RAGに次ぐ情報拡張技術の提案【論文要約】
初めに
こんにちは、AIエンジニアを目指しているmitaです!
今回は
REX-RAG: Reasoning Exploration with Policy Correction in
Retrieval-Augmented Generation
という、RAGと強化学習を使って情報拡張能力を向上させる技術に関する論文を要約&考察していきます。
キャッチアップした内容を共有していくので、何かしらの形でお役に立てれば光栄です!
論文要約
- REX-RAG は、強化学習ベースのRAG(RLVR)における「dead end」問題を解決するために設計されたフレームワーク。
- 2つの柱:
- Mixed Sampling Strategy — 標準ポリシーと探索用ポリシーを組み合わせ、多様な推論経路を生成。
- Policy Correction Mechanism — 探索経路の質を確保し、分布ずれを補正。
- 実験では、7つのQAベンチマークでSFTや従来RLVRを上回る成績を達成し、特にマルチホップ推論や未知ドメインで強みを示した。
論文の詳細
研究背景
- RAG は外部知識を検索+生成する仕組みだが、行動方針は固定的。
- RLVR はRAGの検索戦略や推論手順を強化学習で最適化し、性能向上を実現。
- しかしRLVRは学習中に「dead end(誤った推論経路への早期収束)」が発生しやすく、探索の多様性が不足。
- REX-RAGは、この探索不足を解消しつつ学習を安定化することを目的とする。
REX-RAGとは
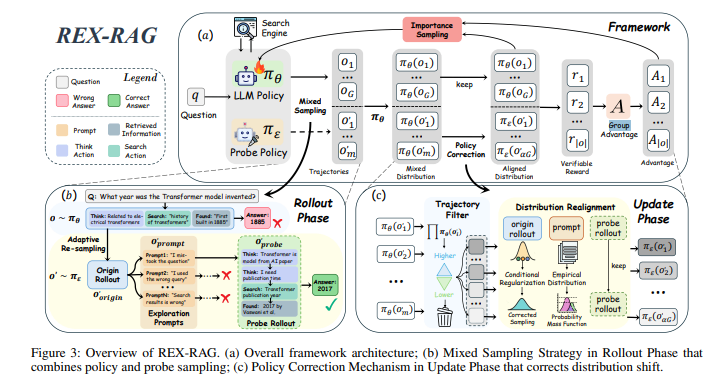
REX-RAGはRAGの発展形であるRLVRで問題となったdead end問題を解決するために提案された手法で、以下の2コンポーネントで構成される。
1. Mixed Sampling Strategy(混合サンプリング戦略)
- 標準ポリシーと探索用ポリシーを組み合わせた混合ポリシーを使用。
- 誤答経路には探索用プロンプトを挿入し、別方向の推論を試みる。
- Adaptive Probe Re-sampling により探索強度を正答率に応じて自動調整。
- プロンプトプールは多様な推論方向を提供するため事前生成。
2. Policy Correction Mechanism(方策補正機構)
- Trajectory Filtering:標準ポリシーと十分に一致する探索経路のみを採用。
- Distribution Realignment:重要度サンプリングで分布ずれを補正。
- これにより探索経路のノイズを減らし、勾配推定の安定性を確保。
Dead End(デッドエンド)とは
1. 概要
Dead End(デッドエンド)とは、探索型アルゴリズムや推論過程において、
これ以上進んでも正解や目的地にたどり着けない行き止まり状態を指す。
機械学習、特に強化学習や情報検索系のタスクでは、
探索の幅が狭まりすぎた結果、正解経路から外れたまま進み続ける現象として現れる。
2. 典型的な発生パターン
-
情報不足による行き止まり
- 検索や推論で得られる情報が限定的で、次のアクション候補が消える。
- 例: 検索エンジンから結果が返らず、追加のヒントも得られない。
-
方策の過学習(Exploitation Bias)
- 過去に成功した経路だけを強化しすぎ、
新しい経路を試さないために未知の正解に到達できなくなる。
- 過去に成功した経路だけを強化しすぎ、
-
局所最適化
- 一見良さそうな部分的解に固執し、グローバルな最適解に到達できない。
3. Dead Endが問題となる理由
-
探索の多様性が失われる
- 未知の正解経路を発見する機会が減少する。
-
性能の頭打ち
- 一定の精度以上に成長できず、タスクの難易度が上がるほど失敗率が増える。
-
長期的な報酬の低下
- 短期的に有効な行動が長期的に失敗へつながるケースが見逃されやすい。
実験結果
- モデル:Qwen2.5-3B/7B-Instruct
- データセット:NQ, TriviaQA, PopQA, HotpotQA, 2Wiki, Musique, Bamboogle
- 評価指標:Exact Match(EM)
結果概要:
- 3Bモデル:SFT比 +5.1%、標準RL比 +4.1%
- 7Bモデル:SFT比 +3.6%
- マルチホップや未知ドメインで特に大幅改善。
アブレーション結果:
- 方策補正機構(IS, TF)を外すと性能大幅低下。
- Adaptive削除でも低下するが、IS/TF削除ほどではない。
個人的感想
論文解釈
REX-RAGはdead endを解決するために、わざと最適解から外れた情報を学習することによって次回以降の推論に幅を持たせ、局所最適解から外れやすくした手法である。
それを実現するために、RLVRで使用されている強化学習ポリシー(LLM Policy)に加えて、Exploraion Prompts(探索用プロンプト)を生成するProbe Policyを併用。
最適解と別探索経路を生成し動的に選択。最適解と混合してアウトプットの確率分布を生成する。
強化学習フェーズ(Update Phase)においては、最適解から離れすぎているアウトプットを補正することで、最適解を大きく崩さずに探索幅拡大に成功している。
考察(感想)
恥ずかしながら、RLVRという技術が存在することすら知らず、さらにその発展形があることに驚きました。
私は個人開発レベルでRAGを触ったことがありますが、その際は「回答が得られなければn回探索しなおす」という単純な処理を加えていました。
今回の論文は、単なる再探索ではなく別経路で探索しなおすという発想であり、非常に勉強になりました。
もちろん、探索経路を複数用意するということは、並列処理を行ったとしても従来手法と比べて探索時間が短くなるわけではないでしょう。
本論文の主眼は精度向上であり、速度改善が論点ではないことは承知していますが、個人的にはRLVRの論文を参照しつつ、RAGの探索時間削減に寄与する研究も読んでみたいと思いました。
具体的な数値は記載されていませんでしたが、マルチホップ問題でも従来手法より性能が向上しているとのことです。
AGIを実現するためには、未知の環境から一般知識を抽出・応用できることが不可欠です。
その過程で複雑なマルチホップ問題にも直面するため、この研究は大いに役立つと考えています。
そうなると、やはり気になるのは「現実世界の情報をどう学習するのか」「未知の環境にどう到達するのか」という点です。
AIは現実世界ではなく、あくまでメモリ上の仮想世界で動作しています。では、どのように物理空間にAIを拡張するのでしょうか。
Sim2Realのように、現実世界を仮想空間に落とし込み、そこで学習した知識やスキルを現実に適用することは可能だと考えられます。
しかし、人間が持つ視覚・聴覚・嗅覚・触覚・味覚といった感覚を、AIにどのように実装し、物理空間で学習させるのかは非常に難しい課題です。
真に人間と同等以上の能力を持つAIを目指すなら、知的能力だけでなく身体的能力の再現も必要になるのではないでしょうか。
今後は、
- AIが五感を持つ研究
- 仮想空間での学習を現実空間に活かす手法
- そもそも物理空間での活用を想定せず仮想空間内で完結させる方向性
といったテーマについても知見を深めていきたいと思います。
これからもキャッチアップを続けていくので、また見ていただけますと幸いです。
Discussion