はじめに
はじめまして!
ZENKIGENのデータサイエンスチームでデータサイエンティストをしている川﨑と申します。
今回は、疑似ラベルを用いたモデルの精度向上に汎用的に使えるアイデアを提案した論文を紹介します。
疑似ラベル生成に伴うバイアス生成の問題についての議論もあり、課題の分析部分も面白いなと思ったので、ぜひご一読いただけると嬉しいです。
疑似ラベルとは
- ラベル付けされてないデータに、予測モデルで予測した結果をラベルとして付与したもの
- 入力データは大量にあるがラベルが付いたデータが少ない場合に有効
参考記事
論文情報
今回紹介する論文の基本情報は以下の通りです。
- タイトル: Debiased Learning from Naturally Imbalanced Pseudo-Labels [arXiv]
- 著者: Xudong Wang, et al.
- 会議: CVPR 2022 [CVPR2022]
TL;DR
- 疑似ラベルは、クラス分布が均衡なデータで学習/生成しても予測分布が偏ってしまう
- → 予測にバイアスが乗っている
- 疑似ラベルの予測分布が偏る原因をクラス間相関にあると指摘
- 疑似ラベルの作成・学習方法を工夫することでバイアス除去し、半教師あり学習を用いたモデル精度を向上させた
- 工夫1: 因果推論を用いたバイアス除去
- 工夫2: 適応的なマージンロスによる、バイアスの低減
1. 疑似ラベルを生成する手法の課題
本論文では、最初にFixMatch / CLIPを例に、既存の疑似ラベルを生成する手法の課題を提示しています。
具体的な課題は、「疑似ラベルを生成すると、クラス分布に偏りが発生してしまう」というものです。この現象は、仮に学習データや疑似ラベルを付与するデータのクラスバランスに偏りがない場合でも生じるとされています。
FixMatchの概要

- augumentationの強弱をつけて、弱augumentationデータで疑似ラベルを生成し、強augumentationデータの出力が擬似ラベルに近づくように学習させる
- confidenceの高い予測結果のみを学習データとして用いる
CLIPの概要

- モデルの学習: 画像とcaptionのペアを用意し、類似度が高くなるように学習
- 疑似ラベル生成:画像と、クラス候補のテキスト集合を潜在空間に埋め込みコサイン類似度を計算、ソフトマックス関数で確率分布に正規化する
なお、わかりやすさのため章番号を振っていますが、論文内の章とは対応していません。
例1: FixMatch:CIFAR10のデータにおける、クラスごとの疑似ラベルの予測割合

図の補足
- 横軸はclass index、縦軸はクラスごとの予測割合
- 図中複数のグラフは、エポックごとのクラス分布
こちらの図は、CIFAR10のデータをfew shot(4 label data / class)で学習させたモデルを元に、FixMatchで半教師あり学習を行った結果と提案手法の比較図になります。
図から、FixMatchのベースラインの手法は学習が進んでもクラス分布の偏りがほぼ改善されていないことが確認される一方、提案手法では学習が進むにつれて予測割合の偏りが改善されているのが確認されます。
例2: CLIP:ImageNetにおける、クラスごとの予測割合, とPrecision, recallのプロット

図の補足
- 横軸はclass index、縦軸は上の図がprecision、下の図がrecall
- グレーの線がクラスごとの存在確率、青とオレンジのプロットがクラスごとのPrecision/Recallと、平滑化したグラフ
こちらの図は、CLIPにImageNetのデータを入力した際のクラスごとの予測割合を表した図です。
この図を見ると、例1と同様にクラス分布の偏りが確認されます。
また、予測割合が高いクラスと中程度のクラスを比較すると、予測割合が高いクラスはPrecision, Recall共に低い傾向にあるのが確認されます。
2. 疑似ラベルでクラス分布が偏る原因の分析
本論文では、疑似ラベルを生成する手法の課題で確認された疑似ラベルの分布が偏る原因をクラス間相関にあると主張しています。
その主張に至る分析内容は以下のとおりです。
2.1 ImageNetを用いたCLIPのクラス間相関の分析

集計方法
- Imagenetの画像をCLIPのencoder部分に入力し、画像特徴量に変換
- クラスごとに画像特徴量を平均し、クラスごとの特徴量とする
- クラスごとの特徴量のcosine類似度を計算
- 予測割合が特に高い/低い10クラスを抽出
- 抽出したクラスとcosine類似度で降順にソートし、上位9クラスに絞り込み表とする
こちらの図は、予測割合が特に高かった/低かった10クラスを対象に、モデルの中間特徴量のcosine類似度が高く「モデル上は似ている」と扱われている上位9クラスの類似度をヒートマップにした図になります。
左側の予測割合が特に高いクラスの図と、右の特に低いクラスの図を比較すると、右のクラスが全体的にcosine類似度が高くなっているのが確認されます。
この図から、予測割合が低いクラスはクラス間の相関が高く、モデルの誤りが生じやすいことが推察されます。
2.2 CIFAR10を用いたFixMatchのクラス間相関の分析

こちらの表は、FixMatchを用いて学習させたモデルによる疑似ラベルの混同行列をヒートマップにしたものになります。
表から、あるクラスのミスラベルが特定の1-2クラスに集中していることが確認されます。
また、こちらも提案手法の比較をしており、提案手法ではミスラベルや偏りが改善されている事がわかります。
2.3 課題の結論
上記を踏まえ、本論文では疑似ラベルの偏りが生じる原因は主にクラス間の交絡にあるとし、提案手法でこの問題に対処していきます。
3. 提案手法
提案手法の方針は「動的な」「バイアス除去」とされていて、具体的なアイデアとして以下の2つが提案されています。
両アイデアともクラスごとの予測確率(以下、クラスごとの周辺確率と表現します)を予測されやすさ、すなわちバイアスとみなしてバイアス除去に利用します。
- 因果推論を用いた適応的バイアス除去
- 疑似ラベル作成時に、モデルの予測結果にクラスごとの周辺確率のlogを引いてからsoftmax関数にかけて疑似ラベルを生成する[1]
- 適応的なmargin loss
- クラスごとの周辺確率のlogをモデルの予測に足してからロス計算する[2]
1つ目は、周辺確率を差っ引くことで、クラスごとの予測されやすさを軽減して疑似ラベルを生成しようというアイデアになります。
2つ目は、ロス計算時に周辺確率を加味することで、予測されやすいクラスほど不正解時のロスが大きくなるように補正しています。これにより、特定のクラスに予測が偏る事象を改善しています。
まとめると、クラスごとに予測確率の分布が変わってくるので、それを疑似ラベル生成と損失関数の両方で改善させようという提案です。
また、各クラスの予測確率は固定値とするのではなく、都度アップデートすることを提案しています。(これが適応的の意味になります)
その際各クラスの予測確率を都度計算するのはコストが高いため、疑似ラベル生成時の予測確率のmomentumで代用しています。
4. 結果・考察
提案手法での比較結果は以下のとおりです。

こちらは、CIFAR10, CIFAR10LT(クラス分布を偏らせたデータセット)を対象に、学習データの件数を変えながら精度評価した表になります。
γがimbalance ratio、その下の数字と%表記は教師データとして用いた件数と、フルデータセットに対する教師データの割合を表します。
こちらを見ると、既存手法と比較して軒並み精度が向上しているのがわかります。
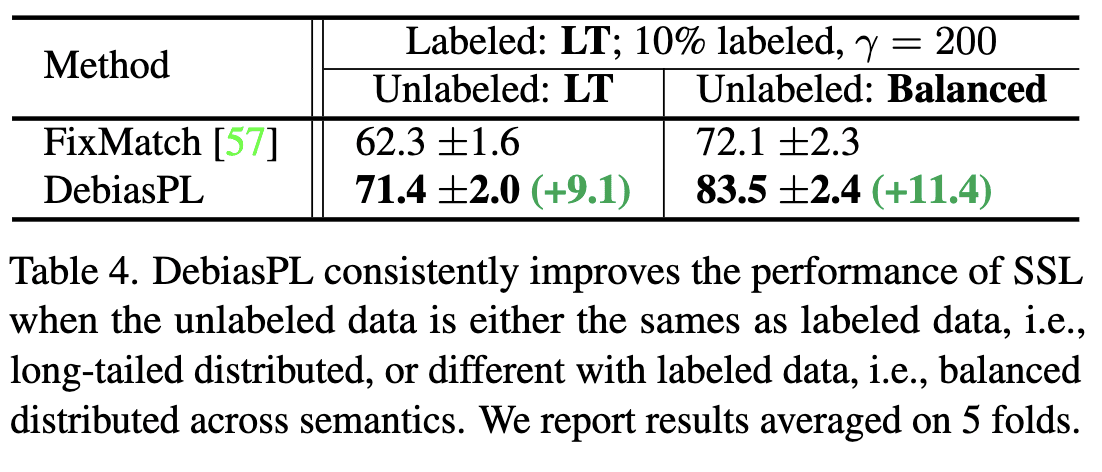
こちらは、元の教師データと、ラベルなしデータ(疑似ラベル学習用 & テストデータ)のクラス分布が同じ / 異なる場合の精度評価の比較です。(左側が同じ、右側が異なる場合)
どちらのケースでも精度が向上していますが、分布が異なる場合の方が精度が向上しているのがわかります。
ベースラインの精度はbalanceの方が高いため、精度向上の余地はbalanceデータの方が小さいことを考えると、データ分布の違いにより強い手法といえるのかなと思いました。
学習手順
- 分布に偏りを持ったデータ(CIFAR10LT)を用いて教師あり学習
- 分布が揃ったデータセット(CIFAR10)で擬似ラベルを用いた学習
まとめ
今回は、疑似ラベル生成を用いた半教師あり学習に一般に利用することで、モデル精度向上が期待できる手法を紹介しました。
論文では課題提起されていたバイアスを因果推論の観点から解説していたりと読んでいて楽しかったので、詳細が気になる方はぜひ論文に目を通して頂ければと思います。
お知らせ
DSチームでは、最近話題になっている技術や気になった論文などを持ち回りで紹介する勉強会を開催しています。
今回の記事では、この勉強会で紹介した内容をまとめ直して投稿させていただきました。
少しでも弊社や harutaka 、revii に興味を持っていただいたという方は、お気軽にご連絡頂けると幸いです!
カジュアルにお話という形でも、副業したいという形でも大歓迎です。
参考URL

Discussion