はじめに
こんにちは。ZENKIGENのデータサイエンスチームに所属しております、脇山です。
今回は、物体検出モデルの学習時に未知オブジェクトの情報も考慮したようなunknown-aware object detectionアルゴリズムを扱う論文を紹介したいと思います。
今回紹介する論文では、「未知クラスのオブジェクト(以下、OOD objectと同意)を、学習データセットに含まれるオブジェクト(以下、ID objectと同意)と自信満々に予測してしまう」といった問題を、どのようにして低減させるかに焦点を当てた研究を行っています。
※ OOD: Out-of-Distribution、ID: In-Distributionの略名
論文情報と概要
- タイトル: Unknown-Aware Object Detection: Learning What You Don't Know from Videos in the Wild [arXiv]
- 執筆者: Xuefeng Du et.al
- 会議: CVPR2022
- 論文内容の概要:
- unknown-aware object detectionの新たなフレームワークとして、STUD(Spatial-Temporal Unknowns Distillation)を提案。
- 本論文の執筆時では、動画であることを活かした情報量を用いて、物体検出モデルにOOD objectを認識させるようにしたのは初めてとのこと。
- 「動画であることを活かす」とは、spatial(画像内の物体の位置、形状)、temporal(時間的な情報)の両方の次元を加味した正則化をすること。
- distillation(蒸留)とは、ID objectとOOD objectが入り混じった動画から、ID objectとOOD objectの区別をするような処理のこと。※ モデルの蒸留とは、異なる意味合い。
- 古典的な物体検出モデルはラベル付けされた物体を学習に利用するが、本論文では物体検出とOOD検出を一緒に最適化することで、モデルの正則化にOOD objectを活用することを試みた。
- unknown-aware object detectionの新たなフレームワークとして、STUD(Spatial-Temporal Unknowns Distillation)を提案。
本論文での課題感とやりたいこと
本ブログの冒頭でも述べたように、この論文で掲げている課題は「OOD objectを、自身満々にID objectとして認識してしまうこと」である。
下の図は自動運転を想定したような図であり、ID objectとして「車」や「歩行者」を認識するように訓練された物体検出モデルでの予測結果である。下の図に注目すると、鹿の形をしたOOD objectに対して、自身満々に「歩行者」という結果を予測しており、false postiveといえる。

本論文のSupplementary Material-Bと、Figure 1(a)を編集したもの
上の例では自動運転における1シーンを切り出して考えたが、オープンワールドに拡張して考えると、OOD objectが発生するシーンは無数にあると考えられる。これと紐づくように、複雑なシーン内のOOD objectを大量にアノテーションするというアプローチはコストが高い、といった懸念も考えられる。
再度、運転中のシーンを想定した場合のunknown-aware object detectionに話を戻り、下の図の1シーンのように、building, treeといった物体(OOD object)が出現するシーンを考えてみたい。

本論文のFigure 1(b)より引用
車や歩行者を検出するようなモデルを構築した場合、これらオブジェクトは明示的なラベル付け(アノテーション)はされていないはずであり、期待するような出力ではないはずである。
本論文でやりたいこととしては、これらbuidling, treeといったオブジェクトが、車や歩行者と認識されるのではなく、OODとして認識されて誤検知(false postive)となる数を減らすことであり、それを実現するためのアルゴリズムを検討することである。
本論文の定性的な結果
本論文ではSpatial-Temporal Unknown Distillation(STUD)という、新しいunknown-aware object detectionのフレームワークを提案している。端的にまとめると、「動画からOOD objectを抽出し、不確実性を考慮したモデルの正則化を行い、ID objectとOOD objectの決定境界を獲得する」という手法である。
具体的な説明に入る前に、既存手法と提案手法の予測結果を定性的に比較したものに目を通し、この論文でやりたいことのイメージをもう少し膨らませておきたい。
下の図はOOD objectを含んだ画像に対する予測結果であり、図の上部は純正のFaster-RCNN、図の下部は提案手法のSTUDの予測結果を可視化したものである。IDデータはBDD100Kであるため、ID objectと予測された場合に出力されるラベルは「pedestrian, rider, car, truck, bus, train, motorcycle, bicycle」である。

本論文のFigure 6に、赤線を追加したもの。
※画質が不十分である場合は、原典を参照していただけると嬉しいです。
Faster-RCNNとSTUDの結果(上図の確認結果)を見比べて言えることは、以下の2点。
- 検出されたオブジェクトについて、false postiveが少なくなっている。
- 例えば、1列目の結果に注目すると、Faster-RCNNは食器棚をbus, truck, carと予測しており、この予測結果はFalseである。
- STUDではOODと予測しているため、誤検知にはいたらない。
- STUDでfalse positiveとなってしまったオブジェクトに注目すると、confidence scoreがFaster-RCNNよりも低くなっている(e.g., 図の赤線部分)
提案手法の各要素
本論文ではunknown-aware objectを検出するためのフレームワークを提案しており、この章では当該フレームワークの各要素について考えてみたい。
提案手法は、大きく分けて2つの要素で成り立っている。
- 動画から、多様なunknown objectを蒸留する(Spatial-Temporal Unknown Distillation)
- 蒸留されたunknown objectを利用して、物体検出器を正則化する(Unknown-Aware Training Objective)
各要素の詳細は後述するが、提案手法を俯瞰した図は、下の通りである。
(定期的にこちらに図に立ち戻りながら読むと、理解しやすいかもしれない)

本論文のFigure 2より引用。
Spatial-Temporal Unknown Distillation
前述の通り、unknown-aware object detectionをする要素の1つとして、spatial-temporal unknown distillationがあると説明した。
本論文では、蒸留工程(distillation)を理解するために、3つのステップに分けた説明がされている。
- spatial unknown distillation
- temporal unknown distillation
- unknown candidate object selection
それでは、蒸留工程(distillation)における各ステップの要点を確認してみたい。
1.spatial unknown distillation
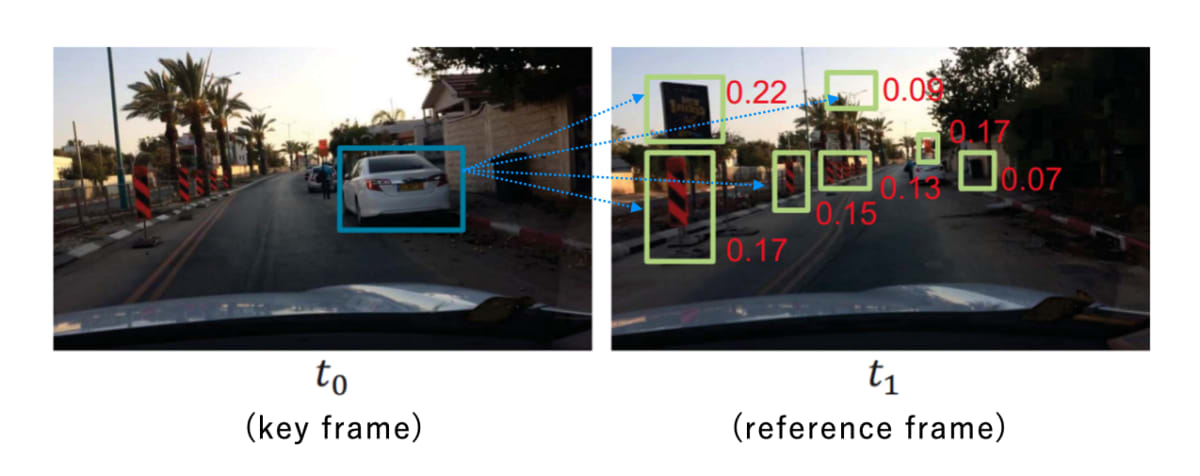
本論文のFigure3を編集したもの。赤色の数値は、正規化された後の非類似度スコア。
このステップでまず押さえておきたいこととして、画像のペア(key frame, reference frame)に着目するということである。
もう少し突っ込んだ説明をすると、タイムスタンプ
非類似度を計算するにあたってのポイントを箇条書きすると、次のようになる。
- proposal generatorの出力(推定された物体の位置情報)を計算に利用
- L2距離を利用して、非類似度スコアを算出する
-
s_{i,j} = \|\hat{h}( \mathbf{x}_{0}, \mathbf{b}_{i}) - \hat{h}( \mathbf{x}_{1}, \mathbf{b}_{j}) \|_{2}^{2} -
h(\mathbf{x}, \mathbf{b}) (\mathbf{x}, \mathbf{b}) (\mathbf{x}, \mathbf{b}) -
\hat{h}( \mathbf{x}, \mathbf{b})
-
-
s_{i,j}
-
-
\mathbf{x_{1}} \hat{\mathbf{o}}^{i} = \sum_{j=1}^{N_{1}} \alpha_{i,j} h(\mathbf{x}_{1}, b_{j}), \ \ \ \alpha_{i,j} = \frac {e^{s_{i,j}}} {\sum_{k=1}^{N_{1}} e^{s_{i,j}}} -
\alpha -
\hat{\mathbf{o}}^{i} x_{0} i
2.temporal unknown distillation
先程説明したspatial unknown ditillationは、1枚のreference frameに対する演算処理である。このステップでは、時間軸方向に拡張させて、複数フレーム(
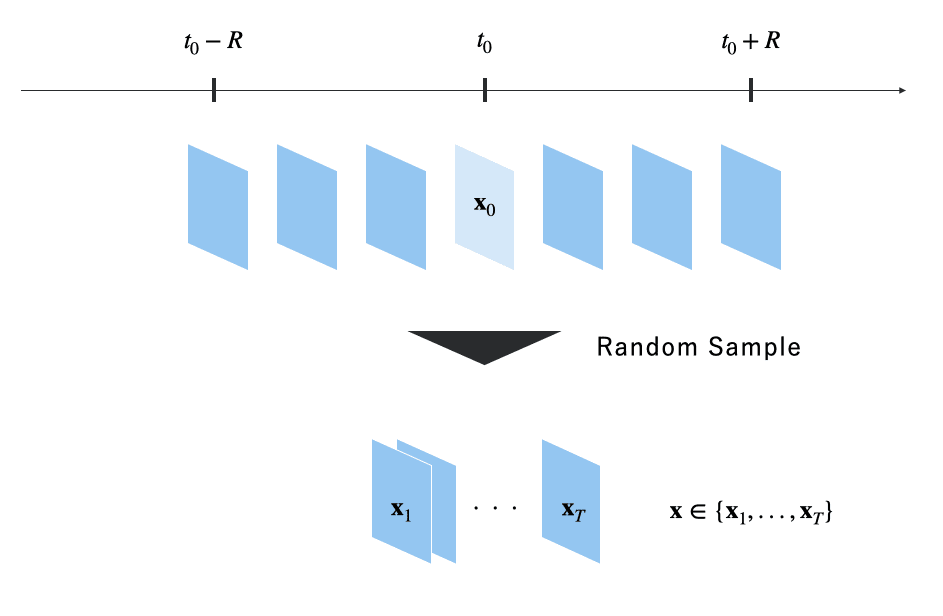
サンプリングのイメージ図
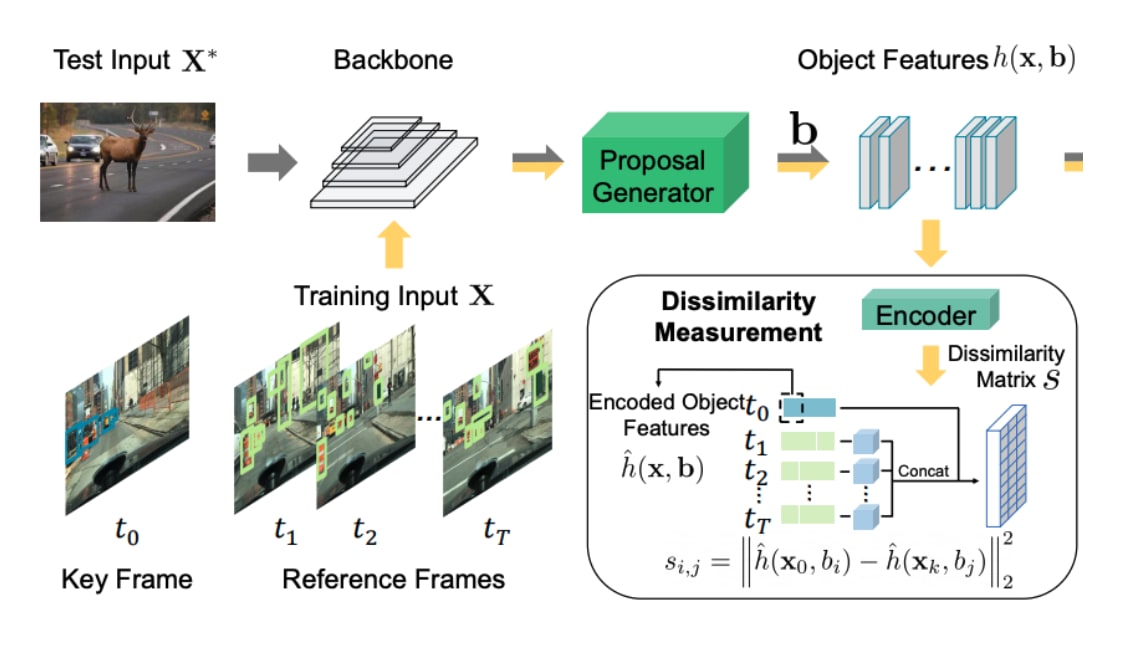
本論文のFigure 2を拡大したもの。
また、本論文のablation studyでは、サンプリングに関するパラメータをそれぞれ比較しており、
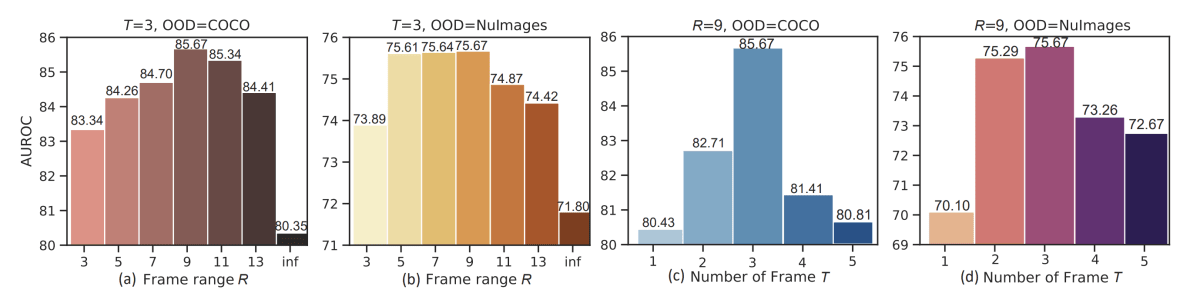
本論文のFigure 5より引用。
(a)~(b)はT=3に固定して、Rを変化させた場合の結果。
(c)~(d)はR=9に固定して、Tを変化させた場合の結果
3.unknown candidate object selection
このステップでは、spatial-temporal次元で蒸留したOOD objectの一部のみを利用(selection)するようなフィルタリングを行う。
なぜなら、reference frameから蒸留したオブジェクトは、ID object、もしくは単純な背景である可能性もある。そして、これらをselectionしなかった場合、モデルの学習過程において、ID objectとOOD objectを混同させる恐れもある。
提案手法では、エネルギースコア(論文 Energy-based Out-of-distribution Detectionで提案されたもの)を利用し、proposal generatorからの出力を事前にフィルタリングしている。
エネルギースコアの計算式
-
E(\mathbf{x_{1}}, \mathbf{b_{j}}) = - \log \sum_{k=1}^{K} \exp^{f_{k}(h(\mathbf{x}_{1}, \mathbf{b}_{j});w_{pred})} -
f_{k}(h(\mathbf{x}_{1}, \mathbf{b}_{j});w_{pred}) - エネルギーが高いほど、OODの性質が強い。
-
p\% \leq Rank(E(\mathbf{x_{1}}, \mathbf{b_{j}}))/N_{1} \leq q\%
-
本論文のFigure 2を拡大したもの。
ablation studyでは、フィルタリングする際のpercentileについて、比較している。

本論文のTable 3より引用。
比較結果からは、以下のことが言える。
- mild energy(40%~60%)でのフィルタリングが適切
- フィルタリングをしない場合を比較して、FPR95が10%改善
Unknown-Aware Training Objective
先程まではOOD objectを蒸留する方法(spatial-temporal unknown distillation)を、3ステップで確認した。
この章では、spatial-temporal unknown distillationを使ったunknow-aware object detectionを、より効果的なものにするためのアプローチを確認する。
本論文では以下のように、
この目的関数の気持ちは、物体検出タスクにおいて「ID objectに対しては不確実性スコアが低くなる(OOD objectに対しては不確実性スコアが高くなる)ように、モデルを正則化したい」といったものである。
ablation studyでは、この
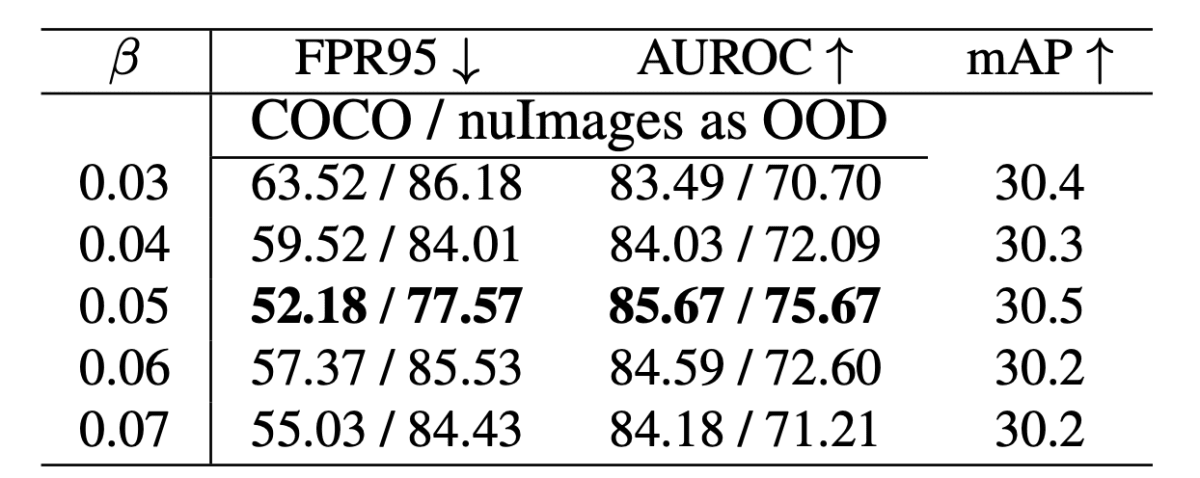
本論文のTable 4より引用。
この結果から言えることとしては、「あまり大きな重みを設定しないことが望ましい」ということである。そして、AUROCに注目すると、多くのケースで提案手法の結果の方が良いことがわかる。
再掲となるが、参考までにTable1の一部の表を下に載せておく。

本論文のTable 1を編集したもの。In-distributionがBDD100Kの結果のみを掲載。
Uncertainty regularization
ここでは、先程触れた目的関数の話に立ち返り、目的関数の要素である
本論文では、以下のように定義されている。
- VOS: Learning What You Don't Know by Virtual Outlier Synthesisにならった、不確実性表面を対照的に形成する(ID ojbectとOOD objectの分離性を強調させる)損失関数である。
- 不確実性を測定するために、エネルギースコアを利用する。
-
E(\mathbf{x}, \mathbf{b}) -
E(\hat{\mathbf{o}})
-
- 不確実性スコアは、重み係数
\theta_{u}
ablation studyでは、今回提案している不確実性のLossが適切に収束するかと、ID objectとOOD objectのエネルギーについて確認している。
この損失関数を使って、Youtube-VISを学習させた結果が下の図である。
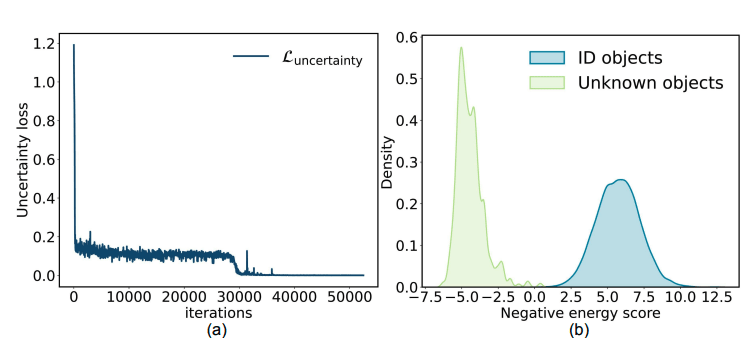
本論文のFigure 4より引用。学習過程でのuncertainty lossと、 学習後のNegative Energy scoreの分布。
左の図からは、不確実性に関するLossが収束していることがわかる。また右の図は、収束後のエネルギースコアの分布である。この結果から、ID objectと蒸留されたOOD objectを分類できるような分布を獲得できていることが見て取れる。
不確実性のLossの有用性を検証するために、以下の表に掲載されている
- STUD w/o
\theta_{u} \mathcal{L}_{uncertainty} \theta_{u} - Hinge loss: 二乗ヒンジ損失
- K+1: 分類ブランチにて、OOD objectを含めたK+1クラスでの分類をする。

本論文のTable 5より引用。
上表の結果からは「蒸留されたOOD objectを新しいクラスとして追加させると、物体を分類する難易度が上がる」「
Ablation on different unknown distillation approaches
本論文では、Spatial-Temporal Unknown Distillation(STUD)に替わるアプローチを3タイプに分類し、これらアプローチに対するablation studyを実施している。どのような3タイプかは以下の通り。
- type-1(
\diamond - spatial/temporal次元での複数オブジェクトの集約をしない。
- Farthest object: 参照フレーム内のオブジェクトのうち、距離が遠い(=類似度が小さい)ものを利用する。
- Random object: ランダムなオブジェクトを利用する。
- Object with mild energy: mild energy score(percentile 40% - 60%)での事前フィルタリングしたオブジェクトを利用する。
- Negative proposal: Object-centric Auto-encoders and Dummy Anomalies for Abnormal Event Detection in Video にならった手法。
- spatial/temporal次元での複数オブジェクトの集約をしない。
- type-2(
\clubsuit - GAN-base, mixupを用いた手法。画素空間でのOOD objectの合成をする。
- type-3(
\natural - ID objectにガウシアンノイズを加えたOOD objectを作成する。
これをさらに3タイプ分類にし、提案手法と比較したものが以下の表である。
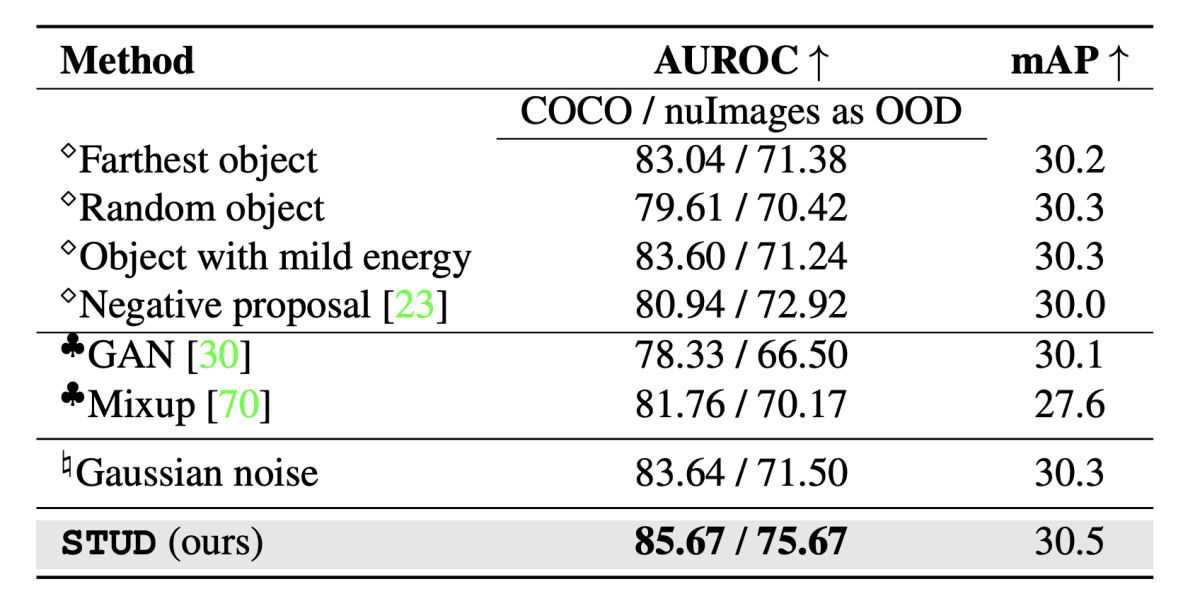
本論文のTable 2より引用。
この結果を見ると、提案手法(STUD)は、比較対象としているアプローチよりも精度が良い。それぞれのアプローチでSTUDの精度に及んでいない理由は、以下とされている。
- type-1:
- 生成されたOOD objectの多様性が不足している(Farthest oject、Random object)
- ID object ↔︎ OOD objectの決定境界を正則化が単純すぎる(Object with mild energy、Negative proposal)
- type-2: GANベースの手法はAUROCの値が相対的に低いのでOODdetectionの精度が低く、mixupの手法はmAPに注目すると物体検出の精度が悪いことが読み取れる。
- type-3: ガウシアンノイズを加える手法はとてもシンプルな手法だが、提案手法(STUD)の精度に及んでいない。
他モデルとの比較
ここまで、蒸留方法や学習の目的関数について、本論文に掲載されているablation studyの結果と合わせて説明をした。
最後に、OOD detectionの従来手法との比較結果を確認し、終わりにしたいと思う。本論文では、公平に比較をするために、全ての手法は同じIDのトレーニングデータを使用し、同じエポック数でトレーニングされている。また、どの手法もResNet-50をバックボーンとしている。
下表は、その比較結果をまとめたものである。

本論文のTable1より引用。
この結果を見ると、提案手法であるSTUDが、これら既存手法よりも大きく上回っていることがわかる。
既存手法で精度が出ていない理由として、「OOD objectによる正則化が行われていないから」と本論文では考察されている。
またmAPの値に注目すると、STUDはIDデータに対して高い物体検出精度を維持したまま、より強いOOD検出性能を実現していることがわかる。(CSIモデルとは対照的な結果である。)
最後に
今回は、Spatial-Temporal Unknown Distillation(STUD)といった、新しいunknown-aware object detectionのフレームワークについて紹介した。
本論文にも記述あるが、unknown-aware object detectionの手法は、まだまだ探索段階とのこと。
今後また新たなOODのフレームワークが出てくることを楽しみに思います。
参考文献
- Towards Open World Object Detection [Joseph et al., 2021]
- Object-centric Auto-encoders and Dummy Anomalies for Abnormal Event Detection in Video [Ionescu et al., 2019]
- Training Confidence-calibrated Classifiers for Detecting Out-of-Distribution Samples [Lee et al., 2018]
- Energy-based Out-of-distribution Detection [Liu et al., 2020]
- mixup: Beyond Empirical Risk Minimization [Zhang et al., 2018]
※ 特に関係しそうな文献を掲載
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion