kubernetes 用のカオスエンジニアリングフレームワーク Litmus を試す
概要
kubernetes 用のカオスエンジニアリングフレームワークにはいくつかありますが、今回はその中のひとつである Litmus を使ってみます。
litmus では k8s 上のアプリケーション (pod) や基盤インフラストラクチャ (node) に対して意図的に負荷や障害を注入し、対象のアプリケーション等の耐障害性や resilience (回復力) を評価することができます。CNCF incubating project に位置づけられており、障害注入や対象の管理・評価を容易に行える、拡張性が高く CI/CD との統合が可能などの特徴があります。
インストール
検証環境の構成
litmus のアーキテクチャは大きく分けて chaos control plane と chaos execution plane の 2 つから構成されます。
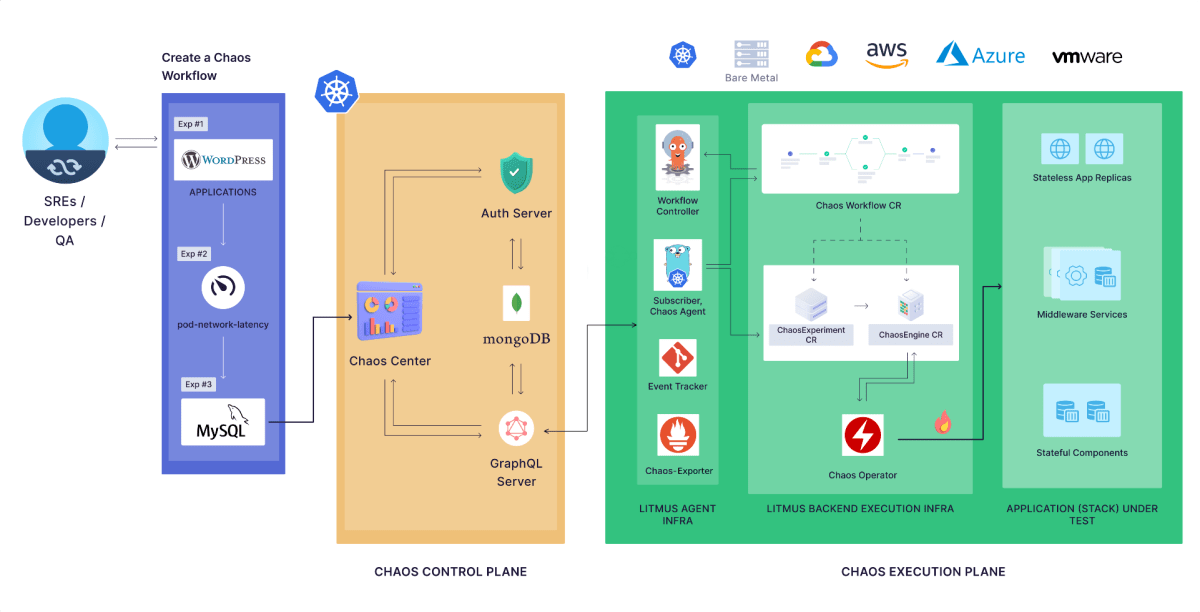
litmus のアーキテクチャ図 (Architecture Summary より引用)
- chaos control plane
- web UI や server, データベース (mongo DB) などの管理コンポーネント pod が配置されるインフラ。
- chaos execution plane
- 実際の障害を発生させる pod やクラスタを含むインフラ。障害を発生させるための pod や control plane と通信を行うための infra agent pod などが配置される。litmus の用語で chaos infrastructure とも呼ばれる。
litmus をインストールして障害を検証するには control plane と execution plane を構築する必要があります。k8s クラスタ 1 つに両方を構築することも可能ですが、今回は 2 つの k8s クラスタを準備し、片方は control plane として litmus の管理コンポーネントをインストールします。もう片方のクラスタは execution plane として litmus namespace に必要なコンポーネントをインストールし、litmus-test namespace に検証に使用する pod などを配置する構成にします。
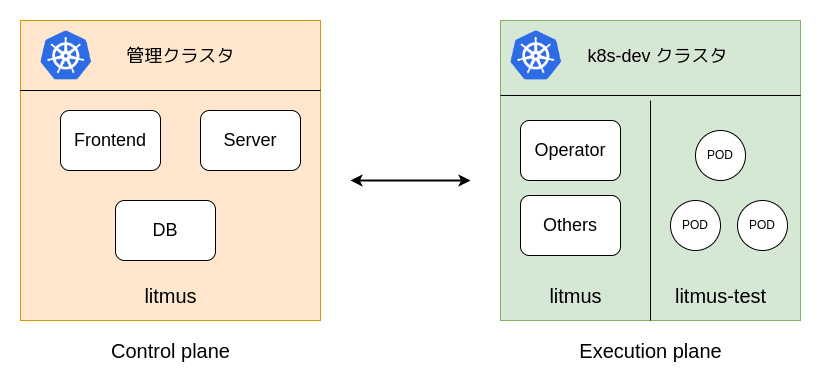
今回の検証の構成図
control plane の構築
インストール手順 に沿って helm でインストールします。
helm repo add litmuschaos https://litmuschaos.github.io/litmus-helm/
helm repo list
kubectl create ns litmus
helm install chaos litmuschaos/litmus --namespace=litmus
これにより以下がインストールされます。
- frontend (ダッシュボード)
- litmus 本体 (server)
- データベース (mongodb)
- 認証サーバ (auth-server)
NAME READY STATUS RESTARTS AGE
pod/chaos-litmus-auth-server-784f74b688-t28b7 1/1 Running 0 27h
pod/chaos-litmus-frontend-57b4fbc7cb-ms47b 1/1 Running 0 27h
pod/chaos-litmus-server-694ddcc947-fvdtv 1/1 Running 0 27h
pod/chaos-mongodb-0 1/1 Running 0 27h
pod/chaos-mongodb-1 1/1 Running 0 27h
pod/chaos-mongodb-2 1/1 Running 0 27h
pod/chaos-mongodb-arbiter-0 1/1 Running 0 27h
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/chaos-litmus-auth-server-service ClusterIP 10.105.84.135 <none> 9003/TCP,3030/TCP 27h
service/chaos-litmus-frontend-service ClusterIP 10.104.96.76 <none> 9091/TCP 27h
service/chaos-litmus-server-service ClusterIP 10.99.121.183 <none> 9002/TCP,8000/TCP 27h
service/chaos-mongodb-arbiter-headless ClusterIP None <none> 27017/TCP 27h
service/chaos-mongodb-headless ClusterIP None <none> 27017/TCP 27h
このうち litmus-frontend-service という名前の svc が ChaosCenter と呼ばれるダッシュボードに対応しています。クラスタ外部からダッシュボードにアクセスできるよう Install Litmus ChaosCenter with Ingress に沿って ingress も作成しておきます。
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/rewrite-target: /$1
name: litmus-ingress
spec:
rules:
- host: litmus.ops.com
http:
paths:
- backend:
service:
name: litmusportal-frontend-service
port:
number: 9091
path: /(.*)
pathType: ImplementationSpecific
- backend:
service:
name: litmusportal-server-service
port:
number: 9002
path: /backend/(.*)
pathType: ImplementationSpecific
これでブラウザからドメイン litmus.ops.com にアクセスすることでダッシュボードを閲覧できます。デフォルトで admin ユーザが作成されるため、 username: admin, password: litmus でログインできます。
execution plane の構築
execution plane の構築は Create an Infrastructure の手順内で行います。まずは Create an Environment に沿って environment を作成します。environment は各 chaos 環境を管理する抽象的な区分となっています。
environment を作成したら Enable Chaos により execution plane に対応する chaos infra を構築します。
はじめに chaos infra の名前を入力します。なんでもいいのでクラスタ名の k8s-dev としておきます。
次に chaos infra の構成を行います。ここでは以下の項目が設定できます。
- mode の選択
- cluster 全体か特定の namespace に対して chaos infra を構築する。作成される role の範囲等に差分がある。
- install namespace
- chaos infra (pod) が作成される namespace 。デフォルトでは litmus
- service account name
- 対象上に作成される k8s service account の名前。デフォルトでは litmus
いずれもデフォルトの設定値のままで良いです。
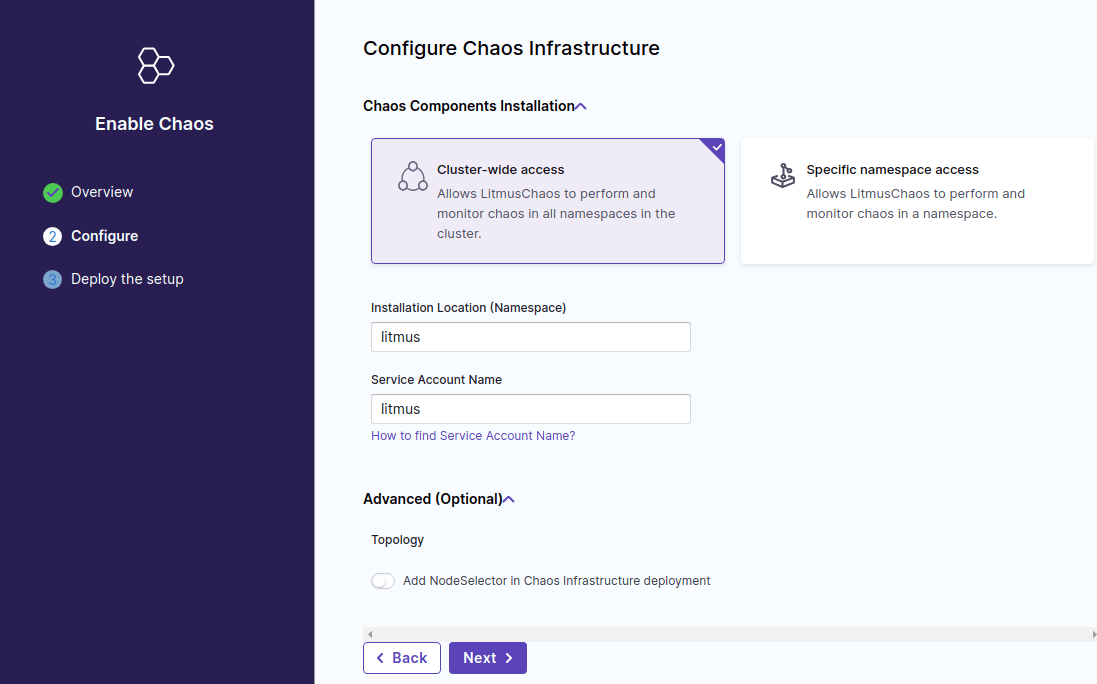
最後に Deploying your Infrastructure として yaml ファイルのダウンロードリンクが表示されます。この yaml は chaos infra の構築に必要な service account やクラスタロール、管理コンポーネントの deployment などが記述されたマニフェストとなっているため、対象の k8s クラスタ上にデプロイすることで簡単に execution plane が構築できるようになっています。
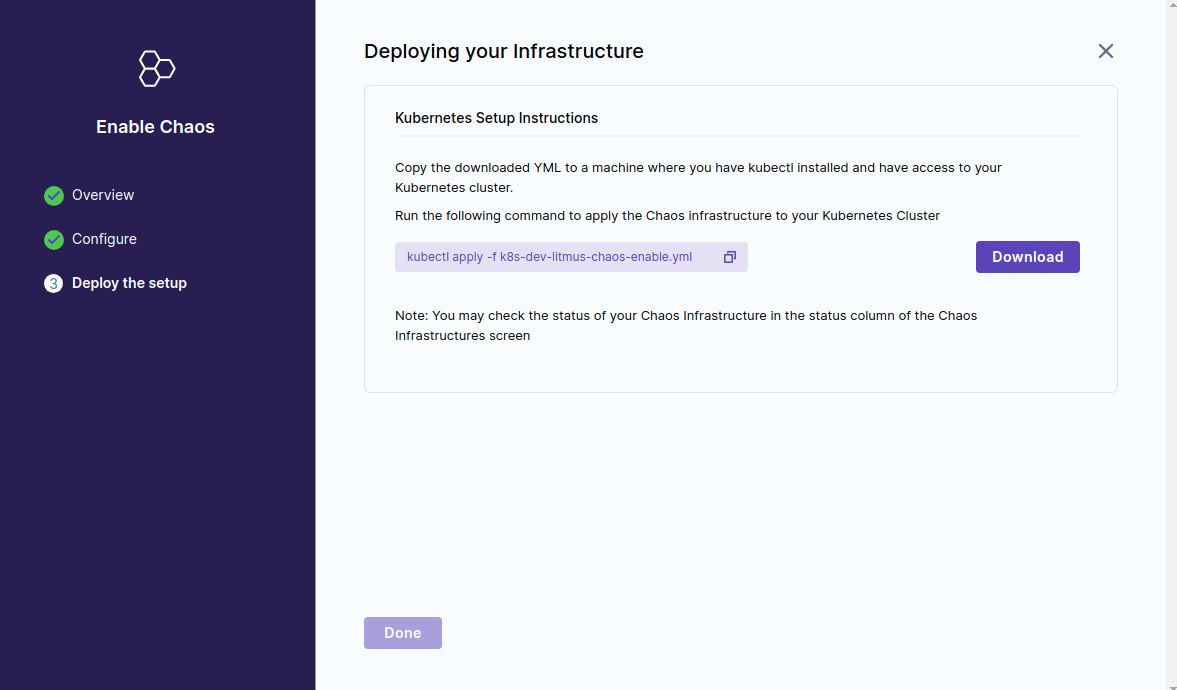
yaml をダウンロードした後、control plane と通信できるようにするため以下の部分を修正します。
configmap の data.SERVER_ADDR が control plane の chaos-litmus-server-service service の clusterIP に指定されているので、クラスタ外から通信できるよう ingress に設定したドメイン名に変更します。今回の環境では nodePort 32324 で公開されている nginx ingress controller にアクセスするとサービスにルーティングされる設定となっているため以下のように書き換えます。
apiVersion: v1
kind: ConfigMap
metadata:
name: subscriber-config
namespace: litmus
data:
- SERVER_ADDR: http://10.98.199.124:9002/query
+ SERVER_ADDR: https://litmus.ops.com:32324/backend/query
また、今回の環境では nginx ingress controller に自己署名証明書を使用してしているため、そのままだと control plane と通信する execution plane 上の pod (subscriber と呼ばれる) で証明書チェックに失敗するエラーが発生します。証明書チェックを行わないため subscriber の deployment の env に SKIP_SSL_VERIFY を追加します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: subscriber
namespace: litmus
spec:
...
env:
+ - name: SKIP_SSL_VERIFY
+ value: "true"
なお configmap の方にも SKIP_SSL_VERIFY の項目があるのでこちらを true に変更してもいいかもしれません。
apiVersion: v1
kind: ConfigMap
data:
SKIP_SSL_VERIFY: "false"
変更したら execution plane 用のクラスタ k8s-dev 上で kubectl apply -f [filename] を実行します。
デプロイが完了すると管理コンポーネントに対応する pod + operator pod が起動します。
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
chaos-exporter-5659c844d5-4kqct 1/1 Running 0 23h
chaos-operator-ce-794f58c9cc-z8vg2 1/1 Running 129 (3m43s ago) 23h
event-tracker-7cbf75c7f7-tbh49 1/1 Running 0 23h
subscriber-788999df-kbkw6 1/1 Running 6 (45m ago) 20h
workflow-controller-69df994ddf-59wks 1/1 Running 0 23h
control plane と chaos infra の通信が正常に行われるとダッシュボード上の表示が pending から connected に変わります。
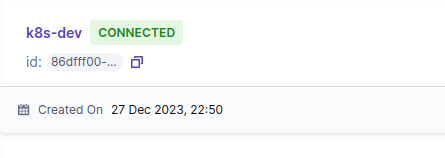
ここでステータスが pending から変更しない場合、chaos infra 上の subscriber pod と control plane 間の通信がうまくいっていない場合が多いです。ネットワークの通信経路が正常でない、証明書関連の設定が適切でないなど理由はいろいろありますが、たいてい subscriber pod のログにエラー内容が出力されているため kubectl logs で内容を確認して修正するのが良いです。
障害の検証
control plane と execution plane の準備ができたので実際に障害を注入して動作検証することができます。litmus では様々な障害を組み合わせて対象の resilience を評価するワークフローがダッシュボードから作成できますが、その前に litmus においてどのように障害を発生させるのかを理解するため、まずは単体で障害を注入する際の手順について見ていきます。
litmus では ChaosEngine というカスタムリソースを作成することで対象のリソースに障害を注入する構成になっています。カスタムリソースの種類や記述方法は下記のドキュメントにまとまっています。
実施できる障害は pod, node レベルでいろいろあるので、ここではその中からいくつか選んで動作を検証していきます。
事前準備
障害の動作確認のため、k8s-dev クラスタ上に litmus-test という namespace を作成します。
kubectl create ns litmus-test
検証用に nginx の pod (replica 10) を起動します。また、外部からこの pod にアクセスできるように service, ingress も作成します。
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
namespace: litmus-test
spec:
replicas: 10
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
---
piVersion: v1
kind: Service
metadata:
name: nginx-service
namespace: litmus-test
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: nginx-ingress
spec:
ingressClassName: nginx
rules:
- host: litmus-test.ops.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: nginx-service
port:
number: 80
pod 削除
まずは単純な障害として ポットの削除 を試します。これは対象の deployment 内の pod をランダムで削除する障害を発生させます。
基本的に各障害について実施に必要な前提条件やリソース、記述方法はドキュメントにまとまっているのでこれを参照していくことになります。
例えば pod 削除に必要な RBAC 権限は Minimal RBAC configuration example に書いてあります。この条件を満たす service account と role を別途作成してもいいですが、chaos infra の構築時に litmus-cluster-scope という serviceaccount が既に作成済みであるため今回はこれを流用します。
デフォルトでは job リソースの create 権限が不足しているため、ClusterRole に権限を追加しておきます。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: litmus-cluster-scope
...
rules:
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["get", "list", "deletecollection", "create"]
...
具体的な障害のプロパティはドキュメントの Experiment tunables や Experiment Examples を見て設定していきます。今回は単純なケースとして、60 秒間、 15 秒間隔でランダムに pod を削除する動作となるようにプロパティを設定します。
- 障害の対象にするリソースは
appinfo以下に namespace, kind, label の 3 つで指定。 -
chaosServiceAccountには serviceaccount 名のlitmus-cluster-scopeを指定。 - 障害のプロパティは
spec.experiments[].spec.components.envに key-value で指定していく。
# tune the deletion of target pods forcefully or gracefully
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: pod-delete
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "litmus-test"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-cluster-scope
experiments:
- name: pod-delete
spec:
components:
env:
- name: FORCE
value: 'true'
- name: TOTAL_CHAOS_DURATION
value: '60'
- name: CHAOS_INTERVAL
value: '15'
ChaosEngine リソースを作成すると、これに対応する [chaos-engine-name]-runner という名前の pod が起動します。処理の中で実際に pod を削除する動作を実行するための [experiment-name]-[random_string] job pod も起動します。
NAME READY STATUS RESTARTS AGE
pod-delete-runner 1/1 Running 0 21s
pod-delete-t1527f-zdbwg 1/1 Running 0 19s
experiment の実行中は設定値に応じてランダムに pod が削除されます。experiment が完了した後に対象の pod 一覧を確認してみましょう。
$ kubectl get pod -n litmus-test
NAME READY STATUS RESTARTS AGE
nginx-6b7f675859-2zspm 1/1 Running 0 4m32s
nginx-6b7f675859-68z2n 1/1 Running 0 4m32s
nginx-6b7f675859-6lqg8 1/1 Running 0 3m35s
nginx-6b7f675859-6lrkv 1/1 Running 0 4m33s
nginx-6b7f675859-9dr8c 1/1 Running 0 4m32s
nginx-6b7f675859-cjmvk 1/1 Running 0 104s
nginx-6b7f675859-fbr5n 1/1 Running 0 2m44s
nginx-6b7f675859-fjfrg 1/1 Running 0 4m32s
nginx-6b7f675859-g7lzg 1/1 Running 0 4m32s
nginx-6b7f675859-v88wt 1/1 Running 0 4m33s
削除されていない pod は同じタイミングで起動しているため AGE が同じですが、削除されたものに関しては削除時に新しい pod が起動するため AGE が他の pod よりも短くなっていることがわかります。
job pod の log から実際にどの pod が削除されたか確認できます。
$ kubectl logs pod-delete-m5wxqk-dd8fp pod-delete-m5wxqk
time="2023-12-28T14:49:20Z" level=info msg="[Chaos]:Number of pods targeted: 1"
time="2023-12-28T14:49:20Z" level=info msg="Target pods list for chaos, [nginx-6b7f675859-wrgz5]"
time="2023-12-28T14:49:20Z" level=info msg="[Info]: Killing the following pods" PodName=nginx-6b7f675859-wrgz5
time="2023-12-28T14:49:20Z" level=info msg="[Wait]: Wait for the chaos interval 10s"
time="2023-12-28T14:49:30Z" level=info msg="[Status]: Verification for the recreation of application pod"
time="2023-12-28T14:49:30Z" level=info msg="[Status]: Checking whether application containers are in ready state"
time="2023-12-28T14:49:30Z" level=info msg="[Status]: The Container status are as follows" Pod=nginx-6b7f675859-2zspm Readiness=true container=nginx
time="2023-12-28T14:49:32Z" level=info msg="[Status]: Checking whether application pods are in running state"
ただしタイムスタンプを確認すると正確に 15 秒間隔で削除が実行されているわけではないようです。メッセージを見る限り、pod を削除する前に指定した label をもつ pod の status (ここでは replica 10 個分の pod) を確認する動作を行っており、その部分で少し時間がかかっているため若干のずれが生じているようです。なので実際にこの障害を試す際はこの部分の処理時間も考慮する必要があります。
http latency
Pod HTTP Latency では svc にアクセスした際、レスポンスを返すまでに遅延を発生させることができます。
前提条件として、この yaml を適用して ChaosExperiment リソースを作成しておきます。
障害を注入する前に、まず遅延がない場合にサービスにアクセスした際に平均してどのぐらいかかるか計測しておきます。測定には k6 を使用しました。
scenarios: (100.00%) 1 scenario, 10 max VUs, 40s max duration (incl. graceful stop):
* default: 10 looping VUs for 10s (gracefulStop: 30s)
data_received..................: 83 kB 8.3 kB/s
data_sent......................: 9.1 kB 905 B/s
http_req_blocked...............: avg=639.72µs min=2.02µs med=5.55µs max=7.54ms p(90)=495.31µs p(95)=6.63ms
http_req_connecting............: avg=607.65µs min=0s med=0s max=7.4ms p(90)=415.15µs p(95)=6.4ms
http_req_duration..............: avg=3.25ms min=1.09ms med=2.02ms max=23.28ms p(90)=5.32ms p(95)=8.58ms
{ expected_response:true }...: avg=3.25ms min=1.09ms med=2.02ms max=23.28ms p(90)=5.32ms p(95)=8.58ms
http_req_failed................: 0.00% ✓ 0 ✗ 100
http_req_receiving.............: avg=424.08µs min=24.99µs med=109.45µs max=15.04ms p(90)=806.5µs p(95)=1.39ms
http_req_sending...............: avg=37.35µs min=8.77µs med=22.88µs max=641.26µs p(90)=52.83µs p(95)=121.81µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=2.79ms min=1.03ms med=1.73ms max=21.73ms p(90)=5.13ms p(95)=8.16ms
http_reqs......................: 100 9.94531/s
iteration_duration.............: avg=1s min=1s med=1s max=1.03s p(90)=1.01s p(95)=1.01s
iterations.....................: 100 9.94531/s
vus............................: 10 min=10 max=10
vus_max........................: 10 min=10 max=10
http_req_duration: avg=3.25ms より、正常な場合では 10 秒間リクエストを送信した際にレスポンスが返されるまでの時間は平均 3 msec 程度となっています。
では以下の ChaosEngine リソースを作成して遅延を発生させます。明示的に指定しない場合、デフォルトでは 2 sec の遅延が発生します。
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: pod-http-latency
spec:
engineState: "active"
annotationCheck: "false"
appinfo:
appns: "litmus-test"
applabel: "app=nginx"
appkind: "deployment"
chaosServiceAccount: litmus-cluster-scope
experiments:
- name: pod-http-latency
spec:
components:
env:
# provide the port of the targeted service
- name: TARGET_SERVICE_PORT
value: "80"
リソースを作成すると、pod delete と同様に chaosEngine 用の runner pod、および実際に遅延を発生させるための pod が起動します。
pod-http-latency-j6ttqj-kqg44 1/1 Running 0 72s
pod-http-latency-runner 1/1 Running 0 75s
この間に同様に k6 で pod に対するリクエストを測定します。
scenarios: (100.00%) 1 scenario, 10 max VUs, 40s max duration (incl. graceful stop):
* default: 10 looping VUs for 10s (gracefulStop: 30s)
data_received..................: 71 kB 6.4 kB/s
data_sent......................: 7.7 kB 698 B/s
http_req_blocked...............: avg=655.52µs min=2.37µs med=5.96µs max=12.99ms p(90)=2.11ms p(95)=5.07ms
http_req_connecting............: avg=369.71µs min=0s med=0s max=5.02ms p(90)=1.93ms p(95)=3.39ms
http_req_duration..............: avg=195.64ms min=1.24ms med=4.97ms max=2.01s p(90)=30.87ms p(95)=2s
{ expected_response:true }...: avg=195.64ms min=1.24ms med=4.97ms max=2.01s p(90)=30.87ms p(95)=2s
http_req_failed................: 0.00% ✓ 0 ✗ 85
http_req_receiving.............: avg=304.5µs min=24.09µs med=98.1µs max=7.63ms p(90)=399.52µs p(95)=1.15ms
http_req_sending...............: avg=62.2µs min=10.82µs med=24.64µs max=534.57µs p(90)=127.31µs p(95)=320.55µs
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=195.27ms min=1.13ms med=4.14ms max=2.01s p(90)=30.46ms p(95)=2s
http_reqs......................: 85 7.670342/s
iteration_duration.............: avg=1.19s min=1s med=1s max=3.02s p(90)=1.03s p(95)=3s
iterations.....................: 85 7.670342/s
vus............................: 1 min=1 max=10
vus_max........................: 10 min=10 max=10
http_req_duration: : avg=195.64ms となっているので障害を注入していないときと比べてレスポンスが遅くなっていますが、それでも 2 sec の latency は発生していません。というのも 1 回の障害注入につき 1 pod しか遅延が発生しないため、svc にアクセスした際に遅延が発生している pod にルーティングされる際はレスポンスが返るまで 2 sec かかりますが、その他の pod にルーティングされる場合は通常と同じ速度で返ってくるためです。
max=2.01s となっているので、遅延が発生している pod にルーティングされたリクエストは確かに 2 sec かかっていることもわかります。
効果をより見やすくするため、pod 数を 1 に設定して再度同様の測定を実施します。
scenarios: (100.00%) 1 scenario, 10 max VUs, 40s max duration (incl. graceful stop):
* default: 10 looping VUs for 10s (gracefulStop: 30s)
data_received..................: 33 kB 2.8 kB/s
data_sent......................: 3.6 kB 302 B/s
http_req_blocked...............: avg=2.18ms min=2.05µs med=4.99µs max=13.03ms p(90)=9.48ms p(95)=11.07ms
http_req_connecting............: avg=2.13ms min=0s med=0s max=12.38ms p(90)=9.32ms p(95)=10.83ms
http_req_duration..............: avg=2s min=2s med=2s max=2.01s p(90)=2.01s p(95)=2.01s
{ expected_response:true }...: avg=2s min=2s med=2s max=2.01s p(90)=2.01s p(95)=2.01s
http_req_failed................: 0.00% ✓ 0 ✗ 40
http_req_receiving.............: avg=195.98µs min=22.4µs med=73.46µs max=2.91ms p(90)=231.3µs p(95)=688.34µs
http_req_sending...............: avg=222.1µs min=7.92µs med=20.59µs max=2.05ms p(90)=446.26µs p(95)=1.99ms
http_req_tls_handshaking.......: avg=0s min=0s med=0s max=0s p(90)=0s p(95)=0s
http_req_waiting...............: avg=2s min=2s med=2s max=2.01s p(90)=2.01s p(95)=2.01s
http_reqs......................: 40 3.31839/s
iteration_duration.............: avg=3.01s min=3s med=3.01s max=3.02s p(90)=3.01s p(95)=3.01s
iterations.....................: 40 3.31839/s
vus............................: 10 min=10 max=10
vus_max........................: 10 min=10 max=10
running (12.1s), 00/10 VUs, 40 complete and 0 interrupted iterations
この場合は http_req_duration: avg=2s min=2s となっていることから、今度は想定通りすべてのリクエストに対して 2 sec の latency が発生していることがわかります。
node 再起動
pod レベルの障害の他に node レベルの障害を注入することもできます。ここでは Node Restart を試します。node Restart は文字通り k8s クラスタ内のノードを再起動する動作であるため、予期せぬ障害によって node がダウンして一時的に通信できないような状況を再現することができます。
前提条件
Prerequisites を見る限り対象の node に ssh でログインして reboot コマンドを実行する挙動となっているため、ssh 用の keypair を作成して k8s secret に格納しておく必要があります。また、これを実行する pod に対応する ChaosExperiment リソースを作成しておく必要があります。
その他、デフォルトでは node に対する 権限が不足しているため、ClusterRole に権限を追加しておきます。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: litmus-cluster-scope
...
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get","list"]
...
実行
今回はクラスタ内の worker node である kube-dev-worker を停止させます。
NAME STATUS ROLES AGE VERSION
kube-dev-master Ready control-plane 132d v1.26.0
kube-dev-worker Ready <none> 132d v1.26.0
Example を参考に ChaosEngine リソースを作成します。
example では ssh ユーザが root になっていますが、対象ノードの OS は ubuntu なので ubuntu ユーザでログインするようにします (root ユーザでアクセスするにはおそらく sshd の設定が必要)。また REBOOT_COMMAND コマンドで sudo を指定しているように、ログインユーザがパスワードなしで sudo コマンドを実行できるように権限を設定しておく必要もありそうです。
apiVersion: litmuschaos.io/v1alpha1
kind: ChaosEngine
metadata:
name: restart
spec:
engineState: "active"
annotationCheck: "false"
chaosServiceAccount: litmus-cluster-scope
experiments:
- name: node-restart
spec:
components:
env:
- name: REBOOT_COMMAND
value: 'sudo systemctl reboot'
- name: TARGET_NODE
value: 'kube-dev-worker'
- name: TOTAL_CHAOS_DURATION
value: '60'
- name: SSH_USER
value: ubuntu
上記の ChaosEngine リソースを作成すると、node-restart pod が起動します。また、処理過程において helper pod という名前の pod が作成されます。この pod 内で対象 node への ssh を行い REBOOT_COMMAND で指定した再起動コマンドを実行する動作となっています。
helper pod はコマンドを実行したらすぐに終了するので、kubectl event 等で確認できます。
4m18s Normal Scheduled Pod/node-restart-helper-pmigkm Successfully assigned litmus/node-restart-helper-pmigkm to kube-dev-master
4m17s Normal Pulling Pod/node-restart-helper-pmigkm Pulling image "litmuschaos/go-runner:latest"
4m16s Normal Started Pod/node-restart-helper-pmigkm Started container node-restart
4m16s Normal Created Pod/node-restart-helper-pmigkm Created container node-restart
4m16s Normal Pulled Pod/node-restart-helper-pmigkm Successfully pulled image "litmuschaos/go-runner:latest" in 1.542583586s (1.542593965s including waiting)
node-restart pod のログでは一連の動作が実行されていることが確認できます。
$ kubectl logs node-restart-xbadae-xlq2t node-restart-xbadae
time="2023-12-28T18:28:25Z" level=info msg="Experiment Name: node-restart"
time="2023-12-28T18:28:25Z" level=info msg="[PreReq]: Getting the ENV for the node-restart experiment"
time="2023-12-28T18:28:27Z" level=info msg="[PreReq]: Updating the chaos result of node-restart experiment (SOT)"
time="2023-12-28T18:28:32Z" level=info msg="The application information is as follows" Node Label= Target Node=kube-dev-worker Chaos Duration=60
time="2023-12-28T18:28:32Z" level=info msg="[Info]: Details of application under chaos injection" Target Node=kube-dev-worker Target Node IP=10.0.0.15
time="2023-12-28T18:28:32Z" level=info msg="[Status]: Checking the status of the helper pod"
time="2023-12-28T18:28:36Z" level=info msg="node-restart-helper-pmigkm helper pod is in Running state"
time="2023-12-28T18:28:38Z" level=info msg="[Wait]: Waiting till the completion of the helper pod"
time="2023-12-28T18:28:38Z" level=info msg="helper pod status: Running"
time="2023-12-28T18:28:38Z" level=info msg="[Status]: The running status of Pods are as follows" Status=Running Pod=node-restart-helper-pmigkm
time="2023-12-28T18:28:39Z" level=info msg="[Cleanup]: Deleting the helper pod"
time="2023-12-28T18:28:41Z" level=info msg="[Confirmation]: node-restart chaos has been injected successfully"
time="2023-12-28T18:28:41Z" level=info msg="[The End]: Updating the chaos result of node-restart experiment (EOT)"
node が再起動することによって node status も一時的に NotReady となります。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
kube-dev-master Ready control-plane 132d v1.26.0
kube-dev-worker NotReady <none> 132d v1.26.0
対象 node 上で配置されている pod は node の起動が完了するまではアクセスできないので、この障害注入によって node レベルの冗長性などの確認が可能です。
ワークフローの検証
上記では ChaosEngine リソースを作成することでどのように単体の障害を発生させているかを確認しました。litmus では複数の障害を組み合わせて一連のワークフローとして実行し、クラスタやアプリケーションの resilience を評価することができます。ダッシュボードの Chaos Experiments から作成できるのでこちらも試してみます。
resilience probe の作成
ワークフロー内で resilience を評価するためには resilience probe と呼ばれるリソースを作成して障害に結びつける必要があります。これは障害発生中に事前定義された http リクエストやコマンドを実行し、決められた条件を満たすかどうかを見ることにより障害の合否を判定するためのリソースとなっています。
現時点では以下 4 種類の probe を使用できます。
- httpProbe: To query health/downstream URIs
- cmdProbe: To execute any user-desired health-check function implemented as a shell command
- k8sProbe: To perform CRUD operations against native & custom Kubernetes resources
- promProbe: To execute promql queries and match prometheus metrics for specific criteria
今回は簡単な http Probe を定義します。これは単純に指定した url に対して http リクエストを送信し、レスポンスの status code に基づいて障害の有無を判定するものとなっています。
作成はダッシュボードの resilience probe > + new probe から行います。作成する probe の種類が表示されるので http を選択。
名前はなんでもいいので、ここでは http-check とします。次に probe の timeout や間隔などのプロパティを選択。
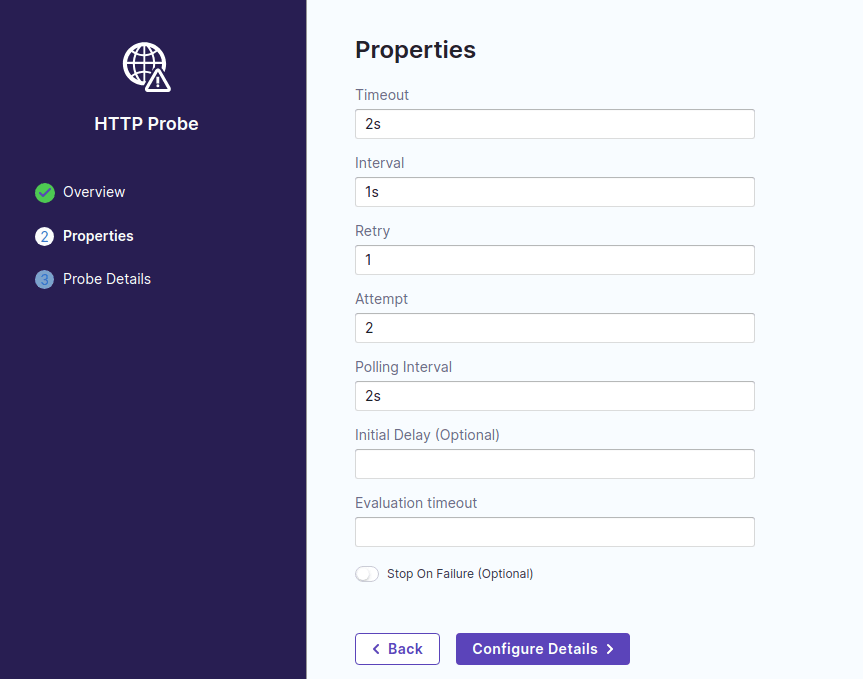
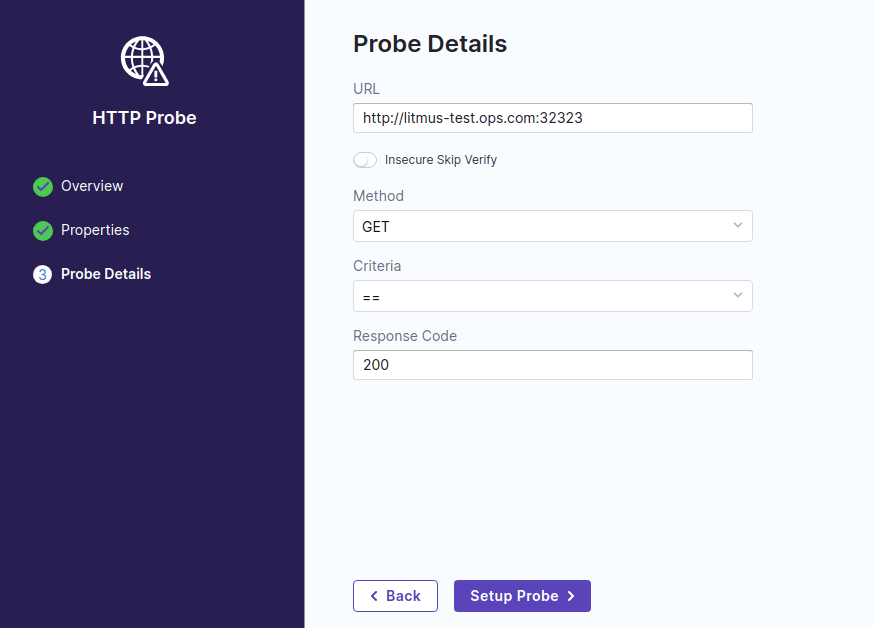
最後に http のリクエスト先、メソッド、成功条件を指定。ここでは単純に status code が 200 だったら成功とみなす条件に設定します。
ワークフローの作成
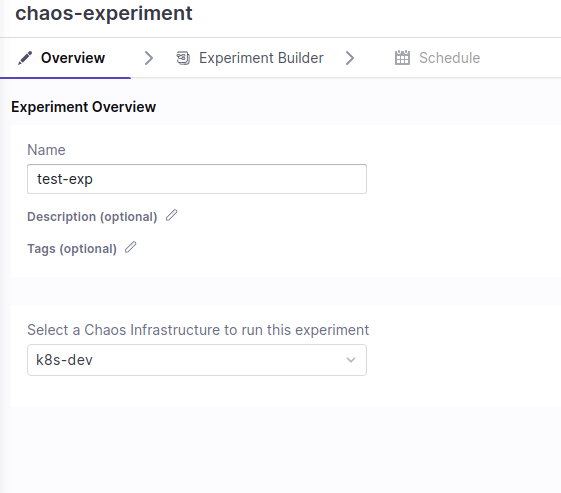
一連の障害を実施するワークフローはダッシュボードの Chaos Experiments から作成できます。
はじめに experiments の名前と対象の chaos infra を設定します。
次の Experiment Builder という画面ではよくあるグラフィカル形式で障害のワークフローを作成できるようになっています。builder 内の Add を選択すると、事前に定義されている障害をワークフローに組み込めるようになっています。

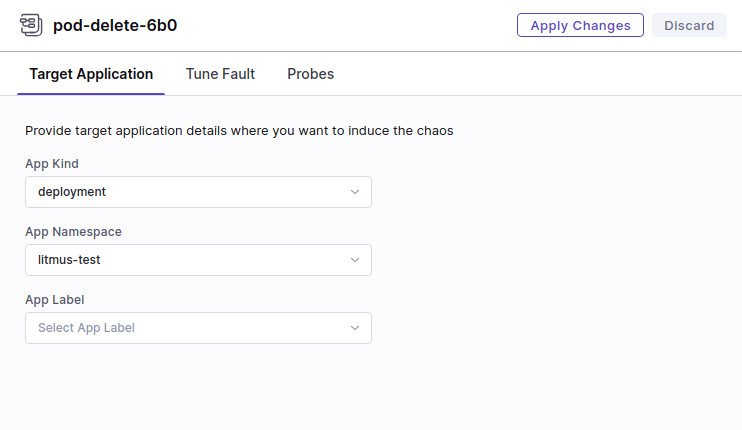
まずは単体の障害注入で検証した pod delete を試します。Kubernetes > pod-delete を選択すると障害のプロパティを指定する画面に遷移するので設定していきます。ここで指定する値は基本的に ChaosEngine の spec 等に対応しています。
例えば以下の Target Application タブで指定する項目は spec.appinfo に対応しています。ちなみに本来は App label が選択できるはずですが、何故かここでは選択できませんでした(バグ?)。このあたりのプロパティは後から変更できるのでいったん空欄で進めます。
Tune Fault タブは experiments.spec の障害の時間や発生間隔のプロパティに対応しています。
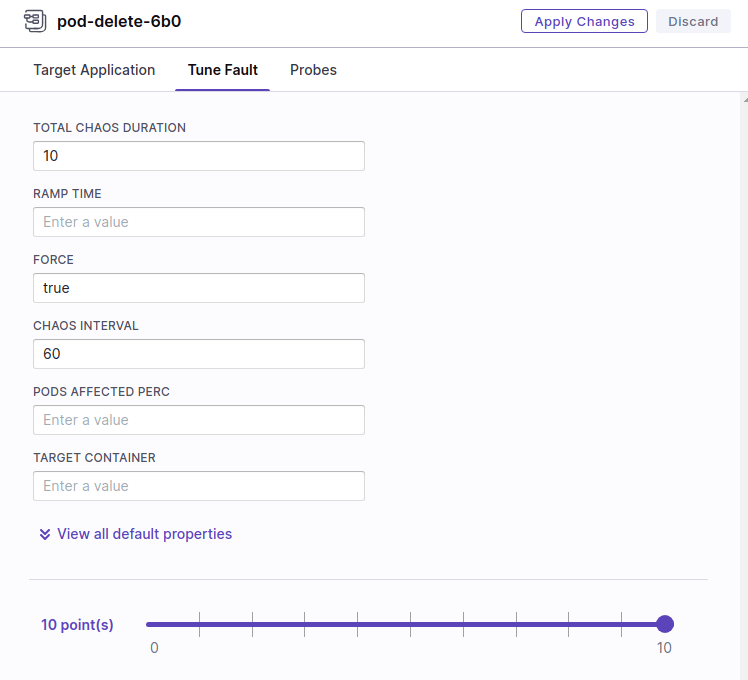
Probes タブでは障害中の正常性確認に使用する resilience probe を指定します。ここでは先ほど作成した http-check probe を選択します。
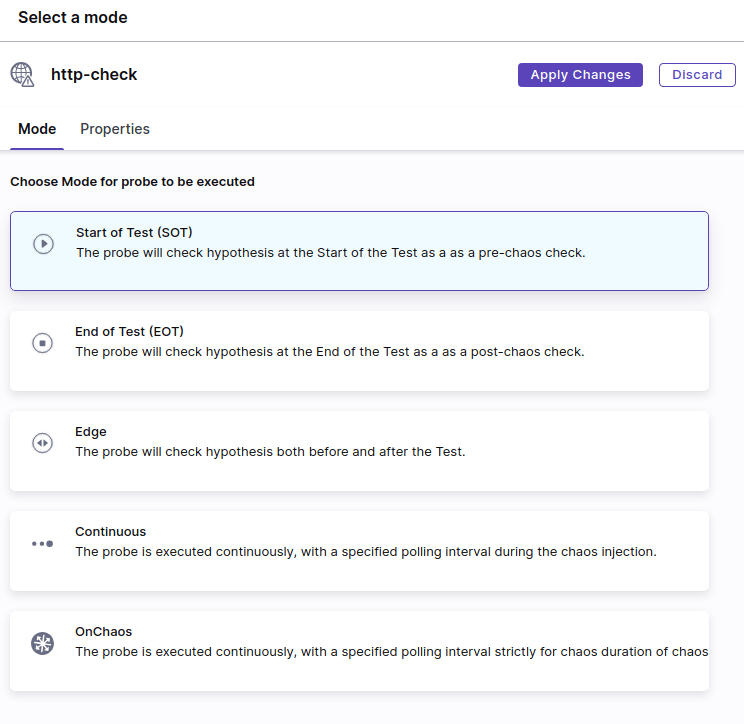
mode タブでは probe を実行するタイミングを選択できます。今回は障害中に継続して実行したいため Continuous を指定します。
これで障害に必要なプロパティが設定できたので右上の Apply Changes で設定を適用し、builder 画面で Save を押して変更を保存します。
また、builder 画面中央の visual|yaml で yaml を選択すると、現在のワークフローの内容を yaml 形式で表示できます。
中身を辿っていくと先程空欄にしていた appinfo.applabel の部分があるので app=nginx を設定します。
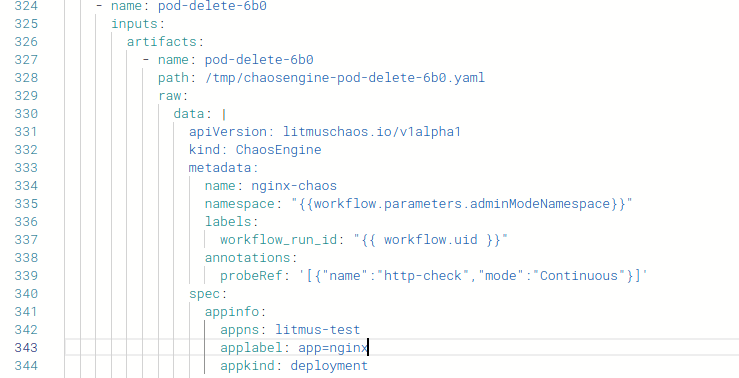
なお yaml の内容からわかるように、内部的には Argo Workflow を使ってワークフロー処理を実現しているようです。
実行
作成した workflow は Run を押すことで即時に実行されます。
workflow の実行中は Logs から対象クラスタ上に作成された pod の log が表示されます (改行等が適用されていないので見にくい)。
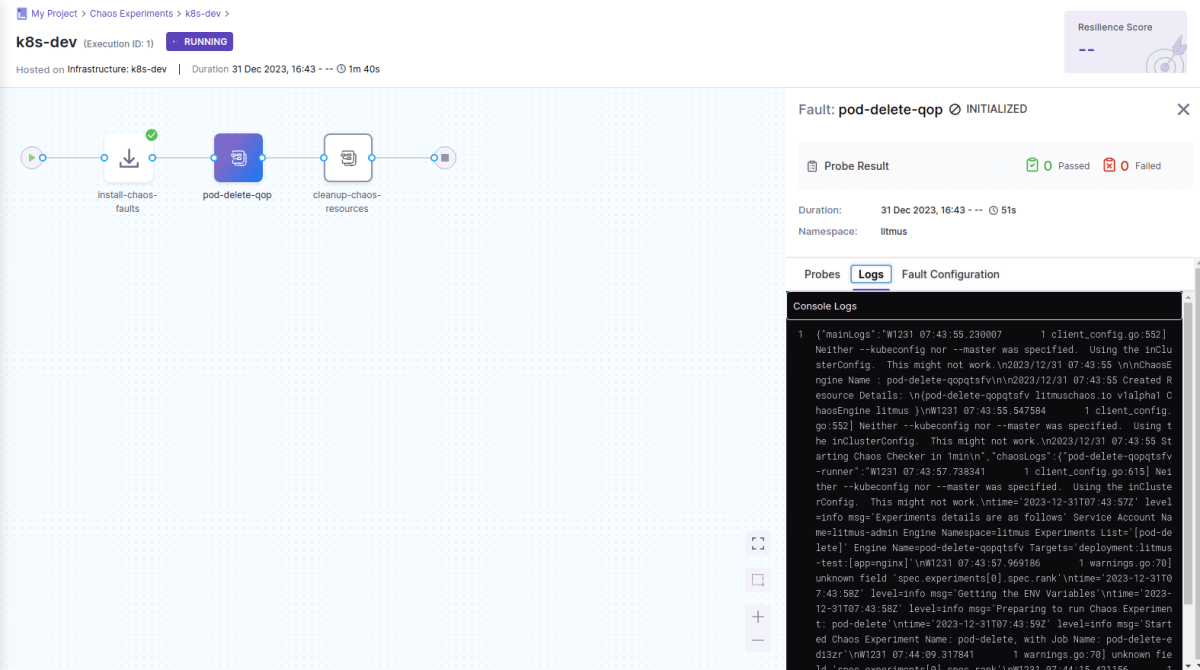
workflow が完了すると障害自体の probe の Pass/Failed の結果や全体の probe 結果を元に算出された resilience score が表示されます。
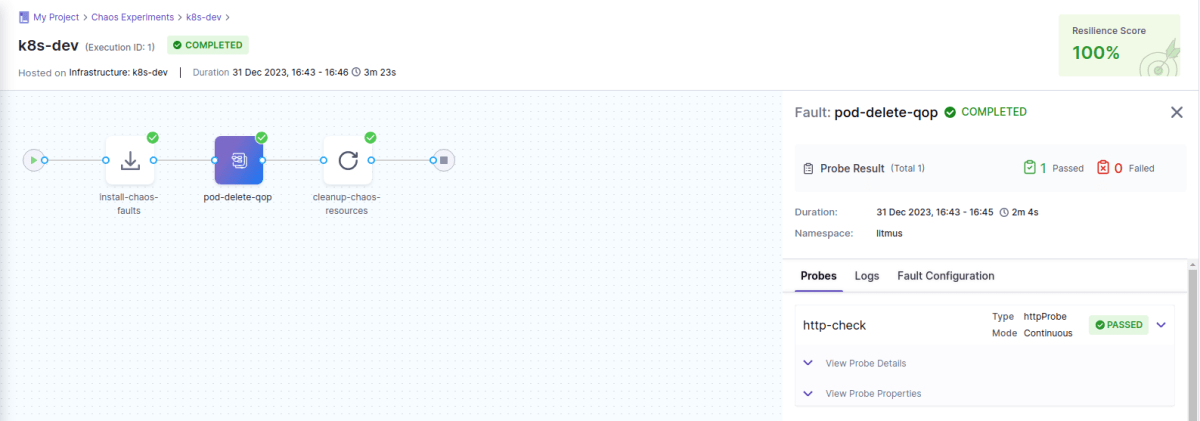
この検証においては対象の pod replicas 数を 10 に設定しているので、 pod が数個削除されても外部からのアクセスにはダウンタイムなしで対応できます。障害発生中の http probe はいずれも成功するので resilience score は 100 % となっています。
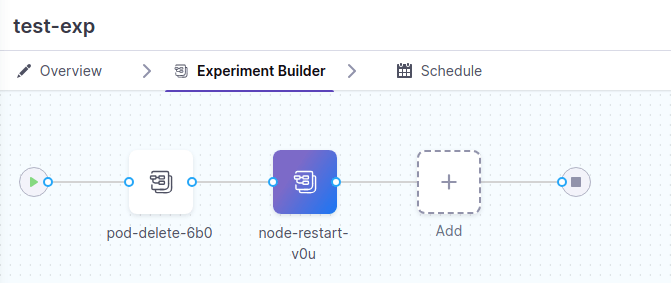
次に、元のワークフローに node-restart の障害を追加します。node-restart の probe には pod delete と同様に http-check probe を設定します。
これを実行すると、resilience score は 50 % となりました。また、node restart の障害には✅ がついていないことがわかります。
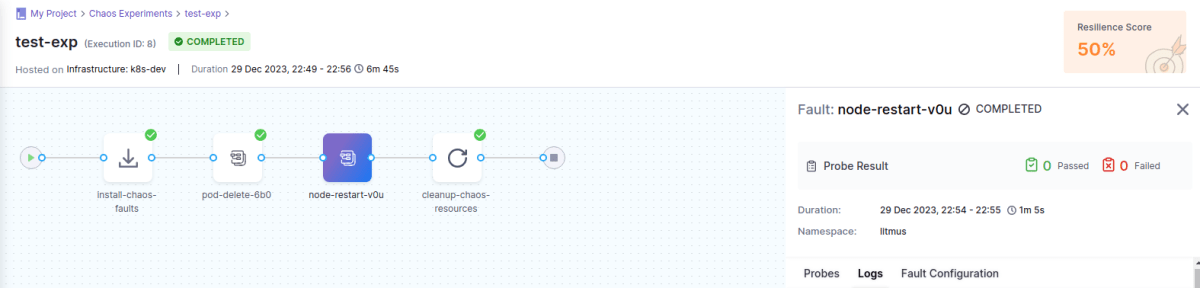
検証用のクラスタではシングル worker node 構成のため、worker node がダウンするとすべての nginx pod が落ちて再起動が完了するまでサービスにアクセスできません。そのため、node restart に設定した http probe は失敗とみなされます。
How the Resilience Score Algorithm works in Litmus! に記載の通り、resilience score はワークフロー全体の resilience probe の成功・失敗とその重みによって算出されます。今回のワークフローでは pod delete と node restart にそれぞれ同じ重みで http probe が設定されており、片方が成功、もう片方が失敗となっているのでスコアは 50 % と算出されています。
2 つのワークフローを実行した結果より、今回検証に使用した k8s クラスタとアプリの構成では、pod レベルの障害に対しては十分な resilience を持っているが、node レベルの障害に対しては resilience が不足していることがわかります。クラスタがシングル worker node 構成であるのである意味自明の結果ではありますが、node レベルの resilience を上げるためには worker node を追加し、各 node に pod を配置する必要があることが今回の障害テストでわかりました。
より大規模なクラスタやアプリの構成であっても上記のように任意に障害を注し、その耐障害性や resilience を評価することができます。
まとめ
k8s 用のカオスエンジニアリングツール litmus を使ってクラスタ上の pod や node に対して障害注入、耐障害性の評価を試しました。
カオスエンジニアリングと聞くといろいろ事前知識や大規模なリソースが必要そうでなかなかとっつきづらいイメージがありますが、litmus は比較的小さな環境ですぐに構築、検証が行えるため、カオスエンジニアリングを実践するための第一歩として良さそうです。
また pod, node レベルの障害も手軽で体系的に発生させることができるので、ちょっとした正常性確認や負荷テストを試すのにも使えるかと思います。
Discussion