
はじめに
こんにちは、DSチームの川﨑です。
今回は、物体検出手法に対して継続学習という技術を適用する研究分野の紹介記事になります。継続学習は近年急激に発展を遂げる基盤モデルとも関係があり、下流タスクへのチューニングに伴う精度劣化を避けるための手法として組み合わせるなど、今後も発展が想定される研究分野と考えられます。
ぜひ、ご一読いただけると幸いです。
流れとしては、継続学習の概観に触れたのち、継続学習を物体検出に応用した分野のレビューと研究例を紹介します。
なお、本記事は主に以下の2つのサーベイ論文を参考に執筆しています。
継続学習
A Comprehensive Survey of Continual Learning: Theory, Method and Application
物体検出における継続学習 (CLOD)
Continual Object Detection: A review of definitions, strategies, and challenges
継続学習
まずはじめに、継続学習について簡単に紹介していきます。
継続学習の概要
継続学習は、以前に学習したタスクを忘れることなく連続したタスクを学習する能力 (Fig.1-a) として定義されます。機械学習の実応用の中では、モデル構築後に分類したいクラスが増えたり、これまでと傾向が異なるデータにも適切な予測を返してほしいというニーズが考えられます。そういったケースにより適切に対処するために、継続学習が研究されています。
機械学習では、一度モデルを学習させたあとに分布が異なる新タスクに対して追加学習させると、過去タスクに対する性能が大幅に低下する破局的忘却という現象が知られています。いかに破局的忘却を軽減させながら新タスクに適応したモデルを構築するかが、継続学習研究の主要な課題となっています。
この考え方は、知識の安定性と学習の可塑性のトレードオフ (Fig.1-b 上図) と解釈することもできます。さらに、タスク間で共通する汎用的な表現を学習するなど一般化を進めることで、トレードオフを超えることを目指すアプローチ (Fig.1-b 下図) もあるようです。

Fig.1. 継続学習の枠組み
継続学習のアプローチ
継続学習のアプローチは大半が5パターンに分類され、Fig.1-cに示すモデル学習のプロセスにマッピングすることが可能です。以下で、それぞれのアプローチを簡単に紹介します。
a. 正則化
損失関数に正則化項を追加することで旧タスクと新タスクへの性能のバランスを取ることを目的としています。
a.1. 重み正則化 (Fig.2 上図)
まず、旧タスクに対してモデルを通常の設定で学習させます。その後、新タスクに対して学習させる際の損失関数に、ネットワークパラメータの変動に対して正則化項を設けます。正則化関数として、L2損失を用いることが一般的なようです。旧タスクに対する重要度に応じ正則化項の各モデルパラメータに対する重みづけをすることで、旧モデルの予測に重要なパラメータの変動を小さくする工夫なども、提案されています。
a.2. 関数正則化 (Fig.2 下図)
新タスクモデルの中間/最終出力が旧タスクモデルの出力に近くなるよう、知識蒸留を用いて正則化を行う手法などが提案されています。
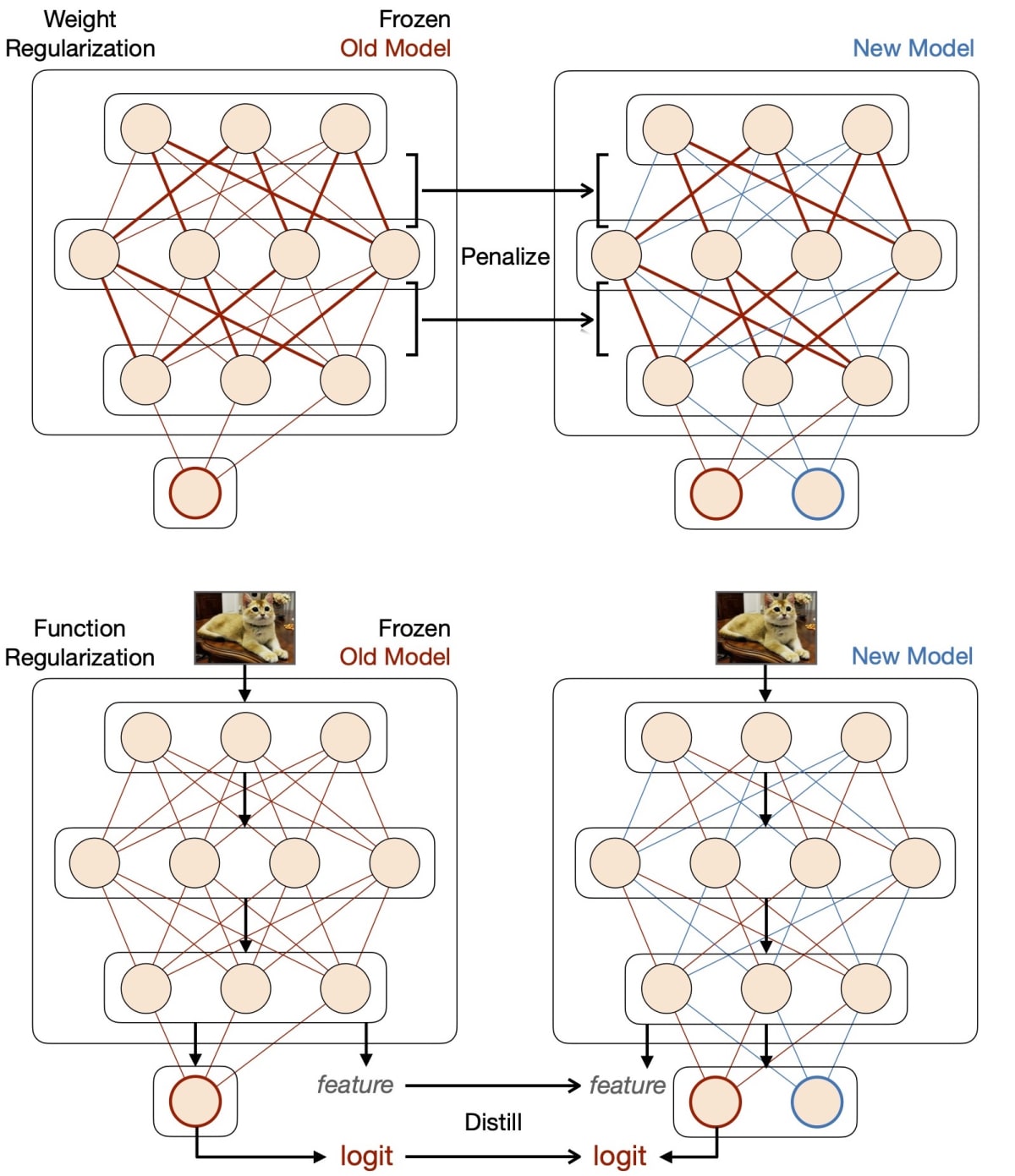
Fig.2. 正則化ベースの手法概要
b. リプレイ
旧タスクのデータ情報を何かしらの方法で復元させて学習にも利用することで、旧タスクの性能が下がらないように新タスクの学習を行います。このアプローチは、損失関数に旧タスクに対する項を明示的に追加していると捉えることもできます。
最も単純な方法としては、旧タスクの学習データを保存しておき新タスクの学習にも利用すること (Fig.3 Memory Buffer) が考えられます。しかし、旧タスクのデータ量が膨大な場合にメモリと学習効率の両面で全量の保存は現実的でないことが想定されます。そのため、過去タスクの忘却を避ける上でより適切なサンプルを選択する手法が多く研究されています。
また、旧タスクのデータを保存するのではなく、旧タスクの忘却を避けるためのデータ/表現を生成するモデルを別途作成し、その出力を学習に利用する手法 (Fig.3 Generative Model) も提案されています。
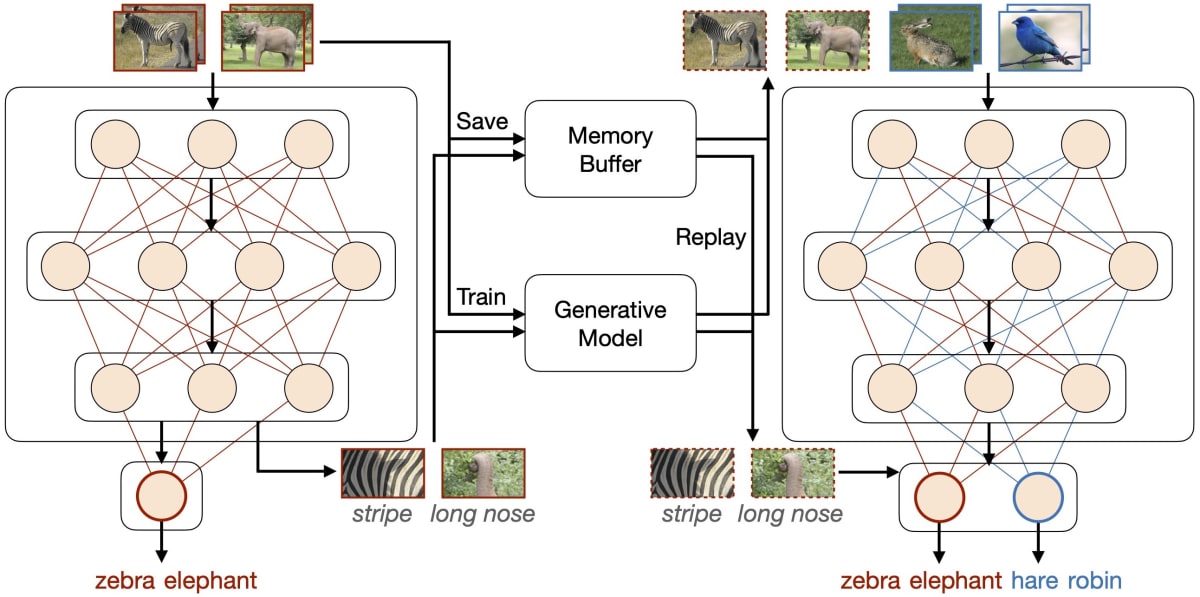
Fig.3. リプレイベースの手法概要
c. 最適化
正則化やリプレイベースのように損失関数に明示的に項を追加するのではなく、最適化の手法を明示的に組み込み学習を行います。方法例として、モデルパラメータ更新時の方向を、旧タスクで学習した際の勾配や入力空間の直交方向に射影させる手法 (Fig.4 Gradient Projection) や、旧タスクの勾配から動的に重要でない基底ベクトルを除いて新タスク学習時に勾配射影することで学習可塑性を高め、パラメータがflat loss landscapeに収束しやすくする手法 (Fig.4 Loss Landscape) などが上げられます。これにより、旧タスクと新タスクの両方に対して損失が小さいパラメータを獲得することが目的となっています。

Fig.4. 最適化ベースの手法概要
d. 表現学習
データから適切な表現を学習することで、破局的忘却を軽減するアプローチが該当します。基盤モデルの学習で用いられる自己教師あり学習 (Fig.5 Contrastive Loss) や、メタ学習の手法を用いてスパースな表現を学習する手法などが該当します。

Fig.5. 表現学習ベース
e. アーキテクチャ
ここまでのアプローチでは、旧・新タスクでモデルパラメータを共有しながらうまく性能を保つことを目指していました。それに対してアーキテクチャベースの手法では、タスク固有のパラメータを設けることで対応します。このとき、タスク毎にパラメータを割り当てるような手法をパラメータ割当 (Fig.6 Parameter Allocation) 、タスクに適応したサブモジュールやネットワークを構築するモジュラーネットワーク (Fig.6 Modular Network) 、モデルをタスク共有部分とタスク固有部分に分割して扱うモデル分解 (Fig.6 Model Decomposition) などが上げられます。

Fig.6. アーキテクチャベース
物体検出における継続学習 (CLOD)
物体検出における継続学習のタスクは、大半が以下の2つに分類されます。
a. ドメイン増分物体検出 (DIOD / Domain Incremental Object Detection)
DIODは傾向が異なるデータセットを連続的に学習させるタスクとなります。例えば晴天の日に撮影されたデータでモデル学習後に、霧や雨天のデータセットで学習させるなどが例として挙げられます。
b. クラス増分物体検出 (CIOD / Class Incremental Object Detection)
CIODは異なるクラスのラベルが付与されたデータセットを連続的に学習させるタスクとなります。一連のタスクを学習後、評価時に全タスクに含まれるクラスを対象に評価を行います。例として、Fig.7 に示すようにTask1では犬と猫のみラベルが付与され、Task2では馬と牛のみにラベルが付与されたデータを用いて学習し、テストではTask1, 2両方に含まれるクラスの検出をする課題が考えられます。
ここで気をつけるべき点として、ラベルが付いてないデータは物体検出において背景として扱われるため、普通に直列で学習を行うと破局的忘却がより生じやすいと考えられます。そのためCIODでは特に破局的忘却を軽減する必要があります。

Fig.7. CIODの課題設定
ベンチマーク手法
ベンチマークには、主に2種類のデータセットが利用されています。
データセットは、様々なシナリオでタスクごとにクラスが割り当てられています。それぞれ、青色で示される部分がベースタスクに含まれるクラス、緑色が追加タスクに含まれるクラスとなっています。各タスクのデータ内にタスクに割り当てられていないクラスの物体が含まれる場合、ラベルを削除する形でデータが修正されます。
a. Pascal VOC 2007 (VOC)
VOCは、全20クラスをいくつかのシナリオでタスクに割り当てて精度検証に用いられます (Fig.8) 。上から3つ目のように追加タスクが複数ある場合は、各タスクを連続で学習したあとに精度評価します。

Fig.8. Pascal VOC 2007データセットに含まれるデータと、ベンチマーク方法
b. MSCOCO 2014 (MSCOCO)
MSCOCOは全80クラスと、VOCデータセットと比較してクラス数が多いです (Fig.9) 。一方で、MSCOCOとVOCにおいて同名のクラスは互いに対応するため、VOCデータで学習させたモデルでMSCOCOのデータを用いて精度検証を行うような、ドメインをまたいだ精度評価を行うケースもあるようです。

Fig.9. MSCOCO 2014データセットに含まれるデータと、ベンチマーク方法
評価指標
はじめに、この項で登場する表記の定義を記載します。
補足として、タスク
mAP
最も基本的な精度を評価する方法としてmAPがあります。こちらは物体検出分野で一般的に用いられる指標であり、すでに先人の方達が解説してくださっているため、本記事では参考記事の紹介で留めさせていただきます。
上限比率
この評価指標は、モデル性能が理想的な学習時の性能と比較してどの程度乖離があるかを評価します。分子はCIODのシナリオどおりに学習させたモデルの精度を、分母は全タスクデータを結合させて1度に学習したモデルの精度を表します。
学習のトレードオフの評価
記憶の安定性と学習可塑性のトレードオフが継続学習において重要な観点と捉えると、手法がどちらを重視しているか評価できることが望ましいです。それぞれを評価するため、以下の評価指標が提案されています。
Rate of Stability Deficit (RSD/安定性損失割合)
結合データで学習したモデルと増分学習したモデルを旧タスクに含まれるクラスの精度で比較することで、記憶の安定性を評価します。
Rate of Plasticity Deficit (RPD/可塑性損失割合)
結合データで学習したモデルと増分学習したモデルを新タスクに含まれるクラスの精度で比較することで、学習可塑性を評価します。
CIOD研究の主要な研究例
IncDet: In Defense of Elastic Weight Consolidationfor Incremental Object Detection
手法内の工夫点は以下のとおりです。
- EWC(パラメータ更新時に、旧タスクにおける重要度で重み付けする手法)の利用
- 旧タスクを学習させたモデルによる疑似Bounding Boxの利用 (Fig10c, d)
- EWCの中で二次損失を用いると勾配爆発を生じやすいため、Huber Lossに変更

Fig.10. IncDetの手法概要
2, 3の工夫点のablation studyについて軽く触れます。
2.疑似Bounding Boxの利用
疑似Bounding Boxの有効性は、(a)origin, (b)mask, (c)pseudoの3種類で検証されており、比較条件のイメージはFig.11の通りです。

Fig.11. 比較条件の例
Fig12に示すように、大半のクラスでpseudo (黄色のバー) が最も良い結果となっていました。
origin (緑のバー) ではtable (中央付近、右から11番目) クラスが著しく悪い結果となっているなど、クラス間の検出精度の差がより大きくなっているように見えます。

Fig.12. 疑似バウンディングボックスのablation studyの結果
3. Huber Loss
左から順にHuber Loss (緑のバー), L2 Loss (緑のバー), GC (Gradient Clipping / 黄色のバー) の3手法で比較されており、結果はFig13の通りです。
旧タスクに含まれるクラスの精度はHuber LossおよびGCの方がよく、新タスク中のクラスはL2 Lossの方が良い傾向にあるようです。
Huber Loss, GCではモデル更新幅が小さくなることで、L2 Lossよりも旧タスクの精度が保たれやすくなる直感に合う結果と考えられます。

Fig.13. 損失関数のablation studyの結果. GCはGradient Clippingの略で、勾配値の上限を設けることで、モデルのパラメータ変化が著しく大きくなることを防ぐ手法.
Towards Open World Object Detection(ORE)
提案自体はOpen World物体検出 (OWOD) という、CIODに近しい課題に主眼においている手法です。現実世界では無限のクラスがあると言えるため、学習データで全てをカバーすることは不可能です。そのため、学習データに含まれないクラスの物体を未知の物体として検出して人がアノテーションすることで、段階的にモデルを改善していくことを目的としています (Fig.14 上部薄オレンジ部分) 。
提案手法では、主に3つの工夫を行っています。
- 対照的クラスタリング損失の利用 (Fig.14 中央下のContrastive Clustering)
a. 特徴空間内で同一クラスの距離が近く、別クラスの距離が遠くなることが目的
b. 各クラスインスタンスの特徴量ベクトルの平均値 (Prototypes) と、全インスタンスの距離を計算し、損失関数に追加 - RPN (Region Proposal Network) の出力を利用した未知クラスへの疑似ラベル付与 (Fig.14 左下のAuto-labelling Unknowns)
a. 未知クラスのラベルがないため、ラベルを作成し学習に利用
b. RPNはクラスに依存せずバウンディングボックスの提案を出すため、シンプルにこれを利用するだけでかなり有効とのこと - リプレイアプローチの利用
a. 過去タスクのデータセットの一部 (提案手法では、各クラス50件ずつ) を保存し、新タスクの学習時に合わせて利用
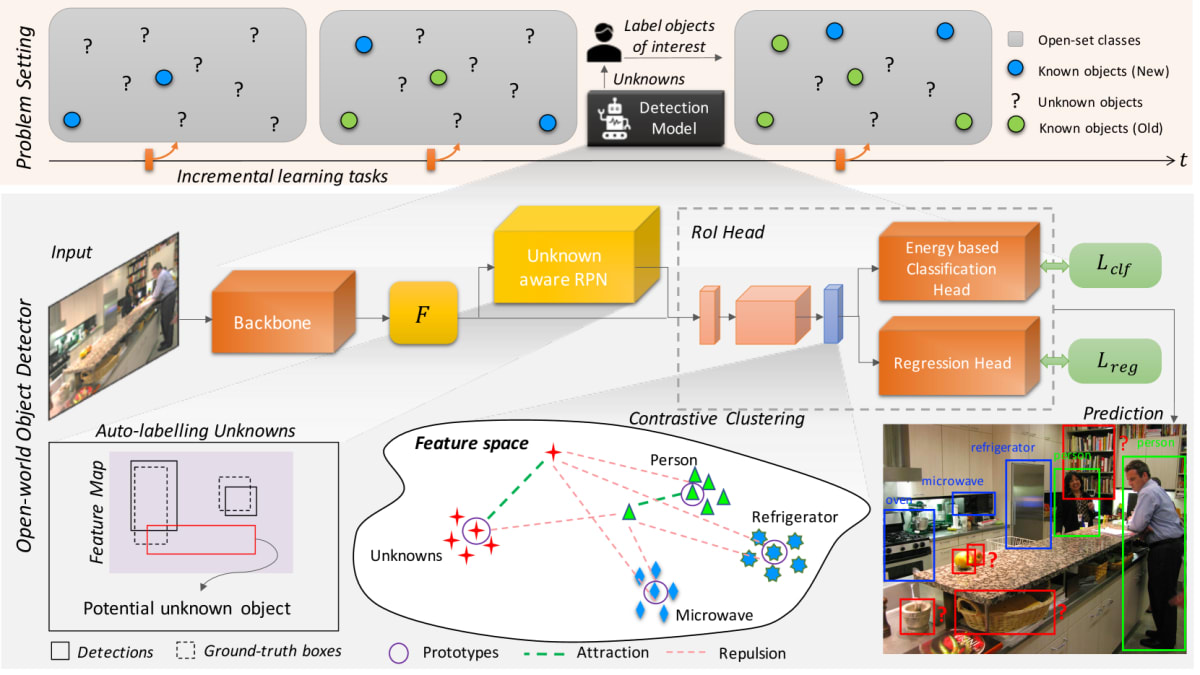
Fig.14. OREの手法概要
今後の方向性
最後に、CIODは発展途上の研究分野であるため、課題がいくつかあります。その中で、評価方法について簡単に触れます。
精度評価方法の課題改善
現状のVOC, COCOデータセットで評価を行った提案手法の殆どはモデルのハイパーパラメータ選択にテストセットを利用しているため、実応用時のパフォーマンスを過大評価している可能性が高いです。しかし、先行研究との精度比較を行い手法の優位性を主張するという建て付けのため、今後の研究でも是正することが難しいと考えられます。
多面的な評価方法の検討
CIODの研究の大半はモデル精度をいかに高くするかに焦点が当てられています。しかし、実応用の場面では計算負荷やモデル更新の頻度、ストレージの容量など別観点でも手法を検討する必要があります。また、新旧タスクに含まれるクラス数の割合など、ベンチマークのシナリオによっても最適な手法やパラメータは異なることが想定されます。実応用で想定される課題に対処することに主眼をおいた研究分野である分、評価方法も実用を見据えた形で高度化されることが期待されます。
おわりに
今回は、継続学習という枠組みを物体検出に適用した分野の紹介を行いました。継続学習の枠組みはモデル運用時への適用などで利用できる可能性がある一方で、研究分野としては発展途上であり、評価方法含め実用に近い状況を見据えた発展が望まれていると感じました。今後も継続的に追っていきたいと思います。
参考文献
A Comprehensive Survey of Continual Learning: Theory, Method and Application[Wang et al., 2023]
Continual Object Detection: A review of definitions, strategies, and challenges[Menezes et al., 2022]
IncDet: In Defense of Elastic Weight Consolidationfor Incremental Object Detection[Liu et al., IEEE, 2020]
Towards Open World Object Detection[Joseph et al., CVPR, 2021]
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。

Discussion