はじめに
こんにちは。ZENKIGENのデータサイエンスチームに所属しております、脇山拓也と申します。
弊社は自己PR動画を解析するAI「harutaka EF」や、企業と候補者の面接を解析し、面接品質の向上をサポートするAI「harutaka IA」などのサービスを提供しており、動画データの利活用を目指しております。
その中で、DSチームでは採用/職場領域の、画像(動画)・音声・テキストデータを使い、モデル開発やデータ分析といった業務をしております。
今回は画像領域(コンピュータビジョン領域)で話題となっているVisionTransformerの派生系モデル(以下MTV)を提案している論文について紹介します。
このモデルは、viewと呼ばれる動画特徴量(video representation)を異なるサイズで並列処理することで、短時間での細かな動きや長時間かけて変化する動きを捉えやすくできると考えられ、提案されました。
論文情報
今回紹介する論文の基本情報は以下の通りです。
- タイトル: Multiview Transformers for Video Recognition [arXiv]
- 著者: Shen Yan, et al.
- 会議: CVPR 2022 [CVPR2022]
論文を読もうと思った動機
CVPR2022で採択されており、Transformerだけで動画認識の精度を向上させようとしている点に興味を惹かれたためです。
2017年にNLP領域でTransformerが提案され、近年コンピュータビジョン分野でもTransformerが応用できると分かってから、動画像分野でのTransformer応用の研究が盛んになっています。
Transformerベースのアプローチによるインパクトの大きさがどの程度か、気になりました。
ViT, ViViTとは(おさらい)
論文で提案された手法に入る前に、ViT(VisionTransformer), ViViT(Video Vision Transformer)について、おさらいをしてみたいと思います。
ViT
-
2020年10月に、arXivにて公表された論文
- 翌年2021年5月に開催されたICLRに採択される
-
それまでは画像処理モデル=CNNベースという風潮だったが、畳み込み処理をしないモデルとして提案された
- 画像を均等サイズのパッチに区切って、トークンとして扱う
- 畳み込み処理の代わりに、Self-Attentionを用いる
-
画像分類タスクで、SoTAモデルと同程度または上回る精度を達成した

ViViT(A Video Vision Transformer)
-
ViTを動画認識に発展させたもの
-
TimeSformerとほぼ同時期に提案されたモデル
- TimeSformerとは、初めてCNNを用いずにTransformerだけで動画認識をするモデル(2021年に発表)
- それまでは3DResNetやSlowFastなどの3DCNNをベースとしたモデルがベースラインとなっていた
-
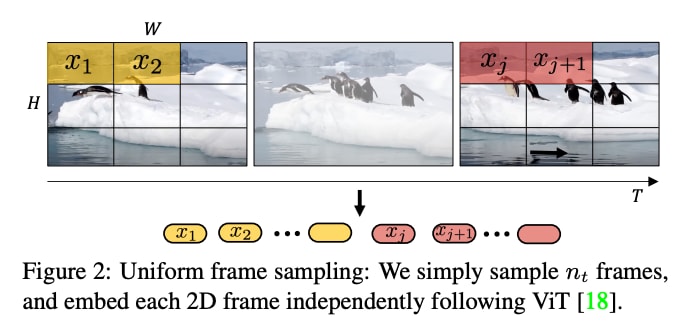
時系列情報と空間情報のトークン化を工夫した
- フレームごとにパッチに分割した特徴量を生成
- tubeletsという、複数フレームをまとめてパッチ分割し、時系列な特徴量を生成

-
ViViTでは4種類のアーキテクチャが検討され、そのうちのmodel-2(Factorized Encoder)が最も精度が良かったため、精度比較のモデルとして採用
- ViViT FEモデルのパフォーマンスが良かった要因はDivided Space-Time Attention
- 時系列情報と空間情報に分割し、それぞれに対してattention処理を行うことで、精度向上にもつながった


提案手法(MTV: Multiview Transformer for Video Recognition)
それでは、本論文の内容に入っていきたいと思います
提案手法の概要
-
動画に現れる様々な挙動を認識するためには、多様な解像度で時系列情報と空間情報を捉えることが必要
- 短時間の細かな動きや長時間のゆっくりとした動きなど
-
上記の達成のため、論文では以下のような工夫を行った
- viewという概念の導入
- viewとは「tubeletsから生成される映像特徴量」
- 様々なviewを生成することで、様々な解像度の動きを捉えられるように工夫
- 大きめのviewは、大きめのtubeletsから生成される特徴量
- 小さめのviewは、小さめのtubeletsからな生成される特徴量
- 直感的には、細かい動きは小さなtubeletsで、ゆっくりと変化する動きは大きなtubeletsで特徴を捉えることができるとされている
- それぞれのviewに適したサイズのTransformer Encoderで処理させ、その情報を統合して全体の推論を行う
- Multiview Encoder
- viewごとに独立したTransformer Encoderを利用
- Encoderの各Transformer Layerは、original tranformer(Attention Is All You Need)と同じデザインのものを利用
- 各viewごとに、異なる深さにすることも可能
- viewごとに独立したTransformer Encoderを利用
- Cross View Fusion
- Cross View Fusionによって、view同士(異なる次元数のtubelet)をどのようにfusionさせるかを考える(本論では、Abliation Studyにて3種類のアプローチを検討した)
→ 2, 3の工夫により計算量を抑えつつ、精度向上を図った
- Cross View Fusionによって、view同士(異なる次元数のtubelet)をどのようにfusionさせるかを考える(本論では、Abliation Studyにて3種類のアプローチを検討した)
- viewという概念の導入
-
最終的には、各ビューからトークン表現を抽出し、これらを最後のGlobal Encoderによって最終的な分類トークンを生成し、これを多層パーセプトロンに通すことで最終的な分類クラスを得る

Ablation Studyのハイライト
-
model-view assignment
-
前提情報
-
各モデルのconfiguration

-
表記の補足
- B/8は、Baseモデルを使って、16×16×8のtubeletsをエンコードしてviewとする
- Ti/2は、Tinyモデルを使って、16×16×2のtubeletsをエンコードしてviewとする
-
-
大きめのモデル(Baseモデル)には、小さめのビューを割り当てた方が精度が高い

-
three-viewモデルにおいて「全てBaseモデルをアサインする場合」と「Baseモデルに小さめのモデルを組み合わせる場合」とで、精度差がない
- →精度をほとんど犠牲にすることなく、モデルの複雑さを軽減できる

- →精度をほとんど犠牲にすることなく、モデルの複雑さを軽減できる
-
-
viewの数
- Single viewよりも、Multiviewの方が精度がいい
- またKinetics-400を使ってTop-1 accuracyを確認すると、
- two-viewモデルは、ベースラインモデル+2.5%
- three-viewモデルは、ベースラインモデル+2.8%
- ベースラインモデルのTop-1 accuracyは、78.3%
-
cross-view fusion method
- Cross-view attention(CVA)がベストパフォーマンスだった
- CVA, Bottleneck tokens, MLP fusionという3 methodを検討した
-
cross-view fusionの位置
- CVAを適用する層数と位置を変えて検証した
- fusion layerが1層の場合、best locationはmid-, late-, early- の順だった
- fusion layerが2層の場合、mid-とlate-でfusion layerを配置するとパフォーマンスが向上した
- CVAを適用する層数と位置を変えて検証した
-
ViViTのFactorized Encoderとの比較
- Single Viewモデルで層を深くするよりも、Multiviewで処理した方が精度がよくなることを確認した
- temporal dimensionを示すパラメータをt=2, 4に変えて比較した図は下の通り
-
t=4 -
t=2

-
括り
今回は、Transformerを使ったVideo Recognitionの論文を紹介しました。
本論文では、畳み込み処理を行わず、Multiview Transformerの利用を提案し、有用性を示しました。
- Multiview Encoder, Cross View Fusionにより、計算コストを抑えながらの精度向上を実現することができた。
- ViViT-FEモデルと比較した結果、Multiviewによるアプローチが有用であることを示した。
近年ではTransformerベースのアプローチの研究がとても盛んで、注目を集めていますが、数年経てば全く別のアプローチがデファクトスタンダードになっている可能性もあります。
ZENKIGENのDSチームでは持ち回りで勉強会も開催しているので、他のメンバーはどのような技術に注目しているのかも踏まえながら、今後も技術動向を追っていきたいと思います!
ご覧いただき、ありがとうございました!
お知らせ
少しでも弊社や harutaka 、revii に興味を持っていただいたという方は、お気軽にご連絡頂けると幸いです!カジュアルにお話という形でも、副業したいという形でも大歓迎です。
引用
-
S.Yan, et al. "Multiview Transformers for Video Recognition" CVPR 2022
-
A.Dosovitskiy, et al. "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale" ICLR 2021
-
A.Arnab, et al. "VIVIT: A Video Vision Transformer" ICCV 2021

Discussion