こんにちは。ZENKIGENデータサイエンスチーム所属の川﨑です。ZENKIGENではharutaka EF(エントリーファインダー)やharutaka BI(ビジネスインテリジェンス)などの機能開発に関わっています。
所属チームでXアカウントを運用しており、AIに関する情報を発信していますのでご興味あれば覗いてみてください。
はじめに
昨今のLLMを始めとする生成AIの発展が著しく、我々の日常や業務にも生成AIを組み込んだサービスが増えていくことが予想されます。
一方で、技術発展や社会実装の速度に対してそれら技術を用いることに対するリスク/懸念の評価は追いついていないのが現状だと思います。
そこで、今回はHCI(Human Computer Interaction)分野の生成AIを用いた検索が人の意見に与える影響に関する論文の内容を簡単に紹介します。
論文はこちらです。
結論
本論文は2つのパートに分かれています。
-
通常の検索システム VS 生成AIを用いた対話型検索システム の比較
- いくつかの仮説で、利用者のバイアス[1]を増長することを示唆
-
利用者の意見寄り VS 利用者に反対寄り の対話型検索システムの比較
- 利用者の意見寄りのシステムを使った場合にバイアスを増大することを支持
- 利用者に反対寄りのシステムを使った場合にバイアスの緩和は支持されなかった
- すなわち、自身が元々持つ意見と異なる意見に触れることで意見が緩和される、という仮説は支持されなかった
関連研究
はじめに、3つの分野にわけて関連する研究について簡単に説明します。
心理学的側面
心理学からは、主に以下の3つの概念が紹介されています。
- selective exposure bias(選択的露出バイアス):自身の意見と一致する情報を選り好みする傾向
- 自身の意見に合ってるものを選択する、それしか見ない
- confirmation bias(確証バイアス):自分の意見に一致する情報に重点を置く傾向
- 自分と異なる意見も見るが、自分が好むものを重視する
- echo chamber effect(エコーチャンバー効果):特定の意見のみが共有される環境 / グループ内で多くの情報に触れることで、偏った意見が強まること
特に近年はSNSの利用が拡大しており、その中で使われるパーソナライゼーション / アルゴリズムフィルタリングにより触れる情報が偏る可能性への懸念などが議論されています。
また、selective exposureに対して、情報の多様性を増やすための基準としてセレンディピティが研究されています。
また、対立意見を受け入れやすくするために最初に同意できる情報を提示する、共通点を強調するなどの様々なアイデアが検証されています。これらのアイデアは多様性を高める効果があることが示されていますが、多くの場合は元々多様な意見に肯定的な集団に対してのみ効果が示されているに留まり、解決の難しさが伺えます。
人とLM(生成言語モデル)の相互作用
HCIの分野ではLLMが登場する前から、人とLMの相互作用による研究がされています。研究対象とされるタスクとしては、プログラミング支援を目的としたコード生成、文章執筆における次の文の生成などがあります。
生成言語モデルを用いて共同で執筆するタスクを対象としたJakeschらの研究では、あるトピックに対して特定のバイアスを持つように設定されたLLMを用いて執筆した場合、以下のような影響が生じることを示しました。
- 文書にモデルのバイアスがより多く現れる
- 参加者自身の意見もバイアスの方向にシフトする
こういった影響は悪意のある者によって悪用され、世論に影響を与えたり、誤った情報を広める可能性があります。
対話型検索
研究アイデアとしては長年研究されてきていて、対話型の検索は旅行の計画を立てるといった複雑な情報検索に特に適しているとの研究があります。
しかし、主に対話部分の技術的な制約から、多くの場合はオズの魔法使い[2]的なアプローチで限定的に研究されているにとどまります。
紹介論文の研究内容
本研究では以下の2つの研究を行っています。
- 通常の検索システム VS 対話システムを用いた検索システム の比較
- 利用者の意見寄り VS 利用者に反対寄り の対話型検索システムの比較
それぞれ分けて説明します。
研究1. 通常の検索システム VS 対話システムを用いた検索システムの比較
あるタスクに取り組む中で実験参加者に検索行動を取ってもらい、参加者が元々持っていた意見に着目して以下の2つの観点でLLMを用いた会話型検索と従来のWeb検索を比較しています。
- 元々の意見に沿った検索行動を促進する(多くなる)か
- 元々の意見をより強くするか
タスク概要
人によって意見が分かれるトピックについて、検索したあとに簡単なエッセイを書くというものです。
トピックの候補は、物議を醸す問題についての審議のためのオンラインリソースであるProCon.orgからピックされました。
それら候補の中から、以下の基準に基づいてトピックの選定をしています。
- 物議を醸すもの
- ニッチではないもの
- 参加者は該当トピックに元々意見を持っている可能性がある
- 複雑で、日常会話で馴染みのあるものではないもの
- 参加者に情報探索するモチベーションが生じることを期待している
実際に選ばれたトピックは以下の3つです。
- 米国政府は国民皆保険制度を提供すべきか?
- サンクチュアリシティは連邦政府の資金援助を受けるべきか?
- 学生ローンの負債は、債務免除か破産で解消すべきか?
トピックは、3つのうち1つが各参加者にランダムで割り振られます。
比較対象
比較は、以下の3種類の情報検索システムで行われました。
- Web検索
- LLMを利用した会話型検索
- LLMを利用した会話型検索(ソース参照付き)
研究手順
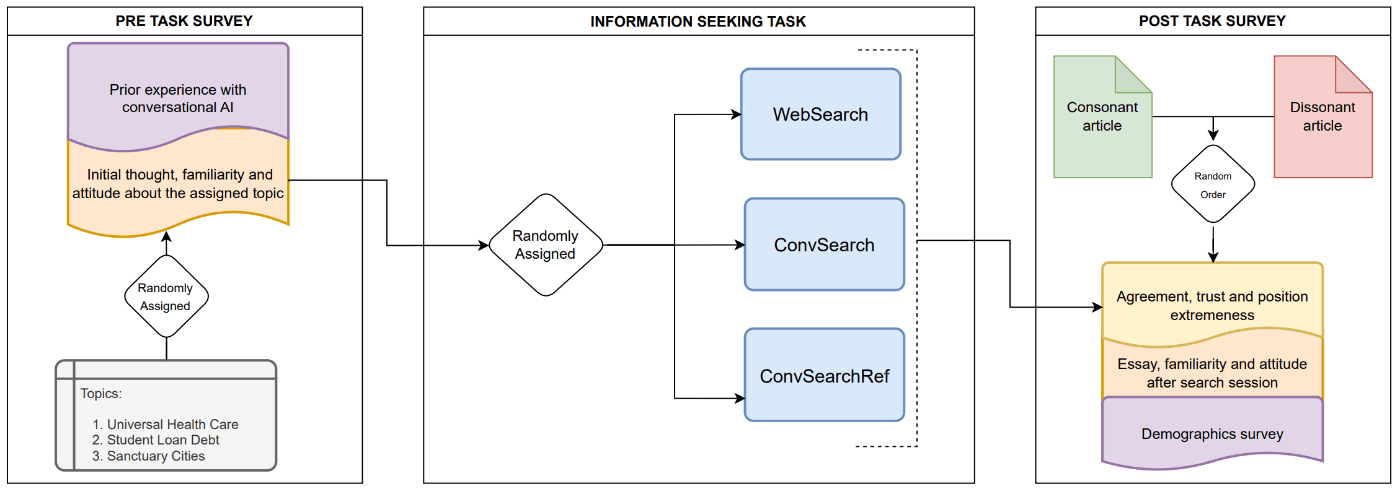
図1: 通常の検索システムと、対話システムを用いた検索システムを比較する手順。論文から引用。
研究手順は上記の図の通りです。それぞれについて簡単に説明します。
1. 事前アンケートの取得
トピックに対する意見、知識量をリッカート尺度で取得します。このとき、参加者に賛否どちらかのスタンスを取ってもらうため、トピックに対する意見のみ6段階にしており、その他の項目は5段階での評価となっています。
2. 情報検索タスクの実施
はじめに、トピックに関する知識を得るため検索システムを用いてトピックについて調べます。その後別ページに移動し、トピックに関して50-100 wordsのエッセイを書きます。ここで、情報検索システムは、比較対象の3システムのいずれかがランダムに割り当てられます。そして、少なくとも3回以上検索を行うことが指示されています。
3. 事後アンケートの取得
事後アンケートでは、事前アンケートと同様にトピックに対する意見を取得します。続いて、参加者のトピックに対する意見の変化についてさらに考察するため、以下の手順でアンケートを取得します。
- エッセイを書いたトピックに関する2つの記事がランダムで提示
- 1つは意見と一致し、もう1つは意見と一致しないもの
- 両記事について、記事に対する同意度、信頼度、記事の立場がどの程度極端に感じるかを評価
取得したアンケートを用いて、本研究で立てた仮説を統計解析にて検定しています。
検索システムの概要
本研究では、事前にキュレーションされたDBに基づき検索結果を返すシステムを用いています。
検索DBの作成
ncbi.nlm.nih.gov、procon.org、jhunewsletter.comなどの信頼性が高いソースから、各トピックに対して支持(N=18)、反対(N=20)、中立(N=9)の記事をキュレーションしています。
1. Web検索
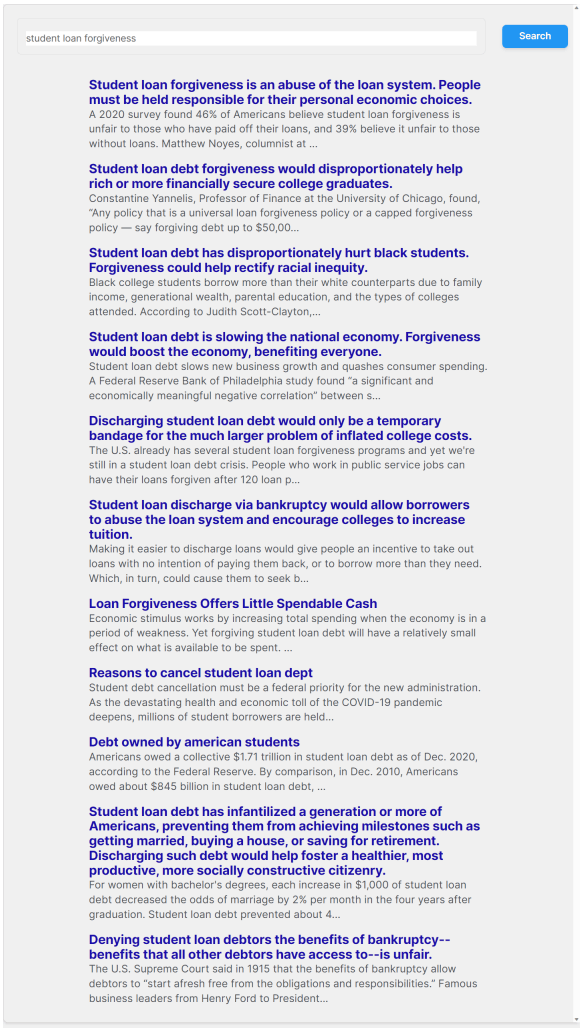
図2: Web検索システムのUIイメージ。論文から引用。
GoogleやBingなどの検索システムに似たインターフェースです。
ユーザーが検索ボックスにクエリを入力すると、システムは関連する記事を取得します。
取得された記事は、タイトルと記事の最初の200文字がプレビューとして表示されます。
2. LLMを利用した会話型検索

図3: LLMを利用した会話型検索システムのUIイメージ。論文から引用。
ChatGPTなどの会話システムに似たインターフェースです。裏側では、RAGを用いてクエリに関連するテキストを参照し回答するシステムを構築しています。
3. LLMを利用した会話型検索(ソース参照付き)

図4: LLMを利用したソース参照付き会話型検索システムのUIイメージ。論文から引用。
2のシステムに加えて、生成された応答にインラインでソース参照を追加する仕様です。
検証仮説
全てWeb検索と比較して、会話型検索では参加者の検索行動・意見が元々の意見方向に強まるという仮説を検証しています。
具体的な仮説の定義はこちらを参照ください。
1: 元々持っていた意見に沿った検索行動を促進する
- **事前アンケートと一致する意見の検索クエリの割合 - 不一致な意見の検索クエリの割合**
2: 元々の意見の方向に意見が強化される
- 賛成~反対が1~6のアンケートの場合、元の意見が3なら2や1、4なら5や6に変化した度合い
3: 執筆したエッセイにおいて、元々の意見が一致する文をより多く執筆する
- 元々の意見に沿った文の割合 - 元々の意見に否定的の文の割合
4: 自身の意見に同意的な記事と否定的な記事を比較して、より同意的な記事に同意する傾向がある
5: 自身の意見に同意的な記事と否定的な記事を比較して、より同意的な記事を信頼する傾向がある
6: 自身の意見に同意的な記事と否定的な記事を比較して、より同意的な記事の立場が**極端でない**と評価する傾向がある
※ 4~6は、事後アンケートにて「自身の意見に同意的な記事への評価 - 自身の意見に否定的な記事への評価」を計算(記事に対して強くXXする ~ 記事に強くXXしないの5段階で回答)
結果

表1: 研究1での各仮説検定の結果。1, 4, 5の仮説で統計的有意な結果となっている。論文から引用。
参加者の検索行動(仮説1)と、元々持っている意見が強まる(仮説4, 5)という仮説の一部が統計的有意な結果になりました。
研究2. 利用者の意見寄り VS 利用者に反対寄りの対話型検索システムの比較

図5: 利用者の意見寄り VS 利用者に反対よりの対話型検索システムの比較を行う手順。論文から引用。
研究2では、対話型検索システムが持つバイアスが利用者に与える影響の比較をしています。
方法としては、検索システムが参照するソースDBから、トピックに賛成 or 反対する文書を除くことで偏りがある対話型検索システムを構築します。そして構築した検索システムを用いて研究1と同様のタスクを参加者に実施してもらい、参加者の意見の変化を分析しています。
比較観点としては、対話型検索システムが利用者の意見寄り or 利用者に反対寄り( or 中立)で、検索行動や元々の意見を強めるかどうかの傾向に差がないかを仮説検定しています。
結果
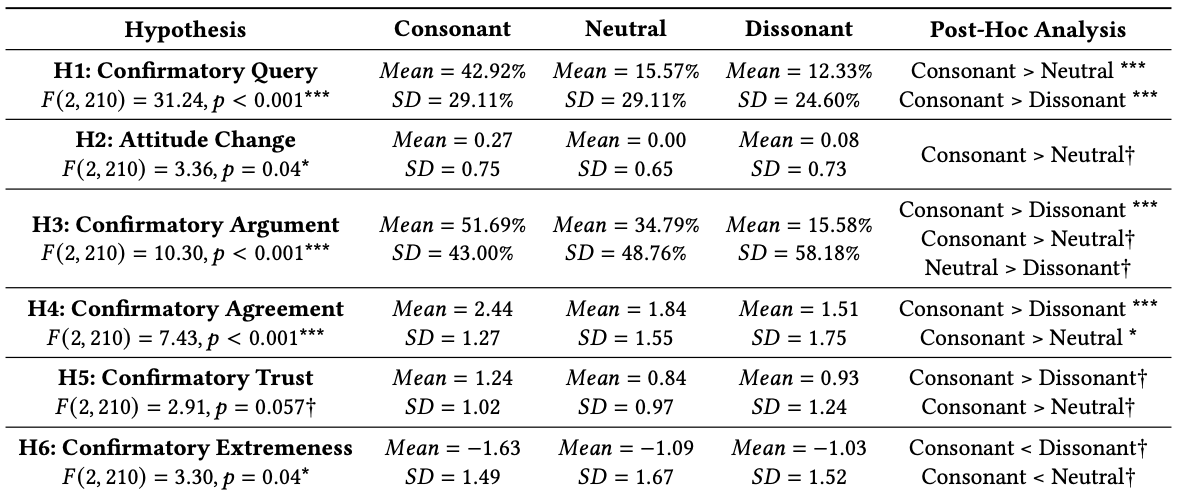
表2: 研究2での各仮説検定の結果。論文から引用。
Consonantが利用者に同意的、Dissonantが利用者に否定的、Neutralが中立を意味します。
表の一番右の列が、各システム間の仮説を調べています。自身の意見に同意的なシステムの場合全項目で統計的有意な結果が出ている一方で、自身の意見に否定的なシステムの場合、3のみ有意でそれ以外は有意差はない結果となっています。
1. 利用者の意見寄りなLLM
会話型検索システムのクエリは一般の検索システムへの入力と比較してより冗長で表現が豊かであることが観察されました。
会話型のやり取りは社会的なやり取りに近いため、人々が会話相手のコミュニケーション行動に収束していく「コミュニケーション的適応」という現象が生じているのではないか、と考察されていました。
2. 利用者の意見に反対寄りなLLM
今回の結果は、LLMを利用した会話型検索システムに反対意見バイアスを加えても、利用者の意見の選り好みや意見の偏りに対抗する効果は限られていることを示唆しています。したがって、人々の情報の多様性を高めるためには、他の介入方法に頼る必要があると考えられます。
介入方法の例として、過去の研究では以下2つのアプローチが提案されています。
- 正確で包括的な情報を学習する人々の正確性動機を高めること
情報源の専門知識やそれがもたらす新しい知識など、反対意見の情報の価値を強調したり、人々に自分の偏見を認識させたりすること - 反対意見を目にした人が意見をシャットダウンしてしまうことを軽減すること
反対意見の共通点を認めたり、多様な視点を同意しやすい情報とともに提示して情報を消費しやすくしたりすること
本研究の限界
最後に、本研究は対話型検索システムが人に与える影響のごく一部を調査しているに過ぎず、以下のような限界があります。
- 検索システムはクローズワールド、かつタスクは論点を絞ったエッセイ執筆タスク
→ 一般化出来てない可能性がある - 今回のアーキテクチャとは異なるシステムの場合、異なるバイアスが生じうる
- 今回のタスクは数クエリ程度の短いタスクである。故により長い時間軸では異なる傾向を示す可能性がある
- 本研究では情報問い合せ行動のみに焦点を当てているため、情報の知覚、保持など、その他影響を与える可能性がある情報消費メカニズムは検討していない
- 人と機械の対話インタラクションは個人差がある事が先行研究から分かっているが、本研究では個人差を考慮せず集団レベルでの分析にとどまる
結び
以上、対話型検索システムが人の意見に与える影響を調査した論文の紹介でした。
今後AIを用いた創作活動や意思決定はより広がっていくことが想定されますが、システムが人に与える影響は未知な部分が多いため、今後も追っていきたいトピックと思いました。
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion
興味深い研究ですね。私もLLMを使うとき、誤った認識がそのまま肯定されてしまうLLM hallucinationを心配しています。「もし私の認識が間違っている場合は修正してください」といったpromptをよく使用しています