こんにちは。ZENKIGENデータサイエンスチームの栗原です。
Llama 3.1 が公開され、クローズドモデル一強からオープンモデルが実用の候補に十分上がる時代が近づいてきました。今回は、Llama 3.1を実用する上での周辺トピックを紹介します。
Llama 3.1のライセンス
Llama 3.1が公開された際、そのライセンスについても注目が集まりました。
Meta公式XからのLlama 3.1のライセンスに関するポストで、Llama 3.1の出力を他のモデルの改良に利用可能にするという発表があり、界隈が盛り上がりました。
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
(DeepL翻訳)
我々はまた、開発者が405Bを含むLlamaモデルからの出力を使用して、他のモデルを改良することができるようにライセンスを更新しました。私たちは、合成データ生成とモデル蒸留ワークフローを通じて、この分野での新たな進歩を可能にすることに興奮しています。
実際のライセンスを見てみましょう。
Llama 3以前のモデルでは、以下の記述があり、モデルの出力を他のモデルの改善に使用することは許可されていませんでした。
Llama 2のライセンス(1. License Rights and Redistribution. > b. Redistribution and Use.内)
v. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Llama 2 or derivative works thereof).
(DeepL翻訳)
v. LlamaマテリアルまたはLlamaマテリアルの出力もしくは結果を使用して、他の大規模言語モデル(Llama 2またはその派生物を除く)を改良することはできません。
Llama 3のライセンス(1. License Rights and Redistribution. > b. Redistribution and Use.内)
v. You will not use the Llama Materials or any output or results of the Llama Materials to improve any other large language model (excluding Meta Llama 3 or derivative works thereof).
(DeepL翻訳)
v. LlamaマテリアルまたはLlamaマテリアルの出力もしくは結果を使用して、他の大規模言語モデル(Meta Llama 3またはその派生物を除く)を改良することはできません。
一方、Llama 3.1のライセンスでは、その記述は削除されています。
ただし、Llama 3.1の出力を利用してモデルを作成した場合、そのモデルの名称の先頭に「Llama」を含めることは求められています。
i. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.
(DeepL翻訳)
i. Llamaマテリアル(またはその派生物)、またはそれらを含む製品もしくはサービス(別のAIモデルを含む)を頒布または利用可能にする場合、利用者は、(A)当該Llamaマテリアルに本契約のコピーを添付し、(B)関連するウェブサイト、ユーザーインターフェイス、ブログ記事、アバウトページ、または製品ドキュメントに「Built with Llama」を目立つように表示するものとします。Llamaマテリアル、またはLlamaマテリアルの出力もしくは結果を使用して、AIモデルを作成、訓練、微調整、またはその他の方法で改良し、それを配布または利用可能にする場合、そのようなAIモデルの名称の先頭に「Llama」を含めるものとします。
以上、Llama 3.1のライセンスに関してでした。
出力を利用してモデルを改良可能になったのは非常に大きな進展だと思います。
Purple Llama: 安全な実運用のために
Purple Llamaは、不適切な入出力検知や安全性評価など、オープンLLMを安全に組み込む上で必要なツール群です。 現在(2024/08/01 現在)、Purple Llamaにはシステムレベルのセーフガード機能と、安全性評価とそのベンチマークが提供されています。
システムレベルセーフガード
- Llama Guard: 不適切な入出力を検知するために設計されたもので、最新のLlama Guard 3はMetaのLlama 3.1-8Bモデルをファインチューニングして構築されたモデルです。
- Prompt Guard: プロンプトインジェクション(事前に設定されたプロンプトやシステムメッセージに不正な入力を追加し意図しない命令を実行させる攻撃)やジェイルブレイク(モデル提供者が設定した出力制限やフィルタなどを解除する攻撃)などの攻撃を検知するために設計されたツールです。
- Code Shield: モデルが生成したコードの安全性を評価し、不適切なコードを検知するためのツールです。
安全性評価とベンチマーク
CyberSec Evalシリーズとして展開されているもので、LLM向けのサイバーセキュリティ安全性評価セットです。
以下が提供されています。
- LLMのサイバーセキュリティリスクを定量化する指標。(v1)
- 安全でないコードの提案頻度を評価するツール。(v1)
- LLMが悪意のあるコードを生成したり、サイバー攻撃の実行を支援することを困難にすることを評価するツール。(v1)
- LLMのコードインタープリタを悪用する傾向や攻撃的なサイバーセキュリティ能力、プロンプトインジェクションへの感受性の測定。(v2)
- 画像系のプロンプトインジェクションへのテスト、スピアフィッシング(個人情報や機密情報を詐取するための攻撃)能力のテスト、自律的な攻撃的サイバー操作のテスト。(v3)
様々なモデルに関して上記安全性指標を計測したリーダーボードも公開されています。
torchchat: 様々なデバイス上でLLMを動かす(MacBook上でLlama 3.1を動かしてみた)
torchchatは、ラップトップ、デスクトップ、モバイルの各デバイス上でLLMを動かすためのライブラリです。 今回はこのtorchchatを使って、Llama 3.1をMacBook上で動かしてみたいと思います。
手元の動作環境
- MacBook Pro (M3 Max)
- メモリ: 96GB
torchchatのセットアップ
まず、セットアップです。
# torchchatのリポジトリをクローン
git clone https://github.com/pytorch/torchchat.git
cd torchchat
# 仮想環境を作成
python3 -m venv .venv
source .venv/bin/activate
# 依存パッケージのインストール
./install_requirements.sh
モデルのダウンロード
次に、モデルをダウンロードするためにHugging Faceにログインします。
Hugging Faceのアカウントを持っていない場合は、こちらからアカウントを作成してください。
huggingface-cli login
すると、アクセストークンの入力を求められるので、Hugging Faceのアカウントページからwriteロールの付与されたトークンを取得して入力してください。取得方法はこちら。
また、Llama 3.1をダウンロードするためには、Hugging Faceのmeta-llamaのページ(meta-llama/Meta-Llama-3.1-8B-Instructなど)で、LLAMA 3.1 COMMUNITY LICENSE AGREEMENTに同意し、モデルへのアクセスのリクエストを送信、承認される必要があります。
私がリクエストを送った際は数分で承認されました。
では、モデルダウンロードの準備が整ったので、ダウンロードします。llama3.1と指定すると、meta-llama/meta-llama-3.1-8b-instructがダウンロードされます。
python3 torchchat.py download llama3.1
ダウンロードできるモデルは以下のコマンドで確認できます。
python3 torchchat.py list
出力例(2024/08/01 実行)
Model Aliases Downloaded
--------------------------------------- ------------------------------------------- -----------
meta-llama/llama-2-7b-hf llama2-base, llama2-7b
meta-llama/llama-2-7b-chat-hf llama2, llama2-chat, llama2-7b-chat
meta-llama/llama-2-13b-chat-hf llama2-13b-chat
meta-llama/llama-2-70b-chat-hf llama2-70b-chat
meta-llama/meta-llama-3-8b llama3-base
meta-llama/meta-llama-3-8b-instruct llama3, llama3-chat, llama3-instruct
meta-llama/meta-llama-3-70b-instruct llama3-70b
meta-llama/meta-llama-3.1-8b llama3.1-base
meta-llama/meta-llama-3.1-8b-instruct llama3.1, llama3.1-chat, llama3.1-instruct
meta-llama/meta-llama-3.1-70b-instruct llama3.1-70b
meta-llama/codellama-7b-python-hf codellama, codellama-7b
meta-llama/codellama-34b-python-hf codellama-34b
mistralai/mistral-7b-v0.1 mistral-7b-v01-base
mistralai/mistral-7b-instruct-v0.1 mistral-7b-v01-instruct
mistralai/mistral-7b-instruct-v0.2 mistral, mistral-7b, mistral-7b-instruct
openlm-research/open_llama_7b open-llama, open-llama-7b
stories15m
stories42m
stories110m
実行
では、ダウンロードしたモデルを使って、チャットをしてみましょう。
python3 torchchat.py chat llama3.1
"What is the most recommended spot in Tokyo?" という入力に対する、実際の実行時の画面録画を以下に示します。2.59 tokens/secという速度でした。
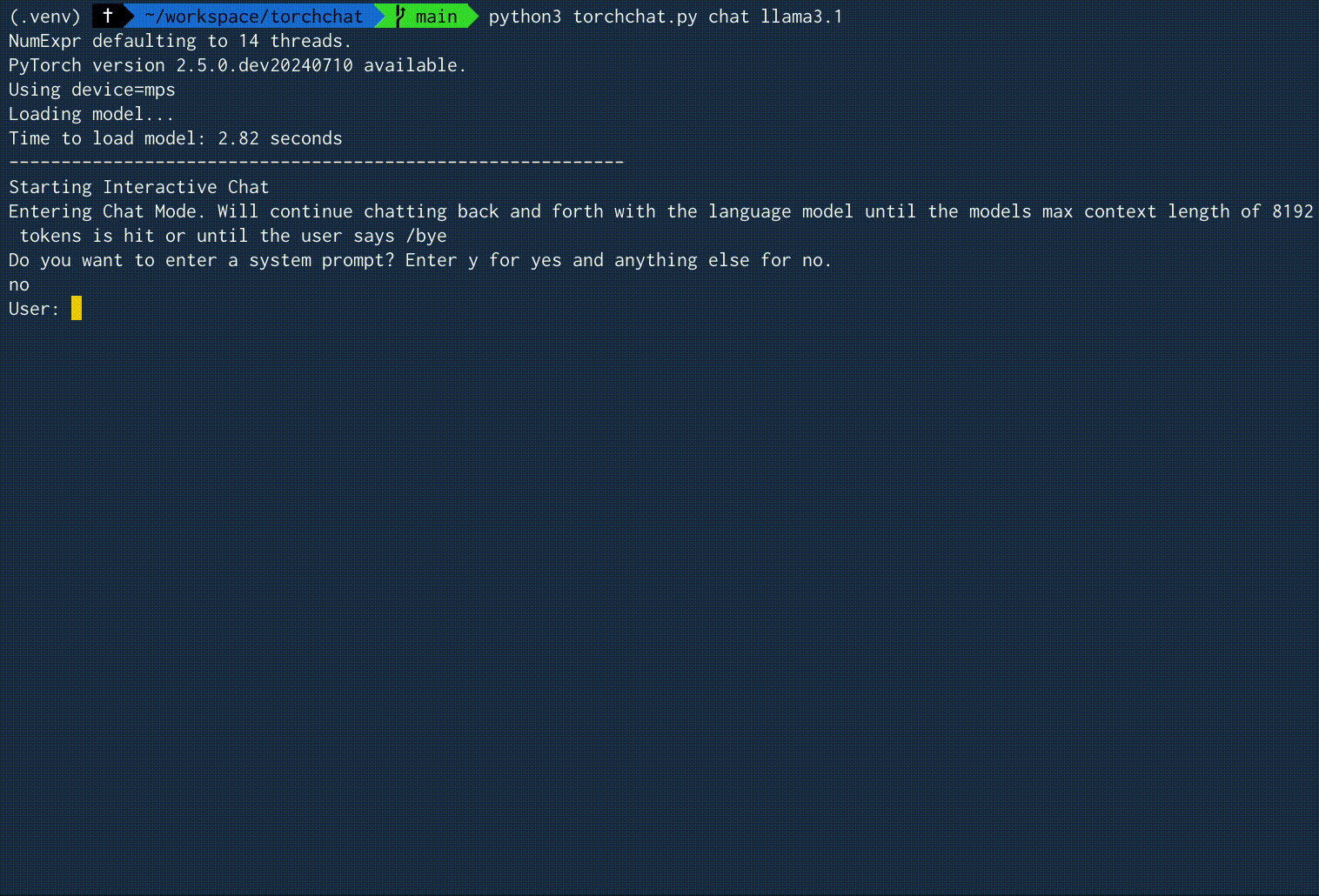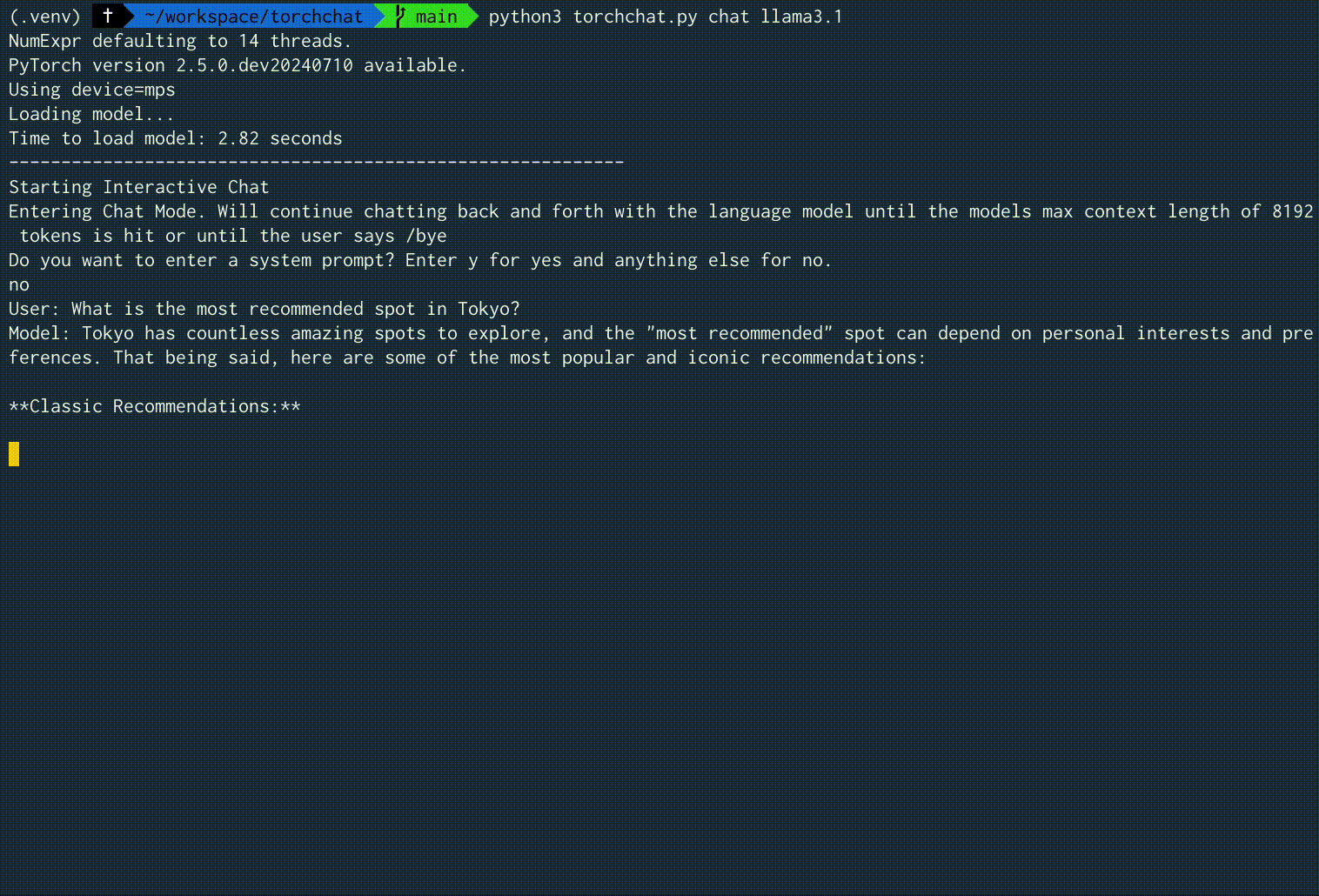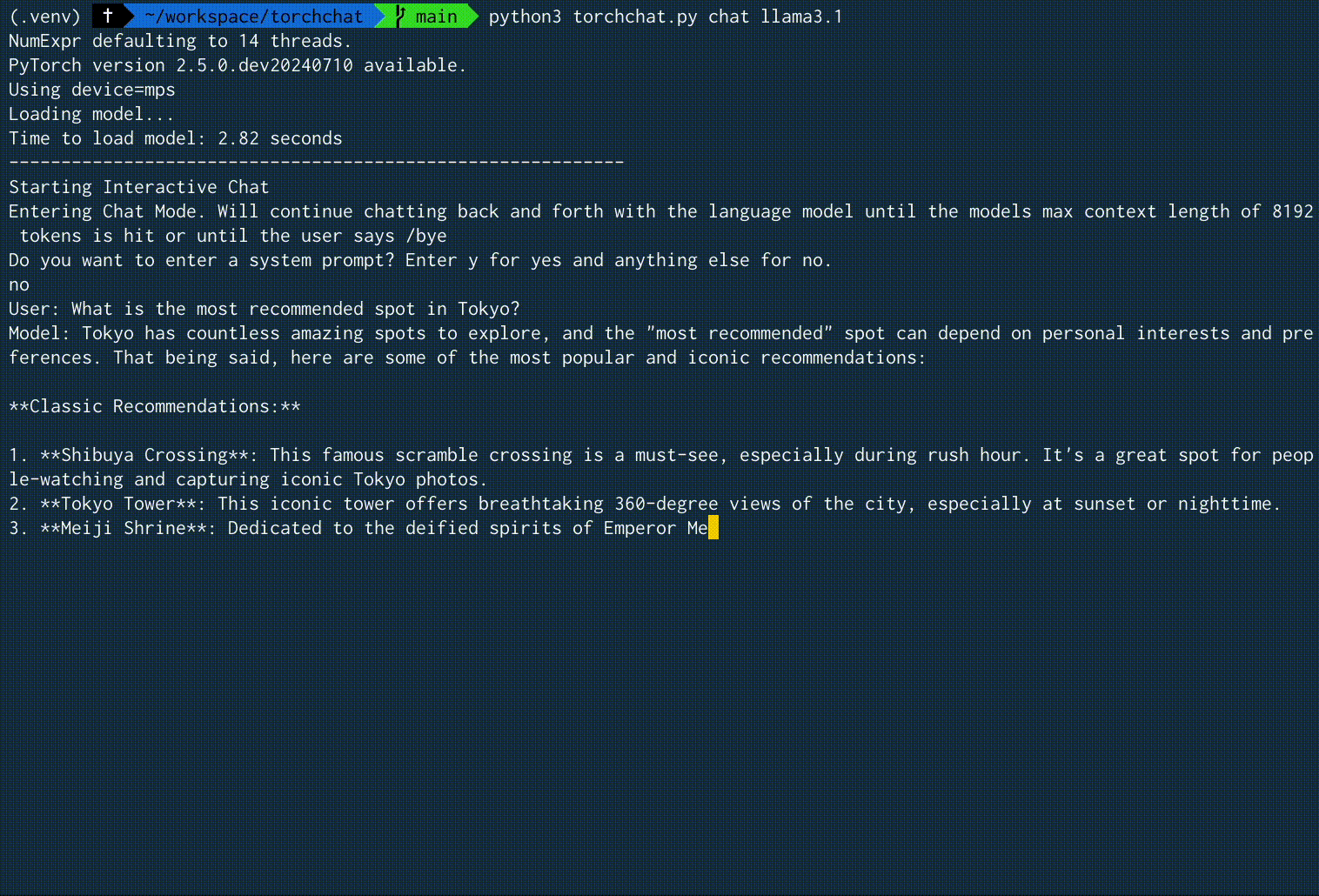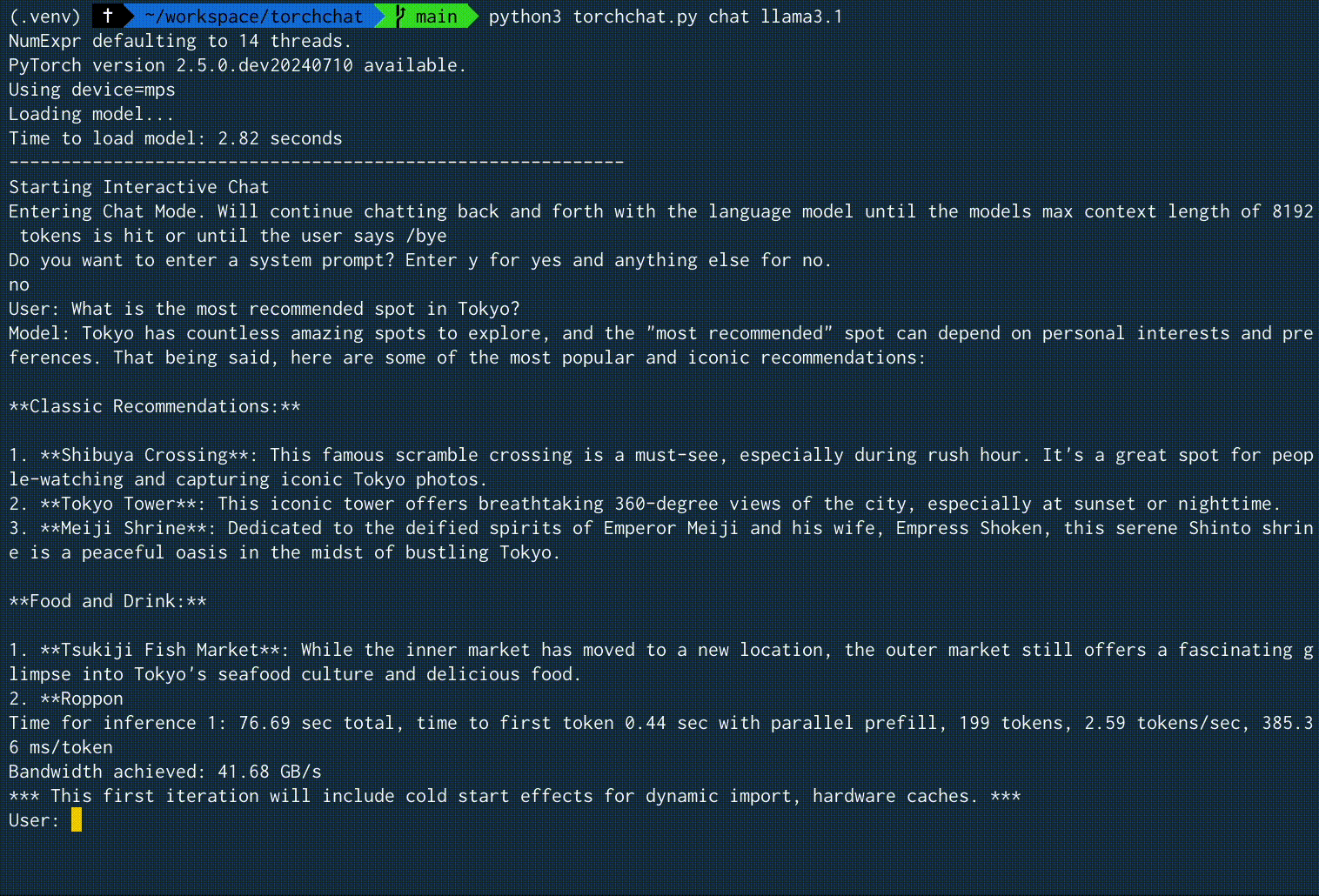
実行結果例全体
NumExpr defaulting to 14 threads.
PyTorch version 2.5.0.dev20240710 available.
Using device=mps
Loading model...
Time to load model: 2.82 seconds
-----------------------------------------------------------
Starting Interactive Chat
Entering Chat Mode. Will continue chatting back and forth with the language model until the models max context length of 8192 tokens is hit or until the user says /bye
Do you want to enter a system prompt? Enter y for yes and anything else for no.
no
User: What is the most recommended spot in Tokyo?
Model: Tokyo has countless amazing spots to explore, and the "most recommended" spot can depend on personal interests and preferences. That being said, here are some of the most popular and iconic recommendations:
**Classic Recommendations:**
1. **Shibuya Crossing**: This famous scramble crossing is a must-see, especially during rush hour. It's a great spot for people-watching and capturing iconic Tokyo photos.
2. **Tokyo Tower**: This iconic tower offers breathtaking 360-degree views of the city, especially at sunset or nighttime.
3. **Meiji Shrine**: Dedicated to the deified spirits of Emperor Meiji and his wife, Empress Shoken, this serene Shinto shrine is a peaceful oasis in the midst of bustling Tokyo.
**Food and Drink:**
1. **Tsukiji Fish Market**: While the inner market has moved to a new location, the outer market still offers a fascinating glimpse into Tokyo's seafood culture and delicious food.
2. **Roppon
Time for inference 1: 76.69 sec total, time to first token 0.44 sec with parallel prefill, 199 tokens, 2.59 tokens/sec, 385.36 ms/token
Bandwidth achieved: 41.68 GB/s
*** This first iteration will include cold start effects for dynamic import, hardware caches. ***
Llama 3.1は公式には日本語をサポートしていませんが、試しに日本語も入力してみました。
"東京でおすすめのスポットはありますか?" という入力に対する、実際の実行時の画面録画を以下に示します。
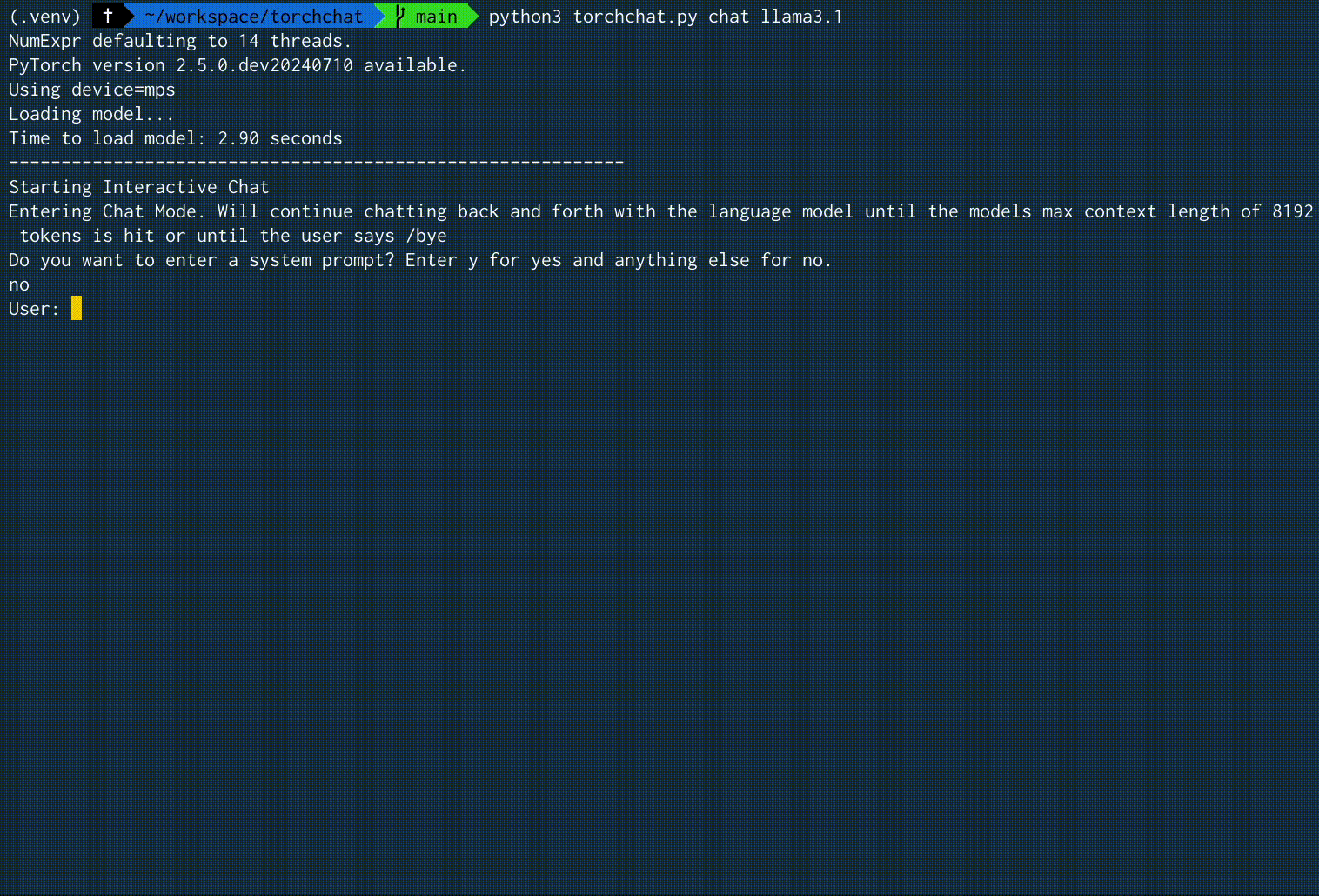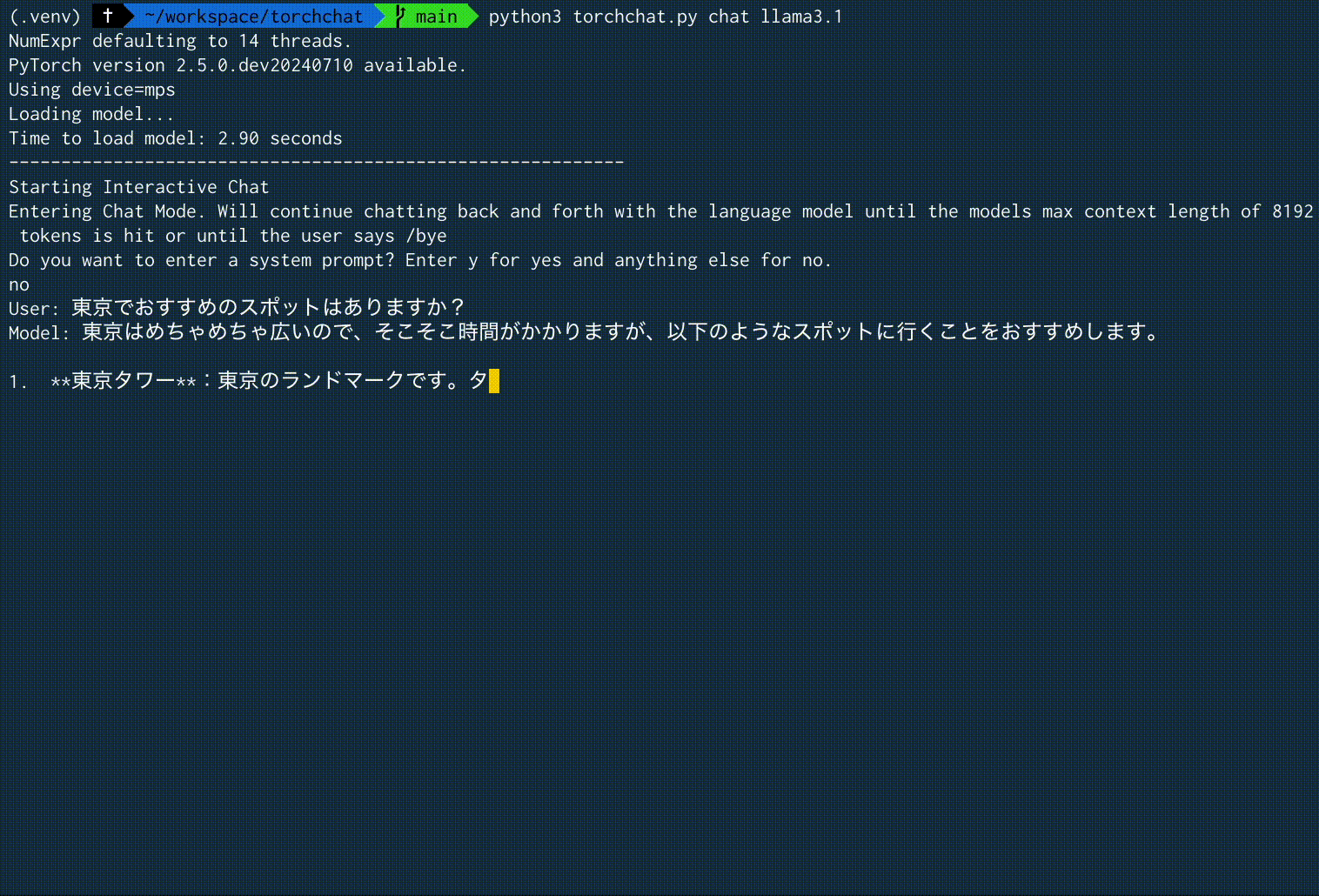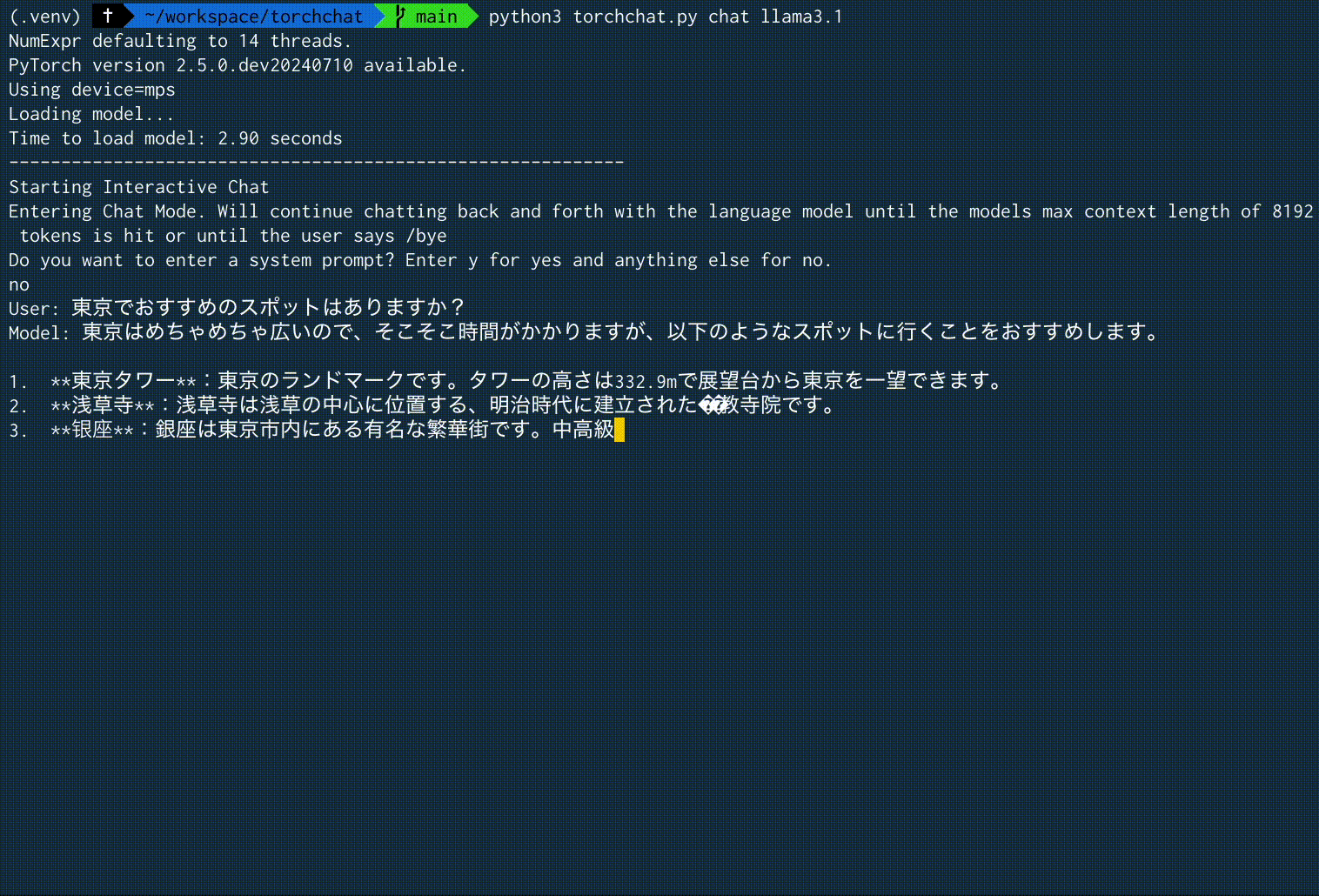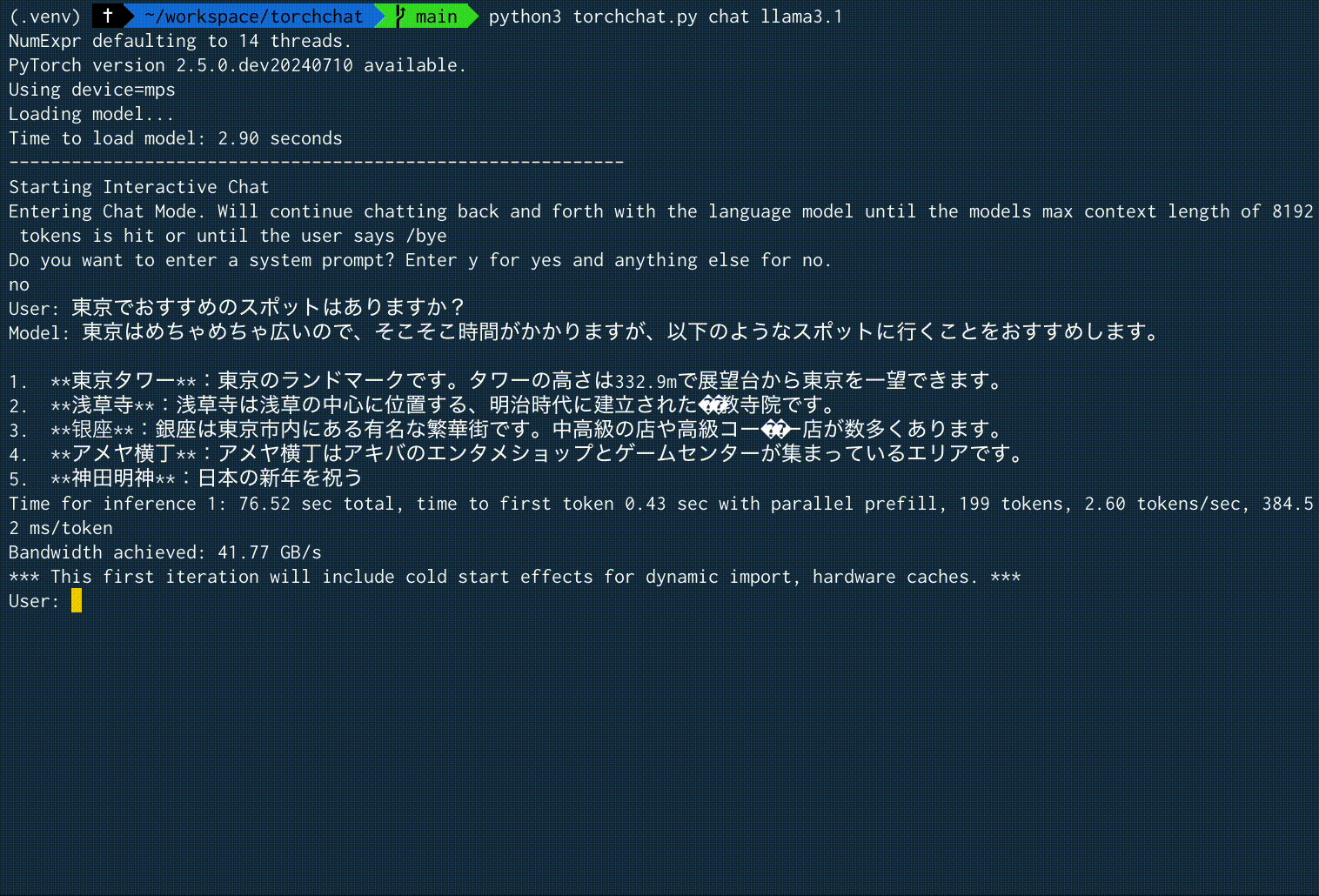
一部不自然な出力もありますが、日本語で回答してくれました。
実行結果例全体
NumExpr defaulting to 14 threads.
PyTorch version 2.5.0.dev20240710 available.
Using device=mps
Loading model...
Time to load model: 2.90 seconds
-----------------------------------------------------------
Starting Interactive Chat
Entering Chat Mode. Will continue chatting back and forth with the language model until the models max context length of 8192 tokens is hit or until the user says /bye
Do you want to enter a system prompt? Enter y for yes and anything else for no.
no
User: 東京でおすすめのスポットはありますか?
Model: 東京はめちゃめちゃ広いので、そこそこ時間がかかりますが、以下のようなスポットに行くことをおすすめします。
1. **東京タワー**:東京のランドマークです。タワーの高さは332.9mで展望台から東京を一望できます。
2. **浅草寺**:浅草寺は浅草の中心に位置する、明治時代に建立された��教寺院です。
3. **银座**:銀座は東京市内にある有名な繁華街です。中高級の店や高級コー��ー店が数多くあります。
4. **アメヤ横丁**:アメヤ横丁はアキバのエンタメショップとゲームセンターが集まっているエリアです。
5. **神田明神**:日本の新年を祝う
Time for inference 1: 76.52 sec total, time to first token 0.43 sec with parallel prefill, 199 tokens, 2.60 tokens/sec, 384.52 ms/token
Bandwidth achieved: 41.77 GB/s
以上、torchchatを使ってLlama 3.1をMacBook上で動かしてみました。
オープンで高性能なモデルの公開が続いている中、それをローカルで動かす環境の発展もさらに進んでいきそうです。
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion