はじめに
ZENKIGENデータサイエンスチーム所属の redtea です。原籍はオムロンソーシアルソリューションズ株式会社 技術創造センタですが、社外出向でZENKIGENに所属しており、数理最適化や機械学習を用いたデータの分析業務、それらの結果に基づいた顧客への提案をしております[1]。所属チームでXを運用しており、AIに関する情報を発信していますのでご興味あれば覗いてみてください。
本記事の構成
本記事では想定読者を欲張って、GraphRAG は初めてでサクっと学びたい方から、詳しく学びたい方まで手広くしたいと思っています。そこで、最初に概論としてサクッと学べる短い章を設け、その後に詳しい説明の章が続くようにします。さらに、習うより慣れよということで、最後にハンズオン形式でナレッジグラフの構築から GraphRAG の実装までを行います。すなわち、
という読み方を想定しています[2]。
詳細の方では、Graph Retrieval-Augmented Generation: A Survey という GraphRAG のサーベイ論文の内容をたどりながら解説し、さらにサーベイ論文が公開された2024年9月から2025年3月現在までの最新の情報にも触れます。
なお、RAG を知らない方は想定読者から外れてしまうので、生成AIに聞いたり、ググったりしてみてください。例えば以下の記事を読むと RAG の概要を理解できるかと思います。
GraphRAG 概論
GraphRAG を初めて学ぶ方向けに、概論を記します。
なぜ GraphRAG をやるのか
なぜ GraphRAG をやるかというと、構造化された外部知識を LLM に供給することで、通常の RAG よりも効率的に外部知識を扱える可能性があるからです。
LLM を支えた RAG
LLM (Large Language Model) をはじめとする生成AIの台頭には目を見張るものがあります。ここまで LLM の持つ力を発揮できたのは Hallucination[3] や Knowledge Cutoff[4] への対処や、学習されていない社外秘データの活用など RAG (Retrieval-Augmented Generation) に代表される外部知識の活用の恩恵が大きかったと思っています。こういう事情もあって、RAG は非常に多くの注目を集めていました[5]。
GraphRAG の特徴
GraphRAG は RAG の一種です。従来の RAG ではテキスト文書から関連情報を検索[6]しますが、GraphRAG ではナレッジグラフ(知識グラフ)などの構造化データベースからグラフのノード・エッジ・サブグラフなどの要素を取得し、LLM へのコンテキストとして入力します。このあたりのイメージさえつけばなんてことはありません。まずはナレッジグラフの一例を見てみます。
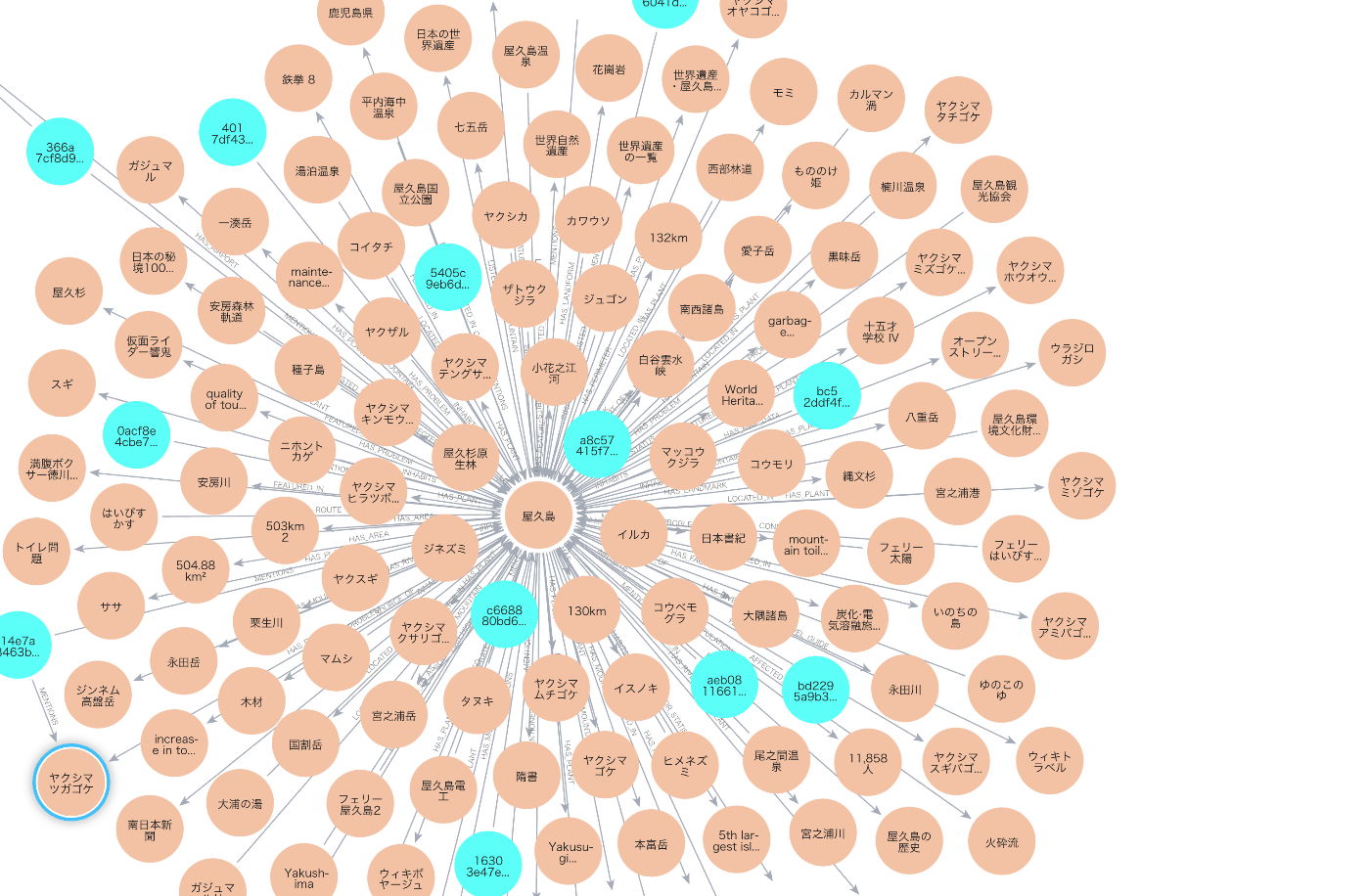
ナレッジグラフの例: Wikipediaの屋久島ページの内容をナレッジグラフ化しています。
ナレッジグラフは名前の通り知識を表すグラフです。各ノード(丸)が意味を持ち、それらをエッジ(線)でどのような関係かを表しながら結んでいます。通常ナレッジグラフは巨大なグラフで、図は一部を切り抜いたものです。次に具体的な説明のためにさらに拡大した一部を見てみましょう。
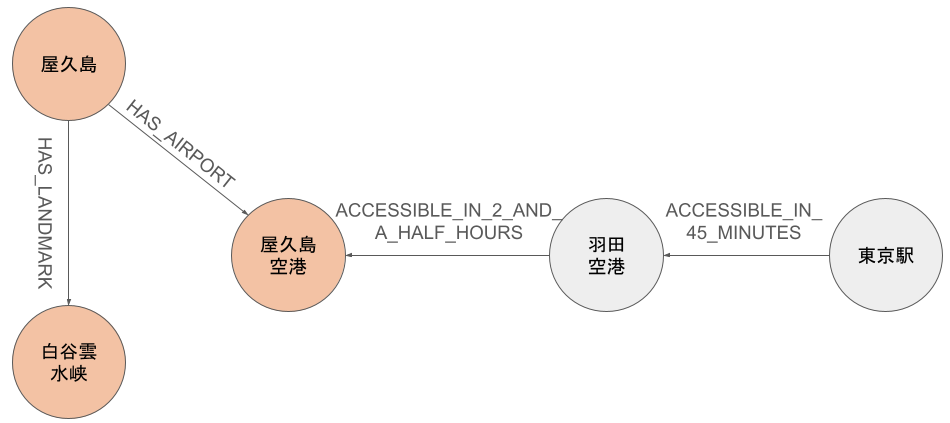
ナレッジグラフの一部を取り出した図です。屋久島には屋久島空港や白谷雲水峡があることが分かります[7]。また、これは私が Wikipedia にない情報を書き足したのですが、羽田空港から屋久島空港まで2時間半、東京駅から羽田空港まで45分で移動できます(Wikipediaには書いてなかったので色を変えています)。
例えば、東京駅から屋久島までの所要時間を LLM に聞いた場合を考えます。以下のようなテキストをコンテキストとして与えてみてはどうでしょうか。
屋久島 - HAS_AIRPORT -> 屋久島空港
羽田空港 - ACCESSIBLE_IN_2_AND_A_HALF_HOURS -> 屋久島空港
屋久島 - HAS_LANDMARK -> 白谷雲水峡
東京駅 - ACCESSIBLE_IN_45_MINUTES -> 羽田空港
実際、Wikipedia の屋久島ページには東京駅や羽田空港から屋久島へのアクセス時間が書かれていません[8]。仮に通常 RAG の情報源として、東京駅から羽田空港までの所要時間、羽田空港から屋久島空港までの所要時間が書かれているデータベースがあって収集できたとしても、別々の知識として扱われるため、これらを統合して回答を生成してくれるかどうかは LLM の頑張り次第になります。一方で、GraphRAG を用いれば関連する知識は統合された上でコンテキストとして与えることができるので、 LLM の認知負荷が下がると考えられます。
このように、GraphRAG はナレッジグラフ上のエンティティ間の関係を明示的に扱うことで、応答の正確性や一貫性を向上できると期待されています。
GraphRAG の強み
GraphRAG の強みは、通常 RAG の弱点の一部を解消できることです。以下、通常 RAG の弱みに対して、GraphRAG の強みを整理します。
Neglecting Relationships
RAG で扱うテキスト内容はそれぞれ独立ではなく、関係性があるはずです。しかし、テキストの中ではそれは構造化されておらず、ベクトル検索などの semantic similarity でドキュメントを検索した結果を並べるだけではそれを表現しきれません。グラフ構造を扱うことで、物事の関係性を明示的に扱うことができます。
Redundant Information
RAG ではテキストをそのままプロンプトに入れるので(しかも複数のテキストを繋げて大量に!)、lost in the middle[9] が起きやすいです。GraphRAG を用いれば、コンテキストとして与える情報を圧縮できるので、緩和されると考えられています。
Lacking Global Information
RAG では文章の一部を類似度に基づいて引っ張ってくるので、文脈が断片的で、文章全体の情報を把握することが難しいです。したがって、Query-Focused Summarization (QFS)[10] のようなタスクが難しくなる場合があります。一方 GraphRAG では、文章全体の意味を知識の構造化によって捉えることができ、一貫性のある解答が期待できます。
GraphRAG の課題
一方、GraphRAGにはいくつかの課題があります。詳しくは詳細で述べますが、有名なものを紹介します。
グラフからの効率的な情報検索
大規模なナレッジグラフではクエリに関連するサブグラフ(ノード集合やパス)の候補が爆発的に増え得るため、効率的な探索アルゴリズムやヒューリスティクスが不可欠です。たとえば全ノードの組合せを検討することは現実的でないため、クエリ中のエンティティに一致するノード近傍に探索範囲を限定する工夫などが求められます。
グラフ情報の LLM への統合
LLM は本来テキスト系列しか扱えないため、ノードとエッジで構成された非ユークリッド構造であるグラフデータをそのまま入力することはできません。このため、グラフ内の事実をテキストにシリアライズ(例:「AはBの子会社である」というトリプレット[11]を自然文に変換)したり、グラフエンコーダ(Graph Neural Network など)で埋め込みベクトルに変換して LLM と統合したりする必要があります。このとき、情報を変換・圧縮する過程での知識損失や、テキスト表現にした際の長大な入力といった問題も生じます。
GraphRAG 詳細
ここからは GraphRAG を作る・使う人向けの詳細な解説です。上記概要を読んだだけでは、
- そもそもどうやってナレッジグラフを作るの?
- GraphRAG には課題があるって書いてあったけど結局使えないの?
などなど、疑問がたくさん湧いたかと存じます。その好奇心を持ったまま、このページをスクロールしていきましょう...
前振りをしてしまったので、ナレッジグラフの作り方と GraphRAG の現状の課題(将来性)については記事中へのハイパーリンクを貼っておきます。
0. 本記事で扱うこと、扱わないこと
サーベイ論文 の3章からの説明を行います。本論文では、GraphRAG の基本的な知識を説明した後、GraphRAG のプロセスの段階に応じて説明しています。
- G-Indexing(グラフインデキシング)
- G-Retrieval(グラフ検索)
- G-Generation(グラフ拡張生成)
下流タスクやベンチマークなどの説明もありますが、GraphRAG 自体にフォーカスを当てるため、本記事では割愛します。論文中にも言及されていますが、GraphRAG はまだ初期段階です[12]。したがって、今後の研究の方向性についても掘り下げていきます。
1. Preliminaries(知識準備)
まずは GraphRAG を理解するための知識の事前準備です。
1.1 Text-Attributed Graphs (TAGs)
TAGs とは、ノード、エッジにテキスト情報が載っているグラフのことです。
- ノードはエンティティの名前をテキストで持ちます
- エッジはエンティティ間の関係をテキストで持ちます
再掲にはなりますが、まさにこのようなグラフのことで、GraphRAG ではこんなグラフを扱います。

TAGs の例(本記事から再掲)。
なお、本記事ではナレッジグラフ(知識グラフ)という表現を用いることが多いです。Knowledge Graph の頭文字を取って、KG と書かれることも多いです。
1.2 Graph Neural Networks(GNNs)
隣接するノード間の情報を集約して、ノード、エッジ、サブグラフの特徴量を作れるニューラルネットワークです。詳細は以下の記事をご参照ください[14]。
1.3 Language Models(LMs)
Generative models と Discriminative models があります。Generative models は言語の確率分布を出力するモデルで、GPT など、今日までの生成AIで使われているものです。Discriminative models とは、テキストを入力として受け付け、クラス分類するなどの識別器としての言語モデルです[15]。
2. Overview of GraphRAG
GraphRAG のゴールは、クエリと最も関連の高い情報をデータベースから見つけ出し、上手に活用することです。以下の図はQA[16]タスクを GraphRAG で答える例を示しています。まず、左下からご覧ください。"Graph Database & G-Indexing" と書かれていますが、世の中にすでに存在する Open Knowledge Graphs または 自作するナレッジグラフに対して、高速検索ができるように Indexing を行っています。次に、図左上の G-Retrieval です。「19世紀の芸術運動は、20世紀の近代美術の発展にどのような影響を与えたのか?」という問いに対して、関連が高い情報を検索します。検索した結果はその右隣に、Retrieval Results として描かれています。ノードを拾ってきたり、トリプレットを拾ってきたり、取得する形式は様々あります。それらを特定のフォーマットに変換して、言語生成器に渡すことで、最終的な解答を生成(G-Generation)しています。

Graph Retrieval-Augmented Generation: A Survey: Figure 2| QAタスクにおける GraphRAG の全体像。
定式化
まずは上記の流れを定式化します。
-
a* * -
a -
q -
\mathcal{G} -
A
としたとき、質問クエリ
ここで、さらにクエリとナレッジグラフ全体から解答を生成する部分
-
\theta, \phi -
G -
G^{*}
としたとき、以下のように書けます。
1行目は、ある解答
近似的な最適サブグラフ
-
\text{Sim} -
R
としたとき、G-Retrieval はナレッジグラフ全体から(近似)最適なサブグラフを抽出するのですが、それは質問クエリに類似[17] したものだと言っています。
最後に、検索して得た最適な部分グラフ
なお、
GraphRAG の3つのステージ
定式化によって、まずは近似最適なサブグラフを選ぶ必要があり、その情報を元に生成を行っていることがわかりました。サーベイ論文では、GraphRAG を以下3ステージに分解して、それらの手法についてサーベイしています。
- Graph-Based Indexing (G-Indexing)
- Graph-Guided Retrieval (G-Retrieval)
- Graph-Enhanced Generation (G-Generation)
Graph-Based Indexing (G-Indexing)
G-Indexing は最初のフェーズで、ナレッジグラフ
Graph-Guided Retrieval (G-Retrieval)
G-Retrieval では、自然言語によるクエリ
グラフ用語がでてきたので、ここで用語の説明だけします。
| 用語 | 説明 | 例 |
|---|---|---|
| エンティティ | ノードやエッジ | 「日本」ノード, 「首都である」エッジ |
| トリプレット | ノード、関係性、ノード のこと | 日本 (→ 首都 →) 京都[21] |
| パス | ノード→エッジ→ノード→エッジ・・・のこと | 日本 (→ 首都 →) 京都府 (→ 人口 →) 257万人 |
| サブグラフ | ナレッジグラフの部分集合。 | - |
Graph-Enhanced Generation (G-Generation)
G-Generation は、
式で書くとシンプルですが、サブグラフをそのまま LLM へ入力することはできません。抽出したサブグラの情報を失うことなく LLM へ入力可能な形式に変換したり、より良い解答を得るための工夫をここで行います。
3. Graph-Based Indexing
ここからは3つのステージそれぞれ深掘りしていきます。
G-Indexing は情報を検索しやすくするために、ナレッジグラフに行う前処理のようなものです。実際に検索するフェーズにおいて、検索する方法に応じた Indexing が必要です。Indexing によって、GraphRAG の検索パフォーマンスが大きく変わります。この章ではグラフデータの選択、構築、indexing の方法について紹介します。
3.1 Graph Data
いきなり G-Indexing とは関係がない話で恐縮ですが、ナレッジグラフにはどんなものがあるか紹介します。
3.1.1 Open Knowledge Graphs
先述の通り、ナレッジグラフにはオープンソースとして公開されている Open Knowledge Graphs というものが存在します。タスクによってはこれらを用いるとクリティカルに効きます。
| 名前 | 概要 |
|---|---|
| Wikidata | ウィキメディア財団が運営するオープンな知識ベースで、構造化データを提供し、Wikipediaや他のプロジェクトで利用される。多言語対応。 |
| Freebase | Googleがかつて運営していたナレッジグラフで、オープンデータとして提供されていたが、2016年にWikidataへ統合された。 |
| DBpedia | Wikipediaの構造化データを抽出し、RDF形式で提供するプロジェクト。オープンなナレッジグラフとして広く活用されている。 |
| YAGO | Wikipedia、WordNet、GeoNamesなどのデータを統合した、高精度なセマンティックナレッジベース。論理的整合性を重視している。 |
| ConceptNet | 人間の常識や単語間の意味関係を記述したオープンナレッジグラフ。自然言語処理(NLP)などの研究に活用される。 |
YAGO の例。
ConceptNet の例
3.1.2 Self-Constructed Graph Data
Self-Constructed Graph Data は名前の通り、独自のナレッジグラフを作る方法です。ナレッジグラフなので、Heterogeneous[22] なグラフを作ることになります。ノード、エッジの種類はタスク次第です。
通常、独自のナレッジグラフを持っていることは稀なので、テキストデータからナレッジグラフを構築することになります。テキストデータからナレッジグラフを作る方法については、GraphRAG の実装周りの紹介にて解説します。ざっくり言ってしまうと、2025年3月の現状は LLM に頼って文から知識を抽出してもらい、それらを繋げていく力技です。langchain にテキストからナレッジグラフを作る機能があるので、作ること自体は難しくありません[23]。
もう少しイメージしやすくするために、langchain の GraphRAG 用のナレッジグラフを作るためのプロンプトを作っている部分を抜粋します。
"You are a top-tier algorithm designed for extracting information in "
"structured formats to build a knowledge graph. Your task is to identify "
"the entities and relations requested with the user prompt from a given "
"text. You must generate the output in a JSON format containing a list "
'with JSON objects. Each object should have the keys: "head", '
'"head_type", "relation", "tail", and "tail_type". The "head" '
"key must contain the text of the extracted entity with one of the types "
"from the provided list in the user prompt.",
...(以下略)
まさに、 LLM に JSON 形式でナレッジグラフを作らせていますね。
ナレッジグラフを自作するプロンプトを作る関数の全体
def create_unstructured_prompt(
node_labels: Optional[List[str]] = None,
rel_types: Optional[Union[List[str], List[Tuple[str, str, str]]]] = None,
relationship_type: Optional[str] = None,
) -> ChatPromptTemplate:
node_labels_str = str(node_labels) if node_labels else ""
if rel_types:
if relationship_type == "tuple":
rel_types_str = str(list({item[1] for item in rel_types}))
else:
rel_types_str = str(rel_types)
else:
rel_types_str = ""
base_string_parts = [
"You are a top-tier algorithm designed for extracting information in "
"structured formats to build a knowledge graph. Your task is to identify "
"the entities and relations requested with the user prompt from a given "
"text. You must generate the output in a JSON format containing a list "
'with JSON objects. Each object should have the keys: "head", '
'"head_type", "relation", "tail", and "tail_type". The "head" '
"key must contain the text of the extracted entity with one of the types "
"from the provided list in the user prompt.",
f'The "head_type" key must contain the type of the extracted head entity, '
f"which must be one of the types from {node_labels_str}."
if node_labels
else "",
f'The "relation" key must contain the type of relation between the "head" '
f'and the "tail", which must be one of the relations from {rel_types_str}.'
if rel_types
else "",
f'The "tail" key must represent the text of an extracted entity which is '
f'the tail of the relation, and the "tail_type" key must contain the type '
f"of the tail entity from {node_labels_str}."
if node_labels
else "",
"Your task is to extract relationships from text strictly adhering "
"to the provided schema. The relationships can only appear "
"between specific node types are presented in the schema format "
"like: (Entity1Type, RELATIONSHIP_TYPE, Entity2Type) /n"
f"Provided schema is {rel_types}"
if relationship_type == "tuple"
else "",
"Attempt to extract as many entities and relations as you can. Maintain "
"Entity Consistency: When extracting entities, it's vital to ensure "
'consistency. If an entity, such as "John Doe", is mentioned multiple '
"times in the text but is referred to by different names or pronouns "
'(e.g., "Joe", "he"), always use the most complete identifier for '
"that entity. The knowledge graph should be coherent and easily "
"understandable, so maintaining consistency in entity references is "
"crucial.",
"IMPORTANT NOTES:\n- Don't add any explanation and text.",
]
system_prompt = "\n".join(filter(None, base_string_parts))
system_message = SystemMessage(content=system_prompt)
parser = JsonOutputParser(pydantic_object=UnstructuredRelation)
human_string_parts = [
"Based on the following example, extract entities and "
"relations from the provided text.\n\n",
"Use the following entity types, don't use other entity "
"that is not defined below:"
"# ENTITY TYPES:"
"{node_labels}"
if node_labels
else "",
"Use the following relation types, don't use other relation "
"that is not defined below:"
"# RELATION TYPES:"
"{rel_types}"
if rel_types
else "",
"Your task is to extract relationships from text strictly adhering "
"to the provided schema. The relationships can only appear "
"between specific node types are presented in the schema format "
"like: (Entity1Type, RELATIONSHIP_TYPE, Entity2Type) /n"
f"Provided schema is {rel_types}"
if relationship_type == "tuple"
else "",
"Below are a number of examples of text and their extracted "
"entities and relationships."
"{examples}\n"
"For the following text, extract entities and relations as "
"in the provided example."
"{format_instructions}\nText: {input}",
]
human_prompt_string = "\n".join(filter(None, human_string_parts))
human_prompt = PromptTemplate(
template=human_prompt_string,
input_variables=["input"],
partial_variables={
"format_instructions": parser.get_format_instructions(),
"node_labels": node_labels,
"rel_types": rel_types,
"examples": examples,
},
)
human_message_prompt = HumanMessagePromptTemplate(prompt=human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[system_message, human_message_prompt]
)
return chat_prompt
3.2 Indexing
ここからが G-Indexing の本題です。効率的なグラフ探索のために必須です。

Graph Retrieval-Augmented Generation: A Survey: Figure3| Indexing の概要です。なんらかのナレッジグラフを高速アクセス可能なデータベースにする工程です。
Indexing の方式には、以下の3種があります。
- Graph Indexing
- Text Indexing
- Vector Indexing
3.2.1 Graph Indexing
グラフ構造をそのまま Index として活用する方法です。全てのノードが、隣接するノードとエッジにアクセスできるようにするという、最もよく用いられている方法です。各ノードの接続情報(隣接リスト)を保存することで、素早く探索できます。グラフなんだから当然かと思われますが、これによってこの先出てくる retrieval stage において BFS (幅優先探索) やグラフ上の最短経路アルゴリズムが使えるようになります。
3.2.2 Text Indexing
検索最適化のために、グラフデータをテキスト文章に変換することです。当然、検索したい単語をノード名で検索しやすくする Indexing も含まれます。テキストからグラフを作っているとすると、グラフをテキストに変換することは元に戻しているだけに思われるかもしれませんが、単に戻しているわけではありません。構造化されていないテキストを一度ナレッジグラフ化することで各テキストの情報を統合した後、テキストに再変換しているので、元のドキュメント情報を広く扱ったテキストになっています。こうすることで、通常の RAG で行われているテクニックが使えます。
具体的には以下のようなアプローチがあります。
- トリプレットを自然言語に変換する
- グラフコミュニティ[24]を見つけて、(LLMを使って)そのサブグラフを文章に変換する
3.2.3 Vector Indexing
グラフのノードやサブグラフを高次元ベクトルに埋め込むことで、LSH (Locality Sensitive Hashing) や HNSW(Hierarchical Navigable Small World)のような効率的なベクトル検索ができます。LSH については以下のブログが実践的で分かりやすかったです。
埋め込みベクトルを作るアプローチには以下が挙げられます。
- Graph Neural Networks などの機械学習モデルを用いる方法
- 言語モデルを用いて、テキストクエリをグラフ探索に使えるベクトルにエンコードする。
- k-hop Ego Network[25] をグラフ埋め込みに変換する
4. Graph-Guided Retrieval
ナレッジグラフから情報を検索し、取得するステージです。RAG の最も本質的な部分であり、最も難しい部分です。難しい理由は以下の2つです。
- Explosive Candidate Subgraphs
取得すべきサブグラフの候補が爆発的に多いことです。サブグラフを効率的に探索するヒューリスティックなアルゴリズムが必要です。
- Insufficient Similarity Measurement
テキストクエリとグラフデータ間の類似性を測定するためには、テキストとグラフの双方を解釈できる方法[26]が必要です。
本節では、Retriever の選択、Retriever のパラダイム、検索する粒度、テクニックを紹介します。
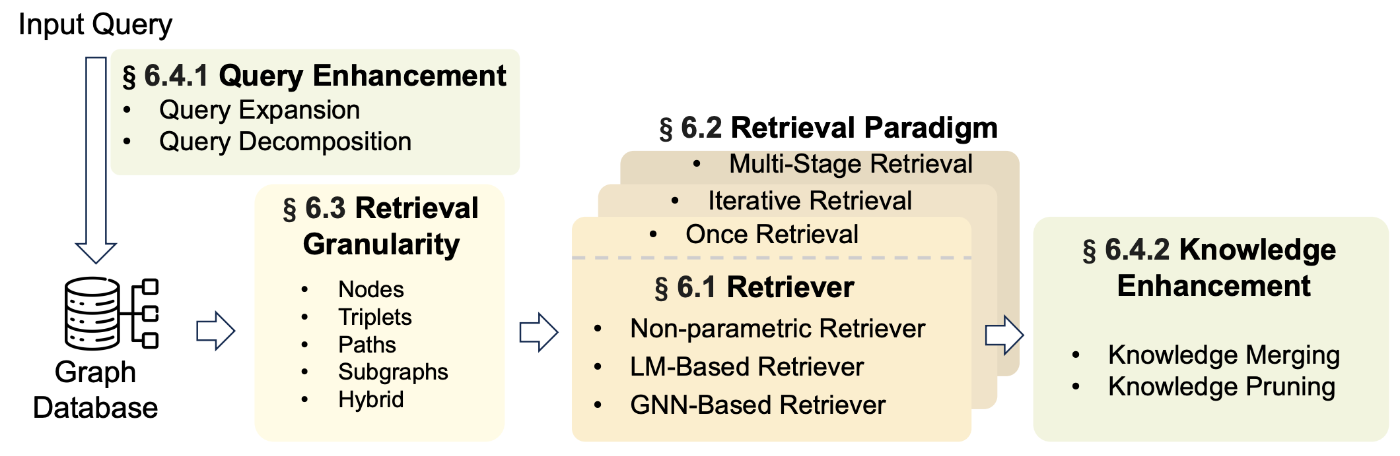
Graph Retrieval-Augmented Generation: A Survey: Figure 4| Graph-Guided Retrieval の一般的なアーキテクチャ。
4.1 Retriever
Retriever は大きく3つに分類されます:
- Nonparametric Retriever
- LM-based Retriever
- GNN-based Retriever
これらは、ナレッジグラフを検索する方法の大別です。それぞれ順番に見ていきます。
4.1.1 Nonparametric Retriever
Nonparametric、すなわち学習パラメータが存在しないアルゴリズムを用いた方法です。昔からあるグラフ探索アルゴリズムやヒューリスティックなルールベースを用いれば、ある程度高速に動作します。例えば、質問クエリや(あれば)答えの選択肢から重要なフレーズ(トピックエンティティ: topic entities)を抽出して、それらのノードを含むような k-hop パス[27]を取得する方法などです。
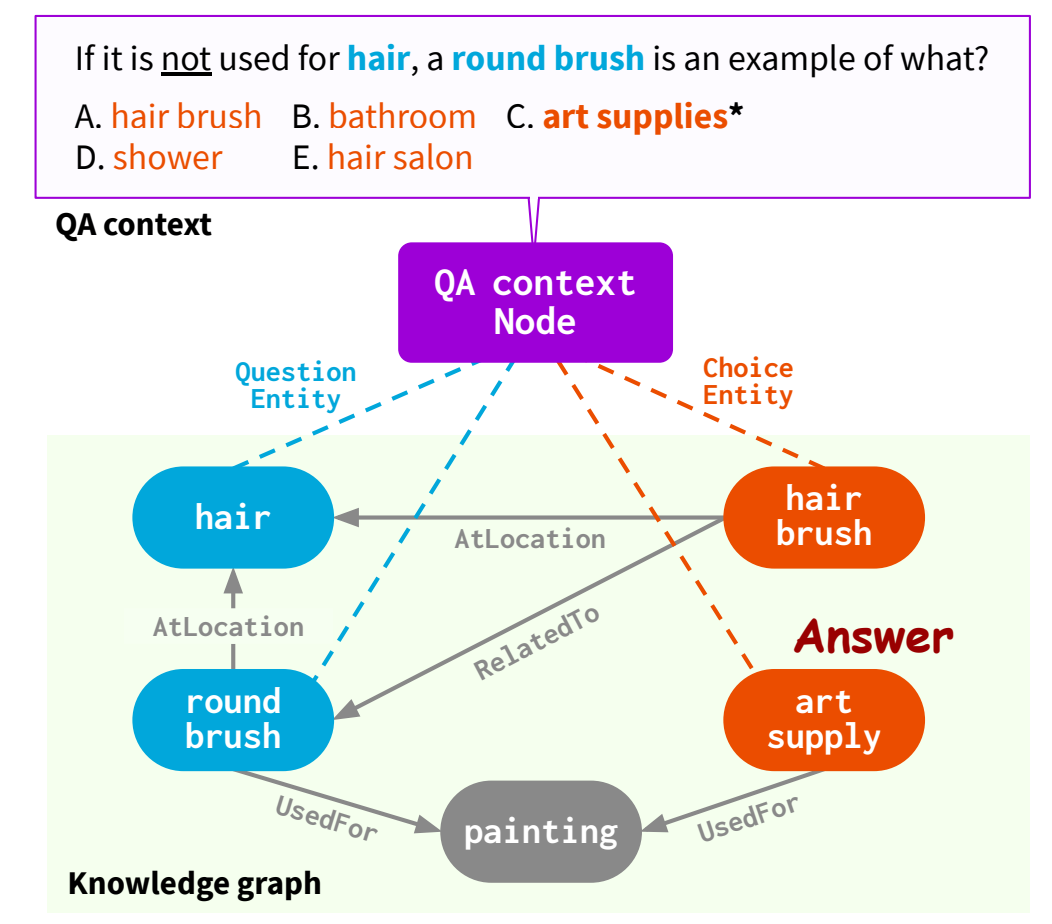
QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering: Figure1| 質問文と答えの選択肢から topic entities を検索。
4.1.2 LM-based Retriever
言語モデルを用いるアプローチです。例えば Subgraph Retriever は、RoBERTa をリトリーバとして学習させ、トピックエンティティから逐次的にパスを検索します。具体的には、質問クエリと知識グラフのエンティティをそれぞれ RoBERTa でベクトル化することで、類似度を内積によって直接比較します。これによって、トピックエンティティも探せますし、パス検索で辿る際にどのエッジを辿っていけばよいかの指針ができます。
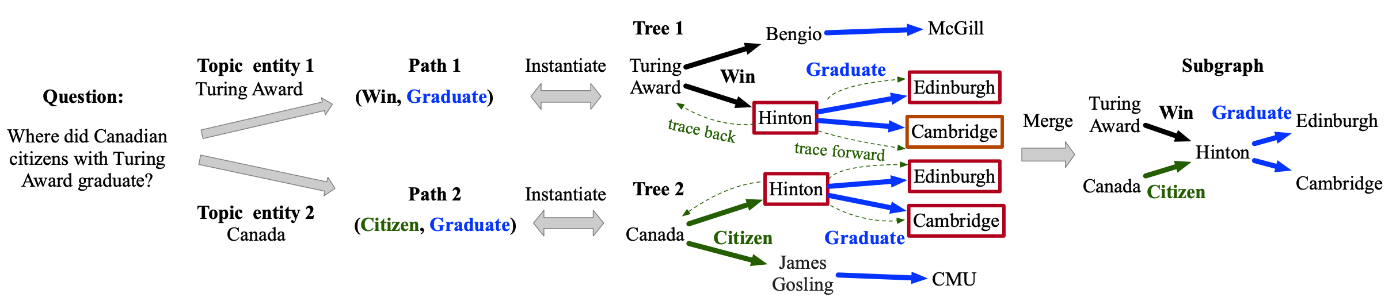
Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering: Figure2|トピックエンティティからナレッジグラフを辿っていき、最終的に辿ったパスをマージすることでサブグラフを構築しています。
4.1.3 GNN-based Retriever
GNN-based Retriever は、GNN でナレッジグラフのエンティティと質問クエリの関係性を学習し、適切なエンティティを推論するイメージです。例えば GNN-RAG では、質問クエリを事前学習済みの言語モデルによってエンコードしたものを用い、GNN による埋め込みベクトルとの類似度を学習させます。

GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
: Figure3| エンコードされた質問クエリに類似するノードを GNN によって推論させ、抽出したノードを最短経路で結んだサブグラフを構築しています。
基本的に GNN の学習が必要なので、QAデータセットが必要で、学習させることも、推論させることもコストになります。
4.1.4 Discussion
3種類の Retriever をみてきました。ノンパラメトリックな方法であればある程度高速ですが、精度に課題があり、LM ベースや GNN ベースは精度が良いが計算が大変というトレードオフの関係があります。ここでは割愛しますが、それらのハイブリッド式の Retriever が流行っているとサーベイ論文には書かれていました。
4.2 Retrieval Paradigm
Retrieval Paradigm (検索パラダイム) はいろいろあるそうですが、サーベイ論文では3つ紹介されていました。これは Graph ではない通常の RAG でも同じだそうです。
- Once Retrieval: 一度の検索だけで情報を収集する方式。
- Iterative Retrieval: 一度収集した情報を元に、再度検索する方式。検索回数を設定するか自動終了させるかでまた派生があります。
- Multi-Stage Retrieval: Iterative Retrieval において、各段階で異なるタイプの Retrievers を用いることが特徴。
以下詳しく見ていきます。
4.2.1 Once Retrieval
ナレッジグラフからの情報の検索・取得を、1回のクエリのみで行う方式です。1回で必要な情報を全て引っ張ってこないといけないので精度面では不利ですが、検索を繰り返さないので高速に動作します。HippoRAG のような埋め込みベクトルの類似度を元にする方法がポピュラーで、GraphRAG では GNNs による埋め込み表現の類似度から探す手法が対応します。
他にもすでに記事中にも登場しましたが、トピックエンティティを決めて検索し、それらを繋ぐパスのグラフを抽出する方法もあります。

KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning: Figure1| 質問クエリ中のトピックエンティティ(adult, use, glue_stick)に対して、それらを繋いだ情報を取得。
また、LLM を使う方法では、回答を得るのに必要な情報が何かを LLM で生成し、幅優先探索でナレッジグラフを検索して、それを prompt に含めるようにするアプローチもあります(以下図)。
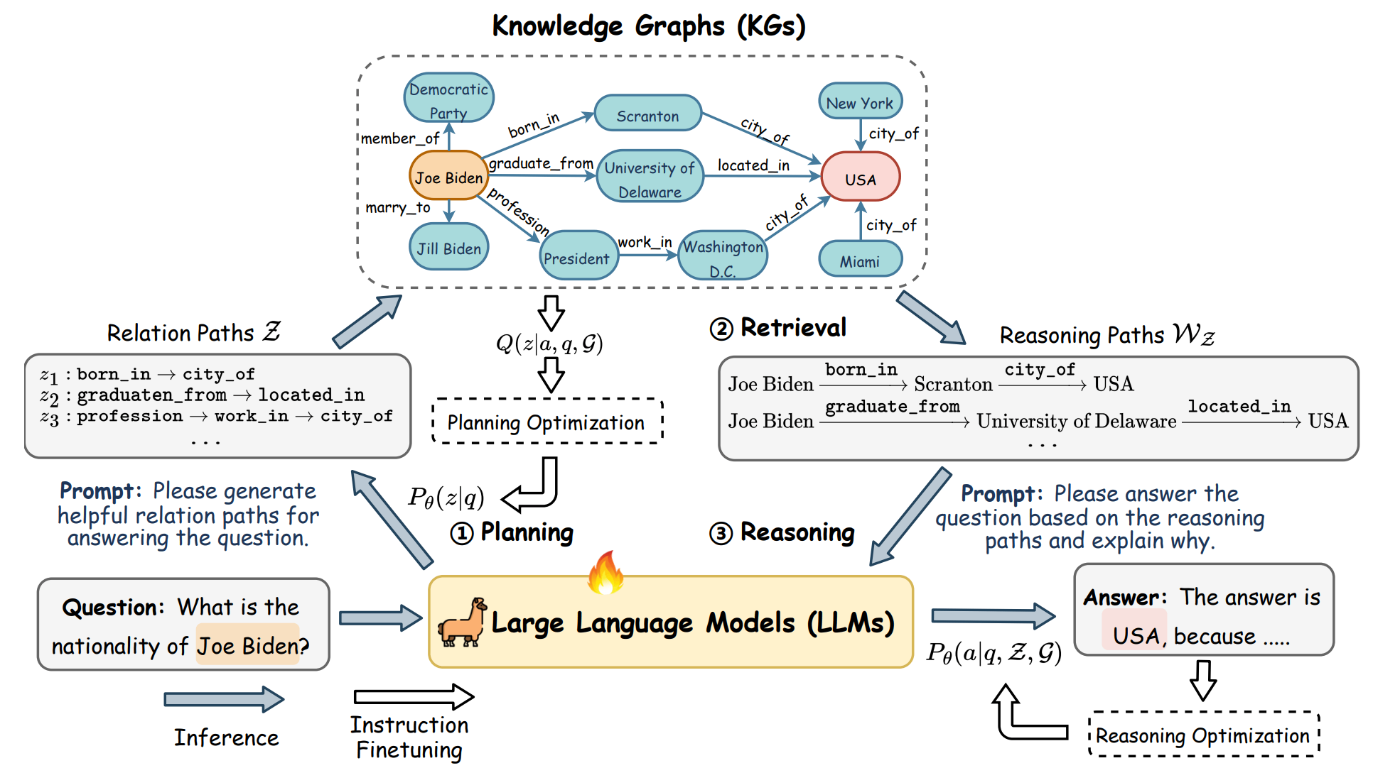
Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning: Figure2| 質問「ジョー・バイデンの国籍は?」に対して、LLM によって解答に必要な情報(生まれた場所や卒業した大学)を抽出し、それをナレッジグラフから検索します。
4.2.2 Iterative Retrieval
Iterative Retrieval は検索を反復して行う方法ですが、さらに non-adaptive とadaptive に分けられます。
non-adaptive は PullNet に見られるように、反復回数を決めたり、制限時間を設けるシンプルな方式です。
一方、adaptive は検索終了タイミングを自律的に最適化する方式です。例えば以下の図のように、グラフを辿る最大 hop 数を推定したり、探索の判断を LLM にやらせたりしています。

KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph: Figure2| 質問文から何 hop グラフを辿る必要かを
図中の実装の通り、LLM をかなりの回数呼び出すことになるので、実行コストは非常に重いです。やはりハイブリッド型が必要になってきそうです。
4.2.3 Multi-Stage Retrieval
Multi-Stage Retrievalでは、あらゆる Retriever を組み合わせて2ステージ以上に分けて検索を行い、精度向上を図ります。例えば、以下のような2ステージが考えられるとサーベイ論文では述べられています。
- LLM で推論したトピックエンティティについて、1-hop 近傍を全て検索する
- その近傍と、「その近傍以外の全ノード」との類似度を求めて、上位 k node を取得する
他にも本記事でも紹介したような GNNsベースの方法もあります。
- GNN でエンティティノードに近い上位 k 個の node を選択する
- エンティティノードとそれら k 個の node との全組み合わせの最短経路を取得する
どちらの方法も k 個の node を選択するステージと、それらからノンパラメトリックな方法でノードを辿る2ステージあるので Multi-Stage Retrieval です。
4.2.4 Disscuss
Once Retrieval は検索を繰り返さない分、高速に動作するので、リアルタイム応答に適しています。複数回検索するものは処理時間が長くなりますが、精度を高められるので、検索パラダイムはユースケースと用件次第です。速度と精度のバランスを取るために、4.2.3 Multi-Stage Retrieval でバランスを取るのが主流のようです。
4.3 Retrieval Granularity
検索で取得する情報の粒度(Granularity)にも様々あります。ナレッジグラフから検索される関連知識の形式は以下の4種が考えられると紹介されています。
- ノード
- トリプレット
- パス
- サブグラフ
ただ、私は実装上明確に分かれるものではないと考えていますので、あくまでも参考程度に受け取ってください。なぜなら、それらの粒度は包含関係にあり、サブグラフはパスで、パスはトリプレットで、トリプレットはノードでできているからです。
4.3.1 Nodes
ノードにはテキスト情報(ラベル)が付与されており、ノードの情報を取得しないことはほとんどないと私は思っています。ノード自体に、ノードを説明するテキスト情報が付与されていればそれも LLM へのインプットに活用できます。ノードからは質問クエリに関する特定の情報を取得できるため、正確性が高いです。
4.3.2 Triplets
トリプレットは主語-述語-目的語のタプル形式なので、1つのトリプレットから1つの意味を抽出できると考えられます。トリプレットからは template を用いたり、LLM を用いたりすることで、LLM へ入力可能な形式(テキスト)に変換します。

Graph Reasoning for Question Answering with Triplet Retrieval: Figure1| トリプレットを自然言語に変換。
4.3.3 Paths
グラフ内の複雑な関係や文脈依存性を捉えられるのが利点です。しかし、パスの探索はグラフのサイズが大きくなるにつれて指数関数的に増加し、計算量が増大する問題があります。この問題に対処するため、事前に定義したルールに基づいて関連するパスを検索する方法があります。例えば、質問クエリから重要なエンティティを複数選択し、次にそれらを n-hop 以内結ぶすべてのパスを抽出する方法が提案されています。

Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering: Figure 2| 質問解答において重要なエンティティを抽出し、それらを結ぶパスを抽出。
4.3.4 Subgraphs
パスはサブグラフなので、パスで紹介した方法もここに含まれます。これに加えて、トピックエンティティと、その 2-hop 近傍のエンティティもノード集合として選択し、それらを結ぶエッジを選択することでサブグラフを構成する方法が紹介されています[28]。
また、埋め込みベクトルベースでサブグラフ検索手法もあります。具体的には、グラフデータベースから全ての k-hop Ego Networks を GNN や LM 等でエンコードし、質問クエリの埋め込みベクトルとの類似性に基づいてに関連するサブグラフを検索する方式です[29]。
4.3.5 Hybrid Granularties
取得粒度を複数用いる方法も提案されています。詳細は元のサーベイ論文に譲るとして、LLM ベースのエージェントが、状況に応じてどの粒度で検索するかを決める方式も提案されています。エージェントによる検索の概要は以下の記事をご覧ください。
4.3.6 Discuss
どの検索粒度を用いるかは当然タスク次第です。単純なクエリや効率が最優先されるようなタスクの場合、検索スピードと関連性を最適化するために、エンティティやトリプレットなどの細かい粒度での検索が好まれます。一方、複雑なシナリオでは、複数の粒度を組み合わせたハイブリッドアプローチが有効な場合が多いと説明されていました。
4.4 Retrieval Enhancement
Retrieval Enhancement(検索強化)とは、検索しやすくするための工夫という位置付けです。以下の観点で検索強化できます。
- Query Enhancement(検索する前のクエリを強化する)
- Query Expansion(検索クエリを拡張する)
- Query Decomposition(検索クエリを分解する)
- Knowledge Enhancement(ナレッジグラフから取得した知識を強化する)
- Knowledge Merging(知識をマージする)
- Knowledge Pruning(知識を枝刈りする)
なお、「検索する前のクエリを強化する」と聞くと、通常の RAG ではよく使われている Query Rewriting[30] が思い浮かぶ方が多いと思います。サーベイ論文中では、Query Rewriting は GraphRAG ではまだあまり使われていないが、ポテンシャルはあるという説明に留まっていました。
以下、サーベイ論文を元に紹介しますが、いずれも通常の RAG でも活用されているアイデアです。
4.4.1 Query Enhancement
Query Expansion はクエリを拡張する方法です。具体例は以下の図(本記事では再掲)です。
Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning: Figure 2| 図左下の質問「ジョー・バイデンの国籍は?」に対して、必要な関係性(born_in, graduate_from など)を抽出しています。このように、元の質問文からナレッジグラフを検索するのに必要な情報に「拡張」し、それをナレッジグラフから検索する方法をクエリ拡張と呼んでいます。
Query Decomposition はクエリを分解する方法です。以下具体例を2つ挙げます。

Complex Logical Reasoning over Knowledge Graphs using Large Language Models: Figure1| 解答を得るのに必要な要素に分解し、それぞれの解答を LLM で生成した後、それらを考慮して最終アウトプットを生成。

KG-GPT: A General Framework for Reasoning on Knowledge Graphs Using Large Language Models: Figure1| 1. クエリをLLMで分解して細かい文章にわける(図上)。 2. 細かい文章ごとにエンティティを決めて、ナレッジグラフから検索する(図左下)。 3. それぞれから関係しそうなリレーションをLLMで決定して、上位
4.4.2 Knowledge Enhancement
Knowledge Enhancementとは、ナレッジグラフから知識を取得した後、それらの知識をマージしたり(Knowledge Merging)刈り込み[31](Knowledge Pruning)したりすることで、取得した知識を洗練させることです。
Knowledge Merging することで、知識の完全性や一貫性を高めるだけではなく、LLM への入力長を制限できます。例えば、抽出したサブグラフをマージして新たな大きなサブグラフを作ります。イメージしやすいと思うので具体例は割愛します。
Knowledge Pruning はフィルタリングのイメージです。re-rank 付けベースのアプローチと LLM ベースのアプローチの2つの主要なカテゴリーがあります。
re-rank 付けベースでは、抽出した知識に「役立ち度ランキング」をつけて、上位のみ利用するアプローチです。具体的には、抽出したトリプレットと質問文の類似度を計る方法が提案されています。
LLM ベースのアプローチでは、例えばどのトリプレットを残すかを LLM に判断させます。以下の図のようなイメージです。

Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering: Figure4| LLMの判断によって、抽出したサブグラフのうち、不要なエッジを削除。
5. Graph-Enhanced Generation
いよいよ抽出した知識を活用した生成のステージです。下流タスクに応じた選定が重要です。
5.1 Graph Formats
4. Graph-Guided-Retrieval で検索した情報をどんな形式で LLM に渡すかを考えます。モデルが公開されていない API 形式で利用するような LLM に、ナレッジグラフの情報を入力する場合はテキスト形式に落とし込む必要があります。そこで、Graph Translator(グラフ翻訳器)により、検索したサブグラフを Graph Languages(グラフ言語)に変換するのが一般的です。一方で、ローカル LLM 向けですが収集したグラフ情報を埋め込みベクトル化して LLM 与える Graph Embeddings(グラフ埋め込み)というアプローチもあります。それぞれ解説します。
5.1.1 Graph Languages
グラフ言語とは、ノードやエッジの情報をテキストで表現するために用いられる形式です。以下の5種類が紹介されています。

Graph Retrieval-Augmented Generation: A Survey: Figure6| グラフ言語の一覧。
(1) Adjacency / Edge Table は隣接行列[32]のことですが、ここでは例えばトリプレットを単に書き並べる例を挙げています。簡潔で分かりやすいですが、テキストとしては淡白すぎて、コンテキスト情報としては物足りなく感じます。
(2) Natural Language は自然言語によってサブグラフを説明する方法です。エッジの種類ごとに文のテンプレートを決めておき、そこにノードやエッジ情報を埋め込む方法や、1~2 hop 隣接ノードの情報を自然言語で説明する方法、グラフコミュニティ単位で要約を作る方法が挙げられます。
(3) Code-Like Forms は LLM が理解できる「コード形式」です。自然言語ではグラフの構造を忠実に表せませんが、このアプローチならグラフ構造を LLM に伝えられるのが利点です。形式としては、GML (Graph Modeling Language) や GraphML (Graph Markup Language) などがあります。
(4) Syntax Tree は、構文木に近い形に変形するアプローチです。階層構造を保ったままグラフ情報を保持できるため、より高度な分析や処理が可能です。以下図の GraphText では、中心ノードの Ego Network を「グラフ構文木」として変換することで、構造的かつ階層的な情報を併せ持つ形式を実現しています。
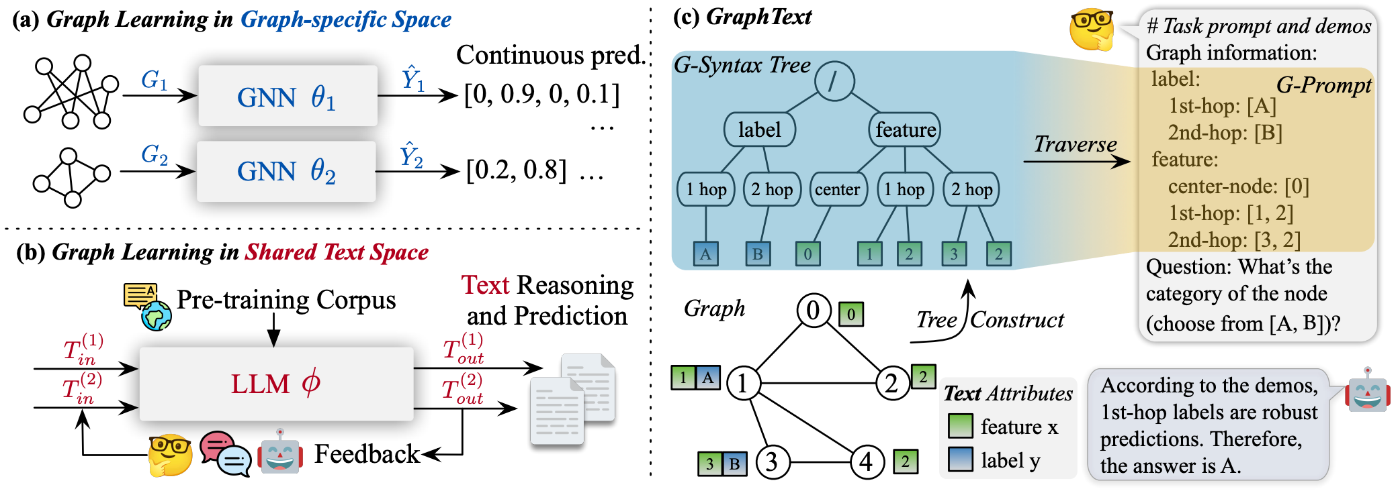
GraphText: Graph Reasoning in Text Space: Figure1| 右上 (c) の部分にて、構文木を LLM に入力可能なテキストで表現。
(5) Node Sequence はあるルールに沿ってノードを列挙し、列として LLM に与える方法です。自然言語よりは短く、かつグラフ構造(隣接関係など)の一部をルールとして反映できると紹介されています。
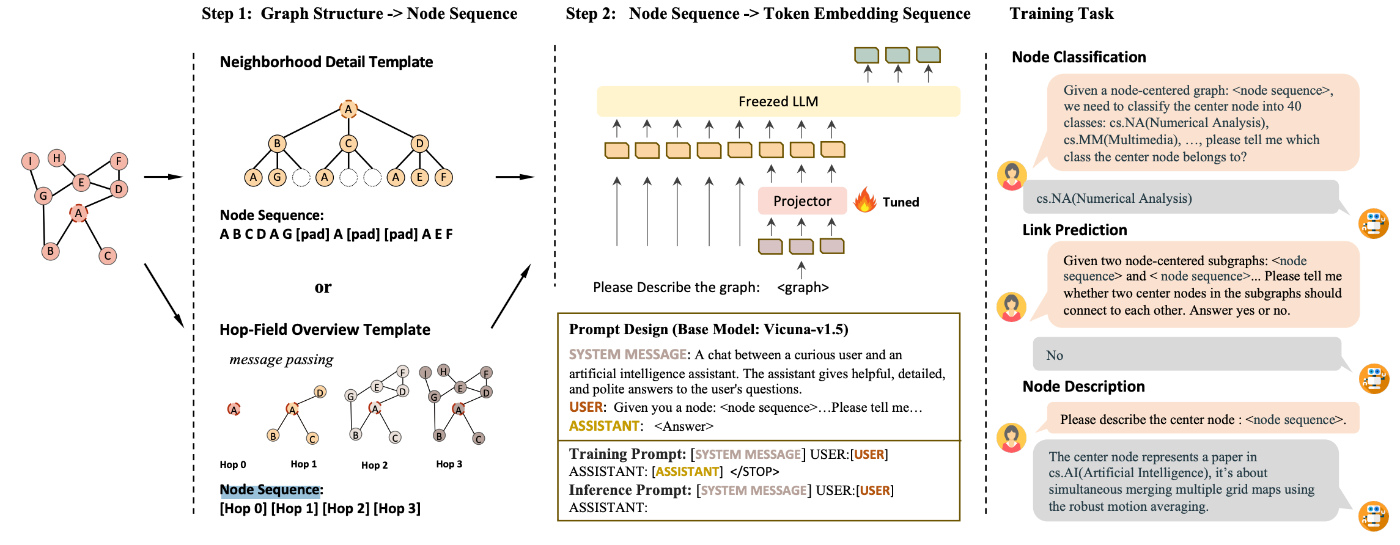
LLaGA: Large Language and Graph Assistant: Figure1 図左側上部にて、node sequence を作成。
選定観点は以下の3つです。
- 完全性: グラフ情報を落とさずに表現できること
- 簡潔性: 入力長が長くなりすぎて、LLM の最大コンテキスト長を食い潰さないこと
- 可読性: LLM が理解しやすい形式であること
5.1.2 Graph Embeddings
グラフ言語をテキスト化すると、(通常 RAG よりマシになるのが利点とは言え、)場合によっては入力が非常に長くなり、LLM のトークン長制限を超える恐れがあります。また、LLM 自体がグラフ構造を完璧に理解しきれないという報告もあります。そこで、GNN を用いてグラフを埋め込みベクトルにし、それを LLM に与えるアプローチも注目されています。もちろんこれは、ChatGPT に代表されるクローズドで API 利用が前提のモデルには適用できない方法ですが、今後ローカル LLM の活用が広がるとこのアプローチも選択肢に入ってきます。
グラフ埋め込みを LM と統合する際は、FiD(Fusion-in-Decoder)を使う方法が多いです。ただし、埋め込みベクトル形式ではノード名などの正確な情報を残しづらいことが課題に挙がっているようです。
5.2 Generation Enhancement
生成段階では、「グラフデータを変換して LLM に渡す」という基本プロセスに加えて、より良い出力を得るための追加的な工夫が行われることがあります。このような生成改善手法は、適用されるタイミングによって「事前(Pre-Generation)」「途中(Mid-Generation)」「事後(Post-Generation)」の3つに分けられます(以下図参照)。

Graph Retrieval-Augmented Generation: A Survey: Figure5| Graph-Enhanced Generation(グラフ強化生成)の概要。改善手法の適用タイミングによって分類。
5.2.1 Pre-Generation Enhancement
生成の前段階で、入力データや内部表現を洗練させる手法です。Knowledge-Enhancement との区別は曖昧ですが、サーベイ論文では「知識取得 → 知識を統合 → 不要部分の除去」までは Knowledge-Enhancement とみなし、それ以降の操作を Pre-Generation Enhancement(プレ生成強化)としています。
具体例としては、検索・取得したグラフデータを LLM を使って書き換えることで、自然なテキストにする手法があります。正直 Knowledge-Enhancement で挙げた手法とかなり似ているように感じますが、サーベイ論文の登場に倣って紹介しました。

Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering: Figure2| 左側は検索して見つけたトリプレットをそのまま LLM に入力しているのに対し、この手法では一度 LLM によって自然な文章にしています。
5.2.2 Mid-Generation Enhancement
Mid-Generation Enhancement は、生成の最中[33]に適用される制約やプロンプト調整などの手法です。
例えば、検索したナレッジグラフに存在しないトリプレットが生成されないように次トークンを制限するような制約付きデコーディングを行う方法です。これはローカル LLM でしかできない方法ですね。
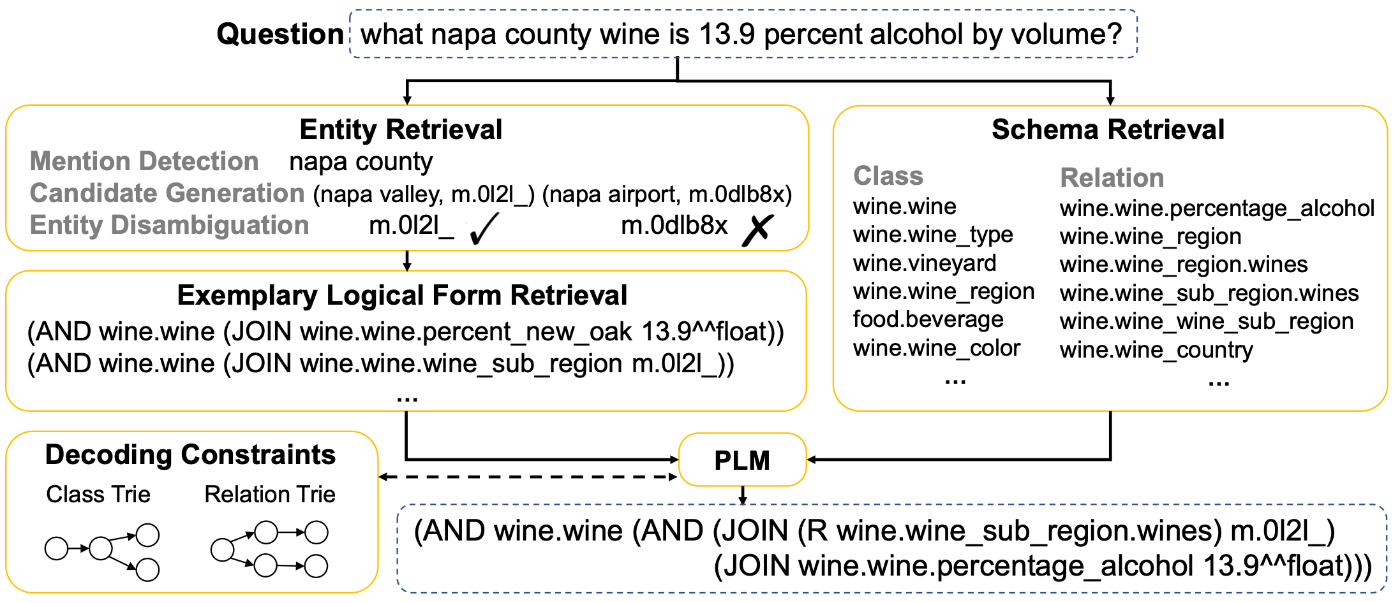
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases: Figure1| 図左下に"Decoding Constraints"と書かれているように、言語モデルの遷移先を検索して定めた情報に基づいて制限しています。
5.2.3 Post-Generation Enhancement
Post-Generation Enhancement は生成の後で、複数の生成結果を組み合わせたり、評価によって解答を選んだりする手法です。複数出力させた後、それらを統合的に判断するやり方は GraphRAG に限った話ではないので、さらっと書くに留めます。
- グラフコミュニティごとに要約を生成し、それらを用いて一時解答を生成。それらを用いて最終的な解答を生成する。
- 複雑なクエリ質問をサブ質問に分割してそれぞれ解答を生成する。最後に統合して解答する方法。
6. Future Prospects
GraphRAG は大きな進歩を遂げ、一部実用化も進んでいる一方で、まだ多くの課題が残されており、さらなる研究が求められています。以下の各項目では、GraphRAG が直面している代表的な課題と、それに対する将来的な研究の方向性を示します。
6.1 Dynamic and Adaptive Graphs(動的かつ適応的なグラフへの対応)
ナレッジ情報は常に更新されるものですから、グラフも更新し続ける必要があります。現在の GraphRAG 手法の多くは静的なデータベースを前提としていますので、新規データを統合できる手法の開発が必要です。
6.2 Multi-Modality Information Integration(マルチモーダル情報の統合)
多くのナレッジグラフはテキスト情報が中心で、画像・音声・動画などのマルチモーダル情報は取り込めていません。これらをグラフデータに組み込むと、グラフの規模や複雑性が増大するので容易ではありませんが、これを実現する基盤技術が確立すればより豊かな GraphRAG が実現できるかもしれません。
6.3 Scalable and Efficient Retrieval Mechanisms(スケーラブルで効率的な検索メカニズム)
実運用を想定すると、数十億単位のエンティティを含むグラフも考えられます。現在研究で用いられているグラフは数千程度のエンティティで構成されており、大きなギャップがあります。大規模なデータの中でも高い検索精度とパフォーマンスを維持できるアルゴリズムや、分散コンピューティング活用のインフラが必要です。
6.4 Combination with Graph Foundation Model(グラフの基盤モデルとの組み合わせ)
グラフに関する多様なタスクを高精度で処理できるグラフの基盤モデルが登場しています。GraphRAG パイプラインにこれらのグラフ基盤モデルを導入することで、パフォーマンスの向上が期待できますが、まだ十分な研究発表が行われておりません。グラフの基盤モデルの開発と、その組み込みに期待が集まっています。
6.5 Lossless Compression of Retrieved Context(取得コンテキストのロスレス圧縮)
多くの GraphRAG では、エンティティやそれらの関係性を含むグラフ情報をLLMが解釈できるようにグラフ言語に変換します。元のテキストをそのまま与えるより文字数を圧縮できることが GraphRAG の利点ではありますが、それでもこの文脈が非常に長くなってしまうことがあります。冗長な情報だけを取り除いて、失うものがない情報圧縮(Lossless Compression)が重要です。本記事でも取り上げた Knowledge Pruning のような手法は、情報量とのトレードオフになってしまいます。
7. 最新の動向(2025年3月現在)
今回紹介しているサーベイ論文の最終更新は2024年の9月なので、その近辺や以降の取り組みをいくつか紹介します。
私が調べた限りの研究については、精度改善は本記事で紹介した手法のハイブリッド形式のものが多い印象です。
Indexing についてはマルチ粒度インデックス、Retrieval については GraphRAG と通常のテキストに対するベクトル検索のハイブリッド方式が提案されています。
また、Microsoft 社が発表した GraphRAG に関する論文やブログは注目を集めています。GraphRAG: Improving global search via dynamic community selection という記事では、 Global Search の改善について説明しています。Global Search は、グラフコミュニティの要約(ベクトルでも良いですし、要約する文章でも良い)を作成し、質問クエリに関連するコミュニティを抽出するアプローチです。一方、ノード単位で検索をかけて、そこからノードを辿って情報を検索していくことを Local Search と言います。Global Search によって、抽象度の高い質問に対しても、検索対象ドキュメント全体を踏まえた回答が期待できます。
LazyGraphRAG ではデータ検索時の計算コストが通常のベクトル検索 RAG 程度の計算量に抑えているそうです。
GraphRAG の実装周りの紹介
2025年現在、オーソドックスな方法として、LangChain を用いて、neo4j 上でグラフデータベースを構築するのが一般的かと思います。他にも、データベースとしては Amazon Neptune、GraphRAG フレームワークの LlamaIndex の利用も選択肢に入ると思います。この手のライブラリは割とすぐに仕様が変わったり、より便利なものが登場したりと移り変わりが激しいので、2025年3月時点でサクッと動かせるものを1つだけ紹介するに留めます。
ハンズオン
今回私が動かしたサンプルソースコードは GitHub にて公開しております。本ハンズオンでは、ポピュラーな方法として、LangChain を用いて、ドキュメントである PDF を Gemini でナレッジグラフ化し、 neo4j 上でグラフデータベースを構築します。
なお本ハンズオンは以下の記事を大いに参照しながら、自身の環境に合わせて動かしたものです。ソースコードの解説はほとんど以下のページにあるので全ては解説しませんが、本記事で扱った内容に関するものだけ解説します。
データの準備
今回は PDF データを用いることにしました。試しに Wikipedia の屋久島ページと種子島ページを PDF 形式でダウンロードします。ダウンロードの方法はこちらをご参照ください。
ダウンロードした PDF ファイルはそれぞれ屋久島.pdf と 種子島.pdf という名前で、database ディレクトリに保存してください。
グラフデータベースの立ち上げ
- neo4j にアクセスし、ログイン。
- Create instance をクリック。
- とりあえず試すだけなら無料枠で十分です。
AuraDB Freeを選択。 -
UsernameとPasswordが表示されるので控える(この後インスタンスが立ち上がるのに少し時間がかかる)。 - 右側の「・・・」をクリックし、表示される
inspectをクリックするとConnection URIが表示されるので、それも控える。

neo4j 上で AuraDB が立ち上がった画面のスクリーンショット。右側の「・・・」から Connection URI を確認できます。。

Connection URI の確認画面。
環境構築
Python環境
rye 環境で、以下のコマンドを実行してください。
rye sync
rye ユーザーではない方は、pyproject.toml を参照して適宜環境構築してください。
環境変数
.env ファイルを作成し、グラフデータベースの立ち上げで控えた内容を書きます。LLM の設定は、各自の環境に合わせてください。
# neo4j の設定
NEO4J_USERNAME="neo4j"
NEO4J_URI=neo4j+s://*******.databases.neo4j.io
NEO4J_PASSWORD=*******
# LLM の設定
project_id=*******
location=*******
model_id=*******
実行
まずはナレッジグラフの構築です。LLM がドキュメントを読み込んでナレッジを作るので、少々時間がかかります。
rye run src/graph_rag/make_knowledge_graph.py
次に、質問クエリを投げて、ナレッジグラフから情報を抽出します。
graph_retrieval.py の QUESTION を自由に書き換えて実験してみてください。
QUESTION = "屋久島と種子島はどこにありますか?"
実行は以下のコマンドです。
rye run src/graph_rag/graph_retrieval.py
サーベイ内容との関連
Graph-Based-Indexing
Indexingに関しては、今回のグラフ作成はノードやエッジ名で検索ができるよう Text Indexing と、質問クエリとの類似度を測るVector Indexing を行なっています。
LangChain がかなり処理を抽象化してくれていますが、ノードやエッジの Text Indexing は特別に指定しなくとも当たり前のようにやってくれています。
graph_documents = llm_transformer.convert_to_graph_documents(docs)
Vector Indexing は、質問クエリのテキストと、各ノードに付随のテキスト間の埋め込みベクトルの類似度を基準にしています。今回の実装では、この検索結果はサブグラフとしてではなく、通常の RAG のような単なるテキスト情報として収集するのに用いられています。
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
search_type="hybrid",
node_label="Document",
text_node_properties=["text"],
embedding_node_property="embedding",
)
Graph-Guided Retrieval
今回の Retrieval は LLM でトピックエンティティを見つけた後、ノンパラメトリックな方法で情報検索しています。まずは以下の部分で、トピックエンティティを抽出しています。
class Entities(BaseModel):
names: List[str] = Field(
...,
description="All the person, organization, or business entities that "
"appear in the text",
)
...(中略)
entities = entity_chain.invoke({"question": question})
QUESTION = "屋久島と種子島はどこにありますか?" という問いに対しては、屋久島と種子島がトピックエンティティになっていました。
そしてその近傍にあるノードを検索しています。
for entity in entities.names:
# 屋久島と種子島はどこにありますか?"` という問いに対するentity は「屋久島」と「種子島」
response = graph.query(
"""CALL db.index.fulltext.queryNodes('entity', $query, {limit:2})
YIELD node,score
CALL {
WITH node
MATCH (node)-[r:!MENTIONS]->(neighbor)
RETURN node.id + ' - ' + type(r) + ' -> ' + neighbor.id AS output
UNION ALL
WITH node
MATCH (node)<-[r:!MENTIONS]-(neighbor)
RETURN neighbor.id + ' - ' + type(r) + ' -> ' + node.id AS output
}
RETURN output LIMIT 50
""",
{"query": generate_full_text_query(entity)},
)
Graph-Enhanced Generation
今回は取得したトリプレットを LLM に与えているので、グラフ言語は 5.1-Graph-Formats で紹介した (1) Adjacency / Edge Table に相当します。また、その他特別な工夫はなされておりませんので、是非様々な Generation-Enhancement を試してみてください。
実行結果の考察
QUESTION = "屋久島と種子島はどこにありますか?" という質問に対して、例えば以下のようなトリプレットが検索されました。
屋久島 - LOCATED_IN -> 東シナ海
屋久島 - SECOND_LARGEST_ISLAND_IN -> 鹿児島県
種子島 - LOCATED_IN_SEA -> 東シナ海
これによって、どちらも東シナ海に位置していることを LLM へ構造的かつ明示的に与えられます。

屋久島と種子島の Wikipedia ページをナレッジグラフ化した際の俯瞰図(の一部表示)。
中央上の大きなコミュニティの中心が「屋久島」ノードで、左下の次に大きなコミュニティの中心が「種子島」ノードです。
それらのコミュニティを「鹿児島県」ノードや、「東シナ海」ノードが繋げている様子が見て取れます。
今回の実装では、通常のベクトル検索 RAG と比較するために[34]、構造化されたナレッジグラフの情報だけでなく、通常のテキストデータも拾ってくるようにしています。チャンクなどの設定にはよりますが、以下のように、大量の文章をつらつらとコンテキストとして LLM に与えるよりも、構造化された情報を与えると良いケースがあるかもしれないことを感じられれば、ハンズオンとしてはゴールです。
取得したテキスト情報の一部
text: 屋久島
ランドサット画像( 2002 年)
所在地
⽇本
⿅児島県熊⽑郡屋久島町
所在海域東シナ海
所属諸島⼤隅諸島
⾯積 504.88 km²
最⾼標⾼1,936 m
最⾼峰 宮之浦岳
⼈⼝ 11,858 ⼈( 2020 年、国勢調査)[1]
屋久島
出典 : フリー百科事典『ウィキペディア( Wikipedia )』
世界 > アジア > 東アジア > ⽇本 > 南⻄諸島 > ⼤隅諸島 > 屋久島
屋久島(やくしま)は、⿅児島県の⼤隅半島佐多岬南南⻄約 60kmの海上に位置する島。熊⽑郡屋久島町に属し、近隣の種⼦島や⼝永良部島などと共に⼤
隅諸島を形成する。南⽅に位置するトカラ列島や奄美群島などとともに南⻄諸島を構成する。
九州最⾼峰の⼭、宮之浦岳(標⾼1936m)がある。⾃然が豊かで、屋久島国
⽴公園の中核をなし、世界⾃然遺産の⼀つに登録されている[2]。
⾯積504.29 km2[3]、周囲 130km (東⻄約 28km 、南北 24km )[4]。円形に近い五
⾓形をしており、淡路島よりやや⼩さい[4]。⿅児島県の島としては奄美⼤島
に次いで 2 番⽬、⽇本の中では本州など 4 島を除くと⾯積第 9 位である[5]。
豊かで美しい⾃然が残されており、島の 90% が森林である。島の中央部の宮
之浦岳( 1936m )を含む屋久杉⾃⽣林や⻄部林道付近など、島の⾯積の約
21% にあたる 107.47 km2がユネスコの世界遺産に登録されている。この世界遺産への登録は1993 年、姫路城、法隆寺、⽩神⼭地とともに⽇本からの第⼀陣であった。
本島においての発電は、屋久島電⼯が製錬所の⾃家発電のために建設した⽕
⼒発電所と⽔⼒発電所からの電気を、安房電気利⽤組合、種⼦屋久農協、九州電⼒送配電、屋久島町の 4 事業者が分担して供給している。したがって本島では九州電⼒送配電が電気を供給していない世帯や事業者も存在する。平
素、島内の電⼒は⽔⼒発電で賄われており、⽕⼒発電は緊急時に限って活⽤される。
屋久島はほぼ全域が⼭地であり、 1,000m から 1,900m 級の⼭々の連なりは⼋重
岳と呼ばれ洋上アルプスの異名もある[6]。屋久島⼭地と記述した⽂献もあ
る[7][8]。中央部には⽇本百名⼭の⼀つで九州地⽅最⾼峰の宮之浦岳 (1,936m)がそびえる。このような中央部の⾼峰は奥岳と呼ばれ、永⽥岳を除き海岸部
の⼈⾥から望むことはできない。宮之浦岳、永⽥岳および栗⽣岳は屋久島三岳とされ、⼭頂に⼀品宝珠⼤権現が祀られ古来より嶽参りの対象とされてき
たが[9]、『三國名勝図會』の記す栗⽣嶽は位置的に現在の黒味岳に相当するとする説もある。海岸部から間近に聳える⼭々は前岳と呼ばれ、本富岳、国割岳および愛⼦岳などがある。また、喜界カルデラを⽣んだ約 7300 年前の⼤
噴⽕の際、屋久島は⽕砕流によって島の⼤部分が覆われたことがあるとされ
ている[10]。
...(以下略)
結び
とりあえずはインプットだ🔥と思って、GraphRAG のサーベイ論文と、そこで引用されている論文を読んでまとめました。いろいろ読んで思ったことは、まだまだ GraphRAG の決定版のようなものは確立されておらず、手探り状態で、いろんな手法が乱立しているということです[35]。おそらくはこの記事で紹介した手法のうち、ベストプラクティスとして残るものはほんの一部かもしれません。それでも、たくさんの情報に触れたことで、GraphRAG 改善時の観点は整理できたかと思っています。GraphRAG に魅力を感じた人が楽しく読んでいただけたのなら、GraphRAG を活用しようと思っている人に何かの役に立てたのなら、筆者の本望でございます。
一所懸命文献を読んでまとめたつもりですが、本記事の内容は例に漏れず私の理解が誤っている可能性は多いにありますので、お気づきの点がございましたらご指摘お願いいたします。
参考文献
- Graph Retrieval-Augmented Generation: A Survey Boci Peng, et al., 2024.
- Graph Reasoning for Question Answering with Triplet Retrieval Shiyang Li, et al., 2023.
- MVP-Tuning: Multi-View Knowledge Retrieval with Prompt Tuning for Commonsense Reasoning Yongfeng Huang, et al., 2023.
- UniOQA: A Unified Framework for Knowledge Graph Question Answering with Large Language Models Zhuoyang Li, et al., 2024.
- From Local to Global: A Graph RAG Approach to Query-Focused Summarization Darren Edge, et al., 2024.
- G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering Xiaoxin He, et al., 2024.
- GRAG: Graph Retrieval-Augmented Generation Yuntong Hu, et al., 2024.
- QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering Michihiro Yasunaga, et al., 2021.
- Subgraph Retrieval Enhanced Model for Multi-hop Knowledge Base Question Answering Jing Zhang, et al., 2022.
- RoBERTa: A Robustly Optimized BERT Pretraining Approach Yinhan Liu, et al., 2019.
-
GNN-RAG: Graph Neural Retrieval for Large Language Model Reasoning
Costas Mavromatis, George Karypis, 2024. - Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning Linhao Luo, et al., 2024.
- KagNet: Knowledge-Aware Graph Networks for Commonsense Reasoning Bill Yuchen Lin, et al., 2019.
- PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text Haitian Sun, et al., 2019.
- KnowledgeNavigator: Leveraging Large Language Models for Enhanced Reasoning over Knowledge Graph Tiezheng Guo, et al., 2024.
- Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering Yuqi Wang, et al., 2024.
- Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering Yanlin Feng, et al., 2020.
- Query Rewriting for Retrieval-Augmented Large Language Models Xinbei Ma, et al., 2023.
- Complex Logical Reasoning over Knowledge Graphs using Large Language Models Nurendra Choudhary, Chandan K. Reddy, 2023.
- KG-GPT: A General Framework for Reasoning on Knowledge Graphs Using Large Language Models Jiho Kim, et. al., 2023.
- Retrieve-Rewrite-Answer: A KG-to-Text Enhanced LLMs Framework for Knowledge Graph Question Answering Yike Wu, et al., 2023.
- Language is All a Graph Needs Ruosong Ye, et al., 2023.
- TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases Yiheng Shu, et al., 2023.
- GraphText: Graph Reasoning in Text Space Jianan Zhao, et al., 2023.
- LLaGA: Large Language and Graph Assistant Runjin Chen, et al., 2024
- GPT4Graph: Can Large Language Models Understand Graph Structured Data ? An Empirical Evaluation and Benchmarking Jiayan Guo, et al., 2023.
- Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering Gautier Izacard, Edouard Grave, 2020.
- Towards Foundation Models for Knowledge Graph Reasoning Mikhail Galkin, et al., 2023
-
KET-RAG: A Cost-Efficient Multi-Granular Indexing Framework for Graph-RAG
Yiqian Huang, et al., 2025. - HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction, Bhaskarjit Sarmah, et al., 2024.
- KET-RAG: A Cost-Efficient Multi-Granular Indexing Framework for Graph-RAG Yiqian Huang, et al., 2025.
お知らせ
少しでも弊社にご興味を持っていただけた方は、お気軽にご連絡頂けますと幸いです。まずはカジュアルにお話を、という形でも、副業を検討したいという形でも歓迎しています。
-
執筆当時 ↩︎
-
概論だけ読むつもりが、気づけば詳細まで読んでいるという状態になっていたら筆者としては感無量です。 ↩︎
-
AIが事実とは異なる内容を生成してしまうことです。 ↩︎
-
学習したデータの最終時点のことです。 ↩︎
-
RAG のサーベイ論文だけでもかなりの数があり、その注目度が窺い知れます。 ↩︎
-
文字列検索とベクトル検索と...などと書いているとそれだけで1記事書けそうな勢いがあります。通常のRAGの詳細な記事は多数出ているので、本記事では割愛しています。 ↩︎
-
実際に Wikipedia にも書かれています ↩︎
-
2025年3月現在。 ↩︎
-
文書の中間部で関連情報が見失われる問題です。RAG のテクニックで、関連が高そうなテキストから冒頭と末尾に交互に配置するテクニックがあるほどです。 ↩︎
-
ユーザーのクエリ(質問やリクエスト)に関連する情報を重点的に抽出し、簡潔に要約することです。 ↩︎
-
「AとBの関係はXです」と表現するのに、A, B, Xの3つが出てくるので、トリプレット(triplet)と言います。 ↩︎
-
2025年3月現在 ↩︎
-
そもそも網羅できるような代物ではありません。 ↩︎
-
私のZenn記事で、この記事を紹介するのは3回目です。いつも本当にお世話になっています。 ↩︎
-
狭義の言語モデルは token の確率分布を学習して次 token 予測を行うものを指しますが、広義の言語モデルとして「言語を扱うモデル」くらいの意味合いで識別モデルも言語モデルと言う場合があります。 ↩︎
-
Question Answering: 質問に答えることです。 ↩︎
-
質問に解答するのに必要という意味で、類似している度合いと捉えています。 ↩︎
-
alignってやつです。 ↩︎
-
検索効率を上げるための前処理、くらいに理解しています。 ↩︎
-
elementsのことです。 ↩︎
-
わざわざ書くまでもありませんが、日本の首都って京都ですよね。 ↩︎
-
グラフにおいて、各ノードやエッジが異なる意味を持ちうるグラフのことです。対照的に、1種類のノードと、同じ意味合いのエッジによって関係を示したものを Homogeneous と言います。Homogeneous の例としては、人ノードと友人エッジしか存在しないグラフが挙げられます。ノードを単なる人ではなく、男女で分けたり、エッジに兄、親などの関係性をグラフの属性として加えると Heterogeneous になります。 ↩︎
-
もちろん実用レベルに持っていくには要件整理や前処理など、相応の努力が必要です。 ↩︎
-
グラフ内において、密接に結びついたノードのグループのことです。私は密集地帯みたいなイメージを持っています。 ↩︎
-
ある中心となるノード(ego)とその隣接ノードからなる局所的なサブグラフのことです。 ↩︎
-
topic entities から
k -
Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering ↩︎
-
例えば GRAG: Graph Retrieval-Augmented Generation がサーベイ論文では紹介されています。 ↩︎
-
ユーザーからの入力(プロンプト)を LLM が検索に適したテキストに書き換える手法です。 ↩︎
-
質問に関係なさそうなものを削除することです。 ↩︎
-
ノードの数分の行と列を持ち、どのノードがどのノードへのエッジがあるかを表す行列です。 ↩︎
-
実務上でもこのようなハイブリッド式が良いとはされています。 ↩︎
-
2010年代の DeppLearning の手法系論文が出まくっていた頃を思い返します。 ↩︎

Discussion
非常に参考になりました。執筆感謝です!
お茶目で可愛いです。
大変勉強になりました!