 sub2-w1 <none> <none> N
nginx-76749dc54c-rqm2n member2 1/1 Running 0 25m 10.244.1.91 sub2-w1 <none> <none> N
ある程度時間が立つと member2 クラスタ上の pod が終了され、マニフェスト上の定義である 10 pod に戻ります。
NAME CLUSTER READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES ADOPTION
nginx-76749dc54c-27fxb member1 1/1 Running 0 23m 10.244.1.104 sub1-w1 <none> <none> N
nginx-76749dc54c-846qb member1 1/1 Running 0 32m 10.244.1.98 sub1-w1 <none> <none> N
nginx-76749dc54c-8zt7h member1 1/1 Running 0 23m 10.244.1.102 sub1-w1 <none> <none> N
nginx-76749dc54c-b4p9k member1 1/1 Running 0 32m 10.244.1.99 sub1-w1 <none> <none> N
nginx-76749dc54c-hm9lj member1 1/1 Running 0 32m 10.244.1.100 sub1-w1 <none> <none> N
nginx-76749dc54c-kj5hs member1 1/1 Running 0 23m 10.244.1.106 sub1-w1 <none> <none> N
nginx-76749dc54c-lp9nn member1 1/1 Running 0 23m 10.244.1.105 sub1-w1 <none> <none> N
nginx-76749dc54c-mmlpq member1 1/1 Running 0 32m 10.244.1.97 sub1-w1 <none> <none> N
nginx-76749dc54c-tnj4k member1 1/1 Running 0 32m 10.244.1.101 sub1-w1 <none> <none> N
nginx-76749dc54c-zb98z member1 1/1 Running 0 23m 10.244.1.103 sub1-w1 <none> <none> N
member2 クラスタが復旧するとダウン時に設定されていた taint は自動で削除されるため、復旧後に新規に作成した pod は member2 にも配置されるようになります。
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal TaintClusterSucceed 24m (x3 over 3d5h) cluster-controller Taint cluster succeed: cluster now has taints([{Key:cluster.karmada.io/not-ready,Effect:NoSchedule}]).
Normal TaintClusterSucceed 23m (x2 over 3d5h) cluster-controller Taint cluster succeed: cluster now has taints([{Key:cluster.karmada.io/not-ready,Effect:NoSchedule},{Key:cluster.karmada.io/not-ready,Effect:NoExecute}]).
Normal TaintClusterSucceed 11m (x2 over 3d4h) cluster-controller Taint cluster succeed: cluster now has taints([{Key:cluster.karmada.io/not-ready,Effect:NoExecute}]).
Normal TaintClusterSucceed 10m (x3 over 3d5h) cluster-controller Taint cluster succeed: cluster now does not have taints.
このようにクラスタ復旧後の pod 数は karmada 側で自動で調整してくれます。ただ上記で見たように調整後に pod が起動しているクラスタが偏っている場合の再配置等は実行されません。上記の状況では member2 クラスタ上の nginx deployment 自体が削除されているので pod 削除や kubectl rollout restart コマンドでは member2 クラスタに配置されず、いったん deployment の削除 → 再作成を行う必要があります。
$ k karmada get deployments.apps -C member1
NAME CLUSTER READY UP-TO-DATE AVAILABLE AGE ADOPTION
nginx member1 10/10 10 10 45m Y
$ k karmada get deployments.apps -C member2
No resources found in namespace.
その他の機能
karmada では他にも様々な機能がありますが数が多いので、ここでは個人的に面白そうな機能について簡単に紹介します。
Override Policy
Overrides Policy ではリソースを複数のクラスタにデプロイする際、対象クラスタの条件に基づいて一部のプロパティを動的に追加、削除、置換する機能となっています。基本的に同じ deployment をデプロイしたいけど label や annotation をクラスタ毎に変更・追加したいといった用途に使えます。ドキュメントでは以下の override が記載されています。
| override の種類 | 説明 |
|---|---|
| ImageOverrider | コンテナイメージを変更する |
| CommandOverrider | コンテナの command を変更する |
| ArgsOverrider | コンテナの args を変更する |
| LabelsOverrider | リソースの label を変更する |
| AnnotationsOverrider | リソースの annotation を変更する |
| PlaintextOverrider | kubectl path に相当し、リソースの任意のプロパティを変更する |
Argocd によるデプロイ
前の検証ではデプロイ対象のリソースと PropagationPolicy のマニフェストを手動でデプロイしましたが、本格的な運用では Argocd などのデプロイツールを利用して自動でデプロイを実行するケースも多いかと思います。ドキュメントでは Argocd と Flux を用いた karmada のデプロイ方法について記載されています。
といっても検証で見たように基本的に PropagationPolicy と対象リソースのマニフェストをそれぞれデプロイすればいいだけなので、Argocd を使う場合でも Github repo にこれらのマニフェストを保存し、Argocd でデプロイを実行するという流れになります。
クラスタ間ネットワーク
karmada で管理するメンバークラスタはあくまでそれぞれ個別のクラスタであるため、クラスタ間の通信は CNI 等を使ったクラスタ内のフラットなネットワークではなく通常のネットワークでの通信到達性を考える必要があります。しかしクラスタ間ネットワークを実現するような OSS 等を利用することにより、クラスタ内でのフラットネットワークをクラスタレベルに拡張し、クラスタ間での Service Discovery や AutoScaling を実現できるようになっています。
ただし karmada 自体にこの機能が組み込まれているわけではなく外部のコンポーネントを利用する必要があるようです。ドキュメント ではクラスタ間のフラットなネットワーク通信を提供する OSS submariner を利用する方法について記載されています。
submariner を利用したクラスタ間 Service Discovery についても検証していましたが、あるクラスタから別のクラスタのサービスに通信する部分がうまく行かず断念しました(機会があればまた試すかも)。
途中までの検証は検証メモの Submariner によるクラスタ間ネットワーク に記載しています。
検証メモ
検証中のメモ
Submariner によるクラスタ間ネットワーク
karmada のクラスタ間ネットワークで記載されているように submariner を使うとクラスタ間で pod や svc の通信が可能となります。submariner では Broker と呼ばれるコンポーネントがクラスタ間ネットワークのメタデータを管理し、各クラスタは Gateway Engine を通じてクラスタ間通信を実現します。
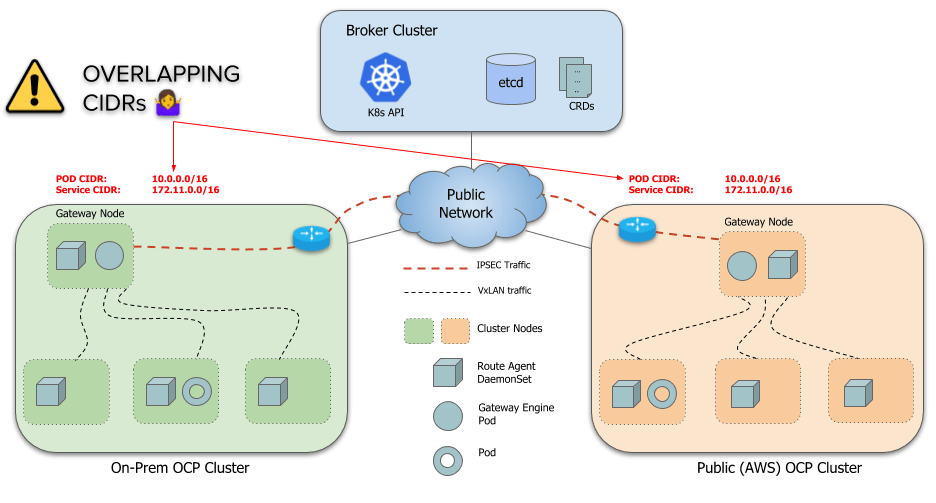
submariner のアーキテクチャ。https://submariner.io/getting-started/architecture/globalnet/ より引用
また、デフォルトの構築方法では各クラスタの ServiceCIDR が重複してはいけないという前提条件があり、重複している場合は Globalnet と呼ばれる仕組みを使う必要があります。
However, by default, a limitation of Submariner is that it doesn’t handle overlapping CIDRs (ServiceCIDR and ClusterCIDR) across clusters. Each cluster must use distinct CIDRs that don’t conflict or overlap with any other cluster that is going to be part of the ClusterSet.
今回の検証に使用した 3 つのクラスタではいずれも POD CIDR と ServiceCIDR が重複しているので globalnet を使用して構築します。
ここでは submariner ドキュメントの EXTERNAL NETWORK (EXPERIMENTAL) に沿ってクラスタ間ネットワークを構築します。ドキュメントでは 2 つのクラスタノードと 1 つの 非クラスタ VM を準備していますが、VM は今回使用しないので不要です。
submariner では subctl CLI で各種操作を行うのでインストール。
curl -Ls https://get.submariner.io | bash
export PATH=$PATH:~/.local/bin
echo export PATH=\$PATH:~/.local/bin >> ~/.profile
はじめに Broker の設定を行います。submariner では Broker がクラスタ間の通信を交換するためのコンポーネントとなっており、クラスタ間ネットワークに含まれるすべてのクラスタがアクセス可能な api server 上に構築する必要があります。今回の検証では karmada cluster が各メンバークラスタと通信可能になっているため、karmada クラスタの通常のクラスタ側 (karmada control-plane ではない) で以下のコマンドを実行して broker を構築します。
export KUBECONFIG=/home/ubuntu/.kube/config
subctl deploy-broker --globalnet
次に他のクラスタを Broker に参加させますが、その前に今回使用しているノード一覧について書き出しておきます。
| ノード名 | cluster | ノードの IP address | POD CIDR | role |
|---|---|---|---|---|
| main-m1 | karmada | 10.0.0.40 | 10.244.0.0/16 | control-plane |
| main-w1 | karmada | 10.0.0.41 | - | worker |
| sub1-m1 | member1 | 10.0.0.50 | 10.244.0.0/16 | control-plane |
| sub1-w1 | member1 | 10.0.0.51 | - | worker |
| sub2-m1 | member2 | 10.0.0.30 | 10.244.0.0/16 | control-plane |
| sub2-w1 | member2 | 10.0.0.31 | - | worker |
- CLUSTER_CIDR はドキュメントの通り POD CIDR の
10.244.0.0/16に設定。 - EXTERNAL_CIDR は全クラスタのノード IP アドレスの範囲とかぶらないように設定する。ここでは
10.0.0.96/27
上記の CIDR を元に karmada クラスタを broker に参加。
CLUSTER_CIDR=10.244.0.0/16
EXTERNAL_CIDR=10.0.0.96/27
subctl join broker-info.subm --clusterid karmada --natt=false --clustercidr=${CLUSTER_CIDR},${EXTERNAL_CIDR}
次に member1, 2 クラスタを broker に参加させます。
subctl join --kubeconfig /home/ubuntu/.kube/sub1.config broker-info.subm --clusterid member1 --natt=false
subctl join --kubeconfig /home/ubuntu/.kube/sub2.config broker-info.subm --clusterid member2 --natt=false
現在のクラスタの接続状況については subctl show all で確認できます。connection や gateway が表示され、エラー等が表示されなければ ok。
$ subctl show all
Cluster "main_k8s"
✓ Detecting broker(s)
NAMESPACE NAME COMPONENTS GLOBALNET GLOBALNET CIDR DEFAULT GLOBALNET SIZE DEFAULT DOMAINS
submariner-k8s-broker submariner-broker service-discovery, connectivity yes 242.0.0.0/8 65536
✓ Showing Connections
GATEWAY CLUSTER REMOTE IP NAT CABLE DRIVER SUBNETS STATUS RTT avg.
sub1-w1 member1 10.0.0.51 no libreswan 242.1.0.0/16 connected 852.419µs
sub2-w1 member2 10.0.0.31 no libreswan 242.2.0.0/16 connected 835.722µs
✓ Showing Endpoints
CLUSTER ENDPOINT IP PUBLIC IP CABLE DRIVER TYPE
karmada 10.0.0.41 118.158.73.193 libreswan local
member1 10.0.0.51 118.158.73.193 libreswan remote
member2 10.0.0.31 118.158.73.193 libreswan remote
✓ Showing Gateways
NODE HA STATUS SUMMARY
main-w1 active All connections (2) are established
✓ Showing Network details
Discovered network details via Submariner:
Network plugin: generic
Service CIDRs: [10.96.0.0/12]
Cluster CIDRs: [10.244.0.0/16,10.0.0.96/27]
Global CIDR: 242.0.0.0/16
✓ Showing versions
COMPONENT REPOSITORY CONFIGURED RUNNING ARCH
submariner-gateway quay.io/submariner 0.17.1 release-0.17-fdfcc8797bc2 amd64
submariner-routeagent quay.io/submariner 0.17.1 release-0.17-fdfcc8797bc2 amd64
submariner-globalnet quay.io/submariner 0.17.1 release-0.17-fdfcc8797bc2 amd64
submariner-metrics-proxy quay.io/submariner 0.17.1 release-0.17-1e49b8404147 amd64
submariner-operator quay.io/submariner 0.17.1 release-0.17-0133a99b08a6 amd64
submariner-lighthouse-agent quay.io/submariner 0.17.1 release-0.17-b9c6b562f556 amd64
submariner-lighthouse-coredns quay.io/submariner 0.17.1 release-0.17-b9c6b562f556 amd64
なお、構築が完了すると submariner-operator namespace に以下の pod が作成されます。
$ k get pod -n submariner-operator
NAME READY STATUS RESTARTS AGE
submariner-gateway-s9hcc 1/1 Running 0 3d3h
submariner-globalnet-gklkd 1/1 Running 0 3d3h
submariner-lighthouse-agent-754bfcf58c-klf5q 1/1 Running 0 3d3h
submariner-lighthouse-coredns-7fb549f74d-jq2zx 1/1 Running 0 3d3h
submariner-lighthouse-coredns-7fb549f74d-vrgf5 1/1 Running 0 3d3h
submariner-metrics-proxy-dmg4w 2/2 Running 0 3d3h
submariner-operator-ffc859cfd-w9sfw 1/1 Running 0 3d3h
submariner-routeagent-7jlwn 1/1 Running 0 3d3h
submariner-routeagent-h8dlk 1/1 Running 0 3d3h
これでクラスタ間ネットワークか構成されたので、karmada の Multi-cluster Service Discovery に沿って動作確認します。
まず serviceexports, serviceimport CRD をメンバークラスタ上に作成します。以下のような ClusterPropagationPolicy マニフェストを作成。
# propagate ServiceExport CRD
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: serviceexport-policy
spec:
resourceSelectors:
- apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: serviceexports.multicluster.x-k8s.io
placement:
clusterAffinity:
clusterNames:
- member1
- member2
---
# propagate ServiceImport CRD
apiVersion: policy.karmada.io/v1alpha1
kind: ClusterPropagationPolicy
metadata:
name: serviceimport-policy
spec:
resourceSelectors:
- apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
name: serviceimports.multicluster.x-k8s.io
placement:
clusterAffinity:
clusterNames:
- member1
- member2
karmada 上でデプロイすることで 2 つのメンバークラスタにまとめて CRD を作成します。
export KUBECONFIG=/home/ubuntu/.kube/karmada.config
k apply -f svc-crd.yml
次にドキュメントの通り以下のマニフェストを作ってデプロイします。
apiVersion: apps/v1
kind: Deployment
metadata:
name: serve
spec:
replicas: 1
selector:
matchLabels:
app: serve
template:
metadata:
labels:
app: serve
spec:
containers:
- name: serve
image: jeremyot/serve:0a40de8
args:
- "--message='hello from cluster member1 (Node: {{env \"NODE_NAME\"}} Pod: {{env \"POD_NAME\"}} Address: {{addr}})'"
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
---
apiVersion: v1
kind: Service
metadata:
name: serve
spec:
ports:
- port: 80
targetPort: 8080
selector:
app: serve
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: mcs-workload
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: serve
- apiVersion: v1
kind: Service
name: serve
placement:
clusterAffinity:
clusterNames:
- member1
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
metadata:
name: serve
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: serve-export-policy
spec:
resourceSelectors:
- apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceExport
name: serve
placement:
clusterAffinity:
clusterNames:
- member1
apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceImport
metadata:
name: serve
spec:
type: ClusterSetIP
ports:
- port: 80
protocol: TCP
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: serve-import-policy
spec:
resourceSelectors:
- apiVersion: multicluster.x-k8s.io/v1alpha1
kind: ServiceImport
name: serve
placement:
clusterAffinity:
clusterNames:
- member2
上記をデプロイすると以下のような動作になります。
-
servepod, svc が member1 クラスタ 上に作成される。 -
ServiceExportCRD によりクラスタ間でアクセス可能なservesvc が作成される。 -
ServiceImportCRD によりserveにアクセスするための svc が member2 クラスタ上に作成される。
submariner の性質により subctl export コマンドで特定のサービスを公開するか ServiceExport CRD を作成すると、クラスタ間でグローバルにアクセス可能なサービスが作成されます。これは globalingressips リソースとして確認できます。
$ k karmada get globalingressips.submariner.io -A
NAMESPACE NAME CLUSTER IP ADOPTION
default serve member1 242.1.255.253 N
default derived-serve member2 242.2.255.253 N
上記の serve が member1 クラスタ上に作成した svc のグローバルエンドポイントに対応し、IP がエンドポイントに接続するための IP アドレスになっています。
また、member1 クラスタの svc を確認すると submariner-.. の svc が作成され、上記で確認した IP アドレスが EXTERNAL-IP に設定されていることが確認できます。
$ k get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 26h
serve ClusterIP 10.102.199.123 <none> 80/TCP 98s
submariner-etcfrt5unwnek3jrjr4joya6kfly4q6b ClusterIP 10.99.110.190 242.1.255.253 80/TCP 98s
上記の IP アドレスにアクセスすることで member1 クラスタのノードだけでなく karmada クラスタ、memebr2 クラスタのノードからでも memebr1 クラスタ上の serve pod に到達できます。
$ curl 242.1.255.253
'hello from cluster member1 (Node: sub1-w1 Pod: serve-8765f9f98-7n4zm Address: 10.244.1.91)'
また、作成されたグローバルエンドポイントは pod 内ネットワークで [service_name].[namespace].svc.clusterset.local で名前解決できます。member2 クラスタ内に適当に pod を立てて、pod 内から nslookup 等を実行することで確認できます。
root@nginx-76749dc54c-czzsk:/# nslookup serve.default.svc.clusterset.local
Server: 10.96.0.10
Address: 10.96.0.10#53
Name: serve.default.svc.clusterset.local
Address: 242.1.255.253
# dig
root@nginx-76749dc54c-czzsk:/# dig serve.default.svc.clusterset.local
; <<>> DiG 9.18.24-1-Debian <<>> serve.default.svc.clusterset.local
;; global options: +cmd
;; Got answer:
;; WARNING: .local is reserved for Multicast DNS
;; You are currently testing what happens when an mDNS query is leaked to DNS
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 27186
;; flags: qr aa rd; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; WARNING: recursion requested but not available
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
; COOKIE: f738fcff83c7111c (echoed)
;; QUESTION SECTION:
;serve.default.svc.clusterset.local. IN A
;; ANSWER SECTION:
serve.default.svc.clusterset.local. 5 IN A 242.1.255.253
;; Query time: 0 msec
;; SERVER: 10.96.0.10#53(10.96.0.10) (UDP)
;; WHEN: Sat Jun 22 10:10:13 UTC 2024
;; MSG SIZE rcvd: 125
このように submariner では k8s service にクラスタ間で有効なグローバルな IP アドレスを割り当てる動作となっています。
上記で作成されたサービスの関係を図示すると以下のようになります。svc を service export で公開するとそれに対応した submariner-... svc が作成され、EXTERNAL-IP (globalingressips) が付加されます。これを通じて submariner に属するクラスタ間アクセスを実現できます。
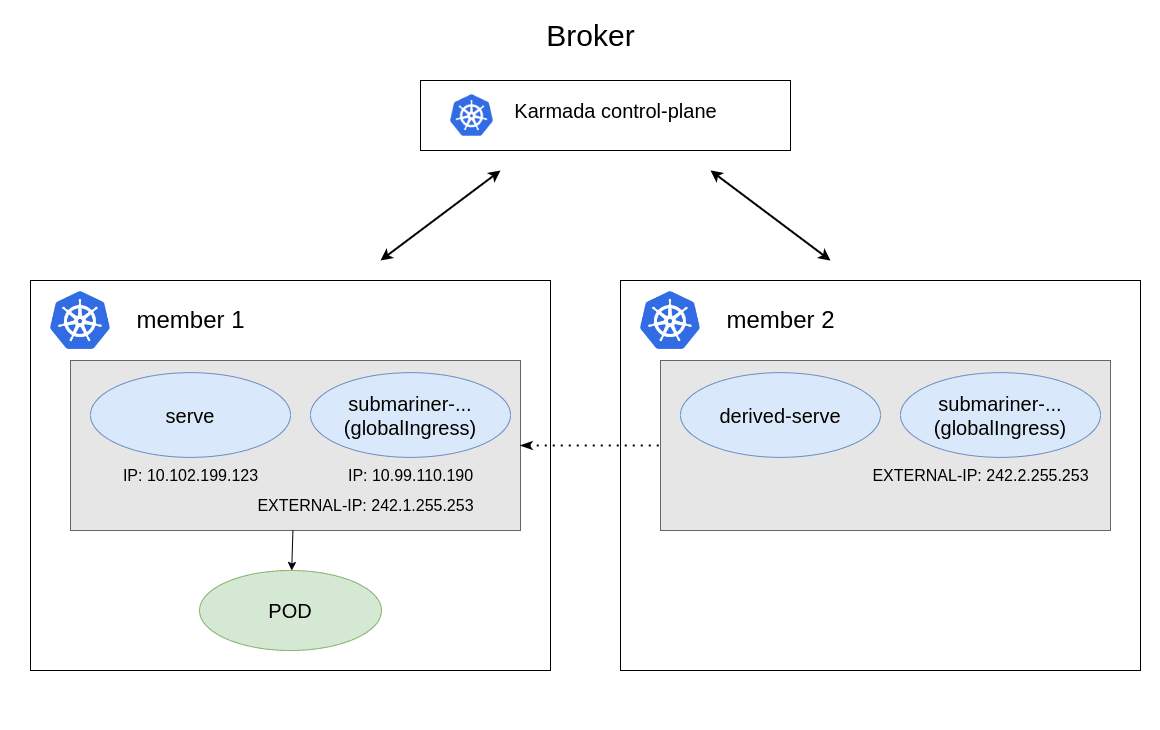
イメージ図
Step 3: Access the service from member2 cluster では karmada の Service Discovery 機能として、本来は derived-serve にアクセスすることで member1 クラスタの pod にルーティングされるように設定できるはずですが、手元で試しても svc と pod が結びつかずうまくいきかせんでした。設定が間違っているのかもしれません。
おわりに
k8s マルチクラスタ管理の OSS karmada を使用してマルチクラスタへのリソースデプロイや Failover の動作を確認しました。karmada 自体の独自概念やコンポーネントが多く学習コストがやや高いことや、そもそもマルチクラスタを本格的に管理しようとすると管理コストや運用方式等を考える必要があるのでなかなか使いどころが難しいという事情はありますが、もし OSS でマルチクラスタ管理を実現したいのであれば選択肢の 1 つには入ってくるといった立ち位置かなと感じました。
とはいえ CNCF の incubator プロジェクトとなっているので、近年のマルチクラウドやマルチクラスタ管理の需要に応じて今後の発展や機能拡張が期待されます。
Discussion