はじめに
こんにちは。ZENKIGENデータサイエンスチームの川﨑です。ZENKIGENではharutaka EF(エントリーファインダー)やharutaka BI(ビジネスインテリジェンス)などの機能開発に関わっています。
所属チームでXアカウントを運用しており、AIに関する情報を発信していますのでご興味あれば覗いてみてください。
今回は、LLMの計画能力を向上させるためのデータセットを自動で作成するフレームワークAgentGenを提案する論文を紹介します。

図1: 計画能力に関する学習の全体像。論文から引用。
論文はこちらです。
背景
LLMの性能が飛躍的に向上する中で、LLMベースのエージェントに注目が集まっています。そして、エージェントが自律的にタスクをこなすためには、状況に応じた計画能力が必要となります。当然、計画能力を向上させる学習にはタスクをどうこなすかのデータが必要となります。しかし、このデータは一般に人手で作成されており、大量のデータを作成することが難しいです。
そこで、本論文はエージェントの計画能力を向上させるための学習データを自動で生成する手法を提案しています。
事前知識
本研究では、決定論的計画問題(以下、計画問題)を扱っています。こちらについて、簡単に補足します。
計画問題
計画問題は、環境とタスクの2つの要素から構成されます。環境はエージェントが相互作用する世界のことを表し、タスクはエージェントが達成すべき状態を表します。それぞれは以下の要素で構成されます。
■ 環境
- 行動空間 (
A - 状態空間 (
S - 遷移関数
T:S×A → S
■タスク
- ゴール条件 (
G - 初期状態 (
I
どちらも
計画問題の実装
計画問題は、PDDL(Planning Domain Definition Language)や、Pythonなどのプログラミング言語で実装可能です。PDDLでは環境とタスクのそれぞれをファイルで定義します。
環境ファイルは、まず状態とアクションを定義します。さらに、各アクションが前提とする状態と効果を指定することで遷移関数を定義します。タスクファイルは状態の組み合わせで定義されます。
環境ファイルの例

図2: 環境ファイルの例。論文から引用。
手法
AgentGenは、主に以下2つから構成されます。
Step1. インスピレーションコーパスを用いた環境の生成
モデルの汎化性能を高めるためには、学習データの多様性が重要と考えられます。しかし、人手でデータを作成するのは大変です。そのため、LLMを用いてデータ作成を自動化することが考えられるのですが、LLM固有の帰納的バイアスにより多様性のある環境を作ることが難しいです。
そこで、本論文では環境生成のインスピレーションとなるような、多様性の高いテキストを含むインスピレーションコーパスを利用して環境生成を多様化します。本研究で利用したコーパスはLIMAというコーパスですが、Common Crawlのような他のコーパスでも実施可能です。
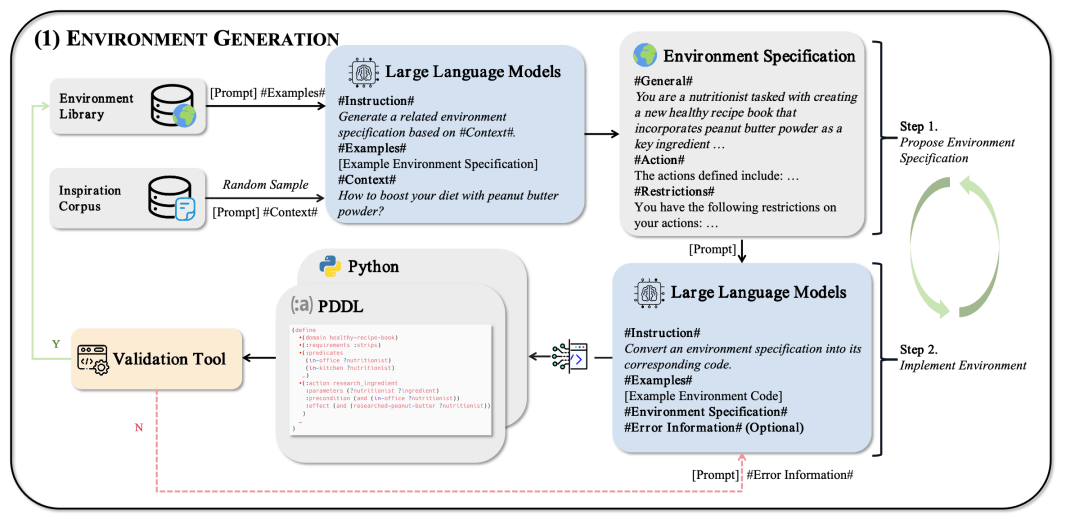
図3: 環境生成プロセスの概要。論文から引用。
手順
- インスピレーションコーパスと環境ライブラリ(すでに作成した環境の集合)から、テキストセグメントと環境をサンプリングする。
例:どうすれば、ピーナッツバターパウダーを使ってダイエットを促進できますか? - LLMを用いて、サンプリングしたテキストセグメントと環境を入力に環境の仕様を生成する。
簡易例:栄養士の設定で、ピーナッツバターパウダーを用いた健康的なレシピを作ってください。詳細な環境の仕様の例


図4: 環境の仕様の例。論文から引用。 - 環境の仕様を入力し、実際の環境をPDDLベースのコードに変換する。
変換したPDDLベースのコード例
図5: 生成したタスクの例。論文から引用。 - コードをバリデーションツールで検証し、問題なければ環境ライブラリに追加する。
Step2. BI-EVOL(双方向進化法)による多様な難易度のタスクの生成

図6: タスク生成プロセスの概要。論文から引用。
上記で作成した環境を元に、LLMを用いてタスクを生成します。さらに、BI-EVOLという手法を用いてタスク難易度が多様になるようにタスクデータセットを拡張します。
BI-EVOLではタスクをシードに、タスク難易度が簡単/複雑になるよう指示を与えてタスクを生成させます。BI-EVOLの例としては、環境やタスク達成までのアクションがより少なく/多くなるような指示を与えてタスク生成させるなどがあります。この手法で生成したタスクもデータセットに加えます。
実験設定
インスピレーションコーパスとして、LIMAを採用しています。環境・タスクはどちらもGPT-4で生成し、592の環境を生成しています。作成した環境に対してランダムに10件のタスクを生成します。
タスクをBI-EVOLで拡張した後、FastDownwardというプランナシステムを利用し、学習の入力となる軌跡データ[1]を生成しています。これにより、最終的に7246の軌跡データを作成しました。この軌跡データをさらにGPT-4を用いて自然言語にマッピングし、学習に用いています。
軌跡データを自然言語にマッピングするプロンプト例


図7: 軌跡データを自然言語にマッピングする際のプロンプト例。論文から引用。
学習では、Llama3-8Bをベースモデルとして用いています。
結果・考察
評価は、成功率(success rate, SR)と進捗率(progress rate, PR)という2指標を用いています。進捗率は、ゴールの状態と現在の状態の類似度となります。成功は、進捗率が1の場合に1、それ以外の場合に0となる指標です。

図8: 精度評価結果。論文から引用。
図8の表は、一般的なPDDLベースで定義されたタスクにおける評価結果です。AgentGenにより、Llama3のベースモデルと比較して全体的に精度向上していることがわかります。成功率が0のタスクがいくつか成功となっていることも確認されます。また、成功率ではGPT-3.5を全体的に上回る結果となりました。

図9: 複数のモデルを対象に、AgentGenで作成したデータでどの程度精度が向上したかを整理した表。論文から引用。
図9の表は、複数のモデルを対象にどの程度精度向上したか検証した結果となります。表より全てのモデルで精度向上しており、AgentGenで作成したデータセットが幅広いモデルで有効であることを示唆します。

図10: 領域外タスクに対する検証結果。論文から引用。
図10の表は、領域外のタスクに対する検証結果です。領域外とは、PDDLベースではないタスクのこととなります。表より、AgentGenが領域外タスクに対しても精度向上しており、特にAlfworldではGPT-3.5を上回る性能を示しました。
結び
以上がAgentGenの紹介でした。
データの自動生成は個人的に関心が強く、さらにデータ量を増やした場合の精度の上限や、人が作成したデータとの性能の違いなどが気になりました。
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
-
特定の環境・状態の条件下でタスクを解くための最適なアクション系列。 ↩︎

Discussion