【AWS】気合い入れて取り組んだコスト削減施策:月額389円しか削減できず企画倒れした話【サブスクの料金かな?】
初めに
本記事は私の失敗談を共有し、皆様に笑顔を届けるために書きました。
...というのは半分冗談です。
もう半分で、読んでくださった方に、「どんな仕事でも改善する余地はあるかもな」と少しでも思っていただけないかなと考えています。
どうにかして誰かに何かの価値を届けられる記事になっていたら幸いです。
目次
初めに
本記事の結論
背景
やったこと
現状とバックアップ方法案を言語化しながらコスト削減できそうか思案
データサイズの計算
結果
感想
本記事の結論
- 考えの筋は良く、一定(月額389円)の削減効果はありそうだった
- データサイズの関係で費用対効果が悪かった
- AWSって企業から見ると本当に安く信頼性のあるクラウドなんだなぁ
背景
私はSES企業所属。
案件は機械学習モデルの保守・運用業務をメインに担当しています。
いわゆるMLOps的な業務。
既存モデルの精度改善、学習パイプライン自動化、正常性確認処理追加などに取り組んでいるのですが、10月ごろに特徴量ストアを作成してバックアップを取ろう、という話が出ました。
現在進行形でバックアップを取るためにS3料金調査、保存期間検討、実装・テスト方法検討、などなどタスクが走っています。
そのうちの一つで以前記事にしたS3の利用料金調査はこちら↓
諸々の検討が終わり、実装をしている最中、妙な処理を発見。
今使っているモデルは複数サービスに対して各1個ずつモデルを作成するタイプなのですが、特徴量がほとんど一緒。
それなのにS3の源泉データからAthenaを使用して学習に使ったら毎回そのデータをローカルから削除している。それをサービスごとに繰り返していたのです。
サービスは50前後あるし、重複して取得しているレコードがかなりありそうだなぁ
↓
これを1回クエリ叩く処理に変えたらコスト削減につながって顧客のビジネス貢献になるかも
↓
ひいては自社からの評価アップでボーナス向上...!?
↓
やってみよう!
ということであまり深く考えず、今回のコスト削減施策に取り組み始めました。
深く考えなかったから先々あんなことに...
やったこと
処理を追加するなら問題ないものの、既存のバッチ処理を修正していろいろやるとなると顧客とすり合わせが必要になる。
提案までにやったことを具体的に書いていきます。
現状とバックアップ方法案を言語化しながらコスト削減できそうか思案
この時はまだコスト削減を本気で目指していたわけではなく、現状の流れを把握してバックアップをどこでとるのがいいかを考えていました。
まずは現行の処理の整理から。
複数サービスごとにS3からAthenaを利用してデータ取得、学習と推論が回り切ったら取ってきたデータをメモリから破棄、それを全メディア分繰り返すという処理をしている。
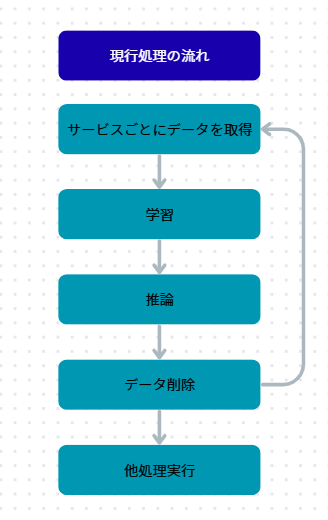
この処理にバックアップをかませるのは簡単で、学習終わりか推論終わりにちょっと処理を加えるだけ。

ここでふとデータを消す意味あるのか?と疑問に思い始めました。
各サービスごとに対象のユーザーが異なるため、完全に同じ特徴量をサービス間で使用することはないものの、毎回S3にデータを取りに行くためデータに重複がある場合余計なクエリが生まれ、Athena利用料金が高くなっている可能性があるのでは?
また、このバックアップ方式だと、サービスごとにS3オブジェクトを生成して保存することになるため、同じく重複があると料金がかさむのでは...?
ということで、各サービスの特徴量がどうなっているかを整理してみました。
| アカウントID | デモグラ特徴量 | 各サービスの実績値 | ターゲットサービスの正解ラベル |
|---|---|---|---|
| 1カラム | 50カラム | 実績値2種類 * メディア数 | 1カラム |
メディア数は50程度なので、大体150カラム存在している。
サービスごとで取得するレコード数と一括でとった時のレコード数の総数を比較して、前者のほうが大きいなら一括でとったほうがましになるなと考えてSQLをたたく。
↓
結果前者のほうが2.5倍程度大きい!
ということで「なんとなく5割くらいはコスト削減できそうだな」というのが分かったので、ここから本格的に提案するための計算を始めました。
データサイズの計算
S3もAthenaもざっくりデータサイズに比例して料金が増えるサービス。
ということで、それぞれのパターンでどのくらいのデータを扱っているのか調べてみることに。
まず、一括でとった時のカラムがどうなるかを確認。下記のようになりました。
| アカウントID | デモグラ特徴量 | 各サービスの実績値 | ターゲットサービスの正解ラベル |
|---|---|---|---|
| 1カラム | 50カラム | 実績値2種類 * メディア数 | 1カラム * メディア数 |
異なるのは正解ラベルのみ。もともとはターゲットサービスのみのラベルを保持すればいいだけだったが、一括でとるとなると全メディアの正解データを先に保持する必要がある。
UU数が大体1億、サービスごとに取得すると2.5億程度になるのは先の調べで分かっていたのでデータサイズ計算に。
データの計算方法は、「int, float型なら8バイト」「strなら英語1文字につき1バイト」で各カラムを計算。
今回はアカウントID以外はすべてint型 or float型だったためざっくり全カラム8バイトとして計算。
計算式はData_Size = カラム数 * カラムごとのbyte * レコード総数となるので、
・サービスごと取得 = 280 GB
・一括取得 = 148 GB
という結果に。
やった!!一括でとったほうが安くなる!!! これで高評価いただきだぜ!!!!
結果
上記の結果を受けて下記のようなバックアップ処理を考えました。

一括で必要な全ユーザーを取得し、その中間テーブルをS3にバックアップ。
その後サービスごとに必要な特徴量を引き抜いてdfに落とし込み、学習推論を実行した後中間dfだけ削除、それを繰り返すという処理。
こちらだと1度しか源泉S3にクエリを投げず、Athenaのスキャン量とバックアップのデータ量が小さくなるためコスト最適化がなされるという寸法です。
そんなこんなで、具体的にどれだけコストが削減できるのかうきうきで計算をしてみました。それが下記。
- コスト削減前
- S3料金:
280GB * 0.025ドル/GB * 3か月 * 150円 = 3150円 - Athena料金:
280GB / 1024(TB換算) * 5ドル/TB * 150円 = 205円 - 合計
3355円
- 合計
- S3料金:
- コスト削減後
- S3料金:
148GB * 0.025ドル/GB * 3か月 * 150円 = 1665円 - Athena料金:
148GB / 1024(TB換算) * 5ドル/TB * 150円 = 108円 - 合計
1773円
- 合計
- S3料金:
差額1582円!!!!!!
1582円!!?!??!!??
小学生のお小遣いかな????
頭痛くなってきた...
はっ!! S3にはparquet形式で入れられるからデータ圧縮されるじゃん!!!
しかもバックアップだからストレージタイプがStandardじゃなくてIAが適切!!!!
そうなると...
- コスト削減前 parquet形式
- S3料金:
280GB / 5 * 0.0138ドル/GB * 3か月 * 150円 = 630円 - Athena料金:
280GB / 1024(TB換算) * 5ドル/TB * 150円 = 205円 - 合計
835円
- 合計
- S3料金:
- コスト削減後 parquet形式
- S3料金:
148GB / 5 * 0.0138ドル/GB * 3か月 * 150円 = 338円 - Athena料金:
148GB / 1024(TB換算) * 5ドル/TB * 150円 = 108円 - 合計
446円
- 合計
- S3料金:
差額389円!!!!!!
感想
何かのサブスク料金かな?(すっとぼけ
しょうもないことに時間を使ってしまった...
ただ、仮説のコスト半減はあっていましたし、本記事で書いたものは諸々省いたうえでの計算なので、最大年間2万円の削減効果は期待できる施策となっています。
他タスクが詰まってさえなければリファクタリングしたほうがよさそうだと顧客からもお伺いしてはいます。
...まあ売り上げが兆単位の企業において、毎年2万の削減は価値があるのかと言われたら目をそらすしかないのですが。
今回削減コストが極小になってしまったのはデータサイズが小さいからでもあります。
より大きなモデルで、かつバックアップ機関がより長くなると、今回考えたリファクタリングも意味が出そうなので、この経験は無駄ではなかったなと感じています。
引き続き価値提供に重きを置いて日々の業務に取り掛かります!
今週もお疲れ様でした!!
Discussion